Подробное объяснение архитектуры RAG 2.0: построение комплексной системы генерации улучшений поиска.
Было много статей о генерации расширенного поиска (RAG). Если мы сможем создать обучаемый поиск или всю RAG можно настроить, как тонкую настройку модели большого языка (LLM), мы определенно сможем получить лучшие результаты. результат. Однако проблема с нынешним RAG заключается в том, что различные подмодули не полностью скоординированы. Это похоже на шовного монстра. Хотя он может работать, его части не гармоничны, поэтому мы представляем здесь концепцию RAG 2.0, чтобы решить эту проблему. проблема.
Что такое РАГ?
Проще говоря, RAG может предоставить нашей модели большого языка (LLM) дополнительный контекст для генерации более качественных и конкретных ответов. LLM обучаются на общедоступных данных и сами по себе являются очень интеллектуальными системами, но они не могут ответить на конкретные вопросы, потому что им не хватает контекста, чтобы ответить на них.
Таким образом, RAG может добавлять новые знания или возможности в LLM, хотя это добавление знаний не является постоянным. Еще один распространенный способ добавить новые знания или возможности в LLM — это точная настройка LLM на наши конкретные данные.
Добавлять новые знания посредством тонкой настройки сложно и дорого, но это навсегда. Добавление новых способностей посредством тонкой настройки может даже повлиять на ранее имевшиеся знания. Во время тонкой настройки мы не можем контролировать, какие веса будут изменены, и поэтому не можем узнать, какие возможности будут увеличены или уменьшены.
Выбор между тонкой настройкой, RAG или их комбинацией полностью зависит от поставленной задачи. Не существует единого подхода, подходящего всем.
Классические шаги RAG следующие:
- Разделите документ на равные части.
- Каждый фрагмент представляет собой кусок необработанного текста.
- Используйте кодировщик для создания вложений для каждого блока (например,,Встроить OpenAI,преобразователь предложений и т. д.),И сохраните его в библиотеке данных.
- Найдите наиболее похожие фрагменты кода, получите необработанный текст этих фрагментов и передайте его генератору в качестве контекста вместе с подсказками.
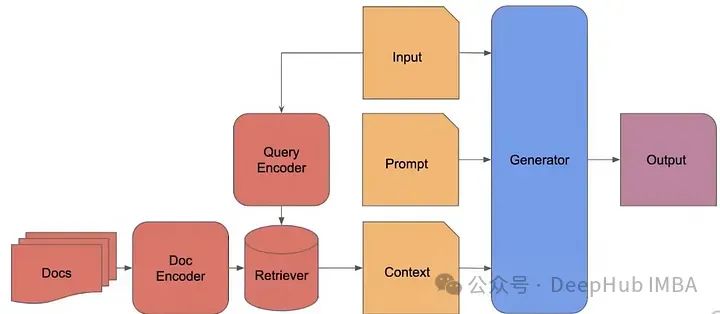
RAG 2.0
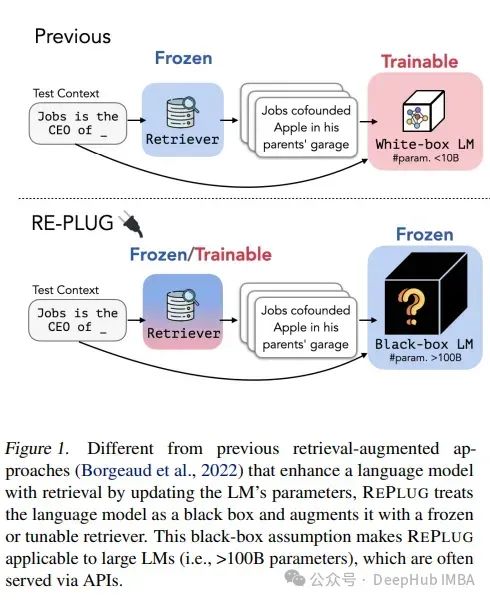
Сегодняшние типичные RAG-системы используют готовые замороженные модели для внедрения, векторные базы данных для поиска и языковые модели «черного ящика» для генерации, объединяя их вместе с помощью подсказок или структур оркестровки. Отдельные компоненты технически осуществимы, но в целом далеко от оптимального. Эти системы хрупкие, им не хватает машинного обучения или специализации в той области, в которой они развернуты, они требуют обширных подсказок и склонны к каскадным ошибкам. В результате системы RAG редко соответствуют производственным стандартам.
А концепция RAG 2.0, о которой мы собираемся поговорить, благодаря предварительному обучению, точной настройке и согласованию всех компонентов, как целостной интегрированной системы, максимизирует производительность за счет двойного обратного распространения языковых моделей и ретриверов:
Ниже приведено наше сравнение контекстных языковых моделей (контекстных языковых моделей) и замороженной модели системы RAG в нескольких измерениях.
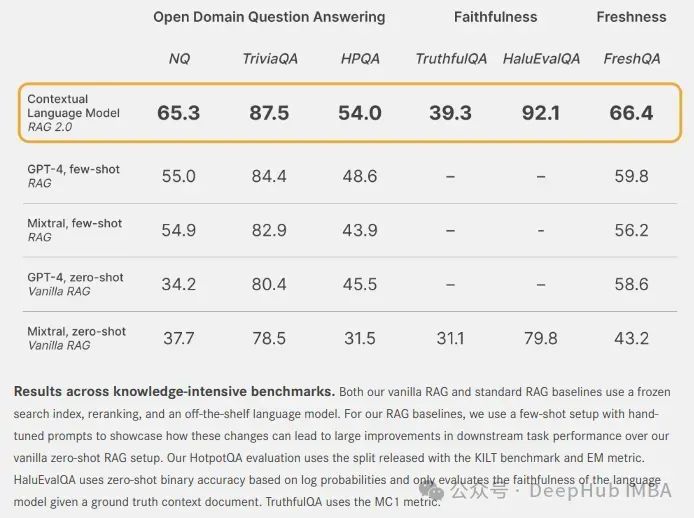
Для ответов на вопросы в открытой области: используйте стандартные наборы данных NaturalQuest (NQ) и TriviaQA, чтобы проверить способность каждой модели извлекать соответствующие знания и точно генерировать ответы. Модель также оценивается с использованием набора данных HotpotQA (HPQA) в одноэтапном режиме поиска. Во всех наборах данных используется метрика точного соответствия (EM).
Для точности: используйте HaluEvalQA и TruthfulQA, чтобы измерить способность каждой модели сохранять обоснованность при поиске доказательств и галлюцинаций.
И свежесть: мы используем индекс веб-поиска для измерения способности каждой системы RAG обобщать знания о быстро меняющемся мире и показывать точность в последнем тесте FreshQA.
Эти размеры важны для создания RAG-систем промышленного уровня. CLM значительно повышает производительность различных мощных систем RAG с замороженными моделями, созданных с использованием GPT-4 или современных моделей с открытым исходным кодом, таких как Mixtral.
Как РАГ решает задачи разведки?
RAG — это полупараметрическая система, параметрическая часть которой представляет собой большую языковую модель (LLM), а остальная часть — непараметрическая. Таким образом мы получаем полупараметрическую систему. LLM хранит всю информацию (в закодированном виде) в своих весах или параметрах, тогда как остальная часть системы не имеет параметров, определяющих эти знания.
Но почему это решает проблему?
- Обмен индексами (конкретной информацией) в LLM дает нам возможность настройки, а это означает, что мы не просто получаем старые знания, но также можем пересматривать содержимое индекса.
- Расположение LLM по этим указателям означает, что иллюзии уменьшаются, а цитаты и атрибуции выполняются путем указания источника.
Таким образом, RAG обеспечивает лучшие возможности контекстуализации для LLM, что повышает его эффективность. Но действительно ли все так просто?
Нет, потому что у нас есть много вопросов, на которые нужно ответить, чтобы создать современный и масштабируемый конвейер RAG.
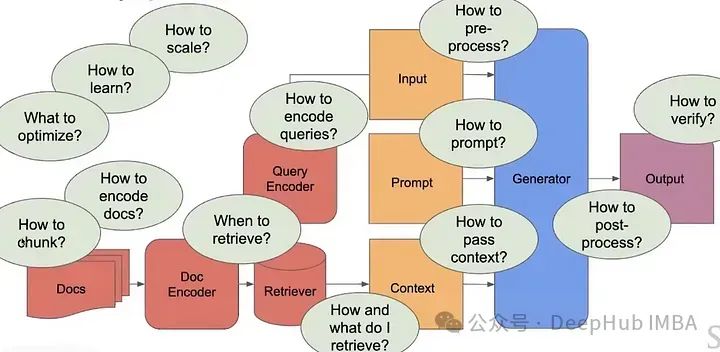
Современные RAG-системы не настолько умны, они очень просты и не могут решать сложные задачи, требующие большого количества специального контекста.
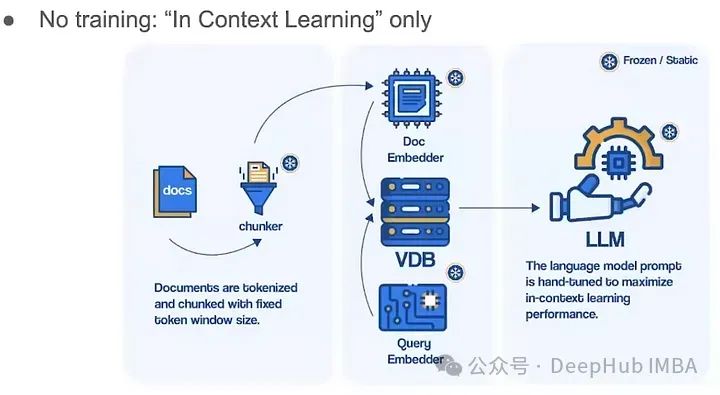
Мы видим, что единственная часть параметра, которую в настоящее время можно обучить, — это LLM. Можно ли добавить больше параметров?
лучшие стратегии поиска
1. Разреженный поиск
TF-IDF: TF-IDF, или частота терминов, обратная частоте документов, является мерой важности слова для документов в наборе или корпусе документов с поправкой на тот факт, что определенные слова обычно встречаются чаще. [1] Он часто используется в качестве весового коэффициента при поиске информации, анализе текста и поиске моделирования пользователей.

BM25: Можно рассматривать как улучшение TF-IDF.
Для запроса «машинное обучение» расчет BM25 будет представлять собой сумму BM25Score(машина) + BM25Score(обучение).
Первая часть формулы — это обратная частота документов (IDF) термина. Вторая часть формулы представляет частоту терминов (TF), нормированную по длине документа.
f(q(i), D) — частота слова q(i) в документе D.
K и b — параметры, которые можно регулировать. |D| представляет длину документа, а avgdl представляет собой среднюю длину всех документов в базе данных.
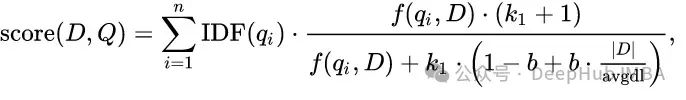
Это лишь некоторые первые шаги в разреженном поиске.
2. Интенсивный поиск
Причина, по которой требуется интенсивный поиск, заключается в том, что язык не так прост. Например, разреженный поиск полностью завершается неудачей, если имеются синонимы. Мы хотим получать информацию не только на основе точных совпадений ключевых слов, но и на основе семантики предложения. Встраивание предложений BERT является примером плотного поиска. После преобразования предложений в векторы используйте скалярное произведение или косинусное сходство, чтобы получить информацию.
Одним из преимуществ интенсивного поиска является то, что он легко распараллеливается, а с помощью графических процессоров он может легко выполнять поиск по сходству на уровне миллиардов. Именно так Meta разработала FAISS, или векторные базы данных, как мы их часто называем.
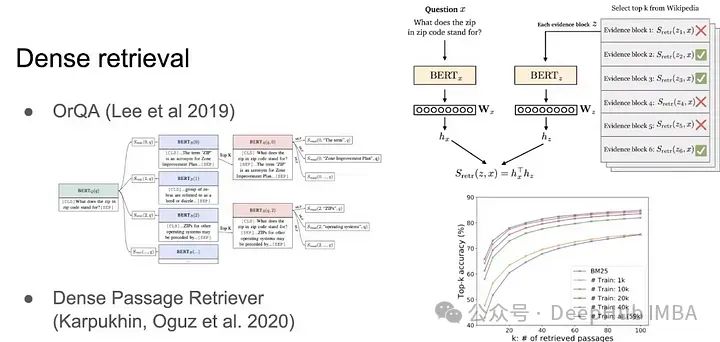
Плотный поиск — это то, что мы часто называем векторным запросом. Обычно для определения сходства громкости используется скалярное произведение. Это также часто используемый шаг в общей RAG. Как нам выйти за рамки простых скалярных произведений?
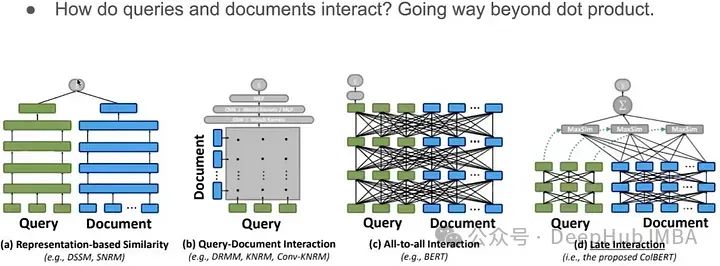
Помимо простых скалярных произведений, существует множество способов взаимодействия с документами и запросами, например сети-близнецы, ColBERT и т. д.
Алгоритм поиска на основе модели
ColBERT — очень хорошая стратегия поиска, но это не SOTA поиска информации. У нас есть и другие, более продвинутые алгоритмы и стратегии, такие как SPLADE, DRAGON и Hybrid search.
1、SPLADE:Расширение запроса, сочетающее разреженность и плотность。

Как видите, расширение запроса охватывает больше контекста, что помогает улучшить поиск.
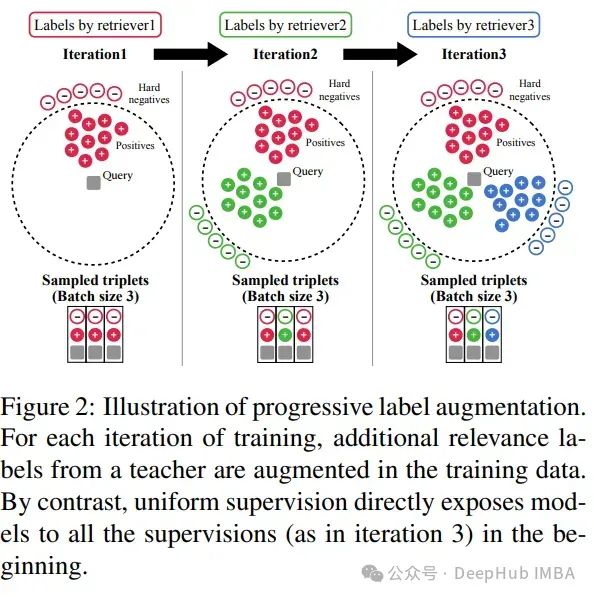
2、DRAGON:посредством прогрессивногоданные Улучшения для продвижения плотных ретриверов。
Давайте разберемся, как работает ДРАКОН, на примере:
- Первоначальный запрос:“Как ухаживать за растениями-пауками?”
- Действия ДРАКОНА:После определения темы ухода за растениями,ДРАКОН формулирует целевой поисковый запрос,Специальный сборник общей информации по уходу за растениями-пауками.
- первоначальный поиск:DRAGONуглубиться в этоданные Библиотека,Получите документацию о потребностях в солнечном свете, графике полива и соответствующих удобрениях для этой листовой зелени. Затем сформулируйте ответы: «Растениям-паукам требуется умеренный непрямой солнечный свет.,Поливать следует один раз в неделю. в течение вегетационного периода,Для них полезна подкормка раз в месяц. "
- Обновления пользователей:Как спрашивает пользователь:“Что делать, если листья становятся коричневыми?”Разговор сместился。
- ДРАКОН адаптируется:DRAGONУточнить поисковый запрос,Сосредоточьтесь на проблеме потемнения листьев растений-пауков.
- Динамическое поисковое действие:DRAGONПолучить информацию об распространенных причинах потемнения листьев.,Например, чрезмерный полив или слишком много прямых солнечных лучей.
- передача знаний:Используя вновь полученныеданные,ДРАКОН адаптирует свою реакцию к развитию разговора: «Коричневые листья на вашем растении-пауке могут быть признаком чрезмерного полива или слишком большого количества прямых солнечных лучей. Попробуйте поливать реже.,И переместите растение в более затененное место. "
DRAGON динамически корректирует свои поисковые запросы в зависимости от меняющихся интересов пользователя в разговоре. Каждый ввод пользователя обновляет процесс поиска в режиме реального времени, гарантируя, что предоставляемая информация актуальна, подробна и соответствует последнему контексту.
3. Гибридный поиск:Мы интенсивныеиинтерполировать между разреженными поисками。ЭтоRAGНаправление, которое исследует сообщество,Например, возьмите что-нибудь вроде BM25 и объедините его со SPLADE или DRAGON.
Но какой бы метод мы ни использовали, ретривер все равно фиксированный или не подлежит кастомизации (тонкой настройке)
Средство извлечения, которое может предоставить контекст
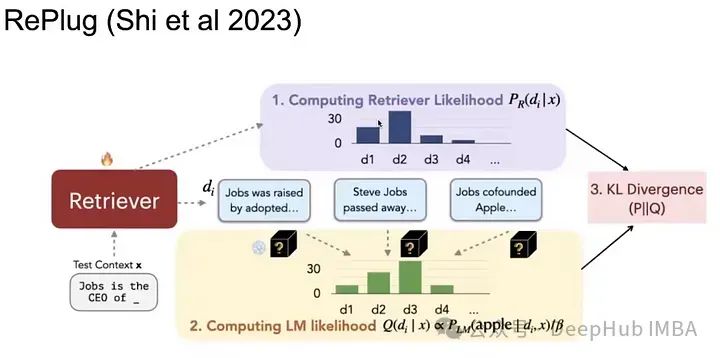
1、RePlug
Это очень интересная статья о поиске. Для данного запроса мы извлекаем K лучших документов и нормализуем их (вычисляем их вероятность), чтобы получить распределение. Затем мы сравниваем каждый документ с запросом как отдельные входные данные для генератора. Затем посмотрите на недоумение языковой модели, чтобы найти правильный ответ. Таким образом, существует два распределения возможностей. На этих распределениях мы вычисляем потери из-за расхождения KL, чтобы минимизировать расхождение KL, и мы получим результат с наименьшей путаницей между полученными документами и правильным ответом.
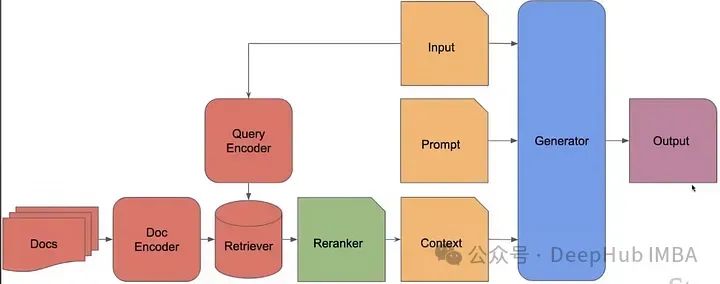
2、In-Context RALM
Он использует замороженные модели RAG и BM25, а затем специализирует извлеченные детали, переупорядочивая их. Содержит нулевую модель изученного языка и обученный механизм изменения рейтинга.

Языковая модель фиксирована, и мы выполняем обратное распространение или обучение только переупорядоченной части. Он не очень продвинут, но по сравнению с предыдущей простой RAG работает хорошо.
Но проблема в том, что если к параметрам LLM нет доступа, как выполнить обратное распространение или обновить параметры ретривера?
Таким образом, для тренировки ретривера используется потеря в стиле подкрепления. Эффективность ретривера оценивается по тому, насколько хорошо полученная им информация улучшает результаты языковой модели. Усовершенствования ретривера направлены на максимальное использование этого улучшения. Это может включать корректировку стратегий поиска (что и как получать информацию) на основе показателей производительности, полученных на основе выходных данных языковой модели. Общие показатели могут включать в себя связность, релевантность и фактическую точность сгенерированного текста.
3. Объедините контекстуализированные ретриверы и генераторы.
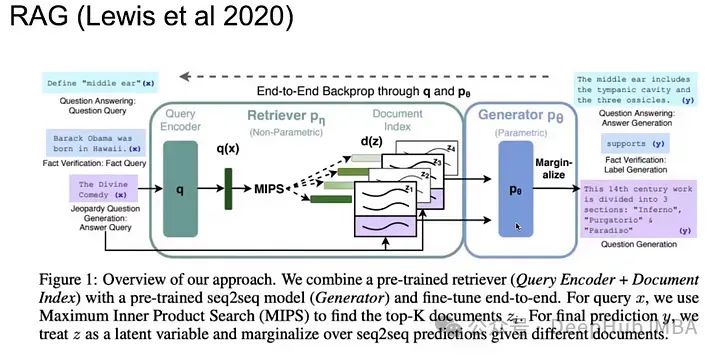
Вместо того, чтобы оптимизировать LLM или ретривер по отдельности, почему бы не оптимизировать весь процесс сразу?

При получении документов существует множество мест, которые можно оптимизировать через каждые n токенов или время получения.
В модели RAG-токена, по сравнению с однократным поиском модели RAG-Sequence, разные документы могут быть получены по разным целевым токенам.
Все k документов кодируются с помощью кодировщика, после чего осуществляется совместная работа, а затем декодирование перед предоставлением их в качестве контекста для приглашения ввода.

4、k-NN LM
Еще одна интересная идея в системах RAG — включение k-NN LM:
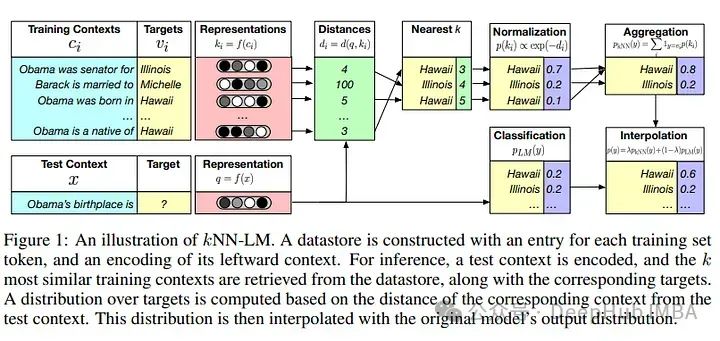
Исследователи показывают, что они могут создавать модели в 25 раз меньше, если обучаться в среде RAG.
В настоящее время организовано SOTA.
Контекстуализация больших языковых моделей (LLM) сложна и дорога. Поскольку повторно обновить весь LLM нелегко, необходимо обновить миллиарды или даже триллионы токенов.
Итак, компания Meta's FAIR выпустила статью ATLAS. В этой статье обсуждается весь конвейер RAG, который можно использовать для обучения, используются разные типы функций потерь для разных частей и сравнивается их производительность.
Вот сравнение производительности всех различных потерь из статьи ATLAS:
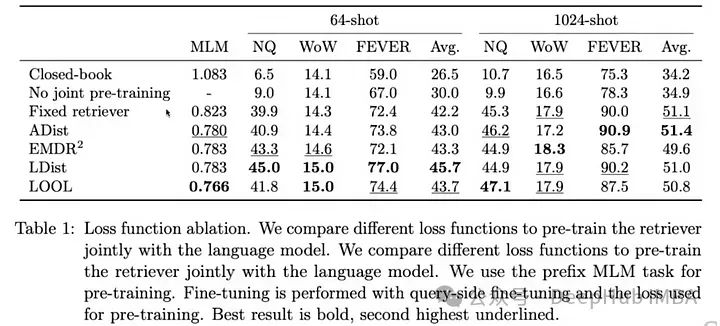
ATLAS — это тщательно разработанная и предварительно обученная языковая модель с расширенными возможностями поиска, способная решать наукоемкие задачи с очень небольшим количеством обучающих примеров. ATLAS интегрирует эти функции потерь в последовательный конвейер обучения, позволяя точно настраивать ретривер непосредственно на основе их влияния на производительность языковой модели, а не полагаться на внешние аннотации или заранее определенные оценки релевантности. Такая интеграция позволяет системе со временем совершенствоваться, адаптируясь к конкретным потребностям ее учебной миссии.
- Использование структуры двойного кодировщика для системы поиска.,Кодер, предназначенный для кодирования запросов.,Второй предназначен для документации.
- Полученные документы затем передаются вместе с запросом в мощный язык последовательного преобразования. Модель, основанная на T5 Архитектура.,Модель действует как декодер в системе.,Сгенерируйте окончательный текстовый вывод.
- Использование метода слияния в декодере,Интегрируйте информацию о полученных документах непосредственно в декодер модели «последовательность-последовательность». Этот подход позволяет модели языка динамически использовать полученную информацию в процессе генерации.,Повысьте актуальность и точность результатов.
Подвести итог
Существует три типа RAG (генерация поискового расширения):
- Модель Freeze: они встречаются во всей отрасли.,Это всего лишь доказательства концепции (POC).
- Полузамороженная МодельRAG: применяет умных ретриверов и пытается каким-то образом адаптировать их. LLM не модифицируется, просто управляет ретриверами и объединяет их с конечным результатом.
- Полностью обучаемая РАГ: сквозное обучение довольно сложное,Но если все сделано правильно,Может обеспечить лучшую производительность. Но это определенно очень ресурсоемко.
RAG, который мы обычно используем, — это только первая замороженная модель RAG, поэтому технология RAG все еще находится в зачаточном состоянии. Параметры для расширения языковых моделей все еще являются токенами. Как эффективно расширить средство извлечения и как объединить память с блоками данных с помощью параметров или. Разделение блоков данных, разделение процессов поиска и генерации знаний и т. д. — все это вопросы, которые необходимо изучить в будущем.
Автор:Вишал Раджпут



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
