Подробное объяснение Латте: первое в мире видео Винсента с открытым исходным кодом DiT, выпущенное в конце прошлого года
Колонна «Машинное сердце»
Редакция «Машинное сердце»
После успешного выпуска Sora модель видео DiT привлекла много внимания и обсуждений. Проектирование стабильных и очень крупномасштабных нейронных сетей всегда было в центре внимания исследований в области генерации видения. Успех DiT [1] дает возможность масштабировать генерацию изображений.
Однако из-за высокоструктурированного и сложного характера видеоданных, как распространить DiT на область генерации видео, является непростой задачей. Исследовательская группа из Шанхайской лаборатории искусственного интеллекта объединилась с другими учреждениями, чтобы ответить на этот вопрос в масштабном масштабе. эксперименты.
Еще в ноябре прошлого года команда открыла исходный код самостоятельно разработанной модели, похожей на технологию Sora: Latte. Будучи первым в мире видео DiT Винсента с открытым исходным кодом, Latte привлек широкое внимание, а дизайн его модели используется и на него ссылаются многие платформы с открытым исходным кодом, такие как Open-Sora Plan (PKU) и Open-Sora (ColossalAI).

- Открытый исходный код Связь:https://github.com/Vchitect/Latte
- Домашняя страница проекта: https://maxin-cn.github.io/latte_project/
- Ссылка на документ: https://arxiv.org/pdf/2401.03048v1.pdf.
Давайте сначала посмотрим на эффект генерации видео Latte.

Введение метода
В целом Latte состоит из двух основных модулей: предварительно обученного VAE и видео DiT. Предварительно обученный кодер VAE сжимает видео из пространства пикселей в скрытое пространство кадр за кадром, видео DiT извлекает токены из неявного представления и выполняет пространственно-временное моделирование, и, наконец, декодер VAE отображает функции обратно в пространство пикселей для создания видео. . Чтобы получить оптимальное качество видео, автор сосредоточился на изучении двух важных аспектов дизайна Латте: (1) общей структуры модели видео DiT и (2) оптимального дизайна модели и деталей обучения (лучшие практики). .
(1) Исследование конструкции общей структуры модели Латте.
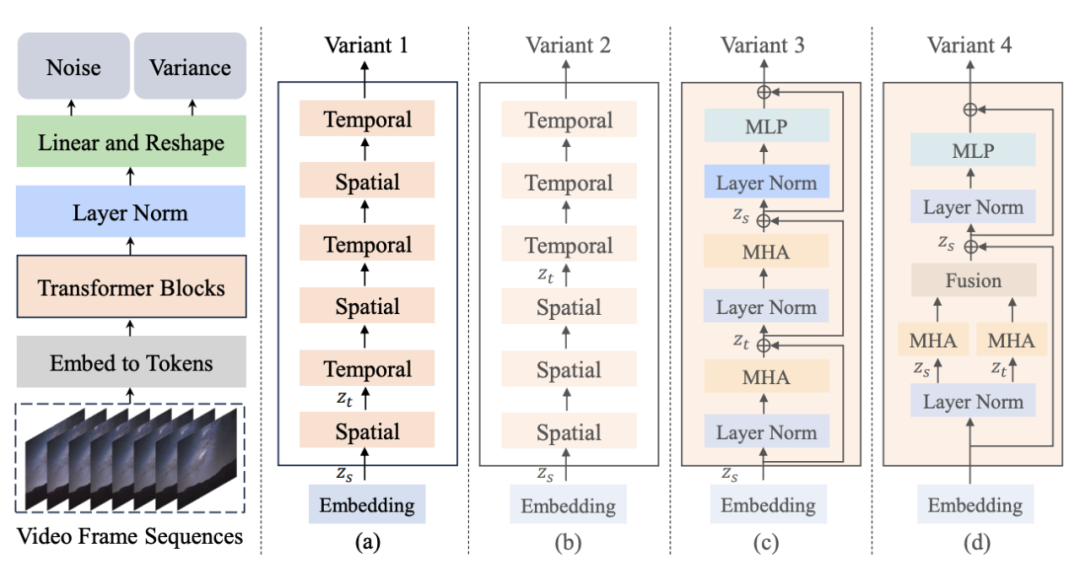
Рисунок 1. Структура модели Латте и ее варианты
Автор предложил 4 различных варианта Латте (рис. 1), разработал два модуля Трансформера с точки зрения пространственно-временного механизма внимания и изучил два варианта (Варианта) в каждом модуле:
1. Модуль механизма единого внимания,в каждом модулеСодержит только внимание времени или пространства.。
- Пространственно-временное моделирование с чередованием (Вариант 1): Модуль времени вставляется после каждого пространственного модуля.
- Пространственно-временное последовательное моделирование (Вариант 2): Модуль времени размещается целиком после модуля пространства.
2. Модуль механизма мультивнимания,в каждом модулеСодержит как временные, так и пространственные механизмы внимания (варианты, на которые ссылается Опен-сора).。
- Серийный пространственно-временной механизм внимания (Вариант 3): Серийное моделирование пространственно-временного механизма внимания.
- Параллельный пространственно-временной механизм внимания (вариант 4): параллельное моделирование и объединение функций пространственно-временного механизма внимания.
Эксперименты показывают (рис. 2), что при установке одинаковых значений параметров для четырех вариантов модели вариант 4 имеет значительную разницу в FLOPS по сравнению с тремя другими вариантами, поэтому он также имеет относительно высокий показатель FVD, а остальные три варианта имеют самый высокий FVD. Общая производительность аналогична, и вариант 1 обеспечивает лучшую производительность. Автор планирует провести более подробное обсуждение крупномасштабных данных в будущем.
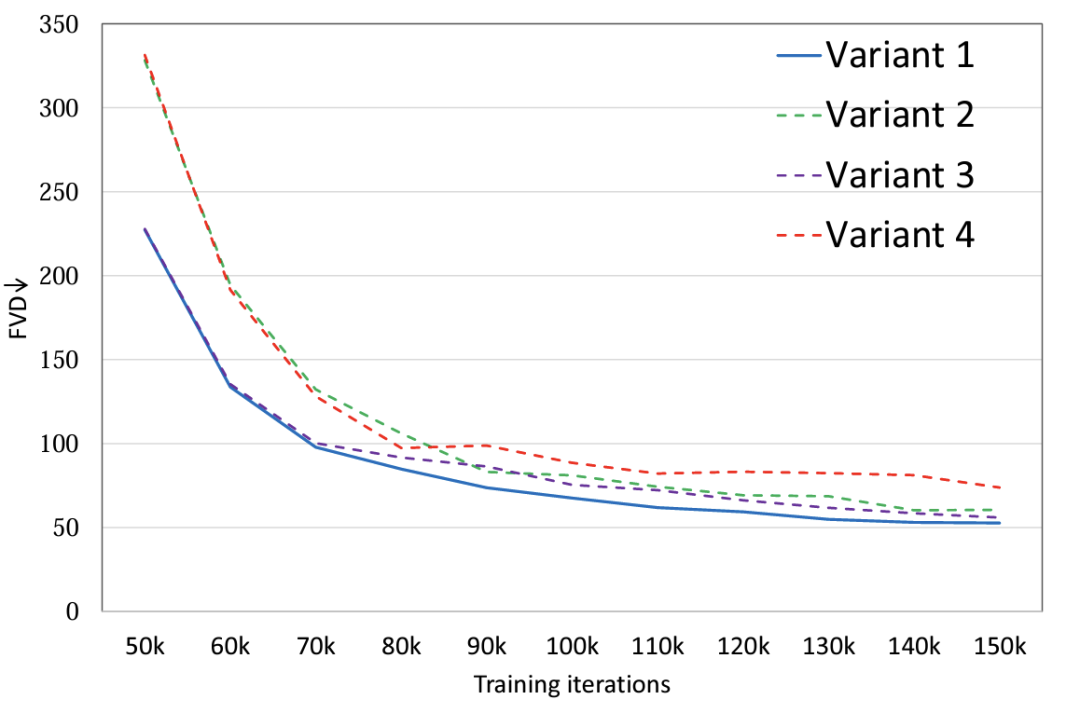
Рисунок 2. Структура модели FVD
(2) Исследование оптимального дизайна модели Латте и деталей обучения (лучшие практики)
Помимо общей структурной конструкции модели, автор также исследовал факторы, влияющие на эффект генерации в других моделях и обучении.
1.Извлечение токенов:исследовалодиночный кадр токен(а) и пространство-время Существует два способа токена (б). Первый сжимается только на пространственном уровне. токен, последний также сжимает время и пространствоинформация。Экспериментальный показодиночный кадр token лучше, чем время и пространство token(картина 4). и Sora Для сравнения автор догадывается Sora предлагаемое время и пространство token через видео VAE Осуществляется предварительное сжатие во временном измерении, а в скрытом пространстве Latte Конструкции аналогичны и используют только одну рамку. token обработка.
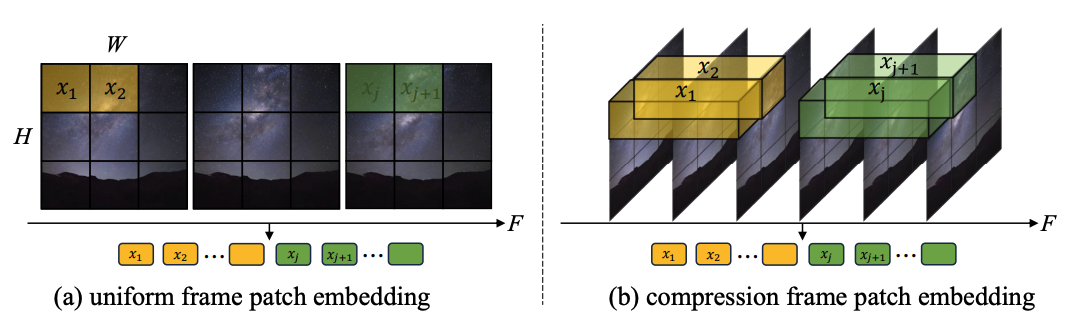
Рисунок 3. Метод извлечения токена: (a) однокадровый токен и (b) пространственно-временной токен
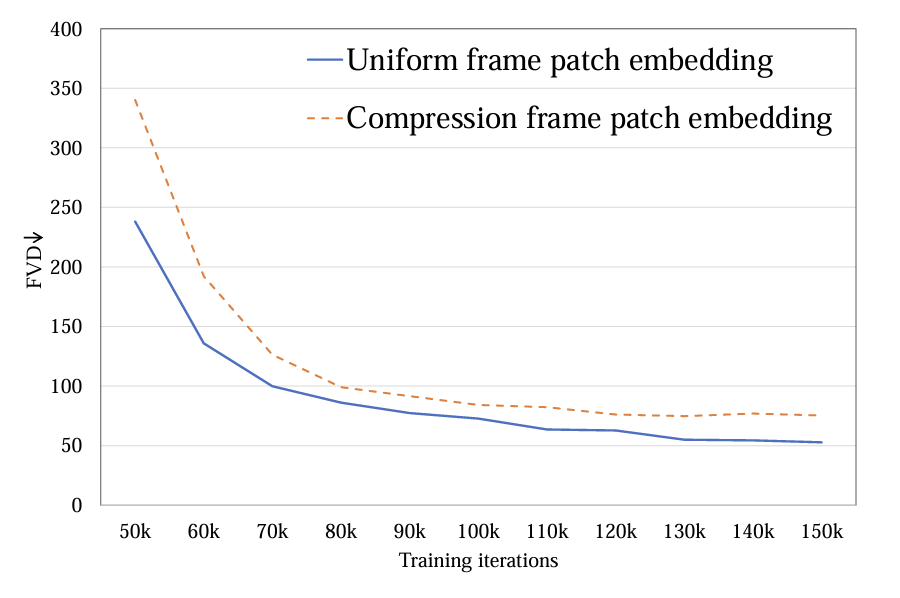
Рисунок 4. Извлечение токена FVD
2. Режим условного впрыска:исследовал(a)S-AdaLN и (б) все tokens два пути (картина 5)。S-AdaLN проходить MLP Преобразуйте условную информацию в переменные при нормализации и внедрите их в модель. Все token Форма преобразует все условия в единое целое. token как Модельвход。Экспериментальное доказательство,S-AdaLN путь по сравнению с all token Более эффективен для получения качественных результатов (картина 6). Причина в том, что S-AdaLN Информацию можно вводить непосредственно в каждый модуль. и all token Условную информацию необходимо передавать слой за слоем от входа до конца, и в процессе потока информации возникают потери.
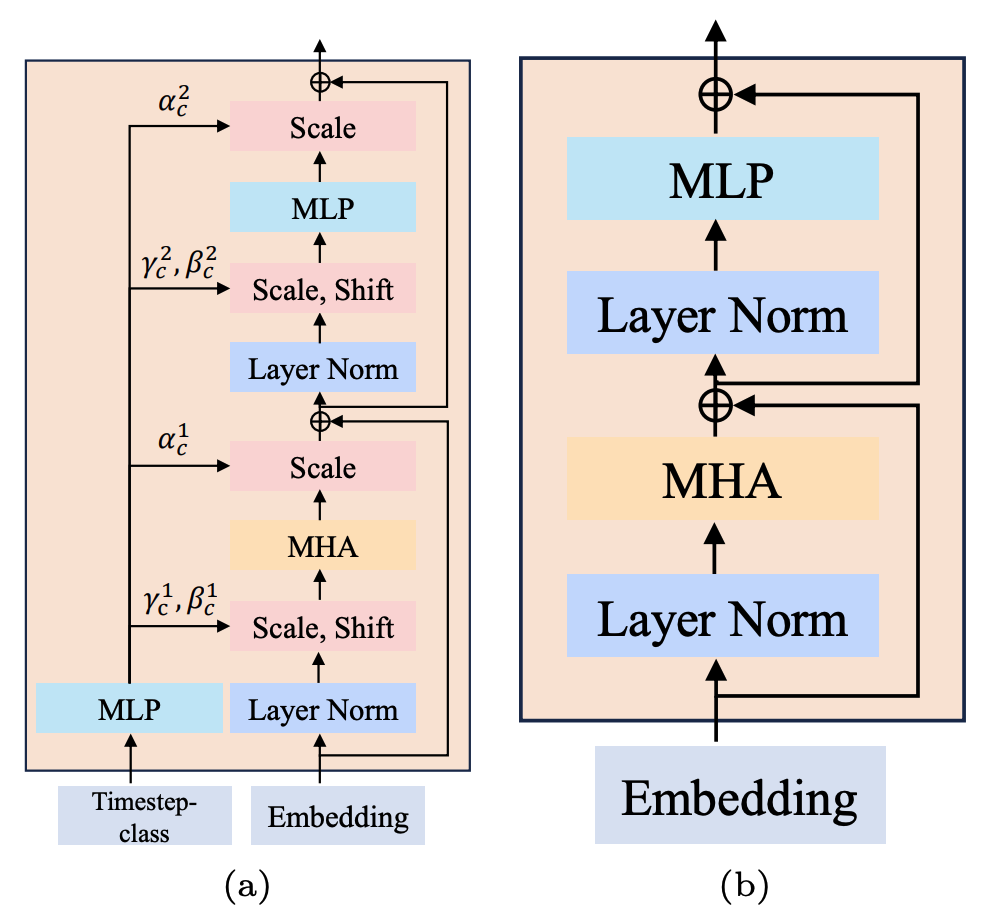
Рисунок 5. (а) S-AdaLN и (б) все токены.
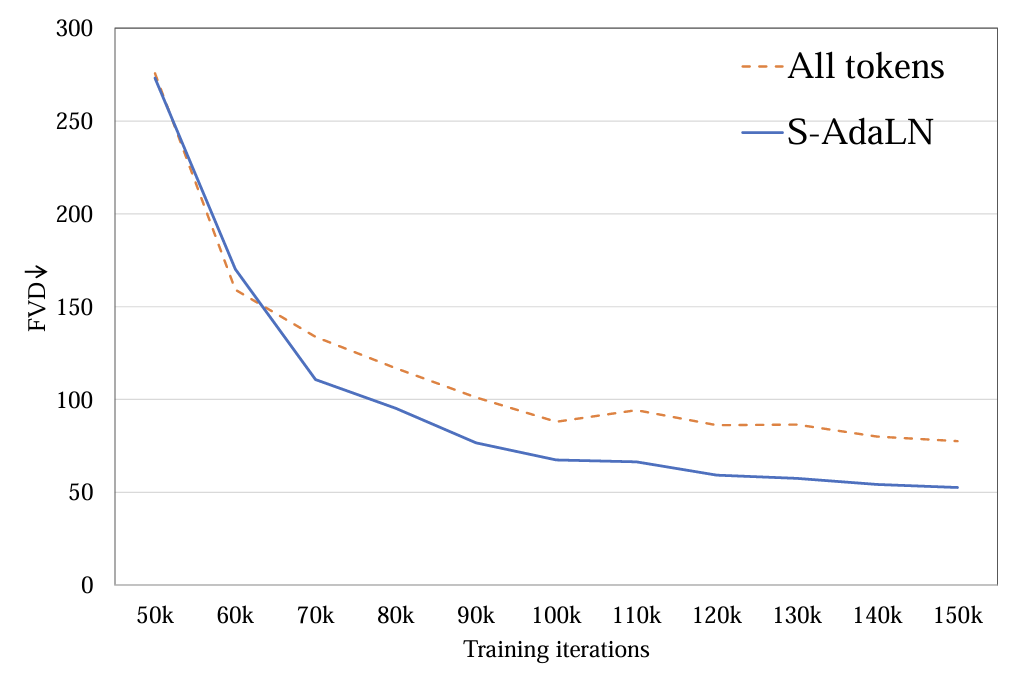
Рисунок 6. Метод условного впрыска FVD
3. пространственно-временное кодирование местоположения:исследовал绝对位置кодированиеиотносительное положениекодирование。Различные позиционные кодировки мало влияют на конечное качество видео. (картина 7). Из-за небольшой продолжительности генерации разница в кодировании позиции недостаточна, чтобы повлиять на качество видео. При длительной генерации видео этот фактор необходимо пересмотреть.
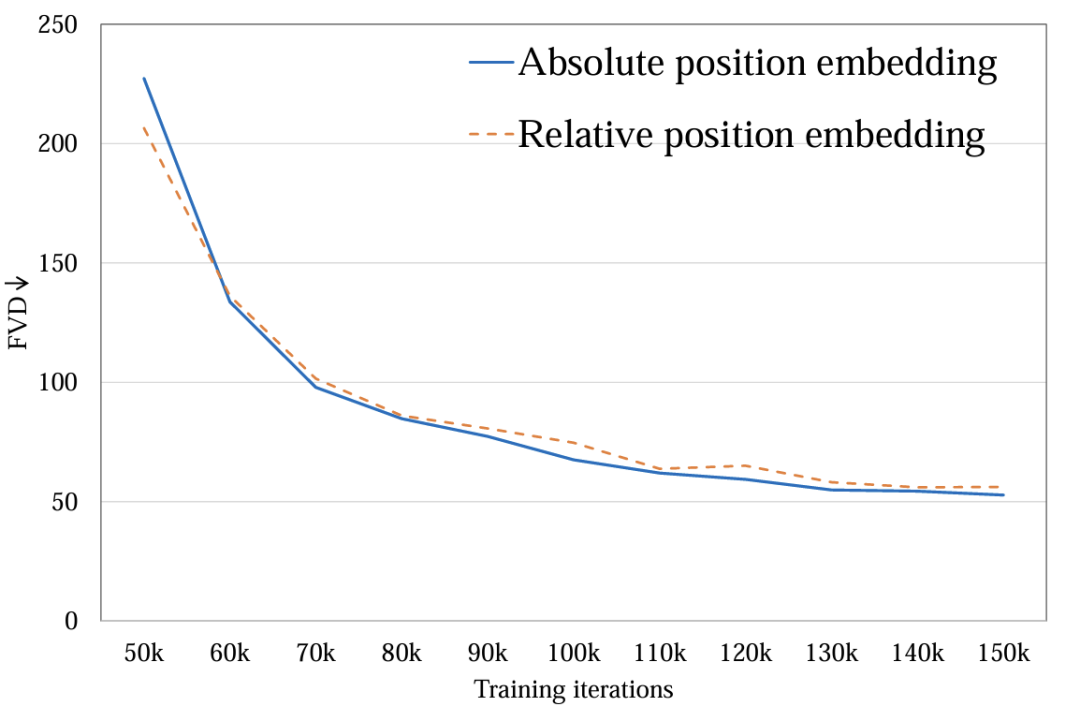
Рисунок 7. Метод кодирования позиции FVD
4. Инициализация модели:Исследоватьиспользовать ImageNet Влияние инициализации параметров перед обучением на производительность модели. Эксперименты показывают,использовать ImageNet Инициализированная модель имела более высокую скорость сходимости, однако по мере обучения случайно инициализированная модель добилась лучших результатов. (картина 8). Возможная причина в том, что ImageNet с обучающим набором FaceForensics Существует относительно большая разница в распределении, поэтому она не способствует достижению окончательных результатов модели. Для задачи видео Винсента этот вывод необходимо пересмотреть. При распределении общих наборов данных пространственное распределение контента изображений и видео аналогично, с использованием предварительного обучения. T2I модель для T2V Может сыграть большую роль в продвижении.
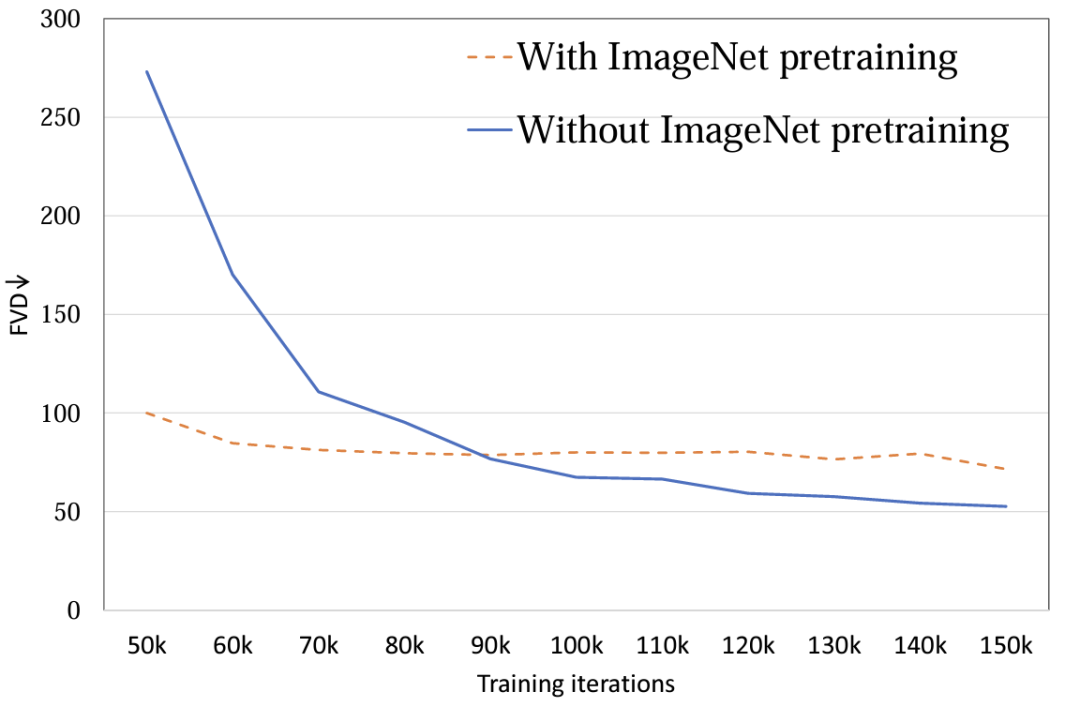
Рисунок 8. Параметр инициализации FVD
5. Фото и видео совместной тренировки:Волявидеоикартина像压缩为统一 token Проведение совместных тренировок, видео token Отвечает за оптимизацию всех параметров изображений. token 只负责优化空间参数。Совместные тренировки значительно улучшают конечные результаты (поверхность 2 и стол 3), будь то картинка ПИД или видео? ФВД, применение комбинированных тренировок были сокращены, результаты основаны на UNet рамка [2][3] последовательны.
6. Размер модели:исследовал 4 Различные размеры модели, S, B, L и XL (поверхность 1)。развернуть видео DiT Масштабирование значительно помогает улучшить качество генерируемых образцов. (картина 9). Этот вывод также доказывает использование модели видеодиффузии. Transformer структура для последующих scaling up правильность.
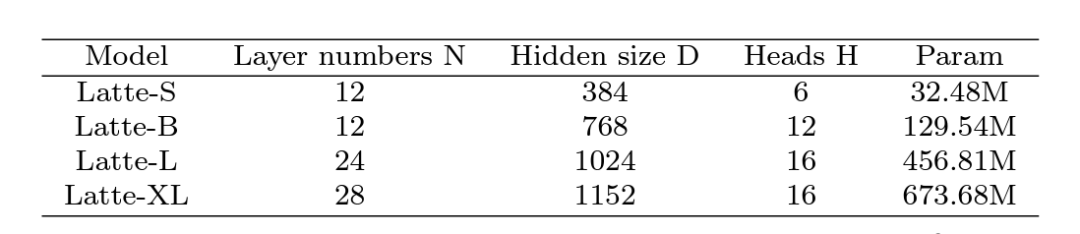
Таблица 1. Масштаб модели латте для разных размеров
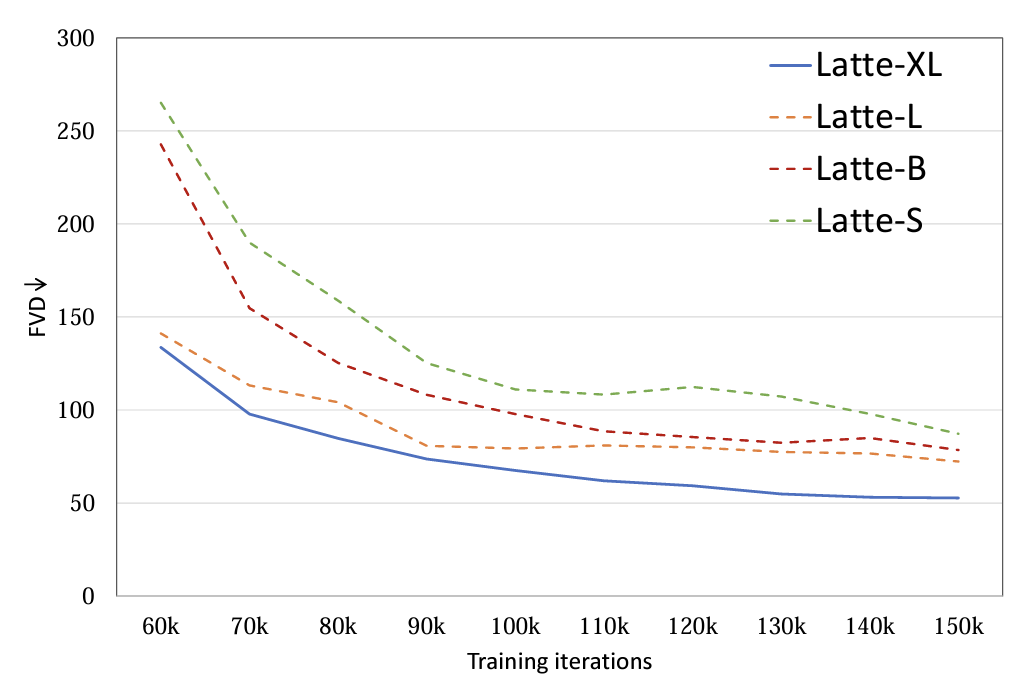
Рисунок 9. Размеры модели FVD
Качественный и количественный анализ
Авторы находятся в 4 академические наборы данных (FaceForensics, TaichiHD, SkyTimelapse а также UCF101) прошел обучение. Качественные и количественные (табл. 2 и стол 3) Отображение результатов Latte Все они достигли наилучших характеристик, что доказывает, что общий дизайн модели превосходен.
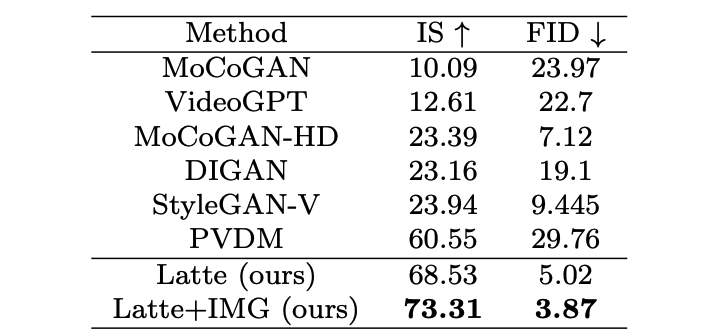
Таблица 2. Оценка качества изображения UCF101
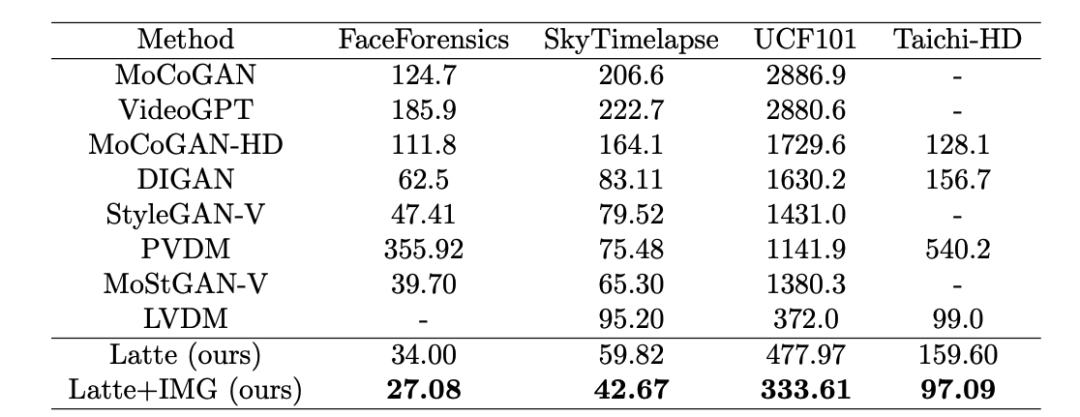
Таблица 3. Оценка качества видео Latte и SoTA
Расширение Винсента Видео
Чтобы еще больше доказать Latte общее исполнение, автор будет Latte Расширено до видеозадачи Винсента с использованием предварительного обучения. PixArt-alpha [4] Модель инициализируется как пространственный параметр по принципу оптимального проектирования после периода обучения Латте. Уже изначально обладая способностями Винсента. Последующий план проведения расширения масштабной проверки Latte Верхний предел генерирующей мощности.
Обсуждение и резюме
Latte Это первое в мире видео Винсента с открытым исходным кодом. DiT добился многообещающих результатов, но из-за огромной разницы в вычислительных ресурсах возникает проблема с обеспечением ясности и беглости речи. также продолжительность и Sora В сравнении все еще существует большой разрыв. Коллектив приветствует и активно ищет все виды сотрудничества, надеясь, что это пройдет Открытый исходный Мощь кода создает самостоятельно разработанную крупномасштабную универсальную видеомодель с превосходной производительностью.
Ссылки
[1] Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2] Ho, Jonathan, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
[3] Wang, Yaohui, et al. "Lavie: High-quality video generation with cascaded latent diffusion models." arXiv preprint arXiv:2309.15103 (2023).
[4] Chen, Junsong, et al. "PixArt-



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
