Плавный переход от одной базы данных и одной таблицы к подбазе данных и подтаблицам.
фон
Далее мы будем использовать электронную коммерцию в качестве примера.
бизнес-перспектива
На заре существования бизнеса база данных была в основном реализована с одной базой данных и одной таблицей, что могло быстро поддерживать бизнес методом проб и ошибок, сводя при этом к минимуму затраты на ресурсы. Однако по мере того, как бизнес продолжает развиваться, количество данные также будут расти в геометрической прогрессии, в конечном итоге вы обнаружите, что одна база данных и одна таблица не могут поддерживать быстрое развитие бизнеса, поэтому существующую архитектуру базы данных необходимо обновить.
техническая перспектива
Согласно предыдущему опыту, одна таблица может поддерживать до 2000 Вт данных. Если объем данных продолжит увеличиваться, это повлияет на эффективность чтения и записи, и необходимо преобразовать одну базу данных и одну таблицу в таблицы подбазы данных. .
Проблемы с одной базой данных и одной таблицей:
- Узкое место в производительности:По мере увеличения объема данных,Производительность чтения и запросов к базе данных будет постепенно снижаться. Особенно, когда количество строк данных в таблице достигает миллионов и более.,Даже простые операции запроса могут стать очень медленными.
- Горячие точки данных:Все операции с данными сосредоточены в одной таблице в одной базе данных.,легко формировать Горячие точки данных, из-за чего некоторые строки данных становятся частым доступом и становятся Узкое место в производительности
- Проблемы высокой доступности и аварийного восстановления:Трудно добиться высокой доступности и аварийного восстановления с помощью единой базы данных и архитектуры одной таблицы.。Как только база данных выйдет из строя,Это повлияет на все приложение. и,Восстановление данных занимает больше времени,Влияет на нормальную работу бизнеса.
- Проблемы масштабируемости:По мере развития бизнеса,Объем данных и доступ продолжают расти,Архитектуру одной базы данных и одной таблицы сложно удовлетворить потребностям путем простого расширения. Как горизонтальное расширение (добавление дополнительных серверов), так и вертикальное расширение (обновление существующего серверного оборудования) имеют ограничения.
- Управление транзакциями и конфликты блокировок:В ситуациях с высоким параллелизмом,Большое количество транзакций и операций с базой данных может привести к проблемам блокировки блокировок.,Влияет на возможности обработки базы данных.
- Сложности резервного копирования и обслуживания:По мере увеличения объема данных,Сложность и временные затраты на резервное копирование и обслуживание базы данных также значительно возрастут.
Процесс обновления архитектуры
ссылка:Процесс эволюции архитектуры базы данных
Здесь мы непосредственно достигаем цели за один шаг: от единой базы данных и одной таблицы до вертикального вывода из эксплуатации и горизонтального разделения таблиц.
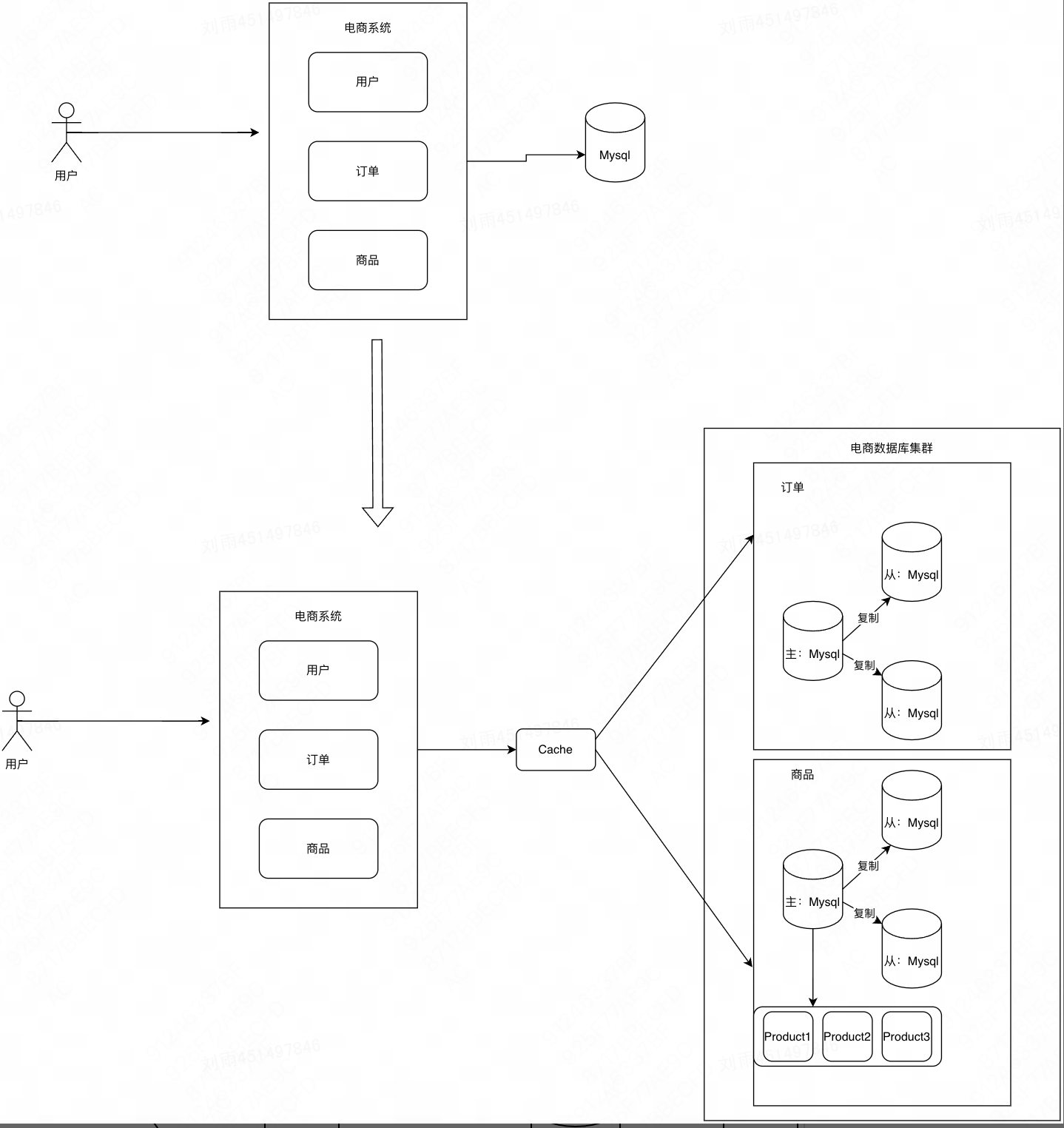
Процесс миграции
Краткое описание сценария
старые и новые данные | читать | Писать |
|---|---|---|
старые данные | да | да |
старые данные | да | да |
шаги миграции
- Возможность реализации чтения и записи новых данных.
- Реализуйте синхронизацию старых данных с новыми данными (путем мониторинга binlog).
- Реализуйте синхронизацию новых данных со старыми (путем мониторинга binlog).
- Начать новые данные в оттенках серого читать
- После прочтения всего объема новых данных закройте старые. данныеизчитать
- Начать новые данные в оттенках серого Писать
- После полного объема новых данных Писать, закройте старые данные Писать.
- После стабильной работы в сети в течение определенного периода времени отключите синхронизацию старых и новых данных.
- Архивстарые данные,офлайнстарые данные
До миграции
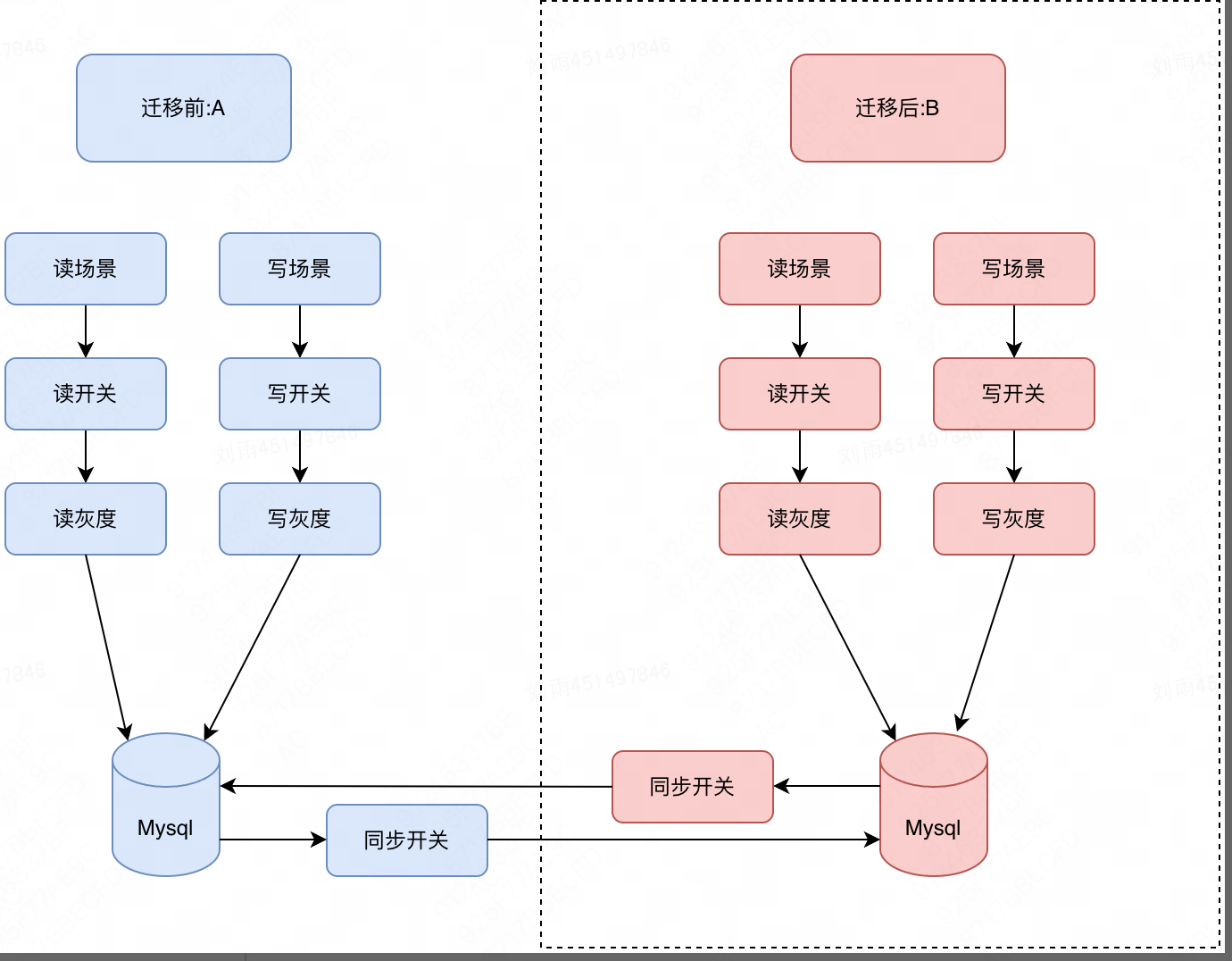
Миграция
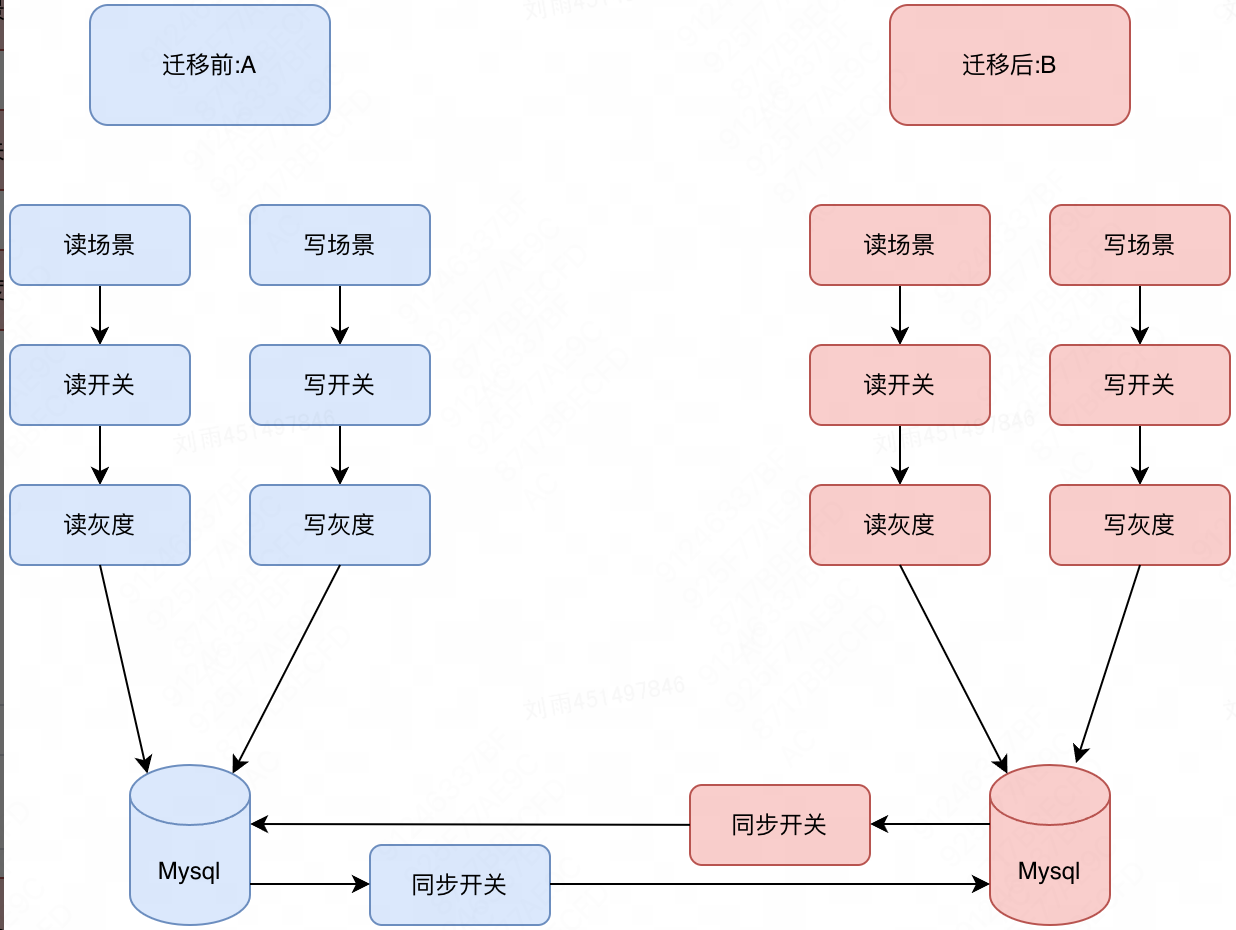
После миграции
Подвести итог
С тех пор архитектура базы данных была обновлена. миграциисередина,Придерживаясь стратегической концепции минимального воздействия на бизнес,Наконец, данные и функции можно плавно перенести в новую архитектуру базы данных. Значительно улучшить масштабируемость и пропускную способность системы.,Может эффективно поддерживать быстрое развитие бизнеса



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
