Почему родилась технология больших данных и какие проблемы она решает?
Предыстория появления и основные понятия больших данных
Почему появились большие данные? И какие проблемы он решает?
1. Модель обработки данных до появления больших данных
Что такое большие данные? Фактически, большие данные — это технология, которая позволяет завершить хранение и расчет этих данных после того, как данные достигнут массового масштаба.
Но прежде чем данные достигнут массового масштаба, есть ли у нас традиционная архитектура обработки данных, которая поможет нам завершить обработку этой части данных?
Прежде всего, с точки зрения типов данных, мы имеем дело со структурированными, неструктурированными и полуструктурированными данными.
Структурированные данные обычно существуют в реляционных базах данных, и все они структурированы. Поскольку оно имеет строгие ограничения на поля, каждое поле имеет свой собственный тип данных.
Этот тип данных, базы данных или хранилища данных может удовлетворить одну из наших потребностей в хранении и вычислениях.
Полуструктурированные данные обычно относятся к таким данным, как журналы и json. Хотя он имеет соответствующие поля и типы данных, он не является строгим.
Например, в json определенная строка данных может иметь на несколько полей меньше, а определенная строка данных может иметь еще несколько полей. Это не имеет значения.
Неструктурированные данные вообще не имеют структуры. Например, изображения, видео и аудио являются неструктурированными данными.
Неструктурированные и полуструктурированные данные обычно хранятся в базах данных NOSQL, но базы данных NOSQL только хранят данные и обычно не вычисляют их. Когда мы хотим вычислить эту часть данных, нам нужно написать несколько параллельных программ для чтения данных из базы данных NOSQL, а затем выполнить соответствующую обработку.
Итак, вы обнаруживаете, что для данных малого и среднего размера сейчас существуют очень зрелые технологии, которые могут помочь нам выполнить задачи хранения и вычислений.
Но как только данные достигают уровня массивности, например, они достигают 100 ТБ, 50 ПБ или даже выше. В это время мы обнаружили, что традиционная архитектура обработки данных создает некоторые узкие места.
2. Узкие места структурированных данных в традиционных методах обработки
Структурированные данные обычно существуют в отдельной базе данных. После резкого увеличения объема данных возникает вопрос, сможет ли их хранить одномашинная база данных. Даже если другой может удовлетворить требования к хранению, скорость его обработки и вычислений очень медленная.
В настоящее время, по мнению некоторых студентов, могут ли теперь отдельные базы данных образовывать кластер? Десятки баз данных образуют относительно большой кластер для унифицированного хранения и вычислений данных. Была ли эта проблема решена?
На самом деле такого понятия не существует. Эта архитектура, в которой несколько узлов работают вместе, называется архитектурой MPP. Однако эта архитектура MPP имеет проблему масштабируемости.
Поскольку он был разработан на основе автономной базы данных, он реализовал такой набор архитектуры, основанный на мозаике автономных баз данных. Таким образом, его производительность расширения все еще относительно ограничена.
Возьмем, к примеру, Oracle. После расширения до 30 единиц его больше нельзя будет расширить. Конечно, приведенный здесь пример неуместен, поскольку Oracle RAC, строго говоря, не является MPP. Однако все продукты с архитектурой MPP достигнут верхнего предела после достижения определенного количества узлов. После достижения верхнего предела размер данных превышает емкость хранилища, и завершить хранение невозможно.
Кроме того, у него также есть проблема с горячей точкой, и его горячие данные могут существовать на определенном узле. Тогда этот узел будет нести большее давление, и он легко зависнет, что окажет определенное влияние на нашу систему.
3. Узкие места неструктурированных и полуструктурированных данных в традиционных методах обработки.
Это более очевидно для неструктурированных полуструктурированных данных. Поскольку их данные хранятся в базе данных NOSQL, производительность масштабируемости базы данных NOSQL, как правило, очень хорошая, но база данных NOSQL отвечает только за хранение и, вообще говоря, не отвечает за вычисления.

При расчете нам необходимо написать вычислительные задачи для чтения данных из различных баз данных, передачи данных по сети к вычислительным узлам, а затем выполнения вычислений. После завершения расчета выводится результат расчета.
База данных NOSQL не имеет проблем с хранилищем. Однако, когда объем данных велик, они будут перемещаться по сети, что приведет к перегрузке сети. Например, для 100 ТБ данных можно предположить, что накладные расходы очень высоки.
Более того, когда выполняются наши вычислительные задачи, его эффективность также очень низка.
4. Первоначальное намерение и определение возникновения больших данных
Существует ли на данный момент полный набор решений, которые помогут нам хранить этот огромный объем структурированных, полуструктурированных и неструктурированных данных? Независимо от того, насколько велик масштаб, хранение может быть завершено. При расчетах на основе больших данных после хранения они также очень эффективны и могут иметь хорошую масштабируемость.
Есть ли такой план? Конечно, есть, это экосистема технологий больших данных.
Для больших данных существует относительно длинное и авторитетное определение.
большие данные означают выход за рамки традиционной базы сбор данных, инструменты, хранилище, набор данных для управления и аналитические возможности. В то же время новые технологии и возможности для своевременного сбора, хранения, агрегации, управления данными, а также углубленного анализа данных быстро растут, точно так же, как закон Мура предсказывает темпы роста вычислительных чипов.
— McKinsey Global InstituteНо подводя итог, можно сказать, что технологию больших данных можно описать одним предложением. Это технология или архитектура, специально разработанная для хранения и расчета данных после того, как они достигнут массового масштаба. Это базовое определение больших данных.
Характеристики сценария больших данных
В контексте больших данных они содержат некоторые основные характеристики. Другими словами, сценарии, соответствующие этим характеристикам, называются сценариями больших данных.
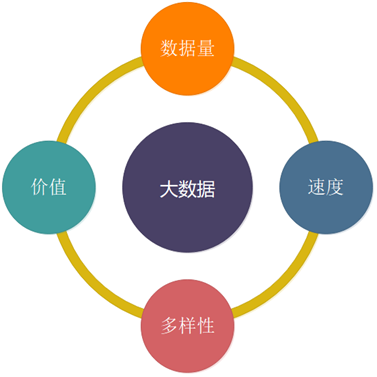
1. Большой объем данных (Объем)
Вообще говоря, первой характеристикой сценариев больших данных является огромный масштаб данных. Например, он достиг масштаба данных 10 ПБ или 50 ПБ. Данные огромны.
2. Скорость
Данные генерируются и обрабатываются быстро. Например, в 2017 году ежедневный прирост данных Ctrip составлял 100 ТБ, а резерв данных у платформы уже был 50 Пб. Таким образом, скорость генерации данных очень высокая.
Ежедневно генерируется очень много данных, и эти данные необходимо быстро обрабатывать. Поэтому существует также требование к скорости его обработки.
Это его вторая характеристика: скорость, которая включает в себя два измерения: скорость генерации данных и скорость обработки.
3. Разнообразие
Большие данные имеют дело со структурированными, неструктурированными и полуструктурированными данными.
А в эпоху Интернета на долю неструктурированных и полуструктурированных данных приходится более высокая доля. Например, логи и json — очень ценные данные. Изображения, видео и аудио представляют собой очень большие отдельные файлы, и объем генерируемых данных также должен быть очень большим.
Следовательно, не только структурированные данные, но также неструктурированные и полуструктурированные данные должны соответствовать требованиям к их хранению и расчетам. На этот раз отражается разнообразие данных.
4. Ценность
Вообще говоря, в сценариях с большими данными, когда данные достигают огромных объемов, ценность, полученная на основе этой части данных, должна быть выше, и из данных можно извлечь некоторые потенциальные закономерности для решения сложных проблем.
И ценность, которую приносит сочетание больших данных и искусственного интеллекта, должна быть огромной.
Но плотность его значений относительно невелика, поскольку плотность равна общей стоимости, деленной на количество данных. Хотя общая стоимость очень высока, объем ваших данных также увеличился и достиг огромных масштабов. Большой знаменатель эквивалентен разбавлению, и плотность его значения уменьшается.
Вообще говоря, сценарии, соответствующие этим четырем характеристикам, называются сценариями больших данных.
В переводе на английский язык все эти четыре характеристики начинаются с четырех слов, начинающихся с буквы V (объем, скорость, разнообразие, значение), поэтому мы также называем их характеристиками 4V или характеристиками 4V больших данных.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
