Подробное понимание Transformer в одной статье
1. Введение
«Внимание — это все, что вам нужно» — это основополагающая статья, опубликованная в 2017 году, в которой впервые была представлена модель Трансформера.
Эта статья полностью изменила направление исследований в области обработки естественного языка (НЛП) и заложила основу для многих последующих моделей и приложений НЛП. Знакомый нам ChatGPT также основан на представленном сегодня Transformer.
2. 5 основных конструкций
Основные концепции проектирования модели Трансформера можно резюмировать следующим образом:
1. Механизм самовнимания
- основные понятия:TransformerМодель Основа – самостоятельная Уведомлениесиловой механизм,Это позволяет модели при работе с такими последовательностями, как текст,Вычислить корреляцию между каждым элементом последовательности и другими элементами последовательности.。Этот механизм позволяет модели фиксировать зависимости на больших расстояниях внутри последовательности.。
- Преимущества:По сравнению с предыдущимRNNиLSTM,с Уведомлениесиловой механизм能够在параллельная обработкаЭффективно обрабатывать зависимости на больших расстоянияхвопрос,Значительно улучшена скорость и эффективность обработки.
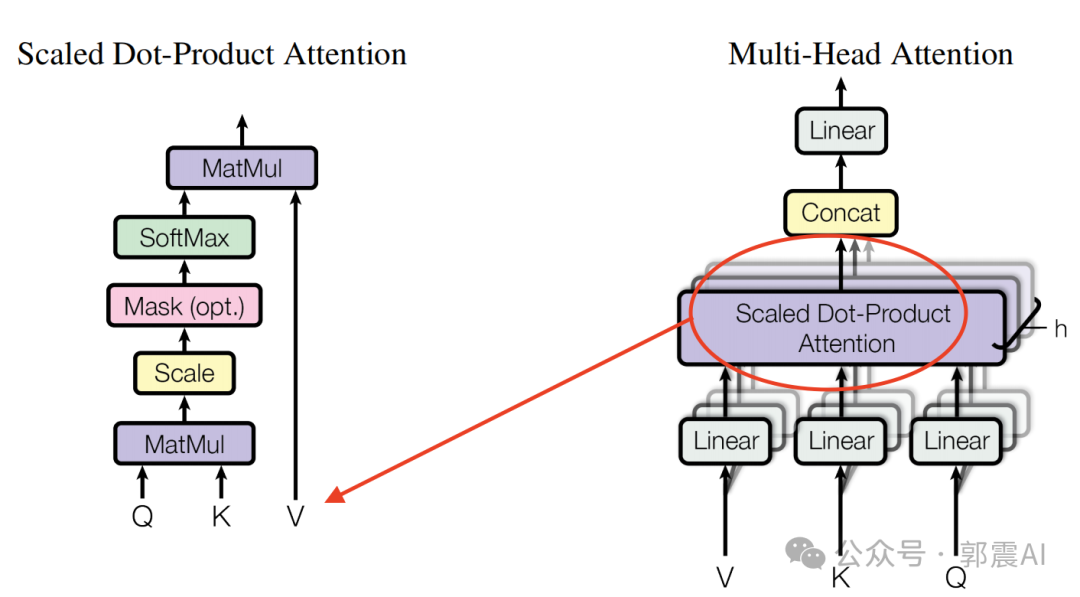
2. Многоголовое внимание
- дизайн:在с Уведомлениена основе силы,Transformerпредставилбычье вниманиемеханизм,добавив Уведомлениесиловой механизм“Расколоть”становитьсяНесколько головок, работающих параллельно,Модель Можно получить изРазличное обучение подпространствуинформация。
- Цель:Этот виддизайнделать Модель Способность лучше понимать множество сложных языковых взаимосвязей.,Например, отношения между синонимами и антонимами, грамматические и семантические отношения и т. д.
3. Позиционное кодирование
- вопрос:потому чтоTransformerПолностью основан на Уведомлениесиловой механизм,Отсутствие информации о положении последовательности.
- решение:Добавляя позицию к каждому элементу входной последовательностикодирование,Модель может использовать эту информацию, чтобы понять позиционные отношения слов в предложениях. Позиция кодирование дополняется словом embedding.,для сохранения информации о местоположении.
4. Архитектура кодировщика-декодера.
- Архитектура:TransformerМодель Включатькодирование器и解码器两部分。кодированиепроцессор используется для обработки входной последовательности,Декодер генерирует целевую последовательность на основе выходных данных кодирующего декодера и предыдущего выходного сигнала.
- Функции:каждыйкодирование器и解码器层都Включатьбычье Механизм внимания и нейронная сеть прямого распространения, автор остаточное соединениеинормализация слой для оптимизации тренировочного процесса.
5. Масштабируемость и эффективность
- параллельная обработка:иRNNиLSTMравный порядок Модельпо сравнению с,Механизм самосилы трансформера позволяет трансформировать всю последовательность,Значительно повышает скорость обучения и вывода.
- Область применения:TransformerМодель Применимо не только кNLPЗадача,также был распространен на другие области,Например, компьютерное зрение, обработка звука и т. д.
3. 3 вектора Q K V
Далее поймите три основных вектора QKV внимания к себе:
Запрос
- QueryПредставляет текущее слово или позицию,находится в центре внимания Модели при попытке лучше понять кодирование. В механизме самосилы,Каждое слово генерирует вектор запроса,Используется для сопоставления ключевого вектора других слов.
Ключ
- Keyи序列середина的каждый单词或位置相关联。它использовать于иqueryСделать матч,определить важность или «силу» каждого слова по отношению к текущему слову. по сути,keyвекторпомощь Модельпонимаю, что это должно"сосредоточиться на" какие части последовательности.
Ценить
- Value也и序列середина的каждый单词或位置相关联。Однажды на основеqueryиkeyСоответствие Уведомлениедоля силы,Эти оценки будут использоваться для взвешивания соответствующего вектора значений. это означает,Вес, присвоенный значению каждого слова, зависит от его важности по отношению к текущему фокусному слову.
Принцип работы
- При обработке слова (или точки запроса),TransformerModel использует вектор запроса слова для выполнения операции скалярного произведения с ключевым вектором всех других слов.,Используйте это для расчета показателя силы Уведомления. Этот балл определяет, какое влияние вектор значений каждого слова оказывает на кодирование текущего слова.
- Затем,Эти показатели силы Уведомления будут нормализованы (через softmax).,И используется для взвешивания valuevector. Суммируя все взвешенные значениявектор,Модель способна генерировать взвешенное представление текущего слова.,Это представление учитывает контекстную информацию на протяжении всей последовательности.
- В конечном счете, процесс для Модель обеспечивает динамический, основанный на содержании подход к решению того, что следует делать при обработке каждой части последовательности. на"Какая информация.
Вычисляет слово «сидел» в предложении «Кот сидел на коврике». Для простоты мы предполагаем, что после некоторого метода внедрения вектор внедрения каждого слова равен:
- "The" -> [1, 0]
- "cat" -> [0, 1]
- "sat" -> [1, 1]
- "on" -> [0, 0]
- "the" -> [1, 0]
- "mat" -> [1, -1]
Уведомление:для Демо Цель,Здесь мы предполагаем, что вектор Query(Q), Key(K) и Value(V) эквивалентен самому встраиванию слова.,И в настоящей модели Трансформера,Q, K и V получаются путем умножения вложений слов на разные весовые матрицы.
Шаг 1. Рассчитайте скалярное произведение слова «сб» и ключевых векторов всех слов.
- счет("сб", "The") = точка([1, 1], [1, 0]) = 1
- счет("сб", "кот") = точка([1, 1], [0, 1]) = 1
- счет("сб", "сб") = точка([1, 1], [1, 1]) = 2
- счет("сб", "вкл") = точка([1, 1], [0, 0]) = 0
- счет("сб", "the") = точка([1, 1], [1, 0]) = 1
- счет("сб", "мат") = точка([1, 1], [1, -1]) = 0
Шаг 2. Примените Softmax для нормализации оценок.
Предполагая, что оценка нормализована функцией Softmax (для упрощения расчета процесс расчета Softmax здесь не показан), полученный вес (предполагаемое значение) равен:
- для "The" -> 0.11
- для "кота" -> 0.11
- для "сидел" -> 0.33
- для "включено" -> 0.11
- для "этого" -> 0.11
- для "мата" -> 0.11
Шаг 3. Рассчитайте сумму вектора взвешенных значений.
На основе весов, полученных выше, мы теперь вычисляем взвешенную сумму векторов значений (в данном случае вектор значений и вектор ключей совпадают):
- Взвешенная сумма = 0,11 * [1, 0] (В) + 0,11 * [0, 1] (кошка) + 0,33 * [1, 1] (сб) + 0,11 * [0, 0] (вкл) + 0,11 * [ 1, 0] (мат) + 0,11 * [1, -1] (мат)
Чтобы выполнить расчет:
- Взвешенная сумма = [0,11, 0] + [0, 0,11] + [0,33, 0,33] + [0, 0] + [0,11, 0] + [0,11, -0,11]
- Взвешенная сумма = [0,66, 0,33]
Анализ результатов
Вектор взвешенной суммы [0,66, 0,33] представляет собой новое представление слова «сат» после учета «внимания» других слов. Этот вектор фиксирует в предложении информацию, наиболее соответствующую слову «сидел». В этом упрощенном примере слово «сат» само по себе имеет наибольший вес, что имеет смысл, поскольку в механизме самообслуживания слово, обрабатываемое в данный момент, имеет тенденцию вносить наибольший вклад в свое собственное представление.
Обратите внимание, что этот пример очень упрощен. Фактически в модели Трансформера размерность встраивания слова будет больше (например, 512 измерений), а векторы Q, K, V получаются путем умножения встраивания слова на. разные весовые матрицы. Кроме того, для дальнейшего расширения возможностей модели будет применен механизм внимания с несколькими головками.
В модели Transformer вектор взвешенной суммы, рассчитанный с помощью механизма самообслуживания, например [0,66, 0,33] в нашем примере, будет использоваться в качестве входных данных следующего слоя или следующего шага обработки. В частности, этот вектор пройдет следующие этапы:
- остаточное соединение:первый,этотвзвешенная объемвектор будет сравниваться с исходным входным вектором (в нашем случае это вставка «sat» [1, 1]) складываем. Эта операция называется форостаточное. соединение(Residual Connection), что помогает предотвратить исчезновение градиента в глубоких сетевыхвопросах.
- нормализация слоя:остаточное Результаты соединения затем проходят нормализацию. слоя(Layer Нормализация)шаг для стабилизации тренировочного процесса.
- сеть прямой связи:затем,этотвекторбудет отправлен всеть прямой связи(Feed-forward Network) эта сеть применяет одну и ту же операцию к каждому местоположению, но она не зависит от других местоположений. Эта сеть прямой связи обычно содержит два линейных преобразования и функцию активации ReLU.
- выход:сеть прямой Выход связи может быть отправлен в механизм самопринуждения следующего уровня (если он есть), чтобы служить входом для следующего уровня для. В TransformerModel этот процесс повторяется несколько раз, и каждый слой вычисляет новую взвешенную величину на основе результата предыдущего слоя. суммавектор。
- финальныйвыход:после последнего слоя,Могут быть дополнительные операции,Например, дополнительная нормализация слоев, линейные слои и т. д.,Конечный результат, в результате которого получается Модель. В последовательных задачах,например машинный перевод,Этот выходной сигнал будет отправлен в часть декодера или напрямую использован для генерации результатов прогнозирования.
Следовательно, на следующей итерации (т. е. на следующем уровне обработки) вектор взвешенной суммы [0,66, 0,33] пройдет серию преобразований, таких как остаточное соединение, нормализация уровня и сеть прямой связи, а затем может стать следующим уровень ввода самовнимания в механизм. Это одна из основных конструкций архитектуры Transformer. Таким образом, модель способна последовательно собирать и интегрировать информацию, а также понимать и обрабатывать текст на глубоком уровне.
4. Реализуйте Трансформер с нуля.
Существует множество способов реализации механизма принудительного Уведомления в PyTorch.,Вот базовый пример реализации самообслуживания.с Уведомлениесила этоTransformerсетьсерединаделатьиспользовать的一种Уведомлениесиловая форма,Это позволяет Модели взвешивать совокупную информацию между различными позициями в последовательности.
Ниже приведена реализация простого класса самообслуживания:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Einsum does matrix multiplication for query*keys for each training example
# with each head
attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
attention = attention.masked_fill(mask == 0, float("-1e20"))
attention = F.softmax(attention / (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhqk,nvhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
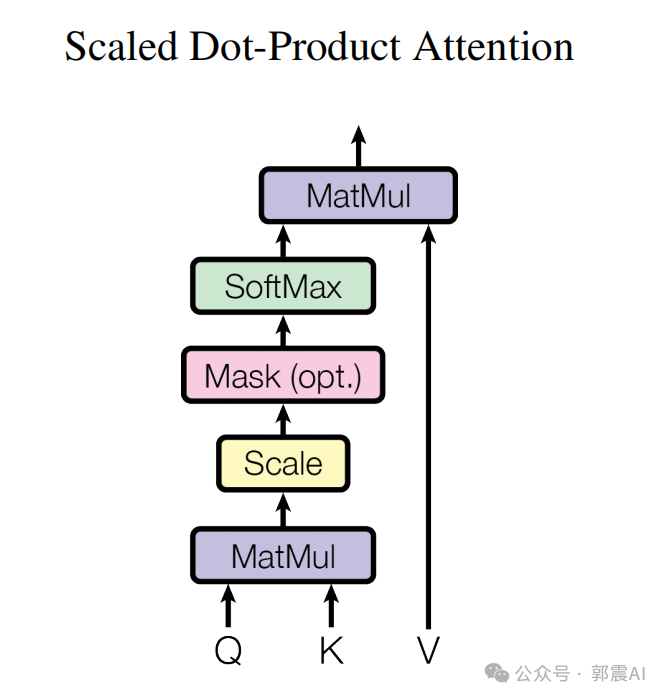
Этот код реализует простой механизм самообслуживания с несколькими головками, который включает в себя следующие шаги:
- Инициализируйте линейные слои для преобразования входных значений, ключей и запросов.
- При прямом распространении входные значения, ключи и запросы передаются через соответствующие линейные уровни.
- делатьиспользовать
einsumВыполнить умножение матрицы,для расчета показателя силы Уведомления между запросом и ключом. - При желании можно применить маску, чтобы избежать определенных позиций в рейтинге силы Уведомления.
- Примените функцию softmax, чтобы получить веса сил Уведомления.
- использовать
einsumВоля Уведомление力权重应использовать于值,Получите взвешенное значение. - Наконец, передайте результат через другой линейный слой для возможного изменения размера. Класс SelfAttention в приведенном выше коде реализует следующий процесс:
Чтобы использовать описанный выше механизм самообслуживания, вам необходимо интегрировать его в модель нейронной сети. Вот пример использования модуля самообслуживания в простой задаче обработки последовательности:
import torch
import torch.nn as nn
# Предположим, у нас есть слой внедрения определенного размера и слой силы самоуведомления.
embed_size = 256
heads = 8
sequence_length = 100 # Введите длину последовательности
batch_size = 32
vocab_size = 10000 # Предполагаемый размер словарного запаса
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, 2 * embed_size),
nn.ReLU(),
nn.Linear(2 * embed_size, embed_size)
)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.norm1(attention + query)
forward = self.feed_forward(x)
out = self.norm2(forward + x)
return out
class Transformer(nn.Module):
def __init__(self, embed_size, heads, vocab_size, sequence_length):
super(Transformer, self).__init__()
self.word_embedding = nn.Embedding(vocab_size, embed_size)
self.position_embedding = nn.Embedding(sequence_length, embed_size)
self.layers = nn.ModuleList([TransformerBlock(embed_size, heads) for _ in range(6)])
self.fc_out = nn.Linear(embed_size, vocab_size)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(x.device)
out = self.word_embedding(x) + self.position_embedding(positions)
for layer in self.layers:
out = layer(out, out, out, mask)
out = self.fc_out(out)
return out
# Создайте экземпляр модели
model = Transformer(embed_size, heads, vocab_size, sequence_length)
# Создайте случайную входную последовательность
input_seq = torch.randint(0, vocab_size, (batch_size, sequence_length))
# Создайте маску (в этом примере для None)
mask = None
# прямое распространение
output = model(input_seq, mask)
Класс TransformerBlock реализует следующий рисунок:
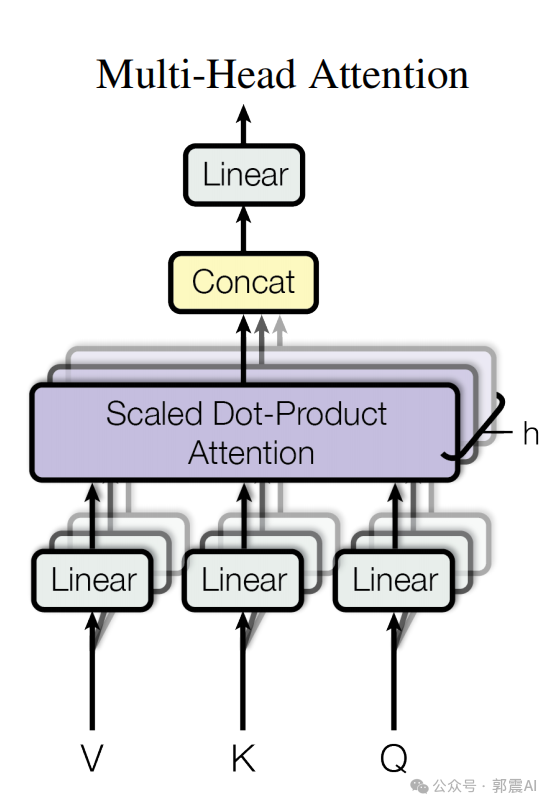
здесь,Transformer类实现了一индивидуальный Включать6индивидуальныйTransformerBlockуровень простотыTransformerМодель,TransformerBlockВключать了с Уведомлениесиловой слой(SelfAttentionсередина的多头с Уведомление Ли Чжун Длинна здесь равна головам для 8)и前馈神经сеть。Модель的输入是一индивидуальный整数序列,Эти целые числа представляют собой индексы в словаре.,ЗатемМодельвыход последовательности одинаковой длины,где каждый элемент представляет собой соответствующий вектор размера словаря,представляет собой распределение вероятностей。
mask Этот параметр является необязательным и может использоваться для маскировки определенных частей последовательности, что полезно, например, при работе с входными данными переменной длины или при предотвращении просмотра модели будущей информации при декодировании.
в практическом применении,Необходимо настроить структуру Модели и гиперпараметры в соответствии с конкретной задачей.,напримерразмер встраивания слова、Уведомление количества силовых головок、длина последовательностиждать,и, возможно, потребуется добавить дополнительные слои и функции.,Такие как слой встраивания слов, уровень встраивания позиции и финальный выходной слой. также,Вам также необходимо подготовить данные для обучения.,Определить функцию потерь и оптимизатор,и выполнить цикл обучения.
5. Анализ результатов
финальныйвыходформа(32, 100, 10000), значение поясняется ниже:
Предположим, мы используем TransformerModel для задачи генерации текста. Задача Модели основана на приведенном выше,Создайте продолжение истории. Обрабатываем 32 сюжетных сегмента одновременно (т.е. размер партии для32),Длина целевой генерации для 100 слов на сегмент,Модель может выбрать слово для каждой позиции из словаря в 10 000 слов.
выходформа(32, 100, 10000)значение
- 32:Это размер партии。значит за один разпрямое распространениесередина,Модель одновременно обрабатывает 32 различных сегмента истории.
- 100:这是каждый故事片段的生становиться长度,То есть каждый сегмент истории содержит 100 слов.
- 10000:Это размер словарного запаса,Средство Модель может выбрать слово для каждой позиции из 10000 разных слов.
Как использовать вывод
- Для каждого фрагмента истории в пакете,Модель имеет вектор распределения вероятностей длиной 10000 в каждой позиции слова. Каждый элемент в этом векторе представляет вероятность того, что соответствующее слово в словаре будет выбрано в качестве слова в этой позиции.
- По слову с наибольшей вероятностью или другой стратегии выборки,Модель Выберите следующее слово. например,К предложению «Однажды в далеком королевстве жил-был…»,
Теперь модели необходимо сгенерировать распределение вероятностей для следующей позиции слова.
Гипотетическое распределение вероятностей
Когда Модель рассматривает следующее слово, предполагая, что оно соответствует следующим параметрам, генерирует распределение вероятностей:
- "prince": 0.6
- "dragon": 0.2
- "castle": 0.1
- "magic": 0.05
- "forest": 0.05
- ...(распределение вероятностей по оставшимся словам)
В этом Гипотетическом распределение В вероятностях «принц» получил самую высокую вероятность (0,6), что указывает на то, что согласно предсказанию Модели и текущему контексту «принц» является преемником «... there lived Наиболее вероятное слово после а».
на основе распределения вероятностей,Следующим словом для слова модель выберет «принц».,Потому что для оно имеет наибольшее значение вероятности (0,6). Это означает, что Модель распознает,в данном контексте,«Князь» — самое подходящее слово для продолжения этой истории.
Поэтому фрагмент рассказа обновлен для: «Однажды в далеком королевстве жил-был принц…».
Допустим, первый фрагмент истории в пакете в данный момент имеет текст «Однажды upon a time, in a faraway kingdom, there lived a ...”,Модель должна выбрать следующее лучшее слово. Распределение вероятностей текущего местоположения Моделидля может быть сильно смещено в сторону слова «принц».,Поэтому в качестве следующего слова для выбрано «принц». Этот процесс повторяется для каждого места и для каждого сегмента истории в пакете.,Пока не будет создан полный фрагмент истории.
финальныйвыходформа(32, 100, 10000)точно отражает Модель在文本生становиться Задачасередина的能力,т.е. параллельная обработка нескольких фрагментов текста,для Распределение вероятностей сгенерированных слов в каждой позиции каждого сегмента,И соответственно подбирайте слова, чтобы построить связный текст. Суть этого метода заключается в том, что модель Transformer может эффективно улавливать зависимости на больших расстояниях с помощью механизма самопринуждения.,и выполнять точную генерацию текста на основе заданного контекста.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
