Подробное объяснение базовых знаний Худи
1. Знакомство с Худи
Apache Hudi переносит основные функции хранилища и базы данных непосредственно в озеро данных. Hudi предоставляет таблицы, транзакции, эффективные операции добавления/удаления, расширенную индексацию, услуги потоковой загрузки, оптимизацию кластеризации/сжатия данных и параллелизм, сохраняя при этом данные в формате файла с открытым исходным кодом.
HudiдаHadoop Upserts and Incrementalsаббревиатура,Используется для управления хранением больших наборов аналитических данных в распределенной файловой системе DFS.
Hudi — это абстракция хранилища данных, оптимизированная для сканирования, для аналитических предприятий. Она позволяет наборам данных DFS поддерживать изменения с задержкой на уровне минуты, а также поддерживает поэтапную обработку этого набора данных последующими системами.
1.1 Возможности и функции Hudi
- Поддерживает быстрое обновление и подключаемые индексы.
- Поддерживает атомарные операции и откат.
- Изоляция снимков между операциями записи и плагинами.
- savepoint Точка сохранения для восстановления пользовательских данных.
- Используйте статистику для управления размером и макетом файла.
- Асинхронное сжатие строк и столбцов.
- Имеет временную шкалу для отслеживания происхождения метаданных.
- Оптимизация наборов данных посредством кластеризации.
1.2 Инфраструктура Худи
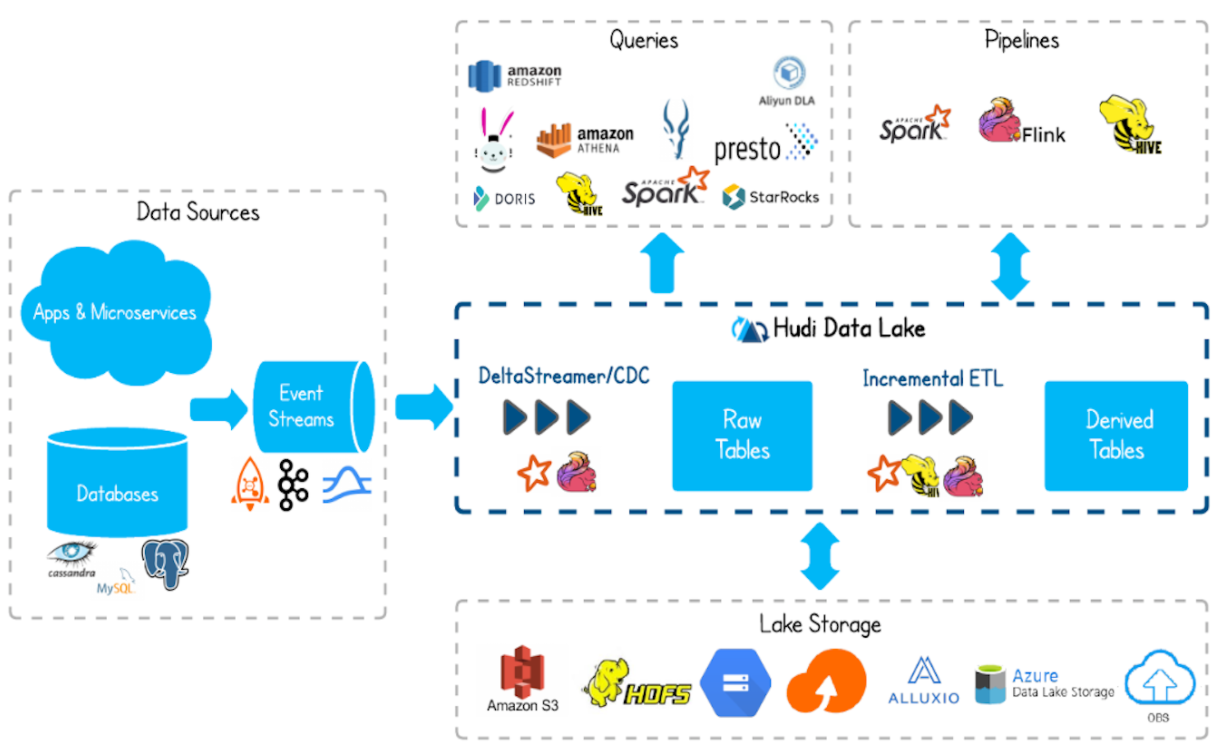
- Поддерживает запись данных в хранилище базы данных с помощью таких инструментов, как Flink, Spark и Hive.
- Поддерживает HDFS, S3, Azure, облако и т. д. в качестве хранилища данных для озера данных.
- Поддерживает различные механизмы запросов, такие как: Spark, Flink, Presto, Hive, Impala, Aliyun DLA.
- Поддерживает вычислительные механизмы, такие как Spark, Flink, Map-Reduce и т. д., для чтения и записи данных Hudi.
1.3 Функция Худи
- Hudi — это набор данных в хранилище больших данных. Журналы изменений можно объединить с Hudi с помощью upsert.
- Пара Hudi может быть представлена как обычная таблица Hive или Spark, а информацию о дополнительных изменениях можно получить через API или командную строку для дальнейшего использования в дальнейшем.
- Худи сохраняет историю изменений и может совершать путешествия во времени и откат назад.
- Hudi имеет внутренний индекс от первичного ключа до уровня файла, а файлом записи по умолчанию является фильтр Блума.
1.4 Особенности Худи
Apache Hudi поддерживает хранение больших объемов данных поверх хранилища, совместимого с Hadoop, не только для пакетной обработки, но и для потоковой обработки в озерах данных.
- Обновление/удаление записей: Hudi использует детальную индексацию уровня файлов/записей для поддержки обновления/удаления. ведение журнала, а также предоставление гарантий транзакций для операций записи. Запрос обрабатывает последний отправленный снимок и выводит результаты на его основе.
- Поток изменений: Hudi обеспечивает отличную поддержку получения изменений данных. Он может получать добавочный поток всех записей, которые были обновлены/вставлены/удалены в данной таблице с заданного момента времени, и разблокировать новые позиции запроса (категории).
- Apache Hudi сам по себе не хранит данные, а только управляет ими.
- Apache Hudi также не анализирует данные и требует использования механизма вычислительного анализа для запроса и сохранения данных, такого как Spark или Flink;
- При использовании Hudi загружается пакет jar и вызывается базовый API. Поэтому необходимо скомпилировать исходный код Hudi в соответствии с используемой версией платформы больших данных и получить соответствующий зависимый пакет jar.
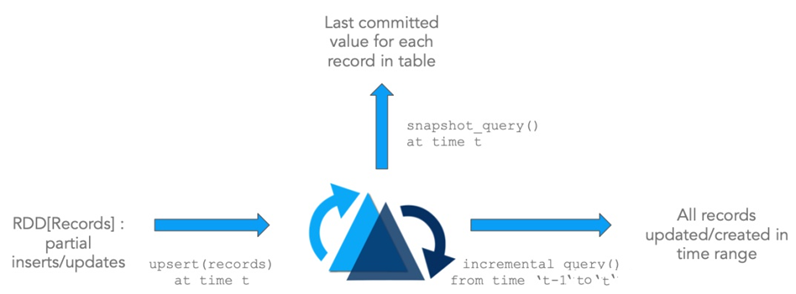
2. Основные концепции
2.1 Timeline
В Hudi поддерживается временная шкала всех операций. Каждая операция соответствует моменту времени. Каждый момент обеспечивает просмотр таблицы и поддерживает поиск данных в хронологическом порядке.
Instant action: Конкретные операции над таблицей.Instant time: Временная метка выполнения текущей операции.state:текущийinstantстатус。
Hudi может гарантировать, что все операции являются атомарными и соответствуют временной шкале. Ключевые операции Hudi включают в себя:
COMMITS:Запишите данные атомарно один раз вHudiОперация。CLEANS:Фоновое действие по удалению старых версий файлов в таблице, которые больше не нужны.。DELTA_COMMIT:delta commitосновнойдапакет атомарных записейMORповерхность,Некоторые из них будут записаны в дельта-логи.COMPACTION: Различные типы операций сжимаются в фоновом режиме, а файлы журналов сжимаются в столбчатый формат хранения.ROLLBACK: будет неудачнымcommit/delta commitвыполнить откат。SAVEPOINT: Отметьте определенные файлы как сохраненные, чтобы облегчить восстановление в нештатных ситуациях.
Государство подробно объяснило:
REQUESTED: Указывает, что операция запланирована, но еще не начата.INFLIGHT: Указывает, что операция в данный момент выполняетсяCOMPLETED: Указывает на завершение операции на временной шкале.
2.2 Расположение файла
- Hudi организует таблицы данных в структуру каталогов по базовому пути распределенной файловой системы.
- Таблица содержит несколько разделов.
- В каждом разделе файлы разделены на группы файлов, уникально идентифицируемые идентификаторами файлов.
- Каждая группа файлов содержит несколько фрагментов файлов.
- Каждый фрагмент содержит базовый файл (.parquet), созданный во время определенной мгновенной операции фиксации/сжатия. Эти файлы содержат самостоятельно созданные базовые файлы. Вставить/обновить базовый файл, начиная с файла.
Hudi использует многоверсионный контроль параллелизма (MVCC), при котором операции сжатия объединяют файлы журнала и базовые файлы для создания новых фрагментов файлов, а операции очистки удаляют неиспользуемые/старые файлы.
Нарезка файлов для освобождения места в файловой системе.
2.3 поверхность&Тип запроса
тип таблицы | Поддерживаемые типы запросов |
|---|---|
Copy On Write | Запрос моментального снимка + инкрементный запрос |
Merge On Read | Запрос моментального снимка + инкрементный запрос + Чтение оптимизированного запроса |
2.3.1 Тип таблицы
2.3.1.1 Copy On Write
использовать эксклюзивный формат файла столбца (например, паркет),просто обнови версию&Перезаписывать файлы, выполняя синхронное слияние во время записи.。
Вот концептуальное объяснение того, как это работает, когда данные записываются в таблицу копирования при записи и к ней выполняются два запроса.
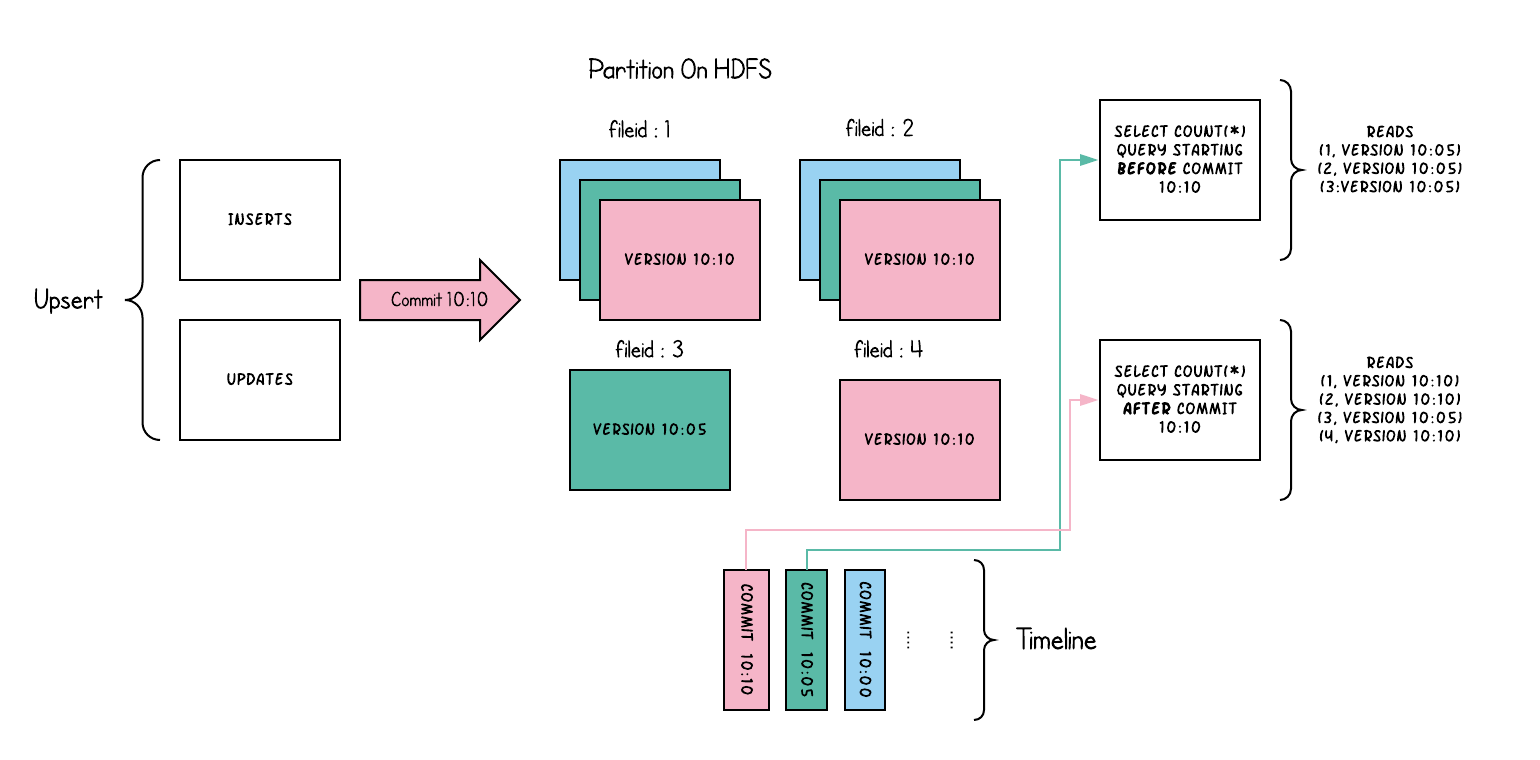
При записи данных обновление существующей файловой группы создает новый срез для файловой группы с отметкой времени немедленной фиксации, в то время как вставка выделяет новую файловую группу и записывает свой первый срез для файловой группы. Те, что отмечены красным выше, отправлены недавно.
2.3.1.1 Merge On Read
Для хранения данных используйте комбинацию столбчатого формата (например: паркет) + формата файла на основе строк (например: avro). Обновления сохраняются в дельта-файлах, а затем сжимаются для синхронизации или
Асинхронно сгенерируйте новую версию столбчатого файла.
Сохраняет входящие добавления для каждой файловой группы в дельта-журнал на основе строк для подтверждения Запроса снимка путем динамического применения дельта-журнала к последней версии каждого идентификатора файла во время запроса.
Поэтому такого рода таблица пытается сбалансировать чтение иусиление записи для предоставления данных, близких к реальному времени.
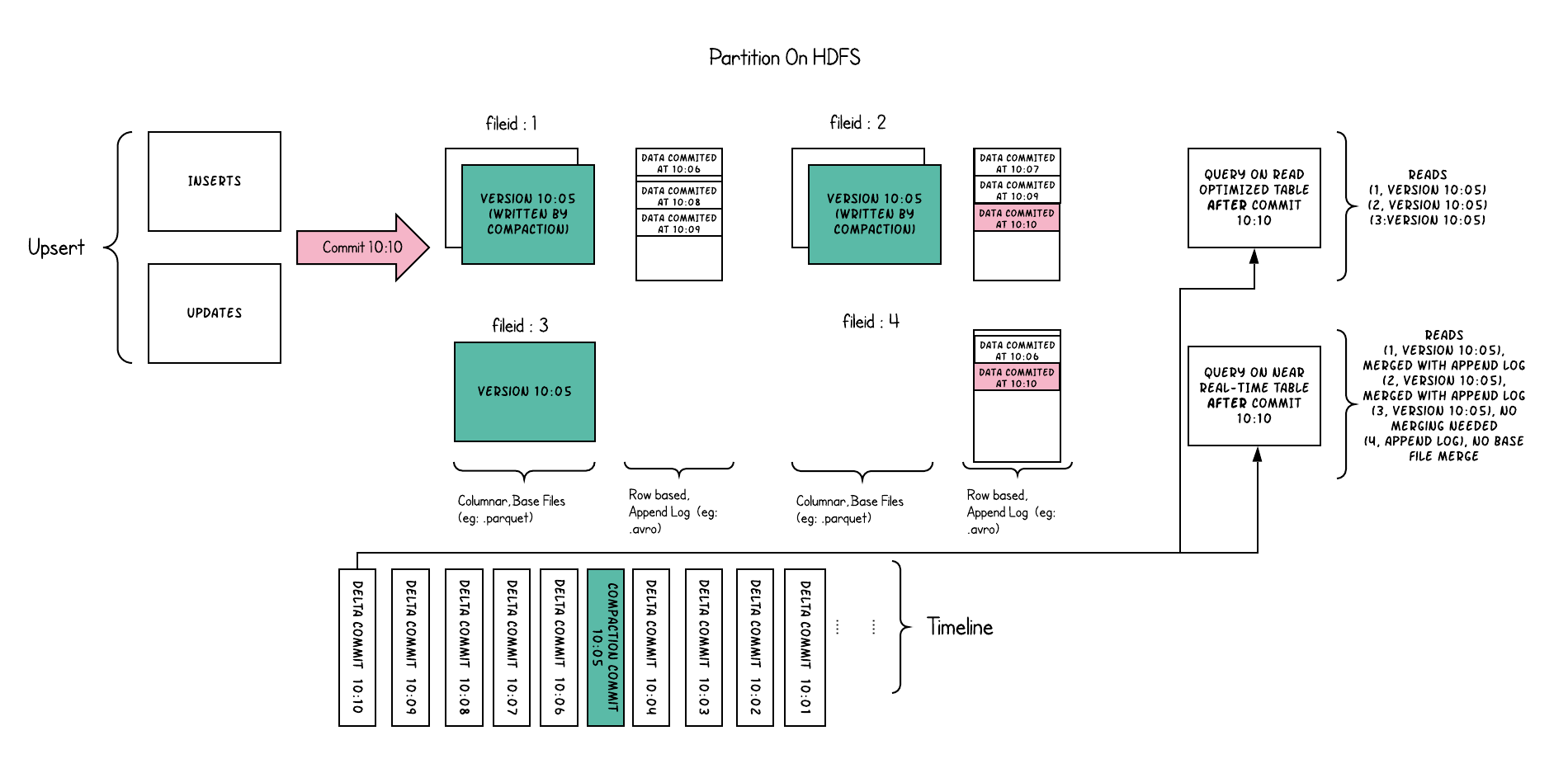
Контрастные размеры | CopyOnWrite | MergeOnRead |
|---|---|---|
задержка данных | Higher | Lower |
Задержка запроса | Lower | Higher |
Стоимость обновления (ввод-вывод) | Высшее (необходимо переписать паркет) | Нижний (добавить в дельта-журнал) |
Размер файла паркета | Меньше (высокая стоимость обновления (I/O)) | Больше (низкая стоимость обновления) |
усиление записи | Higher | Ниже (зависит от стратегии сжатия) |
2.3.2 Тип запроса
- Запрос снимка:Запросы в этом представлении могут просматривать данный коммит.или Во время операции сжатияповерхностьпоследний снимок。
- Для таблиц слияния при чтении (таблиц MOR) это представление предоставляет наборы данных практически в реальном времени (с задержкой в несколько минут) путем динамического объединения базовых файлов (например, parquet) и дельта-файлов (например, avro) последних фрагментов файлов. .
- Для таблиц копирования при записи (таблиц COW) он обеспечивает замену существующих таблиц паркета подключаемым модулем, обеспечивая при этом вставку/удаление и другие функции на стороне записи.
- инкрементный запрос: запросы в этом представлении будут видеть только новые данные, записанные в набор данных после определенной фиксации/сжатия. Обеспечивает потоковую передачу записей изменений для поэтапного чтения.
- Читать оптимизированный запрос:
3. Индекс Худи
Hudi обеспечивает эффективную вставку обновлений, сопоставляя заданный ключ с капюшоном (ключ записи + путь к разделу) идентификатору файла с помощью механизма индексирования.
После записи в файл первой версии записи сопоставление между ключом записи и идентификатором файла не меняется.
Для стола COW:
Это позволяет избежать сканирования всей файловой системы для поддержки быстрых операций добавления/удаления.
Для таблицы MOR:
Позволяет ограничить количество записей в базовом файле, которые необходимо объединить. Для базового файла его необходимо объединить только на основе записей текущего базового файла.
Сравнение стоимости:
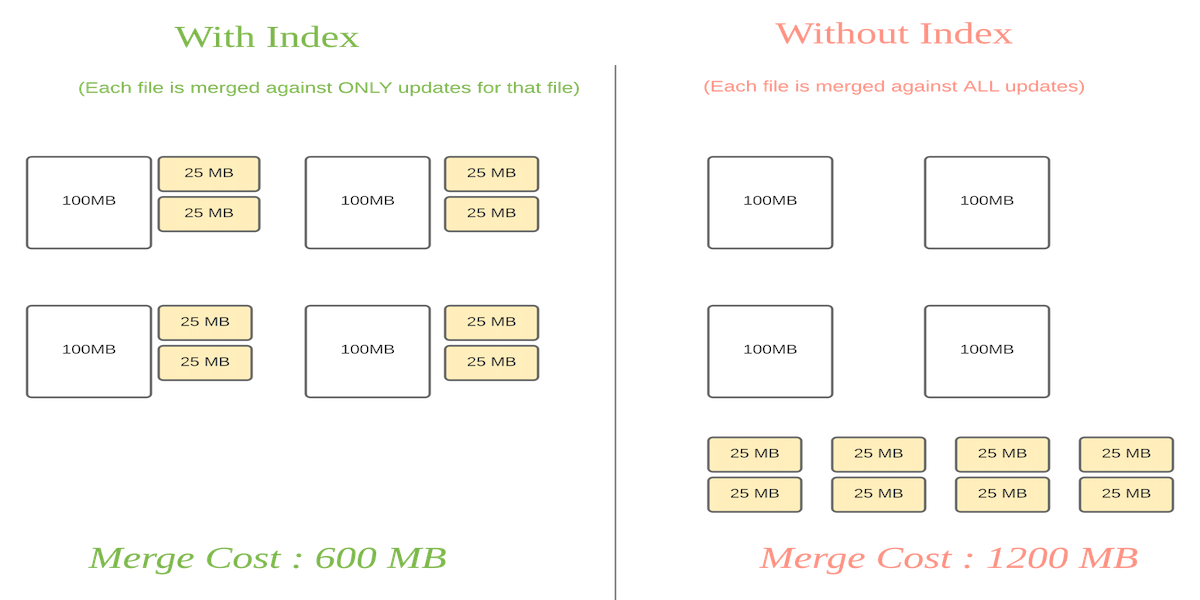
Индексы, поддерживаемые Hudi, следующие:
имя | Примечание |
|---|---|
Индекс Блума | Используя фильтр Блума, созданный на основе ключа записи, вы также можете использовать диапазон ключей записи для удаления файлов-кандидатов. |
Индекс GLOBAL_BLOOM | Похож на индекс Булма, но область действия глобальная. |
Простой индекс | Выполняет экономичное соединение входящих записей обновления/удаления с ключами, извлеченными из таблиц в хранилище. |
Индекс GLOBAL_SIMPLE | Похож на Simple, но область действия глобальная. |
Индекс HBase | Сохраните информацию об индексе в Hbase. |
Индекс INMEMORY | Сохраняйте информацию об индексе в памяти программ Spark, Java и Flink, а Java по умолчанию использует текущий индекс. |
Индекс ВЕДРА | Найдите группу файлов, используя хэш сегмента.,Эффект лучше, когда объем данных велик.。может пройти |
Индекс RECORD_INDEX | Индекс сохраняет ключ записи в сопоставлении местоположений в таблице метаданных Hudi. |
Пользовательский индекс | Пользовательский реализованный индекс. |
ВЕДРО:
- ПРОСТОЙ (по умолчанию): файловая группа каждого раздела использует фиксированное количество сегментов и не может быть уменьшена или расширена. Поддерживаются таблицы COW и MOR. Поскольку количество сегментов нельзя изменить, а между сегментами и файловыми группами существует взаимно однозначное соответствие, этот индекс не очень подходит для случаев асимметрии данных.
- CONSISTENT_HASHING: поддерживает динамическое количество сегментов, количество сегментов можно регулировать в зависимости от размера сегмента.
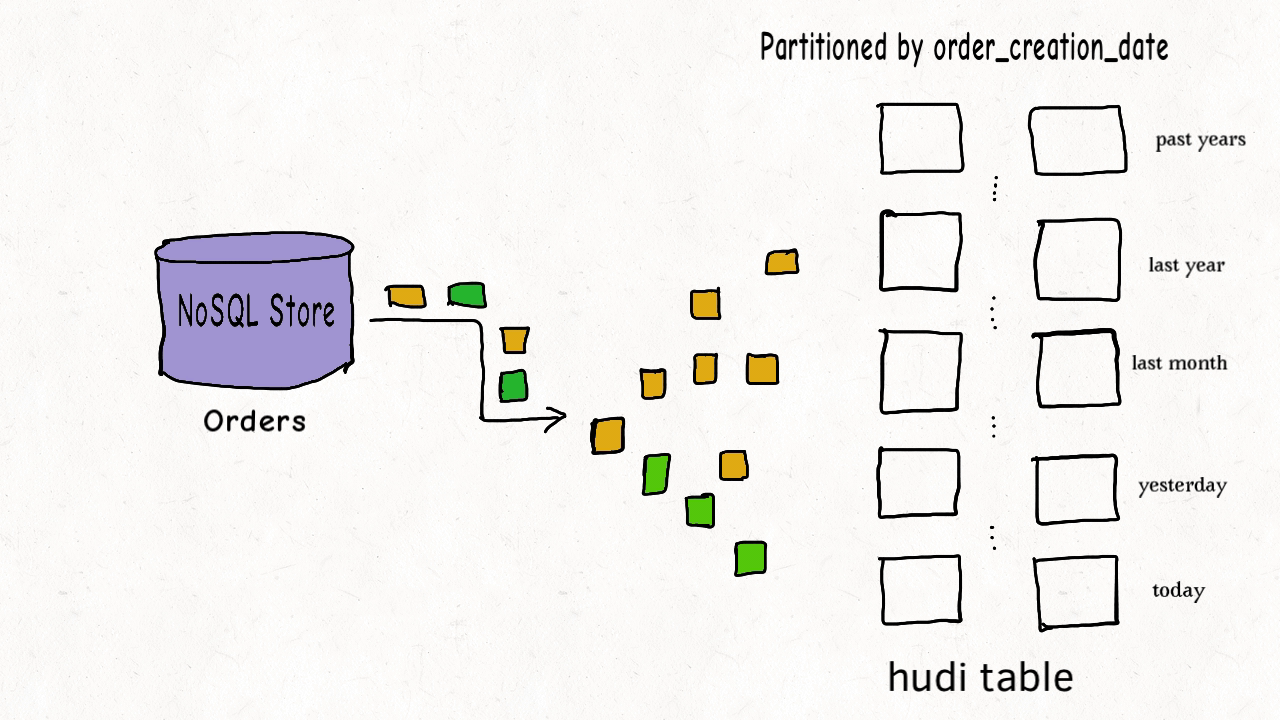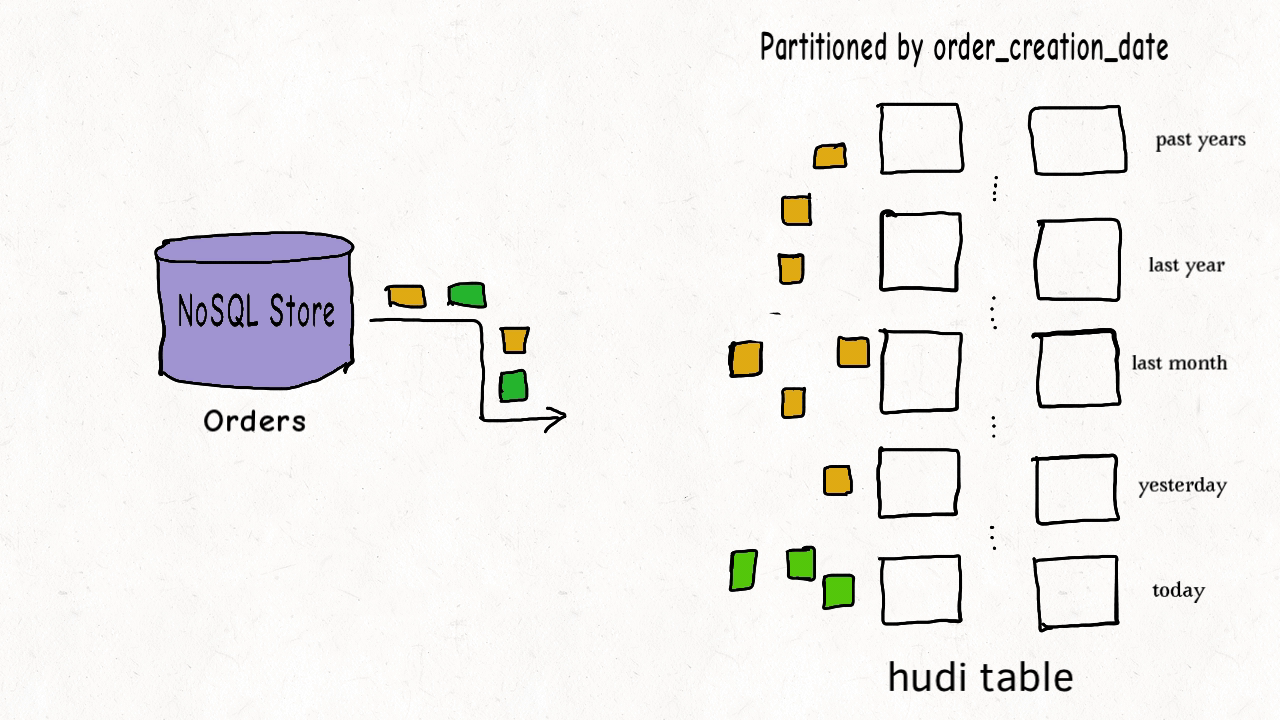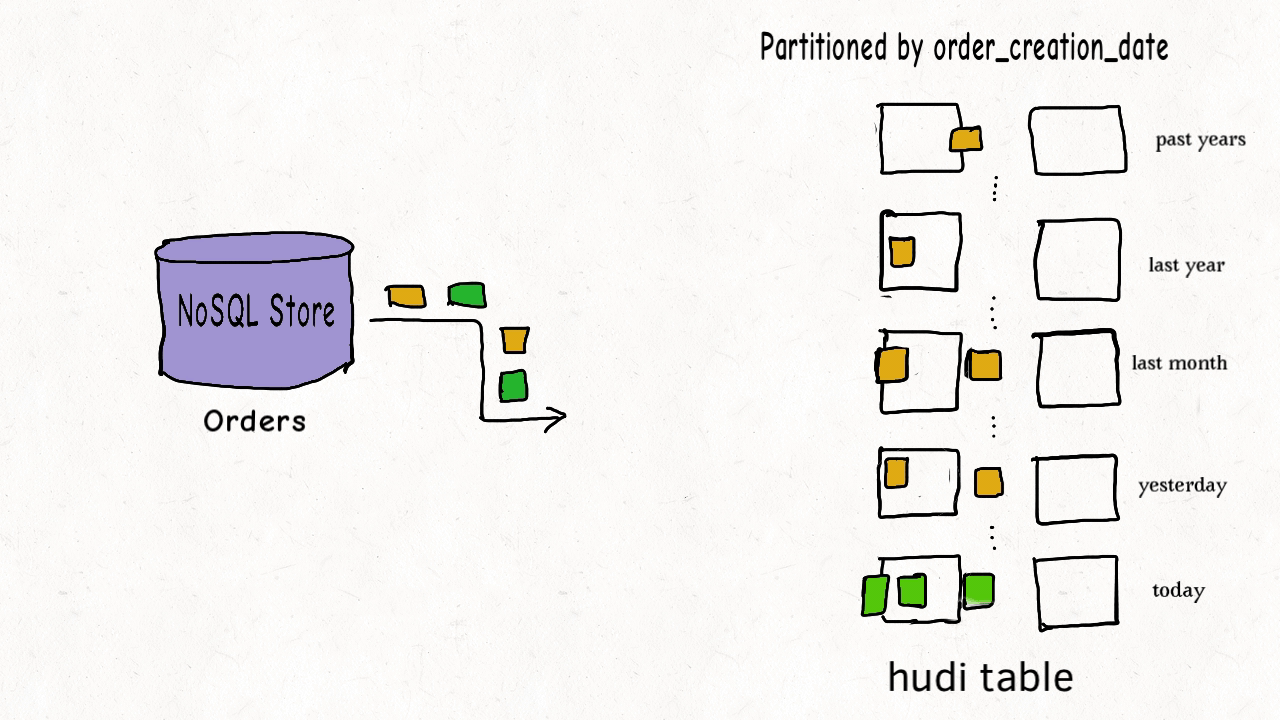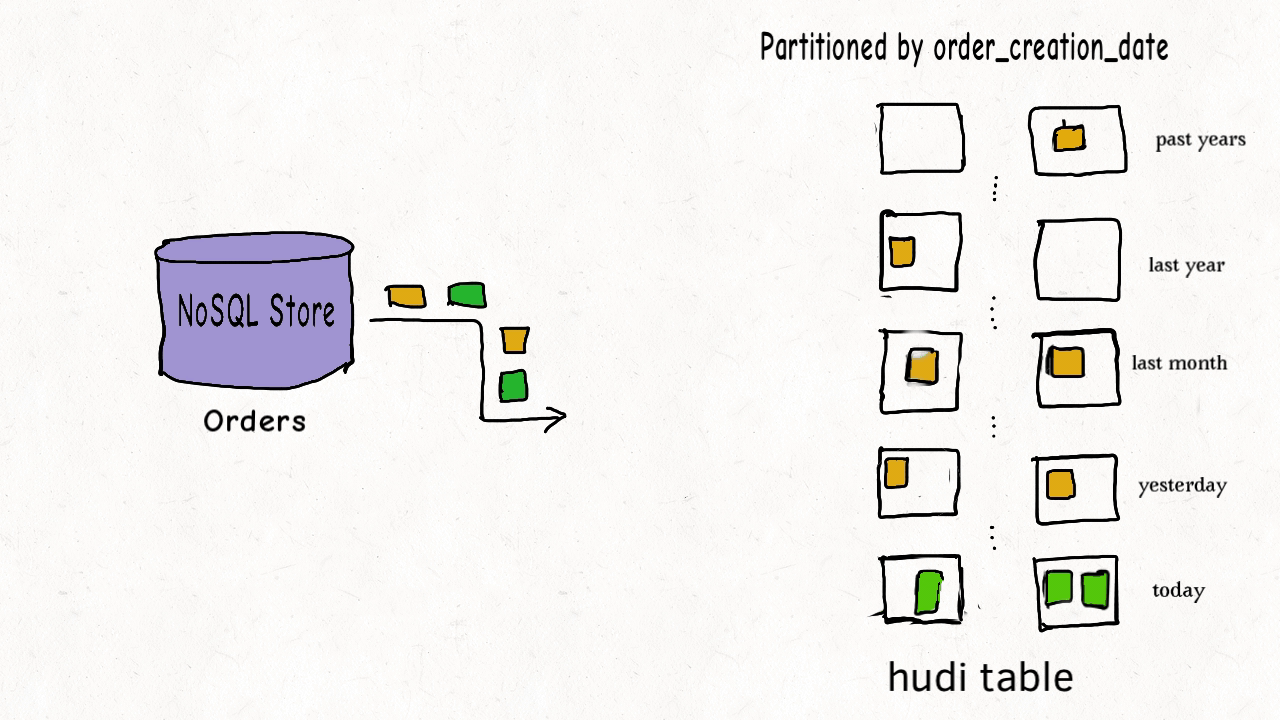
4. Управление данными Худи
4.1 Структура данных таблицы Худи
Файлы данных таблиц Hudi обычно хранятся с использованием HDFS. С точки зрения путей и типов файлов файлы хранения таблиц Hudi делятся на две категории.
- файлы .hoodie,
- Пути, относящиеся к amricas и asia, представляют собой фактические файлы данных, которые хранятся по разделам. Можно указать ключ пути к разделу.
4.1.1 файл .hoodie



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
