Почему после версии 2.8 Kafka отказался от использования ZooKeeper в качестве центра регистрации (подробное объяснение основных принципов архитектуры Kafka)?
Kafka — важный член очереди сообщений. Он широко используется в обработке больших данных, журналировании и других областях. В этой статье объясняется, почему Kafka отказался от использования ZooKeeper в качестве промежуточного программного обеспечения в базовой архитектуре после версии 2.8.
1. Функции очереди сообщений
Прежде всего, нам нужно понять, что такое очередь сообщений. Фактически, суть очереди сообщений — это уровень промежуточного программного обеспечения. Когда клиент взаимодействует с сервером, из-за слишком большого количества передаваемых сообщений сервер не может обработать. сообщения своевременно. В это время появилось сообщение Очередь. Это похоже на шкаф на вынос у входа в школу. Если сообщение приходит, оно не будет обработано немедленно, а будет обработано, когда сервер освободится. . Таким образом, очередь сообщений выполняет несколько основных функций:
(1) Асинхронная обработка:
Приложение A отправляет сообщение в очередь. Приложению B на сервере не требуется его обработка немедленно. Вместо этого оно может выбрать время, когда оно может свободно извлечь сообщение из очереди для обработки.
(2) Разделение приложений:
Если после того, как приложение A отправит сообщение в очередь, приложение B внезапно зависнет в это время, это не повлияет на дальнейшую обработку других служб приложением A.
(3) Ограничение пикового трафика:
Если в приложение A одновременно попадает большое количество запросов, приложению B не нужно обрабатывать большое количество запросов одновременно. Вместо этого оно может обрабатывать запросы со своей собственной скоростью в течение стабильного периода времени. :
2. Проанализируйте основные принципы архитектуры Kafka.
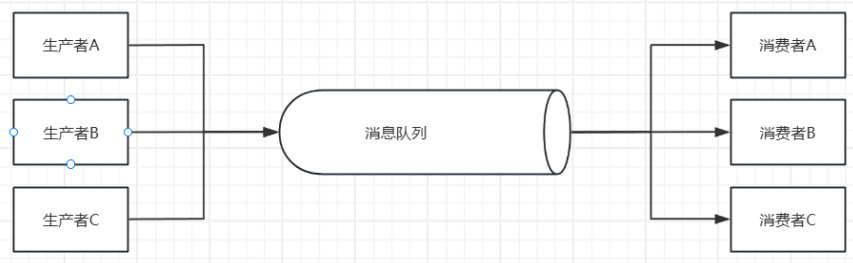
Во-первых, давайте начнем с самой простой очереди сообщений:

Легко понять, что очередь сообщений здесь является средним уровнем, используемым для координации служебной связи между производителем A и потребителем B. Однако для такого промежуточного программного обеспечения было бы немного расточительно иметь только одного производителя и потребителя, поэтому мы подумал о том, чтобы позволить нескольким производителям и нескольким потребителям использовать очередь сообщений одновременно:
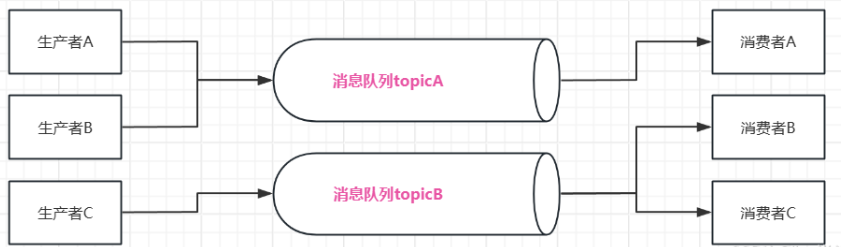
Хотя это увеличивает доступность очереди сообщений, несколько производителей и потребителей будут одновременно конкурировать за очередь сообщений, что приводит к ожиданию. Затем мы можем разделить разные типы сообщений на разные очереди в соответствии с разными типами сообщений, обычно называемыми темами.
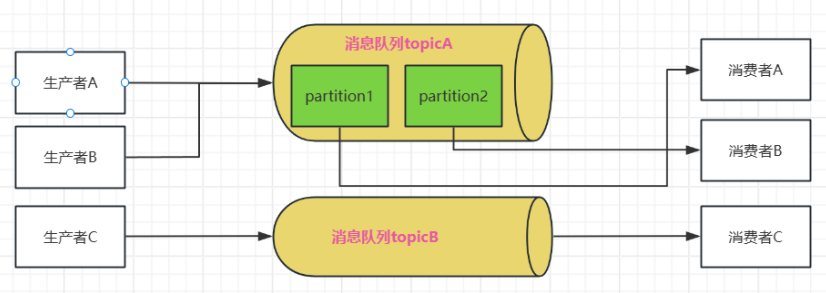
Однако, если емкость очереди сообщений слишком велика, она все равно будет работать очень медленно, когда потребитель захочет получить определенную часть сообщения. Тогда мы можем разделить очередь сообщений на разные разделы и позволить каждому потребителю отвечать за конкретную часть сообщения. раздел:
Однако если развертывание всех разделов на одной машине приведет к слишком высокой нагрузке на одну машину, мы можем развернуть разные разделы на нескольких машинах, где каждая машина называется брокером:
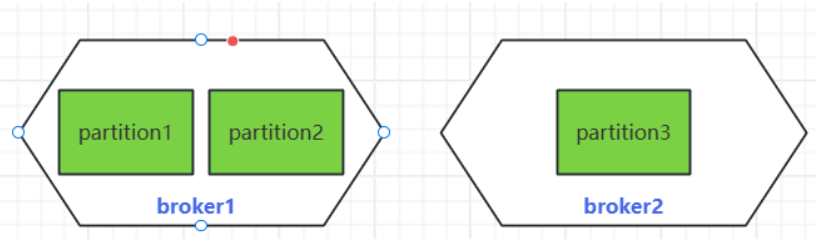
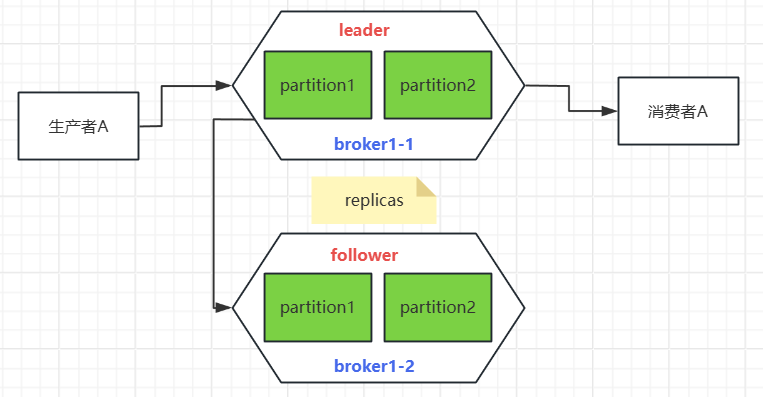
Но что, если хост, на котором расположен брокер, зависнет, что приведет к потере содержащихся в нем сообщений? Ничего страшного, если сделать больше копий, мы можем просто добавить еще несколько копий в каждый раздел. и одновременно установите ведущий узел и ведомый узел, за который отвечает лидер. Производители и потребители пересылают сообщения, а последователям нужно только синхронизировать информацию о лидере. Таким образом, даже если лидер главного узла умирает, следующий последователь может быть выбран в качестве нового главного узла для повышения надежности и улучшения отношений между лидером и последователем. Синхронизация. между репликами также называется репликами:
Однако, если мы рассмотрим экстремальную ситуацию, когда все брокеры зависнут, не будет ли это означать, что данные полностью потеряны? Не бойтесь, мы можем определить стратегию сохранения (данные никогда не будут потеряны после сохранения) и сохранять сохраненные сообщения на диск, чтобы даже в случае перезагрузки компьютера данные не были потеряны, и их нужно было только читать и записывать с диска.
На этом этапе общая базовая архитектура Kafka объяснена, поэтому возникает вопрос. Поскольку версия Kafka до версии 2.8 зависит от ZooKeeper, какие функции нужны ZooKeeper?
3. Кафка использует ZooKeeper
Мы видим, что, поскольку Kafka распределяет очередь сообщений на несколько разделов и разворачивает их на нескольких машинах, если приходит потребитель и хочет получить сообщение, он должен получить IP-адрес хоста, на котором расположен соответствующий раздел раздела. Как это сделать. мы поняли? В программу прописать IP-адрес нельзя. В этом случае для выполнения аналогичных функций необходим центр регистрации.
Функции регистрационного центра:
Регистрация услуги:
В распределенной системе каждый экземпляр службы при запуске регистрируется в центре регистрации, включая адрес службы, порт, номер версии и другую информацию. Таким образом, реестр может поддерживать каталог всех доступных на данный момент экземпляров службы.
Обнаружение службы:
Когда клиенту или другой службе необходимо вызвать службу, он может запросить все доступные экземпляры службы через центр регистрации. Реестр предоставляет механизм, позволяющий потребителям услуг находить поставщиков услуг.
Балансировка нагрузки:
Центр регистрации обычно используется вместе с балансировщиком нагрузки, который может распределять запросы по различным экземплярам службы на основе информации, предоставленной центром регистрации, для достижения балансировки нагрузки. Общие алгоритмы балансировки нагрузки включают опрос, последовательное хеширование, случайное взвешивание и т. д.
Отказоустойчивость и отказоустойчивость:
Когда экземпляр службы недоступен, реестр может помочь клиенту или балансировщику нагрузки перенаправить запросы к другим исправным экземплярам службы, тем самым повышая отказоустойчивость системы.
Управление конфигурацией:
В некоторых архитектурах реестр также можно использовать для управления и распространения информации о конфигурации, позволяя экземплярам службы динамически корректировать свое поведение в соответствии с конфигурацией.
Проверка здоровья:
Центр регистрации может сотрудничать с механизмом проверки работоспособности, чтобы регулярно проверять состояние работоспособности экземпляров службы и своевременно удалять неработоспособные экземпляры для обеспечения качества обслуживания.
В качестве своего рода центра регистрации Kafka использует ZooKeeper в качестве центра регистрации для упрощения управления различными компонентами. В процессе управления ZooKeeper будет регулярно взаимодействовать с каждым компонентом. Если текущий компонент зависнет, он будет перемещен. текущий брокер, чтобы гарантировать статус обслуживания кластера Kafka
Видя это, мы должны задуматься, а не слишком ли хорош ZooKeeper как центр регистрации кластера Kafka. Тогда почему от него стоит отказаться? Причина в том, что ZooKeeper слишком тяжел как центр регистрации, и многие функции в нем не используются? Да, это также увеличит затраты на обслуживание и использование ресурсов. Например:
ZooKeeper обладает сильными функциями согласованности, и ZooKeeper также развертывается на основе распределения. То есть, если информация одного узла изменяется, информация другого узла также должна быть изменена одновременно. Если объем данных небольшой, скорость синхронизации высокая. приемлемо, но если в сценарии большого объема данных скорость синхронизации будет немного неудовлетворительной, а механизм выбора ZooKeeper также замедлит производительность кластера Kafka. Поэтому для Kafka естественно отказаться от ZooKeeper.
4. Крафт-режим после версии 2.8
В версии Kafka 2.8.0 представлены новые функции, основанные на протоколе консенсуса Raft. Из-за ограниченного пространства друзья, желающие разобраться в протоколе Raft, могут узнать о нем самостоятельно. Это позволяет кластеру Kafka работать без ZooKeeper. следующее:
Упрощенное развертывание:
Кластер Kafka больше не зависит от внешних кластеров ZooKeeper, что упрощает развертывание, эксплуатацию и обслуживание.
Улучшите производительность:
Поскольку управление метаданными больше не зависит от ZooKeeper, производительность кластеров Kafka была улучшена, особенно с точки зрения чтения и записи метаданных.
Повышение масштабируемости:
Режим KRaft поддерживает кластеры большего размера и может эффективно масштабироваться до миллионов разделов.
Более быстрое переключение контроллера при отказе:
Выбор контроллера и отработка отказа выполняются быстрее, что повышает стабильность кластера.
В режиме KRaft некоторые узлы в кластере kafka обозначены как контроллеры (Controllers), которые отвечают за управление метаданными и службы консенсуса кластера. Все метаданные хранятся в топике внутри kafka, а не в ZooKeeper. Контроллер передает KRaft. протокол обеспечивает точную репликацию метаданных в кластере. Этот режим использует модель хранения на основе времени, чтобы гарантировать, что журнал метаданных не будет бесконечно расти за счет регулярных снимков.
Подводя итог, это конец знакомства с базовой архитектурой Kafka и причинами, по которым ZooKeeper был заброшен в версии 2.8. Если вы найдете здесь что-то полезное, возможно, вам это понравится и сохраните. ! !



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
