Подробное объяснение PySpark (5) RDD для больших данных Python
Подробное объяснение СДР
Зачем вам нужен РДД?
- Прежде всего, Spark предлагался для решения задач MR-вычислений, таких как итеративные вычисления, такие как машинное обучение или графовые вычисления.
- Есть надежда, что можно будет предложить итеративную структуру данных на основе памяти и ввести эластичный распределенный набор данных RDD.
- Почему RDD отказоустойчив?
- RDD зависит от отношений зависимости
- reduceByKeyRDD-----mapRDD-----flatMapRDD
- Кроме того, многие механизмы, такие как кэширование, широковещательные переменные и механизмы контрольных точек, решают проблемы отказоустойчивости.
- Почему RDD может выполнять вычисления в памяти?
- Сама конструкция RDD основана на итеративных вычислениях в памяти.
- RDD — это абстрактная структура данных.
Что такое РДД?
- Эластичный распределенный набор данных RDD
- Эластичность: может храниться в памяти или на диске.
- Распределенное: распределенное хранилище (разделение) и распределенные вычисления.
- данныенабор:данныеизнаборобъединить
определение СДР
- RDD — это неизменяемая, разделяемая и распараллеливаемая коллекция.
- Дважды нажмите клавишу Shift в pycharm, чтобы просмотреть исходный код, rdd.py.
- RDD предоставляет пять основных атрибутов
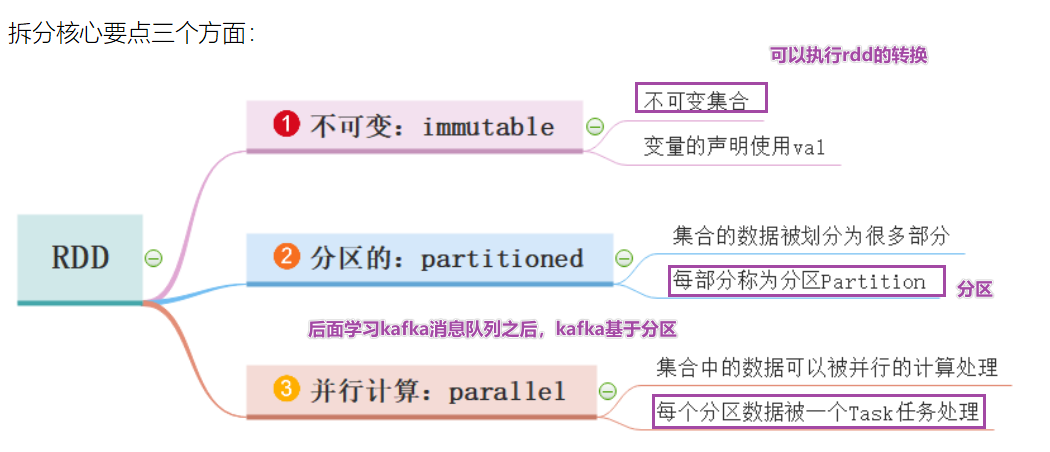
5 основных характеристик RDD
- Пять основных характеристик RDD:
- 1-RDD состоит из серии разделов, списка разделов.
- 2-Функция расчета
- 3-Зависимости, сокращение по ключу зависит от карты и плоской карты.
- 4-(Необязательно) Раздел ключ-значение,Для данных типа «ключ-значение» Разделом по умолчанию является HashРаздел.,Диапазон Раздел и т. д. можно изменить.
- 5-(Необязательно) Приоритет местоположения, мобильные компьютеры не требуют мобильного хранилища.

- 1-
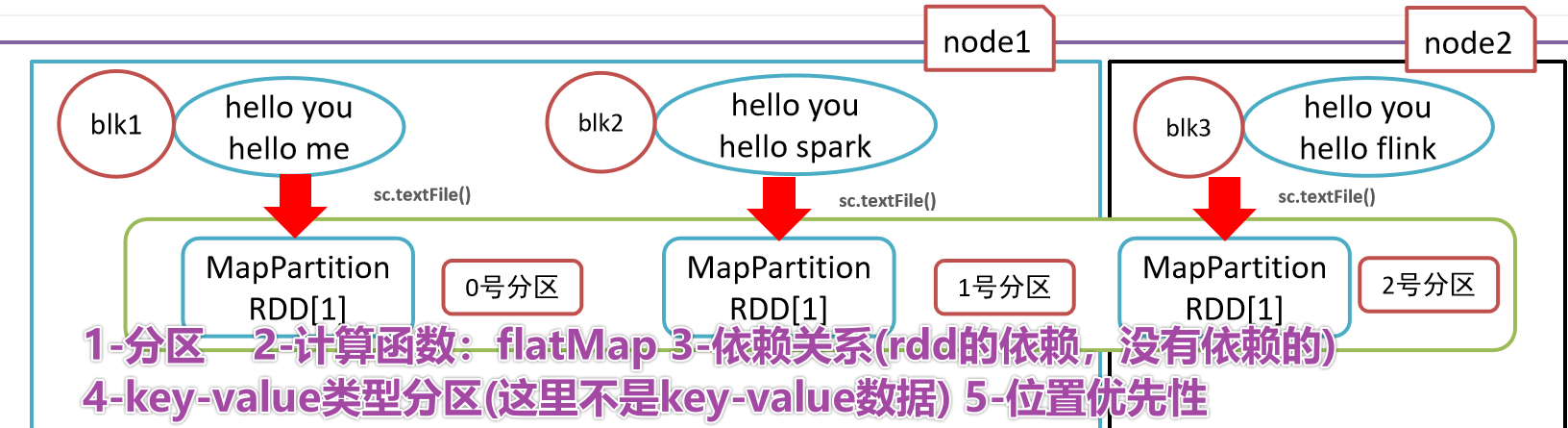
- 2-
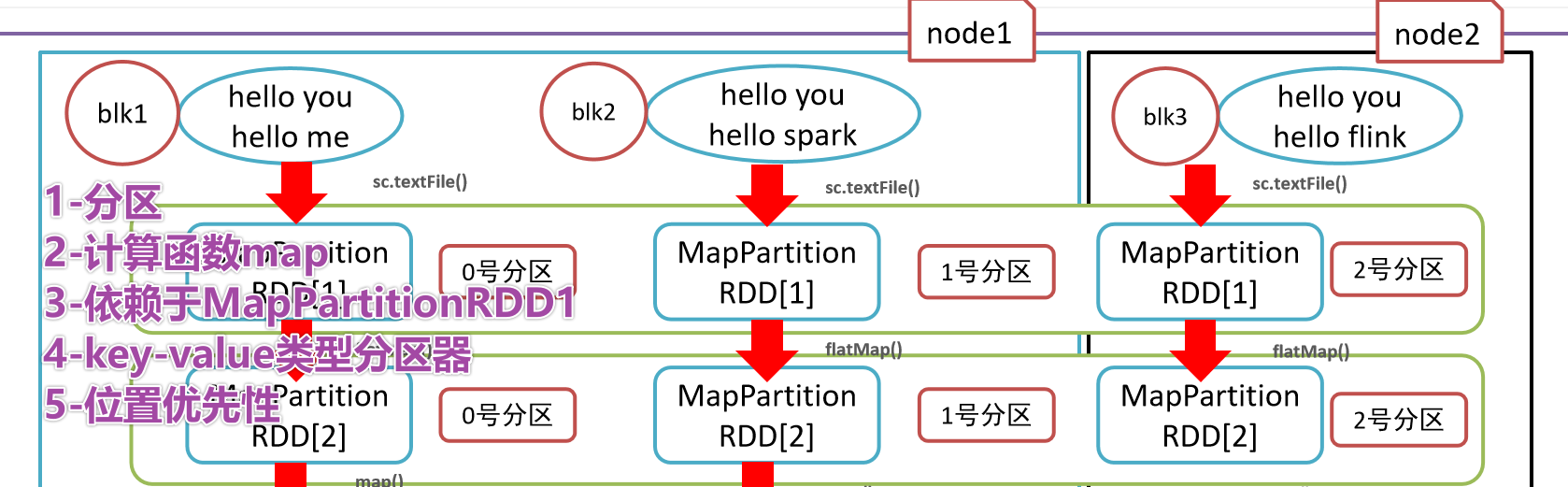
- 3-
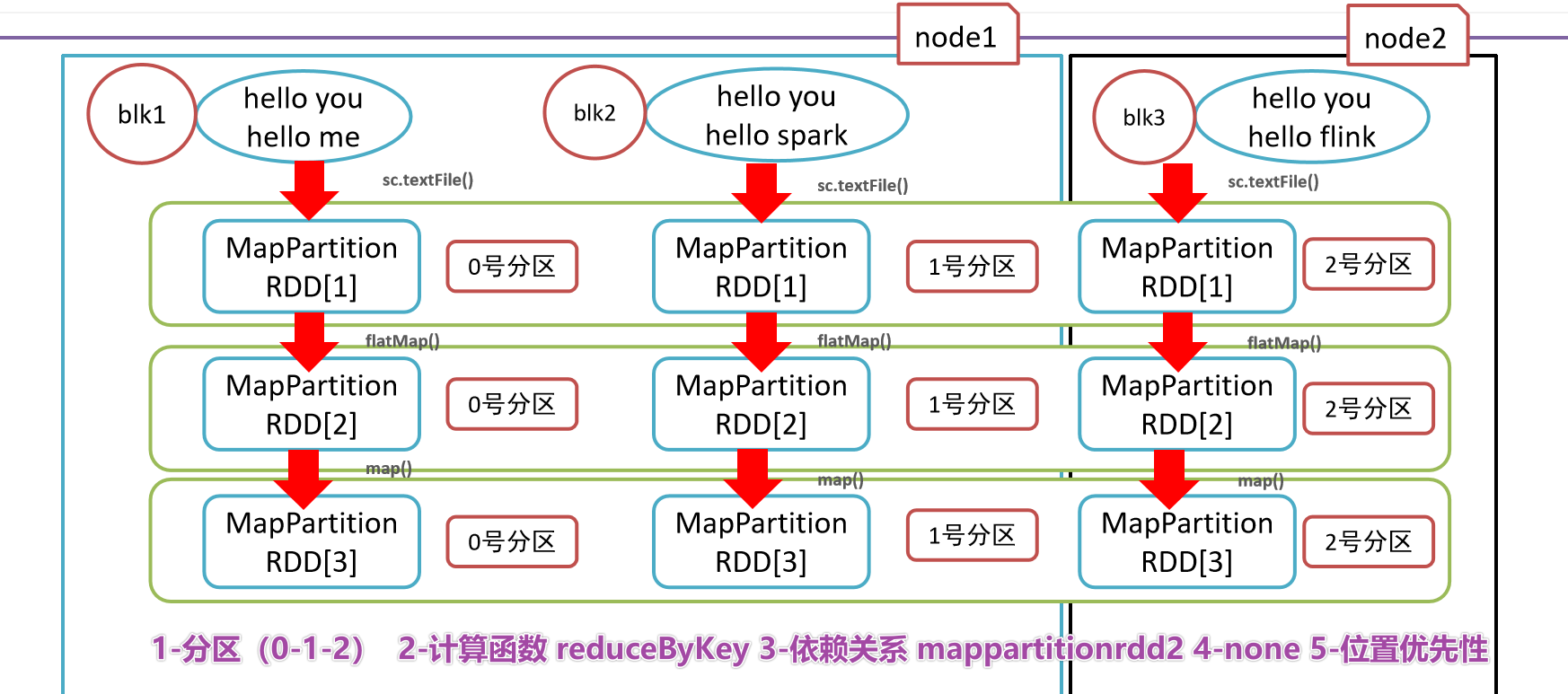
- 4-
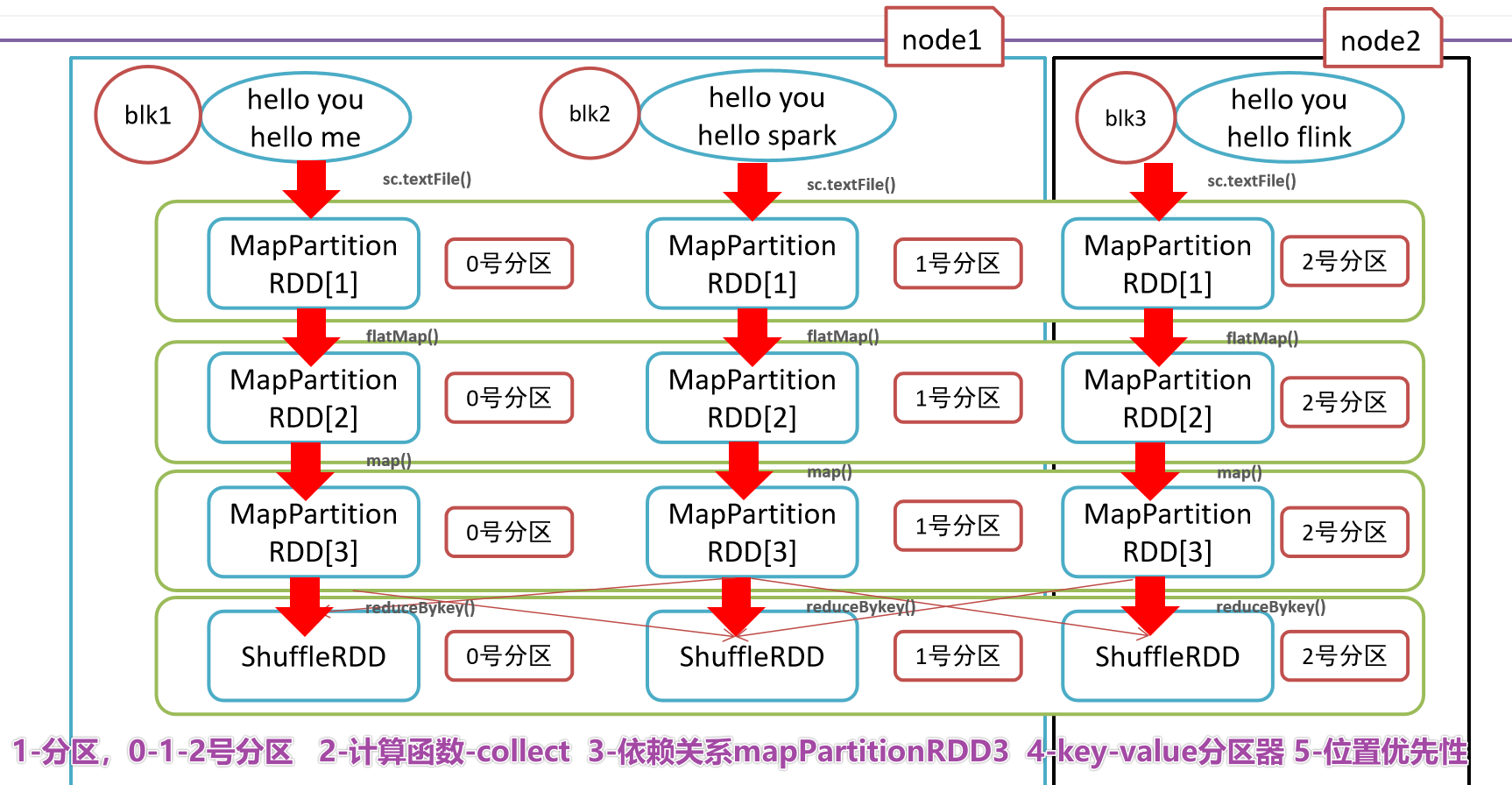
- 5-Заключительная иллюстрация
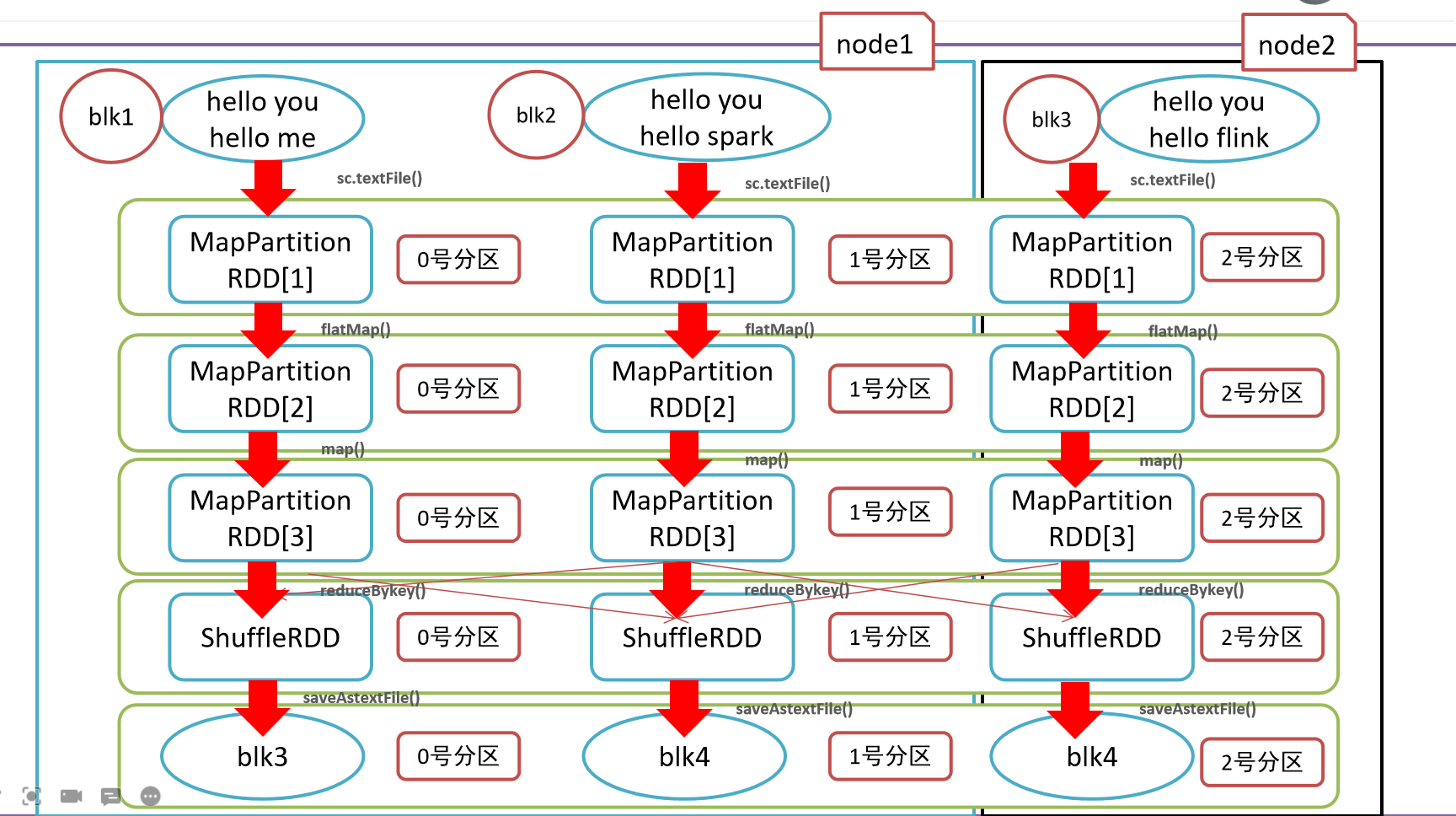
- Краткое изложение пяти основных атрибутов RDD
- 1-Список разделов
- 2-Функция расчета
- 3-Зависимости
- Разделитель с 4 ключами
- 5-позиционный приоритет
Функции RDD — память не требуется
- Раздел
- только чтение
- полагаться
- кэш
- checkpoint
СДР в WordCount
Создание РДД
Существует два способа создания РДД в PySpark.
Параллельное создание RDD rdd1=sc.paralleise([1,2,3,4,5])
Создать RDD из файла
rdd2=sc.textFile(“hdfs://node1:9820/pydata”)
Код:
# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
Первый способ: использование распараллеленных коллекций, по сути, передача локальной коллекции в качестве параметра в sc.pa.
Второй способ: используйте sc.textFile для чтения внешних файловых систем, включая hdfs и локальные файловые системы.
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2- Первый метод с использованием создания rdd
3-секундный метод с использованием создания rdd
4-Закрыть SparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[5]")
sc = SparkContext(conf=conf)
# 2 - Первый метод, созданный с использованием rdd
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6])
print(collection_rdd.collect()) # [1, 2, 3, 4, 5, 6]
# 2-1 Как использовать API, чтобы получить количество Разделов в rdd
print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) # 5
# 3 - Второй метод, созданный с использованием rdd
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt")
print(file_rdd.collect())
print("rdd numpartitions:{}".format(file_rdd.getNumPartitions())) # 2
# 4 - ЗакрытьSparkContext
sc.stop()Чтение небольшого файла
Создать RDD из внешних данных
- http://spark.apache.org/docs/latest/api/python/reference/pyspark.html#rdd-apis

# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2. Чтение внешних файлов с помощью методов sc.textFile и sc.wholeTextFile.
3-ЗакрытьSparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[5]")
sc = SparkContext(conf=conf)
# 2 - Для чтения внешних файлов используйте методы sc.textFile и sc.wholeTextFile\
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100")
wholefile_rdd = sc.wholeTextFiles("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100")
print("file_rdd numpartitions:{}".format(file_rdd.getNumPartitions()))#file_rdd numpartitions:100
print("wholefile_rdd numpartitions:{}".format(wholefile_rdd.getNumPartitions()))#wholefile_rdd numpartitions:2
print(wholefile_rdd.take(1))# путь, конкретное значение
# Как получить Wholefile_rdd, чтобы получить конкретное значение
print(type(wholefile_rdd))#<class 'pyspark.rdd.RDD'>
print(wholefile_rdd.map(lambda x: x[1]).take(1))
# 3 - ЗакрытьSparkContext
sc.stop()* Как просмотреть Раздел rdd? getNumPartitions()Расширенное чтение: Как определить количество разделов RDD
# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
Первый способ: использование распараллеленных коллекций, по сути, передача локальной коллекции в качестве параметра в sc.pa.
Второй способ: используйте sc.textFile для чтения внешних файловых систем, включая hdfs и локальные файловые системы.
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2- Первый метод с использованием создания rdd
3-секундный метод с использованием создания rdd
4-Закрыть SparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[*]")
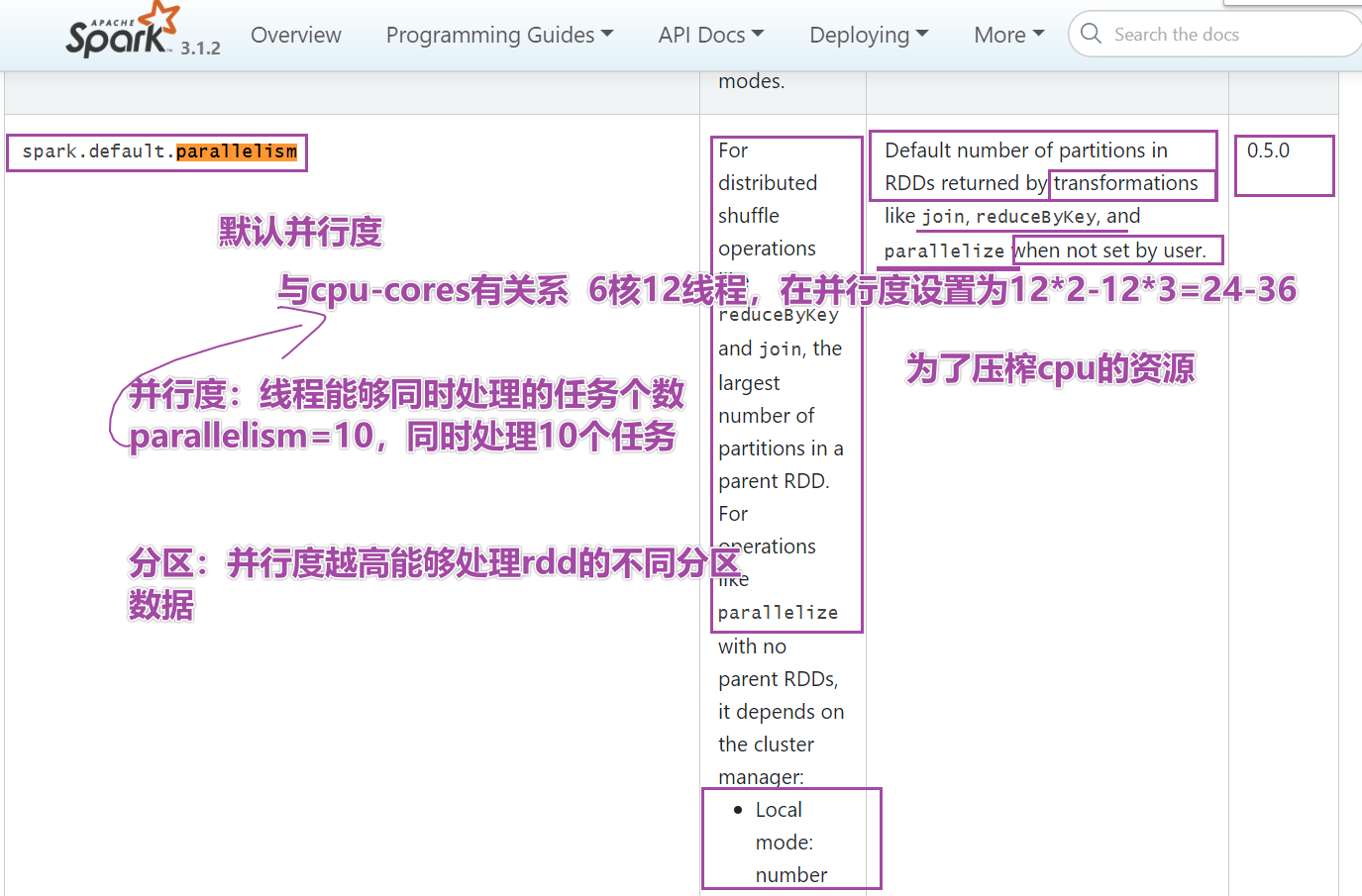
# conf.set("spark.default.parallelism",10)#Переписать степень параллелизма по умолчанию, 10
sc = SparkContext(conf=conf)
# 2 - Первый метод, созданный с использованием rdd,
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6],5)
# 2-1 Как использовать API, чтобы получить количество Разделов в rdd
print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) #2
# Резюме: Sparkconf устанавливает local[5] (степень параллелизма по умолчанию), sc.parallesise напрямую использует Раздел, и число равно 5.
# Если установлен spark.default.parallelism, степень параллелизма по умолчанию, sc.parallesise напрямую использует номер раздела, равный 10.
# Наивысший приоритет имеет второй параметр внутри функции. 3
# 2-2 Как распечатать содержимое каждого раздела
print("per partition content:",collection_rdd.glom().collect())
# 3 - Второй метод, созданный с использованием rdd
# minPartitions — это наименьшее количество разделов, а окончательное количество разделов основано на фактической печати.
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt",10)
print("rdd numpartitions:{}".format(file_rdd.getNumPartitions()))
print(" file_rdd per partition content:",file_rdd.glom().collect())
# Если sc.textFile читает несколько файлов в папке, количество Разделов здесь в основном зависит от количества файлов, и Раздел, написанный вами, не будет работать.
# file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100", 3)
# 4 - ЗакрытьSparkContext
sc.stop()* Сначала проясните ситуацию,Количество разделов,Здесь все основано на том, что вы видите,Особенно в sc.textFile

- Два важных API
- Номер раздела getNumberPartitions
- Разделить внутренний элемент glom().collect()
постскриптум
📢Домашняя страница блога:https://manor.blog.csdn.net
📢Лайки приветствуются 👍 собирать ⭐Оставьте сообщение 📝 Поправьте меня, если есть ошибки! 📢Эту статью написал Maynor Оригинал, впервые опубликовано на Блог CSDN🙉 📢Мне кажется,что самый ласковый и долгий взгляд в этой жизни отдан моему мобильному телефону⭐ 📢Колонка постоянно обновляется,Добро пожаловать на подписку:https://blog.csdn.net/xianyu120/category_12453356.html



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
