Подсказка к расшифровке Серия 9. Модель сложного рассуждения – основы цепочки мышления и продвинутый игровой процесс
Эта статья действительно является подсказкой по расшифровке! Мы обсудим, как писать слова-подсказки для цепочки мыслей и как писать более сложные слова. COT на самом деле является базовой логикой решений по вызову инструментов, использующих большие модели, такие как Self-ASK и ReACT. Поэтому перед главой «Вызов агента» у нас будет две главы, чтобы поговорить о цепочке мыслей.
Давайте сначала примем меры предосторожности: текущие исследования COT содержат некоторые метафизические элементы. Модели, используемые в некоторых исследованиях COT, не являются моделями SOTA, и один и тот же шаблон COT не может быть перенесен между различными моделями, и эффект COT отличается от эффекта COT. Сильная корреляция самой модели. Эта глава просто дает вам некоторые идеи для проектирования цепочек мышления.
Суть цепочки мыслей заключается в улучшении способности модели решать сложные задачи рассуждения, включая, помимо прочего, символические рассуждения, математические задачи, планирование решений и т. д. Цепочка мыслей позволяет модели моделировать процесс человеческого мышления. мышление и рассуждения для создания промежуточных действий перед получением результатов. Применимо к следующим сценариям
- Сложные задачи
- Решение самой задачи требует многоэтапных рассуждений.
- Улучшение производительности задач за счет размера модели относительно ограничено.
Базовое использование COT
Few-shot COT
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Первая глава, естественно, представляет собой знаменитую работу Маленького принца COT, а также новаторскую работу COT. Если судить по количеству цитирований, она уже не имеет аналогов.

В основе статьи лежит схема с несколькими выстрелами.,Направлять процесс промежуточного рассуждения при создании модели.,и в конечном итоге улучшить способность модели решать сложные проблемы。Основная логика оченьSimple\&Naive
- Добавляя процесс вывода к выборкам из нескольких кадров, модель можно настроить так, чтобы она сначала давала процесс вывода в процессе декодирования, а затем получала окончательный ответ.
- Добавление аналогичного промежуточного процесса рассуждения может значительно улучшить производительность модели при решении сложных задач рассуждения, таких как рассуждения на основе здравого смысла, математические задачи и символические рассуждения.
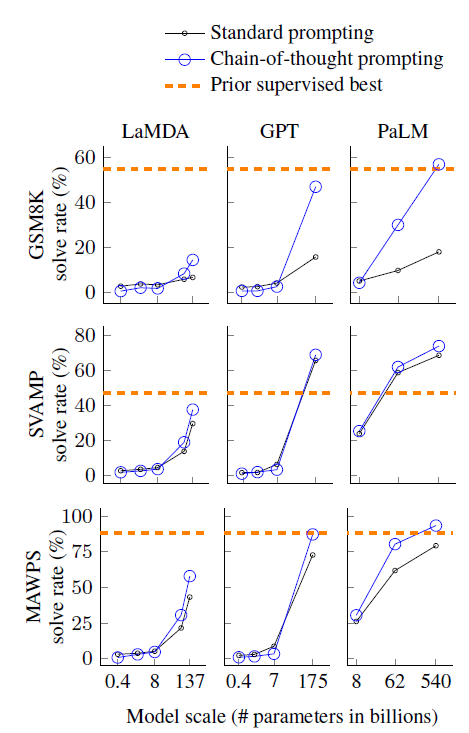
Давайте сначала посмотрим на эффект. См. рисунок выше. Вы можете получить несколько идей.
- Улучшение эффекта, вызванное COT, является неожиданным. Значительно лучшие эффекты проявляются только на больших моделях размером около 100B, но автор не объясняет причину влияния размера модели.
- Улучшение, внесенное COT, более значимо для сложных проблем, таких как GSM8K.
Давайте интуитивно рассмотрим конструкцию шаблона COT с несколькими кадрами и ее влияние на декодирование. Здесь мы используем образец математической инструкции COT Белль для выборки 10, чтобы построить набор инструкций цепочки мышления, состоящих из нескольких шагов, следующим образом:

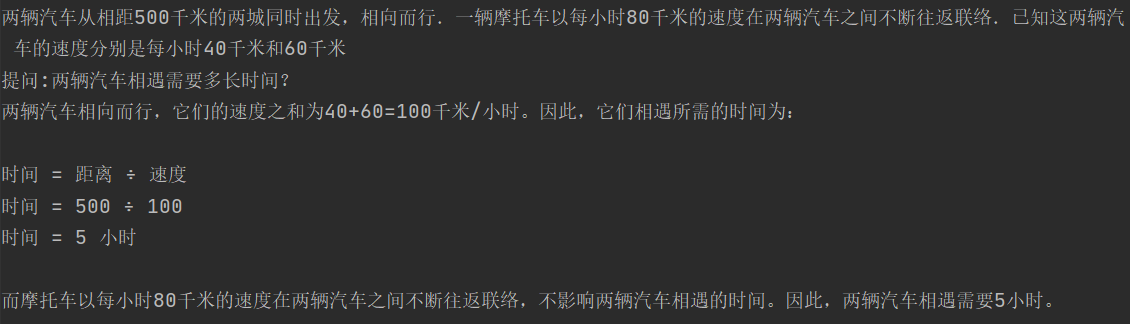
Чтобы проверить ваши математические способности, давайте возьмем классическую задачу о столкновении автомобилей из математической олимпиады начальной школы. Задача такова: две машины одновременно выехали из двух городов, находящихся на расстоянии 500 километров друг от друга, навстречу друг другу. Мотоцикл продолжает общаться между двумя автомобилями на скорости 80 километров в час. Известно, что скорости двух автомобилей равны 40 км/ч и 60 км/ч соответственно. Сколько километров проехал мотоцикл в момент встречи двух автомобилей? Вопрос не сложный 500/(40+60)*80=400 километров.
Нижеследующее использует ChatGPT и ChatGLM для декодирования в режиме жадного поиска, соответственно задавая вопросы напрямую и добавляя несколько шагов перед тем, как задавать вопросы.
prompt | chatgpt | chatglm-6b |
|---|---|---|
прямой вопрос | Предположим, что время встречи двух автомобилей составляет $t$ часов, тогда расстояние до встречи двух автомобилей равно $(40+60)t=100t$ километров. Мотоцикл продолжает двигаться вперед и назад в течение этих $t$ часов, что эквивалентно проезду $2\x 80t=160t$ километров туда и обратно между двумя автомобилями. Таким образом, мотоцикл проехал в общей сложности 160 тысяч долларов километров. По смыслу вопроса, расстояние встречи двух автомобилей составляет 500 километров, поэтому $t=\frac{500}{100}=5$ часов. Подставив результаты, мотоцикл проехал в общей сложности $160\times 5=\boxed{800}$ километров. | Предположим, что мотоцикл проехал $x$ часов, когда две машины встретились. По смыслу вопроса два автомобиля движутся навстречу друг другу, и их относительная скорость равна $40+60=100$ километров/час. Следовательно, когда две машины встречаются, сумма пройденных ими расстояний равна: $500\times(100+40)=50000$ Поскольку в момент встречи двух машин мотоцикл ехал, расстояние, пройденное мотоциклом, равно расстояние, пройденное мотоциклом при встрече двух автомобилей. Сумма пройденного расстояния: $x\times80=50000$. Решение: $x=4000$. Следовательно, когда две машины встретились, мотоцикл проехал в общей сложности $4000$. километров. |
few-shot COT | Предположим, что мотоцикл проехал в общей сложности x километров, тогда при встрече двух автомобилей количество поездок туда и обратно составит x/500. За каждый рейс туда и обратно расстояние, пройденное мотоциклом, составляет 80 километров, поэтому общее расстояние, пройденное мотоциклом, равно: x = (80 километров) × (x/500) = 0,16x километров. Когда встречаются два автомобиля, они получают общее расстояние. составляет 500 километров, поэтому время, необходимое для их встречи, равно: t = 500 километров/(40 километров/час + 60 километров/час) = 5 часов. В зависимости от скорости и времени движения мотоцикла получим: x. = 80 км/ч × 5 часов = 400 км. Таким образом, мотоцикл проехал всего 400 км. | Предположим, что мотоцикл проехал $x$ часов, когда две машины встретились. Из смысла вопроса видно, что когда две машины встретились, они уже проехали 500 километров, поэтому: $40x + 60x = 500$ Решение — $x=50/9$, то есть когда. встретились две машины, мотоцикл проехал 50/9 часов. Следовательно, мотоцикл проехал в общей сложности: $80\раз (50/9) = 400$. |
После присоединения к COT и Chatgpt, и Chatglm ответили правильно. Хотя здесь была некоторая удача, процесс рассуждения казался немного замедленным. Но вы обнаружите, что без добавления модели COT с несколькими кадрами она все равно будет выполнять вывод и затем давать ответ вместо модели, приведенной в статье, которая дает ответ напрямую, без каких-либо рассуждений. Причина в том, что в статье используется text-davinci-002, старая версия модели, не проходившая RLHF. Мы также протестировали некоторые вопросы с несколькими вариантами ответов, требующие рассуждения. Независимо от того, используем ли мы COT с несколькими предложениями или добавляем образцы инструкций COT для точной настройки, это действительно может привести к определенной степени улучшения рассуждений/математических способностей.
В документе также были проведены некоторые эксперименты по абляции, в том числе
- Происходит ли повышение точности за счет введения математических формул?
В статье была опробована часть с несколькими выстрелами, и только добавление формул не смогло существенно улучшить эффект. Лично я считаю, что этот эксперимент по абляции не очень завершен.,Потому что многие сложные модели проблем MWP трудно сопоставить с одной формулой.,Сначала разложите задачу, а затем постепенно отобразите ее в промежуточную формулу.,В нашем сценарии эффект можно улучшить。Вот два рекомендуемых набора данных:APE210KиMath23Kсоответственнода ЮаньфудаоиTencent выкладывает в открытый доступ набор данных, который преобразует математические задачи мира в формулы,Вы можете попробовать это сами
- Является ли повышение точности результатом того, что метод «несколько кадров» помогает модели лучше запомнить соответствующие знания?
В статье опробован шаблон подсказки, который сначала дает ответы, а затем делает выводы, и обнаружил, что эффект был значительно хуже. Это показывает, что COT с несколькими выстрелами активирует модель только для получения вывода, а сам процесс вывода является основой улучшения эффекта модели. Мы также обнаружили, что в некоторых вопросах с несколькими вариантами ответов, требующих рассуждения, сначала рассуждение, а затем ответ на варианты, значительно более эффективно, чем сначала ответить на варианты, а затем приводить процесс рассуждения.
zero-shot COT
Large Language Models are Zero-Shot Reasoners
В дополнение к использованию образцов Few-shot-COT, позволяющих модели обеспечить процесс рассуждения, простое использование инструкций также может позволить модели обеспечить цепочку мышления, что может еще больше улучшить способность модели к рассуждению для сложных проблем. Самая эффективная команда для активации цепочки мышления в статье — «Давайте думать шаг за шагом», ха-ха-ха. Когда я увидел эту часть статьи, у меня возникло ощущение, будто воздух застыл.

Zero-shot-COT требует двух этапов декодирования в статье. Первый шаг — использовать «Давайте подумаем шаг за шагом», чтобы позволить модели представить процесс рассуждения. Второй шаг — ввести процесс рассуждения и вопрос в модель и затем. пусть модель даст результат. Но при реальном использовании вы обнаружите, что в основном первый шаг модели декодирования даст результат в конце вывода, и если входные данные с результатом вводятся в модель, существует высокая вероятность того, что второй шаг модели даст тот же ответ, поэтому на самом деле COT с нулевым выстрелом также можно выполнить за один шаг.
Наше основное внимание сосредоточено на вопросе о встрече, или о встрече мотоцикла и грузовика. Давайте зададим его еще раз, используя несколько разных наборов активирующих слов.
слово активации | chatgpt | chatglm |
|---|---|---|
Пожалуйста, используйте пошаговые рассуждения и анализ для решения следующих задач. | Предположим, что время встречи двух автомобилей равно t часов, тогда расстояние до встречи двух автомобилей равно (40+60)t=100t километров. Поскольку два автомобиля движутся навстречу друг другу, их относительная скорость равна 40+60=100 км/ч. Следовательно, расстояние туда и обратно мотоцикла за t часов составит 2×80t=160t километров. По смыслу вопроса мотоцикл остановился при встрече двух автомобилей, следовательно, общий пройденный мотоциклом путь составил 160т километров. Объединив два приведенных выше уравнения, мы получаем t=2,5 часа. Следовательно, общий пробег мотоцикла составит 160×2,5=400 километров. | Предположим, что мотоцикл проехал $x$ часов, когда две машины встретились. По смыслу вопроса два автомобиля движутся навстречу друг другу, и их относительная скорость равна $40+60=100$ километров/час. Следовательно, при встрече двух автомобилей расстояние между ними составляет $500-x$ километров. Согласно смыслу вопроса, мотоцикл постоянно перемещается между двумя автомобилями со скоростью $80$ километров в час. Следовательно, каждый раз, когда мотоцикл проедет $x$ часов, он проедет $80x$ километров, когда встречаются две машины. Следовательно, уравнение можно записать: $80x = 500-x$ Решая уравнение получаем: $x = 50$ Следовательно, когда две машины встретились, мотоцикл проехал в общей сложности $80x=3000$ километров. |
Пожалуйста, ответьте на вопрос поэтапно | настраивать Когда встречаются две машинымеждуtЧас,Тогда расстояние встречи двух автомобилей будет (40+60)t=100ткм по смыслу вопроса.,Мотоцикл продолжает двигаться вперед и назад между двумя автомобилями со скоростью 80 км/ч.,Следовательно, поездка на мотоцикле в течение T часов составляет 2 × 80 × T = 160tkm,Мотоцикл проехал в общей сложности 160ткм. Приравняем два уравнения.,Получить: 100t=500t=5это,Когда встречаются две машины,Мотоциклы ехали вместе160×5=<<160*5=800>>800км. | Предположим, что мотоцикл проехал $x$ часов, когда две машины встретились. По смыслу вопроса две машины движутся навстречу друг другу, поэтому время их встречи можно рассчитать по следующему уравнению: $t = \frac{500}{40 + 60} = 10$ Поскольку мотоцикл имеет ехал, когда две машины встретились, поэтому время в пути на мотоцикле также составит $x$ часов. По смыслу вопроса скорость мотоцикла равна $80$ километров в час, поэтому расстояние, пройденное мотоциклом, можно рассчитать по следующему уравнению: $x \times 80 = 500 - t$ Подставив значение $ t$ в приведенное выше уравнение, мы получаем: $x \times 80 = 500 - 10 = 490$. Таким образом, когда две машины встретились, мотоцикл проехал в общей сложности 490$ километров. |
Существует 2 набора слов-подсказок, и только первый набор позволил чату дать правильный ответ. В целом, эффект слов-подсказок очень метафизический. Мы пробовали много разных решений для разных вопросов, таких как множественный выбор и математические вычисления. , но ничего не найдено. Автор статьи также попробовал разные слова инструкций, чтобы проверить степень зависимости COT с нулевым выстрелом от слов инструкций, как показано в таблице ниже. В целом, пока слова инструкции имеют смысл, направляя модель на пошаговые рассуждения, эффект модели будет улучшаться. Лично я только видел это и чувствовал, что COT с нулевым выстрелом действительно может быть разумным, потому что приведенная выше семантика, обеспечиваемая инструкциями, действительно имеет определенную корреляцию с семантикой декодирования модельных рассуждений.

С точки зрения эффекта в статье он сравнивается с алгоритмом с несколькими выстрелами на MultiArith и GSM8k. В целом он немного хуже, чем с несколькими выстрелами, но значительно превосходит базовый уровень, в котором используются только инструкции. Однако следует отметить, что оценочной моделью здесь по-прежнему является text-davinci-002. Это версия, которая не прошла через RLHF и сделала только SFT. Это не самая сильная модель на данный момент. Следующая картина будет значимой при использовании скидки GPT4. В конце концов, точность GPT-4 при использовании COT с несколькими выстрелами на GSM8k достигла 90%+. Что касается размера модели, COT с нулевым выстрелом также имеет эффект масштаба, и только на больших моделях он демонстрирует эффекты, выходящие за рамки обычных инструкций.
Расширенное использование COT
Независимо от вышеупомянутого COT с несколькими или нулевыми шагами, процесс рассуждения по-прежнему основан на самой модели, и люди не будут слишком сильно вмешиваться в процесс рассуждения. При расширенном использовании в процессе рассуждения будет производиться дальнейшее ручное вмешательство для управления этапами декодирования и дальнейшего повышения точности декодирования, а следующие расширенные решения могут использоваться в комбинации.
Self-Consistency
SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
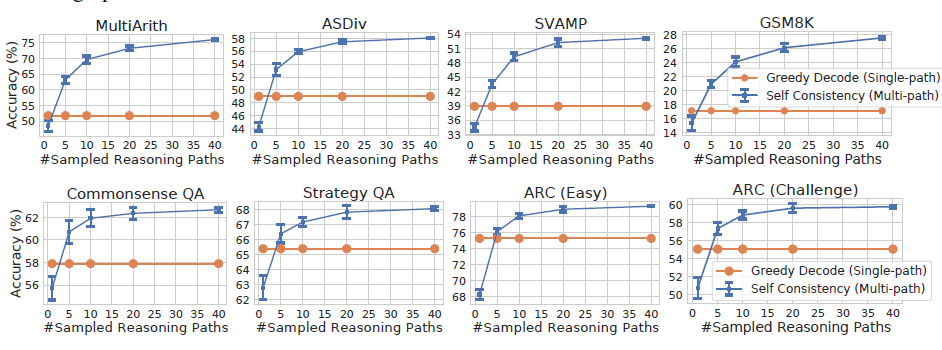
Самосогласованность — это стратегия декодирования, которая использует Ensemble для замены жадного поиска на основе нескольких шагов для повышения точности декодирования. В статье показано, что добавление самосогласованности может еще больше улучшить эффект мыслительной цепочки GSM8K (+17,9%). ).
При использовании больших моделей для ответа на фиксированные вопросы, такие как вопросы с множественным выбором и математические вопросы, мы часто используем жадный поиск для декодирования, чтобы гарантировать, что декодирование модели дает фиксированные результаты. В противном случае используется случайное декодирование. Модель выбрала ABCD. один раз, так модель ответила на этот вопрос правильно или неправильно? ? Однако локальная оптимальная схема декодирования, которая выбирает верхний токен на каждом этапе, очевидно, не является глобальной оптимальной. Самосогласованность на самом деле обеспечивает неконтролируемую схему ансамбля для «голосования» за множественные ответы, генерируемые случайным декодированием модели. более точный ответ, как показано ниже

Основное предположение о самосогласованности очень гуманно: разные люди будут предлагать разные решения одной и той же проблемы, но правильные решения приведут к одному и тому же правильному ответу разными путями. Используя эту модель аналогии для декодирования, различные случайные декодирования одного и того же вопроса приведут к разным процессам рассуждения в цепочке мышления. Ответ с наибольшей ожидаемой вероятностью имеет наибольшую точность. Затем ядром становится то, как агрегировать ответы для нескольких выходных данных декодирования. В статье сравниваются следующие варианты
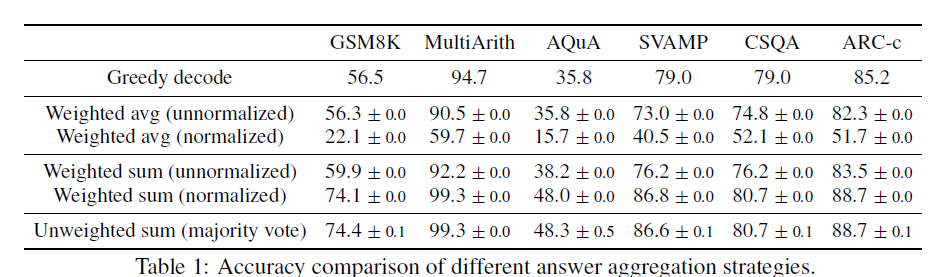
Дана командная строка и вопрос-вопрос,Модель будет генерировать группу путем случайного декодированияa_1,a_2,...a_m Ответить кандидатам,И соответствующий путь цепочки мышленияr_1,r_2,...r_m . Две схемы агрегирования с лучшими результатами:
- мажорное голосование: прямое голосование за декодированный результат, чтобы проголосовать за ответ с наибольшей вероятностью появления. Следует сказать, что самое простое решение часто является лучшим. Все результаты, приведенные ниже в статье, основаны на методе голосования.
- normalized weighted sum: вычислить(r_i, a_i) Вероятность пути представляет собой сумму вероятностей условного декодирования каждого токена, выдаваемого моделью, а длина декодирования K нормируется. Хотя это немного удивительно, я думал, что взвешенные результаты будут лучше, что также может указывать на то, что вероятность декодирования модели в определенной степени не сильно отличается от правильности ответа.
Также были проведены некоторые тесты на бумаге с параметрами декодирования.
- Случайные параметры: самосогласованность поддерживает различные стратегии случайного декодирования. При настройке параметров необходимо сбалансировать разнообразие и точность декодирования. Например, если температура слишком низкая, разница в декодировании будет слишком маленькой, и голосование будет одиноким. слишком высокая температура повлияет на точность конечного результата. Если посмотреть на тест, то top-p=40 и температура=0,5 могут быть хорошей отправной точкой для тестирования.
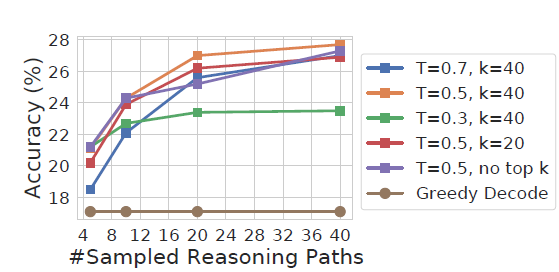
- Количество выборок: Эффект мажоритарного голосования во многом зависит от количества выборок кандидатов. В статье взята выборка 40 раз. Сын домовладельца не посмел бы этого сделать... Видно, что выборок больше. более чем в 5 раз может превзойти жадное декодирование. Конкретное количество декодирований зависит от того, сколько излишков еды есть в вашей семье...
Least-to-Most
LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS
Если вышеописанная Самосогласованность несколько жестока и творит чудеса, то От Наименее к Наибольшему, очевидно, более элегантен. Идея очень проста. При решении сложных задач первый шаг — помочь модели разделить проблему на подвопросы, второй шаг — ответить на подвопросы один за другим и использовать ответы на подвопросы; вопросы в качестве ответа на следующий вопрос до тех пор, пока не будет дан окончательный ответ. Ответ сосредоточен на пошаговом решении проблемы. Это также можно понимать как использование нескольких шагов, чтобы помочь модели дать более разумные и последовательные идеи рассуждения, а затем решить проблему на основе этой идеи.
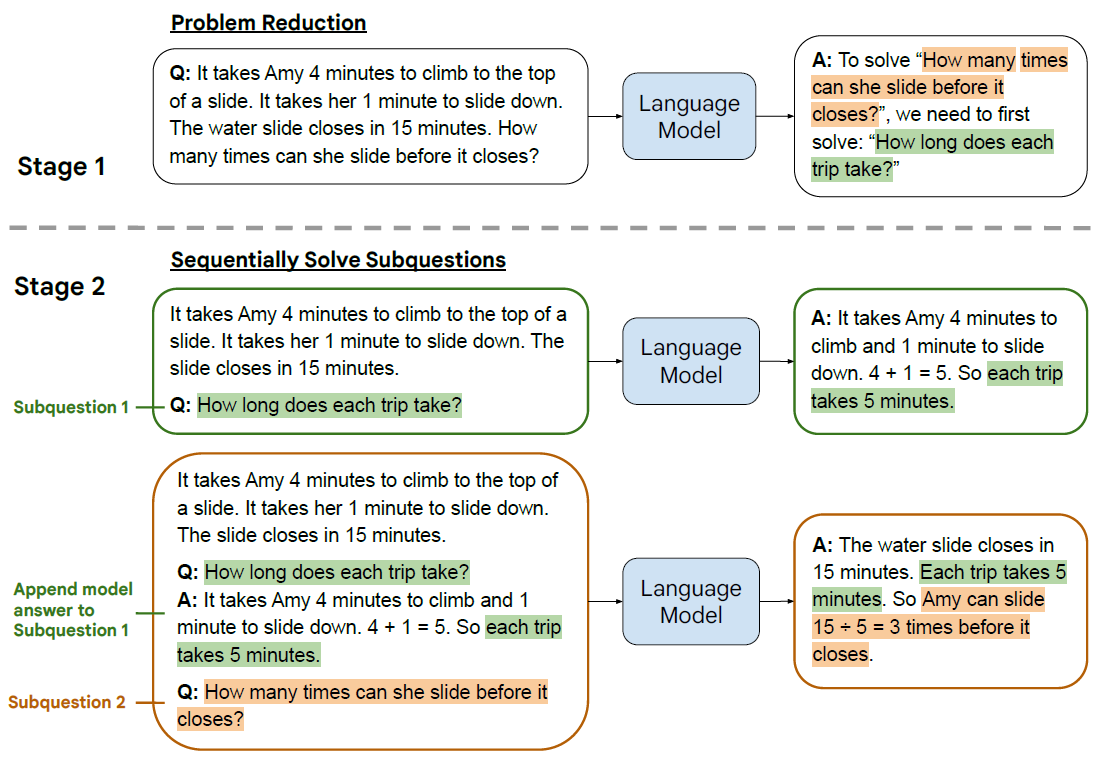
Идея дизайна очень хорошая,Но больше всего меня интересует, как написать COT с несколькими кадрами.,Только таким образом можно управлять моделью для выполнения разумных операций для различных сценариев. Здесь мы еще рассмотрим, как построить несколько выстрелов для математических задач.,в газетеfew-shot-promptдаПолностью рукописный и произведенный,Здесь я использую Chatgpt для генерации, а затем вручную настраиваю. Случайно выбранные 3 вопроса от APE21K,Будьте осторожны, не будьте слишком простыми,Уже есть документы, подтверждающие,Чем больше шагов вывода для выборок COT с несколькими выстрелами, тем лучше эффект. Подсказка (не настроенная) для моего разбора задачи здесь: «Решение задач для следующих математических задач».ы, разделенные на несколько необходимых промежуточных шагов решения проблемы и заданные соответствующие вопросы, Вопрос: ", чтобы позволить ChatGPT генерировать промежуточные шаги решения проблем в виде шаблона с несколькими выстрелами.
- Уменьшение проблем

По-прежнему возникает та же проблема, через подсказку «Уменьшить», вывод ChatGPT: сколько километров проехал мотоцикл в общей сложности? Нам необходимо ответить на следующие вопросы: «Сколько времени встретится две машины?», «Сколько километров проехал мотоцикл за это время?»
Приведенный выше анализ проблемы не очень стабилен. Иногда он включает в себя финальную задачу, а иногда только промежуточные этапы решения проблемы. На всякий случай вы можете добавить исходную задачу после анализируемой проблемы.
- Последовательное решение. Ответы на подвопросы даются по порядку.
Разберите подвопросы шага сокращения, введите Chatgpt по порядку и сначала ответьте на первый подвопрос.
Затем соедините первый подвопрос и ответ, как указано выше. Здесь вы также можете использовать историю разговора. Объединение предназначено только для визуального отображения.

Самая важная вещь для наименьшего количества-это идея разделения его проблемы, которая широко используется позже, например, как агент вызывает, как разделить шаги вызова каждого шага и как думать о следующем этапе Следующий шаг.
Если вы хотите увидеть более полный обзор статей, связанных с большими моделями, данными и платформами точной настройки и предварительного обучения, а также приложениями AIGC, перейдите на Github. >> DecryptPropmt



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
