Перспектива интеграции программного и аппаратного обеспечения: понимание высокопроизводительных сетей в одной статье
С широкой популярностью больших моделей масштаб кластерных вычислений на графических процессорах становится все больше и больше (вычислительная мощность одного чипа ограничена, а общую вычислительную мощность можно улучшить только за счет расширения масштаба на тысячу карт и десять). тысячи карт стали мейнстримом, а сто тысяч карт стали мейнстримом. Карты и карты на миллион долларов также планируются на ближайшие 3-5 лет.
Сети кластерных вычислений можно разделить на две категории: трафик север-юг, обычно известный как внешний сетевой трафик; трафик восток-запад, обычно известный как трафик внутренней сети. Количество сетевых подключений для кластерных вычислений S = N x (N-1) (N — количество узлов). Именно поэтому трафик восток-запад в дата-центрах сейчас составляет более 90%. В сочетании с увеличением сетевого трафика между севером и югом, вызванным расширением масштаба системы, пропускная способность сети, необходимая для центра обработки данных, увеличивается в геометрической прогрессии.
В 2019 году NVIDIA приобрела Mellanox. Благодаря своим ведущим преимуществам в InfiniBand и ROCEv2, NVIDIA стала повелителем высокопроизводительных сетей. Чтобы не отставать, основные конкуренты, особенно производители облачных вычислений, такие как AWS и Alibaba Cloud, последовательно запустили свои собственные высокопроизводительные сетевые протоколы и соответствующие продукты. В отрасли полно конкурирующих школ. Высокопроизводительные сети — это поле битвы для военных стратегов, мы подождем и посмотрим, кто будет доминировать в будущем.
В этой статье представлены и анализируются технологии, связанные с высокопроизводительными сетями, с точки зрения интеграции программного и аппаратного обеспечения, что позволяет каждому понять высокопроизводительные сети в одной статье.
1 Обзор высокопроизводительных сетей
1.1 Параметры производительности сети
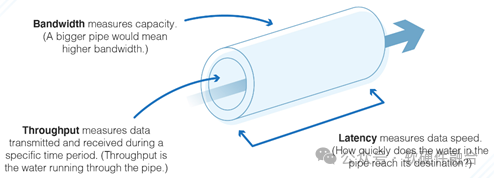
Производительность сети в основном зависит от трех параметров: пропускной способности, пропускной способности и задержки:
- Пропускная способность: относится к объему данных, которые могут быть переданы в течение определенного периода времени. Высокая пропускная способность не обязательно гарантирует оптимальную производительность. Например,На пропускную способность сети влияют потеря пакетов, джиттер или задержка.,У вас могут возникнуть проблемы с задержкой.
- Пропускная способность: относится к объему данных, которые могут быть отправлены и получены в течение определенного периода времени. Средняя пропускная способность сети дает пользователям представление о количестве пакетов, которые успешно достигли нужного места назначения. Для высоких производительность,Пакет должен иметь возможность достичь правильного пункта назначения. Если во время передачи потеряно слишком много пакетов,Тогда производительность сети может оказаться недостаточной.
- Задержка: время, необходимое пакету для достижения пункта назначения после отправки. Мы измеряем задержку сети как обратный путь. Результатом задержек часто является нестабильное и отстающее обслуживание. Например, видеоконференции и т.п.,Очень чувствителен к задержке.
Кроме того, есть еще очень важный показатель PPS (Packet Per Second, количество пакетов, передаваемых в секунду). Многие сетевые устройства могут достигать скорости линии при использовании больших пакетов, но при использовании малых пакетов (64 байта) их производительность сильно ухудшается, в основном из-за недостаточных возможностей PPS. Таким образом, идеальной ситуацией является достижение скорости линии при минимальном размере пакета.
Высокопроизводительная сеть должна обеспечивать максимальную пропускную способность (бесконечно близкую к пропускной способности сети) с низкой задержкой (чем меньше, тем лучше) и низким уровнем джиттера (независимо от больших или малых пакетов, любого узла сети). Конечно, эти параметры влияют друг на друга, и реальная система представляет собой баланс между этими параметрами.
1.2 Сложная многоуровневая сеть
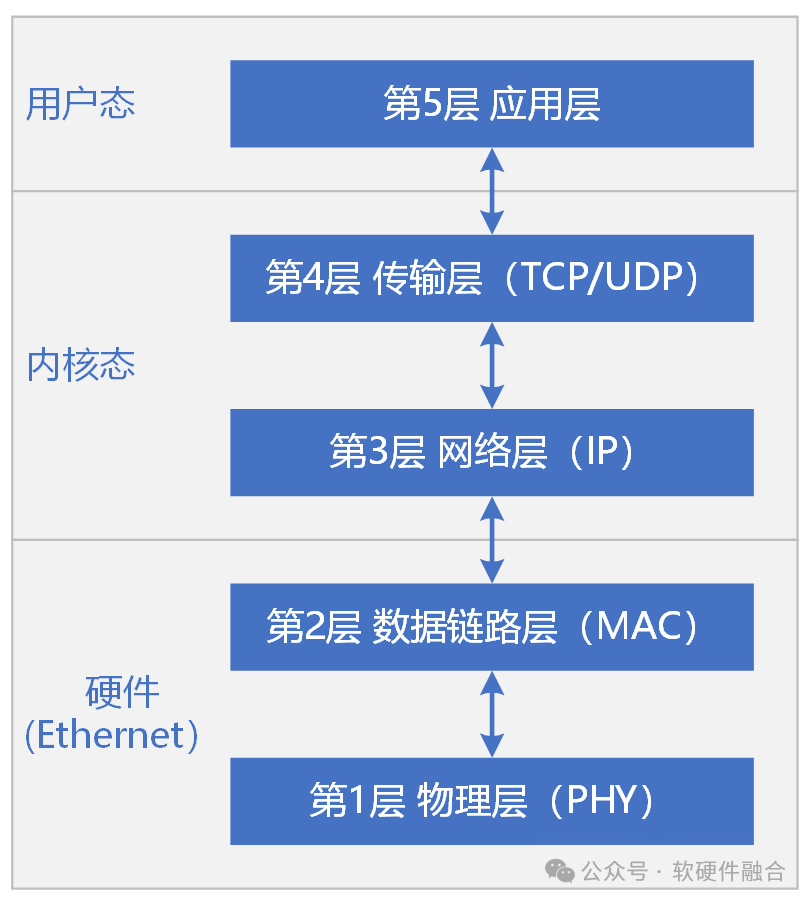
OSI определяет семиуровневый сетевой протокол. Сетевой протокол TCP/IP, используемый в реальных инженерных приложениях, обычно состоит из пяти уровней:
- Снизу вверх: физический уровень、канальный уровень、сетьслой、Транспортный уровень и прикладной уровень.
- Обычно,Физический уровень и канальный уровень реализованы в аппаратном обеспечении.,Сетевой уровень, транспортный уровень и прикладной уровень реализованы программно.
- Семейство TCP/IP — это группа протоколов связи, используемых в компьютерах. Базовыми протоколами являются управление передачей (TCP), интернет-протокол (IP) и пользовательские дейтаграммы (UDP).
- Ethernet — это технология, предназначенная для обеспечения связи в локальной сети.,Он определяет содержание физического уровня проводки, электронных сигналов и уровня протокола доступа к среде передачи. Ethernet в настоящее время является наиболее часто используемой технологией.

Сеть центра обработки данных более сложна и разделена на оверлейную и подлежащую сеть. Если сеть является многоуровневой в соответствии с функциональной логикой, сеть центра обработки данных облачных вычислений можно разделить на три уровня:
- первый этаж,Основы физики сетевого подключения,Это то, что мы обычно понимаем как базовую транспортную сеть Underlay;
- второй этаж,Виртуальная сеть, построенная на основе базовой физической сети.,Это то, что мы обычно понимаем под туннельным наложением;
- третий этаж,Различные видимые пользователю сервисы уровня приложений,Например, шлюз доступа, балансировка нагрузки и т. д. Это также могут быть другие обычные приложения, требующие использования сети.
Физический центр обработки данных представляет собой локальную сеть, которая разделена на десятки тысяч виртуальных частных сетей через оверлейную сеть. После междоменной изоляции требуется определенный механизм сетевой безопасности для достижения высокопроизводительного междоменного доступа.

По логике сетевой обработки сеть можно разделить на три части:
- первый этап,Упаковка/распаковка бизнес-данных. Когда Tx направлен,Упакуйте бизнес-данные в соответствии с установленным сетевым форматом Rx;,Это распаковка полученного пакета данных.
- второй этап,Обработка сетевых пакетов. Такие как Оверлейсет,Пакет данных необходимо снова инкапсулировать, например, с помощью брандмауэра;,Для идентификации сетевого пакета,Разрешить ли передачу (как входную, так и выходную, например шифрование и дешифрование сетевых пакетов);
- Третий этап — передача сетевого пакета (Tx/Rx). Это высоко производительностьсетьсосредоточиться на части.
1.3 Зачем нужны высокопроизводительные сети
Зачем вам нужна высокопроизводительная сеть?
- Причина первая,сетьчрезвычайной важности。
- Важность сетевых соединений: сеть соединяет все узлы.,Различные услуги связаны через сеть,Пользователи работают удаленно через сеть. Нет сети,Все пусто.
- Сложность сети: Бизнес-системы,Либо уровень одного сервера, либо уровень кластера, сетевые системы — это, по сути, уровень центра обработки данных;,В масштабе всего дата-центра,Создавайте различную сложную бизнес-логику,Сложность всей системы очень высока.,Влияние также велико.
- Серьезность сбоя в сети: сбой вычислительного сервера и сбой сервера хранения являются локальными сбоями.,А сбой в сети влияет на весь организм. Любой крошечный сбой в сети,Все это может привести к тому, что весь центр обработки данных станет недоступным. сети При возникновении неисправности,Должно быть, это серьезный провал.
- Причина вторая,Сверхбольшие кластерные вычисления,Увеличился трафик с востока на запад. Сложные вычислительные сценарии в центрах обработки данных,Система продолжает разрушаться,Увеличение трафика с востока на запад,Требования к пропускной способности сети быстро повышаются с 10G и 25G до 100G.,Даже 200G.
- Причина третья,передача на короткие расстояния,Задержка системного стека выделена. По сравнению с городской сетью или глобальной сетью Интернета,Расстояние передачи данных по сети центра обработки данных очень короткое,Задержка в стеке серверной системы выделена.
- Причина четвертая,Узкое место в производительности процессора,сети Задержка обработки еще больше увеличивается. Пропускная способность сети быстро увеличивается,Производительность процессора уже ограничена. потребление ресурсов сети ЦП при обработке стека быстро возрастает,И задержка еще больше увеличивается.
- Причина пятая: межсерверные вызовы чувствительны к задержкам. Вызовы между программными службами требуют, чтобы удаленные вызовы между серверами имели низкую задержку, близкую к задержке локальных вызовов.
1.4 Контроль перегрузки сети
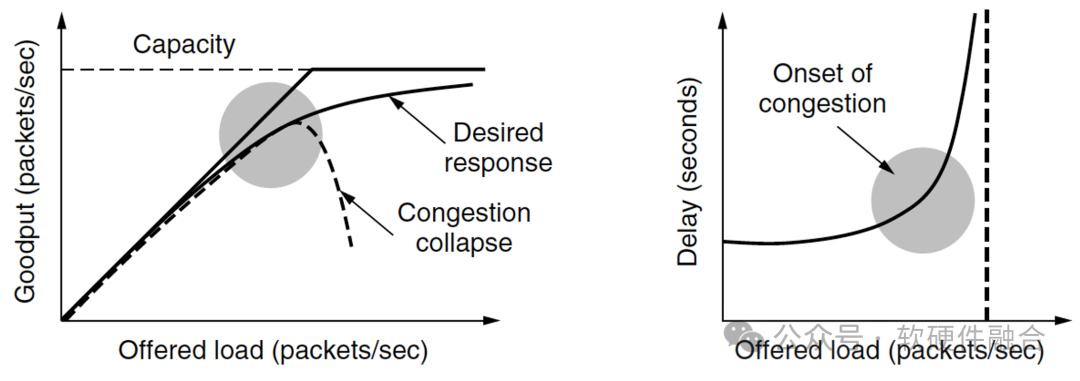
Если в сети слишком много пакетов данных, пакеты будут задерживаться и отбрасываться из-за тайм-аута, что снижает производительность передачи. Это называется перегрузкой. Высокопроизводительная сеть должна полностью использовать пропускную способность сети, обеспечивать передачу данных по сети с малой задержкой и максимально избегать перегрузки сети.
Когда количество пакетов данных, отправленных хостом, находится в пределах диапазона передачи сети, доставка увеличивается пропорционально количеству отправленных пакетов данных. Однако по мере того, как нагрузка приближается к пределу пропускной способности сети, случайные всплески сетевого трафика вызывают коллапс перегрузки, когда загруженные пакеты данных приближаются к пределу пропускной способности, задержка резко возрастает, что является перегрузкой сети;
В чем разница между контролем перегрузки (CC) и управлением потоком? Контроль перегрузки, гарантирующий, что сеть может передавать весь поступающий трафик, является глобальной проблемой; контроль потока, гарантирующий, что быстрый отправитель не будет непрерывно передавать со скоростью, превышающей пропускную способность приемника, является проблемой сквозной передачи.
По эффекту от медленного к быстрому методы борьбы с заторами можно разделить на:
- Сеть с более высокой пропускной способностью;
- Настройте маршрутизацию с учетом трафика на основе шаблонов трафика;
- Уменьшите нагрузку, например, контроль допуска;
- Доставлять информацию обратной связи на исходную сторону, требуя от исходной стороны подавления трафика;
- Все попытки провалились,сеть отбрасывает недоставленные пакеты.
Основные принципы алгоритма контроля перегрузок заключаются в следующем:
- Оптимизированный метод распределения полосы пропускания позволяет полностью использовать всю доступную полосу пропускания, избегая при этом перегрузки;
- Алгоритм распределения полосы пропускания справедлив для всех передач, обеспечивая как слоновьи, так и мышиные потоки;
- Алгоритм контроля перегрузок может быстро сходиться.
1.5. Многопутевая маршрутизация с равной стоимостью ECMP
Архитектура CLOS — это топология, используемая для построения высокопроизводительных и надежных сетей центров обработки данных. Под влиянием таких факторов, как рост трафика с востока на запад, центры обработки данных обычно принимают структуру CLOS, чтобы удовлетворить потребности сетевого трафика с большой пропускной способностью. Архитектура CLOS позволит существовать нескольким сетевым путям между хостами, а «многопуть» является основой для создания высокопроизводительных и высоконадежных сетей.
Становится все более важным становится то, как использовать топологию сети центра обработки данных, ресурсы путей, ресурсы полосы пропускания и т. д., чтобы лучше достигать балансировки нагрузки сетевого трафика, распределять потоки данных по различным путям передачи данных, избегать перегрузок и улучшать использование ресурсов в центре обработки данных. и более важно.
ECMP (многопутевая маршрутизация с равной стоимостью, многопутевая маршрутизация с равной стоимостью) — это пошаговая стратегия балансировки нагрузки на основе потоков. Когда маршрутизатор обнаруживает, что для одного и того же адреса назначения появляется несколько оптимальных путей, он обновляет их. таблицу маршрутизации. Для этого добавьте к адресу несколько правил, соответствующих нескольким следующим переходам. Эти пути можно использовать одновременно для пересылки данных и увеличения пропускной способности.
Существует множество методов выбора стратегии общего пути ECMP:
- Хеширование, например выбор пути для потока на основе хэша исходного IP-адреса.
- Опрос: каждый поток опрашивается по нескольким путям передачи.
- В зависимости от веса пути потоки распределяются в соответствии с весом пути. Путям с большим весом выделяется больше потоков.
Следует отметить, что в такой среде, как центр обработки данных, где наблюдается большой импульсный трафик и сосуществуют слоновьи потоки и потоки мыши, необходимо тщательно продумать стратегию балансировки нагрузки. Хотя ECMP прост и удобен в развертывании, их много. проблемы, на которые необходимо обратить внимание.
2 Высокопроизводительная сеть TCP/IP
Стек протоколов TCP/IP в основном относится ко всему системному стеку Ethernet+TCP/IP+Socket.
2.1 Аппаратная разгрузка стека протоколов TCP/IP
Первая категория, освобождающая от некоторых функций TCP.
- TSO,TCP Segmentation Разгрузка, с помощью сетевой карты аппаратное обеспечение возможности фрагментации TCP-пакетов.
- UFO,UDP Fragmentation Offload , поддержка UDP для отправки больших пакетов, аппаратное обеспечение будет сегментировано.
- LRO,Large Receive Разгрузка, сетевая карта аппаратное обеспечение Объединяет несколько полученных данных TCP в один большой пакет данных.
- RSS,Receive Side Scaling,Разделить сетевой поток на разные очереди,Затем они распределяются по нескольким ядрам ЦП для обработки.
- CRC Удаление с помощью аппаратного обеспечение Полный расчет CRC и пакетизация.
Вторая категория, разгрузка стека протоколов TCP/IP (TCP/IP Offload Engine, TOE).
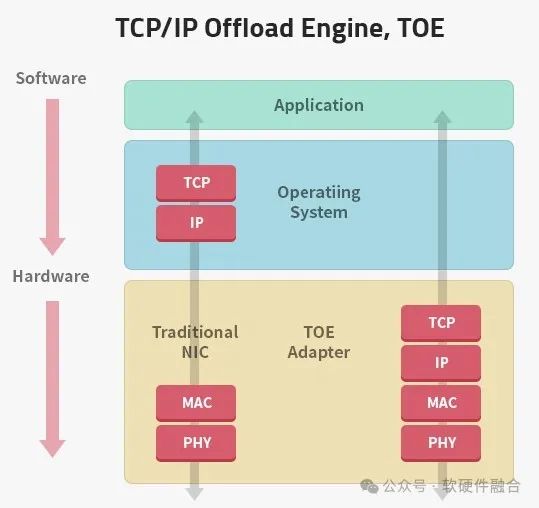
Накладные расходы на обработку традиционных программных сетевых стеков очень высоки. Перегрузка всего стека протоколов TCP/IP на аппаратное обеспечение может повысить производительность сетевой обработки и значительно снизить затраты на процессор.
Стандартное ядро Linux не поддерживает сетевые карты TOE. Основные причины:
- Безопасность. TOEаппаратное реализация программного обеспечения, аппаратное по сравнению с хорошо протестированными программными стеками TCP/IP в ОС Риски безопасности программного обеспечения высоки.
- ограничение аппаратного обеспечения. Поскольку сетевое соединение буферизуется и обрабатывается чипом TOE.,По сравнению с огромными объемами процессора и памяти, доступными программному обеспечению,Более вероятен дефицит ресурсов.
- Сложность. TOE нарушает предположение о том, что ядро всегда имеет доступ ко всем ресурсам.,Также требуются очень большие изменения в сетевом стеке.,несмотря на это,Такие функции, как качество обслуживания и фильтрация пакетов, также могут не работать.
- Настраиваемость. Каждый поставщик представляет собой индивидуальный ОО, а это означает, что для обработки различных реализаций ОО необходимо переписать больше кода за счет сложности решения и возможных рисков безопасности. Кроме того, прошивка TOE имеет закрытый исходный код и не может быть изменена персоналом, занимающимся программным обеспечением.
- Устаревший. ПАЛЕЦ НА НОГЕ Срок службы NIC ограничен: производительность ЦП быстро догонит и превысит производительность TOE, итерация стека программной системы будет значительно быстрее, чем аппаратное; обеспечениепротоколкуча。
Поэтому по вышеуказанным причинам TOE не получил широкого распространения.
2.2 Загрузка стека протоколов TCP/IP прикладного уровня
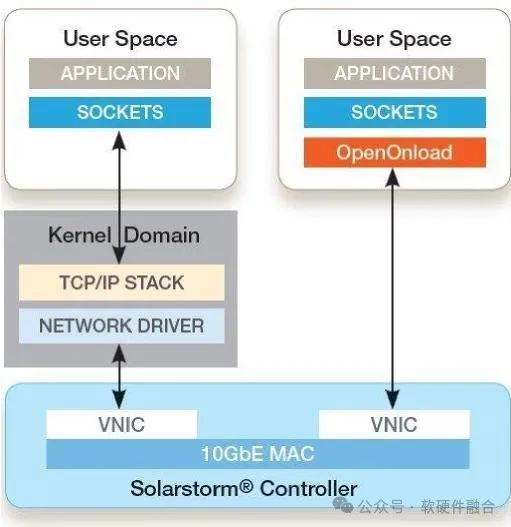
Onload — это ускоренное сетевое промежуточное программное обеспечение Solarflare (Solarflare была приобретена Xilinx, а Xilinx — AMD). Ключевые особенности включают в себя:
- Реализация TCP/UDP на основе IP,Динамическая привязка к адресному пространству приложения пользовательского режима.,Приложения могут отправлять и получать данные напрямую из сети.,Без участия ОС.
- Обход ядра, реализованный Onload, позволяет избежать деструктивных событий, таких как системные вызовы, переключения контекста и прерывания, тем самым повышая эффективность процессора при выполнении кода приложения.
- Библиотека Onload динамически связывается с приложением во время выполнения с помощью стандартного API-интерфейса Socket, что означает, что никаких изменений в приложении не требуется.
- Onload снижает нагрузку на процессор, улучшает задержку и пропускную способность.,и улучшить масштабируемость приложений,существенно сократить расходы.
Основную технологию Onload можно резюмировать следующим образом: аппаратная виртуализация SR-IOV, обход ядра и SocketAPI приложений.
2.3 Оптимизация транспортного протокола: от TCP к QUIC
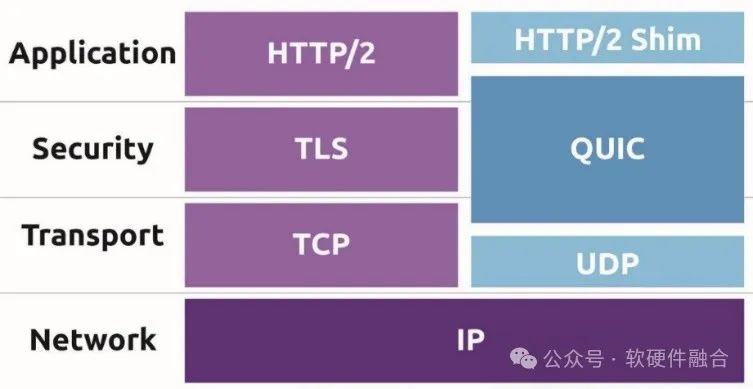
QUIC (Quick UDP Internet Connections, Quick UDP Internet Connections) — это новый протокол передачи данных в Интернете, который оптимизирует и частично или полностью заменяет L4, L5 (безопасность) и L7.
QUIC — это автономный протокол приложения, позволяющий внедрять инновации. Это невозможно при использовании существующих протоколов, чему препятствует устаревшее клиентское и системное промежуточное программное обеспечение.
По сравнению с TCP+TLS+HTTP2 к основным преимуществам QUIC относятся:
- Задержка в установлении соединения. Проще говоря, для подтверждения QUIC требуется 0 циклов передачи данных перед отправкой полезных данных, а для TCP+TLS требуется 1–3 цикла передачи данных.
- Улучшен контроль перегрузок. QUIC в основном реализует и оптимизирует медленный запуск TCP, предотвращение перегрузки, быструю повторную передачу и быстрое восстановление. В зависимости от ситуации можно выбирать различные алгоритмы управления перегрузкой; он позволяет избежать проблем с двусмысленностью повторной передачи TCP и т. д.; .
- Мультиплексирование без внешней блокировки. TCP имеет проблему блокировки начала строки. QUIC предназначен для мультиплексирования операций, и потоки без потерь могут продолжать продвигаться вперед.
- Прямое исправление ошибок. Чтобы восстановить потерянные пакеты, не дожидаясь повторной передачи, QUIC может дополнить набор пакетов пакетом FEC.
- Миграция подключения. TCP-соединения идентифицируются четырьмя кортежами, соединения QUIC идентифицируются 64-битным идентификатором соединения. Если клиент меняет IP-адрес или порт, TCP-соединение становится недействительным; QUIC может использовать старый идентификатор соединения, не прерывая текущие запросы.
3 Обзор стека высокопроизводительных сетевых протоколов на примере IB
3.1 Введение в сетевой протокол IB
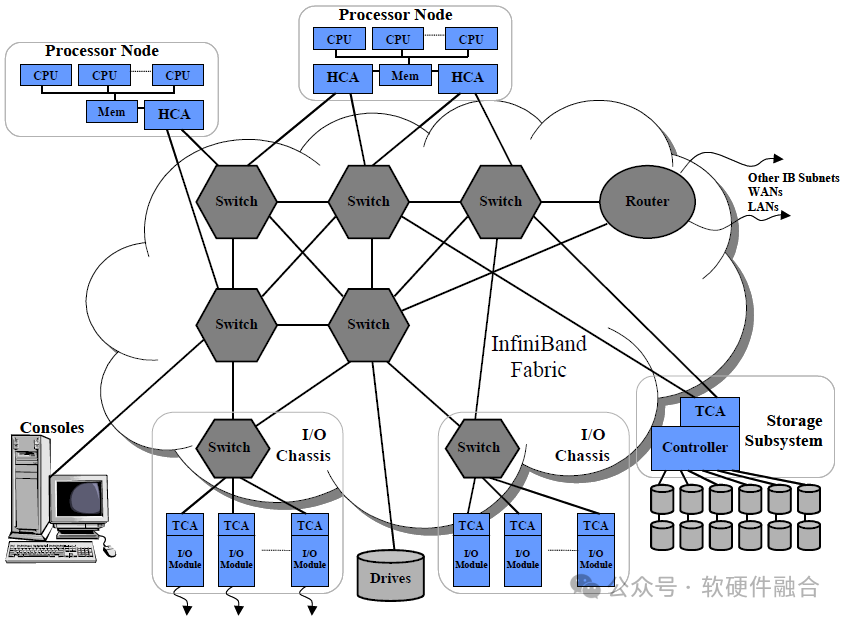
InfiniBand (IB) — это стандарт сетевых коммуникаций для высокопроизводительных вычислений с чрезвычайно высокой пропускной способностью и чрезвычайно низкой задержкой.
IB используется для соединения данных между компьютерами и внутри компьютеров. Его также можно использовать в качестве прямого или коммутируемого соединения между серверами и системами хранения, а также для соединения между системами хранения.
Цель разработки IB: всесторонне рассмотреть вычислительные, сетевые технологии и технологии хранения данных для разработки масштабируемой, высокопроизводительной архитектуры связи и ввода-вывода.
Основные преимущества ИБ:
- производительность, около половины суперкомпьютеров ТОП500 используют IB;
- Низкая задержка, задержка сквозного измерения IB составляет 1 мкс;
- Высокая эффективность,IB изначально поддерживает RDMA и другие протоколы.,Помогите клиентам повысить эффективность обработки рабочих нагрузок.
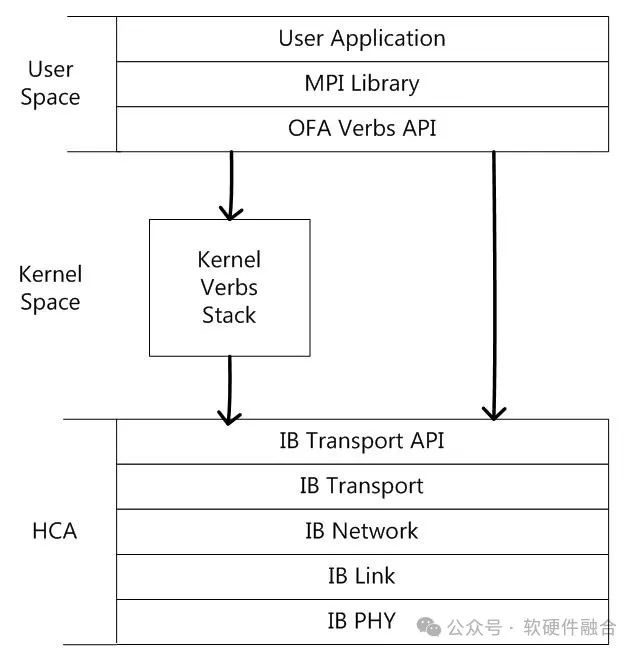
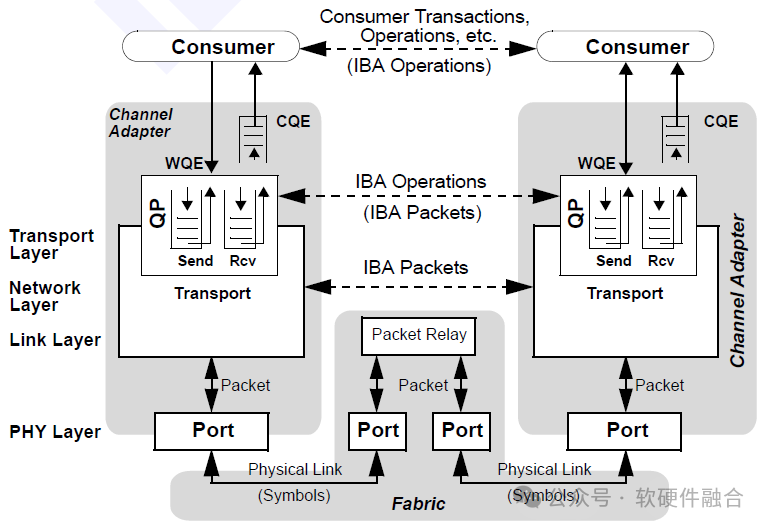
IB также представляет собой пятиуровневую сеть: физический уровень、канальный уровень、сетьслой、Транспортный уровень и прикладной уровень.ТрадициясетьизL1&L2аппаратное реализовано программное обеспечение L3/L4, а IB L1-L4 реализовано аппаратно; реализация программного обеспечения. API транспортного уровня IB — это программное обеспечение между сетевой картой HCA и процессором. обеспечениеинтерфейс。Socket API — это сетевой интерфейс приложений традиционной сети TCP/IP, а Verbs API — это сетевой интерфейс приложений IB. MPI — это библиотека методов, которая реализует распараллеливание, предоставляя параллельную библиотеку, которая может быть основана на OFA. Verbs API, также может быть основан на TCP/IP. Socket。
3.2 Почему IB может добиться высоких результатов?
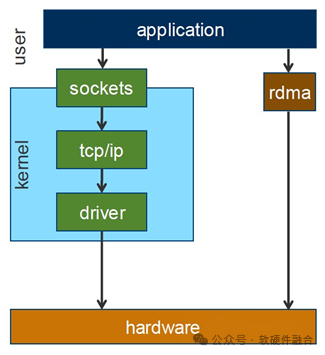
Проблемы с традиционными стеками сетевых протоколов:
- Длинный путь, приложению необходимо подключиться к сетевой карте через системный уровень;
- Делайте несколько копий. Много копий не требуется;
- Недостаточная гибкость,стек протокола проходит через ядро,Это затрудняет пользователям оптимизацию функции протокола.
В рамках четырех аспектов оптимизации производительности стека сетевых протоколов мы суммируем основные технологии оптимизации, используемые полным стеком IB:
- Оптимизация стека протоколов: упрощенно、легкий、Разделенный системный стек.
- ускорятьсяпротоколиметь дело с:протоколаппаратное обеспечение ускорения обработки, Несколько уровней протоколов L2–L4 удалены;
- Уменьшите промежуточные ссылки: такие как RDMA. kernel Bypass,IBсеть Встроенная поддержкаRDMA;
- Оптимизация взаимодействия с интерфейсом: например, мягкое аппаратное обеспечение Механизм взаимодействия, Send/Rcv Queue Pair、Work/Completion Queues。
3.3 InfiniBand vs Ethernet
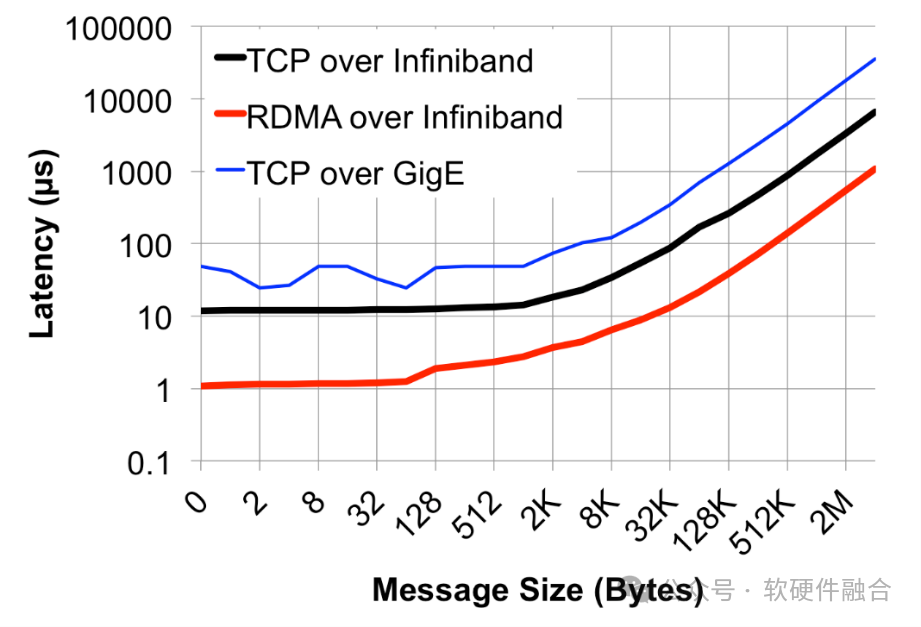
Сравнение Infiniband и Ethernet в различных аспектах:
- цели дизайна. Eth рассматривает, как беспрепятственно обмениваться информацией между несколькими системами, отдавая приоритет совместимости и распределению, IB призван решить проблему передачи данных в сценариях HPC.
- пропускная способность. Скорость сети IB обычно выше, чем у Eth,Основная причина заключается в том, что IB используется для соединения серверов в сценариях HPC.,Eth больше ориентирован на соединение терминальных устройств.
- Задерживать. Задачи, решаемые коммутаторами Eth, относительно сложны.,что приводит к большим задержкам(>200ns)。иIBвыключательиметь дело сочень просто,гораздо быстрее, чемEthвыключатель(<100ns)。использоватьRDMA+IBизсеть Задержка трансивера600ns,Задержка отправки и получения Eth+TCP/IP достигает 10 мкс.,Разница более чем в 10 раз.
- надежность. Потеря пакетов и повторная передача оказывают большое влияние на производительность. IB основан на сквозном управлении потоком, чтобы гарантировать, что пакеты не перегружены на протяжении всего процесса, а дрожание задержки сводится к минимуму. Eth не имеет управления потоком на основе планирования. В крайних случаях может возникнуть перегрузка, приводящая к потере пакетов, что приводит к значительным колебаниям производительности пересылки данных.
- Сетевой метод. О добавлении и удалении узлов в Ethset необходимо уведомлять каждый узел.,Когда количество узлов увеличивается до определенного числа,Произойдет радиовещательный шторм. На втором уровне IB есть менеджер подсети для настройки LocalID.,Затем информация о пути пересылки рассчитывается единообразно.,Вы можете легко развернуть большой сервер второго уровня с десятками тысяч серверов.
4 Высокопроизводительная сеть RDMA
4.1 Обзор RDMA
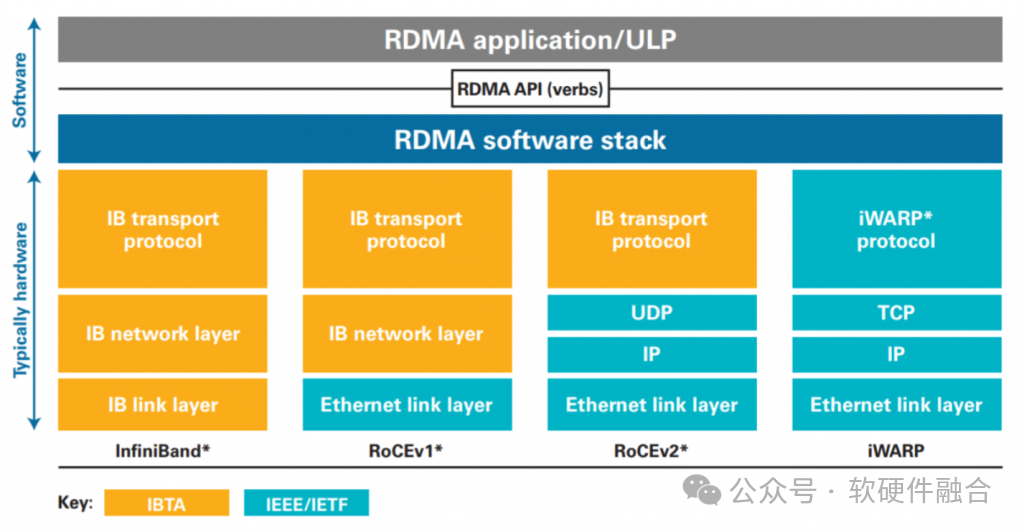
RDMA — это технология межсетевого соединения с высокой пропускной способностью, низкой задержкой и низким потреблением ресурсов ЦП, которая решает многие проблемы традиционных сетей TCP/IP. Технические характеристики RDMA:
- Удаленный, данные передаются между двумя узлами;
- прямой,Никакого участия ядра не требуется.,Вся обработка передачи перекладывается на аппаратное обеспечение NIC;
- Память, данные передаются между виртуальной памятью приложения двух узлов без дополнительного копирования;
- Доступ, операции доступа включают отправку/получение, чтение/запись и т. д.
Некоторые другие характеристики RDMA:
- RDMA и IB изначально интегрированы;
- RoCEv1 — это RDMA, основанный на стандарте Eth;
- RoCEv2 основан на стандартах Eth, IP и UDP и поддерживает стандартные маршрутизаторы L3.
4.2 Уровни системного стека RDMA/RoCEv2
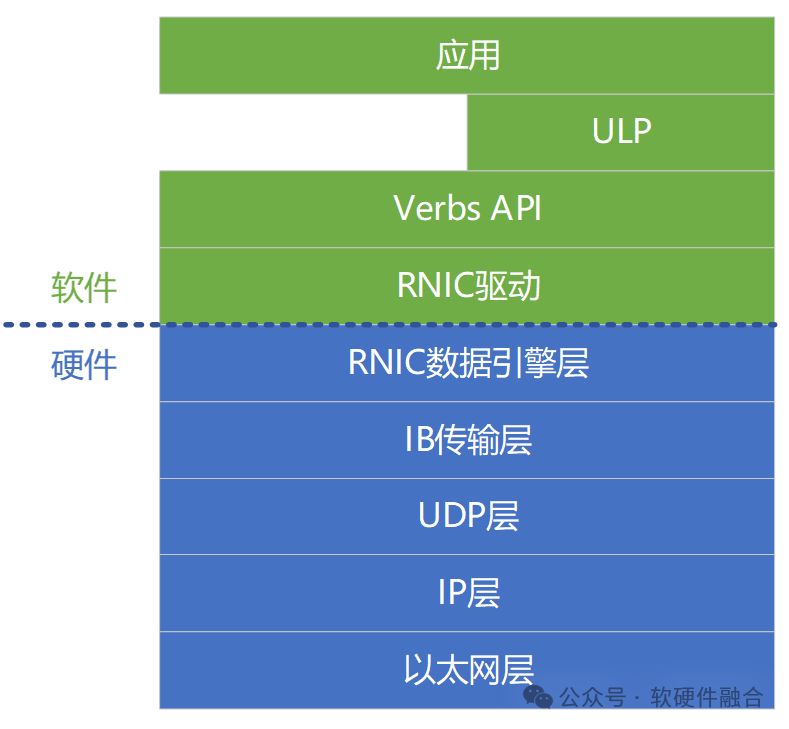
RoCEv2 — популярная технология RDMA в современных центрах обработки данных. Мы возьмем RoCEv2 в качестве примера, чтобы представить многоуровневую систему RoCE:
- Уровень Ethernet: Стандартный уровень Ethernet,Прямо сейчассетьпятьслойпротоколфизикаслойиканальный уровень。
- сетьслойIP:сетьпятьслойпротоколсерединаизсетьслой。
- Транспортный уровень UDP: Транспортный уровень в пятиуровневом протоколе сети (UDP вместо TCP).
- Транспортный уровень IB: отвечает за распределение, сегментацию, мультиплексирование каналов и услуги передачи пакетов данных.
- Уровень механизма данных RDMA (данные Engine Слой): Отвечает за память и RDMAаппаратное. обеспечение между работой/завершением запрошенной передачи данных и т. д.
- Уровень драйвера интерфейса RDMA: отвечает за аппаратное обеспечение RDMA. обеспечение управления конфигурацией, управление очередью и памятью, ответственное за добавление рабочих запросов в рабочую очередь, ответственное за завершение обработки запросов и т. д. Уровень драйвера интерфейса и уровень механизма обработки данных вместе образуют аппаратное программное обеспечение RDMA. обеспечениеинтерфейс。
- Verbs Уровень API: инкапсуляция глаголов драйвера интерфейса, управление состоянием соединения, управление памятью и поворотным доступом, а также передача работы в RDMAаппаратное. обеспечение、отRDMAаппаратное обеспечение Получите работу и мероприятия.
- Слой ULP: OFED Библиотека ULP (протокол верхнего уровня) обеспечивает RDMA для различных программных протоколов. Поддержка Verbs позволяет легко переносить приложения верхнего уровня на платформу RDMA.
- Прикладной уровень: собственное приложение RDMA, основанное на RDMA. verbs Разработка API; OFA также предоставляет стек протоколов OFED, позволяющий существующим приложениям беспрепятственно использовать функции RDMA.
4.3 Рабочая очередь RDMA
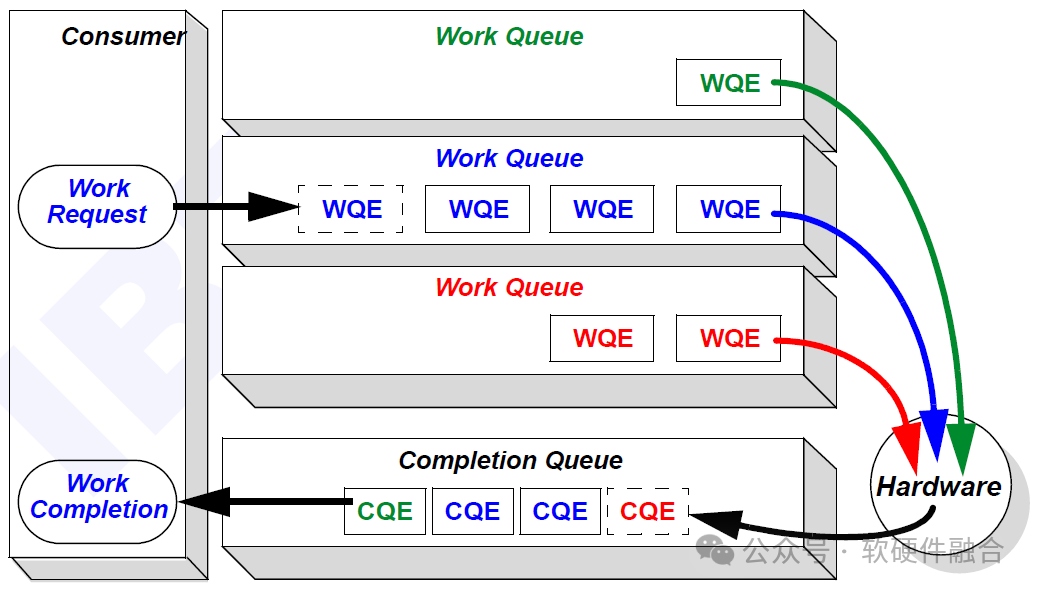
У RDMA нет строгих программных и аппаратных интерфейсов, и реализация в каждой компании может быть разной. Требуется только поддержка механизма очереди RDMA.
Взаимодействие между программными драйверами и аппаратными устройствами обычно основано на модели производитель-потребитель, которая обеспечивает асинхронное разделение взаимодействия программного и аппаратного обеспечения. Структура данных очереди, совместно используемая программным и аппаратным обеспечением RDMA, называется рабочей очередью.
Драйвер отвечает за добавление рабочего запроса (Work Request) в рабочую очередь и превращение его в элемент рабочей очереди, называемый элементом рабочей очереди WQE. Аппаратное устройство RDMA будет отвечать за передачу WQE между памятью и оборудованием и, наконец, отправлять WQE в рабочую очередь получателя через сеть RDMA.
Аппаратное обеспечение RDMA получателя отправит информацию о подтверждении на аппаратное обеспечение RDMA отправителя, а оборудование RDMA отправителя сгенерирует элемент CQE очереди завершения на основе информации подтверждения и отправит его в очередь завершения памяти.
Типы очередей RDMA включают в себя: очередь отправки, очередь приема, очередь завершения и пара очередей. Очередь отправки и очередь приема образуют пару очередей. SRQ, общая очередь приема. Совместное использование RQ для всех связанных QP. Этот общий RQ называется SRQ.
4.4 RDMA Verbs API
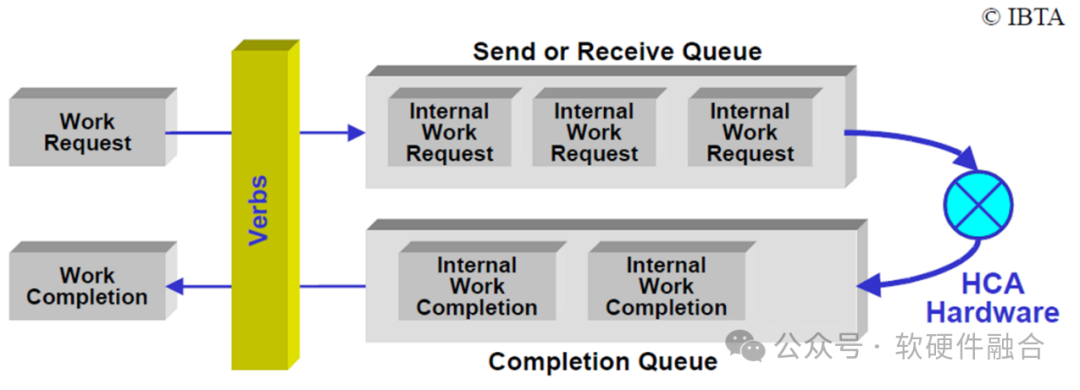
Глаголы RDMA — это абстракции функций и действий RDMA, предоставляемые приложениям. Verbs API — это особая реализация Verbs, предоставляющая стандартный интерфейс для вызовов приложений.
В RoCEv2 существует два основных типа операций с глаголами:
- Отправить/получить. Подобно структуре Клиент/Сервер, операция отправки и операция получения выполняются совместно. Прежде чем отправитель подключится, получатель должен находиться в состоянии прослушивания, а получатель не знает местоположение виртуальной памяти; не знать виртуальную память адреса отправителя. Поскольку RDMA Send/Recv работает непосредственно с памятью, область памяти, используемую для передачи, необходимо зарегистрировать заранее.
- Написать/Читать. В отличие от архитектуры клиент/сервер, запись/чтение заключается в том, что запрашивающая сторона активна, а отвечающая пассивна. Запрашивающая сторона выполняет операцию записи/чтения, а ответчику не требуется выполнять какие-либо операции. Чтобы иметь возможность управлять памятью ответчика, запрашивающему необходимо заранее получить адрес ответчика и значение ключа.
5 высокопроизводительных сетей AWS SRD
5.1 Обзор AWS SRD и EFA
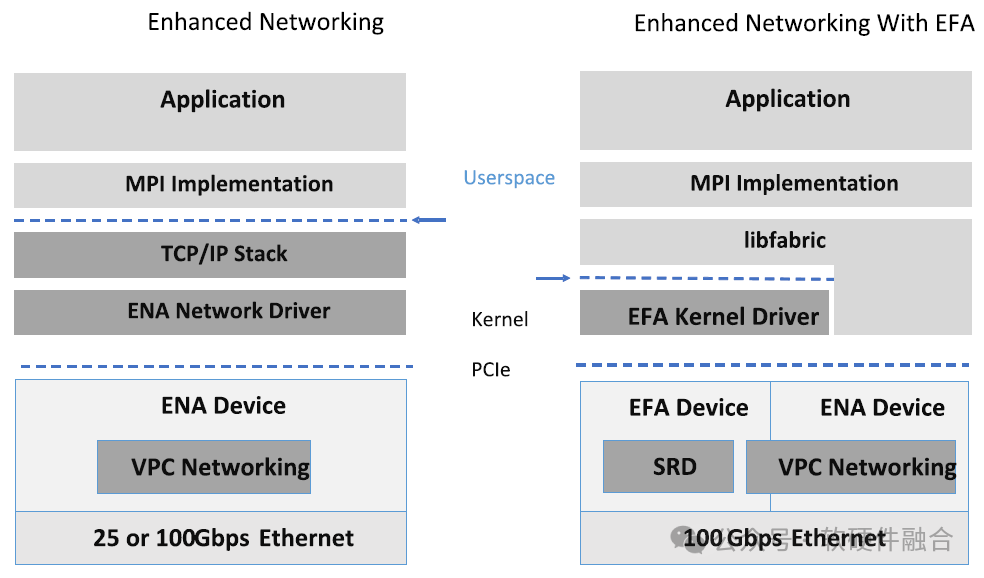
SRD (Scalable Reliable Datagram, масштабируемая надежная дейтаграмма) — это надежный, высокопроизводительный протокол сетевой передачи с малой задержкой, разработанный AWS; EFA (адаптер Elastic Fabric) — это тип, предоставляемый экземплярами AWS EC2. Высокопроизводительный сетевой интерфейс.
Технологии AWS SRD и EFA в основном имеют следующие характеристики:
- Ethernet на основе стандартов SRD,Используется для оптимизации протокола транспортного уровня.
- SRD основан на надежных датаграммах IB.,в то же время,Рассмотрение рабочих нагрузок в сценариях крупномасштабных облачных вычислений,Использует ресурсы и функции облачных вычислений (например, сложную многопутевую магистраль AWS) для поддержки новых стратегий передачи данных.,Сделайте его ценным в тесно связанных рабочих нагрузках.
- Благодаря EFA приложения HPC, использующие интерфейс передачи сообщений MPI, и приложения ML, использующие библиотеку коллективных коммуникаций NVIDIA (NCCL), могут легко масштабироваться до тысяч процессоров или графических процессоров.
- Существует два программного обеспечения пользовательского пространства EFA: базовый драйвер, открытый EFAаппаратное. надежная возможность доставки вне очереди, а библиотека libfabric реализует переупорядочение пакетов;
- EFA похож на IB Verbs. Вся передача данных EFA осуществляется посредством пар передачи/приема. Опираясь на механизм Sharedturn, количество требуемых QP можно значительно сократить.
- Управление буфером и контроль потока, выполняемые уровнем обмена сообщениями, тесно связаны с приложением.
5.2 Почему AWS не выбирает TCP или RoCE
AWS считает:
- TCP является основным средством надежной передачи данных, но не подходит для обработки, чувствительной к задержке. Оптимальная двусторонняя задержка TCP составляет около 25 мкс, а время ожидания, вызванное перегрузкой, может достигать 50 мс или даже секунд. Основная причина — потеря пакетов и повторная передача.
- IB — это решение для высокопроизводительных вычислений с высокой пропускной способностью и низкой задержкой.,Но IB не подходит для требований масштабируемости. Одной из причин является приоритетное управление потоком (PFC) RoCEv2.,Невозможно в большой сети. Это может привести к блокировке начала линии, распространению перегрузки и случайным взаимоблокировкам. Даже если PFC доступен,RoCE по-прежнему страдает от ECMP при перегрузке и неоптимальном контроле перегрузки. конфликт.
- SRD оптимизирован для гипермасштабируемых центров обработки данных: балансировка нагрузки по нескольким путям, быстрое восстановление, управляемый отправителем ECMP, специализированные алгоритмы управления перегрузкой, надежная, но внеочередная доставка и многое другое.
- SRD находится в AWS Реализовано в карте Nitro. Держите SRD как можно ближе к физическому уровню, чтобы избежать влияния шума на производительность ОС и гипервизора. Может быстро ретранслировать и быстро замедляться в ответ на построение поворота. SRD предоставляется хосту как устройство EFA, EFA — это Amazon. сетевой интерфейс для экземпляров EC2.
5.3 Одна из особенностей SRD: многоканальная балансировка нагрузки

Для лучшей балансировки многоканальной нагрузки AWS SRD следует следующим принципам:
- Чтобы снизить вероятность потери пакетов, трафик должен быть равномерно распределен по доступным путям.
- Отправителям SRD необходимо распределять пакеты (даже для одного потока приложения) по нескольким путям, особенно по слоновым потокам. Чтобы свести к минимуму возможность возникновения горячих точек и обнаружить неоптимальные пути.
- Для совместного использования устаревшего трафика без включения многопутевого доступа,Поэтому случайный распыляемый трафик неуместен.,SRD избегает использования перегруженных путей.
- из-за масштаба,Случайные неисправности неизбежны. Чтобы сеть могла быстро восстановиться после сбоев канала.,Если исходный путь передачи недоступен,SRD может перенаправить повторно переданные пакеты.,Нет необходимости ждать, пока обновления маршрутизации сойдутся.
5.4 Вторая особенность SRD: доставка вне заказа
При сетевой передаче балансировка трафика по нескольким доступным путям помогает уменьшить задержки в очередях и предотвратить потерю пакетов, однако это неизбежно приводит к прибытию пакетов с нарушением порядка;
В то же время общеизвестно, что восстановление порядка пакетов в сетевых картах обходится очень дорого, ресурсы которых обычно ограничены (пропускная способность памяти, емкость буфера переупорядочения или количество открытых контекстов упорядочения).
Если вы отправляете полученные сообщения последовательно, вы ограничиваете масштабируемость или увеличиваете среднюю задержку в случае потери пакетов. Отсрочка отправки неупорядоченных пакетов в программное обеспечение хоста потребует очень большого буфера и значительно увеличит среднюю задержку. Многие пакеты данных могут быть отброшены из-за задержки, а повторная передача увеличивает ненужное потребление пропускной способности сети.
SRD предназначен для передачи потенциально неправильных пакетов данных непосредственно на хост без их обработки.
Приложения, обрабатывающие пакеты с нарушением порядка, невозможны в протоколах потоков байтов, таких как TCP, но легко реализуются, если они основаны на семантике сообщений. Упорядочение или другие типы отслеживания зависимостей для каждого потока выполняются уровнем обмена сообщениями поверх SRD. Информация об упорядочивании уровня сообщений передается на другой конец вместе с пакетом и невидима для SRD;
5.5 Третья функция SRD: контроль перегрузок
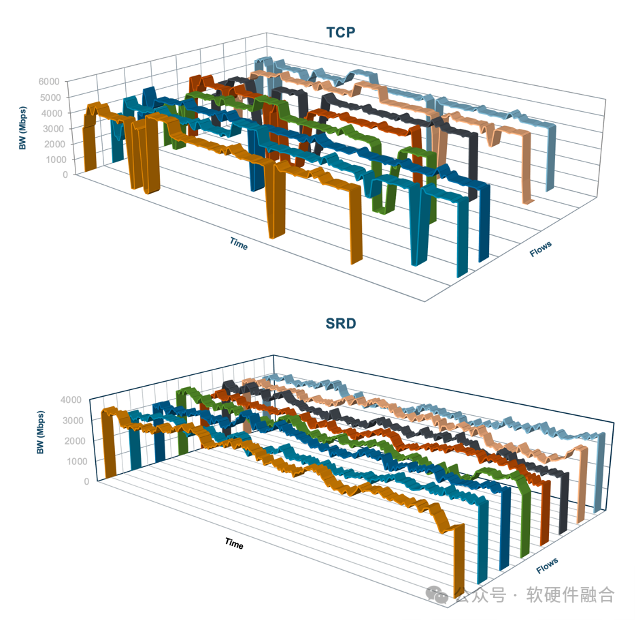
Incast — это шаблон трафика, при котором множество трафиков сходятся к одному и тому же интерфейсу коммутатора, исчерпывая буферное пространство интерфейса и вызывая потерю пакетов.
Multipath Spray снижает нагрузку на промежуточные коммутаторы, но сам по себе не решает проблему перегрузки Incast. Распыление может усугубить проблему incast: даже если отправитель ограничен собственной пропускной способностью канала, трафик от отправителя в разное время может приходить одновременно по разным путям. Для многопутевой передачи контроль перегрузки имеет решающее значение, чтобы свести к минимуму совокупную очередь на всех путях.
Таким образом, цель SRD CC — добиться максимально справедливого распределения полосы пропускания с наименьшим объемом передаваемых данных и предотвратить накопление очередей и потерю пакетов. Отправителю необходимо корректировать свою скорость передачи для каждого соединения на основе оценки скорости, основанной на временной подсказке пакета подтверждения, принимая во внимание недавние изменения скорости передачи и RTT.
6 Другие высокопроизводительные сетевые технологии
6.1 Truefabric от Microsoft Fungible
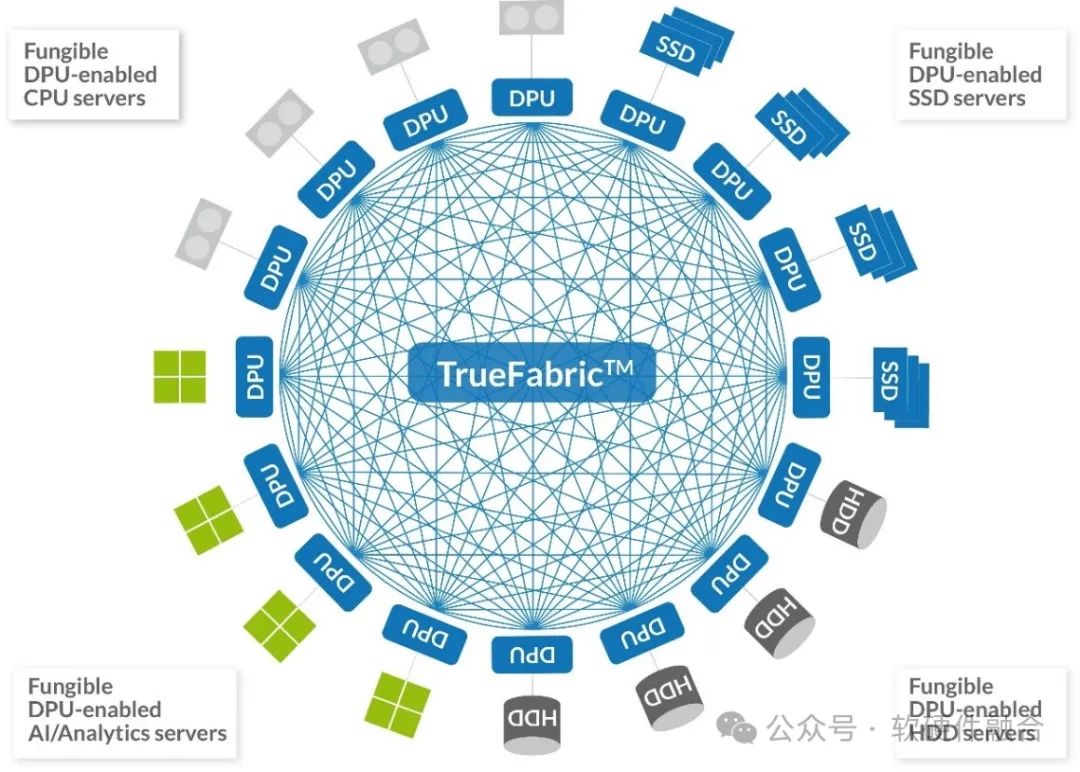
TrueFabric — это сетевая технология открытого стандарта, повышающая производительность, экономичность, надежность и безопасность центров обработки данных. Масштаб одного кластера варьируется от нескольких до тысяч стоек.
- Масштабируемый дата-центр,Все серверные узлы соединены через надежную локальную сеть высокой производительности. в настоящий момент,Большинство центров обработки данных по-прежнему построены на Eth+TCP/IP.
- Локальные сети на три порядка или более быстрее, чем глобальные, а TCP/IP становится узким местом в производительности. Разгрузка TCP не удалась, и было сложно четко разделить TCP между ЦП и механизмом разгрузки.
- сетьинтерфейсиSSDоборудованиеиз Производительность лучше, чем у универсальногоCPUулучшаться быстрее;Система продолжает разрушаться,Увеличение трафика с востока на запад。I/Oтехнологияи业务应用изразвивать,Оказывая огромное давление на сетевой стек.
- Все функции TrueFabric основаны на стандартной реализации протокола New Fabric Control (FCP) UDP/IP Ethernet.
- Поддержка TrueFabric: малый и средний масштаб,Серверные узлы напрямую подключены к коммутаторам Spine;,двухуровневая топология,Коммутаторы Spine и Leaf также могут поддерживать более масштабные сети с тремя и более уровнями коммутаторов.
- На рисунке справа показано абстрактное представление развертывания TrueFabricset.,Существует четыре типа серверов:CPUсервер、Сервер искусственного интеллекта/анализа данных、SSD-сервер и HDD-сервер. Каждый экземпляр сервера содержит взаимозаменяемый DPU.
Возможности TrueFabric/FCP
- Масштабируемость: его можно расширить от небольшого развертывания с использованием интерфейсов 100GE до крупномасштабного развертывания сотен тысяч серверов с использованием интерфейсов 200/400GE.
- Полная пропускная способность поперечного сечения: поддерживает сквозную пропускную способность полного поперечного сечения для размеров пакетов Ethernet стандартного IP. TrueFabric поддерживает эффективный обмен короткими сообщениями с малой задержкой.
- Низкая задержка и низкий уровень джиттера: обеспечивает минимальную задержку между узлами и очень жесткий контроль задержки с длинным хвостом.
- Справедливость: справедливое распределение пропускной способности между конкурирующими узлами с точностью до микросекунды.
- Предотвращение перегрузок: встроенное активное предотвращение перегрузок.,Это означает, что пакеты практически никогда не теряются из-за перегрузки. и,Технология предотвращения перегрузок не зависит от характеристик основного коммутатора сети.
- Отказоустойчивость: благодаря встроенной системе обнаружения и восстановления потери пакетов восстановление после ошибок происходит на пять порядков быстрее, чем традиционные методы восстановления, основанные на маршрутизации.
- Программно-определяемая безопасность и политика: поддержка сквозного шифрования на основе AES. Определенные развертывания можно настроить для разделения на отдельные домены шифрования.
- Открытые стандарты: FCP построен на стандартном IP на основе Ethernet и полностью совместим со стандартным TCP/IP через Ethernet.
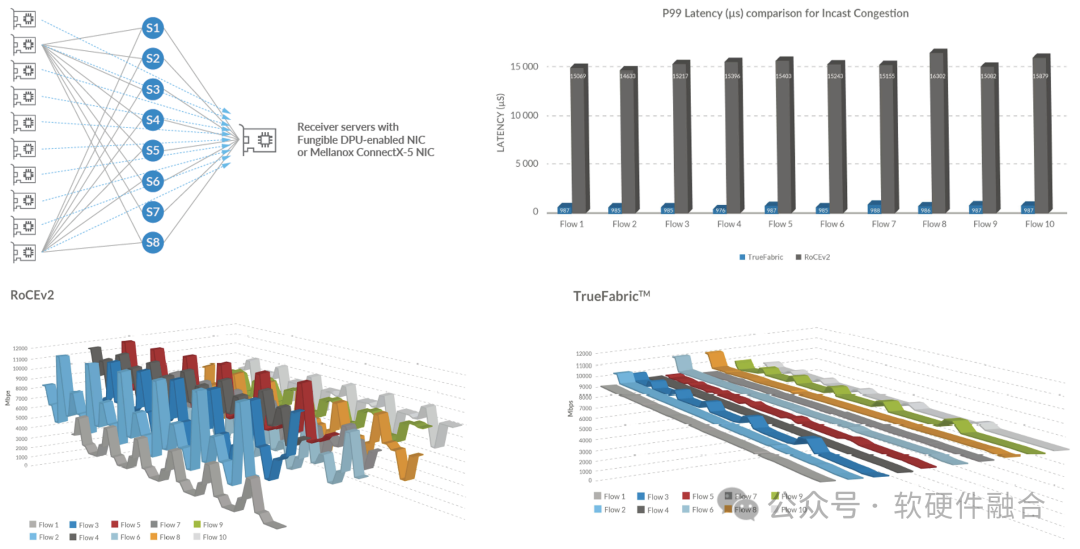
На приведенном выше рисунке показано сравнение производительности TrueFabric и RoCEv2 при Incast 10:1. Как видно на верхнем правом рисунке, Truefabric имеет очень значительное улучшение по сравнению с ROCEv2 с точки зрения задержки P99 с длинным хвостом. Судя по сравнению джиттера производительности между RoCEv2 и Truefabric на двух рисунках ниже, стабильность производительности Truefabric значительно лучше, чем у RoCEv2.
6.2 Alibaba Cloud HPCC и eRDMA
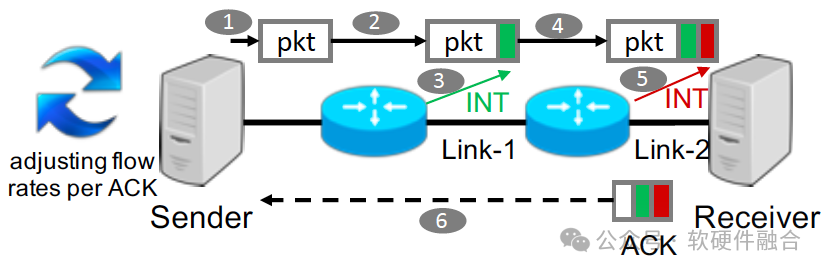
Ключевым методом HPCC (высокоточного контроля перегрузки) Alibaba Cloud является использование точной информации о загрузке канала, предоставляемой INT (внутрисетевой телеметрии), для расчета точных обновлений трафика.
- Крупномасштабная RDMAсеть сталкивается с проблемами балансировки низкой задержки, высокой загрузки полосы пропускания и высокой стабильности. Классический механизм перегрузки RDMA,Например, алгоритмы DCQCN и TIMELY.,Имеет некоторые ограничения:Медленная конвергенция、Неизбежная очередь пакетов、Сложные параметры настройки.
- Отправитель HPCC может быстро увеличить скорость потока для достижения высокого уровня использования или быстро снизить скорость потока, чтобы избежать перегрузки. Отправитель HPCC может быстро регулировать скорость потока так, чтобы входная скорость каждого канала была немного ниже пропускной способности канала; , поддерживая высокую загрузку канала. Поскольку скорость отправки точно рассчитывается на основе прямых измерений на коммутаторе, HPCC требует всего 3 независимых параметра для настройки справедливости и эффективности;
- По сравнению с DCQCN, TIMELY и другими решениями,HPCC быстрее реагирует на доступную полосу пропускания и перегрузку,И держите поворот близким к нулю.
Elastic Remote Direct Memory Access (eRDMA) — это эластичная сеть RDMA, разработанная Alibaba Cloud в облаке. Базовые каналы повторно используют сеть VPC и используют полнофункциональный алгоритм управления перегрузкой (HPCC), который использует традиционный RDMA. Сеть имеет высокую пропускную способность и низкую задержку, она может поддерживать крупномасштабные сети RDMA за считанные секунды. Совместимость с традиционными приложениями HPC и традиционными приложениями TCP/IP.
Возможности eRDMA в основном имеют следующие преимущества продукта:
- высокая производительность。RDMAОбход ядрапротоколкуча,Передача данных непосредственно из программы пользовательского режима в HCA для передачи по сети.,Значительно снижает нагрузку на процессор и задержку. eRDMA обладает преимуществами традиционных сетевых карт RDMA.,При этом к VPCсети применяется традиционная технология RDMA.
- Масштабное развертывание. Традиционный RDMA основан на принципе отсутствия потерь в сети.,Затраты на крупномасштабное развертывание высоки, а крупномасштабное развертывание затруднено. В своей реализации eRDMA использует самостоятельно разработанный алгоритм CC контроля перегрузки.,Допускать изменения качества передачи в VPCсеть (задержку, потерю пакетов и т. д.),Он по-прежнему имеет хорошую производительность в сетевой среде с потерями.
- Эластичное расширение. В отличие от традиционных сетевых карт RDMA, для которых требуется отдельное аппаратное обеспечениесетевая карта,eRDMA может динамически добавлять устройства во время использования ECS.,Поддержка живой миграции,Гибкое развертывание.
- Общая VPCсеть. eRDMA опирается на Elastic Network Interface (ENI).,сеть Полностью многоразовый,без изменения бизнес-сети,Вы можете активировать функцию RDMA в исходной сети.,Познакомьтесь с RDMA.
6.3. Появление ультра-Ethernet
В июле 2023 года был официально создан Консорциум Ultra Ethernet (UEC). Это новая организация, спонсируемая Linux Foundation и его Фондом совместного развития. UEC стремится выйти за рамки существующих возможностей Ethernet, таких как удаленный прямой доступ к памяти (RDMA) и RDMA через конвергентный Ethernet (RoCE), чтобы обеспечить высокопроизводительный, распределенный транспортный уровень без потерь, оптимизированный для высокопроизводительных вычислений и искусственного интеллекта. по конкурирующему протоколу передачи InfiniBand.
Искусственный интеллект и высокопроизводительные вычисления создают новые проблемы для сетей, такие как необходимость большего масштаба, более высокой плотности полосы пропускания, многопутевого доступа, быстрого реагирования на перегрузку и взаимозависимости при выполнении отдельных потоков данных (где задержка хвоста является ключевым моментом, который следует учитывать). ). Спецификация UEC призвана устранить эти пробелы и обеспечить более масштабные сети, необходимые для этих рабочих нагрузок. UEC нацелен на полный стек коммуникаций, который решает технические проблемы на нескольких уровнях протокола и предоставляет функциональные возможности, которые легко настраивать и управлять.
UEC предоставит открытую, совместимую, высокопроизводительную архитектуру полного коммуникационного стека на основе Ethernet для удовлетворения растущих сетевых потребностей крупномасштабного искусственного интеллекта и высокопроизводительных вычислений. От физического уровня до уровня программного обеспечения UEC планирует внести изменения во многие уровни стека Ethernet.
Технической целью ОДК является разработка спецификаций, API и исходного кода. ОДК определяет:
- протокол для связи Ethernet、Электрические и оптические характеристики сигнала、API/структуры данных.
- Канальный и сквозной сетевой транспортный протокол, который может расширять или заменять существующие каналы и транспортный протокол.
- Перегрузка на уровне канала и сквозная перегрузка、Механизмы телеметрии и сигнализации, подходящие для искусственного интеллекта.、Машинное обучение и высокопроизводительные вычислительные среды.
- Архитектура программного обеспечения, хранения, управления и безопасности для поддержки различных рабочих нагрузок и операционных сред.
Протокол передачи УЭК:
- С самого начала разрабатывался как открытая спецификация протокола, работающего через IP и Ethernet.
- Многолучевая передача, распыление пакетов,Получите максимум от AIсеть,Не вызовет перегрузку или блокировку начала линии.,Нет необходимости в централизованных алгоритмах балансировки нагрузки и контроллерах маршрутизации.
- Механизм управления Incast контролирует подключение по конечному каналу к целевому хосту с минимальной потерей пакетов.
- Эффективный алгоритм управления скоростью позволяет быстро увеличить скорость передачи до линейной скорости без потери производительности конкурирующих потоков.
- для передачи пакетов вне очереди API,Возможность последовательного завершения сообщений,Максимизируйте параллелизм сети и приложений,и минимизировать задержку сообщений.
- Масштабируемость в будущем, поддержка 1 000 000 конечных точек.
- Производительность и оптимальное использование сети без необходимости настройки параметров алгоритма перегрузки в зависимости от сети и рабочей нагрузки.
- Предназначено для коммерческого использования. обеспечение реализовано на 800G、1.6T и скорость передачи данных для будущего более быстрого Ethernet.
7 Высокая производительность глобального Интернета
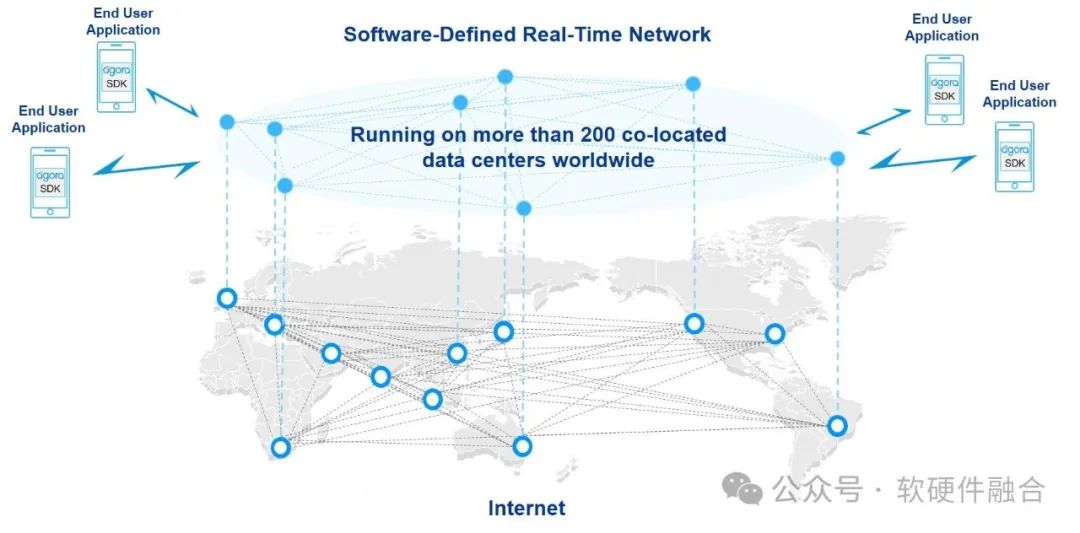
Благодаря широкомасштабному охвату коммуникационной инфраструктуры 5G, широкому использованию мультимедийных приложений, таких как короткие видеоролики и видеоконференции, широкому внедрению автономного вождения и интеллектуальных подключенных автомобилей, а также быстрому развитию метавселенной VR/AR, влияние весь глобальный Интернет. Различные аспекты, такие как пропускная способность, производительность в реальном времени и стабильность, выдвигают более высокие требования.
На рисунке выше показано, что Acoustic Network создала глобальную сеть связи в реальном времени с помощью технологии SD-RTN (программно-определяемая глобальная сеть реального времени), основанной на архитектуре SDN. Она использует дешевые периферийные узлы и уникальную технологию интеллектуального ускорения маршрутизации для глобального управления. сквозная задержка до 400 мс в пределах.
8. Обзор высокопроизводительной сети
8.1 Краткое описание оптимизации высокопроизводительной сети
Основные средства высокопроизводительной оптимизации сети:
- Обновление пропускной способности сети: например, обновление пропускной способности сети.,Обновите всю сеть с 25 Гбит/с до 100 Гбит/с, например, увеличив количество сетевых портов и соединений;
- легкийпротоколкуча:центр обработки данныхсеть Не то же самое, что Интернетслойсорт,короткое физическое расстояние,Чувствителен к задержке стека,Нет необходимости в сложном стеке протоколов TCP/IP для глобального физического соединения;
- сетьпротоколаппаратное обеспечениеускорятьсяиметь дело с;
- высокая производительностьмягкийаппаратное Softwareinteraction: эффективный протокол взаимодействия + PMD + PF/VF/MQ и т. д., например AWS EFA;
- высокая оптимизация производительности: посредством ① многопутевой балансировки нагрузки, ② доставки вне очереди, ③ контроля перегрузки, ④ многопутевой параллельной обработки и других технологий (таких как AWS SRDтехнология),Достичь ① низкой задержки, ② высокой надежность (низкий уровень джиттера)、③Высокий коэффициент использования.
8.2 Взгляд на многоуровневую систему с точки зрения стека высокопроизводительных сетевых протоколов
Взглянем на многоуровневую систему с точки зрения стека высокопроизводительных сетевых протоколов:
- Система состоит из нескольких слоев.
- Каждый уровень можно рассматривать как независимый компонентный модуль. Различные уровни можно выбирать в соответствии с потребностями, а отдельные уровни, чувствительные к бизнесу, можно настраивать, разрабатывать и оптимизировать для объединения персонализированных системных решений, отвечающих потребностям бизнеса.
- Даже если существует хорошая развязка между уровнями, каждый уровень все равно не изолирован; каждый уровень не должен быть черным ящиком, чтобы его нельзя было оптимизировать на уровне системы для достижения максимальной производительности системы. Сотрудничество между различными уровнями; куча.
- Полная оптимизация стека. Систему необходимо постоянно оптимизировать, каждый уровень необходимо постоянно оптимизировать, интерактивный интерфейс между верхним и нижним уровнями также необходимо постоянно оптимизировать, а многоуровневую операционную платформу также необходимо постоянно оптимизировать.
- Каждый уровень, интерактивный интерфейс и вся система требуют постоянных изменений для адаптации к изменениям потребностей бизнеса.
(Конец текста)



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
