Отчет о сценарии угроз ИИ на 2024 год: выявление крупнейших сегодняшних проблем безопасности ИИ
Искусственный интеллект революционизирует все возможности, основанные на данных, потенциально открывая новую эру процветания и поднимая качество человеческой жизни на невообразимые высоты. Но, как и любая новая прорывная технология, большой потенциал часто сопряжен с огромными рисками.
ИИ, по большому счету, является самой хрупкой технологией, когда-либо применявшейся в производственных системах. Он уязвим на уровне кода, во время обучения и разработки, после развертывания, в сети, при генерировании выходных данных и т. д.
В последнем отчете HiddenLayer об угрозах искусственного интеллекта на 2024 год исследователи пролили свет на эти уязвимости и их влияние на организации, а также предоставили рекомендации лидерам в области ИТ-безопасности и обработки данных, занимающимся решением этих проблем. Наконец, в отчете также раскрываются передовые достижения в различных формах контроля безопасности с помощью ИИ.
канал данных
- в среднем,Предприятия развертывают до 1689 моделей искусственного интеллекта в производственной системе;
- 98% ИТ-руководителей считают, что хотя бы некоторый ИИ имеет решающее значение для успеха их бизнеса.
- 83% респондентов заявили, что ИИ широко используется во всех командах их организации.
- 61% ИТ-руководителей признают, что «теневой ИИ» (решения, которые не одобрены ИТ-специалистами и не находятся под контролем ИТ-отдела) является серьезной проблемой в их организации.
- 89% респондентов выразили обеспокоенность по поводу уязвимостей, связанных со сторонней интеграцией ИИ, до 75% респондентов даже считали, что сторонняя интеграция представляет большие риски, чем существующие угрозы;
- 77% компаний сообщили, что их ИИ подвергся взлому в прошлом году.
- 92% респондентов все еще разрабатывают комплексные планы по устранению этой возникающей угрозы.
- 2024 год,94% респондентов выделяют бюджет на AI Security,Но только 61% респондентов полностью уверены в распределении бюджета.
- 30% ИТ-руководителей развернули ручную защиту от вредоносного искусственного интеллекта, но только 14% планируют и тестируют такие атаки.
- только30%компаний, нацеленныхкража моделиугнать(model кражи), а 20% компаний запланировали и протестировали эту угрозу.
- 83% ИТ-руководителей работают с внешними сетевыми компаниями для улучшения ИИ.
- 58% респондентов выразили сомнения относительно того, сможет ли реализованный ими протокол Безопасности справиться с меняющимися угрозами.
- 96% ИТ-руководителей говорят, что их проекты искусственного интеллекта будут иметь решающее значение для получения дохода в ближайшие 18 месяцев.
- 98% ИТ-руководителей активно ищут технологические решения для расширения возможностей искусственного интеллекта и машинного обучения.
- 92% компаний создают собственные модели для улучшения бизнес-операций.
Хроника главных событий состязательного ИИ
- 2002 г. — появился фильтр обнаружения спама на основе машинного обучения с использованием алгоритма Наивного Байеса;
- 2004 г. — Первое использование методов обхода в линейных спам-фильтрах путем вставки поля «хорошо»;
- 2006 г. – опубликован первый документ, в котором изложена классификация атак ОД;
- 2012 г. — первая атака на нелинейные алгоритмы, основанная на градиенте;
- 2014 г. — Первая демонстрация атаки на глубокую нейронную сеть;
- 2015 г. — основана компания OpenAI;
- 2016 г. — инцидент с отравлением чат-бота Microsoft Тая;
- 2017 г. — Первая демонстрация атаки «черный ящик» на машинное обучение;
- 2018 г. - Внедрение концепции «Boundary Attack» (алгоритм состязательной атаки на основе принятия решений);
- 2018 г. - Атаки с извлечением полной модели: KnockOffNets, CopycatCNN;
- 2019 – Представляем однопиксельную атаку Pixel атака, которая может атаковать Модель, просто получив входное изображение) и «атака» (HopSkipJump, метод противостояния «черного ящика», который можно рассматривать как Boundary Attack++);
- 2019 г. – Сингапур формулирует модель системы управления ИИ;
- 2021 г. – Появится первая технология внедрения нейронной полезной нагрузки «черный ящик»;
- 2021 г. — выпущен MITRE ATLAS;
- 2022 г. – начинается разработка законопроекта ЕС об искусственном интеллекте;
- 2022 г. — впервые раскрыта быстрая инъекция против LLM;
- 2022 г. – Канада принимает Закон об искусственном интеллекте и данных (AIDA);
- 2022 г. – Соединенные Штаты разрабатывают проект Билля о правах ИИ;
- 2022 г. — OpenAI запускает ChatGPT;
- 2022 г. — обнаружена вредоносная зависимость PyTorch от PyPI;
- 2023Год——NISTпосадочная дистанция Система управления рисками ИИ(AI RMF);
- 2023 г. - выпущена первая копия модели с закрытым исходным кодом с открытым исходным кодом (Alpaca, OpenLLaMA);
- 2023 г. — Google запускает Безопасность AIрамка (SAIF);
- 2023 - PoisonGPT - демонстрация отравления LLM;
- 2023 г. – Белый дом США публикует информацию по безопасности.、надежный、Распоряжение о надежной разработке и использовании ИИ;
Риски, связанные с приложениями ИИ
Как и любая другая технология, меняющая жизнь, ИИ — это палка о двух концах. Хотя это начало оказывать огромное положительное влияние на нашу жизнь и рабочие процессы, оно также несет в себе огромный потенциальный вред.
Создавайте вредоносный контент
Все, от легкодоступных рынков даркнета до легкодоступных наборов инструментов для взлома и программ-вымогателей как услуги (RaaS), использующих практически неотслеживаемые криптовалюты, помогает киберпреступникам процветать. Что еще хуже, генеративный ИИ может быстро и легко проникнуть в мир сложных сценариев атак, одновременно предоставляя тщательно продуманный фишинг и вредоносное ПО любому, кто об этом попросит. Чат-боты с искусственным интеллектом также могут получить доступ к незаконной информации, которая может привести к физическим угрозам.
Хотя популярные решения генеративного искусственного интеллекта работают над внедрением мощных фильтров и ограничений контента, большинство из них оказалось относительно легко обойти. Более того, модели искусственного интеллекта с открытым исходным кодом можно настраивать без каких-либо ограничений. Эти модели могут принадлежать злоумышленникам или быть доступны широкой публике в даркнете.
Дипфейки
Еще одной очевидной проблемой является создание очень реалистичных фейковых изображений, аудио и видео, используемых для кражи денег, извлечения конфиденциальной информации, нанесения ущерба личной репутации и распространения дезинформации.
Мошенники уже много лет используют различные приемы для обмана людей. Появление дипфейков вывело эту проблему на совершенно новый уровень, из-за чего даже опытным экспертам по кибербезопасности стало сложно отличать настоящие от фейков. Хуже всего то, что влияние Deepfake связано не только с деньгами и репутацией, но также может сорвать политические кампании, манипулировать демократическими выборами, манипулировать обществом и спровоцировать беспорядки. Если вовремя не принять адекватные меры, демократии и социальному порядку будет нанесен серьезный ущерб.
Конфиденциальность и нарушение данных
Рекомендации по защите конфиденциальности всегда отставали от внедрения новых технологий. Часто последствия нарушения конфиденциальности становятся очевидными только после того, как первоначальное волнение утихнет. Мы уже видим это в генеративном искусственном интеллекте.
Например, любое соглашение об условиях предоставления услуг на основе искусственного интеллекта должно описывать, как поставщик услуг использует наши запросы. Однако эти статьи часто представляют собой длинные тексты, написанные намеренно сложным языком. Если пользователь не хочет тратить часы на расшифровку деталей, лучше предположить, что каждый запрос к модели каким-либо образом регистрируется, сохраняется и обрабатывается. Как минимум, пользователи должны знать, что их входные данные будут включены в набор обучающих данных и, следовательно, могут случайно попасть в выходные данные других запросов.
Нарушение авторских прав
Модели, лежащие в основе генеративных решений искусственного интеллекта, часто обучаются на больших объемах общедоступных данных, некоторые из которых защищены законом об авторском праве. Проблема в том, что генеративный ИИ не может отличить вдохновение от плагиата. Результаты, которые он дает, часто слишком близки к оригинальному контенту в обучающем наборе, но при этом не указывается первоначальный автор, что может привести к серьезному нарушению авторских прав.
Проблемы с точностью и предвзятостью
Качество модели ИИ зависит от набора обучающих данных. Большие генеративные модели ИИ обучаются на терабайтах данных, которые в большинстве случаев без разбора извлекаются из Интернета, что делает невозможным тщательное изучение обучающих наборов. Это может привести к проблемам с точностью, справедливостью и общей целостностью модели, а также к потенциальному нарушению конфиденциальности данных, если модель случайно обучается на конфиденциальных данных. Кроме того, рост онлайн-обучения, при котором вводимые пользователем данные постоянно учитываются в процессе обучения, делает решения ИИ уязвимыми к предвзятости, дезинформации и преднамеренному отравлению.
Даже если набор данных содержит объективную и точную информацию, алгоритмы ИИ не всегда верны и иногда могут прийти к странным ошибочным выводам. Они называются «иллюзиями» и являются неотъемлемыми свойствами современной технологии искусственного интеллекта. По своей конструкции ИИ не может отличить реальность от вымысла, поэтому, если набор обучающих данных содержит смесь этих двух, ИИ иногда будет реагировать вымыслом.
Риски, с которыми сталкиваются системы искусственного интеллекта
Существует много дискуссий о безопасном и этичном использовании инструментов ИИ, однако безопасность самих систем ИИ по-прежнему часто игнорируется. Важно помнить, что, как и любая другая повсеместно распространенная технология, решения на основе искусственного интеллекта могут быть использованы злоумышленниками не по назначению, что приведет к сбоям в работе, финансовым потерям, репутационному ущербу и даже рискам для здоровья и жизни людей.
1. Состязательные атаки машинного обучения
Отравление данных
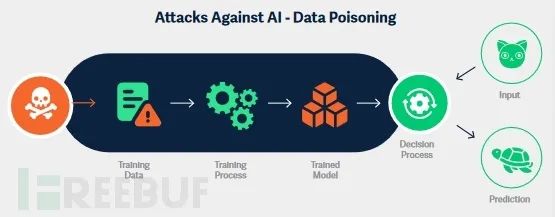
Отравление Цель атаки данных — изменить поведение Модели так, чтобы прогнозы были предвзятыми, неточными или иным образом манипулировались ими в целях злоумышленника. Злоумышленник может выполнить Отравление двумя способами. данные: изменить записи в существующем наборе данных (например, изменить характеристики или метки) или добавить в набор данных новые, специально обработанные части данных.
Даже для неопытных противников,Атаку «Отравление данных» также относительно легко выполнить.,Потому что создание «испорченных» данных часто можно сделать интуитивно, без специальных знаний. Подобные атаки происходят каждый день,От манипулирования завершением текста до влияния на отзывы о продуктах,кампаниям политической дезинформации.
Самое раннее широко разрекламированное «Отравление». Один из случаев с данными касается раннего чат-бота Microsoft Tay. Тай в 2016 году Опубликовано годом в Твиттере в марте,и продолжайте обучаться вводу данных пользователем,Но его в спешке закрыли всего через 16 часов после того, как он появился в сети. за такой короткий период времени,Пользователям удается делать ботов грубыми и расистскими,и производил предвзятые и вредные результаты. Инцидент нанес Microsoft репутационный ущерб.,Даже угрожали судебным иском.
Более сложное Отравление Попытки использования данных могут иметь разрушительные последствия. Что еще хуже, предварительно обученные Модели не застрахованы от отравления, поскольку ими можно манипулировать во время точной настройки. В атаке под названием «PoisonGPT» злоумышленники использовали метод под названием «Rank-One». Технология «редактирования модели» изменяет существующие модели на основе GPT, заставляя их распространять контролируемую злоумышленником ложную информацию.
модель побега
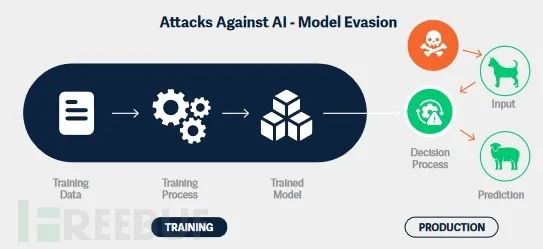
Эскейп-атаки, также известные как обход модели, направлены на преднамеренное манипулирование входными данными модели для получения неправильной классификации. Входные данные, созданные злонамеренно для модели, называются состязательными примерами. Их цель обычно состоит в том, чтобы избежать правильной классификации или вызвать определенные последствия, определяемые злоумышленником. Они также могут помочь злоумышленникам понять границы принятия решений модели.
Разница между необработанными входными данными и манипулируемыми входными данными часто незаметна для людей. Например, в системе визуального распознавания злоумышленник может изменить изображение, добавив невидимый для человеческого глаза слой шума, или даже повернуть изображение, или изменить отдельные пиксели. Это приведет к тому, что модель ИИ будет давать неверные прогнозы. Злоумышленник обычно отправляет в модель большое количество несколько разных входных данных и записывает прогнозы, пока не найдет образец, который вызывает желаемую неправильную классификацию.
В 2019 году исследователи Skylight Cyber создали модель классификации вредоносных программ на основе искусственного интеллекта, которая успешно обходила несколько наборов инструментов для обхода антивирусов, таких как MalwareGym и MalwareRL, в которых атаки уклонения сочетались с обучением с подкреплением, автоматически генерировали мутации вредоносных программ, благодаря которым они проявлялись. безвреден для моделей классификации вредоносных программ.
Эти атаки также могут быть использованы для угона беспилотных автомобилей. Исследователи показали, что размещение специально созданной наклейки на знаке «Стоп» может обмануть транспортное средство, заставив его неверно классифицировать знак и продолжить движение. Аналогично, злоумышленник, желающий обойти систему распознавания лиц, может разработать специальную пару солнцезащитных очков, которые сделают владельца невидимым для системы. Возможности таких атак безграничны, некоторые из них могут иметь фатальные последствия.
кража модели
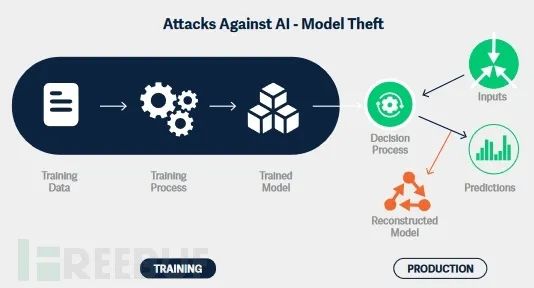
Информация о модели и наборах данных, на которых она основана, не является общедоступной, но пользователи обычно могут запрашивать модель (например, через графический интерфейс или API). Этого достаточно, чтобы злоумышленник совершил атаку и попытался скопировать модель или извлечь конфиденциальные данные.
Конкуренты могут попытаться украсть модель, чтобы получить конкурентное преимущество без необходимости искать правильный набор данных, маркировать векторы признаков и нести затраты на обучение модели. Украденными моделями можно даже торговать на подпольных форумах, как и конфиденциальным исходным кодом и другой интеллектуальной собственностью.
В начале 2023 года исследователи Стэнфордского университета доработали модель AI LLaMA компании Meta и выпустили ее под названием Alpaca, а OpenLM выпустила лицензированную копию LLaMA с открытым исходным кодом под названием OpenLLaMA. Это еще раз доказывает, что при достаточном доступе к API можно клонировать большую и сложную модель для создания очень эффективной копии, избавляя вас от необходимости обучать модель.
2. Генеративные атаки ИИ
Развитие генеративного ИИ породило новые этические проблемы и проблемы безопасности, и злоумышленники могут воспользоваться преимуществами генеративных систем ИИ различными способами.
быстрая инъекция
Быстрая инъекция — это метод, который можно использовать, чтобы заставить ботов ИИ выполнять неожиданные или ограниченные действия. Этот метод реализуется путем создания специального приглашения для обхода фильтров контента Модели. После этого специального приглашения чат-бот выполнит действия, ограниченные в противном случае.
косвенныйбыстрая инъекция
Другой недавно продемонстрированный метод под названием“косвенныйбыстрая инъекция”(IndirectPrompt С помощью инъекции исследователи превратили чат-бота Bing в самозванца для кражи конфиденциальных данных. По замыслу Bing Chat может запрашивать доступ ко всем открытым вкладкам и содержимому веб-сайта на этих вкладках. Злоумышленник создал вредоносный веб-сайт, содержащий специально разработанную подсказку, которая изменяла поведение Bing Chat всякий раз, когда веб-сайт открывался в браузере жертвы и вкладка была доступна Bing. Злоумышленники могут использовать эту атаку для кражи конкретной конфиденциальной информации, манипулирования пользователями для загрузки вредоносного ПО или просто введения в заблуждение и распространения дезинформации.
внедрение кода
В большинстве случаев модели GenAI могут генерировать только тот тип вывода, для которого они предназначены (т. е. текст, изображения или звуки). Это означает, что если кто-то предложит чат-боту на основе LLM выполнить команду оболочки или просканировать сетевой диапазон, чат-бот не выполнит ни одного из этих действий. Однако он может выдать правдоподобно ложный вывод, указывающий на то, что операции действительно были выполнены.
HiddenLayer обнаружил, что некоторые модели искусственного интеллекта действительно могут выполнять код, предоставленный пользователем. Например, существует приложение Streamlit MathGPT, которое отвечает на математические вопросы, сгенерированные пользователем, преобразует полученные запросы в код Python, а затем выполняется моделью для возврата «вычисленных» результатов.
3. Атаки на цепочку поставок
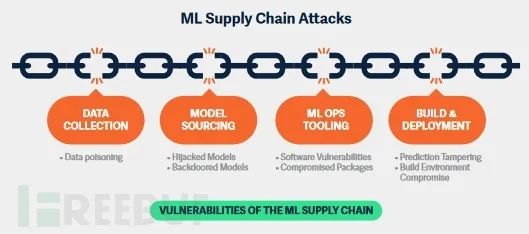
Атаки в цепочке поставок происходят, когда доверенный сторонний поставщик становится жертвой атаки. Сегодняшняя цепочка поставок машинного обучения представляет собой обширную экосистему различных инструментов, библиотек и услуг. От фреймворков машинного обучения до инструментов MLOps и репозиториев моделей — каждый из них играет важную роль в демократизации ИИ и ускорении прогресса в этой области. Однако, учитывая такое большое количество движущихся частей и новых технологий, они непреднамеренно создают новые риски в цепочке поставок, делая нас уязвимыми для повторения ошибок прошлого.
Исследователи полагают, что в цепочке поставок машинного обучения существуют следующие ключевые риски:
- злонамеренный Модель;
- Модель бэкдора;
- Характер безопасности общедоступных репозиториев моделей;
- злонамеренные сторонние подрядчики;
- Уязвимости в инструментах ML;
- Отравление данных。
Достижения в области безопасности ИИ
Наступательные инструменты безопасности ИИ
Инструменты наступательной безопасности существуют уже давно и позволяют красным командам и тестерам на проникновение оценивать ИТ-системы на предмет возможных слабых мест. В настоящее время концепция наступательной безопасности также вошла в область ИИ, и исследователи безопасности ИИ разработали различные инструменты для проверки своих методов атак.
Состязательная платформа машинного обучения
- 2016 год,Появилась CleverHans, первая библиотека надежности для тестирования систем на состязательных примерах.
- В 2018 году IBM выпустила Adversarial. Robustness Рамка Toolbox (ART) для реализации различных атак на ИИ и включает понятный Jupyter. Пример блокнота.
- 2019 год,Выпущена удобная облачная рамкаMLSploit,Он позволяет создавать атаки на различные классификаторы вредоносного ПО, детекторы вторжений и детекторы объектов.
- тот же год,QData представляет мощную НЛП-атаку FrameTextAttack,Может помочь в проведении состязательных текстовых атак, улучшении текста и обучении моделей.
- В 2020 году был выпущен Armory, инструмент тестирования контейнеров для оценки состязательной защиты.
- 2021 год,Facebook выпускает август,Это расширенная библиотека данных.,Может использоваться для создания состязательных примеров.
- тот же год,Microsoft запускает Counterfit,Это простой в использовании уровень автоматизации командной строки.,Оценка безопасности для MLМодель.
Инструменты обхода защиты от вредоносных программ
Помимо мощных систем оценки, существуют также более специализированные инструменты, нацеленные на конкретные результаты. Например, MalwareGym может помочь обойти решения по борьбе с вредоносным ПО на основе искусственного интеллекта. Выпущенный в 2017 году антивирусной компанией Endgame, он реализует обучение с подкреплением в модификациях приложений Windows. Взяв функциональность безобидного исполняемого файла и добавив ее во вредоносный файл, MalwareGym может создать вредоносное ПО, которое обходит сканеры вредоносных программ.
кража моделиинструмент
KnockOffNets — инструмент для создания копий моделей ИИ (другими словами, для кражи моделей), автор Макс Опубликовано в 2021 году исследователями Института информационных исследований Планка. Хотя он был создан, чтобы показать кража модели/Модель удобство извлечения, но также может помочь злоумышленникам построить собственную кража моделиинструмент。
Защитная система искусственного интеллекта
За последние два года несколько крупных игроков в области кибербезопасности создали комплексные структуры, включающие в себя различные методы обеспечения безопасности, стратегии и рекомендации по искусственному интеллекту. Эти рамки являются ценным первым шагом на долгом пути.
MITRE ATLAS
MITRE ATLAS, впервые выпущенная на GitHub в 2020 году, представляет собой базу знаний о стратегиях, методах и тематических исследованиях состязательного машинного обучения, призванную помочь специалистам по кибербезопасности, специалистам по обработке данных и их компаниям понять новейшие атаки и атаки против состязательного машинного обучения.
Матрица ATLAS разделена на два основных раздела: тактика и техника. Среди них тактика описывает то, чего хочет достичь противник; технология описывает, как атакующий будет реализовывать свою тактику.
Система управления рисками НИСТ в области искусственного интеллекта
В январе 2023 года Национальный институт стандартов и технологий (NIST) выпустил систему управления рисками AI (AI RMF). Это концептуальная основа, которая извлекает уроки из традиционного программного обеспечения и информационных систем и применяет их к уникальным задачам, возникающим в результате систем искусственного интеллекта.
Структура разделена на две части: структуру рисков, связанных с системами ИИ, и саму базовую структуру. Ядро описывает четыре функции: управление, картографирование, измерение и управление. Каждый из них разбит на дополнительные элементы управления, чтобы дать организациям более глубокое понимание того, как защитить свою инфраструктуру искусственного интеллекта.
Google Safe AI Framework
Secure AI Framework (SAIF), запущенный Google в июне 2023 года, представляет собой концептуальную структуру, которая, как и NIST AI RMF, предоставляет рекомендации по защите систем искусственного интеллекта. Он опирается на лучшие практики и опыт традиционной разработки программного обеспечения и адаптирует его к потребностям систем искусственного интеллекта.
OWASP top10
Open Worldwide Application Security Project (OWASP) — это некоммерческая организация и интернет-сообщество, которое предоставляет бесплатные рекомендации и ресурсы, такие как статьи, документация и инструменты, в области безопасности приложений. Список топ-10 рисков безопасности OWASP содержит наиболее важные угрозы безопасности, с которыми сталкиваются различные веб-технологии, такие как контроль доступа и сбои шифрования.
Платформа безопасности AI Databricks (DAISF)
В рамках DAISF принята комплексная стратегия по снижению киберрисков в системах искусственного интеллекта. Он дает представление о том, как машинное обучение влияет на безопасность системы и как принципы проектирования безопасности могут быть применены к системам искусственного интеллекта. Он также предоставляет подробные инструкции для понимания безопасности и соответствия конкретным системам ML.
IBM Generative AI Security Framework
В январе 2024 года IBM выпустила платформу Securing Generative AI, ориентированную на использование LLM и других решений GenAI на предприятиях и организациях. Он обеспечивает защитный подход, помогая оценить наиболее вероятные уязвимости, которые могут возникнуть на каждом этапе конвейера, и рекомендуя соответствующие защитные и оборонительные меры.
Красная команда и оценка рисков
Первые идеи создания красных команд ИИ появились в конце 2010-х годов. В то время системы ИИ уже были известны своей уязвимостью к предвзятости, состязательным примерам и широко распространенным злоупотреблениям. Сегодня некоторые крупные игроки (например, Google, Nvidia) вложили средства в создание собственных внутренних команд, занимающихся углубленным тестированием решений искусственного интеллекта, которые они разрабатывают и внедряют.
- 2021 год Декабрь,Microsoft опубликовала свои лучшие практики AI Security для управления рисками;
- июнь 2023 г.,Nvidia представляет миру свою Red Team,и структуру, которую они используют в качестве основы для своей оценки;
- июль 2023 г.,После того, как Google выпустил SAIFрамку,Официально объявлена собственная красная команда AI.
Политика и правила
Мы уже обсуждали, что ИИ — это палка о двух концах: его легко можно использовать против людей, бизнеса и общества, что приведет к далеко идущим последствиям, которые могут быть разрушительными. По этой причине правительства во всем мире приняли строгие правила относительно безопасного, законного и этического использования ИИ.
- В 2019 году Организация экономического сотрудничества и развития (ОЭСР) приняла Рекомендации по ИИ. В нем описаны пять принципов и пять рекомендаций для стран ОЭСР и присоединившихся к ним экономик-партнеров по продвижению ответственной и заслуживающей доверия политики в области искусственного интеллекта.
- В 2022 году ЕС предложил более комплексный законопроект об искусственном интеллекте, который делит решения искусственного интеллекта на три категории: приложения с низким уровнем риска, которые должны соответствовать законам о прозрачности, но в остальном не регулируются, приложения с высоким уровнем риска, на которые распространяются строгие ограничения, и приложения, считающиеся опасными; и вообще запретили.
- 2019 год,Сингапур формулирует первую версию модели управления ИИ,Состоит из 11 этических принципов искусственного интеллекта.,включить прозрачность、Интерпретируемость、Безопасностьсекс、Безопасностьсекс、данные Управление и подотчетность.
- Октябрь 2022 г.,США представили «План Билля о правах ИИ»,Это набор рекомендаций и указаний по разработке и использованию ИИ-системы.
- октябрь 2023 г.,Белый дом издал указ о безопасной, надежной и заслуживающей доверия разработке и использовании ИИ. В нем обозначены риски, которые несет AIсистема.,Например, угрозы для людей, обнаружение контента, созданного ИИ.,А также обеспечение системы безопасности экологии ИИ.
Прогноз развития ИИ
1. Специалисты по данным будут работать со специалистами по безопасности для защиты моделей ИИ.
Индустрия кибербезопасности уже несколько десятилетий находится в гонке технологических вооружений со злоумышленниками, поскольку каждое новое достижение создает уникальные проблемы безопасности, которые требуют индивидуальных решений безопасности. Однако безопасность искусственного интеллекта и машинного обучения игнорируется в области науки о данных; быстрое развитие искусственного интеллекта и машинного обучения часто не обеспечивает базовых мер безопасности. Это привело к появлению множества уязвимостей в библиотеках и инструментах, которые стали основой разработки программного обеспечения для искусственного интеллекта. Мы ожидаем, что эта тенденция немного изменится в следующем году, поскольку исследователи быстро обнаруживают уязвимости и помогают поддерживать проекты ML с открытым исходным кодом для их защиты. Сотрудничество специалистов по данным и экспертов по кибербезопасности повысит безопасность всей экосистемы искусственного интеллекта.
2. Цепочки поставок, использующие артефакты машинного обучения, станут более распространенными.
Из-за небезопасности, присущей цепочкам инструментов машинного обучения, у киберпреступников есть много легкодоступных преимуществ. Злоумышленники все чаще обращаются к платформам и инструментам MLOps. Со временем уязвимости в цепочках поставок будут становиться все более распространенными, и не только для традиционных целей первоначального компрометации и горизонтального перемещения. Чувствительность моделей машинного обучения и данных, с которыми они соприкасаются, делает их очень уязвимыми для киберпреступников. Злоумышленники будут все чаще использовать уязвимости в платформах MLOps для отравления обучающих наборов и кражи конфиденциальных данных во время обучения или вывода, чтобы получить конкурентное преимущество или злоупотребить системами искусственного интеллекта.
3. Состязательные атаки ИИ значительно увеличатся.
Обратная атака для получения подробностей обучающих данных или модели.,Атаки на основе логического вывода для создания обхода/неправильной классификации,И со временем атаки с применением кража-модели также станут более распространенными. Важным фактором, способствующим этим атакам, является расширение исследований состязательного машинного обучения в научных кругах и промышленности. Некогда чрезвычайно сложная задача,Сейчас (и будет) проще,Даже сценаристы могут сделать это легко.
4. Злоумышленники будут использовать LLM для автоматизации хакерских атак.
Киберпреступники уже используют LLM для усиления существующих атак: от написания более реалистичных фишинговых писем до динамического создания уникальных вредоносных программ и совершенствования усилий по социальной инженерии. Нетрудно представить, что в следующем году злоумышленники будут использовать LLM для автоматизации хакерских атак, проведения разведки и дополнения киберпреступности как услуги.
Еще одной интересной разработкой в области LLM является RAG (Поисковая дополненная генерация), которая дополняет модель внешними источниками информации или достоверными данными. LLM с поддержкой RAG легко подвергаются злоупотреблениям со стороны вандалов, которые пытаются получить конфиденциальную информацию, используя тщательно продуманные подсказки.
5. Поскольку все больше организаций используют передовые инструменты для борьбы с угрозами, поверхность атаки ИИ будет расширяться.
Разработка, использование и внедрение ИИ в вашей организации еще никогда не была такой простой. Такая быстрая интеграция с устоявшимися процессами создает новую и расширяющуюся поверхность атаки, которую традиционные меры безопасности не могут защитить.
В наступающем году предприятия столкнутся со многими проблемами роста, такими как раскрытие или небезопасная настройка ИИ, что приведет к утечкам данных, компрометации или еще хуже.
С другой стороны, мы также надеемся, что принципы безопасности ИИ станут более широко использоваться в организациях, а передовые методы мониторинга поведения моделей и оценки безопасности моделей будут популяризироваться. В результате больше организаций смогут выявлять состязательные атаки и принимать меры против них.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
