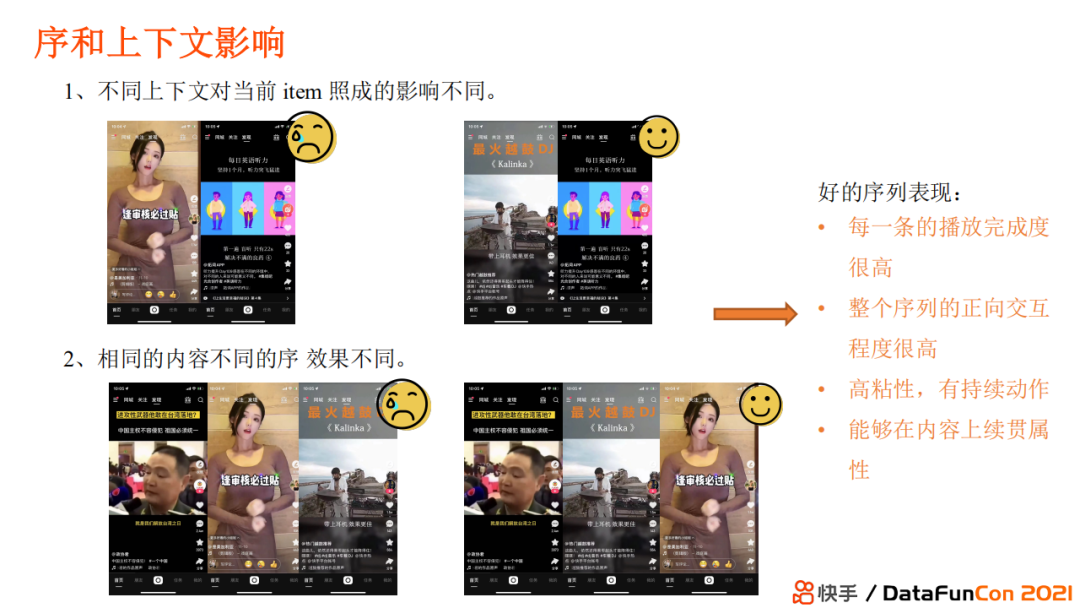
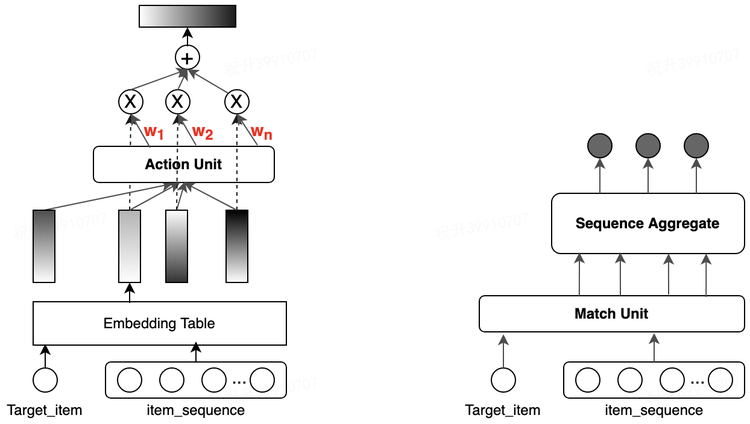
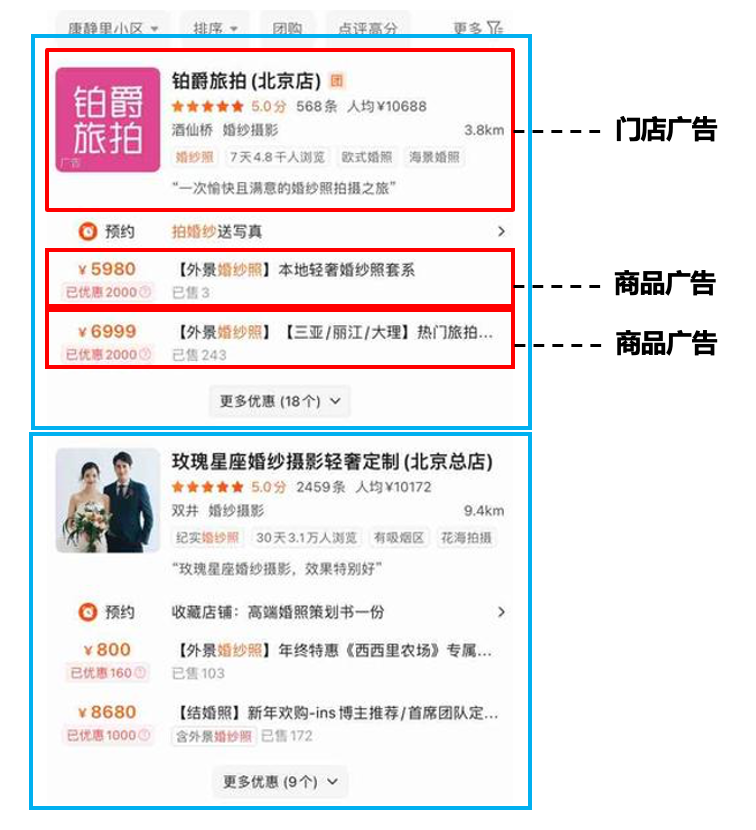
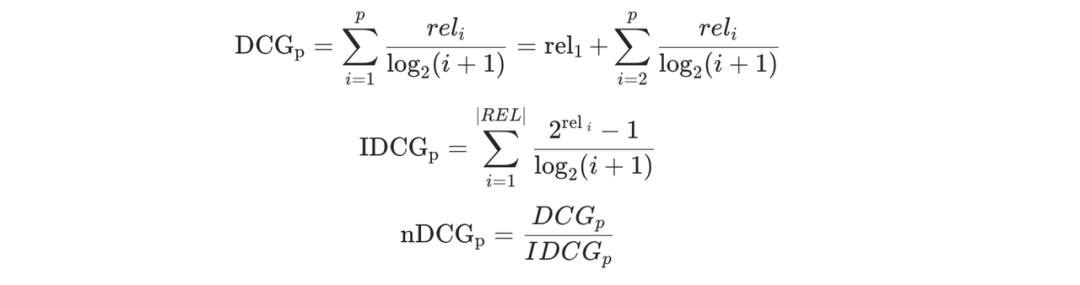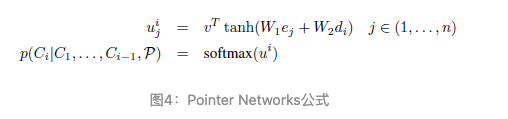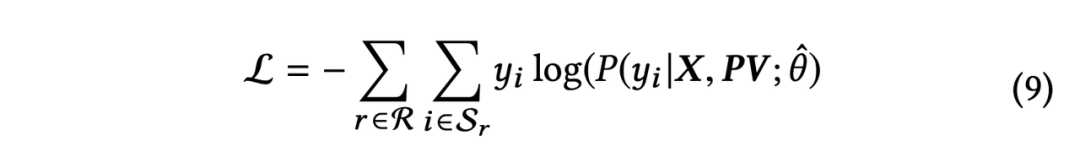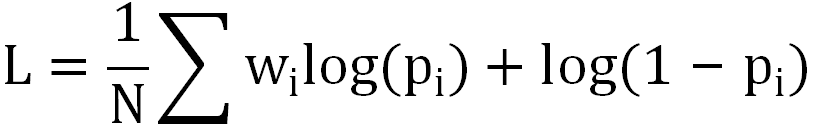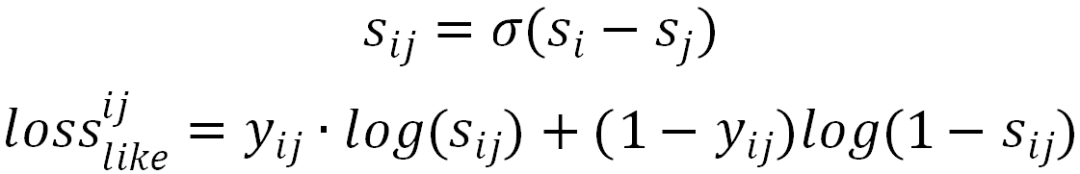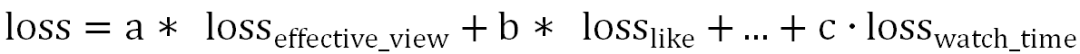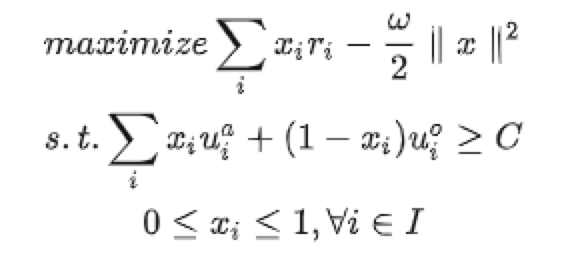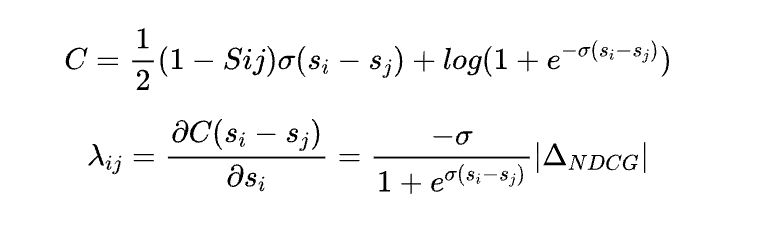Перестановка вообще является ближайшим к пользователю звеном (в некоторых сценах даже есть перестановки), поэтому перестановка/перетасовка часто определяет результат данной рекомендации, поэтому не будет преувеличением назвать ее «судьей жизни и смерти».
Его позиционирование заключается в переупорядочении первых N кандидатов, оцененных с помощью уточненной модели ранжирования, систематическом моделировании оптимальных преимуществ с точки зрения контекстного списка, а затем восстановлении последовательности элементов TOP-K для отображения пользователю.
Зачем нужна перестановка。Тонкая гребляиз Идея состоит в том, чтобы оценивать продукты,По этому баллу от высокого к низкому классифицировать,Чем выше балл, тем выше ценность предмета. -> Положение дисплея выше -> Фактические получаемые выгоды больше. Но у этой логики есть серьезный недостаток: контекстная информация элемента будет сильно влиять на принятие решения пользователем.
Возьмем, к примеру, короткие видеоролики Куайшоу. Например, первое видео представляет собой высказывания генерала о кризисе в Тайваньском проливе, но если в следующем видео рекомендуется видео с молодой девушкой, это будет совершенно неуместно, поскольку эти два видео не связаны друг с другом. и эффект рекомендаций плохой. Если следующим рекомендуемым видео будет относительно популярная музыка, а затем будет рекомендовано видео танцующей девушки, то контент будет более связным и пользователи не будут чувствовать резкости.
В частности, проблемы, которые должен решать модуль реорганизации:
Это уже не просто вопрос размышлений, таких как отзыв, грубое и точное планирование.
user * item
парные отношения, но
user * N\_items
Как максимизировать ценность всей последовательности показов за счет их взаимного влияния;
В различных сценариях: как разумно определить «ценность», что такое хорошая ценность и как отразить волю бизнеса;
Все больше и больше компаний занимаются тем, как правильно распределять трафик. В дополнение к своим основным бизнес-целям (GMV, продолжительность и т. д.) им также необходимо учитывать большее разнообразие, доступность, пользовательский опыт и т. д., а также, возможно, потребуется реализовать некоторые бизнес-стратегии (такие как взвешивание, снижение веса, фильтрация плохих регистров и т. д.)
Как более своевременно определять предпочтения поведения пользователей,Быстрый ответ на корректировку стратегии модели.
Теперь, когда цель ясна, как оценить эффект и насколько он может соответствовать нашей конечной цели?
Точность: НДЦГ. Этот показатель измерения соответствует точному ранжированию. Цель состоит в том, чтобы ранжировать продукты, которые пользователи могут нажать/купить, как можно выше с более высокой эффективностью. Формула выглядит следующим образом.
Разнообразие: α-NDCG. Это взято из статьи «Новизна и разнообразие в оценке информационного поиска», опубликованной в SIGIR в 2008 году. Сутью по-прежнему остается логика DCG, которая оптимизирует определение выгоды.
2. Разработка модели перестановки.
Разработка моделей перестановок в основном включает в себя
точечная Модель. Классическая модель CTR в основном аналогична,Такие как DNN, WDL, DeepFM. По сравнению с моделью точного ранжирования основное преимущество заключается в обновлении из Модели, а также весов функций и элементов управления в реальном времени. С модернизацией инженерных возможностей из,Внедрение функций реального времени ODL принесло значительные улучшения;
попарно Модель. Используйте попарно, чтобы сравнить порядок отношений между парами элементов.,Такие как GBRank, RankSVM, RankNet и т. д.,Но pirwiseиз Модель не учитывает список глобальной информации.,и значительно увеличился Модельное обучение Оценивается по сложности.
по списку Модель. Список элементов ввода модели: общая информация и информация для сравнения, а также передать list-wise Функция потерь для сравнения отношений между элементами последовательности. Лямбда Март, МИДНН 、DLCM、PRM и SetRank проходит соответственно GBT、DNN、RNN、Self-attention и Induced self-attention чтобы извлечь эту информацию. По мере совершенствования инженерных возможностей на этапе сортировки также извлекаются входные данные о последовательности и соотношения сравнения.
генеративная модель. В основном делится на два типа,Метод, учитывающий информацию преамбулы,нравиться MIRNN и Seq2Slate Все прошло RNN чтобы извлечь информацию о предварительном заказе, а затем передать DNN или Pointer-network для создания окончательного списка рекомендаций шаг за шагом из входного списка продуктов.
diversityМодель。В конечном итоге предстоит проделать большую работурекомендоватьв спискеиз Актуальностьи Разнообразиедостичь баланса,Такие как Хулу,youtubeизDPPМодель。
2.1 На основе жадного поиска
Стратегия жадного поиска на каждом этапе выбирает контент с наибольшей целевой функцией полезности в текущем состоянии и добавляет его в список кандидатов до тех пор, пока длина списка кандидатов не будет соответствовать требованиям. На каждом этапе жадной стратегии используется локально оптимальная стратегия, и нет никакой гарантии, что она приведет к глобально оптимальному решению.
2.1.1 MMR
[CMU SIGIR 1998] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
M M R=A r g \max _{D_i \in R \backslash S}\left[\lambda \operatorname{Sim}_1\left(D_i, Q\right)-(1-\lambda) \max _{D_j \in S} \operatorname{Sim}_2\left(D_i, D_j\right)\right]
Среди них Q — поисковый запрос, D — элемент-кандидат (например, результат уточненной оценки ранжирования), а S — элемент, выбранный алгоритмом MMR. Sim1 используется для измерения корреляции между элементом и запросом, а Sim2 используется для измерения максимального сходства между текущим элементом-кандидатом Di и выбранным элементом.
Как видно из формулы, основная идея MMR — жадный поиск, который жадно генерирует топовый набор. Первоначально выбирается элемент с наибольшей корреляцией с запросом, а затем каждый последующий выбор — это элемент с наибольшей корреляцией с запросом и наименьшим сходством с уже выбранным элементом. Первое обеспечивает актуальность, а второе — разнообразие, используя параметры
\lambda
Используется для регулирования весов смещения в сторону релевантности и разнообразия.
MMR успешно реализован в поисковых рекомендательных системах Microsoft, Amazon и JD.
2018 (Amazon) (RecSys) Adaptive, Personalized Diversity for Visual Discovery
2.1.2 DPP
[Google CIKM'18] Practical Diversified Recommendations on YouTube with Determinantal Point Processes
[Hulu NIPS'18] Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity
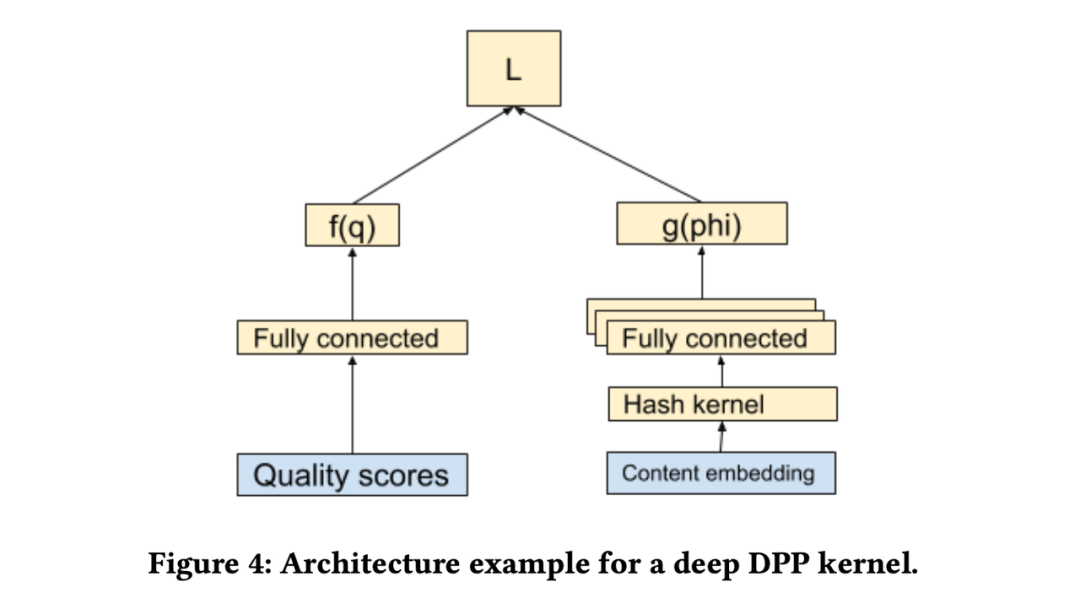
DPP(Determinantal Point Процессы) Входные данные модели – это элемент тонкой оценки ранжирования, а также попарное расстояние между двумя предметами (можно рассчитать с помощью жаккарда, emd и т.п.),Затем сгенерируйте результаты topk,Цель оптимизации –Разнообразиеиэффективность。
Логика математического вывода DPP относительно сложна, включая версии, основанные на параметризации ядра и глубоком обучении. Здесь мы рассмотрим только версию DL.
Среди них входные данные функции f — это скрытый вектор последнего слоя модели точного ранжирования, а входные данные функции g — векторное представление элемента.
2.2 Контекстно-ориентированный список
Context-aware List-wise Модель генерирует результаты Top-K путем моделирования отношений взаимного влияния между элементами Top-N, созданными с помощью уточненной модели ранжирования. Включая ми РНН, DLCM, PRM, EdgeRec, PRS, AirbnbDiversity и т. д. успешно применяются к поиску Taobao, рекомендациям, поиску Airbnbиз Изменить порядоксередина。
2.2.1 miRNN
[Али IJCAI'18] Глобально оптимизированный рейтинг с учетом взаимного влияния в поиске электронной коммерции
https://arxiv.org/abs/1805.08524
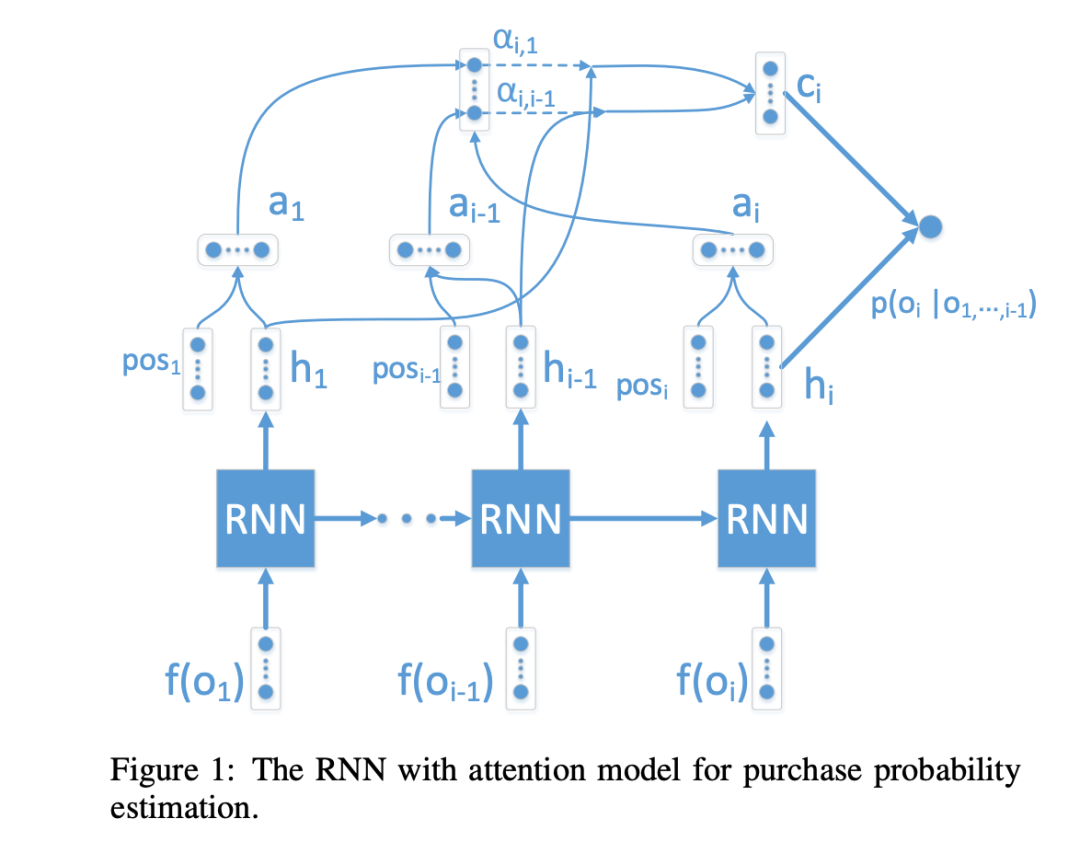
Таобаопоиск Изменить порядоксцена,GMV необходимо максимизировать. Автор использует RNN для моделирования контекстной информации.,На основе цены продукта и вероятности транзакции продукта в списке отображения.,Сгенерируйте результаты списка топ-листов для достижения оптимального GMV.
Эту проблему можно разбить на две небольшие проблемы (
v(i)
цена продукта):
Оцените вероятность продажи каждого товара в топк-листе,
p(i|c(o,i))
Как найти оптимальную последовательность топков
o^*
Для вопроса 1 автор использует RNN для моделирования, то есть учитывает влияние ранее выбранных товаров на последующие покупки продуктов.
Как учитывать контекстную информацию? Вводя глобальные черты, автор называет характеристики самих традиционных предметов локальными чертами. Если взять цену в качестве примера, цена глобальной функции определяется как нормализация цены текущего элемента в наборе кандидатов.
Вопрос 2, основанный на изученной модели RNN, можно решить с помощью Beam Search.
2.2.2 DLCM
[SIGIR'18] Learning a Deep Listwise Context Model for Ranking Refinement
https://arxiv.org/pdf/1804.05936
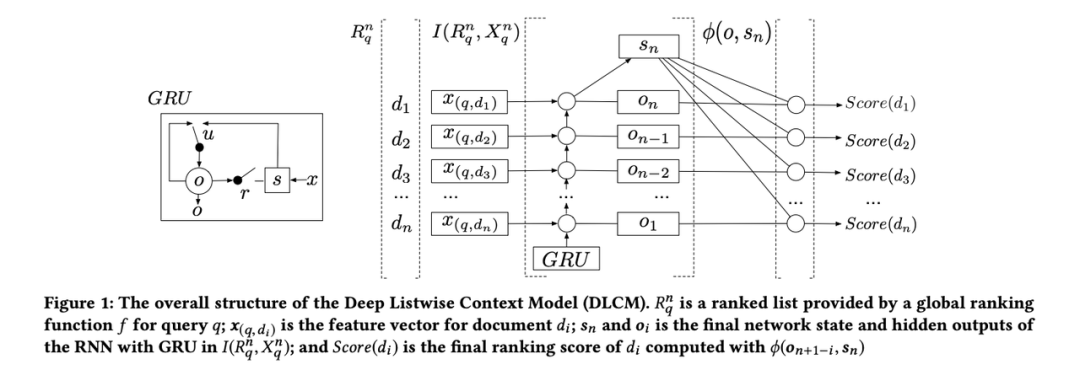
В сценариях поиска традиционная модель LTR не является оптимальной для каждого запроса (даже если общий средний эффект хороший). Причина этого явления в том, что пространства признаков связанных документов, соответствующих разным запросам, могут иметь разные распределения.
Таким образом, основной подход DLCM, предложенный автором, заключается в использовании модели GRU для изучения контекстной информации о лучших продуктах после точного ранжирования для повторного ранжирования. DLCM в основном включает в себя три этапа:
Модель «По традиции» LTR, получи мелкую строку изtopk item;
Используйте GRU для изучения взаимосвязи между элементами топка в порядке от начала до конца (от начала до конца вы можете в наибольшей степени сохранить информацию об элементе с высокими баллами до финального этапа передачи RNN);
Изменить ранжирование обучения на основе результатов модели GRU;
s_n
Это окончательный вектор кодирования сети GRU, который затем использует метод, аналогичный методу внимания, для получения окончательной выходной оценки каждого документа.
[Google ICML'19] Seq2Slate: переранжирование и оптимизация Slate с помощью RNN
https://arxiv.org/abs/1810.02019
В сценарии с рекомендацией видео Google предыдущие модели использовали методы кодирования, а попытки декодирования еще не предпринимались.
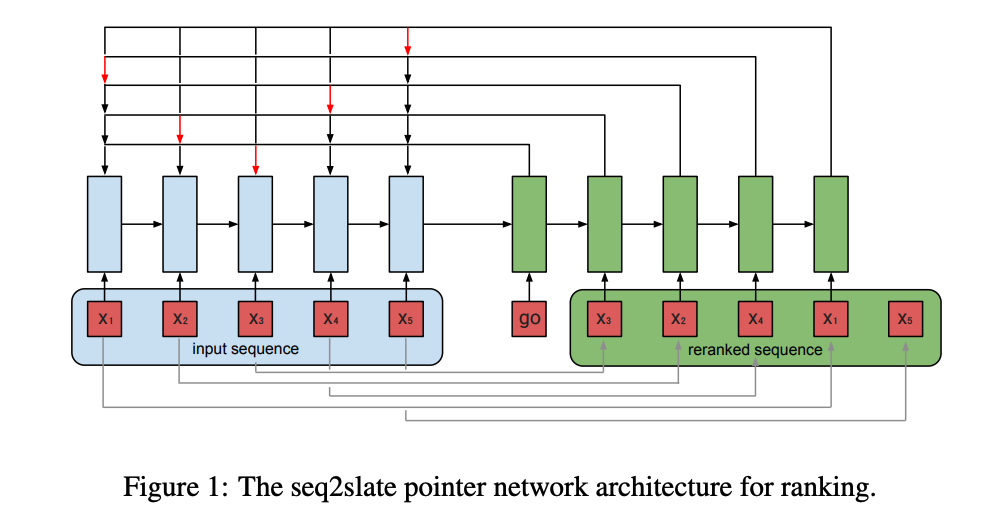
Для решения проблемы рекомендаций по перестановке предлагается архитектура, использующая seq2seq, называемая seq2Slate. Используйте сеть точек, чтобы спрогнозировать следующее видео для просмотра на основе видео, которые пользователь смотрел ранее.
Сеть указателей: это упрощение механизма seq2seq+attention, которое может решить проблему, связанную с тем, что структура seq2seq не может решить проблему, связанную с изменением словарного запаса выходной последовательности при изменении длины входной последовательности. Объяснение в одном предложении: традиционная модель seq2seq с механизмом внимания выводит распределение вероятностей для выходного словаря, а Pointer Networks выводит распределение вероятностей для входной текстовой последовательности.
Входной слой: входные данные представляют собой список наборов кандидатов.
Кодировщик: Модель RNN, от пересылки до посткодирования.
Декодер: go означает начать прогнозирование и каждый раз находить наиболее релевантную из непрогнозированных выборок (стрелка указывает выборку, которую в данный момент необходимо предсказать, а красная стрелка указывает выборку, которая в данный момент прогнозируется как лучшая. Если образец был предсказан, в следующий раз рассматривать его не буду)
Порядок ввода выборок может повлиять на окончательный результат прогнозирования.
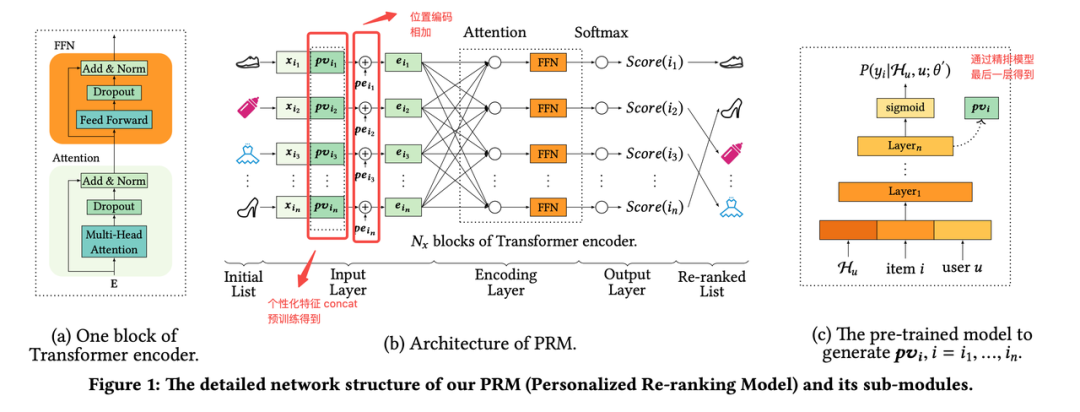
2.2.4 PRM
[Али RecSys'19] Персонализированное изменение рейтинга для рекомендаций
https://arxiv.org/abs/1904.06813
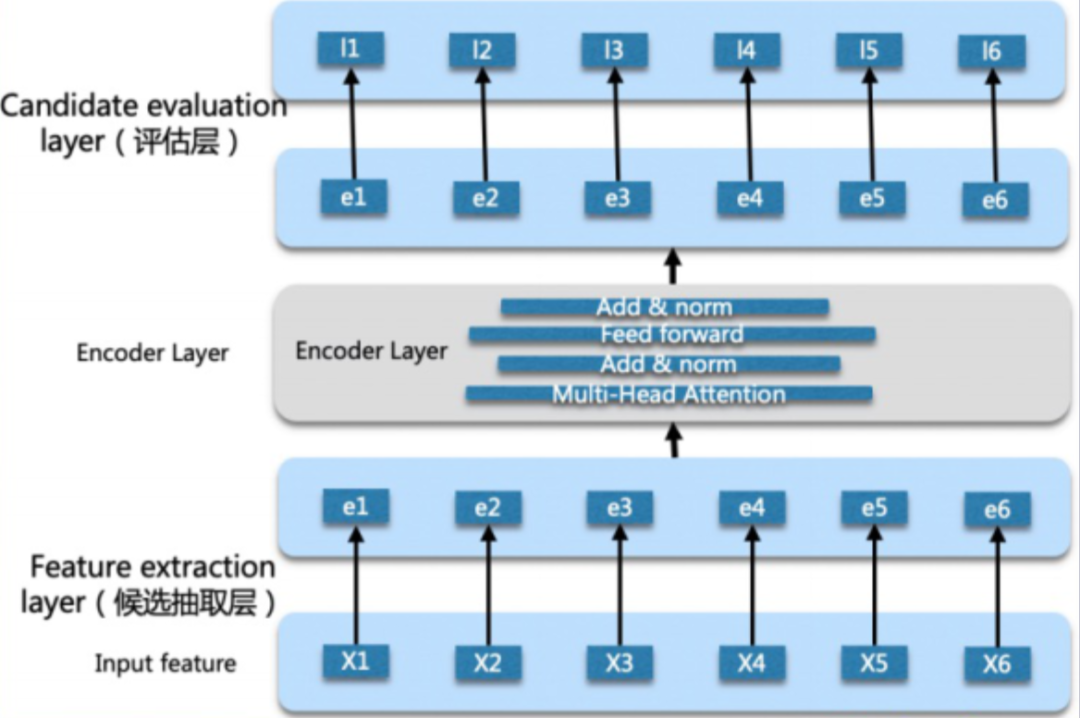
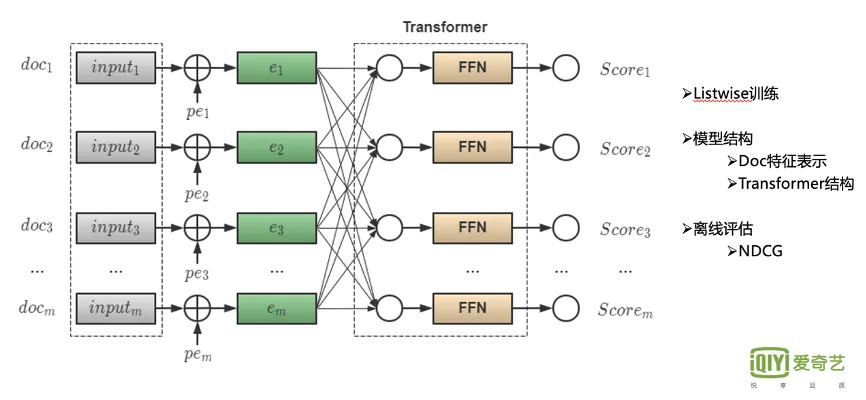
Обычно предметы оцениваются по пунктам.,При этом учитываются только отношения между пользователями и отдельными элементами.,Без учета взаимодействия между элементами списка. Также ведется работа по использованию RNN для моделирования последовательностей.,Но недостатком является то, что если два предмета находятся далеко друг от друга,Тогда ты не сможешь хорошо учиться. Используйте Transformer для персонализации результатов после тонкой настройки.
Разделите уточненный вывод строки из вектора на,Объединение кода позиции для получения каждого элемента ввода,Затем используйте Transformer для кодирования,Наконец, оценка каждого элемента получается через слой полносвязного слоя и softmax.
Входной слой: входные данные представляют собой список оценок, полученных по тонкой строке.
S=[i_1,i_2,...,i_n]
,Особенности включают в себя
Матрица характеристик элемента
X
Матрица персонализации: пользователь x размерность элемента из функций, полученных в результате предварительного обучения модели (может создавать векторы посредством точной модели рядов)
Особенности локации: обучаемая матрица
Уровень кодирования: Трансформатор
Выходной слой:
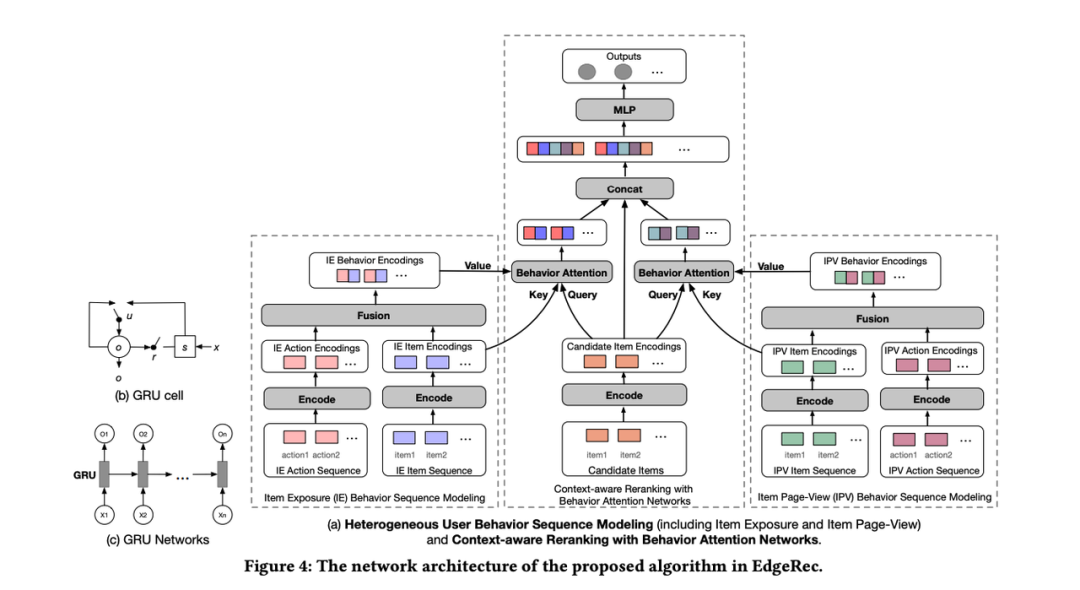
2.2.5 EdgeRec
[Alibaba CIKM'20] EdgeRec — рекомендательная система на Edge в мобильном Taobao
https://arxiv.org/abs/2005.08416
Первый сценарий рекомендации Alibaba Taobao. Это несколько отличается от предыдущей модели. EdgeRec — это модель, развернутая на стороне клиента. Для расчетов предыдущей модели мы обычно развертываем ее на стороне сервера (в этом режиме клиентская сторона собирает пользовательские данные). на стороне клиента) Поведенческие характеристики, сгенерированные на модели, затем передаются модели на сервере для расчета, и, наконец, сервер возвращает рассчитанные и отсортированные результаты клиенту).
Как упоминалось выше, ресурсы вычислительной памяти и своевременность в рамках традиционной модели представляют собой очень серьезные проблемы, особенно во время крупных фестивалей продаж.
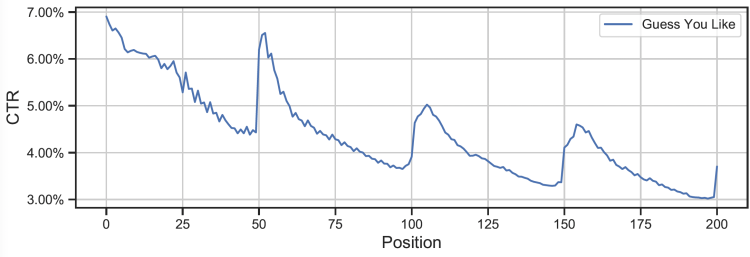
Кроме того, текущие поисковые рекомендации, как правило, имеют форму пейджинговых запросов, то есть возможность корректировки списка товаров имеется только после перелистывания страницы, и не могут своевременно реагировать на изменение интересов пользователя (см. на рисунке ниже, после перелистывания страницы ctr внезапно увеличится). Например, взаимодействие пользователя с четвертым товаром указывает на то, что ему не нравятся «мотоциклы», но поскольку пейджинговый запрос может быть только после 50 товаров, другие «мотоциклические» товары позже на странице не могут быть скорректированы вовремя.
Проектирование архитектуры и системы выходит за рамки этой статьи. Подробности см. в исходной статье. Здесь мы сосредоточимся на модели реорганизации, чтобы увидеть, как изменить порядок отображения продуктов в реальном времени.
Прежде всего, первый модуль — это моделирование последовательности гетерогенного поведения пользователей, который в конечном итоге используется для моделирования поведения пользователя в реальном времени. Он включает в себя две части: моделирование последовательности поведения воздействия продукта и моделирование последовательности поведения страницы с подробными сведениями о продукте.
Следующим шагом является использование этих функций реального времени для моделирования конечной перестановки. В середине — набор потенциальных продуктов, подлежащих сортировке, а встраивание получается с помощью GRU. Левая часть — моделирование воздействия в реальном времени. последовательность справа — построение страницы сведений о продукте при нажатии пользователем формы;
Затем используйте целевое внимание для интеграции, то есть позвольте сортируемым продуктам увидеть, какие продукты нравятся/не нравятся предыдущим пользователям, и скорректируйте порядок последующих.
2.2.6 PRS
[Али 2021] Пересмотрите рекомендательную систему в перспективе перестановок
https://arxiv.org/abs/2102.12057
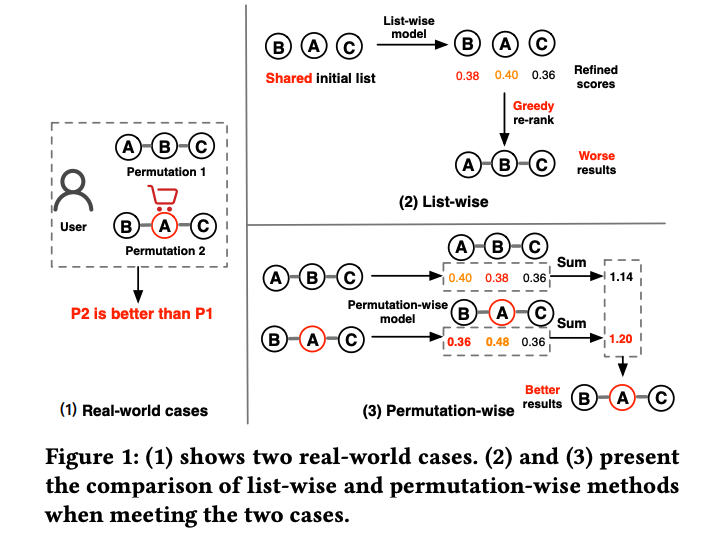
Али рекомендует эту сцену. Это основано на реальном наблюдении: при отображении списка рекомендаций одному и тому же пользователю разный порядок отображения продуктов серьезно повлияет на обратную связь с пользователем.
Как показано на рисунке ниже, два списка A-B-C и B-A-C содержат одни и те же три элемента, но их расположение различно. Пользователь взаимодействует с расположением B-A-C, но не взаимодействует с расположением A-B-C. Одна из возможных причин заключается в том, что дороже. Размещение товара Б перед более дешевым товаром А может увеличить желание пользователя купить товар А. Тогда такое различное расположение приведет к разным факторам влияния на отзывы пользователей.
Таким образом, лучший способ перестановки — рассмотреть все возможные перестановки, оценить результаты каждой перестановки и выбрать результат отсортированного списка с наивысшей оценкой для отображения пользователю. Но здесь явно есть две проблемы
Рассчитать задачу взрыва: от длины до n Выбрать из коллекции m Рекомендуемые продукты, в виде списка Переставить Модельизпоиск в пространстве
O(n^m)
, а пространство перестановок, предложенное в этой статье, равно
O(A_{n}^{m})
Проблема оценки списка: как точно оценить результаты, полученные с помощью Permutation-Wise?
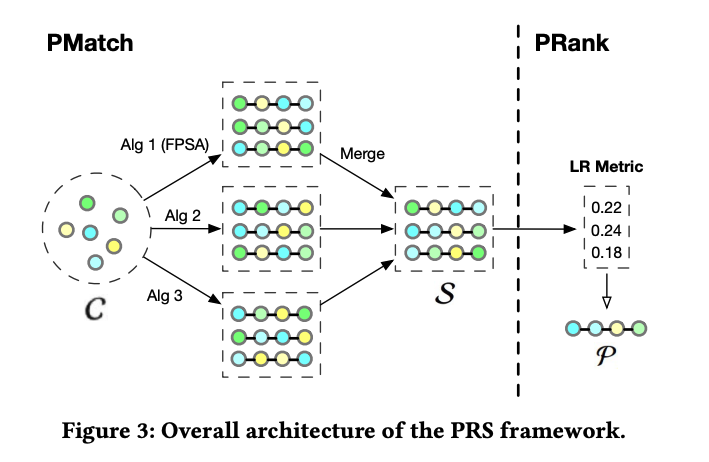
Автор статьи предлагает двухэтапную структуру реорганизации PRS, которая разделена на два этапа: PMatch и PRank.
Тренируйте модель в автономном режиме,Прогноз вероятности клика по элементу pctr и Продолжить просмотр
p^{next}
онлайн-обслуживание когда, использовать beam-search генерация метода k длина n очередь кандидатов, подсчитать
r_{pv}
Совокупное воздействие в надежде увеличить глубину просмотра,
r_{ipv}
Суммируйте частоту показов * частоту кликов по каждому элементу. На частоту показов будет влиять предыдущая последовательность. Чем больше, тем лучше для обоих.
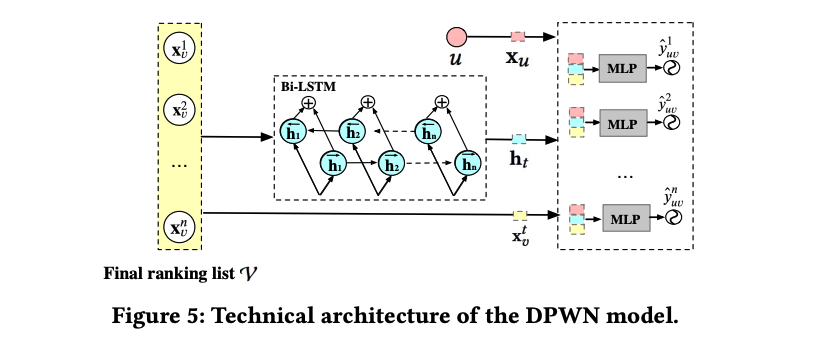
PRank: сортировать группы сценического использования. bi-lstm Структура из DPWN Модель, рассчитывающая рейтинг кликов каждого элемента в очереди. pCTR, а затем выровнять все из pCTR добавляется в качестве показателя для этой очереди, выберите pctr Самый высокий результат как у победителя.
2.3 На основе обучения с подкреплением
Оставить дыру
3. Реализация реорганизации на практике в отрасли
Несмотря на то, что вышеизложенное представляет собой, по сути, первоклассную встречу после практики в бизнес-направлении, в конце концов, этот документ все еще остается документом, и в нем относительно мало содержания, включающего практический опыт и описание ошибок. С помощью нескольких пабликов разберемся в практике перестановки модулей у крупных производителей.
несколько целейсортировать В Куайшоу короткометражкавидеорекомендоватьсерединаизупражняться[1]
Сцена представляет собой короткую видеорекомендацию Куайшоу, включая страницу открытия, страницу отслеживания и страницу местного города.
Основная цель оптимизации рекомендаций по коротким видео — увеличить общий DAU пользователей и улучшить удержание пользователей. Конкретный метод заключается в увеличении времени использования/положительных отзывов (например, коллекций, лайков, комментариев, степени завершения и т. д.) и уменьшении отрицательных отзывов (таких как неприязнь, пропуск и т. д.).
Усовершенствованная многоцелевая сортировка
Опытная ручная настройка параметров и слияние -> Простая модель машинного обучения -> Модель LTR ->
Формула ручного слияния: оценка = a*pEvtr + b*\pLtr + ... + g*f(pWatchTime),Недостаток заключается в том, что он слишком сильно полагается на разработку правил вручную и настройку параметров.,отсутствие персонализации;
Древовидная модельEnsemble Fusion: Введение pXtr, портретные и статистические функции, используйте GBDTModel, чтобы соответствовать метке. Недостаток заключается в том, что Модель дерева имеет ограниченные выразительные возможности и не может online learning。
Сквозной LTR: замените вышеупомянутую модель башен-близнецов моделью перекрестно уточненной строки и попробуйте точечное, попарное и обучение с потерями.
Изменить порядок
При перестановке необходимо учитывать взаимное влияние видео.
listwise переоценка: используйте преобразователь для моделирования кандидатов из топ-6, взвешенных. обучение с логлоссом
Обучение с подкреплением:
Обслужить изменение рейтинга:
3.2 【2021】Изменение порядка коротких видео Kuaishou
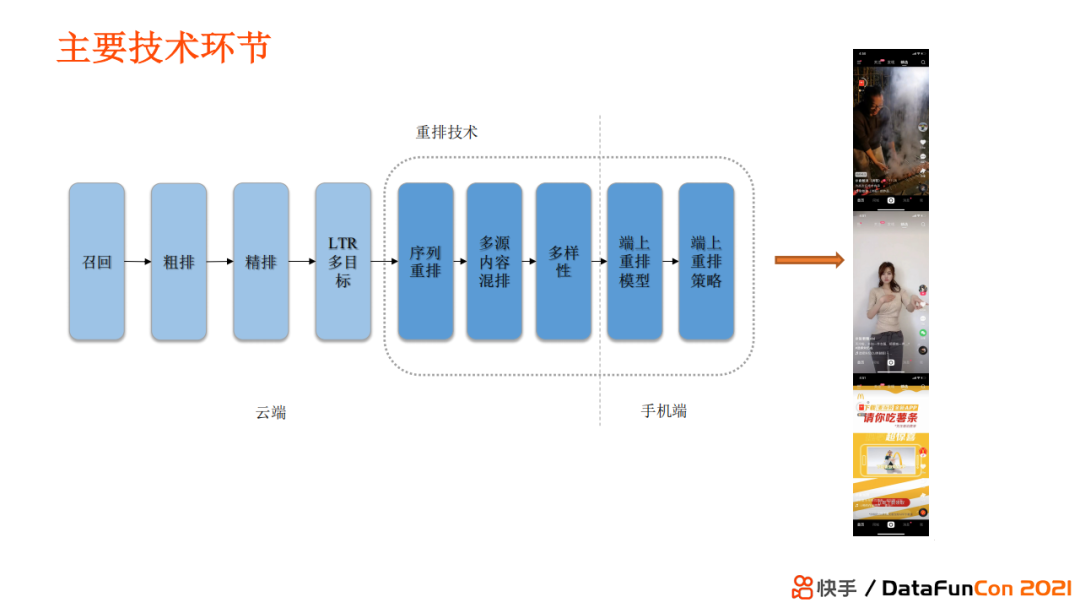
Перестановка и обмен короткими видеорекомендациями Kuaishou, общая структура выглядит следующим образом.
Как видите, общая перестановка включает и серверную часть (Перестановка последовательности、Контент из нескольких источниковперетасовать、Разнообразие)и Мобильная версия(переставить на сторону Модель&Стратегия)две части。
3.2.1 Перестановка последовательности
Прежде всего, как упоминалось вначале, то, как определить хорошую последовательность, чрезвычайно важно и определяет направление оптимизации. Критериями для коротких видеороликов Kuaishou являются: считается, что хорошая последовательность имеет высокую степень завершенности, вся последовательность имеет высокую степень позитивного взаимодействия, пользователь имеет высокую прилипчивость, готов просматривать видео после просмотра, а последовательность имеет последовательные атрибуты в содержании.
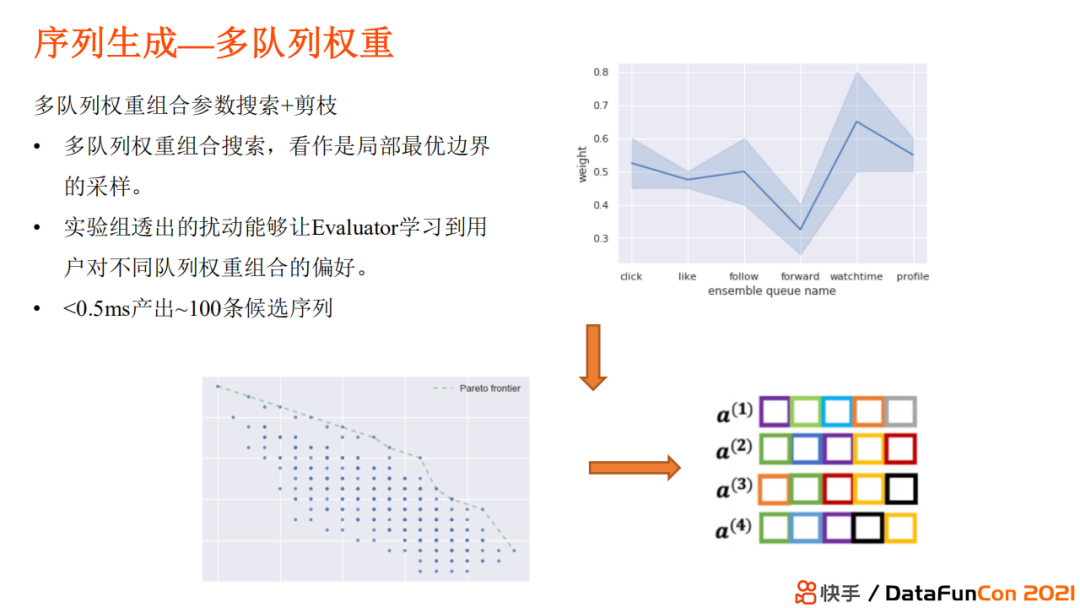
Общая перестановка последовательностей использует парадигму GE (генератор-оценщик). Генератор генерирует множество последовательностей-кандидатов из топ50, а затем использует оценщик для оценки последовательностей-кандидатов на основе их общего значения.
3.2.1.1 Generaotr
Обычно используемый метод генерации — это лучевой поиск, который последовательно генерирует видео для каждой позиции. Конкретная стратегия состоит в том, чтобы выбрать оптимальные топ-видео, оцененные моделью, из видео, которые были сгенерированы в предыдущей последовательности. Некоторые другие методы генерации включают вызов разнообразия MRR, вызов Seq2slate и т. д., представленные ранее.
Kuaishou здесь использует веса нескольких очередей. До онлайна базовым вариантом была ручная настройка параметров веса каждой очереди (в настоящее время параметры фиксированы), но лучше то, что параметры настраиваются адаптивно (например, в течение определенного периода времени, я должен рекомендовать видео с более длительным временем погружения, а другой период времени требует недорогого и высокодоходного видеоконтента, поэтому первый должен уделять больше внимания цели времени просмотра, и взаимодействие может быть преобразовано, тогда как второй требует взаимодействия и более высокая ставка). Таким образом, параметры можно отбирать совместно для получения различных последовательностей.
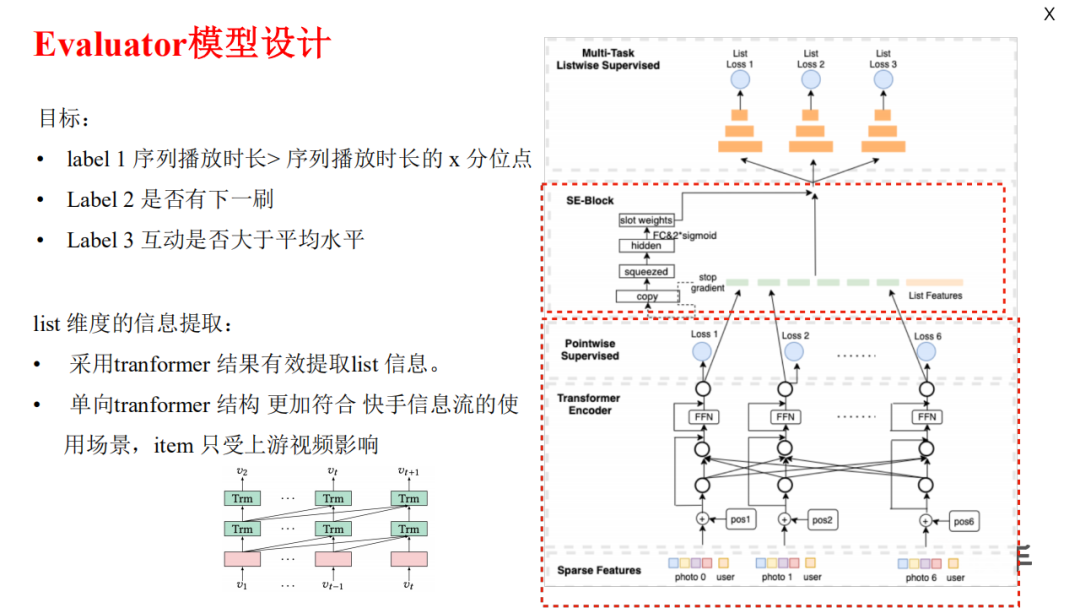
3.2.1.2 Evaluator
Evaluator использует односторонний преобразователь, поскольку действие пользователя по перелистыванию видео является односторонним, а информация нисходящего видео не имеет преимущества перед восходящим видео.
Общая модель разделена на два слоя:
Первый уровень использует односторонний transformer Смоделируйте предмет, и для каждого item сделай один потеря (аналогично Цзинпаю поточечноиз ctr Оценивать? В статье не указано);
Второй уровень предназначен для того, чтобы получить встраивание элемента из предыдущего уровня, добавить функцию списка для моделирования общей последовательности и выполнить многоцелевую и многозадачную работу в форме общего нижнего уровня.
3.2.2 Многомерное смешивание
Проблема, которую необходимо решить при перетасовке, заключается в том, как правильно объединить результаты доходности каждого бизнеса, чтобы получить последовательность результатов с наибольшей комплексной ценностью.
В самом простом решении каждый бизнес получает трафик через фиксированные места. Но отсутствие персонализации снижает эффективность как пользователей, так и платформы. Кроме того, в документе LinkedIn (KDD 2020 | Распределение рекламы в ленте посредством ограниченной оптимизации) это преобразуется в оптимизацию величины дохода при предположении, что ценность пользовательского опыта превышает C. Подробности см. в исходном документе.
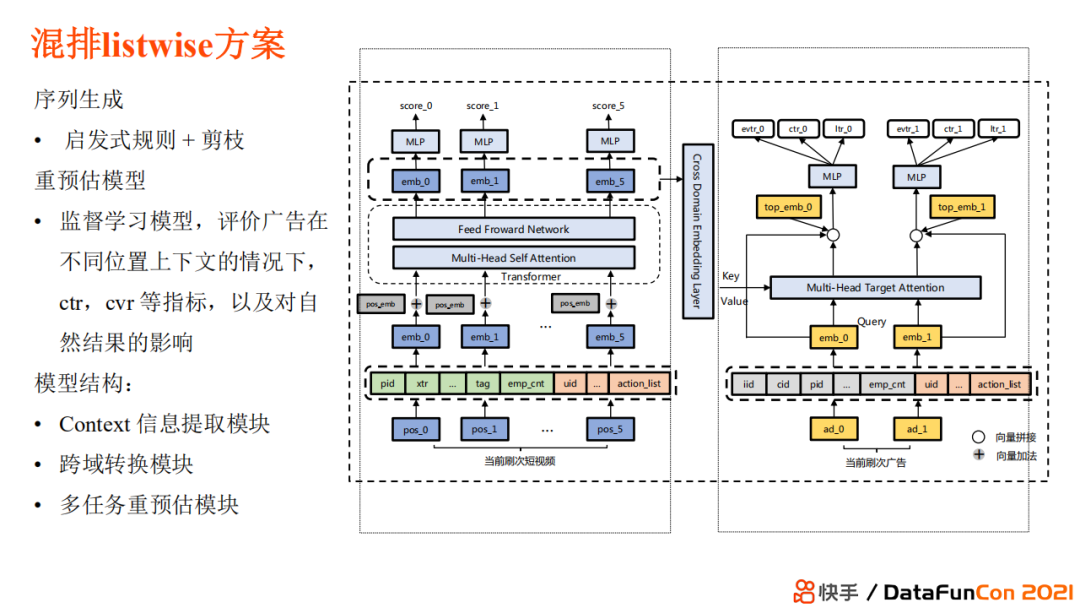
Смешанная списочная схема использует парадигму генератора-вычислителя, и модель включает три части:
Модуль извлечения информации contetx: перепрогнозирование естественного видеоконтента (Тонкая гребля Модель Уже есть точная оценка товара,Почему нам нужна переоценка? На рейтинг продукта будет влиять контекст, в котором он находится.,Интеграция контекстной информации может сделать прогнозы более точными.)
Модуль междоменной конвертации: учитывая, что натуральный и рекламный контент принадлежат двум несовместимым доменам.
Многозадачный модуль повторного прогнозирования: включение естественного контента,Перепрогнозируйте свою рекламу,измерить этоиз Контакт、ctr、cvr и другие индикаторы для получения оптимальной последовательности значений.
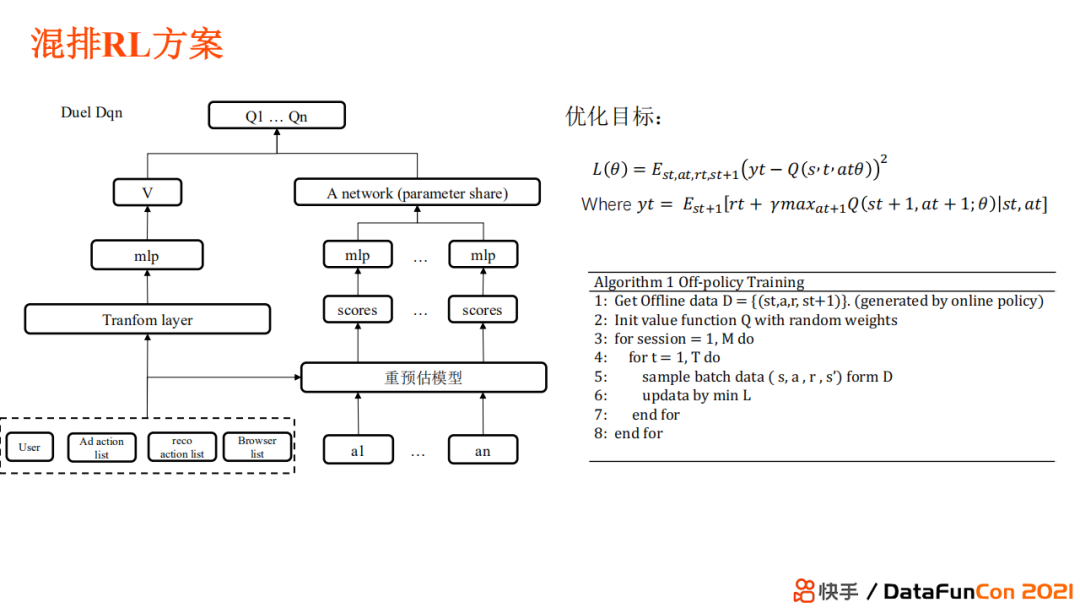
Сначала определяется схема RL смешанного ранга.
Статус: Пользователь находится в session Внутренняя глубина кисти, содержание экспозиции, история взаимодействия с рекламой, история взаимодействия с контентом, контекстная информация Также Содержимое этой кисти
Пространство действия: например, где разместить первую и вторую рекламу и т. д. (необходимо соблюдать бизнес-ограничения) использовать Duel DQN Целью оптимизации плана является выбор на каждом этапе достижения конечного максимального общего значения, вознаграждения. Это сочетание долгосрочной и краткосрочной стоимости.
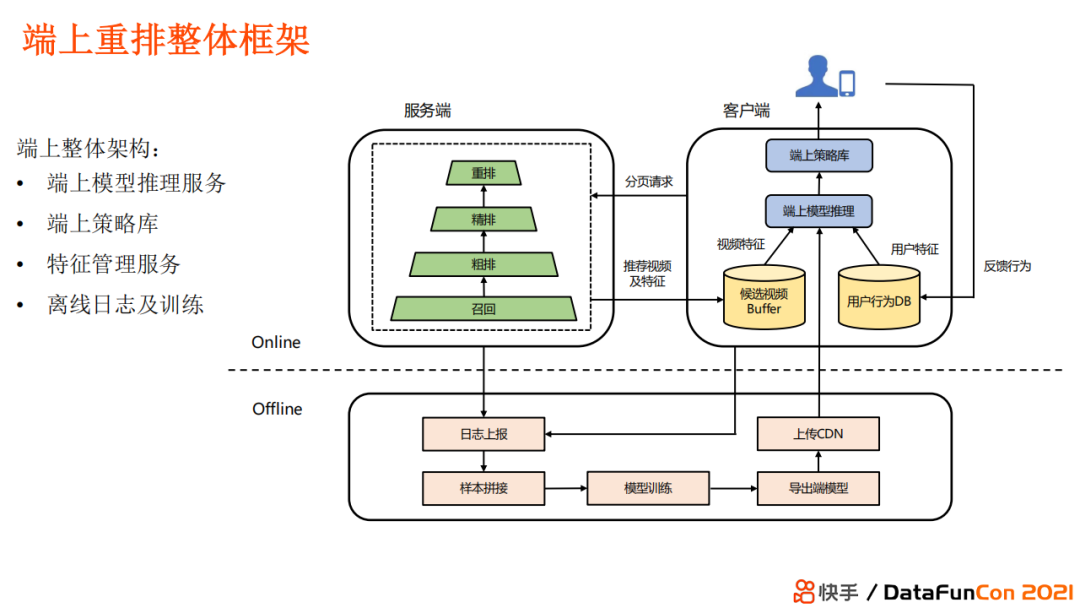
3.2.3 Сквозная перестановка
Общая архитектура сквозной перестановки аналогична приведенной выше:
Сервер производит отзыв после получения пейджингового запроса от мобильного телефона.、Грубый скандал. Тонкая гребля、переставить,возвращатьсярекомендоватьизвидеои особенности;
Конец вывода Модель с использованием видео-кандидата также характеристики, а также характеристики пользователя и отзывы для прогнозирования и, наконец, в сочетании с конечной стратегией для получения окончательного перетасовать результат. На терминале Модель может использовать более полные функции обратной связи в режиме реального времени для составления прогнозов.
3.3. Обратите внимание на WeChat, чтобы порекомендовать смешанную схему.
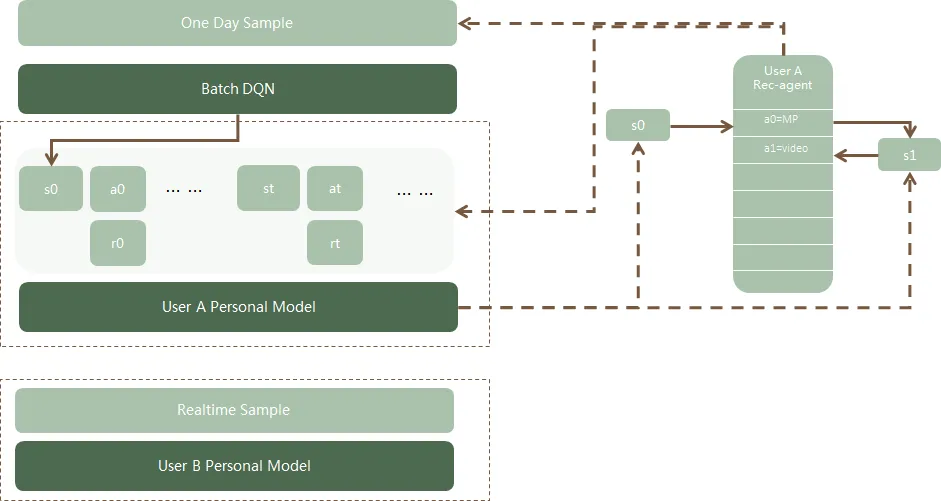
Использование обучения с подкреплением для моделирования смешанного порядка
Когда поступает запрос пользователя, скрытое состояние будет рассчитываться на основе его предыдущего поведения как часть входного состояния. Каждый раз в качестве действия выбирается определенное дело, а в качестве вознаграждения используется щелчок обратной связи.
Этот обмен знакомит с общим бизнесом поиска iQiyi, включая обработку запросов, отзыв, грубое ранжирование, точное ранжирование, переупорядочение и т. д. Здесь зафиксирована только часть перестановки.
Причина перестановки заключается в том, что часть точной сортировки фрагментирована и не может быть контекстно-зависимой. Конкретная модель аналогична PRM, а индикатор автономной оценки — NDCG.
3.5 Перестановка поиска Meituan
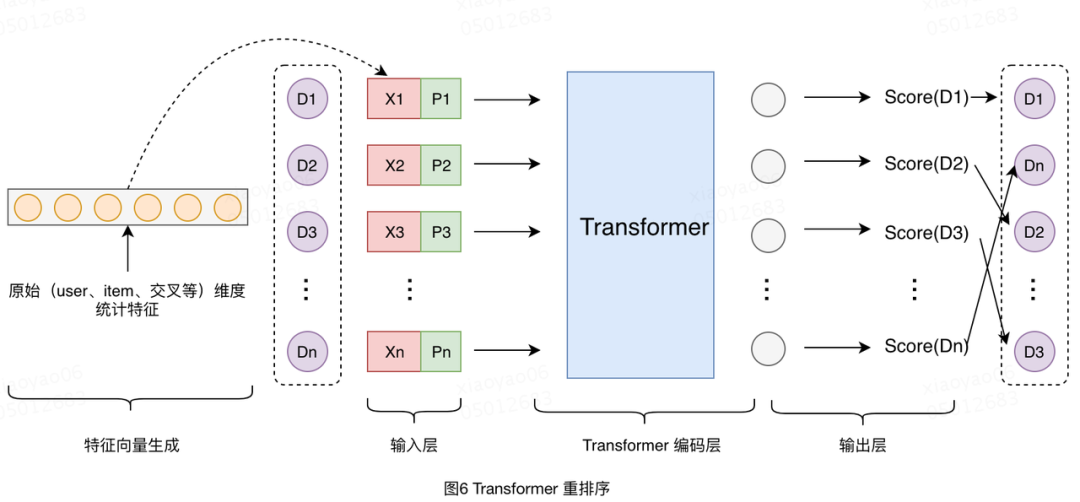
Transformer В Мэйтуанепоисксортироватьсерединаизупражняться[2]
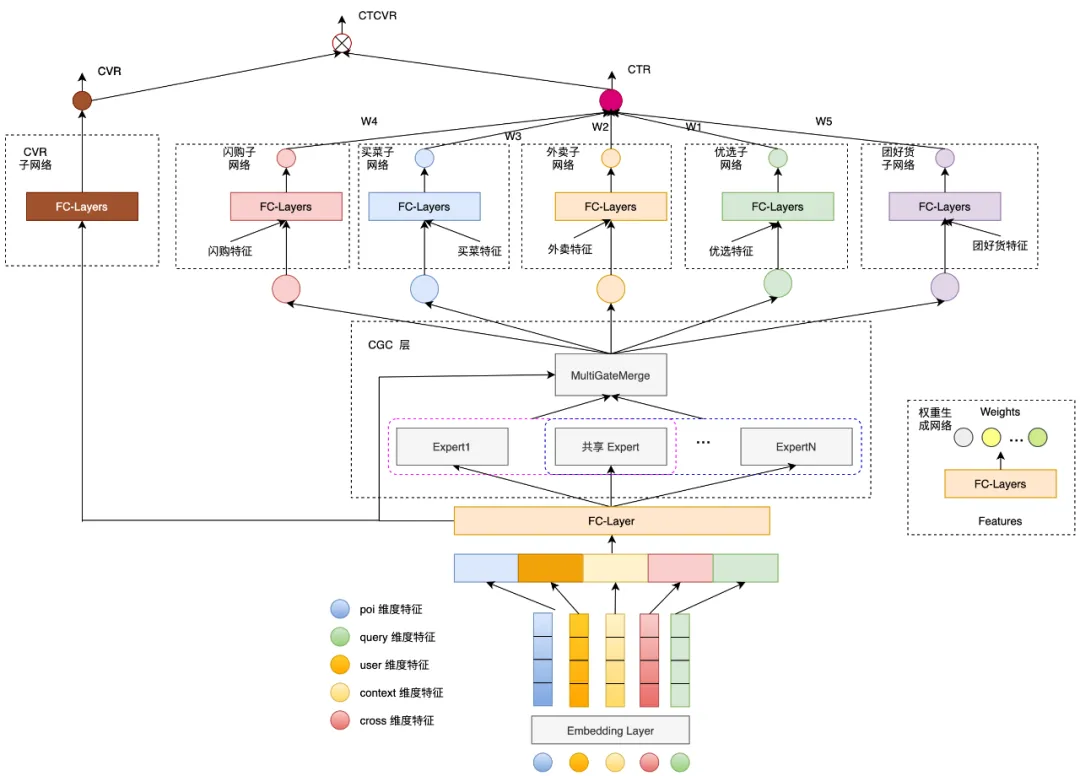
Сценарий — поиск на домашней странице Meituan. Когда пользователь выполняет поиск по запросу, различные бизнес-продукты должны быть равномерно смешаны и отсортированы, включая флэш-продажи, покупки продуктов, выбор, группировку хороших продуктов и т. д.
Поскольку цели мультибизнеса на самом деле одни и те же (для gmv), здесь подробнее о многокритериальном моделировании и моделировании нескольких бизнесов, а также о том, как использовать общие черты и характеристики между различными бизнесами в модели.
Общая модель представляет собой структуру ESMM+многобашенная.
3.7 Перестановка конца поиска Meituan
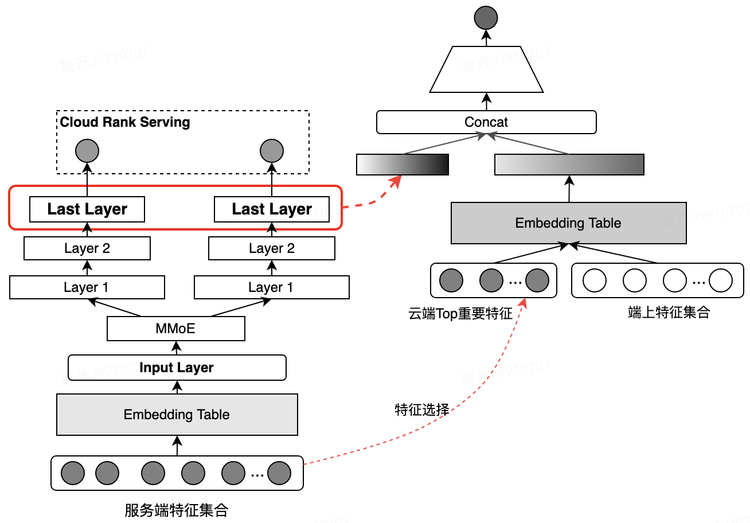
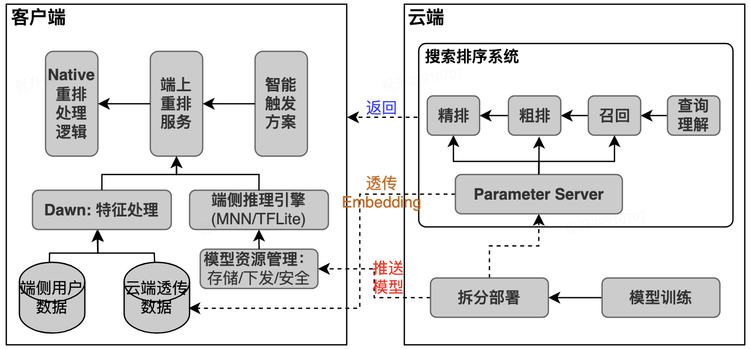
Конец интеллекта в Дяньпине поиск Изменить порядокиз приложения упражняться[3]
Бизнес-сценарий — поиск в Дяньпине. По сравнению с моделью обработки облачного сервера архитектура модели на устройстве имеет следующие преимущества:
Поддерживайте перекомпоновку страницы и принимайте решения в режиме реального времени на основе отзывов пользователей.
Без задержек в определении пользовательских предпочтений в режиме реального времени.
Лучшая защита конфиденциальности пользователей Специально дляпереставить на сторонуиз Задача,На основе отзывов пользователей о предыдущих результатах сортировкииз,Динамически настройте последовательность кандидатов ниже,Оптимизируйте общий рейтинг кликов на странице списка.
3.7.1 Алгоритм модели
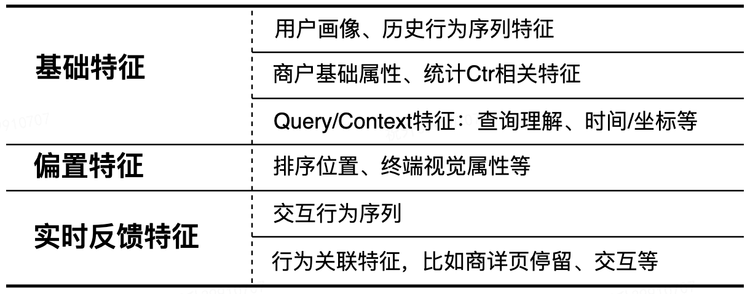
Разработка функций и облачные модели мало чем отличаются
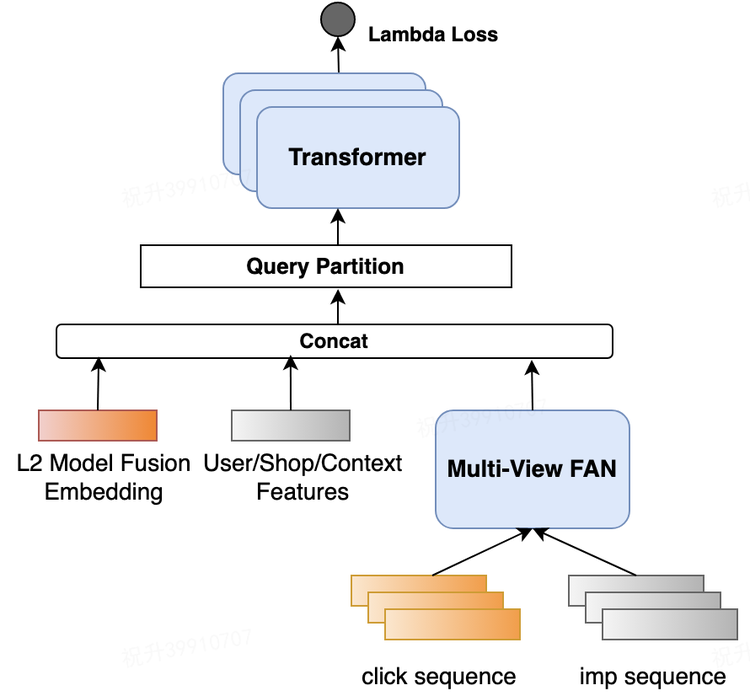
Общее моделирование основано на контекстно-зависимых списках, а результаты Top-K генерируются путем моделирования отношений взаимного влияния между контекстами элементов Top-N, созданных с помощью уточненной модели ранжирования.
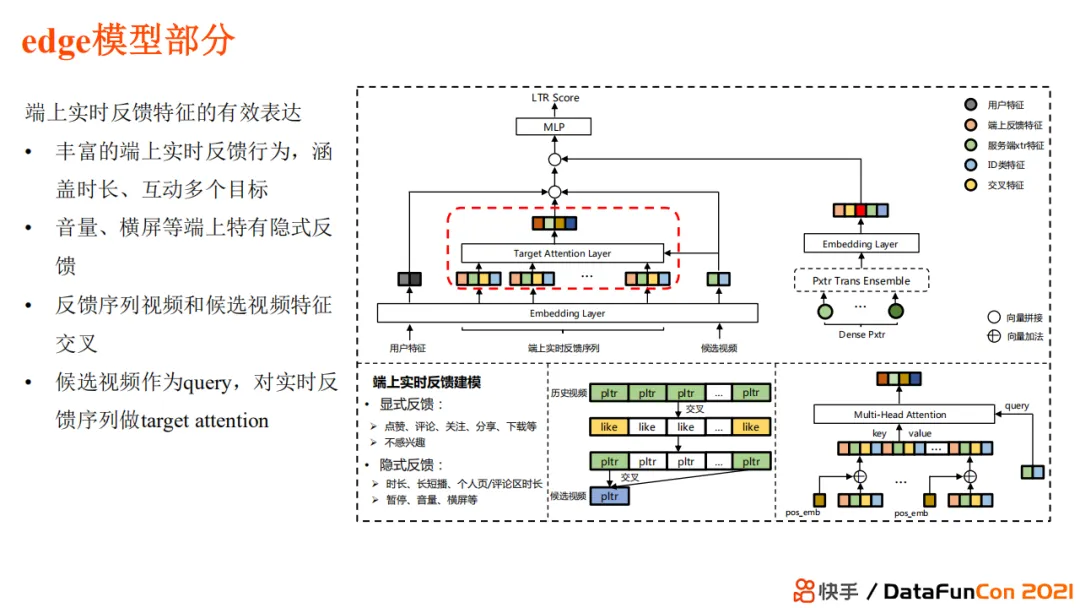
Здесь Multi-View FAN — это сеть, которая моделирует поведение обратной связи с пользователем.
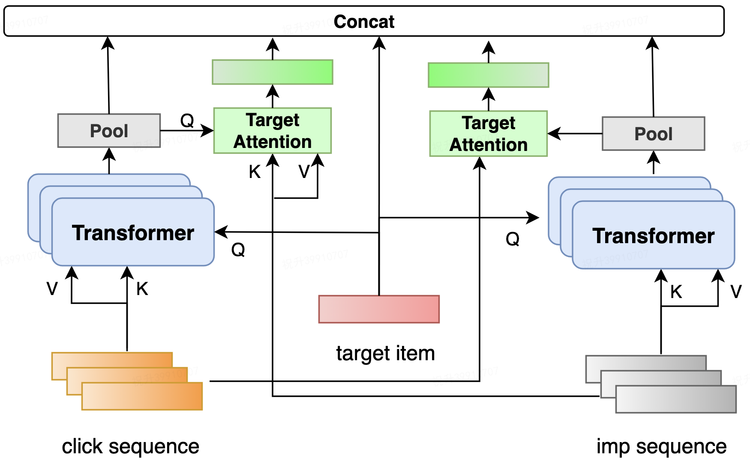
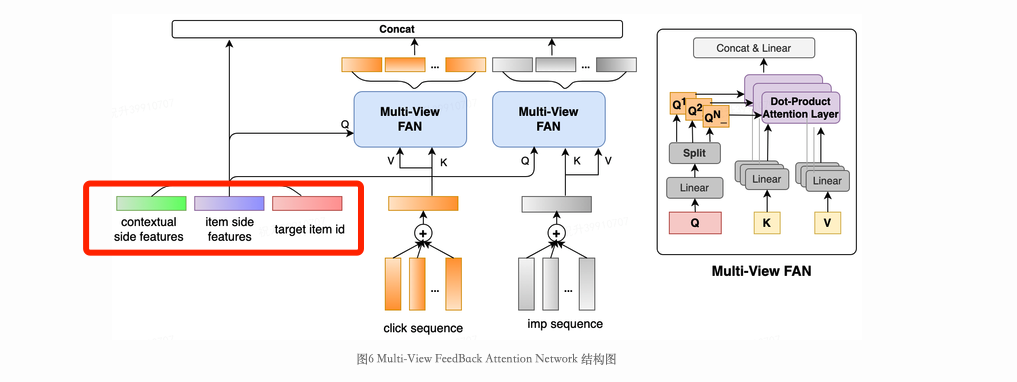
Представляем сеть глубокой обратной связи. Разделите последовательность положительной и отрицательной обратной связи, сначала выполните цель. внимание, после создания векторного представления как Query и еще одна последовательность действий внимание. При этом, учитывая разреженность сигнала обратной связи, введем ноль внимания, избегайте шума.
Многоперспективное перекрестное моделирование последовательностей положительной и отрицательной обратной связи. Многоперспективный индекс на самом деле является кандидатом item изцена、расстояние、среда、Тонкая характеристика вкуса,Лучше учитывайте интересы пользователей, моделируя несколько измерений.
Match&Aggregate характеристики последовательности. Можно понимать как своего рода «Жесткий» из Attention Способ,Формы извлечения включают в себя: Hit (даже если это попадание), Частота (сколько попаданий), Шаг (длина интервала) и т. д.,В дополнение к одномерной последовательности из кроссовера,Вы также можете объединить несколько переменных для пересечения.,Улучшить описание поведения, детализацию и дифференциацию.
Совместное обучение устройству и облаку. Совместное обучение по тонкой настройке на стороне сервера и переорганизации на стороне облака,Может полностью повторно использовать большой объем сложной и эффективной информации.,В то же время избегаются накладные расходы вычислительных ресурсов.
Цель оптимизации: CTR. Обзор поисксосредоточиться наиз — это результат, который занимает верхнюю часть страницы: «хороший» или «плохой», поэтому используйте listwise из lambda утрата, знакомство значение deltaNDCG для усиления влияния положения головы.
3.7.2 Развертывание архитектуры
Общий размер приложения не превышает нескольких сотен МБ, поэтому модель, развернутая на терминале, должна учитывать ограничения вычислительных ресурсов и хранилища.
Поисковая реклама Meituan ограничена LBS (службами определения местоположения), поэтому в определенных категориях становится меньше кандидатов в магазины, а меньшее количество кандидатов серьезно ограничивает потенциал всей системы ранжирования. Вы можете рассмотреть возможность использования рекламы продукта в качестве дополнительного варианта рекламы в магазине и показывать их в смешанном виде. Формы и методы смешивания рекламы товаров и рекламы магазинов следующие:
После внедрения рекламы продукта количество кандидатов увеличилось со 150+ до 1500+. Есть несколько проблем
Давление на производительность оценки детализации продукта: увеличьте количество кандидатов как минимум в 10 раз после перехода к детализации продукта.,В результате служба онлайн-оценки не может выдержать увеличения затрат времени.
Сложность моделирования отношений между комбинациями. Трудно описать контекстуальные отношения между магазинами и комбинациями продуктов с помощью моделирования точечных потерь.
Проблема холодного старта рекламы продукта: используйте показ только кандидатов после выбора модели,Сформировать эффект Мэтью легко.
3.9 [Агрегация] Alibaba рекомендует реорганизацию
Taobao публично публикует множество технических статей по реорганизации.
【2021.09-Таобаопрямая трансляциярекомендовать】Практика алгоритма перестановки полноэкранных страниц Taobao Live(прямая трансляциярекомендовать Для каждого запроса отображается только один результат,Каждое пролистывание будет повторно инициировать запрос.,Поэтому перестановка происходит с использованием поточечной Модель)
Архитектура генератора-оценщика на самом деле больше похожа на архитектуру обучения с подкреплением. Модель генератора генерирует некоторые (не обязательно хорошие) последовательности посредством исследования/выборки, а затем оценщик оценивает их, а результат оценки используется в качестве вознаграждения генератора. Если вознаграждение положительное, генератор увеличивает совместную вероятность генерации этой последовательности. И наоборот, если полученное вознаграждение отрицательное, генератор уменьшает совместную вероятность генерации этой последовательности.
3.9.1 Generator
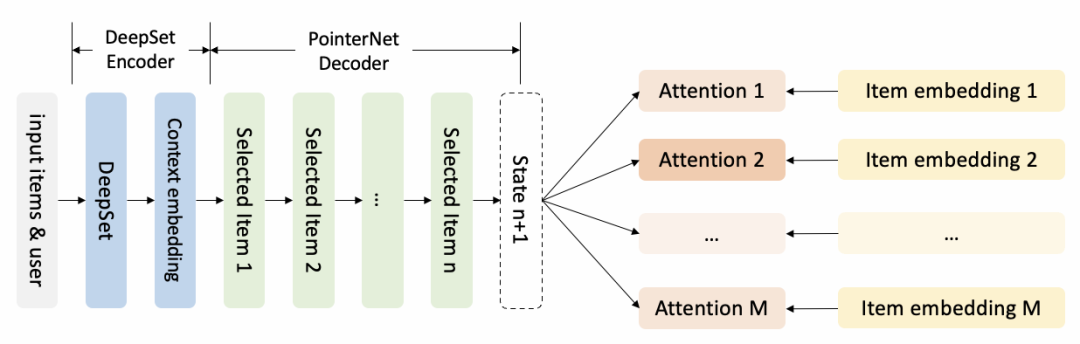
В частности, генератор представляет собой модель структуры кодер-декодер.
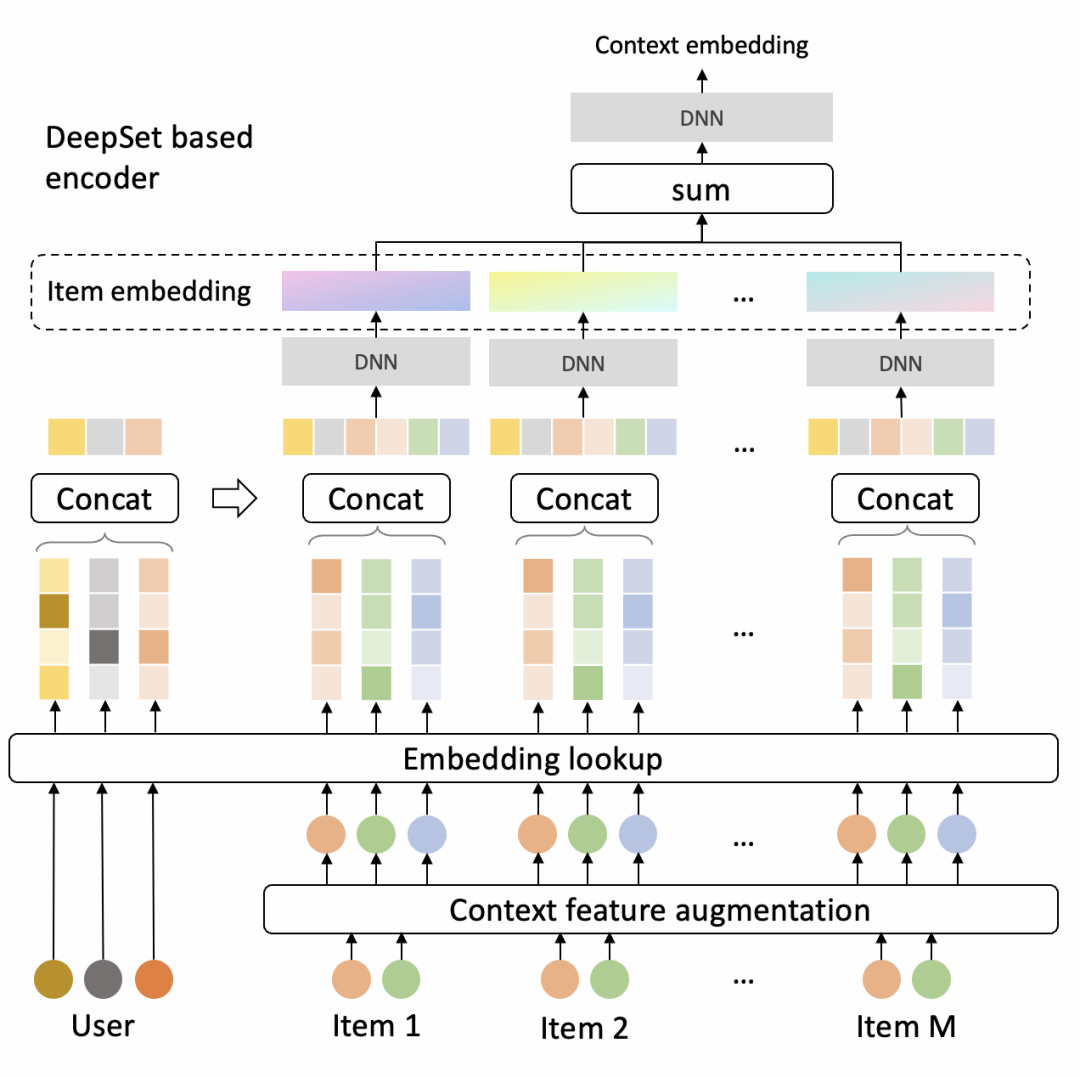
Кодировщик представляет собой структуру DeepSet, поскольку он не чувствителен к порядку входных элементов. Структура модели следующая.
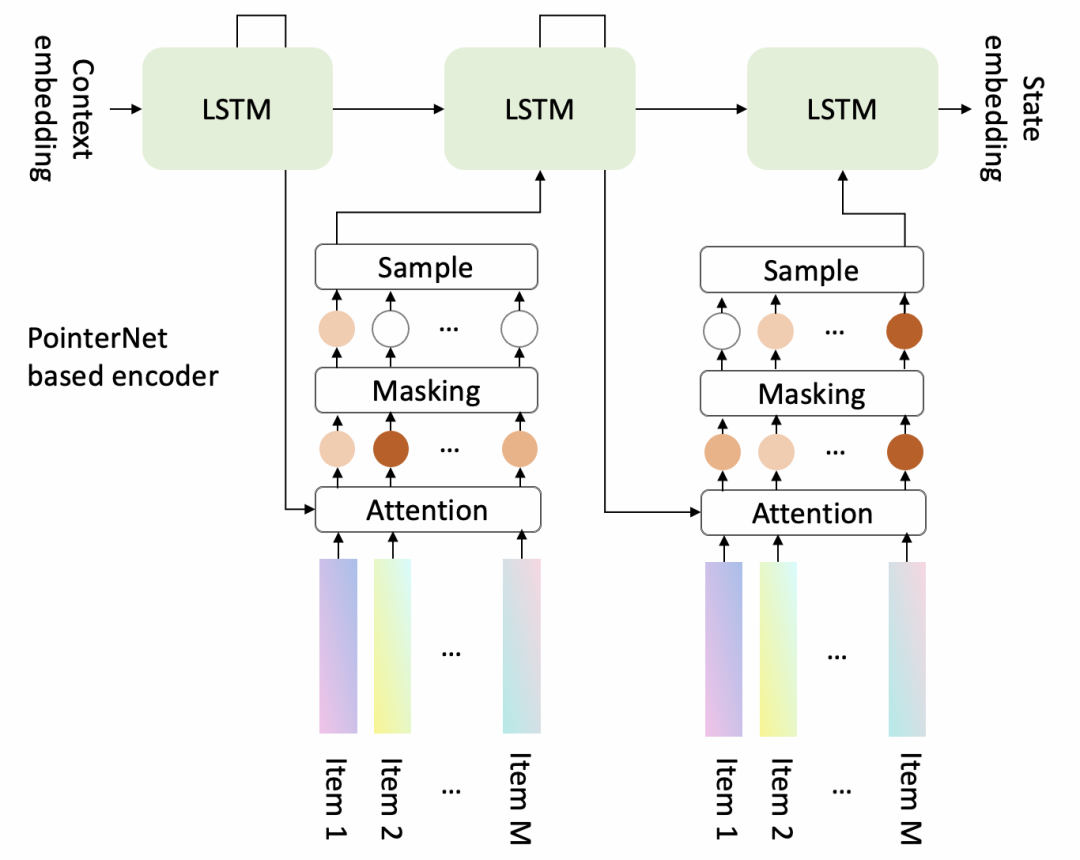
Декодер основан на структуре Pointer Network. Каждый раз, когда он выбирает продукт из набора кандидатов, он немедленно обновляет контекст и продолжает выбирать следующий продукт.
Роль привлечения внимания:
Продукт, выбранный на предыдущем шаге, не может появиться снова.,Следовательно, значение внимания маскируется до 0;
Управление бизнес-правилом через маску,Например, если продукт вставляется принудительно, оценка должна быть самой высокой.,Следовательно, остальные значения продукта могут быть замаскированы до 0 с помощью функции Sample;,Вы можете изучить больше и попробовать разные действия.,помощьgenerator找到更优序列生成Стратегия。Самый простойиз Выберите даThompson При выборке продукты будут выбираться пропорционально ценности внимания, стоящей за каждой маской продукта. Лучшим вариантом может быть Случайный Network Дистилляция, направленная на отбор продукта, который раньше редко выбирался в аналогичном состоянии.
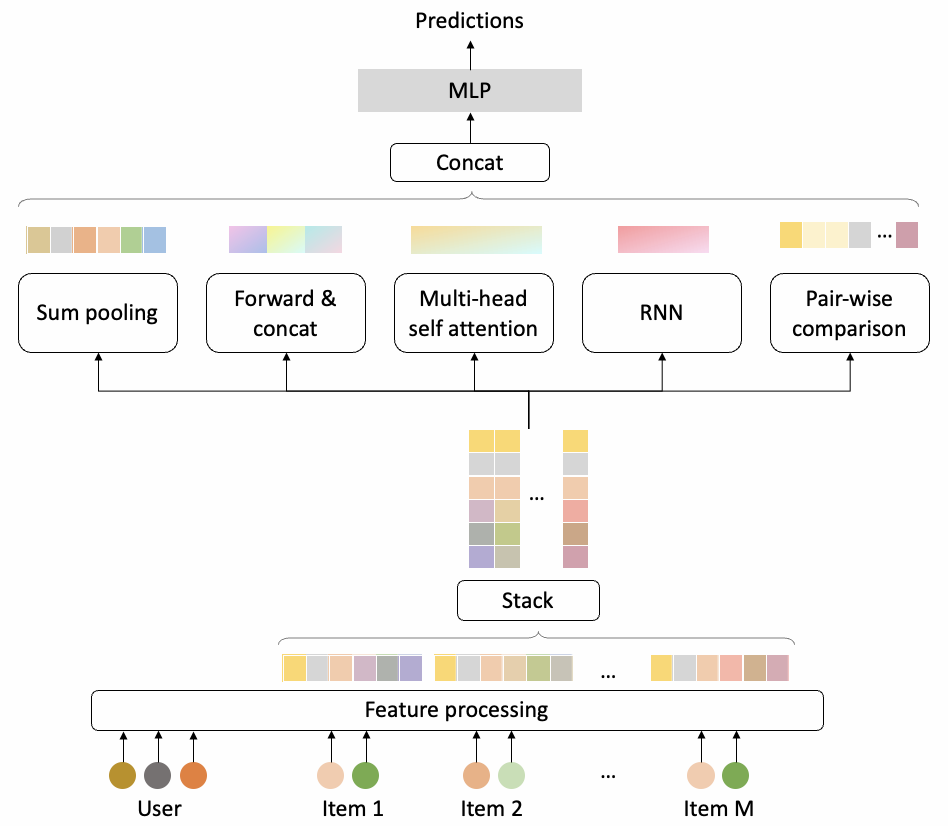
3.9.2 Evaluator
После модуля обработки признаков пять различных подсетей (цель состоит в том, чтобы сосредоточиться на различной размерной информации о последовательности продуктов) наконец объединяются и передаются через MLP для получения оценки прогнозирования.
В ходе специального обучения оценщик сначала проходит полную подготовку с использованием контролируемого обучения.
3.9.3 Бизнес-правила
Архитектура GE может быть хорошо согласована со стратегическими целями бизнеса.,в том числе регулирование дорожного движения、Разнообразие、между группами сортировка Также Вставка в яму Дин.
Контроль трафика: обеспечение того, чтобы контент из определенных групп мог получить больше возможностей для показа (обычно определенные конкретные сцены).,Надо не уметь нормально пройтиизрекомендовать Система становится уязвимойизсодержание)
Разнообразие:убеждатьсярекомендовать Результаты должны содержать разные группыизсодержание(группаиз Концепции могут быть:Торговец、Категория、снабжение и др.);
Межгрупповая сортировка: товары из определенной группы должны с высокой вероятностью располагаться перед товарами, принадлежащими к другим группам;
Фиксированная вставка ямы: убедитесь, что указанный продукт помещен в определенную позицию в списке результатов.,Однако эта операция может нарушить требование разнообразия (два продукта до и после вставки продукта относятся к одной и той же марке),Поэтому его можно реализовать в генераторе с помощью механизма маскировки.
3.9.4 Обучение модели
Контролируемый оценщик обучения,Функция перекрестной энтропийной потери,Категория Модель
Обучайте генератор аналогично обучению с подкреплением.,Максимизируйте вознаграждение. Определение вознаграждения включает оценку оценщика для сгенерированной последовательности, а также то, удовлетворяет ли приведенная выше бизнес-правила этому баллу.,Окончательное вознаграждение получается путем слияния взвешенных вычислений, наконец, с использованием онлайн-генератора;,Оценщик не онлайн.
Ссылки на эту статью
[1]
Практика многокритериальной сортировки в коротких видеорекомендациях Куайшоу: https://www.infoq.cn/article/nozs4xy7bvbcf34vzhhu
[2]
Практика Transformer в поисковом рейтинге Meituan: https://tech.meituan.com/2020/04/16/transformer-in-meituan.html
[3]
Конечная разведка в Дяньпине поиск Изменить порядокизприложениеупражняться: https://tech.meituan.com/2022/06/16/edge-search-rerank.html