Появился Vision Transformer, который идеально поддерживает ввод любого разрешения | Производительность сверхбольших разрешений, таких как 4032×4032, превосходит такие модели, как DeiT

В этой статье рассматривается основная проблема, с которой сталкиваются визуальные преобразователи (ViT): их ограниченная масштабируемость при различных разрешениях изображений. Обычно производительность ViT ухудшается при обработке разрешений, отличных от тех, которые наблюдались во время обучения. Работа авторов представляет две ключевые инновации для решения этой проблемы. Во-первых, предлагается новый модуль для динамической регулировки разрешения, который разрабатывает один блок Transformer специально для достижения эффективной поэтапной интеграции токенов. Во-вторых, в Vision Transformer введено нечеткое кодирование положения, чтобы обеспечить единообразную распознавание положения при нескольких разрешениях, тем самым предотвращая переподгонку к какому-либо одному тренировочному разрешению. ViTAR (визуальный преобразователь с произвольным разрешением) демонстрирует отличную адаптивность, достигая точности Top-1 83,3% при разрешении 1120x1120 и точности 80,4% при разрешении 4032x4032, при этом снижая вычислительные затраты. ViTAR также демонстрирует высокую производительность в последующих задачах, таких как экземплярная и семантическая сегментация, и его можно легко комбинировать с методами самоконтролируемого обучения, такими как автокодировщики маски. Наша работа обеспечивает экономически эффективное решение для улучшения масштабируемости разрешения ViT, открывая путь к более гибкой и эффективной обработке изображений с высоким разрешением.
1 Introduction
Огромный успех Transformer в области обработки естественного языка (NLP) вдохновил на значительные исследования в сообществе компьютерного зрения (CV). В частности, визуальные преобразователи (ViT) сегментируют изображения на непересекающиеся фрагменты, проецируют каждый фрагмент на маркер, а затем применяют многоголовое самообслуживание (MHSA) для фиксации зависимостей между различными маркерами. Благодаря превосходным возможностям моделирования Transformer, ViTs добился хороших результатов в различных задачах машинного зрения, включая классификацию изображений, обнаружение целей, визуальное моделирование и даже распознавание видео.
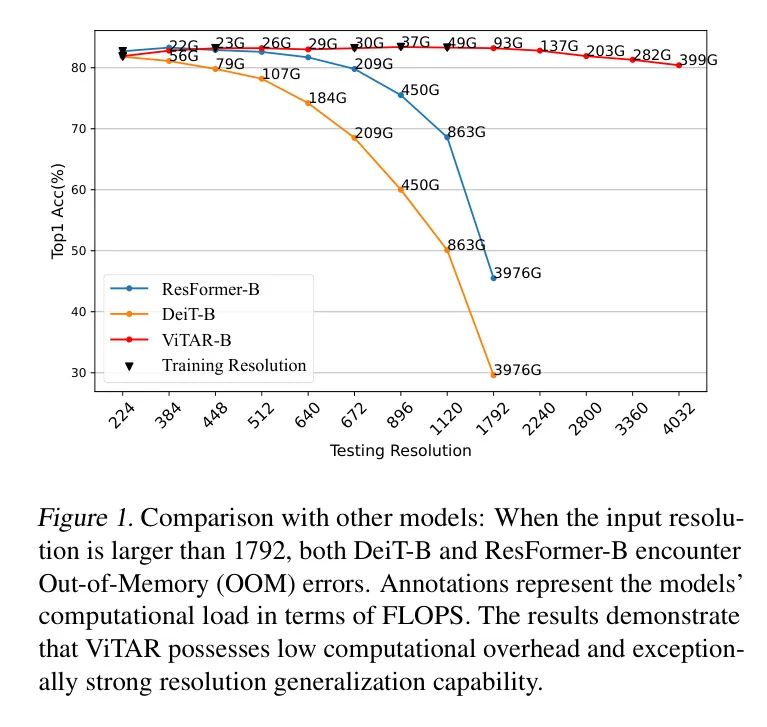
Рисунок 1: Сравнение с другими моделями: И DeiT-B, и ResFormer-B столкнулись с ошибками нехватки памяти (OOM), когда входное разрешение превышало 1792. В аннотациях указана вычислительная нагрузка модели в единицах FLOPS. Результаты показывают, что ViTAR имеет низкие вычислительные затраты и особенно сильные возможности обобщения разрешения.
Несмотря на свой успех в различных областях, ViT неудовлетворительно работают в реальных сценариях, где необходимо обрабатывать входные данные с переменным разрешением. Лишь немногие исследования изучали, как адаптировать ViT к различным разрешениям. На практике никакое обучение не может охватить все разрешения, простым и широко используемым методом является интерполяция непосредственно перед вводом позиционного кодирования в ViT. Однако такой подход приводит к значительному снижению производительности в таких задачах, как классификация изображений. Чтобы решить эту проблему, ResFormer включает в процесс обучения изображения с разным разрешением. Кроме того, в позиционные кодировки, используемые ViT, были внесены улучшения, превратившие их в более гибкие позиционные кодировки на основе свертки.
Однако ResFormer по-прежнему сталкивается с проблемами. Во-первых, он может поддерживать высокую производительность только в относительно узком диапазоне изменения разрешения, как показано на рисунке 1. При увеличении разрешения, превышающего 892 или даже выше, производительность модели существенно падает. Кроме того, из-за внедрения позиционного кодирования на основе свертки становится сложно интегрировать ResFormer в широко распространенные системы самоконтроля, такие как Masked AutoEncoder (MAE).
В этом исследовании авторы предлагают визуальный преобразователь с возможностью произвольного разрешения (ViTAR), который обрабатывает изображения высокого разрешения с низкой вычислительной нагрузкой и демонстрирует сильные возможности обобщения разрешения. В ViTAR автор представляет модуль Adaptive Token Merging (ATM), который итеративно обрабатывает токены, встроенные в срезы. Банкомат распределяет все токены по сетке. Этот процесс сначала рассматривает токен в сетке как единое целое. Затем постепенно объедините токены в каждой единице и, наконец, сопоставьте все токены с сеткой фиксированной формы. В результате этого процесса создается коллекция так называемых «жетонов сетки».
Впоследствии этот набор токенов сетки подвергается извлечению функций с помощью серии нескольких модулей самообслуживания с несколькими головками. Модуль ATM не только улучшает адаптивность модели к разрешению, но также позволяет снизить вычислительную сложность при обработке изображений с высоким разрешением. Как показано на рисунке 1, ViTAR лучше обобщает невидимые разрешения, чем DeiT и ResFormer. Кроме того, по мере увеличения входного разрешения вычислительные затраты, связанные с ViTAR, сокращаются до одной десятой от традиционного ViT или даже ниже.
Чтобы модель могла обобщаться на произвольные разрешения, авторы также разработали метод, называемый нечетким позиционным кодированием (FPE). FPE вносит определенную степень возмущения положения, превращая точное восприятие положения в нечеткое восприятие со случайным шумом. Эта мера предотвращает переподгонку модели к местоположениям с определенным разрешением, тем самым повышая адаптируемость модели к разрешению. В то же время FPE можно понимать как неявное улучшение данных, которое позволяет модели получать более надежную информацию о местоположении и достигать более высокой производительности.
Вклад авторов можно резюмировать следующим образом:
- Автор предлагает простой и эффективный модуль адаптации мультиразрешения – Adaptive Marker Merger.,Включите ViTAR для адаптации к требованиям рассуждений с несколькими разрешениями. Этот модуль адаптивно объединяет входные токены по,Значительно улучшены возможности обобщения разрешения модели.,И значительно снижает вычислительную нагрузку модели при вводе с высоким разрешением.
- Автор вводит нечеткое положение кодирования (Fuzzy Positional Encoding),Этот вид кодирования позволяет модели воспринимать надежную информацию о местоположении во время обучения.,а не подгонка под конкретное разрешение. Автор преобразует обычно используемое кодирование точного положения точки в нечеткое восприятие дальности. Это значительно улучшает адаптируемость модели к входным сигналам с различным разрешением.
- Автор проводит обширные эксперименты для проверки эффективности авторского метода в множественных рассуждениях. Основа автора Модель 224.、Входное разрешение 896 и 4032 соответственно достигло 81,9.、Точность Топ-1 83,4 и 80,4. Его надежность значительно превосходит существующую Ви ТМодель. ViTAR также демонстрирует высокую производительность в последующих задачах, таких как сегментация экземпляров и семантическая сегментация.
2 Related Works
Визуальный трансформер. Visual Transformer (ViT) — это мощная архитектура машинного зрения, которая демонстрирует впечатляющую производительность в классификации изображений, распознавании видео и визуально-лингвистическом обучении. Было предпринято много усилий для повышения эффективности ViT как с точки зрения данных, так и с точки зрения эффективности вычислений. В этих исследованиях большинство исследователей использовали тонкую настройку, чтобы адаптировать модель к более высокому разрешению, чем при обучении. В немногих исследованиях предпринимались попытки напрямую адаптировать модели к неизвестным разрешениям без тонкой настройки, что часто приводит к снижению производительности. Точная настройка при высоких разрешениях часто требует дополнительных вычислительных затрат. Поэтому особенно важно разработать модель машинного зрения, которая может напрямую обрабатывать несколько разрешений. Однако это направление остается малоизученным.
Многозначное рассуждение. Исследование способности единой модели видения выполнять рассуждения с разным разрешением остается в значительной степени неисследованной областью. Для большинства моделей зрения, если разрешение, используемое во время вывода, отличается от разрешения, используемого во время обучения, и если вывод выполняется напрямую без тонкой настройки, будет наблюдаться ухудшение производительности. Будучи новаторской работой в этой области, ResFormer применяет подход, включающий обучение с несколькими разрешениями, чтобы позволить модели адаптироваться к входным изображениям различного разрешения. Он также добавляет несколько уникальных кодировок положения, чтобы улучшить способность модели адаптироваться к различным разрешениям.
Однако позиционное кодирование, используемое ResFormer, основано на сверточной нейронной сети, и эту конфигурацию трудно применить к средам самоконтролируемого обучения, таким как MAE. Кроме того, сам ResFormer основан на оригинальной архитектуре ViT, которая требует значительных вычислительных затрат при увеличении входного разрешения. Чтобы сделать модель адаптируемой к более широкому диапазону разрешений и подходящей для широко используемых сред самообучения, необходима дальнейшая оптимизация модели.
Кодирование позиции. Кодирование положения имеет решающее значение для ViT, часто обеспечивая его распознавание местоположения и повышение производительности. Ранние версии ViT использовали синус-косинусное кодирование для передачи информации о местоположении, и некоторые исследования продемонстрировали надежность этого метода кодирования положения при ограниченном разрешении. Напротив, позиционное кодирование на основе свертки демонстрирует более высокую устойчивость к разрешению. Модели, использующие сверточное позиционное кодирование, могут даже повысить производительность при работе с невидимыми разрешениями. К сожалению, сверточное позиционное кодирование препятствует применению модели в средах самоконтролируемого обучения, таких как MAE. Это затрудняет применение модели для обучения крупномасштабным неразмеченным наборам данных.
3 Methods
Overall Architecture
Общая структура ViTAR показана на рисунке 2 и в основном включает в себя адаптивное слияние меток (ATM), нечеткое позиционное кодирование (FPE) и традиционную архитектуру ViT. Автор не использует многоуровневую структуру; вместо этого автор использует сквозную архитектуру, аналогичную ResFormer и DeiT.
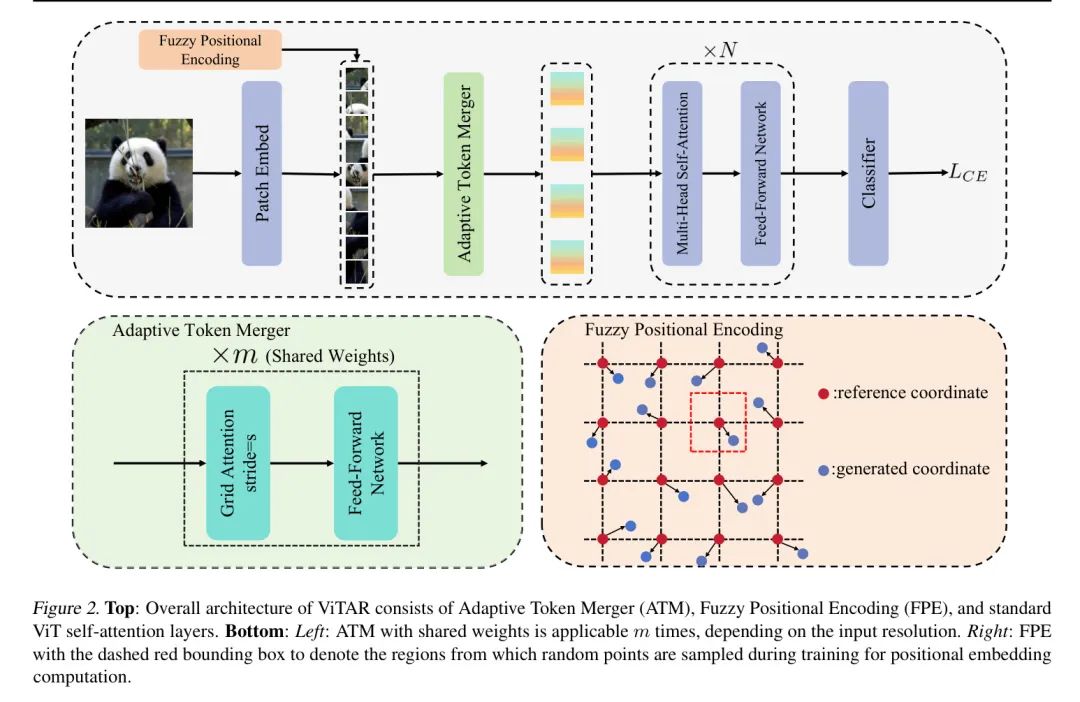
картина2:вершина:ViTARОбщая архитектура включает в себя адаптивный объединитель тегов.(ATM)、Нечеткое местоположениекодирование(FPE)истандартныйViTслой самообслуживания。нижний:_левый_:Общий весATMМожет применяться в зависимости от входного разрешения
Второсортный. _Справа_: FPE с пунктирной красной рамкой представляет собой область маркера, из которой случайным образом выбираются точки при вычислении встраивания позиции во время обучения.
Adaptive Token Merger (ATM)
Модуль ATM получает на вход встроенные теги Patch. Автор по умолчанию
Количество оценок, которые в конечном итоге надеется получить автор. Банкомат будет иметь форму
Знаки делятся на размеры
сетка. Для простоты представления автор предполагает
может быть
делимый,
может быть
Делимый. Следовательно, количество маркеров, содержащихся в каждой сетке, равно
. В практических приложениях
Обычно устанавливается на 1 или 2,
Относитесь к этому так же.
В частности, когда
Когда автор устанавливает
, таким образом получая
. когда
Когда же автор
заполнить до
и установить
, все еще поддерживаю
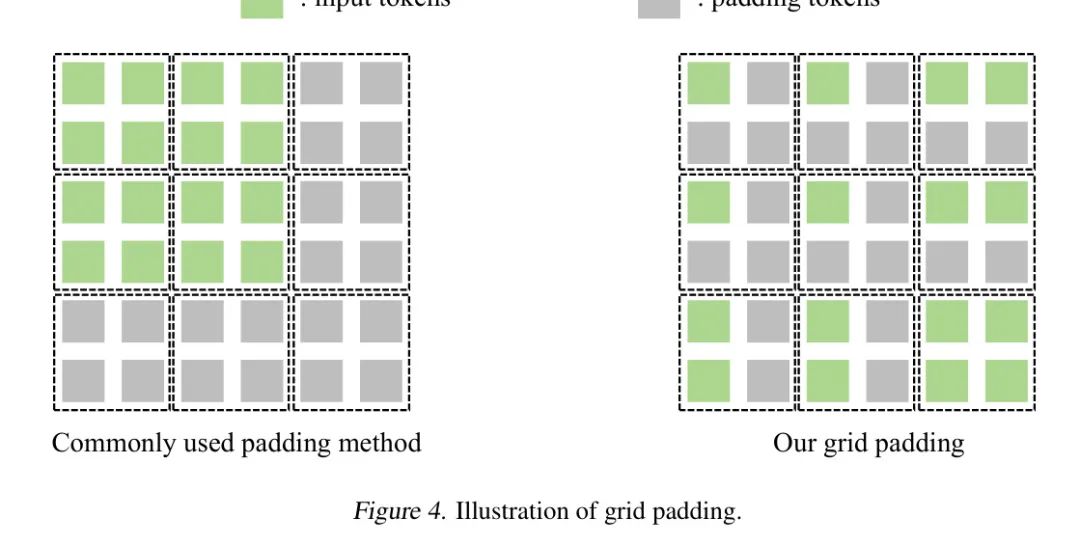
. Конкретные способы заполнения можно найти в приложении.
час,
Отметины на краях больше не сливаются, в результате чего
. Предположим, что для конкретной сетки ее отметка выражается как
,в
и
. Автор несет ответственность за все
Выполните объединение средних значений, чтобы получить среднюю метку. Впоследствии, используя средний токен в качестве Query, все
как ключ и значение,Авторы используют перекрестное внимание, чтобы объединить все токены внутри сетки в один токен. Автор назвал этот процесс GridAttention.,Кратко это можно описать на рисунке 3.
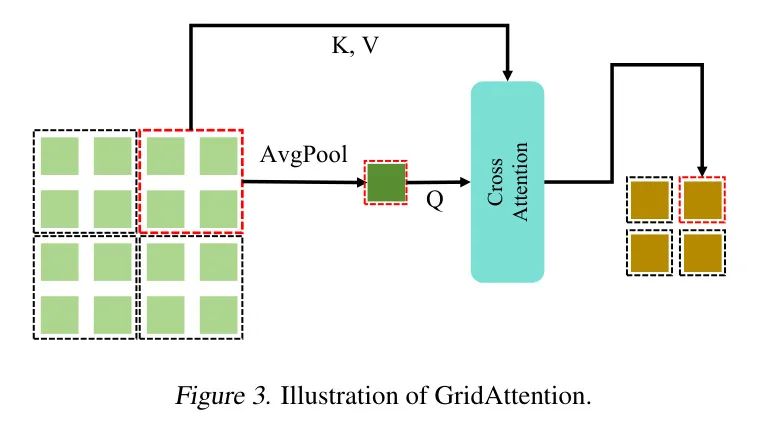
Рисунок 3: Принципиальная схема механизма внимания сетки.
Подобно стандартному механизму самоконтроля с несколькими головками, GridAttention также включает остаточные соединения. Для выравнивания формы маркеров авторы использовали остаточные связи со средним пулом. Полный GridAttention показан в уравнении 1.
После обработки GridAttention,Слитые маркеры подаются в стандартную сеть прямой связи для завершения слияния каналов.,На этом итерация слияния меток завершена. GridAttentionиFFN выполняет несколько итераций, и итерации имеют одинаковый вес. Во время этих итераций,Автор постепенно уменьшает
значение до
и
. Как и в стандартном ViT, авторы обычно устанавливают
. Этот метод поэтапного объединения меток значительно улучшает адаптируемость разрешения ViTAR и снижает вычислительную нагрузку модели при большом входном разрешении.
Fuzzy Positional Encoding
Многие исследования указывают,Часто используемые обучаемые позиции кодирования синусоидальных и косинусоидальных позиций очень чувствительны к изменениям входного разрешения.,и они не могут обеспечить эффективную адаптируемость разрешения. Хотя кодирование положения на основе свертки демонстрирует лучшую устойчивость к разрешению.,Но его восприятие соседних маркеров не позволяет ему, например,MAEТакое яконтролируемое Приложения в обучениирамка.
Авторский ФПЭ отличается от приведенного выше метода. Повышая надежность разрешения, он не вводит определенную пространственную структуру, такую как свертка. Следовательно, его можно применять, поскольку это разрешено. обучениерамкасередина. Эта функция позволяет применять ViTAR к крупномасштабным, Без маркировки Обучающий набор обучается для получения более мощной визуальной базовой модели.
В FPE, следуя ViT, авторы случайным образом инициализируют набор обучаемых вложений позиций в качестве кодирования позиции модели. Во время обучения модели типичное кодирование положения обычно предоставляет модели точную информацию о местоположении. Напротив, FPE предоставляет модели только нечеткую информацию о местоположении, как показано на рисунке 2. Информация о местоположении, предоставляемая FPE, смещена в определенном диапазоне. Предположим, что точные координаты целевого маркера
, координаты местоположения, предоставленные FPE во время обучения,
,в
。
и
Все следуют равномерному распределению. во время тренировки,Автор добавляет к координатам ссылки случайно сгенерированные смещения координат. На основе вновь сгенерированных координат,Авторы выполняют выборку сетки обучаемых вложений позиций, таким образом получая Нечеткое кодирование позиции.
в процессе рассуждения,Автор больше не использует неоднозначные локации кодирования.,Вместо этого выберите точное место кодирования. когда输入картина像分辨率发生改变час,Авторы интерполируют обучаемые вложения местоположений. Поскольку кодирование позиций размытия использовалось на этапе обучения, для любого интерполированного кодирования положения Модель могла увидеть и каким-то образом использовать его. В результате Модель приобрела сильную позиционную адаптивность. В результате при выводе столкнулся с невиданным разрешением входных данных.,Модель по-прежнему демонстрирует солидную производительность.
Multi-Resolution Training
Похоже на: ResFormer,При обучении ViTARчас автор также применил метод обучения с несколькими разрешениями. По сравнению с Рес Формером,ViTAR значительно снижает вычислительные требования при обработке изображений высокого разрешения.,Это позволяет авторам использовать более широкий диапазон разрешений во время обучения. В отличие от ResFormer, который обрабатывает входные пакеты с различным разрешением.,и используйте потерю KL для контроля перекрестного разрешения,ViTAR обрабатывает каждую партию входных данных с постоянным разрешением.,Полагаясь только на базовую потерю перекрестной энтропии для контроля.
На основе стратегии обучения с несколькими разрешениями,ViTAR может применяться к очень широкому диапазону разрешений.,并существоватькартина像分类任务середина取得良好результат.такой жечас,При обработке входных задач высокого разрешения (сегментация экземпляров, семантическая сегментация)час,ViTARдостигает существующих результатов при гораздо меньших вычислительных затратах Модель Сходствопроизводительность。Конкретно,В задачах сегментации экземпляров и семантической сегментации, требующих ввода с высоким разрешением.,ViTAR использует 50% провалов,Достиг аналогичного результата с ResFormerиDeiT.
4 Experiments
Авторы проводят обширные эксперименты над множеством задач по зрению, такими как классификация изображений в ImageNet-1K, сегментация экземпляров в COCO и семантическая сегментация в ADE20K. Автор также обучит модель на платформе самоконтроля MAE для проверки совместимости между ViTAR и MAE. После этого авторы провели исследования абляции, чтобы проверить важность каждого компонента ViTAR.
Image Classification
настраивать.Автор начинает с нуляImageNet-1KобучениеViTAR。Автор следуетDeiTсерединаиз训练策略,Но дополнительный контроль потерь при перегонке снят. Единственным надзором ViTAR является потеря классификации. Авторы используют оптимизатор AdamW с планировщиком скорости обучения по косинусному затуханию для обучения всех моделей. Автор устанавливает начальную скорость обучения, затухание веса и размер пакета равными 0,001, 0,05 и 1024 соответственно. То же, что Деи Т,Этот параметр включает RandAugment(randn9-mstd0.5-inc1), Mixup(prob=0,8), CutMix(prob=1,0), случайное смешивание (вероятность=0,25). Для стабилизации процесса обучения автор также использовал слои распада.
результат.МодельсуществоватьImageNet上取得из结果展示существоватьповерхность1середина。ViTARсуществовать相当大из分辨率范围内展示了优秀из分类准确性。для"S"большой или маленький Модель,当输入картина像из分辨率超过2240час,Из-за ограничений вычислительных ресурсов традиционная архитектура ViT (DeiTиResFormer) не может выполнять логический вывод. Напротив, ViTAR способен выполнять логические выводы с меньшими вычислительными затратами, сохраняя при этом высокую точность (**2800: 52G)., 81.3%**,3360: 72G, **80.0%**)。
Для модели размера «B»,ViTAR демонстрирует аналогичную картину,并能很好地适应输入картина像分辨率из改变. Когда размер ввода составляет 1120 часов, он показывает лучшую точность классификации **83,3%**, но требует только ViT. 1/20изFLOPs。такой жечас,По результатам эксперимента,ViTAR демонстрирует улучшенную генерализацию разрешения с увеличением размера (при разрешении 4032 пикселей).,ViTAR-B достиг повышения производительности на 1,8% по сравнению с ViTAR-S).
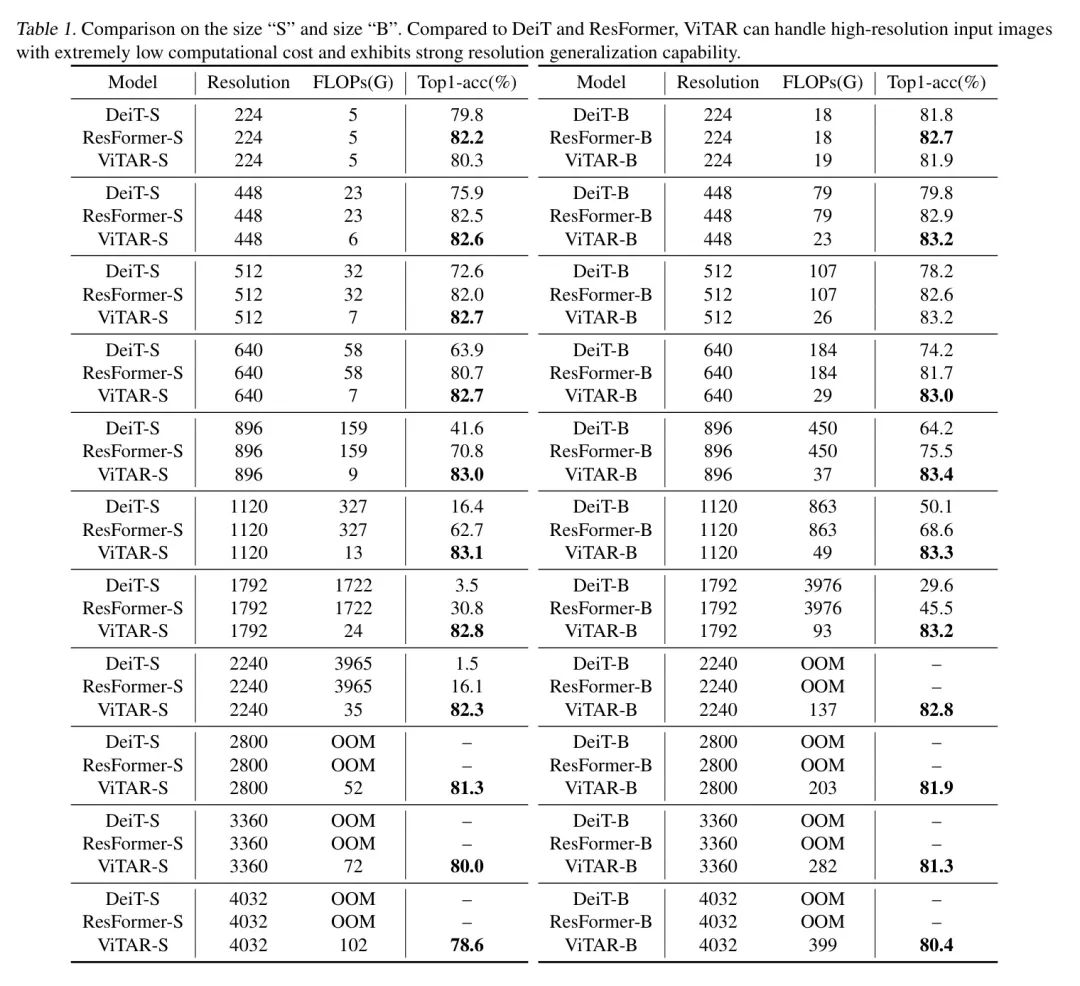
Таблица 1: Размер «S» в сравнении с размером «B». По сравнению с DeiTиResFormer,ViTAR способен обрабатывать входные изображения высокого разрешения с чрезвычайно низкими вычислительными затратами.,И демонстрирует сильные возможности обобщения разрешения.
Object Detection
настраивать.Автор принимаетMMDetectionосознатьMask-RCNN,Проверить эффективность ViTAR при обнаружении целей. Набор данных, используемый автором, — COCO. Экспериментальная установка автора основана на ResFormerиViTDet. Автор использует общепринятые
план обучения для обучения модели. Автор применяет оптимизатор AdamW с начальной скоростью обучения
и установите снижение веса на
. Следуя предыдущей работе, авторы используют размер пакета 16.
результат.существовать目标检测и实例分割任务середина,Авторы не использовали стратегию обучения с несколькими разрешениями. поэтому,ATM выполняет итерацию только один раз. в банкомате,
и
Установлено на 1. Результаты, представленные в таблице 2, показывают, что,ViTAR добился отличных результатов как в обнаружении целей, так и в сегментации экземпляров. Конкретно,Ви ТАР-Б
Превосходит ResFormer-B
, да и по другим показателям ViTAR-B тоже лучше ResFormer.
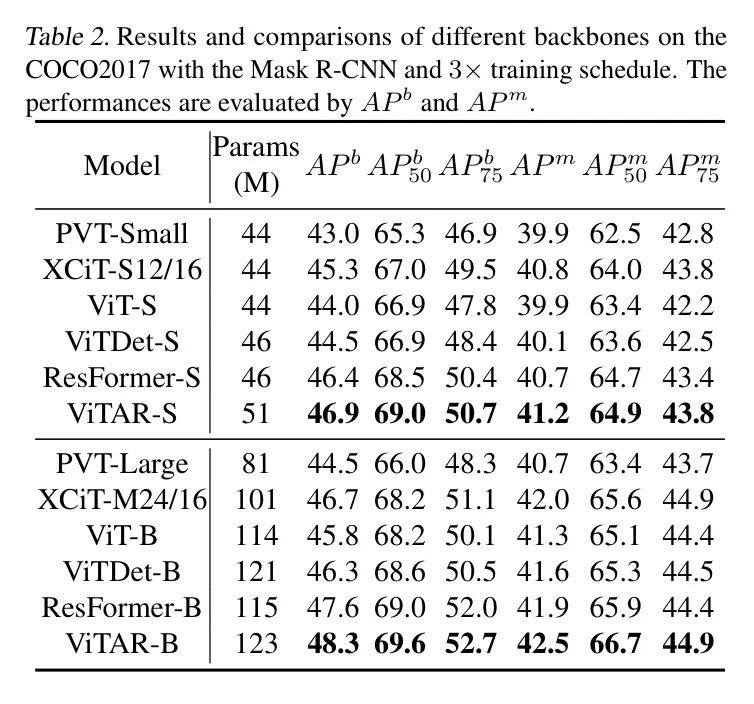
Таблица 2. Набор данных COCO2017 с использованием маски R-CNNи
Результаты и сравнение различных магистральных сетей для планов обучения. Выступление пройдено
и
Сделайте оценку.
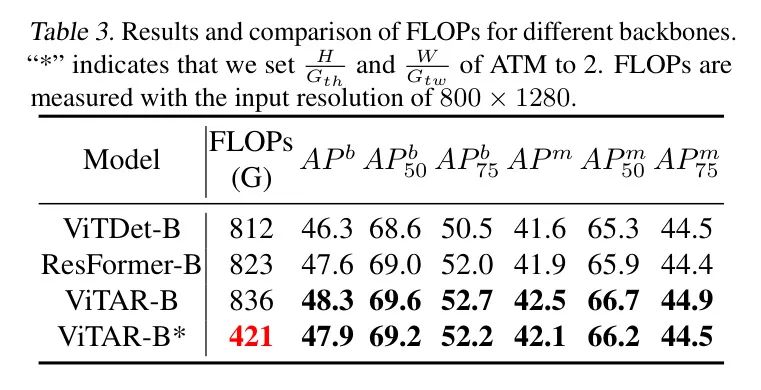
В дальнейшем, чтобы уменьшить вычислительную нагрузку ViTAR, автор будет
и
установить на 2,и сравнил ViTAR со стандартным ViT,Как показано в Таблице 3. Модуль ATM снижает вычислительные затраты примерно на 50%, сохраняя при этом высокую точность плотных прогнозов.,доказал свою эффективность. Эти результаты убедительно показывают,Банкомат получил возможность адаптироваться к разрешениям различного размера.
Semantic Segmentation
настраивать.следоватьResFormerиз做法,Автор использует MMSegmentation для реализации UpperNet.,Проверить производительность ViTAR. Набор данных, используемый автором, — ADE20K. Для обучения UpperNet,Автор придерживается настроек по умолчанию в Swin. В качестве оптимизатора автор выбирает AdamW.,Для обучения Модель,Количество итераций 80k/160k.
результат:作者существоватьповерхность4иповерхность5середина报告了分割изрезультат.就像существовать目标检测середина所做из那样,Автор впервые описывает банкомат
и
установить на 1,Сравнить ViTAR со стандартной ViTМодель. Как показано в Таблице 4,ViTAR работает лучше, чем ResFormer и другие варианты.

Таблица 4: Результаты и сравнение различных магистральных сетей в наборе данных ADE20K. Все магистральные сети предварительно обучены на ImageNet-1k.
В частности, авторская небольшая база Моделей Модель улучшена на 0,6 млн.
и
установить на 2,Результаты показаны в Таблице 5. Авторский банкомат снижает вычислительные затраты примерно на 40%,При этом сохраняя точность, аналогичную оригинальной модели. Это полностью доказывает эффективность модуля банкомата. Результаты сегментации экземпляров и семантической сегментации показывают, что,ViTAR способен обрабатывать изображения высокого разрешения с относительно небольшими вычислительными затратами.,Вряд ли влияет на Модельпроизводительность.
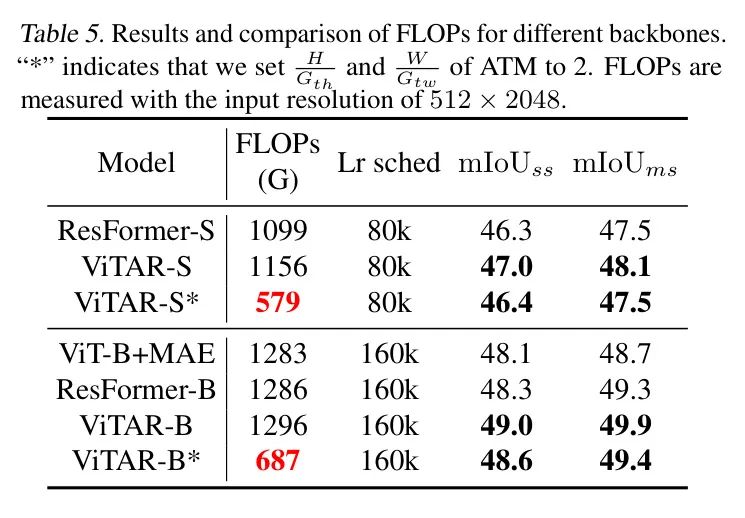
Таблица 5: Результаты FLOP и сравнение различных магистральных сетей. «*» означает, что автор будет использовать банкомат.
и
Установите на 2. Флопы основаны на
Входное разрешение используется в качестве эталона для измерений.
Compatibility with Self-Supervised Learning
**Настройки.**ResFormer использует свертку для кодирования положения, что затрудняет совместимость с системами самоконтролируемого обучения, такими как Mask AutoEncoder (MAE), поскольку MAE разрушает пространственную структуру изображения. Поскольку ViTAR не вводит пространственную структуру, связанную со сверткой, а предложенное автором нечеткое кодирование положения (FPE) не требует дополнительной пространственной информации, его удобнее интегрировать в MAE. В отличие от стандартного MAE, авторы по-прежнему применяют стратегию ввода с несколькими разрешениями во время обучения. Авторы предварительно обучили ViTAR-B в течение 300 эпох и выполнили дополнительные 100 эпох точной настройки.
результат.作者существоватьповерхность6середина报告了实验результат.Только предварительно обученный300个周期изViTAR,существоватьи预训练了1600个周期изViTМодельверно Сравниватьсередина显示出明显из优势. Когда входное разрешение увеличивается, производительность ViT+MAE значительно снижается. С другой стороны, ViTAR+MAE демонстрирует высокую надежность разрешения. Даже если входное разрешение превышает 4000, Модель сохраняет высокую производительность. Эти результаты показывают, что ViTAR имеет обучениерамкасередина具有很大潜力,Как показано в МАЭ. Преимущество ViTAR перед MAE может быть обусловлено двумя аспектами. Во-первых, банкомат позволяет модели изучать токены более высокого качества.,Обеспечивает часть полученной информации для Модели. Второй — FPE как неявное улучшение данных.,Позволяет модели получать более точную информацию о местоположении. Как показывает Droppos,Информация о местоположении модели имеет решающее значение для процесса ее обучения.

Таблица 6: Результаты с использованием структуры MAE. Резолюции обучения, использованные автором: (224, 448, 672, 896, 1120).
Ablation Study
Адаптивное слияние разметки.Адаптивное объединение теговViTARсерединаиз一个关键模块,Это позволяет модели обрабатывать входные данные с несколькими разрешениями. В процессе объединения тегов,Это эффективно снижает вычислительную нагрузку,и позволяет модели легко адаптироваться к различным входным разрешениям. Авторы сравнивают два метода объединения маркеров: ATM (Adaptive Marker Merging) и AvgPool (Adaptive Average Pooling). Для среднего пула,Автор делит все теги на
сетки, а маркеры внутри каждой сетки усредняются для объединения маркеров внутри этой сетки. Количество маркеров, полученных после этого слияния, такое же, как и после обработки АТМ. Результаты сравнения представлены в таблице 7. Авторы использовали ViTAR-S для проведения исследований абляции.
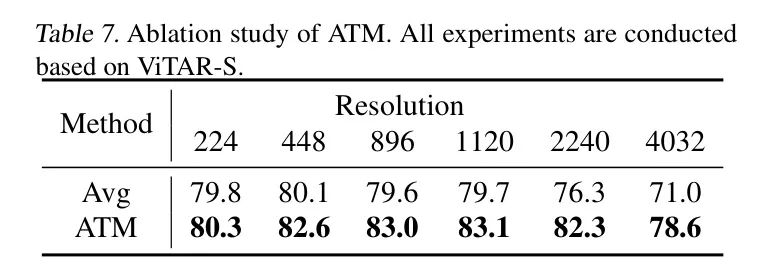
Таблица 7: Исследование абляции АТМ. Все эксперименты проводились на базе ViTAR-S.
Результаты в Таблице 7 показывают,Авторский АТМ существенно повышает производительность и разрешающую способность Модели. Особенно в сценах с высоким разрешением.,Преимущества банкоматов становятся все более очевидными. Конкретно,В разрешении 4032,作者提出изATMСравнивать Baseline Улучшена точность на 7,6%. При разрешении 224 ATM также демонстрирует улучшение производительности на 0,5% по сравнению с AvgPool.
Нечеткое кодирование позиции.作者Сравнивать较了不такой жеиз位置кодированиеверно Модель分辨率泛化能力из影响。这包括существоватьResFormerсередина常用изsimcos绝верно位置кодирование(APE),условное положениекодирование(CPE),Кодирование глобальной локальной позиции (GLPE),Относительное смещение позиции (RPB) в Swin,и ФПЭ, предложенный автором. Стоит отметить, что,С МАЭрамкой совместим только APEиFPE. Из-за присущей свёртке пространственной структуры расположения,Две другие позиции кодирования трудно интегрировать в структуру обучения MAE. Для модели без MAE,Автор использует ViTAR-S для экспериментов.,И для модели с использованием MAE,Авторы используют ViTAR-B.
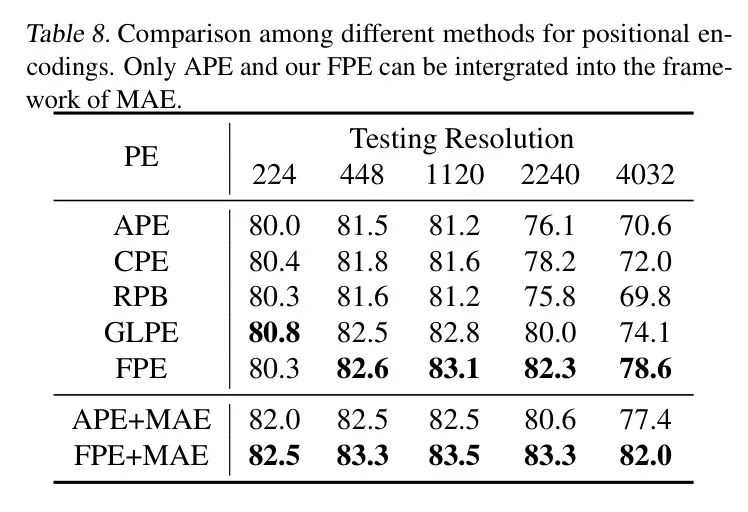
Результаты различных кодировок положения при различных разрешениях испытаний показаны в Таблице 8. Видно, что предложенный автором FPE демонстрирует значительные преимущества в способности к обобщению разрешения. Кроме того, в рамках системы самостоятельного обучения MAE FPE также демонстрирует превосходные результаты по сравнению с APE, что доказывает потенциальную применимость FPE в более широком диапазоне областей. В частности, при входном разрешении 4032 точность FPE Top-1 превышает GLPE на 4,5%. В рамках MAE FPE на 4,6% выше, чем APE.
резолюция по обучению.иResFormer仅существовать训练期间使用较低分辨率(128、160、224)不такой же,Благодаря вычислительной эффективности ViTAR,Он может обрабатывать ввод с очень высоким разрешением. также,Использование более широкого диапазона разрешения расширило возможности ViTAR по обобщению в предыдущих экспериментах.,Авторы использовали (224, 448, 672, 896, 1120) эти разрешения для обучения всех моделей. в этом разделе,Авторы стараются уменьшить разрешение, используемое во время обучения.,Проверить энергию обобщения разрешения Моделисилы.
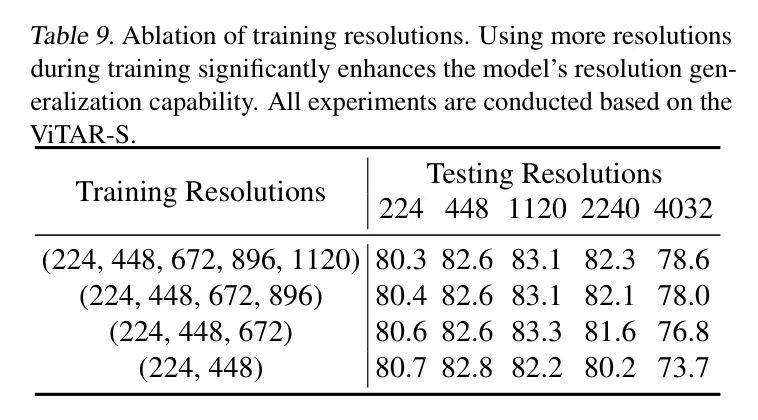
Таблица 9: Исследование абляции при разрешении тренировки. Использование большего разрешения во время обучения значительно повышает способность Моделисилы к обобщению разрешения. Все эксперименты проводятся на базе ViTAR-S.
Результаты экспериментов, представленные в Таблице 9, показывают, что,В диапазоне разрешения, использованном в экспериментах,Модель Чем выше разрешение, используемое при обучении,Чем сильнее его способность к обобщению разрешения. в частности,Когда ViTAR обучается с использованием этих пяти разрешений (224, 448, 672, 896, 1120), Модель демонстрирует самую сильную способность к обобщению разрешения по сравнению с обучением с использованием только (224, 448).,Точность при высоком разрешении (4032) повышена на 4,9%. Это наглядно демонстрирует эффективность обучения с несколькими разрешениями.
5 Conclusions
В этой работе авторы предлагают новую архитектуру: визуальный преобразователь с произвольным разрешением (ViTAR). Функция адаптивного объединения маркеров в ViTAR позволяет модели адаптивно обрабатывать входные изображения с переменным разрешением, постепенно объединяя маркеры до фиксированного размера, что значительно расширяет возможности обобщения разрешения модели и повышает производительность при обработке входных данных с высоким разрешением. Снижаются вычислительные затраты. Кроме того, ViTAR включает в себя нечеткое позиционное кодирование, позволяющее модели запоминать надежную позиционную информацию и обрабатывать входные данные высокого разрешения, которые не встречаются во время обучения.
ViTAR также совместим с существующими системами самостоятельного обучения на базе MAE, демонстрируя свой потенциал для крупномасштабного обучения. Без маркировки Набор данных。существовать需要高分辨率输入из任务,Например, сегментация экземпляров и семантическая сегментация.,ViTAR значительно снижает вычислительные затраты практически без потери производительности. Авторы надеются, что это исследование вдохновит последующие исследования в области обработки изображений с высоким или переменным разрешением.
ссылка
[1].ViTAR: Vision Transformer with Any Resolution.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
