Первое знакомство с большими данными ------Как Flink реализует однократный расчет без дублирования и потерь?
Flink использует Kafka для связывания вычислительных задач и использует Kafka ровно один раз для достижения потоковых вычислений без дублирования или потерь. Семантика Kafka Exactly Once совместно реализуется посредством его характеристик транзакционной и производственной идемпотентности.
1. Архитектура среды потоковых вычислений и ее вычислительные принципы.
Flink — это платформа потоковых вычислений в реальном времени, «в реальном времени». Одно означает, что данные генерируются в «реальном времени», а другое означает, что процесс статистического анализа выполняется в «реальном времени».
Независимо от того, используете ли вы Flink, Spark или другие платформы потоковых вычислений, задачу определения потоковых вычислений можно в основном разделить на три части: определение ввода, определение логики вычислений и определение вывода. С точки зрения непрофессионала, то есть: откуда поступают данные. Откуда посчитать и куда записать результаты - это три вещи.
Как выполняются вычислительные задачи во Flink? Общая картина следующая:

Эта картина немного сложна, поэтому давайте не будем обращать внимания на детали и посмотрим на общую картину. Кластер Flink похож на другие распределенные системы. Большинство узлов в кластере являются узлами TaskManager, и каждый узел представляет собой процесс Java, отвечающий за выполнение вычислительных задач. Другой тип узла — это узел JobManager, который отвечает за управление и координацию всех вычислительных узлов и вычислительных задач. В то же время клиент и веб-консоль также отправляют и управляют каждой вычислительной задачей через JobManager.
После того, как мы напишем код вычислительной задачи, упакуем его в JAR-файл, а затем отправим его в JobManager через клиент Flink. После того, как вычислительная задача будет проанализирована Flink, будет создан граф потока данных, также называемый JobGraph или сокращенно DAG. Это ориентированный ациклический граф (DAG).
Каждый узел в JobGraph — это задача, задача может выполняться параллельно, а каждый поток — это подзадача. Подзадача назначается TaskManager с помощью JobManager и выполняется в потоке процесса TaskManager.
2. Практика: используйте Kafka для разделения вычислений и хранения в памяти (распределенная файловая система HDF).
Сама среда потоковых вычислений представляет собой распределенную систему, обычно состоящую из нескольких узлов, образующих кластер. Когда наши вычислительные задачи выполняются в вычислительном кластере, они будут разделены на несколько подзадач, и эти подзадачи также распределяются по нескольким вычислительным узлам в кластере.
Большинство платформ потоковых вычислений используют конструкцию разделения хранения и вычислений и сохраняют статус вычислительных задач в распределенных системах хранения, таких как HDFS. После того, как каждая подзадача разделяет состояние, он становится узлом без состояния. Если вычислительный узел выходит из строя, любой узел в кластере можно использовать для замены вышедшего из строя узла.
Однако для потоковых вычислений все еще существует нерешенная проблема: данные, текущие в кластере, не сохраняются, поэтому они могут быть потеряны из-за сбоя узла. Как решить эту проблему? Этот метод также относительно прост и груб: он заключается в непосредственном перезапуске всей вычислительной задачи и отслеживании некоторых данных из источника данных. После перезапуска вычислительной задачи произойдет перераспределение вычислительных узлов и миграция неисправностей завершится.
Обратная трассировка источника данных может гарантировать, что данные не будут потеряны. Это похоже на метод повторной отправки неудачных сообщений в очередях сообщений, чтобы гарантировать, что данные не будут потеряны.
Кластер Flink сам по себе также является распределенной системой. Сначала необходимо обеспечить, чтобы данные вычислялись только один раз внутри кластера Flink. Только на этой основе можно достичь сквозного метода Exactly Once.
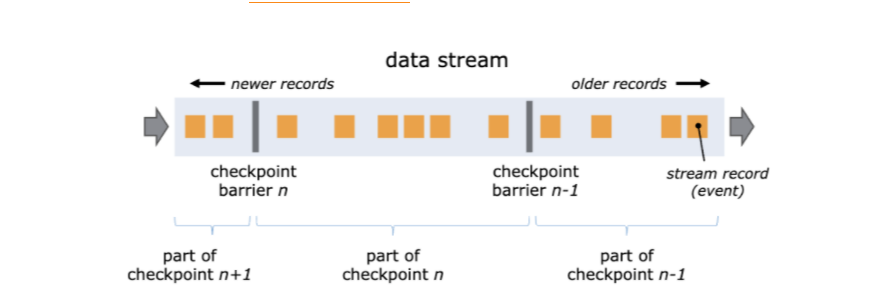
Flink использует механизм CheckPoint для регулярного сохранения снимков вычислительных задач. Этот снимок в основном содержит две важные данные:
Статус всей вычислительной задачи. Это состояние в основном представляет собой временные данные о состоянии, которые каждая подзадача должна сохранять во время процесса расчета в задаче расчета. Например, половина данных была суммирована в примере из предыдущего урока.
Информация о местоположении источника данных. Эта информация записывает, какие данные были рассчитаны в этом потоке из источника данных. Если источником данных является тема Kafka, эта информация о местоположении является местом потребления в теме Kafka.
Flink гарантирует, что позиция и состояние в CheckPoint полностью соответствуют друг другу, вставляя в поток данных Barrier.
краткое содержание
Сквозная семантика Exactly Once может гарантировать, что в распределенной системе каждый фрагмент данных обрабатывается только один раз. В потоковых вычислениях, поскольку дублирование данных может привести к ошибкам в результатах вычислений, функция Exactly Once особенно важна в сценариях потоковых вычислений. И Kafka, и Flink предоставляют функции, которые гарантируют Exactly Once, а при совместном использовании может быть достигнута сквозная семантика Exactly Once.
В Flink в случае сбоя узла вычислительные задачи могут быть автоматически перезапущены, а вычислительные узлы могут быть переназначены для обеспечения доступности системы. Сотрудничая с механизмом CheckPoint, он может гарантировать, что состояние задачи после перезапуска будет восстановлено до последнего CheckPoint, а затем продолжить чтение данных из позиции восстановления, записанной в CheckPoint для расчета. Flink использует умный Barrier, чтобы полностью соответствовать позиции восстановления в CheckPoint и статусу каждого узла.
Семантика Exactly Once в Kafka реализована совместно посредством идемпотентных функций транзакций и производства. При работе с Flink каждая CheckPoint Flink соответствует транзакции Kafka. Пока транзакции CheckPoint и Kafka отправляются синхронно, может быть достигнут сквозной метод Exactly Once, который гарантирует CheckPoint с помощью классического «двухфазного» алгоритма. commit» для распределенных транзакций. Согласованность с состоянием транзакции Kafka.
ЯсуществоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Соберите команду, чтобы выиграть приз!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
