Почему оконные функции более склонны к проблемам с производительностью? —— Случай оптимизации
Наши текущие данные могут легко достигать десятков миллиардов, а поля часто могут представлять собой огромные строки JSON. Повсюду существуют неизлечимые проблемы. Поэтому мы каждый день отчаянно изучаем эти принципы и ищем методы оптимизации.
Фактически, эта статья основана на одном из моих предыдущих случаев оптимизации:
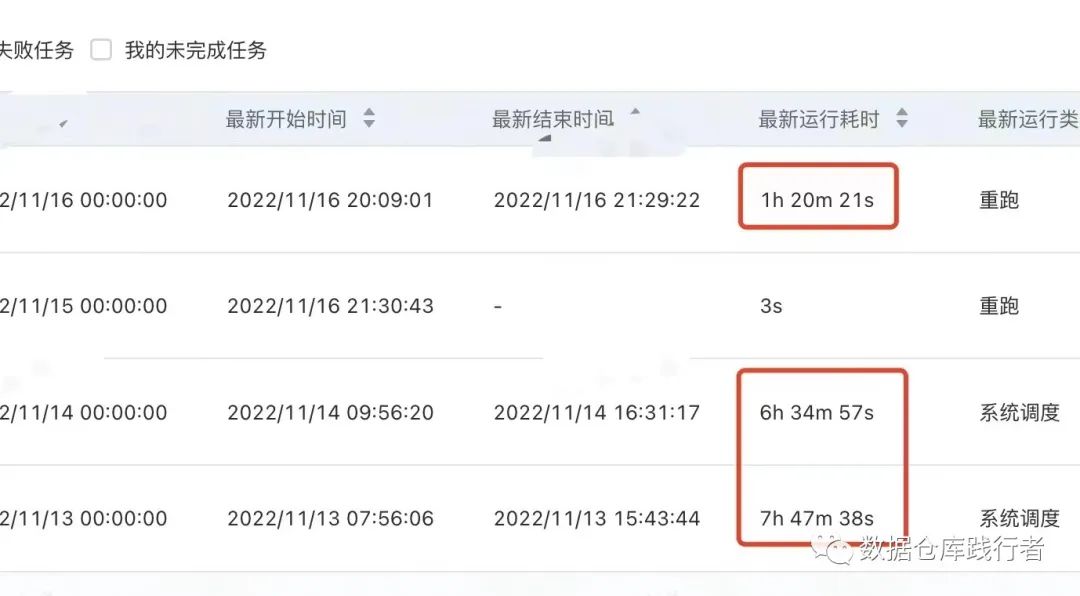
Эффект оптимизации очевиден, но метод очень прост. Трудность заключается в понимании использования памяти оконными функциями.
В этой статье мы поговорим о том, почему оконные функции более склонны к проблемам с производительностью с точки зрения обработки памяти.
Если вам кажется, что эта статья сложна для понимания, я уже давно обобщил некоторые моменты, связанные с оконными функциями. Эти знания все еще применимы и сейчас. Пожалуйста, сначала посмотрите:
Обзор принципов реализации оконных функций в Spark и Hive
Анализ исходного кода оконной функции SparkSql (часть 1)
Hive Анализ исходного кода оконной функции SQL
SparkSQL более оптимизирован, чем HiveSQL (оконная функция)
Выполнение оконных функций обходится дороже, чем выполнение обычных агрегатных функций. Почему?
- Обычные операторы агрегатной функции могут выполняться в режиме частичного + слияния в зависимости от функции, то есть предварительной агрегации на стороне карты, тогда как операторы окна должны быть агрегированы все сразу на стороне сокращения, то есть только в режиме полного выполнения;
- Планы физического выполнения обычных агрегатных функций делятся на SortBased и HashBased, тогда как все окна являются SortBased;
- Оператор окна работает с несколькими строками и возвращает агрегированный результат для каждой строки, что определяет, что окну требуется больший буфер для агрегирования во время выполнения.
Вход в логику обработки оконной функции в Spark находится в классе WindowExec. В этом классе мы видим, что ExternalAppendOnlyUnsafeRowArray — это структура кэша, используемая оконной функцией для хранения данных в каждом окне:
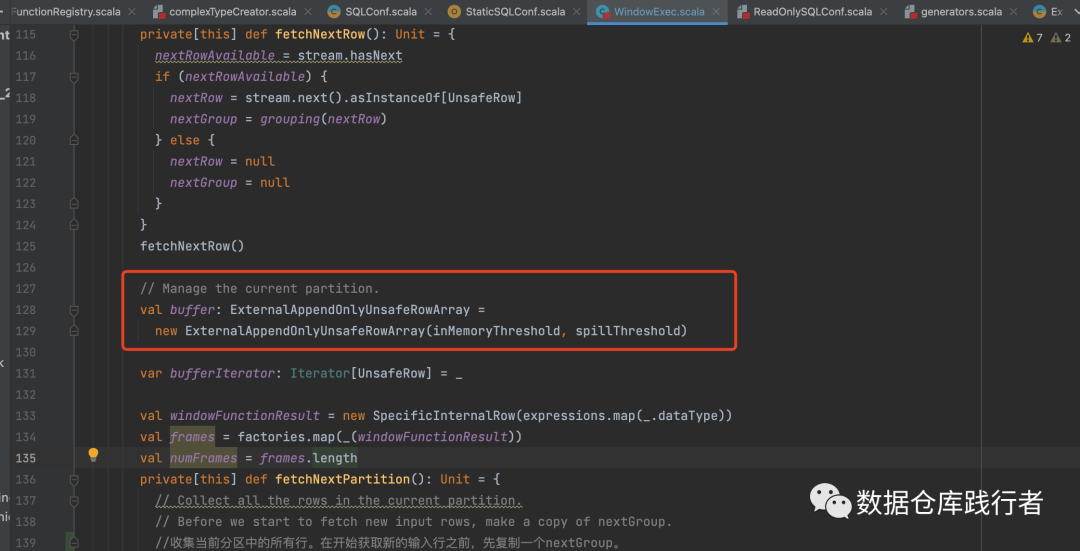
Есть два параметра:
1、spark.sql.windowExec.buffer.in.memory.threshold
Управляет объемом данных, помещаемых в ExternalAppendOnlyUnsafeRowArray. Значение по умолчанию — 4096. Когда это количество строк будет превышено, оно будет преобразовано в UnsafeExternalSorter. Если этот параметр установлен слишком большим, он будет занимать слишком много памяти.
val WINDOW_EXEC_BUFFER_IN_MEMORY_THRESHOLD =
buildConf("spark.sql.windowExec.buffer.in.memory.threshold")
.internal()
.doc("Threshold for number of rows guaranteed to be held in memory by the window operator")
.version("2.2.1")
.intConf
.createWithDefault(4096)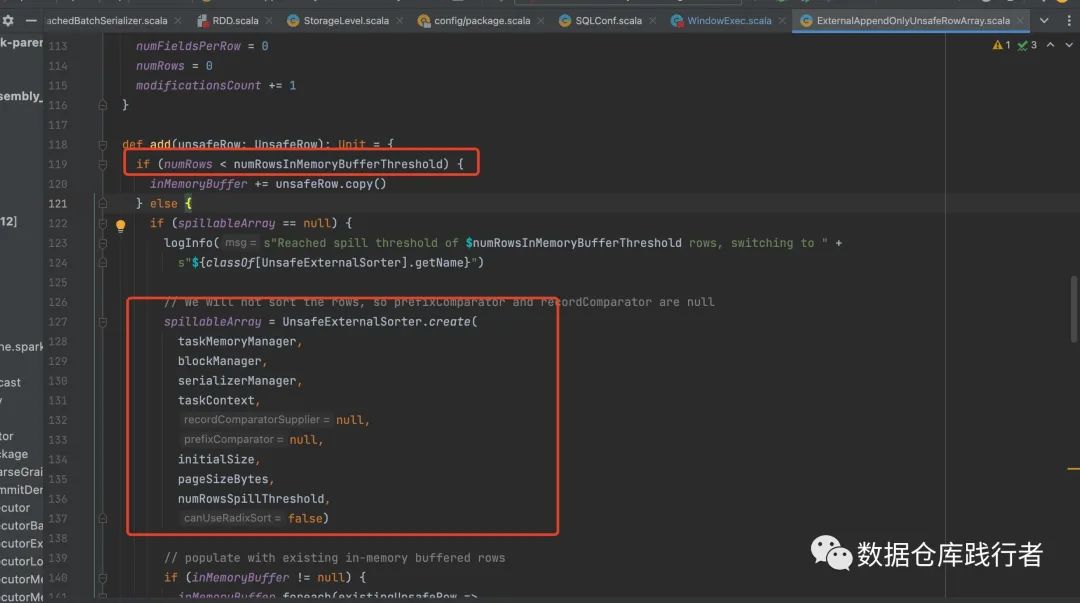
2、spark.sql.windowExec.buffer.spill.threshold
Когда ExternalAppendOnlyUnsafeRowArray преобразуется в UnsafeExternalSorter, когда количество элементов данных в UnsafeExternalSorter превышает пороговое значение, представленное этим параметром, Spark записывает данные на диск. Значение по умолчанию — Integer.MAX_VALUE. Если это значение установлено слишком низким, данные будут часто переполняться и вызывать чрезмерную запись на диск, что приведет к снижению производительности.
val WINDOW_EXEC_BUFFER_SPILL_THRESHOLD =
buildConf("spark.sql.windowExec.buffer.spill.threshold")
.internal()
.doc("Threshold for number of rows to be spilled by window operator")
.version("2.2.0")
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
private[spark] val SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD =
ConfigBuilder("spark.shuffle.spill.numElementsForceSpillThreshold")
.internal()
.doc("The maximum number of elements in memory before forcing the shuffle sorter to spill. " +
"By default it's Integer.MAX_VALUE, which means we never force the sorter to spill, " +
"until we reach some limitations, like the max page size limitation for the pointer " +
"array in the sorter.")
.version("1.6.0")
.intConf
.createWithDefault(Integer.MAX_VALUE)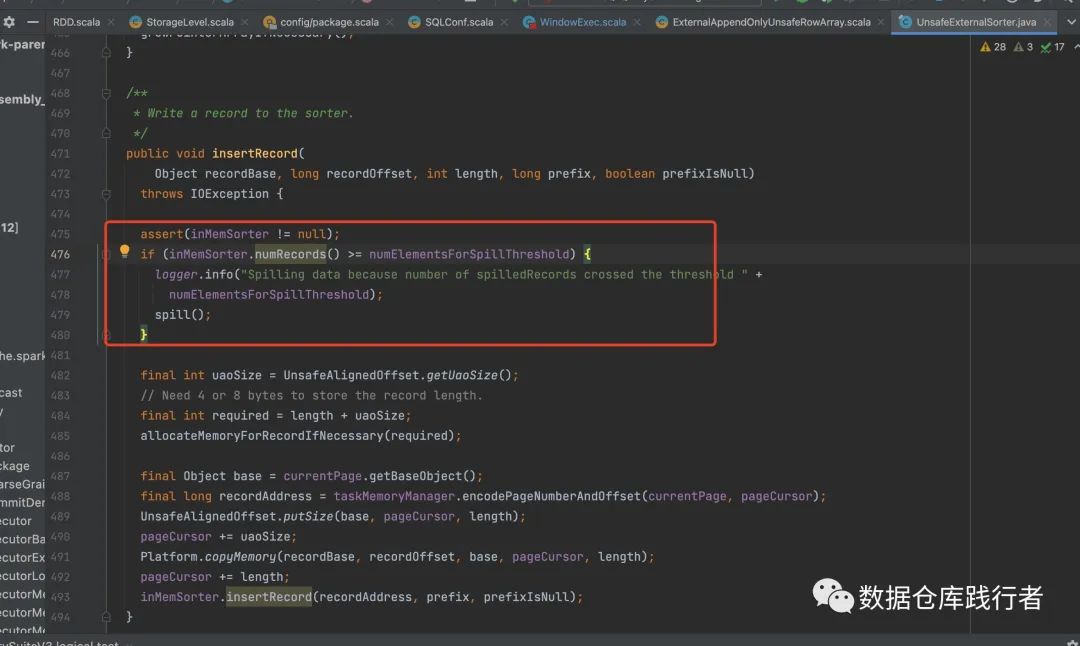
PS: На самом деле значение Integer.MAX_VALUE равно 21474836473. Это значение уже очень велико. В обычных обстоятельствах количество элементов данных в окне трудно превысить 20 миллиардов+. Если элементов так много, данные будут. быть правильно перекошенным.
Когда ExternalAppendOnlyUnsafeRowArray преобразуется в UnsafeExternalSorter,Здесь есть еще одна вещь,Определяет, должен ли UnsafeExternalSorter перегружать данные на диск.,Кромеspark.sql.windowExec.buffer.spill.threshold Помимо этого условия, есть еще одно условие: То есть можно ли выделить достаточно места для UnsafeInMemorySorter.
UnsafeExternalSorter использовать UnsafeInMemorySorter Чтобы реализовать сортировку в памяти, аналогичную массиву указателей сортировки, можно использовать ExternalAppendOnlyUnsafeRowArray. По умолчанию этот массив1Mкосмос,Если оно закончится,Его необходимо расширить,Если нет возможности расширения,Требуется перезапись.
Конкретный код для определения необходимости перезаписи выглядит следующим образом:
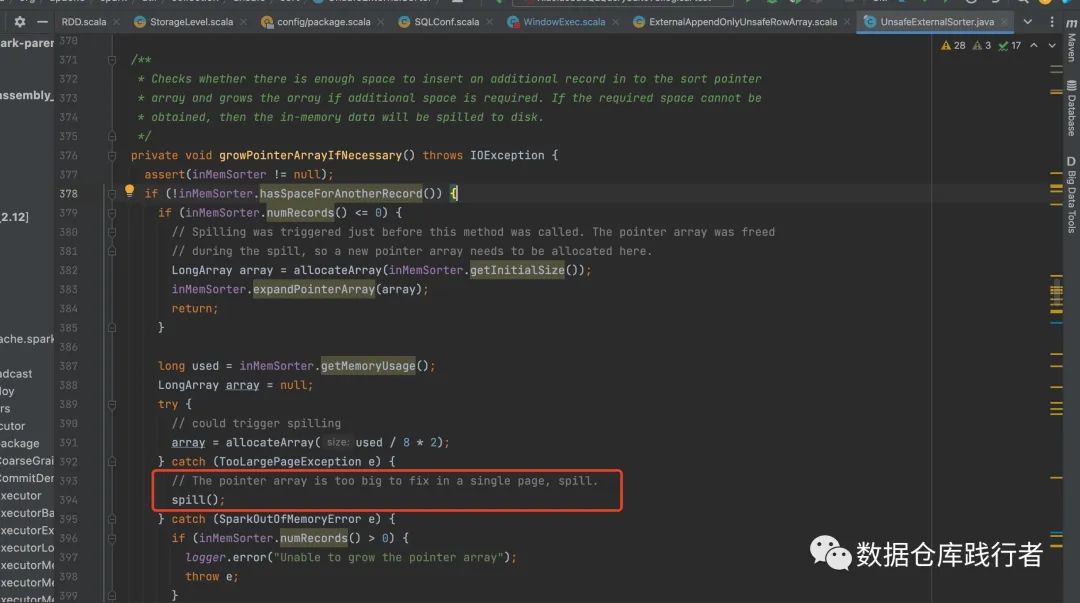
Так что, слушай, всё дело в памяти~
Если памяти недостаточно, она часто переполняется. Результатом частого переполнения является слишком много операций ввода-вывода, что влияет на эффективность. Если ситуация более серьезная, это может вызвать ООМ (поскольку Spark получает используемую память путем случайной выборки. Это может быть). из-за объёма данных Большая и неточная выборка, невозможность разлить вовремя, что приводит к ООМ)
Итак, каково решение этой проблемы?
Самый простой способ — увеличить память Исполнителя и увеличить количество разделов, чтобы каждый раздел обрабатывал меньше данных.
Однако мы знаем, что количество памяти и разделов Исполнителя не может быть увеличено без ограничений. Добавление слишком большого количества памяти приведет к очень низкому использованию памяти всей задачей, поскольку другая логическая обработка в SQL может не использовать столько памяти, и количество разделов. Слишком большое его увеличение может также вызвать другие проблемы с производительностью.
Поэтому есть другой способ оптимизировать написание SQL. В SQL, который содержит оконную функцию, не добавляйте слишком много столбцов, не связанных с оконной функцией, особенно больших полей, которые занимают много памяти. можно вынести отдельно, дождаться расчета оконной функции, а затем снова связать ее. Псевдокод следующий:
SELECT xx,
a,
b,
c,
d,
....,
row_number() OVER(
PARTITION BY
xxid,
xxid,
xxid
ORDER BY
xx ASC
) AS rn
FROM tablex
-----------------------------------------------------------
select
window_info.*,
other_info.*
from
(SELECT
id,
row_number() OVER(
PARTITION BY
xxid,
xxid,
xxid
ORDER BY
xx ASC
) AS rn
FROM tablex) window_info
left join
(
select
id,
....
from tablex
) other_info on ..Что необходимо отметить: при дизассемблировании логики необходимо обеспечить уникальность связанного ключа. Лучше всего группировать по ключу, либо использовать другие методы для его обеспечения.
——Основная идея по-прежнему — разделяй и властвуй! ! !
С 18 декабря, после окончания последнего второго курса по исходному коду sparksql, всё словно зашло в тупик.
Жизнь застойна, технологическое развитие застойно, танцы застойны...
Несколько дней назад я думал, что собирать песок в башню — это слишком медленно, но теперь я могу наслаждаться процессом замедления, чтобы в будущем иметь возможность бежать с большей энергией.
Тихо наслаждаюсь этим застоем в эти дни
Наслаждайтесь возможностью регулировать все свои состояния прямо сейчас.
Я благодарен вам, кто все еще ждет и сопровождает меня.
В новом году я начну снова и наберусь уверенности, чтобы записать много новых надежд.
Спустя годы третья фаза исходного кода sparksql продолжится, и маленький кнут снова будет поднят.
Интенсивное чтение исходного кода — эффективный способ развития экспертных знаний~~
Если вы хотите развить свои сильные стороны
Увеличьте свое влияние на рабочем месте за счет своих сильных сторон
Но не знаю, как начать
Или не уверен в себе
Добро пожаловать в сообщество по изучению исходного кода, которое я основал (платно)
Содержание интенсивного чтения:Путь к тому, чтобы стать богом с исходным кодом SparkSql



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
