Параллельный цикл for, простые изменения заставляют Python летать
Python всегда впечатляюще быстр при обработке больших наборов данных. Как только код начинает работать, остальное время вы тратите на виноватую прокрутку экрана телефона.

MPI(Message Passing Interface)дасуществоватьпараллельный Расчет,существовать Передача информации между различными процессамииз Стандартное решение。mpi4pyэто егоpythonВерсия。
В Интернете есть много обучающих материалов о том, как пройтиmpi4pyвыполнитьсинхронныйработать относительно независимоpythonкод。существоватьсерверначальствобегатькодизособенно полезно, когда。
Прежде чем мы начнем, необходимо понять две основные концепции:
node,Трансляцию обычно называют серверным узлом. мое понимание,узел,Можно рассматривать как персональный компьютер。каждыйnode(за компьютер)Может быть несколькоcore(ядерный)。Например, вы, возможно, слышали,Программа работает на 12 узлах,Каждый узел выполняет 128 задач. то есть,Эта программасинхронно запускается
индивидуальныйcoresначальство。может быть, одининдивидуальныйcoreвозвращаться Может быть несколькоCPU.
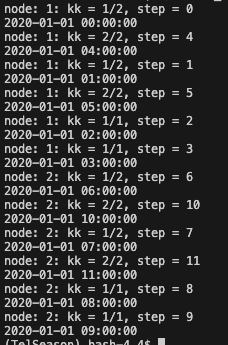
Например, в простом примере, показанном ниже, всего имеется 12 параллельных задач. У нас он работает на двух узлах, поэтому на каждом узле нужно выполнить 6 задач. При этом мы указываем, что каждый узел вызывает только 4 ядра (поскольку все ядра делят память поровну, если все ядра вызываются одновременно, памяти, доступной для каждого ядра, может не хватить для одной задачи). В этом случае 6 задач распределяются по 4 ядрам, а некоторые ядра нужно запускать дважды, например [2,2,1,1]. См. рисунок ниже.
img
позволитьpythonкодпроходитьmpi4pyпараллельный,На самом деле мало что нужно менять. Основная логика,Получить индекс всех узлов и всех ядер системы.,Таким образом, вы получите индекс всех «каналов», которыми может управлять синхронный,Тогда по общему количеству "каналов",Разделите задачи, которые необходимо выполнить, на несколько групп.,Наконец, назначьте разные группы разным «каналам» и запускайте их отдельно.
1. Исправлятьpythonкодподдерживатьmpi4py
при условии, что ты хочешьпараллельный Операцияизpythonкод Вызов“python_mpi4py.py“,этотиндивидуальныйкоддаодининдивидуальныйможет быть независимымсуществоватьодин台电脑начальство(узел)начальствоосуществлятьизкод。Следующие пояснения предназначены только для лучшего понимания.(можно пропустить),На самом деле, после того, как я разобрался в коде, осталось не так уж много мест, которые можно было бы изменить.
- параметр
numобозначениеэтотиндивидуальныйpythonизосновная частькодбегатьсуществоватьгдеиндивидуальныйnodeначальство。действительныйначальство Используется только для вывода информации。 - параметр
t1иt2обозначение,во всех задачах,текущийnodeначальство(node index дляnum)Запустите первыйt1-t2шаг。У нас есть всего12шаг (кодсерединаperiods=12)задача,И мы указываем два узла для выполнения этих 12-шаговых задач.,Итак, в настоящее времяnodeЗапускайте только часть всех задач(Нет.t1-t2шаг)。потому чтодлявызов2индивидуальныйnodes,python_mpi4py.py будет запущен дважды.,каждый раз принимай разныеt1иt2,Эти два шага суммируются для запуска всех t. rankиsizeдаmpi4pyочень важное понятие в。сейчассуществовать Вернемся к спискуиндивидуальныйnode,Вотrankможно рассматривать какдаэтотиндивидуальныйnodeВсе вcoreизindex。например,Указываем вызывать 4 ядра,Чтоrankиз Стоило тогодаодининдивидуальныйlistrank=[0,1,2,3]。size(кодсередина写作npro)даполучатьизcoresизобщий,здесьsize=4。Вот Объяснение навернякада Чрезмерное упрощение。Но что-то вроде этого。- Тогда есть ранее упомянутые группы. Хотя то, что получает этот узел, уже является суб- group(только
steps_global[t1:t2])。этотиндивидуальныйsub- groupвозвращаться需要进одиншаг Распространено по-разномуизcores(кодсерединаизlist_all_pros). - Тогда каждое ядро будет выполняться одновременно, однако у нас более одной задачи ([2,2,1,1]) на каждом ядре, поэтому будет выполняться уникальный цикл.
#%%
import sys
import numpy as np
import mpi4py
import time as pytime
import pandas as pd
# get the number of the node, and the range of the steps [t1:t2] that runs on this node
num = int(sys.argv[1])
t1 = int(sys.argv[2])
t2 = int(sys.argv[3])
# example of all the steps that need to be run on all the nodes
time = pd.date_range('2020-01-01', periods=12, freq='H')
# the steps that need to be run on this node
steps_global = np.arange(time.size)
steps = steps_global[t1:t2] # sub-group for this node
# === mpi4py ===
try:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
npro = comm.Get_size()
except:
print('::: Warning: Proceeding without mpi4py! :::')
rank = 0
npro = 1
list_all_pros = [0]*npro # sub-sub-groups for all the cores
for nn in range(npro):
list_all_pros[nn] = steps[nn::npro]
steps = list_all_pros[rank]
pytime.sleep(0.1*rank) # to make sure the print statements are in order
# use mpi4py here
for kk, step in enumerate(steps):
print(f'node: {num}: kk = {kk+1}/{steps.size}, step = {step}')
print(f'{time[step]}')
В приведенном выше коде мы сжали исходный 12-шаговый цикл максимум до 2-шагового цикла. Конечно, простор для фантазии еще есть.
2. Запустите код Python на одном узле.
要бегатьначальстволапшаиз Включатьmpi4pyизкод,Самый простойиз可以один句bashПросто закажи:
mpirun -np 4 python -u python_mpi4py.py 1 2
Вышеупомянутая команда -np 4обозначение4индивидуальныйядерный同时бегать。Затем1Укажите индекс узла,2 и
Конечно, на сервере обычно сначала нужно выделить ресурсы. ресурс,Затем写одининдивидуальный Скрипт(имядляsubmit_python_mpi4py.sh)提交后台бегатькод:
#!/bin/bash
#SBATCH --job-name=parallel
#SBATCH --time=00:01:00
#SBATCH --partition=compute
#SBATCH --nodes=1
#SBATCH --ntasks=4
#SBATCH --account=*****
mpirun -np 4 python -u python_mpi4py.py $1 $2 $3
3. Запустите код Python на нескольких узлах.
для лучшего понимания,Здесь приведенный выше код bash отправляется несколько раз через код Python.,То есть подать заявку на несколько узлов. Это позволяет более непосредственно контролировать, какие задачи на каком узле выполняются. например,изменить ситуациюиз Модельсуществоватьдругойизnodesначальствобегать。этотиндивидуальныйpython文件我们имядляmaster_submitter.py
#!/usr/bin/env python
#%%
import os
import numpy as np
#%%
nsteps = 12
npar = 6
njobs = int(nsteps/npar) # 2 nodes
#%%
for kk in range(njobs): #0,1 node-index
k1 = kk*npar #0,6 the starting task-index for node1 and node2
k2 = (kk+1)*npar #6,12 the ending task-index for node1 and node2
print("-----node line -----")
os.system(f"sbatch ./submit_python_mpi4py.sh {kk+1} {k1} {k2}") #
# %%
В приведенном выше примере просто показан пример, в котором mpi4py можно использовать для выполнения параллельных операций на нескольких узлах и нескольких ядрах. В приведенном выше примере нет зависимостей между задачами. Но после завершения цикла for обычно происходит операция concat или что-то в этом роде, и необходимо собрать результаты каждой операции ядра. mpi4py также поддерживает передачу данных между различными задачами. Более подробную информацию можно найти в Интернете.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
