Первый опыт SpringAI позволяет каждому запускать большие модели
Первый опыт SpringAI позволяет каждому запускать большие модели
Spring AI — проект, призванный упростить разработку приложений, содержащих возможности искусственного интеллекта. Он вдохновлен такими проектами Python, как LangChain и Llama Index, но не является прямым портом этих проектов. Основная идея Spring AI — предоставить базовые абстракции для разработки приложений ИИ. Эти абстракции имеют несколько реализаций, что позволяет легко переключать компоненты между различными реализациями с минимальными изменениями кода.
Их философия дизайна заключается в том, чтобы предоставить разработчикам абстрактный интерфейс, который закладывает основу для включения генеративного ИИ в приложения в качестве независимых компонентов.
В настоящее время поддерживает всех основных поставщиков моделей, таких как OpenAI, Microsoft, Amazon, Google и Huggingfac.
Эта статья Воля Позвольте вам испытать его иOllamaсочетание больших моделей。
Это его официальный документ:Spring AI :: Spring AI Reference
Если вам интересно, вы можете сначала проверить официальную документацию.
Без лишних слов, давайте перейдем непосредственно к самому бою.
Потому что это относительно новый пакет. Поэтому нам нужно следовать инструкциям официальной документации и сначала указать адрес склада кода.
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>Затем добавьте управление версиями:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>0.8.1-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Серверная часть Олламы
Следующие операции будут выполнены в соответствии с этим документом.:Ollama Chat :: Spring AI Reference
Прежде всего, что такое Оллама?
Ollama — это инструмент и платформа, предназначенные для упрощения локального запуска больших языковых моделей (LLM). Он позволяет пользователям легко запускать большие языковые модели с открытым исходным кодом, такие как Llama 224, на своем локальном устройстве, упаковывая веса моделей, конфигурацию и данные в один пакет. Ollama оптимизирует детали установки и конфигурации, включая использование графического процессора, что позволяет даже пользователям без сильной технической подготовки легко устанавливать, запускать и взаимодействовать с моделями.
Это его официальный адрес;Ollama
Сначала нам нужно скачать версию для Windows.
Проще говоря, вы можете понимать это как нечто, что может запускать модель.
После установки нам нужно скачать несколько больших моделей.
Вот рекомендую вот это:llama2-chinese (ollama.com)
Потому что он поддерживает китайцев.
Заходим сюда и следуем его указаниям
Просто введите следующую команду, и она начнет загрузку
ollama run llama2-chinese
Пожалуйста, терпеливо дождитесь первой загрузки.

Вы можете видеть, что скорость загрузки по-прежнему очень высокая.
Даже если загрузка завершена

Давайте посмотрим на интеграцию с Spring позже.
Сначала нужно добавить пакет:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xiaou</groupId>
<artifactId>xiaou-backend</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>xiaou-backend</name>
<description>xiaou-backend</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.12</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>0.8.1-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
</project>
Затем делаем настройку:
server:
port: 8081
spring:
ai:
ollama:
chat:
options:
model: llama2-chineseЗатем пишем контроллер
@RestController
public class AIController {
@Resource
private OllamaChatClient ollamaChatClient;
@GetMapping("/chat")
public String chat(@RequestParam(name = "message") String message) {
return ollamaChatClient.call(message);
}
}
Это самый простой контроллер
Тогда давайте посмотрим на его демонстрацию:
Это может быть немного медленно, нужно подождать около полутора минут.
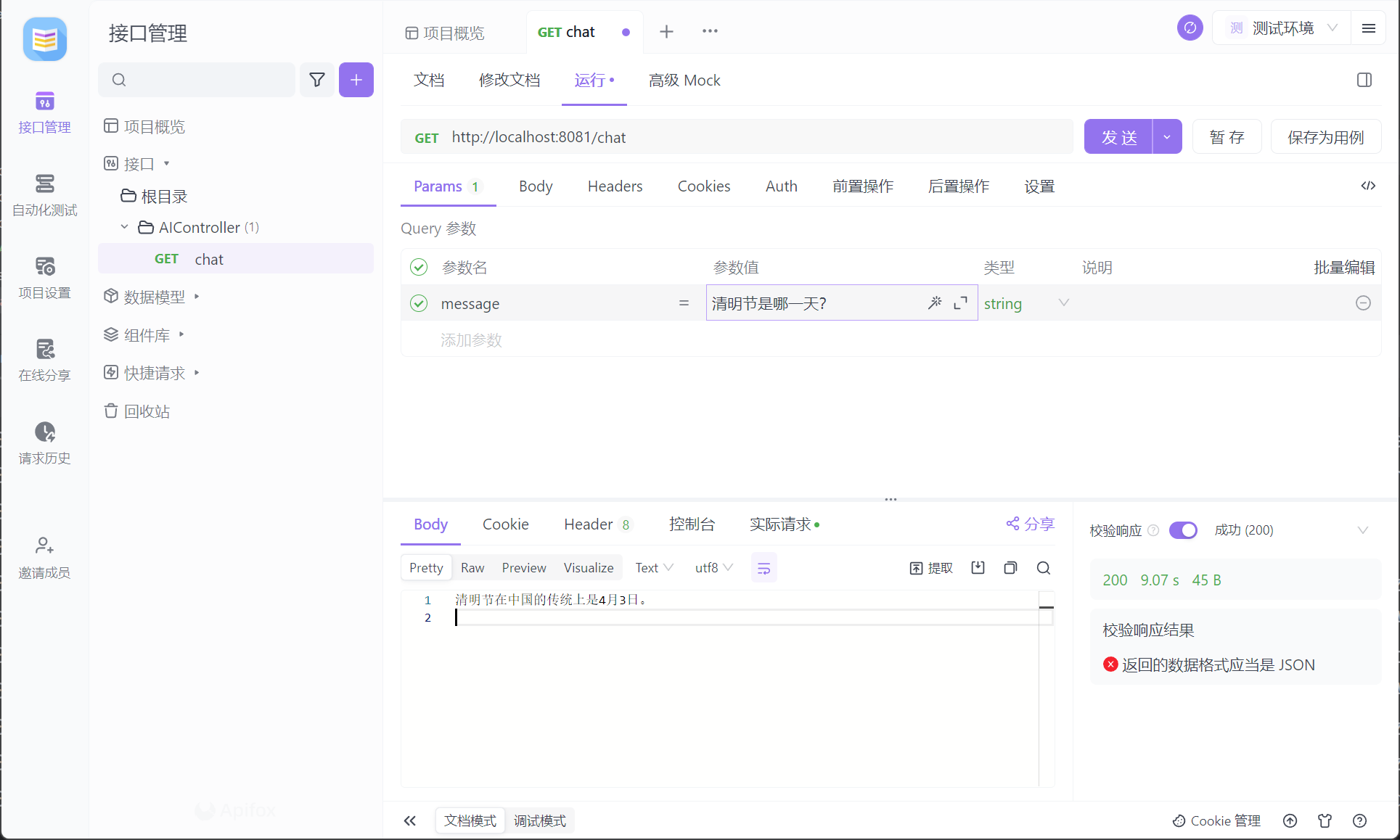
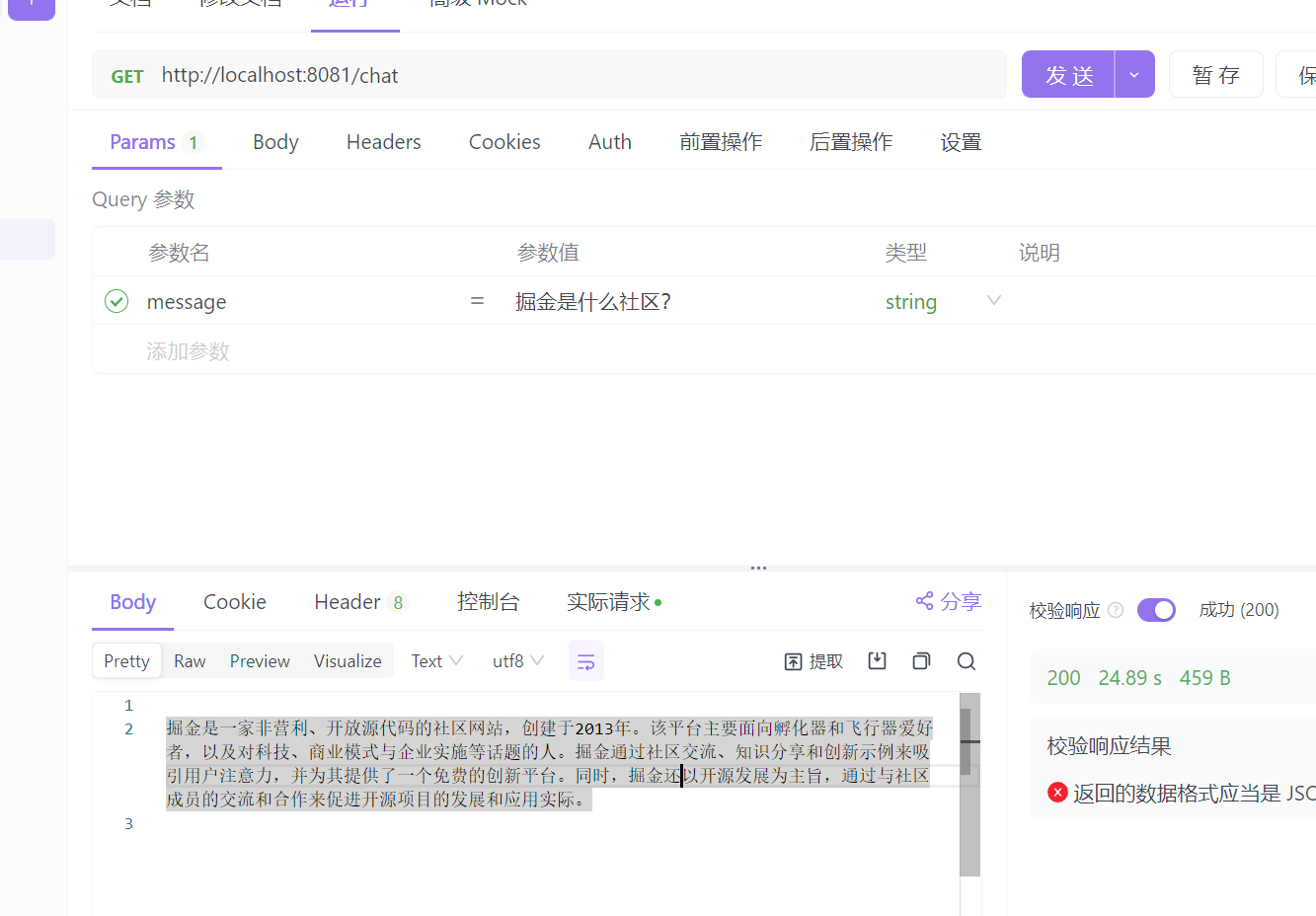
Передняя часть Олламы
Вот небольшая демо-версия для реализации фронтенд-части.
Я не буду много говорить о фронтенде, просто посмотрим на эффект. Вам нужно подождать около полминуты, потому что он запускается локально.
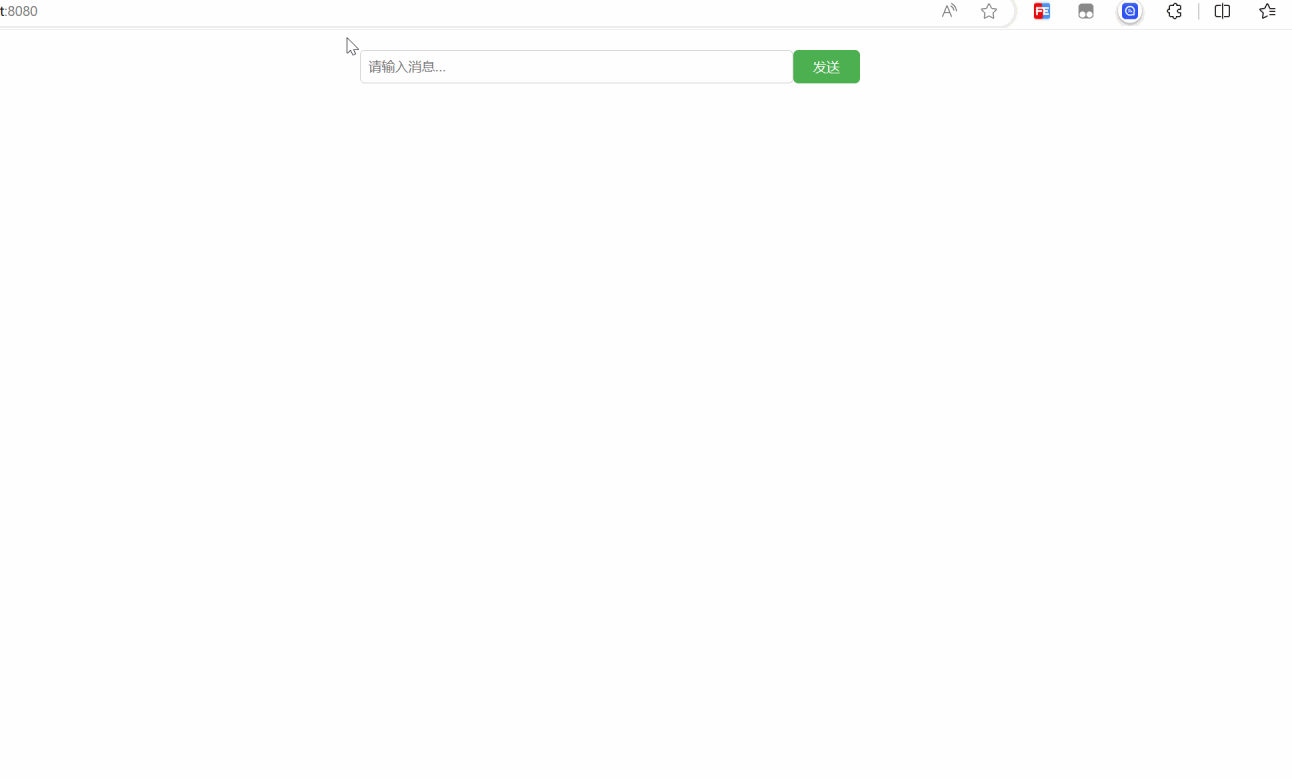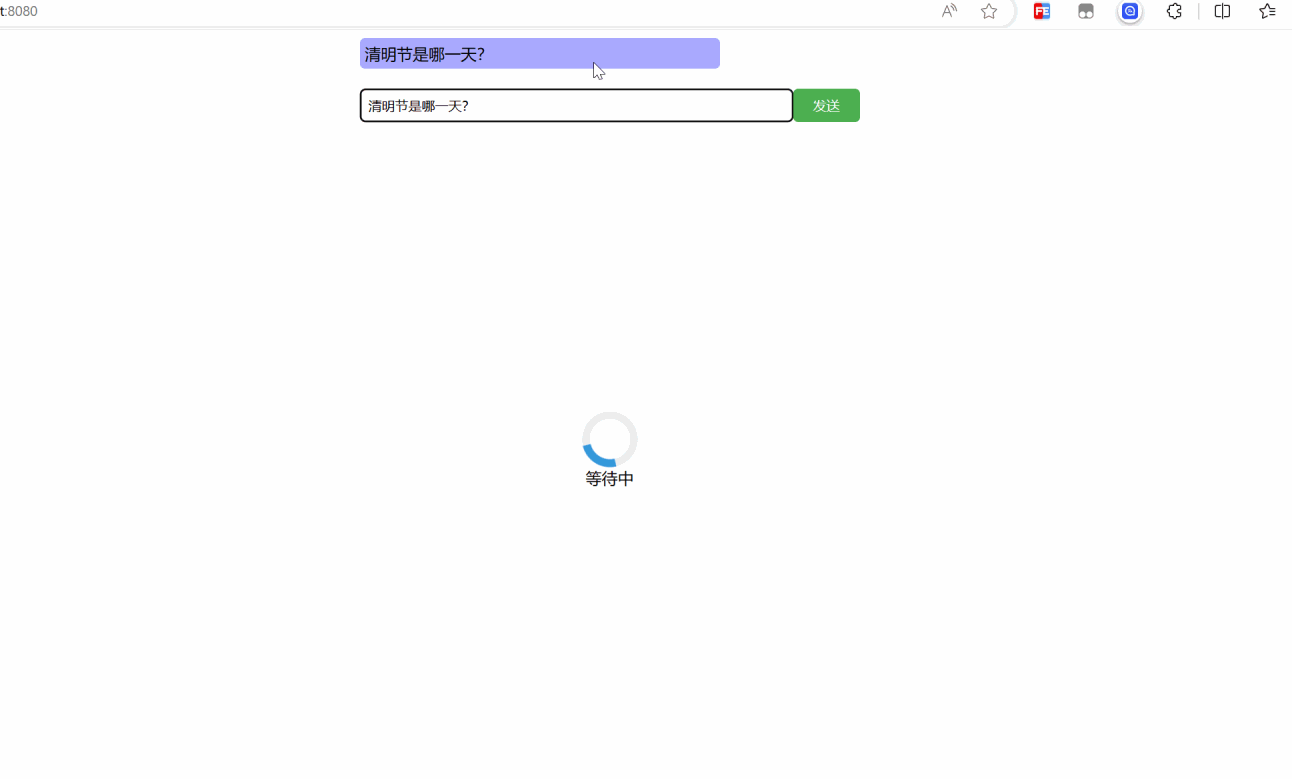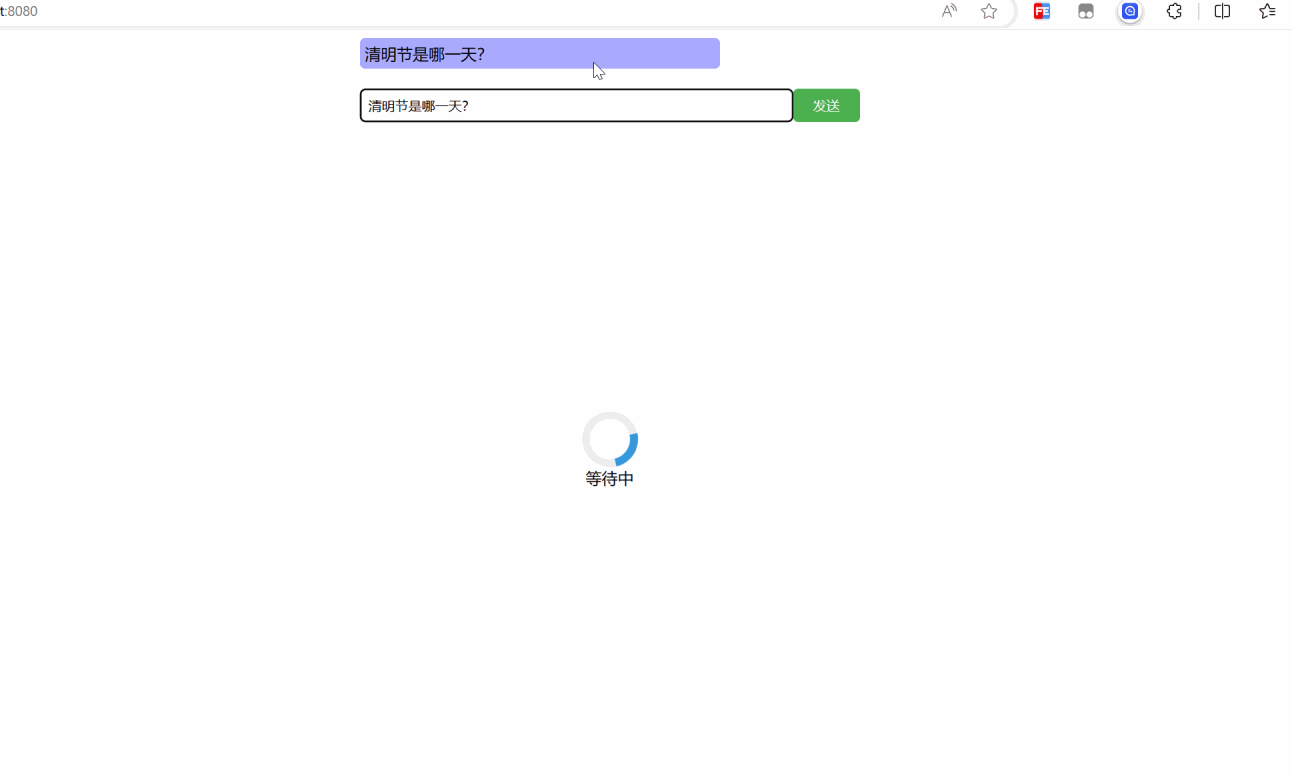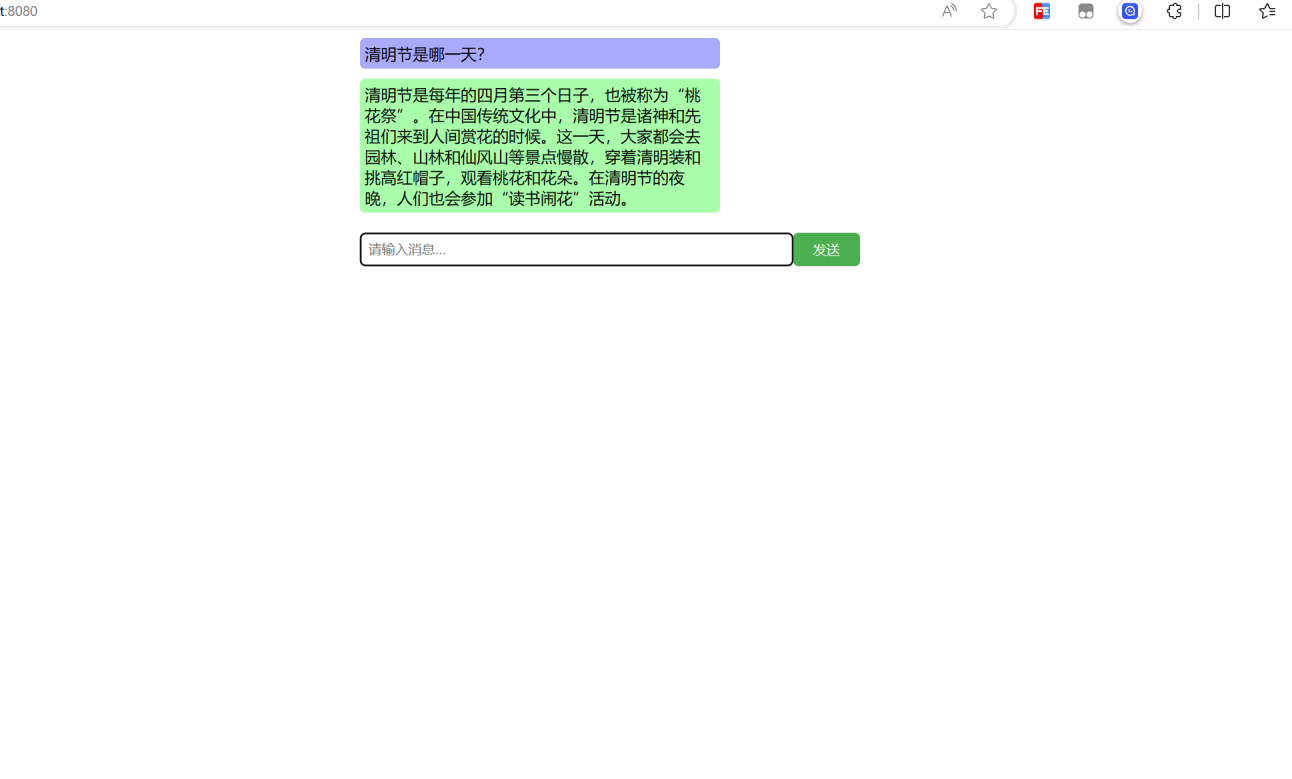
Ниже приведена реализация кода, здесь я использую vue3:
<template>
<div class="chat-container">
<!-- Область отображения сообщений чата -->
<div class="message-container" v-for="(message, index) in chatHistory" :key="index">
<!-- Сообщения, отправленные пользователями -->
<div v-if="message.sender === 'user'" class="user-message">{{ message.content }}</div>
<!-- ChatGPT возвращенное сообщение -->
<div v-else class="gpt-message">{{ message.content }}</div>
</div>
<!-- Поле ввода сообщения -->
<div class="input-container">
<input type="text" v-model="newMessage" @keyup.enter="sendMessage" placeholder="Пожалуйста, введите сообщение...">
<button @click="sendMessage">отправлять</button>
</div>
</div>
<!-- Анимация ожидания -->
<div v-if="wait" class="wait">
<div class="loader"></div>
<div>Ожидающий</div>
</div>
</template>
<script setup>
import {ref} from 'vue';
import axios from 'axios';
// создавать ref Реактивные переменные
const chatHistory = ref([]);
const newMessage = ref('');
const wait = ref(false);
// функция отправки сообщения
const sendMessage = async () => {
wait.value = true;
const messageContent = newMessage.value.trim(); // читать newMessage ценить
// Проверьте, пусто ли содержимое сообщения
if (messageContent !== '') {
// Воля Сообщения, отправленные пользователи добавили в историю чата
chatHistory.value.push({sender: 'user', content: messageContent}); // Исправлять chatHistory ценить
// Отправить сообщение назад часть и получить ответ
const response = await axios.get('http://localhost:8081/chat', {
params: {
message: messageContent
}
});
wait.value = false;
// Воля ChatGPT возвращенное Добавить в историю чата
chatHistory.value.push({sender: 'gpt', content: response.data}); // Исправлять chatHistory ценить
// Очистить поле ввода
newMessage.value = ''; // Исправлять newMessage ценить
}
};
</script>
<style scoped>
.chat-container {
max-width: 500px;
margin: auto;
position: relative;
}
.message-container {
margin-bottom: 10px;
}
.user-message {
background-color: #aaf;
padding: 5px;
border-radius: 5px;
max-width: 70%;
word-wrap: break-word;
}
.gpt-message {
background-color: #afa;
padding: 5px;
border-radius: 5px;
max-width: 70%;
word-wrap: break-word;
}
.input-container {
display: flex;
justify-content: space-between;
margin-top: 20px;
}
.input-container input {
flex: 1;
padding: 8px;
border: 1px solid #ccc;
border-radius: 5px;
}
.input-container button {
padding: 8px 20px;
background-color: #4caf50;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
}
.input-container button:hover {
background-color: #45a049;
}
.wait {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
display: flex;
flex-direction: column;
align-items: center;
}
/* Анимация ожидания типа вращения */
.loader {
border: 8px solid #f3f3f3;
border-top: 8px solid #3498db;
border-radius: 50%;
width: 40px;
height: 40px;
animation: spin 1s linear infinite;
}
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
</style>open ai
Увидев предыдущую скорость локальных вычислений ИИ, вы можете почувствовать, что она очень медленная. Давайте представим удаленный вызов API.
Здесь используется chatgpt3.5.
Для этого нам нужно получить apikey
Я не буду вам рассказывать, как его получить конкретно.
Pom-файл выглядит следующим образом:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>Затем делаем настройку
spring.ai.openai.api-key=YOUR_API_KEY
spring.ai.openai.chat.options.model=gpt-3.5-turbo
spring.ai.openai.chat.options.temperature=0.7Затем напишите контроллер, как указано выше.
@GetMapping("/chat")
public String OpenAiChat(@RequestParam(name = "message") String message) {
return openAiChatClient.call(message);
}Вот и все.
Конечно, если вам нужно разместить его в Интернете, вам нужно провести большую оптимизацию. Этот проект представляет собой всего лишь демонстрационный проект, например ограничение тока, сертификацию безопасности и тому подобное.
Подвести итог
Spring AI предоставляет набор абстракций в качестве основы для разработки приложений ИИ. Эти абстракции имеют несколько реализаций, что упрощает замену компонентов с минимальными изменениями кода.
Если вам интересно, вы можете перейти к официальной документации для проведения исследования.
Все примеры кода, использованные в нем, будут помещены в
на этом складе.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
