Платформа потокового озера данных Apache Paimon (2) интегрирует движок Flink
Глава 2. Интеграция Flink Engine
Paimon в настоящее время поддерживает Flink 1.17, 1.16, 1.15 и 1.14. В этом курсе используется Flink 1.17.0.
2.1 Подготовка среды
Экологическая подготовка
2.1.1 Установите Флинк
1) Загрузите и распакуйте установочный пакет Flink.
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
2) Настройте переменные среды
sudo vim /etc/profile.d/my_env.sh
export HADOOP_CLASSPATH=hadoop classpath
source /etc/profile.d/my_env.sh
2.1.2 Загрузка jar-пакета
1) Загрузите и загрузите jar-пакет Paimon.
Адрес загрузки пакета Jar: https://repository.apache.org/snapshots/org/apache/paimon/paimon-flink-1.17/0.5-SNAPSHOT/
2) Скопируйте jar-пакет paimon в каталог lib на flink.
cp paimon-flink-1.17-0.5-20230703.002437-67.jar /opt/module/flink-1.17.0/lib
2.1.3 Запуск Hadoop
(немного)
2.1.4 Запуск sql-клиента
1) Измените конфигурацию flink-conf.yaml.
vim /opt/module/flink-1.16.0/conf/flink-conf.yaml
#Чтобы устранить искаженные китайские символы, параметр перед версией 1.17 равен env.java.opts.
env.java.opts.all: -Dfile.encoding=UTF-8
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4
execution.checkpointing.interval: 10s
state.backend: rocksdb
state.checkpoints.dir: hdfs://hadoop102:8020/ckps
state.backend.incremental: true
2) Запустите кластер Flink.
(1) Решение проблем зависимости
cp /opt/module/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar /opt/module/flink-1.17.0/lib/
(2) Здесь в качестве примера мы возьмем режим Yarn-Session.
/opt/module/flink-1.17.0/bin/yarn-session.sh -d
3) Запустите sql-клиент Flink.
/opt/module/flink-1.17.0/bin/sql-client.sh -s yarn-session

4) Установите режим отображения результатов
SET ‘sql-client.execution.result-mode’ = ‘tableau’;
2.2 Catalog
Каталог Paimon может сохранять метаданные и в настоящее время поддерживает два типа метахранилищ:
Файловая система (по умолчанию). Храните метаданные и файлы таблиц в файловой системе.
hive: хранить метаданные в метахранилище hive. Пользователи могут получать доступ к таблицам непосредственно из Hive.
2.2.1 Файловая система
CREATE CATALOG fs_catalog WITH (
‘type’ = ‘paimon’,
‘warehouse’ = ‘hdfs://hadoop102:8020/paimon/fs’
);
USE CATALOG fs_catalog;
2.2.2 Hive Catalog
При использовании каталога Hive изменения в каталоге будут напрямую влиять на соответствующее метахранилище куста. К таблицам, созданным в таких каталогах, также можно получить доступ непосредственно из Hive.
Чтобы использовать каталог Hive, имена баз данных, имена таблиц и имена полей должны быть написаны строчными буквами.
1) Загрузите hive-коннектор
Восходящий поток flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar в каталог lib Flink
2) Перезапустите кластер пряжи-сессии.
3) Запустите службу метахранилища hive.
nohup hive --service metastore &
4) Создать улей Catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://hadoop102:9083',
'hive-conf-dir' = '/opt/module/hive/conf',
'warehouse' = 'hdfs://hadoop102:8020/paimon/hive'
);USE CATALOG hive_catalog;
5) На что следует обратить внимание
См. HIVE-17832 при использовании каталога Hive для изменения несовместимых типов столбцов с помощью таблицы изменения. Требуется настройка
vim /opt/module/hive/conf/hive-site.xml;
<property>
<name>hive.metastore.disallow.incompatible.col.type.changes</name>
<value>false</value>
</property>Приведенную выше конфигурацию необходимо настроить в файле hive-site.xml и перезапустить службу метахранилища hive.
Если вы используете Hive3, отключите Hive ACID:
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
2.2.3 файл инициализации sql
1) Создайте sql-файл инициализации.
vim conf/sql-client-init.sql
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://hadoop102:8020/paimon/fs'
);
CREATE CATALOG hive_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://hadoop102:9083',
'hive-conf-dir' = '/opt/module/hive/conf',
'warehouse' = 'hdfs://hadoop102:8020/paimon/hive'
);
USE CATALOG hive_catalog;
SET 'sql-client.execution.result-mode' = 'tableau';2) При запуске sql-клиента указываем файл инициализации sql
bin/sql-client.sh -s yarn-session -i conf/sql-client-init.sql
3) Посмотреть каталог
show catalogs;
show current catalog;
2.3 DDL
2.3.1 Создать таблицу
2.3.1.1 Таблица управления
Таблица, созданная в каталоге Paimon, является таблицей управления Paimon и управляется каталогом. Когда таблица удаляется из каталога, ее файлы таблицы также будут удалены, аналогично внутренним таблицам Hive.
1) Создать таблицу
CREATE TABLE test (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);2) Создать таблицу разделов
CREATE TABLE test_p (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);Настроив раздел part.expiration-time, разделы с истекшим сроком действия можно автоматически удалять.
Если определен первичный ключ, поля секционирования должны быть подмножеством первичного ключа.
Следующие три типа полей можно определить как поля разделов:
Время создания (рекомендуется). Время создания обычно неизменяемо, поэтому его можно смело рассматривать как поле секционирования и добавлять к первичному ключу.
Время события. Время события — это поле в исходной таблице. Для данных CDC, таких как таблицы, синхронизированные с MySQL CDC, или журналы изменений, созданные Paimon, они представляют собой полные данные CDC, включая записи UPDATE_BEFORE, и уникальные эффекты могут быть достигнуты, даже если вы объявите первичный ключ, содержащий поле раздела.
CDC op_ts: не может быть определен как поле раздела, и не может быть известна отметка времени предыдущей записи.
3)Create Table As
Таблицы можно создавать и заполнять на основе результатов запросов. Например, у нас есть такой sql: CREATE TABLE table_b AS SELECT id, имя FORM table_a. Созданная таблица table_b будет эквивалентна следующему оператору для создания таблицы и вставки. данные: CREATE TABLE table_b (id INT, имя STRING); INSERT INTO table_b SELECT id, имя FROM table_a;
При использовании CREATE TABLE AS SELECT мы можем указать первичный ключ или раздел.
CREATE TABLE test1(
user_id BIGINT,
item_id BIGINT
);
CREATE TABLE test2 AS SELECT * FROM test1;
– Укажите раздел
CREATE TABLE test2_p WITH (‘partition’ = ‘dt’) AS SELECT * FROM test_p;
– Укажите конфигурацию
CREATE TABLE test3(
user_id BIGINT,
item_id BIGINT
) WITH (‘file.format’ = ‘orc’);
CREATE TABLE test3_op WITH (‘file.format’ = ‘parquet’) AS SELECT * FROM test3;
– Укажите первичный ключ
CREATE TABLE test_pk WITH (‘primary-key’ = ‘dt,hh’) AS SELECT * FROM test;
– Укажите первичный ключи Раздел
CREATE TABLE test_all WITH (‘primary-key’ = ‘dt,hh’, ‘partition’ = ‘dt’) AS SELECT * FROM test_p;
4)Create Table Like
Создайте таблицу с той же схемой, секционированием и свойствами таблицы, что и у другой таблицы.
CREATE TABLE test_ctl LIKE test;
5) Атрибуты таблицы
Пользователи могут указать свойства таблицы, чтобы включить функциональные возможности Paimon или повысить производительность Paimon. Полный список таких свойств см. в разделе «Конфигурации»: https://paimon.apache.org/docs/master/maintenance/configurations/.
CREATE TABLE tbl(
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh)
WITH (
'bucket' = '2',
'bucket-key' = 'user_id'
);2.3.1.2 Внешние таблицы
Внешние таблицы записываются, но не управляются Каталогом. Если внешняя таблица удалена, ее файлы таблицы не будут удалены, как и внешняя таблица Hive.
Внешние таблицы Paimon можно использовать в любом каталоге. Если вы не хотите создавать каталог Paimon и хотите просто читать/записывать таблицу, вы можете рассмотреть возможность создания внешней таблицы.
CREATE TABLE ex (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'path' = 'hdfs://hadoop102:8020/paimon/external/ex',
'auto-create' = 'true'
);2.3.1.3 Временная таблица
Только Flink поддерживает временные таблицы. Как и внешние таблицы, временные таблицы представляют собой просто записи, но не управляются текущим сеансом Flink SQL. Если временная таблица удалена, ее ресурсы не будут удалены. Когда сеанс Flink SQL закрывается, временная таблица также удаляется. Отличие от внешних таблиц в том, что в Каталоге Paimon создаются временные таблицы.
Если вы хотите использовать Каталог Paimon с другими таблицами, но не хотите хранить их в других каталогах, вы можете создать временные таблицы.
USE CATALOG hive_catalog;
CREATE TEMPORARY TABLE temp (
k INT,
v STRING
) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://hadoop102:8020/temp.csv',
'format' = 'csv'
);2.3.2 Изменение таблицы
2.3.2.1 Изменение таблицы
1) Изменить/добавить свойства таблицы
ALTER TABLE test SET (
‘write-buffer-size’ = ‘256 MB’
);
2) Переименуйте имя таблицы.
ALTER TABLE test1 RENAME TO test_new;
3) Удалить атрибуты таблицы
ALTER TABLE test RESET (‘write-buffer-size’);
2.3.2.2 Изменение столбцов
1) Добавить новый столбец
ALTER TABLE test ADD (c1 INT, c2 STRING);
2) Переименуйте имена столбцов.
ALTER TABLE test RENAME c1 TO c0;
3) Удалить столбцы
ALTER TABLE test DROP (c0, c2);
4) Изменить обнуляемость столбца
CREATE TABLE test_null(
id INT PRIMARY KEY NOT ENFORCED,
coupon_info FLOAT NOT NULL
);
– Столбец купон_информация изменен, чтобы разрешить нулевое значение.
ALTER TABLE test_null MODIFY coupon_info FLOAT;
– Столбец купон_информация изменен, чтобы не допускать значение null.
– Если в таблице уже есть нулевое значение, установите следующие параметры, чтобы удалить нулевое значение перед его изменением.
SET ‘table.exec.sink.not-null-enforcer’ = ‘DROP’;
ALTER TABLE test_null MODIFY coupon_info FLOAT NOT NULL;
5) Изменить комментарии столбца
ALTER TABLE test MODIFY user_id BIGINT COMMENT ‘user id’;
6) Добавьте позицию столбца
ALTER TABLE test ADD a INT FIRST;
ALTER TABLE test ADD b INT AFTER a;
7) Изменить положение столбца
ALTER TABLE test MODIFY b INT FIRST;
ALTER TABLE test MODIFY a INT AFTER user_id;
8) Изменить тип столбца
ALTER TABLE test MODIFY a DOUBLE;
2.3.2.3 Изменение водяного знака
1) Добавить водяной знак
CREATE TABLE test_wm (
id INT,
name STRING,
ts BIGINT
);
ALTER TABLE test_wm ADD(
et AS to_timestamp_ltz(ts,3),
WATERMARK FOR et AS et - INTERVAL ‘1’ SECOND
);
2) Изменить водяной знак
ALTER TABLE test_wm MODIFY WATERMARK FOR et AS et - INTERVAL ‘2’ SECOND;
3) Удалить водяной знак
ALTER TABLE test_wm DROP WATERMARK;
2.4 DML
2.4.1 Вставка данных
Инструкция INSERT вставляет в таблицу новые строки или перезаписывает существующие данные в таблице. Вставленные строки могут быть указаны выражениями значений или результатами запроса в соответствии со стандартным синтаксисом SQL.
INSERT { INTO | OVERWRITE } table_identifier [ part_spec ] [ column_list ] { value_expr | query }
part_spec
Необязательно укажите список пар ключ-значение для раздела, разделенных запятыми. Можно использовать литералы типов (например, date’2019-01-02’).
Синтаксис: PARTITION (имя столбца раздела = значение столбца раздела [ , … ] )
column_list
Необязательно укажите список полей, разделенных запятыми.
Синтаксис: (имя_столбца1 [,имя_столбца2, …])
Все указанные столбцы должны существовать в таблице и не могут быть дубликатами друг друга. Он включает в себя все столбцы, кроме столбцов статического секционирования. Список полей должен быть точно такого же размера, как данные в предложении или запросе VALUES.
value_expr
Укажите значение для вставки. Можно вставить явно указанное значение или NULL. Каждое значение в предложении должно быть разделено запятой. Вы можете указать более одного набора значений для вставки нескольких строк.
Синтаксис: ЗНАЧЕНИЯ ( { значение | NULL } [ , … ] ) [ , ( … ) ]
В настоящее время Flink не поддерживает прямое использование NULL, поэтому NULL необходимо преобразовать в фактическое значение типа данных, например «CAST (NULL AS STRING)».
Примечание. Запишите поля, допускающие значение NULL, в поля с ненулевым значением.
Вы не можете вставить столбец, допускающий значение NULL, из другой таблицы в столбец, допускающий значение NULL, одной таблицы. Flink может использовать функцию COALESCE для обработки этого значения. Например, key1 таблицы A не имеет значения NULL, а key2 таблицы B может иметь значение NULL:
INSERT INTO A key1 SELECT COALESCE(key2, ) FROM B
Случай:
INSERT INTO test VALUES(1,1,‘order’,‘2023-07-01’,‘1’), (2,2,‘pay’,‘2023-07-01’,‘2’);
INSERT INTO test_p PARTITION(dt=‘2023-07-01’,hh=‘1’) VALUES(3,3, ‘pv’);
– В режимах выполнения различаются разделенный и пакетный режимы.
INSERT INTO test_p SELECT * from test;
Paimon поддерживает перетасовку данных через разделы и сегменты на этапе приемника.
2.4.2 Перезапись данных
Покрытие данных поддерживает только пакетный режим. По умолчанию потоковые чтения игнорируют фиксации, созданные INSERT OVERWRITE. Если вы хотите читать коммиты OVERWRITE, вы можете настроить потоковое чтение-перезапись.
RESET ‘execution.checkpointing.interval’;
SET ‘execution.runtime-mode’ = ‘batch’;
1) Перезаписать несекционированную таблицу
INSERT OVERWRITE test VALUES(3,3,‘pay’,‘2023-07-01’,‘2’);
2) Перезаписать таблицу разделов.
Для таблиц разделов режимом перезаписи Paimon по умолчанию является динамическая перезапись разделов (т. е. Paimon удаляет только те разделы, которые появляются в данных вставки перезаписи). Чтобы изменить это, вы можете настроить переопределение динамического раздела.
INSERT OVERWRITE test_p SELECT * from test;
Перезаписать указанный раздел:
INSERT OVERWRITE test_p PARTITION (dt = ‘2023-07-01’, hh = ‘2’) SELECT user_id,item_id,behavior from test;
3) Очистить стол
Вы можете использовать INSERT OVERWRITE для очистки таблицы путем вставки нулевых значений (отключение динамической перезаписи разделов).
INSERT OVERWRITE test_p/*+ OPTIONS(‘dynamic-partition-overwrite’=‘false’) */ SELECT * FROM test_p WHERE false;
2.4.3 Обновление данных
В настоящее время Paimon поддерживает использование UPDATE для обновления записей в Flink 1.17 и последующих версиях. Вы можете выполнить ОБНОВЛЕНИЕ в пакетном режиме Flink.
Эта функция поддерживается только для таблиц первичного ключа. Обновление первичных ключей не поддерживается.
MergeEngine требует дедупликации или частичного обновления для поддержки этой функциональности. (дедупликация по умолчанию)
UPDATE test SET item_id = 4, behavior = ‘pv’ WHERE user_id = 3;
2.4.4 Удаление данных
Удалить из таблицы (Flink 1.17):
Эта функция поддерживается только для таблиц, для которых установлен режим записи журнала изменений. (Если есть первичный ключ, по умолчанию используется журнал изменений)
Если у таблицы есть первичный ключ, MergeEngine необходимо выполнить дедупликацию. (дедупликация по умолчанию)
DELETE FROM test WHERE user_id = 3;
2.4.5 Merge Into
Обновления на уровне строк реализуются посредством слияния. Эту функцию поддерживают только таблицы первичного ключа. Эта операция не создает UPDATE_BEFORE, поэтому устанавливать «changelog-producer» = «input» не рекомендуется.
Операция слияния использует семантику «upsert» вместо «обновления», что означает, что если строка существует, выполняется обновление, в противном случае выполняется вставка.
1) Грамматическое описание:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
merge-into \
--warehouse <warehouse-path> \
--database <database-name> \
--table <target-table> \
[--target-as <target-table-alias>] \
--source-table <source-table-name> \
[--source-sql <sql> ...]\
--on <merge-condition> \
--merge-actions <matched-upsert,matched-delete,not-matched-insert,not-matched-by-source-upsert,not-matched-by-source-delete> \
--matched-upsert-condition <matched-condition> \
--matched-upsert-set <upsert-changes> \
--matched-delete-condition <matched-condition> \
--not-matched-insert-condition <not-matched-condition> \
--not-matched-insert-values <insert-values> \
--not-matched-by-source-upsert-condition <not-matched-by-source-condition> \
--not-matched-by-source-upsert-set <not-matched-upsert-changes> \
--not-matched-by-source-delete-condition <not-matched-by-source-condition> \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]]
--source-sql <sql> Вы можете передать sql в среду конфигурации и создать исходные таблицы во время выполнения.Описание «Матча»:
(1) соответствует: измененные строки поступают из целевой таблицы, и каждая строка может соответствовать строке исходной таблицы в соответствии с условиями (источник ∩ цель):
Условия слияния (–on)
Условия соответствия (–matched-xxx-condition)
(2) несовпадение: измененные строки взяты из исходной таблицы, и все строки не могут соответствовать ни одной строке целевой таблицы в соответствии с условием (источник – цель):
Условия слияния (–on)
Условие несоответствия (–not-matched-xxx-condition): Столбцы целевой таблицы нельзя использовать для создания условных выражений.
(3) не сопоставлено по источнику: измененные строки происходят из целевой таблицы, и все строки не могут соответствовать каким-либо строкам исходной таблицы в зависимости от условия (цель – источник):
Условия слияния (–on)
Условие «Исходное не соответствует» (–not-matched-by-source-xxx-condition): Столбцы из исходной таблицы нельзя использовать для создания условных выражений.
2) Практический пример
Вам нужно использовать paimon-flink-action-xxxx.jar, загрузить:
cp paimon-flink-action-0.5-20230703.002437-53.jar /opt/module/flink-1.17.0/opt
Адрес загрузки:
https://repository.apache.org/snapshots/org/apache/paimon/paimon-flink-action/0.5-SNAPSHOT/
(1) Подготовьте тестовую форму:
use catalog hive_catalog;
create database test;
use test;
CREATE TABLE ws1 (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws1 VALUES(1,1,1),(2,2,2),(3,3,3);
CREATE TABLE ws_t (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws_t VALUES(2,2,2),(3,3,3),(4,4,4),(5,5,5);(2) Случай 1: ws_t совпадает с идентификатором ws1,Воляws_tсерединаts>2изvcИзменить на10,ts<=2изудалить
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
merge-into \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table ws_t \
–source-table test.ws1 \
–on “ws_t.id = ws1.id” \
–merge-actions matched-upsert,matched-delete \
–matched-upsert-condition “ws_t.ts > 2” \
–matched-upsert-set “vc = 10” \
–matched-delete-condition “ws_t.ts <= 2”
(3) Случай 2: ws_t соответствует ws1 по идентификатору. Если идентификатор совпадает, добавьте 10 к vc в ws_t. Если совпадения в ws1 нет, вставьте его в ws_t.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
merge-into \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table ws_t \
–source-table test.ws1 \
–on “ws_t.id = ws1.id” \
–merge-actions matched-upsert,not-matched-insert \
–matched-upsert-set “vc = ws_t.vc + 10” \
–not-matched-insert-values “*”
(4) Случай 3: ws_t соответствует ws1 по идентификатору. Если в ws_t нет соответствующего идентификатора, если ts больше 4, значение vc будет увеличено на 20, а если ts=4, удалите его.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
merge-into \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table ws_t \
–source-table test.ws1 \
–on “ws_t.id = ws1.id” \
–merge-actions not-matched-by-source-upsert,not-matched-by-source-delete \
–not-matched-by-source-upsert-condition “ws_t.ts > 4” \
–not-matched-by-source-upsert-set “vc = ws_t.vc + 20” \
–not-matched-by-source-delete-condition " ws_t.ts = 4"
(5) Случай 4. Используйте –source-sql, чтобы создать исходную таблицу в новом каталоге, сопоставить идентификатор ws_t и вставить несовпадающий идентификатор в ws_t.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
merge-into \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table ws_t \
–source-sql “CREATE CATALOG fs2 WITH (‘type’ = ‘paimon’,‘warehouse’ = ‘hdfs://hadoop102:8020/paimon/fs2’)” \
–source-sql “CREATE DATABASE IF NOT EXISTS fs2.test” \
–source-sql “CREATE TEMPORARY VIEW fs2.test.ws2 AS SELECT id+10 as id,ts,vc FROM test.ws1” \
–source-table fs2.test.ws2 \
–on “ws_t.id = ws2. id” \
–merge-actions not-matched-insert\
–not-matched-insert-values “*”
2.5 Таблица запросов DQL
2.5.1 Пакетный запрос
Как и все другие таблицы, таблицу Paimon можно запросить с помощью оператора SELECT.
Пакетное чтение Paimon возвращает все данные в снимке таблицы. По умолчанию пакетное чтение возвращает последний снимок.
В sql-клиенте просто установите пакетный режим выполнения:
RESET ‘execution.checkpointing.interval’;
SET ‘execution.runtime-mode’ = ‘batch’;
2.5.1.1 Путешествие во времени
1) Прочитайте снимок указанного идентификатора
SELECT * FROM ws_t /*+ OPTIONS(‘scan.snapshot-id’ = ‘1’) */;
SELECT * FROM ws_t /*+ OPTIONS(‘scan.snapshot-id’ = ‘2’) */;
2) Прочитайте снимок указанной метки времени.
– Просмотр информации о снимке
SELECT * FROM ws_t&snapshots;
SELECT * FROM ws_t /*+ OPTIONS(‘scan.timestamp-millis’ = ‘1688369660841’) */;
3) Прочитать указанный тег
SELECT * FROM ws_t /*+ OPTIONS(‘scan.tag-name’ = ‘my-tag’) */;
2.5.1.2 Инкрементный запрос
Считывает инкрементные изменения между начальным (эксклюзивным) и конечным снимками. Например, «3,5» представляет изменения между снимком 3 и снимком 5:
SELECT * FROM ws_t /*+ OPTIONS(‘incremental-between’ = ‘3,5’) */;
В пакетном режиме записи DELETE не возвращаются, поэтому записи -D будут удалены. Если вы хотите просмотреть записи DELETE, вы можете запросить таблицу Audit_log:
SELECT * FROM ws_t$audit_log /*+ OPTIONS(‘incremental-between’ = ‘3,5’) */;
2.5.2 Потоковый запрос
По умолчанию потоковое чтение принимает последний снимок таблицы при первом запуске и продолжает считывать последние изменения.
SET ‘execution.checkpointing.interval’=‘30s’;
SET ‘execution.runtime-mode’ = ‘streaming’;
Вы также можете прочитать последнюю версию и установить режим сканирования:
SELECT * FROM ws_t /*+ OPTIONS(‘scan.mode’ = ‘latest’) */
2.5.2.1 Путешествие во времени
Если вы хотите обрабатывать данные только за сегодняшний день и за его пределами, вы можете использовать для этого фильтр разделов:
SELECT * FROM test_p WHERE dt > ‘2023-07-01’
Если таблица не секционирована или фильтрация по секциям невозможна, можно использовать потоковое чтение с перемещением по времени.
1) Считайте измененные данные, начиная с указанного идентификатора снимка.
SELECT * FROM ws_t /*+ OPTIONS(‘scan.snapshot-id’ = ‘1’) */;
2) Начать чтение с указанной временной метки
SELECT * FROM ws_t /*+ OPTIONS(‘scan.timestamp-millis’ = ‘1688369660841’) */;
3) Прочитайте указанные данные моментального снимка при первом запуске и продолжайте читать изменения.
SELECT * FROM ws_t /*+ OPTIONS(‘scan.mode’=‘from-snapshot-full’,‘scan.snapshot-id’ = ‘3’) */;
2.5.2.2 Consumer ID
1) Преимущества
Укажите идентификатор потребителя при потоковой передаче таблицы. Это экспериментальная функция.
Когда поток читает таблицу Paimon, идентификатор следующего снимка будет записан в файловую систему. Это имеет несколько преимуществ:
Когда предыдущее задание остановлено, новое запущенное задание может продолжать использовать предыдущий прогресс без необходимости выхода из состояния. Новое чтение начнется со следующего идентификатора снимка, найденного в файле потребителя.
При определении того, истек ли срок действия снимка, Paimon проверит всех потребителей таблицы в файловой системе. Если еще есть потребители, использующие этот снимок, то снимок не будет удален из-за истечения срока действия.
Если водяной знак не определен, таблица Paimon передает водяной знак из снимка в следующую таблицу Paimon, что означает, что вы можете отслеживать продвижение водяного знака по всему конвейеру.
Примечание. Потребитель предотвратит истечение срока действия снимков. «consumer.expiration-time» можно указать для управления жизненным циклом потребителя.
2) Демонстрация кейса
Укажите идентификатор потребителя, чтобы начать потоковый запрос:
SELECT * FROM ws_t /*+ OPTIONS(‘consumer-id’ = ‘atguigu’) */;
Остановите исходный потоковый запрос и вставьте данные:
insert into ws_t values(6,6,6);
Снова укажите потоковый запрос идентификатора потребителя:
SELECT * FROM ws_t /*+ OPTIONS(‘consumer-id’ = ‘atguigu’) */;
2.5.3 Оптимизация запросов
Настоятельно рекомендуется указывать фильтры разделов и первичных ключей во время запроса, что ускорит пропуск данных для запросов.
Функции фильтра, которые могут ускорить переход данных:
=
<
<=
=
IN (…)
LIKE ‘abc%’
IS NULL
Paimon сортирует данные по первичному ключу, ускоряя запросы точек и диапазонов. При использовании составных первичных ключей фильтр запроса предпочтительно должен формировать крайний левый префикс первичного ключа, чтобы обеспечить хорошее ускорение.
CREATE TABLE orders (
catalog_id BIGINT,
order_id BIGINT,
…,
PRIMARY KEY (catalog_id, order_id) NOT ENFORCED – composite primary key
)
Указав фильтр диапазона в крайнем левом префиксе первичного ключа, запрос значительно ускоряется.
SELECT * FROM orders WHERE catalog_id=1025;
SELECT * FROM orders WHERE catalog_id=1025 AND order_id=29495;
SELECT * FROM orders
WHERE catalog_id=1025jkjkjk
AND order_id>2035 AND order_id<6000;
Следующий пример фильтра не очень хорошо ускоряет запрос:
SELECT * FROM orders WHERE order_id=29495;
SELECT * FROM orders WHERE catalog_id=1025 OR order_id=29495;
2.6 Системные таблицы
Системные таблицы содержат метаданные и информацию о каждой таблице, например созданные снимки и используемые параметры. Пользователи могут получать доступ к системным таблицам посредством пакетных запросов.
2.6.1 Таблица снимков
Информацию об истории снимков таблицы можно запросить через таблицу снимков, включая количество записей, произошедших в снимке.
SELECT * FROM ws_t$snapshots;
Запросив таблицу моментальных снимков, вы можете узнать об отправке таблицы и сроке ее действия, а также о перемещении данных во времени.
2.6.2 Таблица схем
Историческую схему таблицы можно запросить через таблицу схем.
SELECT * FROM ws_t$schemas;
Таблицы моментальных снимков и таблицы схемы можно объединить для получения полей для данного моментального снимка.
SELECT s.snapshot_id, t.schema_id, t.fields
FROM ws_t
schemas t
ON s.schema_id=t.schema_id where s.snapshot_id=3;
2.6.3 Таблица опций
Информацию об опциях таблицы, указанной в DDL, можно запросить через таблицу опций. Неотображаемые параметры будут значениями по умолчанию.
SELECT * FROM ws_t$options;
2.6.4 Таблица журнала аудита Таблица журнала аудита
Если вам нужен журнал изменений таблицы аудита, вы можете использовать системную таблицу Audit_log. Через таблицу Audit_log столбец типа строки можно получить при получении инкрементных данных таблицы. Вы можете использовать этот столбец для выполнения фильтрации и других операций для завершения проверки.
rowkind имеет четыре значения:
+I: операция вставки.
-U: использовать предыдущее содержимое строки обновления для операций обновления.
+U: использовать новое содержимое строки обновления для выполнения операции обновления.
-D: операция удаления.
SELECT * FROM ws_t$audit_log;
2.6.5 Таблица файлов
Файлы могут быть запрошены для конкретной таблицы моментальных снимков.
– Запросить последний файл снимка
SELECT * FROM ws_t$files;
– Запросить файл указанного снимка
SELECT * FROM ws_t$files /*+ OPTIONS(‘scan.snapshot-id’=‘1’) */;
2.6.6 Таблица тегов
Таблицу тегов можно использовать для запроса информации об истории тегов таблицы, включая сведения о том, какие снимки используются для маркировки, а также некоторую историческую информацию о снимках. Вы также можете получить все имена тегов и данные о путешествиях во времени для определенного тега по имени.
SELECT * FROM ws_t$tags;
2.7 Таблица размеров
Paimon поддерживает синтаксис Lookup Join, который используется для дополнения полей измерений данными, запрашиваемыми Paimon. Требуется, чтобы одна таблица имела атрибут времени обработки, а другая таблица поддерживалась соединителем источника поиска.
Paimon поддерживает таблицы с первичными ключами и соединения поиска таблиц только для добавления в Flink. Следующий пример иллюстрирует эту функциональность.
USE CATALOG fs_catalog;
CREATE TABLE customers (
id INT PRIMARY KEY NOT ENFORCED,
name STRING,
country STRING,
zip STRING
);
INSERT INTO customers VALUES(1,‘zs’,‘ch’,‘123’),(2,‘ls’,‘ch’,‘456’), (3,‘ww’,‘ch’,‘789’);
CREATE TEMPORARY TABLE Orders (
order_id INT,
total INT,
customer_id INT,
proc_time AS PROCTIME()
) WITH (
‘connector’ = ‘datagen’,
‘rows-per-second’=‘1’,
‘fields.order_id.kind’=‘sequence’,
‘fields.order_id.start’=‘1’,
‘fields.order_id.end’=‘1000000’,
‘fields.total.kind’=‘random’,
‘fields.total.min’=‘1’,
‘fields.total.max’=‘1000’,
‘fields.customer_id.kind’=‘random’,
‘fields.customer_id.min’=‘1’,
‘fields.customer_id.max’=‘3’
);
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;
Оператор Lookup Join будет локально поддерживать кэш RocksDB и получать последние обновления таблицы в режиме реального времени. Оператор соединения find извлекает только необходимые данные, поэтому критерии фильтра очень важны для производительности.
Если запись «Объединение заказов» (основная таблица) отсутствует, это связано с тем, что данные, соответствующие клиентам (справочная таблица), еще не готовы. Вы можете рассмотреть возможность использования стратегии отложенного повтора Flink для поиска.
2.8 Интеграция CDC
Paimon поддерживает несколько методов извлечения данных в таблицы Paimon посредством эволюции схемы. Это означает, что добавленные столбцы синхронизируются с таблицей Paimon в режиме реального времени, и задание синхронизации для этой цели не будет перезапущено.
На данный момент поддерживаются следующие методы синхронизации:
Таблица синхронизации MySQL: синхронизируйте одну или несколько таблиц MySQL с таблицей Paimon.
База данных синхронизации MySQL: синхронизируйте всю базу данных MySQL с базой данных Paimon.
Таблица синхронизации API: синхронизируйте свои пользовательские входные данные DataStream с таблицей Paimon.
Таблица синхронизации Kafka: синхронизируйте таблицу тем Kafka с таблицей Paimon.
База данных синхронизации Kafka: синхронизируйте тему Kafka, содержащую несколько таблиц или несколько тем, каждая из которых содержит одну таблицу, с базой данных Paimon.
2.8.1 MySQL
Добавьте разъем Flink CDC.
cp flink-sql-connector-mysql-cdc-2.4.0.jar /opt/module/flink-1.17.0/lib
Перезапустите кластер Yarn-session и sql-клиент.
2.8.1.1 Таблица синхронизации
1) Грамматическое описание
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
mysql-sync-table
–warehouse \
–database \
–table \
[–partition-keys ] \
[–primary-keys ] \
[–computed-column <‘column-name=expr-name(args[, …])’> [–computed-column …]] \
[–mysql-conf [–mysql-conf …]] \
[–catalog-conf [–catalog-conf …]] \
[–table-conf [–table-conf …]]
Описание параметра:
Конфигурация | описывать |
|---|---|
–warehouse | Путь к складу Пеймон. |
–database | Имя базы данных в каталоге Paimon. |
–table | Имя таблицы Paimon. |
–partition-keys | Ключ раздела для таблицы Paimon. Если имеется несколько ключей разделов, соедините их запятыми, например «dt,hh,mm». |
–primary-keys | Первичный ключ таблицы Paimon. Если существует несколько первичных ключей, соедините их запятыми, например «buyer_id,seller_id». |
–computed-column | Определение вычисляемого столбца. Поля параметров берутся из имен полей таблицы MySQL. |
–mysql-conf | Flink CDC MySQL Исходная таблица Конфигурации. Каждую Конфигурацию следует указывать в формате «ключ=значение». Имя хоста, имя пользователя, пароль, база Имя данных и имя таблицы являются обязательными Конфигурация, остальные не являются обязательными Конфигурация. |
–catalog-conf | Paimon Каталог Конфигураций. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
–table-conf | Paimon Стол-мойка Конфигурация. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
Если указанная таблица Paimon не существует, эта операция автоматически создаст таблицу. Его схема будет получена из всех указанных таблиц MySQL. Если таблица Paimon уже существует, ее схема сравнивается со схемами всех указанных таблиц MySQL.
2) Практический пример
(1) Синхронизировать таблицу в MySQL с таблицей в Paimon.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
mysql-sync-table \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table order_info_cdc \
–primary-keys id \
–mysql-conf hostname=hadoop102 \
–mysql-conf username=root \
–mysql-conf password=000000 \
–mysql-conf database-name=gmall \
–mysql-conf table-name=‘order_info’ \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hadoop102:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4
(2) Синхронизируйте несколько таблиц MySQL с одной таблицей Paimon.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
mysql-sync-table \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table order_cdc \
–primary-keys id \
–mysql-conf hostname=hadoop102 \
–mysql-conf username=root \
–mysql-conf password=000000 \
–mysql-conf database-name=gmall \
–mysql-conf table-name=‘order_.*’ \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hadoop102:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4
2.8.1.2 Синхронизировать базу данных
1) Грамматическое описание
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
mysql-sync-database
–warehouse \
–database \
[–ignore-incompatible <true/false>] \
[–table-prefix ] \
[–table-suffix ] \
[–including-tables <mysql-table-name|name-regular-expr>] \
[–excluding-tables <mysql-table-name|name-regular-expr>] \
[–mysql-conf [–mysql-conf …]] \
[–catalog-conf [–catalog-conf …]] \
[–table-conf [–table-conf …]]
Описание параметра:
Конфигурация | описывать |
|---|---|
–warehouse | Путь к складу Пеймон. |
–database | Имя базы данных в каталоге Paimon. |
–ignore-incompatible | По умолчанию установлено значение false; в этом случае будет выдано исключение, если имя таблицы MySQL существует в Paimon и их схемы несовместимы. Вы можете явно указать значение true, чтобы игнорировать несовместимые таблицы и исключения. |
–table-prefix | Префиксы всех таблиц Paimon, которые необходимо синхронизировать. Например, если вы хотите, чтобы все синхронизируемые таблицы имели префикс «ods_», вы можете указать «--table-prefix ods_». |
–table-suffix | Суффиксы всех таблиц Paimon, которые необходимо синхронизировать. Использование такое же, как «--table-prefix». |
–including-tables | Используется для указания исходных таблиц для синхронизации. Вы должны использовать '|' для разделения нескольких таблиц, например: 'a|b|c'. Поддерживает регулярные выражения, например, указание «--include-tables test|paimon.*» означает синхронизацию таблицы «test» и всех таблиц, начинающихся с «paimon». |
–excluding-tables | Используется для указания того, какие исходные таблицы не синхронизированы. Использование такое же, как и «--include-tables». Если также указано «--кроме-таблиц», «--кроме-таблиц» имеет более высокий приоритет, чем «--include-tables». |
–mysql-conf | Flink CDC MySQLИсходная таблица Конфигурации. Каждую Конфигурацию следует указывать в формате «ключ=значение». Имя хоста, имя пользователя, пароль, база Имя данных и имя таблицы являются обязательными Конфигурация, остальные не являются обязательными Конфигурация. |
–catalog-conf | Paimon Каталог Конфигураций. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
–table-conf | Paimon Стол-мойка Конфигурация. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
Синхронизироваться будут только таблицы с первичными ключами.
Для каждой таблицы MySQL, которую необходимо синхронизировать, если соответствующая таблица Paimon не существует, эта операция автоматически создаст таблицу. Его схема будет получена из всех указанных таблиц MySQL. Если таблица Paimon уже существует, ее схема сравнивается со схемами всех указанных таблиц MySQL.
2) Практический пример
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
mysql-sync-database \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table-prefix “ods_” \
–table-suffix “_cdc” \
–mysql-conf hostname=hadoop102 \
–mysql-conf username=root \
–mysql-conf password=000000 \
–mysql-conf database-name=gmall \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hadoop102:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4 \
–including-tables ‘user_info|order_info|activity_rule’
3) Синхронизируйте вновь добавленные таблицы с базой данных.
Во-первых, предположим, что задание Flink синхронизирует таблицы [продукт, пользователь, адрес] в базе данных source_db. Команда для отправки задания выглядит следующим образом:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
mysql-sync-database \
–warehouse hdfs:///path/to/warehouse \
–database test_db \
–mysql-conf hostname=127.0.0.1 \
–mysql-conf username=root \
–mysql-conf password=123456 \
–mysql-conf database-name=source_db \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hive-metastore:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4 \
–including-tables ‘product|user|address’
Позже мы хотим, чтобы задание также синхронизировало таблицу [order, custom], содержащую исторические данные. Мы можем добиться этого, восстановив предыдущий снимок задания и тем самым повторно используя существующее состояние задания. Восстановленное задание сначала сделает снимок вновь добавленной таблицы, а затем автоматически продолжит чтение журнала изменений из предыдущего местоположения.
Команда восстановления из предыдущего снимка и добавления новой таблицы для синхронизации выглядит следующим образом:
<FLINK_HOME>/bin/flink run \
–fromSavepoint savepointPath \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
mysql-sync-database \
–warehouse hdfs:///path/to/warehouse \
–database test_db \
–mysql-conf hostname=127.0.0.1 \
–mysql-conf username=root \
–mysql-conf password=123456 \
–mysql-conf database-name=source_db \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hive-metastore:9083 \
–table-conf bucket=4 \
–including-tables ‘product|user|address|order|custom’
2.8.2 Kafka
Flink предоставляет несколько форматов Kafka CDC: canal-json, debezium-json, ogg-json, maxwell-json. Если сообщения в теме Kafka представляют собой события изменений, полученные из другой базы данных с помощью инструмента отслеживания измененных данных (CDC), вы можете использовать Paimon Kafka CDC. Запишите проанализированные сообщения INSERT, UPDATE и DELETE в таблицу paimon. На официальном сайте Paimon перечислены следующие поддерживаемые форматы:
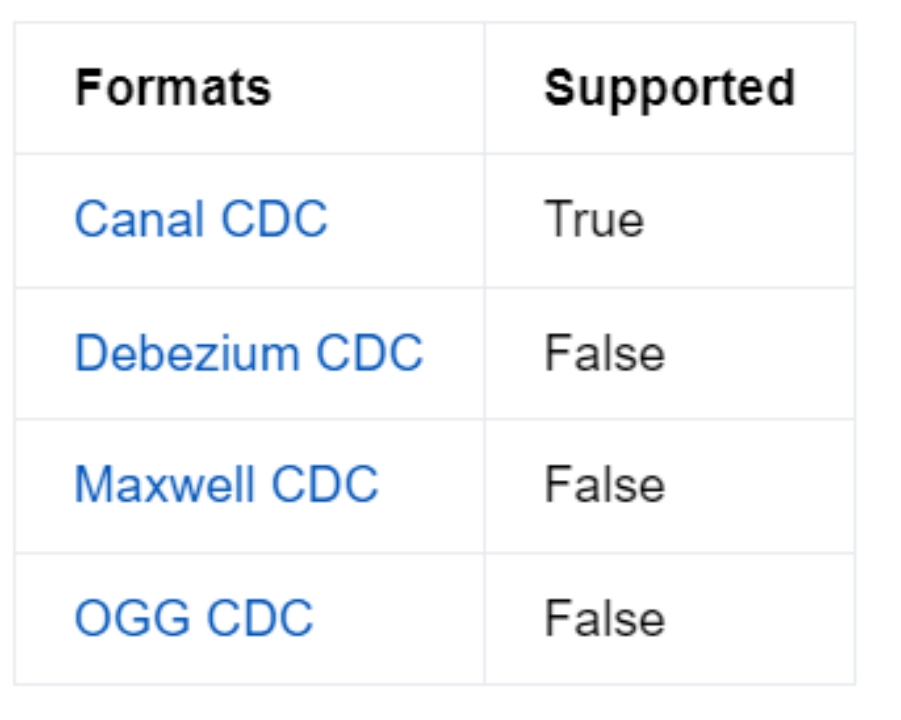
Добавьте коннектор Kafka:
cp flink-sql-connector-kafka-1.17.0.jar /opt/module/flink-1.17.0/lib
Перезапустите кластер Yarn-session и sql-клиент.
2.8.2.1 Таблица синхронизации
1) Грамматическое описание
Синхронизируйте одну или несколько таблиц в теме Kafka с таблицей Paimon.
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
kafka-sync-table
–warehouse \
–database \
–table \
[–partition-keys ] \
[–primary-keys ] \
[–computed-column <‘column-name=expr-name(args[, …])’> [–computed-column …]] \
[–kafka-conf [–kafka-conf …]] \
[–catalog-conf [–catalog-conf …]] \
[–table-conf [–table-conf …]]
Описание параметра
Конфигурация | описывать |
|---|---|
–warehouse | Путь к складу Пеймон. |
–database | Имя базы данных в каталоге Paimon. |
–table | Имя таблицы Paimon. |
–partition-keys | Ключ раздела для таблицы Paimon. Если имеется несколько ключей разделов, соедините их запятыми, например «dt,hh,mm». |
–primary-keys | Первичный ключ таблицы Paimon. Если существует несколько первичных ключей, соедините их запятыми, например «buyer_id,seller_id». |
–computed-column | Определение вычисляемого столбца. Поле параметра взято из имени поля таблицы темы Kafka. |
–kafka-conf | Flink Kafka Источник конфигурации. Каждую Конфигурацию следует указывать в формате «ключ=значение». properties.bootstrap.servers、topic、properties.group.id и value.format Конфигурация обязательна, другая Конфигурация не является обязательной. |
–catalog-conf | Paimon Каталог Конфигураций. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
–table-conf | Paimon Стол-мойка Конфигурация. Каждую Конфигурацию следует указывать в формате «ключ=значение». |
Если указанная вами таблица Paimon не существует, эта операция автоматически создаст ее. Его схема будет получена из таблиц всех указанных тем Kafka, и он получит самую раннюю схему анализа данных, не относящуюся к DDL, из этой темы. Если таблица Paimon уже существует, ее схема сравнивается со схемами всех указанных таблиц тем Kafka.
2) Практический пример
(1) Подготовьте данные (формат canal-json)
Для удобства напрямую вставьте в тему данные в формате канала (данные одной таблицы user_info):
kafka-console-producer.sh --broker-list hadoop102:9092 --topic paimon_canal
#Вставьте данные следующим образом:
{"data":[{"id":"6","login_name":"t7dk2h","nick_name":"Bingbing11","passwd":null, "name":"Чун Юбин","phone_num" :"13178654378","эма il»: «t7dk2h@263.net», «head_img»:null, «user_level»: «1», «день рождения»: «1997-12-08», «пол»: null, «create_time»: «2022- 06-08 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689150607000, «id»: 1, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Бинбин»}], «pkNames»:[«id»], «sql»: «», «sqlType»:{«id»:-5, «login_name»:12, «nick_name»:12, «passwd» :12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151566836, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"7","login_name":"vihcj30p1","nick_name":"Хаосинь22", "passwd":null, "name":"Вэй Хаосинь","phone_num" :"13956932645","эма il»: «vihcj30p1@live.com», «head_img»:null, «user_level»: «1», «день рождения»: «1991-06-07», «пол»: «M», «create_time»: « 08.06.2022 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151623000, «id»: 2, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"Большое сердце"}],"pkNames":[" id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd" :12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151623139, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"8","login_name":"02r2ahx","nick_name":"Qingqing33","passwd":null, "name":"Му Цин","phone_num ”:“13412413361”,“эма il»: «02r2ahx@sohu.com», «head_img»:null, «user_level»: «1», «день рождения»: «08.07.2001», «пол»: «F», «create_time»:» 08.06.2022 00:00:00», «operate_time»: null, «статус»: null}], «база данных»: «gmall», «es»: 1689151626000, «id»: 3, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Цинцин»}], «pkNames»:["id"],"sql":"","sqlType":{"id":-5, "login_name":12, "nick_name":12,"passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151626863, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"9","login_name":"mjhrxnu","nick_name":"Такешин44","passwd":null, "name":"Ло Усинь"," phone_num»: «13617856358», «электронная почта l»: «mjhrxnu@yahoo.com», «head_img»: null, «user_level»: «1», «день рождения»: «2001-08-08», «gender»: null, «create_time»: «2022- 06-08 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151630000, «id»: 4, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Такешин»}], «pkNames»:["id"],"sql":"","sqlType":{"id":-5, "login_name":12, "nick_name":12,"passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151630781, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"10","login_name":"kwua2155","nick_name":"Wanwan55", "passwd":null, "name":"Цзян Ван","phone_num ”:“13742843828”,“эм ail»: «kwua2155@163.net», «head_img»:null, «user_level»: «3», «день рождения»: «1997-11-08», «пол»: «F», «create_time»: « 08.06.2022 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151633000, «id»: 5, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Ваньван»}], «pkNames»:[«id»], «sql»: «», «sqlType»: {»id»:-5, «login_name»:12, «nick_name»:12, «passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»:93, «operate_time»:93, «статус»:12}, «таблица»: «user_info», «ts»:1689151633697, «тип»: «ОБНОВЛЕНИЕ»}
(2) Синхронизация темы Kafka (содержащей данные одной таблицы) с таблицей Paimon.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
kafka-sync-table \
--warehouse hdfs://hadoop102:8020/paimon/hive \
--database test \
--table kafka_user_info_cdc \
--primary-keys id \
--kafka-conf properties.bootstrap.servers=hadoop102:9092 \
--kafka-conf topic=paimon_canal \
--kafka-conf properties.group.id=atguigu \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://hadoop102:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=42.8.2.2 Синхронизировать базу данных
1) Грамматическое описание
Синхронизируйте несколько тем или тему с базой данных Paimon.
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
kafka-sync-database
--warehouse <warehouse-path> \
--database <database-name> \
[--schema-init-max-read <int>] \
[--ignore-incompatible <true/false>] \
[--table-prefix <paimon-table-prefix>] \
[--table-suffix <paimon-table-suffix>] \
[--including-tables <table-name|name-regular-expr>] \
[--excluding-tables <table-name|name-regular-expr>] \
[--kafka-conf <kafka-source-conf> [--kafka-conf <kafka-source-conf> ...]] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-sink-conf> [--table-conf <paimon-table-sink-conf> ...]]Описание параметра:
Конфигурация | описывать |
|---|---|
–warehouse | Путь к складу Пеймон. Путь к складу Пеймон. |
–database | Имя базы данных в каталоге Paimon. |
–schema-init-max-read | Если все ваши таблицы относятся к определенной теме, вы можете установить этот параметр, чтобы инициализировать количество таблиц, которые необходимо синхронизировать. Значение по умолчанию — 1000. |
–ignore-incompatible | По умолчанию установлено значение false; в этом случае будет выдано исключение, если имя таблицы MySQL существует в Paimon и их схемы несовместимы. Вы можете явно указать значение true, чтобы игнорировать несовместимые таблицы и исключения. |
–table-prefix | Префиксы всех таблиц Paimon, которые необходимо синхронизировать. Например, если вы хотите, чтобы все синхронизируемые таблицы имели префикс «ods_», вы можете указать «--table-prefix ods_». |
–table-suffix | Суффиксы всех таблиц Paimon, которые необходимо синхронизировать. Использование такое же, как «--table-prefix». |
–including-tables | Используется для указания исходных таблиц для синхронизации. Вы должны использовать «|» для разделения нескольких таблиц. Поскольку «|» является специальным символом, необходима запятая, например: «a|b|c». Поддерживает регулярные выражения, например указание «--include-tables test|paimon.*» означает синхронную таблицу «test», и все таблицы начинаются с «paimon». |
–excluding-tables | Используется для указания того, какие исходные таблицы не синхронизированы. Использование такое же, как и «--include-tables». Если также указано «--кроме-таблиц», «--кроме-таблиц» имеет более высокий приоритет, чем «--include-tables». |
–kafka-conf | Flink Kafka Источник конфигурации. Каждую Конфигурацию следует указывать в формате «ключ=значение». properties.bootstrap.servers、topic、properties.group.id и value.format требуется Конфигурация,Другая конфигурация не является обязательной. Полный список конфигураций,Пожалуйста, обратитесь к его документации. |
–catalog-conf | Paimon Каталог Конфигурации. Каждую Конфигурацию следует указывать в формате «ключ=значение». Полный список каталогов смотрите здесь. Конфигурация. |
–table-conf | Paimon Конфигурация мойки для обеденного стола. Каждую Конфигурацию следует указывать в формате «ключ=значение». Полный список таблиц см. здесь. Конфигурация. |
Синхронизироваться будут только таблицы с первичными ключами.
Для каждой синхронизируемой таблицы тем Kafka операция автоматически создаст соответствующую таблицу Paimon, если она не существует. Его схема будет получена из таблиц всех указанных тем Kafka, и он получит самую раннюю схему анализа данных, не относящуюся к DDL, из этой темы. Если таблица Paimon уже существует, ее схема сравнивается со схемами всех указанных таблиц тем Kafka.
2) Практический пример
(1) Подготовьте данные (формат canal-json)
Для удобства прямо в тему вставьте данные в формате Воляканала (многотабличные данные user_infoиspu_info):
kafka-console-producer.sh --broker-list hadoop102:9092 --topic paimon_canal_2
#Вставьте данные следующим образом (следите за тем, чтобы не было пустых строк):
{"data":[{"id":"6","login_name":"t7dk2h","nick_name":"Bingbing11","passwd":null, "name":"Чун Юбин","phone_num" :"13178654378","эма il»: «t7dk2h@263.net», «head_img»:null, «user_level»: «1», «день рождения»: «1997-12-08», «пол»: null, «create_time»: «2022- 06-08 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689150607000, «id»: 1, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Бинбин»}], «pkNames»:[«id»], «sql»: «», «sqlType»:{«id»:-5, «login_name»:12, «nick_name»:12, «passwd» :12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151566836, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"7","login_name":"vihcj30p1","nick_name":"Хаосинь22", "passwd":null, "name":"Вэй Хаосинь","phone_num" :"13956932645","эма il»: «vihcj30p1@live.com», «head_img»:null, «user_level»: «1», «день рождения»: «1991-06-07», «пол»: «M», «create_time»: « 08.06.2022 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151623000, «id»: 2, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"Большое сердце"}],"pkNames":[" id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd" :12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151623139, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"8","login_name":"02r2ahx","nick_name":"Qingqing33","passwd":null, "name":"Му Цин","phone_num ”:“13412413361”,“эма il»: «02r2ahx@sohu.com», «head_img»:null, «user_level»: «1», «день рождения»: «08.07.2001», «пол»: «F», «create_time»:» 08.06.2022 00:00:00», «operate_time»: null, «статус»: null}], «база данных»: «gmall», «es»: 1689151626000, «id»: 3, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Цинцин»}], «pkNames»:["id"],"sql":"","sqlType":{"id":-5, "login_name":12, "nick_name":12,"passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151626863, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"9","login_name":"mjhrxnu","nick_name":"Такешин44","passwd":null, "name":"Ло Усинь"," phone_num»: «13617856358», «электронная почта l»: «mjhrxnu@yahoo.com», «head_img»: null, «user_level»: «1», «день рождения»: «2001-08-08», «gender»: null, «create_time»: «2022- 06-08 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151630000, «id»: 4, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Такешин»}], «pkNames»:["id"],"sql":"","sqlType":{"id":-5, "login_name":12, "nick_name":12,"passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»: 93, «operate_time»: 93, «статус»: 12}, «таблица»: «user_info», «ts»: 1689151630781, «тип»: «ОБНОВЛЕНИЕ»} {"data":[{"id":"10","login_name":"kwua2155","nick_name":"Wanwan55", "passwd":null, "name":"Цзян Ван","phone_num ”:“13742843828”,“эм ail»: «kwua2155@163.net», «head_img»:null, «user_level»: «3», «день рождения»: «1997-11-08», «пол»: «F», «create_time»: « 08.06.2022 00:00:00», «operate_time»: null, «status»: null}], «database»: «gmall», «es»: 1689151633000, «id»: 5, «isD dl»: false, «mysqlType»: { «id»: «bigint», «login_name»: «varchar(200)», «nick_name»: «varchar(200)», «pa sswd»: «varchar(200)», «name»: «varchar(200)», «phone_num»: «varchar(200)», «email»: «varchar(200)», «head_img»: «varchar( 200)», «user_level»: «varchar(200)», «день рождения»: «дата», «пол»: «varchar(1)», «cre ate_time»: «datetime», «operate_time»: «datetime», «status»: «varchar(200)»}, «old»:[{«nick_name»: «Ваньван»}], «pkNames»:[«id»], «sql»: «», «sqlType»: {»id»:-5, «login_name»:12, «nick_name»:12, «passwd ”:12 , «нам e»:12, «phone_num»:12, «электронная почта»:12, «head_img»:12, «user_level»:12, «день рождения»:91, «пол»:12, «создать _time»:93, «operate_time»:93, «статус»:12}, «таблица»: «user_info», «ts»:1689151633697, «тип»: «ОБНОВЛЕНИЕ»}{"data":[{"id":"12","spu_name":"Huawei Smart Screen Полноэкранный смарт-телевизор 4K 1", "description": "Huawei Smart Screen Полноэкранный смарт-телевизор 4K", "category3_id": "86", "tm_id": "3", "create_time": "14.12.2021 00:00:00», «operate_time»: null}], «database»: «gmall», «es»: 1689151648000, «id»: 6, «isDdl»: false, «mysqlType»: { «id»: «bigint», «spu_name»: «varchar(200)», «d escription":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{" spu_name":"Умный экран Huawei Полноэкранный Smart TV 4K"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12 ,"category3_id" :-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151648872,"type":"UPDATE"} {“data”:[{“id”:“3”,“spu_name”:“Apple iPhone 13”,“description”:“Apple iPhone 13”,“category3_id”:“61”,“tm_id”:“2”,“create_time”:“2021-12-14 00:00:00”,“operate_time”:null}],“database”:“gmall”,“es”:1689151661000,“id”:7,“isDdl”:false,“mysqlType”:{“id”:“bigint”,“spu_name”:“varchar(200)”,“description”:“varchar(1000)”,“category3_id”:“bigint”,“tm_id”:“bigint”,“create_time”:“datetime”,“operate_time”:“datetime”},“old”:[{“spu_name”:“Apple iPhone 12”,“description”:“Apple iPhone 12”}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id”:-5,“spu_name”:12,“description”:12,“category3_id”:-5,“tm_id”:-5,“create_time”:93,“operate_time”:93},“table”:“spu_info”,“ts”:1689151661828,“type”:“UPDATE”} {“data”:[{“id”:“4”,“spu_name”:“HUAWEI P50”,“description”:“HUAWEI P50”,“category3_id”:“61”,“tm_id”:“3”,“create_time”:“2021-12-14 00:00:00”,“operate_time”:null}],“database”:“gmall”,“es”:1689151669000,“id”:8,“isDdl”:false,“mysqlType”:{“id”:“bigint”,“spu_name”:“varchar(200)”,“description”:“varchar(1000)”,“category3_id”:“bigint”,“tm_id”:“bigint”,“create_time”:“datetime”,“operate_time”:“datetime”},“old”:[{“spu_name”:“HUAWEI P40”,“description”:“HUAWEI P40”}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id”:-5,“spu_name”:12,“description”:12,“category3_id”:-5,“tm_id”:-5,“create_time”:93,“operate_time”:93},“table”:“spu_info”,“ts”:1689151669966,“type”:“UPDATE”} {"data":[{"id":"1","spu_name":"Xiaomi 12sultra","description":"Xiaomi 12","category3_id":"61","tm_id":"1"," create_time":"14 декабря 2021 г. 00:00:00», «operate_time»: null}], «database»: «gmall», «es»: 1689151700000, «id»: 9, «isDdl»: false, «mysqlType»: { «id»: «бигинт», «spu_ name»: «varchar(200)», «description»: «varchar(1000)», «category3_id»: «bigint», «tm_id»: «bigint», «create_time»: «datetime», «opera te_time”:“datetime”},"old":[{"description":"Xiaomi 10"}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id” :-5, «spu_name»:12, «описание ”:12, “category3_id”:-5, “tm_id”:-5, “create_time”:93, “operate_time”:93}, “table”: “spu_info”, “ts”:1689151700998, “type”:“ ОБНОВЛЯТЬ"}
Подготовьте еще одну тему, содержащую только данные одной таблицы spu_info:
kafka-console-producer.sh --broker-list hadoop102:9092 --topic paimon_canal_1
#Вставьте данные следующим образом:
{"data":[{"id":"12","spu_name":"Huawei Smart Screen Полноэкранный смарт-телевизор 4K 1", "description": "Huawei Smart Screen Полноэкранный смарт-телевизор 4K", "category3_id": "86", "tm_id": "3", "create_time": "14.12.2021 00:00:00», «operate_time»: null}], «database»: «gmall», «es»: 1689151648000, «id»: 6, «isDdl»: false, «mysqlType»: { «id»: «bigint», «spu_name»: «varchar(200)», «d escription":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{" spu_name":"Умный экран Huawei Полноэкранный Smart TV 4K"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12 ,"category3_id" :-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151648872,"type":"UPDATE"} {“data”:[{“id”:“3”,“spu_name”:“Apple iPhone 13”,“description”:“Apple iPhone 13”,“category3_id”:“61”,“tm_id”:“2”,“create_time”:“2021-12-14 00:00:00”,“operate_time”:null}],“database”:“gmall”,“es”:1689151661000,“id”:7,“isDdl”:false,“mysqlType”:{“id”:“bigint”,“spu_name”:“varchar(200)”,“description”:“varchar(1000)”,“category3_id”:“bigint”,“tm_id”:“bigint”,“create_time”:“datetime”,“operate_time”:“datetime”},“old”:[{“spu_name”:“Apple iPhone 12”,“description”:“Apple iPhone 12”}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id”:-5,“spu_name”:12,“description”:12,“category3_id”:-5,“tm_id”:-5,“create_time”:93,“operate_time”:93},“table”:“spu_info”,“ts”:1689151661828,“type”:“UPDATE”} {“data”:[{“id”:“4”,“spu_name”:“HUAWEI P50”,“description”:“HUAWEI P50”,“category3_id”:“61”,“tm_id”:“3”,“create_time”:“2021-12-14 00:00:00”,“operate_time”:null}],“database”:“gmall”,“es”:1689151669000,“id”:8,“isDdl”:false,“mysqlType”:{“id”:“bigint”,“spu_name”:“varchar(200)”,“description”:“varchar(1000)”,“category3_id”:“bigint”,“tm_id”:“bigint”,“create_time”:“datetime”,“operate_time”:“datetime”},“old”:[{“spu_name”:“HUAWEI P40”,“description”:“HUAWEI P40”}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id”:-5,“spu_name”:12,“description”:12,“category3_id”:-5,“tm_id”:-5,“create_time”:93,“operate_time”:93},“table”:“spu_info”,“ts”:1689151669966,“type”:“UPDATE”} {"data":[{"id":"1","spu_name":"Xiaomi 12sultra","description":"Xiaomi 12","category3_id":"61","tm_id":"1"," create_time":"14 декабря 2021 г. 00:00:00», «operate_time»: null}], «database»: «gmall», «es»: 1689151700000, «id»: 9, «isDdl»: false, «mysqlType»: { «id»: «бигинт», «spu_ name»: «varchar(200)», «description»: «varchar(1000)», «category3_id»: «bigint», «tm_id»: «bigint», «create_time»: «datetime», «opera te_time”:“datetime”},"old":[{"description":"Xiaomi 10"}],“pkNames”:[“id”],“sql”:“”,“sqlType”:{“id” :-5, «spu_name»:12, «описание ”:12, “category3_id”:-5, “tm_id”:-5, “create_time”:93, “operate_time”:93}, “table”: “spu_info”, “ts”:1689151700998, “type”:“ ОБНОВЛЯТЬ"}
(2) Синхронизировать тему Kafka (содержащую данные из нескольких таблиц) с базой данных Paimon.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
kafka-sync-database \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table-prefix “t1_” \
–table-suffix “_cdc” \
–schema-init-max-read 500 \
–kafka-conf properties.bootstrap.servers=hadoop102:9092 \
–kafka-conf topic=paimon_canal_2 \
–kafka-conf properties.group.id=atguigu \
–kafka-conf scan.startup.mode=earliest-offset \
–kafka-conf value.format=canal-json \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hadoop102:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4
Синхронизация с базой данных Paimon из нескольких тем Kafka.
bin/flink run \
/opt/module/flink-1.17.0/opt/paimon-flink-action-0.5-20230703.002437-53.jar \
kafka-sync-database \
–warehouse hdfs://hadoop102:8020/paimon/hive \
–database test \
–table-prefix “t2_” \
–table-suffix “_cdc” \
–kafka-conf properties.bootstrap.servers=hadoop102:9092 \
–kafka-conf topic=“paimon_canal;paimon_canal_1” \
–kafka-conf properties.group.id=atguigu \
–kafka-conf scan.startup.mode=earliest-offset \
–kafka-conf value.format=canal-json \
–catalog-conf metastore=hive \
–catalog-conf uri=thrift://hadoop102:9083 \
–table-conf bucket=4 \
–table-conf changelog-producer=input \
–table-conf sink.parallelism=4
2.8.3 Поддерживаемые изменения схемы
Интеграция cdc поддерживает ограниченные изменения схемы. В настоящее время платформа не может удалять столбцы, поэтому поведение DROP будет игнорироваться, а RENAME добавит новый столбец. В настоящее время поддерживаются следующие изменения схемы:
(1) Добавьте столбцы.
(2) Изменить тип столбца:
Изменение типа строки (char, varchar, text) на другой тип строки большей длины,
Изменение двоичного типа (двоичный, varbinary, blob) на другой двоичный тип большей длины.
Переход от целочисленного типа (tinyint, smallint, int, bigint) к другому целочисленному типу с более широким диапазоном,
Измените тип с плавающей запятой (float, double) на другой тип с плавающей запятой с более широким диапазоном.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
