Подробные оконные функции MySQL: принципы и приложения
1. Что такое оконная функция?
Оконные функции — это расширенная функция стандарта SQL.,Это позволяет пользователям изменять количество строк в наборе результатов запроса, не меняя,Выполняйте агрегатные вычисления или другие сложные вычисления в каждой строке. Эти вычисления основаны на взаимосвязи между текущей строкой и другими строками в наборе результатов. Функция окна особенно полезна, когда вычисления необходимо выполнять по нескольким строкам.,В то же время вы хотите сохранить неизменным количество строк в исходном наборе результатов запроса.
1. Принцип работы окна
Оконные функции работают путем определения «окна» над набором результатов запроса, который может представлять собой весь набор результатов или его подмножество. Оконные функции выполняют вычисления над строками внутри окна и возвращают значение для каждой строки. Это значение рассчитывается на основе значения строки в окне и логики самой оконной функции.
Оконная функция не меняет количество строк в наборе результатов запроса, но добавляет дополнительный столбец к каждой строке. Этот столбец содержит результат вычисления оконной функции. Это делает оконные функции идеальными для сценариев, в которых необходимо выполнять агрегирование или другие сложные вычисления, сохраняя при этом исходные данные.
2. Компоненты оконных функций
Основная синтаксическая структура оконных функций выглядит следующим образом:
<окнофункция>(<параметр>) OVER (
[PARTITION BY <выражение разделения>]
[ORDER BY <выражение сортировки> [ASC | DESC]]
[ROWS/Range <окнообъем>]
)- <окнофункция>(<параметр>):Указатьиспользоватьизокнофункцияипараметр。окнофункция Может быть совокупностьюфункция(нравитьсяSUM、AVG и т. д.) или функция, специально разработанная для функции Windows (например, ROW_NUMBER、РАНГ и др.).
- OVER(): Определите рамку окна. Все окна требуют использования предложения OVER() для указания области действия и поведения окна.
- PARTITION BY <выражение разделения>(Необязательный):Разделить набор результатов на несколько разделов,Функция Windows будет выполняться независимо в каждом разделе. Выражением раздела может быть одно или несколько имен столбцов.,Используется для определения того, как разделить набор результатов на разные разделы.
- ORDER BY <выражение сортировки> ASC | DESC (необязательно): определяет порядок сортировки строк в окне. Выражением сортировки может быть одно или несколько имен столбцов, определяющих способ сортировки строк в окне.
- ROWS/Range <диапазон строк>(Необязательный):определениеокноиздиапазон строк。диапазон строк Может是固定из行数(нравитьсяROWS BETWEEN 2 PRECEDING AND CURRENT ROW) или динамический диапазон относительно текущей строки (например, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, то есть все строки от начала окна до текущей строки).
3. Объясните диапазон окон
В оконной функции MySQL синтаксис для указания размера окна в основном реализуется через предложение OVER(), в котором ключевое слово ROWS или RANGE может использоваться для определения границ окна. Однако следует отметить, что ROWS и RANGE определяют, основан ли диапазон окна на физических позициях строк или значениях столбцов, а не прямо указывают «размер» окна. «Размер» окна фактически определяется этими параметрами диапазона и предложением ORDER BY.
Синтаксис для указания диапазона окна с помощью предложения OVER()
OVER (
[PARTITION BY partition_expression, ... ]
[ORDER BY sort_expression [ASC | DESC], ...]
[ROWS frame_specification]
-- или
[RANGE frame_specification]
)в,frame_specificationопределение了окноиз起始иконечное положение,Он бывает следующих форм:
BETWEEN frame_start AND frame_end: определяет начальную и конечную границы окна.
Frame_start: Если указана только начальная граница, окно будет простираться от этой границы до последней строки текущего раздела.
frame_end: Обычно вы не указываете только конечную границу, поскольку для формирования полного размера окна требуется начальная граница.Для ROWS и RANGE параметры Frame_start и Frame_end могут иметь одно из следующих значений:
UNBOUNDED ПРЕДЫДУЩИЙ: Окно начинается с первой строки текущего раздела.
N ПРЕДЫДУЩИЙ: окно начинается с N-й строки перед текущей строкой, где N — положительное целое число.
CURRENT СТРОКА: окно начинается с текущей строки.
N СЛЕДУЮЩЕЕ: Окно начинается с N-й строки после текущей строки.
UNBOUNDED СЛЕДУЮЩЕЕ: Окно заканчивается на последней строке текущего раздела (обычно используется только для Frame_end).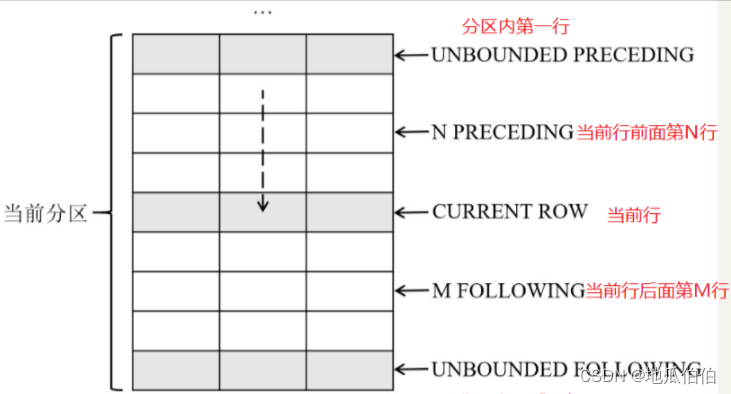
ROWS определяет диапазон окна на основе физического местоположения строки, а RANGE определяет диапазон окна на основе значений столбца, указанных в предложении ORDER BY. RANGE особенно полезен при работе с числовыми данными, поскольку он может содержать другие строки со значениями, аналогичными текущей строке, даже если они физически не являются соседними.
пример:
-- Используйте ROWS, чтобы указать диапазон окна и вычислить общий объем продаж текущей строки и ее первых двух строк.
SELECT sale_date, amount,
SUM(amount) OVER (ORDER BY sale_date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS rolling_total
FROM sales;
-- Используйте RANGE, чтобы указать диапазон окна и вычислить среднее значение в пределах диапазона рядом с текущим значением строки.
SELECT price,
AVG(price) OVER (ORDER BY price RANGE BETWEEN 10 PRECEDING AND 10 FOLLOWING) AS avg_nearby_price
FROM products;В первом примере ROLLING_TOTAL вычисляет сумму полей AMOUNT предыдущих трех строк, включая текущую строку. Во втором примере AVG_NEARBY_PRICE вычисляет среднюю цену в диапазоне 10 единиц до и после текущего значения PRICE (обратите внимание, что фактический диапазон может включать больше строк, поскольку RANGE будет включать все строки в этом диапазоне, даже если их физическое расположение находятся не рядом друг с другом).
Следует отметить, что использование RANGE может быть затруднено из-за распределения и дублирования значений столбцов, поскольку необходимо поддерживать упорядоченную структуру данных, чтобы определить, какие строки находятся в пределах указанного диапазона. ROWS, с другой стороны, вычисляет окно просто на основе физического порядка строк.
Общие параметры предложения ROWS
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT СТРОКА: от начала окна до текущей строки. Это диапазон окна по умолчанию, используемый, если не указано предложение ROWS.
ROWS BETWEEN N PRECEDING AND CURRENT СТРОКА: от N-й строки перед текущей строкой до текущей строки. N должно быть неотрицательным целым числом.
ROWS BETWEEN CURRENT ROW AND N СЛЕДУЮЩЕЕ: От текущей строки до N-й строки после текущей строки.
ROWS BETWEEN N PRECEDING AND M СЛЕДУЮЩЕЕ: от N-й строки перед текущей строкой до M-й строки после текущей строки.Общие параметры предложения RANGE
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT СТРОКА: от минимального значения окна до текущего значения строки.
RANGE BETWEEN CURRENT ROW AND UNBOUNDED СЛЕДУЮЩИЙ: От текущего значения строки до максимального значения окна.
RANGE BETWEEN N PRECEDING AND CURRENT СТРОКА: вычтите N из текущего значения строки до текущего значения строки. N здесь обычно представляет собой числовое выражение, определяющее размер диапазона относительно текущего значения строки.
RANGE BETWEEN CURRENT ROW AND N СЛЕДУЮЩИЙ: От текущего значения строки до текущего значения строки плюс N.Обратите внимание, что RANGE часто используется с предложением ORDER BY для определения логического порядка границ окна. Кроме того, при использовании RANGE окно может содержать больше строк, чем ожидалось, если имеются повторяющиеся значения столбцов.
Обычное использование RANGE — Рассчитать. скользящее среднее,Особенно, когда точки данных распределены неравномерно. Однако,на практике,Поскольку RANGE необходимо поддерживать упорядоченную структуру данных.,и процессМогут возникнуть проблемы с производительностью при дублировании значений.,Таким образом, ROWS обычно более популярен, чем RANGE.
4. Разница между оконными функциями и агрегатными функциями
Оконные функции и агрегатные функции являются мощными инструментами для анализа данных и составления отчетов в MySQL, но между ними есть явные различия. Ниже мы проиллюстрируем разницу между ними на конкретных примерах.
Агрегатные функции
Агрегатные функции работают с набором строк и возвращают одно значение. Общие агрегатные функции включают SUM(), AVG(), MIN(), MAX(), COUNT() и т. д. Эти функции часто используются с предложением GROUP BY для агрегирования сгруппированных данных.
пример:Предположим, есть таблица данных о продажах. продажи, в том числе product_id、sale_date и amount Список. Чтобы рассчитать общий объем продаж каждого продукта, вы можете использовать агрегатную функцию следующим образом:
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;В этом примере СУММ(сумма) это агрегатная функция, которая применяется к каждому product_id внутри группы amount Найдите значение,Возвращает общий объем продаж для каждого продукта. Результирующий набор будет содержать меньше строк,Потому что данные агрегируются по каждому идентификатору продукта.
Оконные функции
Оконные функции работают с каждой строкой набора результатов запроса, но их вычисления основаны на других строках в пределах диапазона «окна». Оконные функции не уменьшают количество строк в наборе результатов, а вместо этого добавляют дополнительные вычисления к каждой строке. Общие оконные функции включают ROW_NUMBER(), RANK(), DENSE_RANK(), SUM() (используется как оконная функция), AVG() (используется как оконная функция) и т. д.
пример:использовать相同из sales В таблице, если мы хотим рассчитать продажи каждого продукта за каждый день, а также хотим узнать совокупные продажи этого продукта до этого дня, мы можем использовать оконную функцию следующим образом:
SELECT product_id, sale_date, amount,
SUM(amount) OVER (PARTITION BY product_id ORDER BY sale_date ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_sales
FROM sales;В этом примере СУММ(сумма) OVER (…) это оконная функция. Он вычисляет до текущей строки включительно, путем sale_date Сортировать каждый product_id совокупных продаж. РАЗДЕЛ BY product_id Указывает, что данные сначала секционируются по идентификатору продукта, а затем сортируются по дате продажи в каждом разделе. Ряды BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW Определяет диапазон окна от первой строки раздела до текущей строки.
Результирующий набор будет содержать то же количество строк, что и исходная таблица продаж, но будет добавлен дополнительный столбец cumulative_sales, чтобы отобразить совокупные продажи до каждой строки.
Функции агрегирования уменьшают количество строк в наборе результатов, объединяя несколько строк данных в одно значение. Оконные функции сохраняют количество строк в наборе результатов постоянным и добавляют к каждой строке расчет, основанный на других строках в диапазоне окна. Агрегатные функции обычно используются с GROUP BY, а оконные функции используются с предложением OVER() для определения поведения окна.
2. Классификация оконных функций
Функцию окон MySQL можно классифицировать в соответствии с ее функциями и использованием:
1. Функция окна серийного номера
Функция серийного номера присваивает уникальный серийный номер или ранг каждой строке в наборе результатов. Эти номера обычно назначаются на основе порядка сортировки и других критериев.
ROW_NUMBER(): присвойте каждой строке уникальный серийный номер.
RANK(): присваивает ранг каждой строке, оставляя пробелы для одинаковых значений.
DENSE_RANK(): присваивает ранг каждой строке, но не оставляет пробелов для одинаковых значений.
Предположим, у нас есть таблица сотрудников, которая содержит информацию о сотрудниках, как показано ниже:
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
salary DECIMAL(10, 2)
);
INSERT INTO employees (emp_id, emp_name, salary) VALUES
(1, 'Alice', 50000),
(2, 'Bob', 55000),
(3, 'Charlie', 50000),
(4, 'David', 60000),
(5, 'Eva', 55000);Теперь мы хотим присвоить каждому сотруднику уникальный серийный номер (используя ROW_NUMBER()), рейтинг (используя RANK()) и плотный рейтинг (используя DENSE_RANK()), и все это на основе их зарплаты.
SELECT
emp_id,
emp_name,
salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
RANK() OVER (ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM
employees;
-- Результаты этого запроса могут выглядеть так:
emp_id | emp_name | salary | row_num | rank | dense_rank
-------+----------+--------+---------+------+------------
4 | David | 60000 | 1 | 1 | 1
2 | Bob | 55000 | 2 | 2 | 2
5 | Eva | 55000 | 3 | 2 | 2
1 | Alice | 50000 | 4 | 4 | 3
3 | Charlie | 50000 | 5 | 4 | 3В этом наборе результатов:
Столбец row_num показывает уникальные порядковые номера, присвоенные с помощью функции ROW_NUMBER(). Числа расположены в порядке убывания зарплаты, поэтому самый высокооплачиваемый сотрудник (Дэвид) получает номер 1.
rank В столбце показано использование RANK() Ранжирование функциональных назначений. Обратите внимание, что когда два сотрудника имеют одинаковую зарплату, они получают одинаковый рейтинг, а соответствующий рейтинг пропускается для следующего сотрудника. В этом примере Боб и Eva Все были оценены 2. Поэтому Alice и Charlie Пропустить рейтинг 3. Непосредственное получение рейтинга 4。
dense_rank В столбце показано использование DENSE_RANK() Плотное ранжирование назначений функций. и RANK() Разное, DENSE_RANK() При обнаружении повторяющихся значений пробелов не остается. Поэтому, несмотря на Bob и Eva Зарплата та же, но Alice и Charlie Все еще получил следующий плотный рейтинг 3。
2. Функция окна распределения
Функции распределения используются для расчета относительного положения или распределения значений внутри окна.
PERCENT_RANK(): Вычислите процентильный ранг строки.
CUME_DIST(): Вычисляет совокупное распределение строки относительно всех остальных строк.
При использовании оконных функций PERCENT_RANK() и CUME_DIST() час,Эти функции часто используются для расчета относительного ранжирования и совокупного распределения строк в наборе результатов. Вот пример,Показывает, как использовать обе функции в одном запросе.
Предположим, у нас есть таблица sales, содержащая данные о продажах, как показано ниже:
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
sale_date DATE,
amount DECIMAL(10, 2)
);
INSERT INTO sales (sale_id, sale_date, amount) VALUES
(1, '2023-01-01', 1000),
(2, '2023-01-02', 1500),
(3, '2023-01-03', 1200),
(4, '2023-01-04', 1800),
(5, '2023-01-05', 1100);Теперь мы хотим рассчитать процентный ранг и совокупное распределение продаж для каждой строки. Ниже приведен пример запроса:
SELECT
sale_id,
sale_date,
amount,
PERCENT_RANK() OVER (ORDER BY amount DESC) AS percent_rank,
CUME_DIST() OVER (ORDER BY amount DESC) AS cume_dist
FROM
sales;
-- Результаты этого запроса могут выглядеть так:
sale_id | sale_date | amount | percent_rank | cume_dist
--------+-------------+--------+--------------+-----------
4 | 2023-01-04 | 1800 | 0 | 0.2
2 | 2023-01-02 | 1500 | 0.25 | 0.4
3 | 2023-01-03 | 1200 | 0.5 | 0.6
5 | 2023-01-05 | 1100 | 0.75 | 0.8
1 | 2023-01-01 | 1000 | 1 | 1.0В этом наборе результатов:
percent_rank В столбце показано использование PERCENT_RANK() Функция вычисляет процентильный рейтинг. Это отношение ранга текущей строки к общему количеству строк минус 1, умноженное на 100. Поскольку у нас есть 5 строк данных, процентильный рейтинг варьируется от 0 до 1 (включая 0, но исключая 1), и amount Отсортируйте по убыванию.
cume_dist В столбце показано использование CUME_DIST() Кумулятивное распределение вычислений функций. Он представляет собой долю количества строк, значение которых меньше или равно значению текущей строки, к общему количеству строк. В этом примере CUME_DIST() Также нажмите amount Отсортировано в порядке убывания, поэтому строка с наибольшими продажами имеет наименьшее совокупное значение распределения (но не будет равно 0, если нет идентичных amount значение), а строка с наименьшими продажами имеет наибольшее совокупное значение распределения (всегда 1).
Обратите внимание, что PERCENT_RANK() и CUME_DIST() Результаты расчета могут различаться в зависимости от Реализация и точность данных немного различаются, но приведенный выше пример должен дать общее представление. Кроме того, если amount При одном и том же значении две функции будут вести себя по-разному: PERCENT_RANK(). присвоит один и тот же процентильный ранг одному и тому же значению, тогда как CUME_DIST() Будет рассмотрено влияние того же значения на кумулятивное распределение.
3. Функции переднего и заднего стекла.
Функции «до» и «после» позволяют получить доступ к значениям из предыдущей или следующей строки относительно текущей строки.
LAG(expr, offset, default): возвращает значение строки до указанного смещения.
LEAD(expr, offset, default): Возвращает значение строки после указанного смещения.
4. Функции первого и последнего окна
Первая и последняя функции позволяют получить значение первой или последней строки окна.
FIRST_VALUE(expr): возвращает значение первой строки в окне.
LAST_VALUE(expr): возвращает значение последней строки в окне.
Следует отметить, что FIRST_VALUE() и LAST_VALUE() без указания ORDER BY Предложение может работать не так, как ожидалось, поскольку порядок окон не определен. Кроме того, LAST_VALUE() В некоторых случаях лучше использовать LEAD() Функциональность гибкая.
Например: мы предполагаем, что существует таблица stock_prices, в которой записана ежедневная информация о ценах на определенную акцию.
Структура таблицы следующая:
CREATE TABLE stock_prices (
stock_date DATE PRIMARY KEY,
price DECIMAL(10, 2)
);
INSERT INTO stock_prices (stock_date, price) VALUES
('2023-10-01', 100.00),
('2023-10-02', 102.50),
('2023-10-03', 99.75),
('2023-10-04', 101.25),
('2023-10-05', 104.00),
('2023-10-06', 105.50),
('2023-10-07', 103.00);Сейчас,Мы хотим запросить ежедневную цену акций,И цена накануне и послезавтра,Также указана цена акции в первый и последний день периода регистрации. Ниже приведен пример запроса:
SELECT
stock_date,
price,
LAG(price) OVER (ORDER BY stock_date) AS prev_day_price,
LEAD(price) OVER (ORDER BY stock_date) AS next_day_price,
FIRST_VALUE(price) OVER (ORDER BY stock_date) AS first_day_price,
LAST_VALUE(price) OVER (ORDER BY stock_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_day_price
FROM
stock_prices;
-- Результаты запроса могут быть следующими:
stock_date | price | prev_day_price | next_day_price | first_day_price | last_day_price
------------+---------+----------------+----------------+-----------------+----------------
2023-10-01 | 100.00 | NULL | 102.50 | 100.00 | 103.00
2023-10-02 | 102.50 | 100.00 | 99.75 | 100.00 | 103.00
2023-10-03 | 99.75 | 102.50 | 101.25 | 100.00 | 103.00
2023-10-04 | 101.25 | 99.75 | 104.00 | 100.00 | 103.00
2023-10-05 | 104.00 | 101.25 | 105.50 | 100.00 | 103.00
2023-10-06 | 105.50 | 104.00 | 103.00 | 100.00 | 103.00
2023-10-07 | 103.00 | 105.50 | NULL | 100.00 | 103.00Обратите внимание, что LAST_VALUE() по умолчанию не работает должным образом, поскольку возвращает последнюю строку в окне, а не последнюю строку всего набора результатов. Чтобы гарантировать, что LAST_VALUE() возвращает последнюю строку всего набора результатов, мы используем ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING, чтобы он учитывал весь раздел (в этом случае весь набор результатов представляет собой один раздел).
В этом примере столбец prev_day_price показывает цену предыдущего дня (с использованием функции LAG), столбец next_day_price показывает цену следующего дня (с использованием функции LEAD), столбец first_day_price показывает цену первого дня всей записи. период (с использованием функции FIRST_VALUE), столбец Last_day_price показывает последнюю цену за весь период записи (с использованием функции LAST_VALUE и обеспечения правильного диапазона окна).
Обратите внимание, что в зависимости от вашей системы базы данных функция LAST_VALUE() может вести себя по-разному, особенно при работе с окнами по умолчанию. В некоторых системах баз данных может потребоваться корректировка приведенного выше запроса, чтобы гарантировать, что LAST_VALUE() правильно возвращает последнюю строку всего набора результатов. В некоторых случаях для достижения этой цели может потребоваться использовать подзапросы или другие методы.
5. Функция окна агрегирования
Функции агрегирования в качестве оконных функций: SUM(), AVG(), MIN(), MAX() и т. д. также могут использоваться в качестве оконных функций для расчета накопительных, скользящих или других совокупных значений для каждой строки.
Предположим, у нас есть файл с именем sales_data Таблица, в которой фиксируются ежедневные продажи разных продавцов. Структура таблицы следующая:
CREATE TABLE sales_data (
sales_date DATE,
salesperson_id INT,
sales_amount DECIMAL(10, 2)
);
INSERT INTO sales_data (sales_date, salesperson_id, sales_amount) VALUES
('2023-10-01', 1, 1000),
('2023-10-01', 2, 1500),
('2023-10-02', 1, 1200),
('2023-10-02', 2, 1300),
('2023-10-03', 1, 900),
('2023-10-03', 2, 1400),
('2023-10-04', 1, 1100),
('2023-10-04', 2, 1600);Сейчас,Мы хотим запрашивать продажи каждого продавца каждый день.,и продавец до сих пор(С начала месяца до текущего числа)средний объем продаж、максимальные продажи、Общий объем продаж и минимальный объем продаж. Ниже приведен пример запроса:
SELECT
sales_date,
salesperson_id,
sales_amount,
AVG(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS avg_sales,
MAX(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS max_sales,
SUM(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS total_sales,
MIN(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS min_sales
FROM
sales_data
ORDER BY
salesperson_id,
sales_date;
-- Результаты запроса могут быть следующими:
sales_date | salesperson_id | sales_amount | avg_sales | max_sales | total_sales | min_sales
------------+----------------+--------------+-----------+-----------+-------------+-----------
2023-10-01 | 1 | 1000.00 | 1000.00 | 1000.00 | 1000.00 | 1000.00
2023-10-02 | 1 | 1200.00 | 1100.00 | 1200.00 | 2200.00 | 1000.00
2023-10-03 | 1 | 900.00 | 1033.33 | 1200.00 | 3100.00 | 900.00
2023-10-04 | 1 | 1100.00 | 1050.00 | 1200.00 | 4200.00 | 900.00
2023-10-01 | 2 | 1500.00 | 1500.00 | 1500.00 | 1500.00 | 1500.00
2023-10-02 | 2 | 1300.00 | 1400.00 | 1500.00 | 2800.00 | 1300.00
2023-10-03 | 2 | 1400.00 | 1400.00 | 1500.00 | 4200.00 | 1300.00
2023-10-04 | 2 | 1600.00 | 1450.00 | 1600.00 | 5800.00 | 1300.00В этом запросе:
sales_date, salesperson_id, и sales_amount Столбец взят напрямую из sales_data поверхность.
Столбец avg_sales рассчитывает средний объем продаж на одного продавца с начала месяца до текущей даты.
Столбец max_sales рассчитывает максимальный объем продаж на одного продавца с начала месяца до текущей даты.
Столбец total_sales подсчитывает общий объем продаж на одного продавца с начала месяца до текущей даты.
Столбец min_sales вычисляет минимальные продажи для каждого продавца с начала месяца до текущей даты.
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW гарантирует, что окно начинается с первой строки текущего раздела и заканчивается текущей строкой. В этом случае раздел определяется PARTITION BY salesperson_id, и данные каждого продавца составляют один раздел. ORDER BY sales_date обеспечивает сортировку данных по дате продаж, что необходимо для расчета совокупной статистики.
6. Другие функции
В эту категорию входят некоторые оконные функции, которые не попадают в вышеуказанные категории, но тем не менее очень полезны в контексте оконных вычислений.
NTH_VALUE(expr, n): Возвращает значение n-й строки в окне.
NTILE(n): делит набор результатов на указанное количество примерно равных групп и присваивает каждой строке номер группы.
Предположим, у нас есть таблица данных о продажах sales_data.,ВСодержит сумму и дату продажи для каждого продавца.
Структура таблицы следующая:
CREATE TABLE sales_data (
sales_id INT PRIMARY KEY,
salesperson_id INT,
sale_date DATE,
amount DECIMAL(10, 2)
);
-- Вставьте пример данных
INSERT INTO sales_data (sales_id, salesperson_id, sale_date, amount) VALUES
(1, 1, '2023-01-01', 1000.00),
(2, 2, '2023-01-01', 1500.00),
(3, 1, '2023-01-02', 700.00),
(4, 3, '2023-01-02', 900.00),
(5, 2, '2023-01-03', 1100.00),
(6, 1, '2023-01-03', 1200.00),
(7, 3, '2023-01-03', 1300.00);Теперь мы хотим решить следующие две задачи:
- Для данных о продажах за каждый день найдите продавца со вторым по величине объемом продаж за этот день и его продажами.
- Разделите ежедневные данные о продажах на два уровня в зависимости от объема продаж для анализа эффективности продаж.
Для выполнения этих задач мы можем использовать оконные функции. Для начала выполним первое задание:
SELECT
sale_date,
salesperson_id,
amount AS second_highest_sale
FROM (
SELECT
sale_date,
salesperson_id,
amount,
NTH_VALUE(salesperson_id, 2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS second_salesperson_id,
NTH_VALUE(amount, 2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS second_highest_amount
FROM
sales_data
) AS subquery
WHERE
salesperson_id = second_salesperson_id
ORDER BY
sale_date;
-- Результат может быть следующим:
sale_date | salesperson_id | second_highest_sale
--------------+----------------+---------------------
'2023-01-01' | 2 | 1500.00
'2023-01-02' | 1 | 700.00
'2023-01-03' | 1 | 1200.00Примечание. С приведенным выше запросом существует проблема: NTH_VALUE может не вернуть ожидаемые результаты, поскольку не гарантируется возврат только одной строки. NTH_VALUE может возвращать идентификаторы нескольких продавцов при наличии параллельных продаж. Чтобы решить эту проблему, нам может потребоваться использовать ROW_NUMBER() или DENSE_RANK(). Однако для упрощения предположим, что связанных продаж нет, и немного скорректируем запрос.
Более точный запрос может выглядеть так:
WITH RankedSales AS (
SELECT
sale_date,
salesperson_id,
amount,
ROW_NUMBER() OVER (PARTITION BY sale_date ORDER BY amount DESC) AS rn
FROM
sales_data
)
SELECT
sale_date,
salesperson_id,
amount AS second_highest_sale
FROM
RankedSales
WHERE
rn = 2
ORDER BY
sale_date;Теперь выполним второе задание:
SELECT
sale_date,
salesperson_id,
amount,
NTILE(2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS sale_performance_group
FROM
sales_data
ORDER BY
sale_date,
sale_performance_group DESC,
amount DESC;
sale_date | salesperson_id | amount | sale_performance_group
--------------+----------------+-----------+----------------------
'2023-01-01' | 2 | 1500.00 | 1
'2023-01-01' | 1 | 1000.00 | 2
'2023-01-02' | 3 | 900.00 | 1
'2023-01-02' | 1 | 700.00 | 2
'2023-01-03' | 3 | 1300.00 | 1
'2023-01-03' | 1 | 1200.00 | 2
'2023-01-03' | 2 | 1100.00 | 2Этот запрос сортирует данные о продажах за каждый день в порядке убывания продаж и использует NTILE(2) для разделения их на две группы. Продавцы с более высокими продажами будут отнесены к первой группе (sale_ Performance_group = 1), а продавцы с более низкими продажами будут отнесены ко второй группе (sale_ Performance_group = 2). Внутри каждой даты продажи группируются независимо.
3. Общие сценарии применения
Оконные функции очень полезны во многих сценариях, вот несколько типичных примеров:
- Посчитайте совокупную сумму:использоватьSUM()функцияиOVER()пункт,Можно легко рассчитать совокупную сумму для каждой строки,Это полезно при анализе данных о продажах, финансовой отчетности и т. д.
- Рассчитать рейтинг:ROW_NUMBER()、RANK() и DENSE_RANK() и т. д. Функция может ранжировать набор результатов на основе значения определенного столбца. это на спортивных мероприятиях、Это очень распространено в таких сценариях, как рейтинг успеваемости учащихся.
- Рассчитать скользящее среднее:Указавокнообъем,Может Рассчитать скользящее среднее, что очень полезно для анализа данных временных рядов, цен на акции и т. д.
- Рассчитать разницу и процентное изменение:использоватьLAG()иLEAD()функция,Вы можете рассчитать разницу и процентное изменение между текущей строкой и предыдущей или следующей строкой.
4. Стратегия оптимизации
Хотя оконные функции являются мощными, производительность может стать проблемой при работе с большими объемами данных. Вот некоторые стратегии оптимизации:
- Уменьшите объем данных:в приложенииокнофункция До,По соответствующим фильтрам Уменьшите объем данные. Этого можно добиться с помощью предложения WHERE или подзапроса.
- Выберите подходящий размер окна:过大изокно Увеличит вычислительные затраты,Слишком маленькое окно может не обеспечить необходимую глубину анализа. Выберите подходящий размер окна в зависимости от ваших конкретных потребностей.
- Использовать индекс:Убедитесь, что столбцы, участвующие в запросе, проиндексированы правильно.,Это помогает ускорить процессы доступа к данным и вычислений.
- Избегайте вложенных оконных функций:Вложенныйокнофункция Может привести к усложнению запросов и снижению производительности.。нравитьсяесли возможно,Попробуйте разделить функцию вложенного окна на отдельные этапы запроса.
- Советы по оптимизатору запросов:в некоторых случаях,Вы можете использовать Советы по оптимизатору запросов, чтобы указать MySQL, как выполнять запрос. Но, пожалуйста, используйте его с осторожностью,Потому что неправильные подсказки могут привести к снижению производительности.
5. Резюме
Функция окна MySQL предоставляет мощные инструменты для анализа данных и создания отчетов. Благодаря глубокому пониманию его принципов и сценариев применения, а также принятию эффективных стратегий оптимизации можно полностью использовать преимущества окон при обработке и анализе данных. Поскольку объем данных продолжает расти, а потребности анализа становятся все более сложными, функция главного окна станет базой. данных Один из важных навыков разработчика и аналитика данных.
Навыки обновляются благодаря обмену ими, и каждый раз, когда я получаю новые знания, мое сердце переполняется радостью. Искренне приглашаем вас подписаться на публичный аккаунт 『
Код на тридцать пять』 , для получения дополнительной технической информации.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
