Основные показатели превосходят GPT-4 Turbo! «Распаковка» мультимодальной большой модели SenseTime
Автор | Ли Си
Редактор | Ю Куай
Крупные модели уже не просто инструмент для развлечения, они становятся производственным инструментом для решения повседневных задач.
Именно такое ощущение у AI Nuggets после прочтения последней версии Ririxin 5.0, выпущенной SenseTime.
В последней версии Ririxin 5.0, выпущенной SenseTime, его возможности в области языка, знаний, рассуждения, математики, кодирования и других областях были значительно улучшены, достигая или превосходя GPT-4 Turbo в основных объективных оценках.
Будучи студентом гуманитарных наук, RiRiXin 5.0 внес ключевые оптимизации в сценарии открытых вопросов и ответов, достигнув лидирующего в отрасли уровня в чате, многораундовом диалоге, извлечении информации, написании и других сценариях.
Будучи студентом естественных наук, RiRiXin 5.0 обладает знаниями, математикой, рассуждением и способностями к программированию на одном уровне с GPT-4 Turbo.
Мы интуитивно чувствуем, что мультимодальная большая модель быстро меняется.
Придут ли хорошие новости для промышленности и рабочих-мигрантов?
1. Ежедневные инновации · Обсудить мультимодальность 5.0, распаковка
SenseTime Multimodal 5.0 может не только понимать текст, но и обрабатывать содержимое документов, диаграмм, снимков экрана и фотографий.
Я могу говорить с вами о поэзии, поэзии, математике, физике и химии, а также о жизненных приложениях. У меня есть талант студента гуманитарного факультета и дотошность специалиста по естественным наукам.
Предложения по экипировке, анализ продуктов питания, создание копирайтинга, рекомендации по приготовлению пищи и т. д. — он стал «разумным» ежедневным помощником во многих повседневных сценариях.
Умею копирайтинг (пишу стихи, пишу эссе, пишу положительные отзывы)
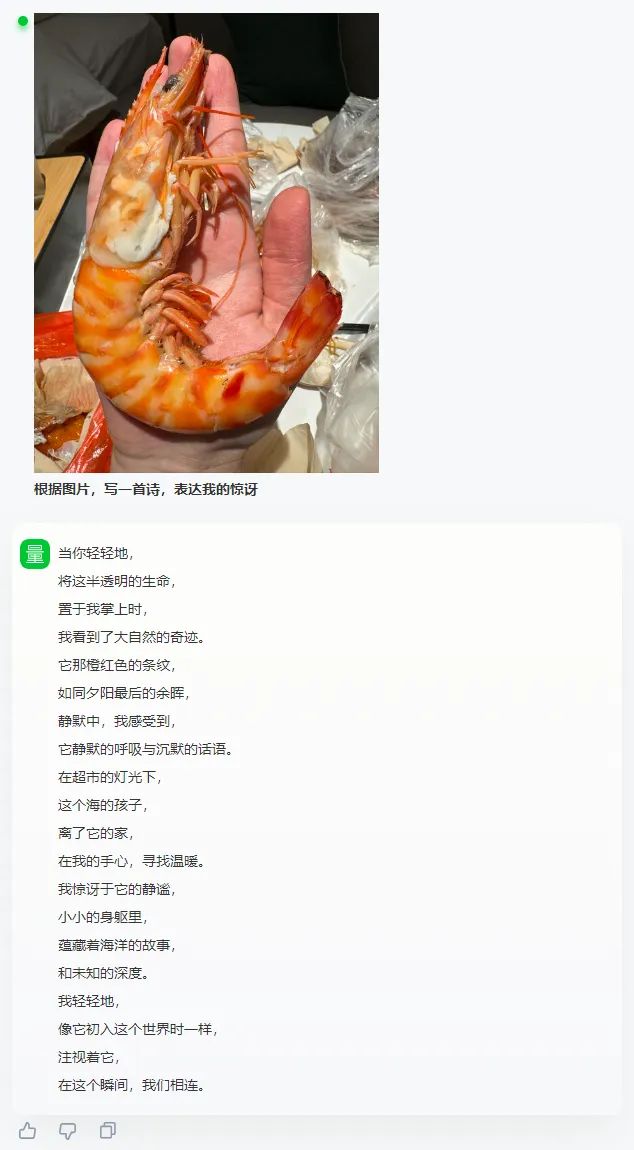

Объясните смайлы, он тоже понимает мемы

Помогает определить, подходит ли пища (предпочтительно для людей, занимающихся фитнесом и снижением веса).

Я могу точно понять содержание изображения, а также могу судить, что это коммерческая сфера, исходя из окружающей среды.

Я бужу цветы в бачке унитаза, а также немного разбираюсь в цветочном искусстве (добавлены новые знания о цветочном искусстве)

Кажется, он тоже хорошо готовит
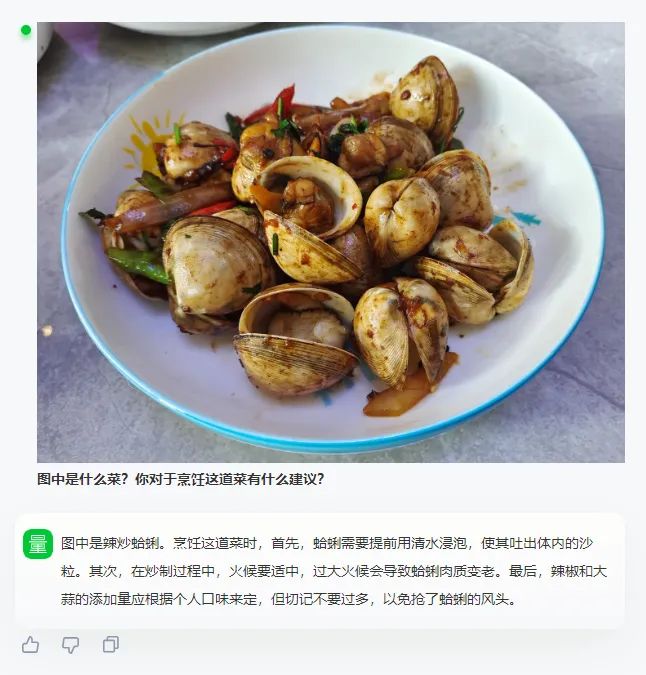
Содержание скриншотов точное и чрезвычайно подробное.

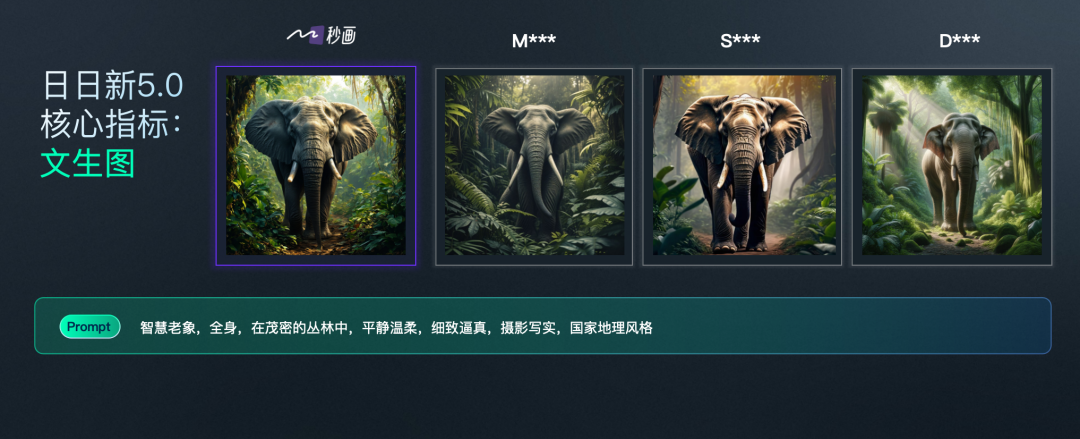
Фотографии Винсента и видео Винсента из SenseTime 5.0 тоже неплохие. Например, в «Слоне Винсента» изображение старого слона Шан Таном имеет более естественный эффект, а в «Друге Шанга» изображен слон с тремя ногами.

Три видеоролика, воспроизводимые на месте, были полностью созданы большими моделями с реалистичными видеоэффектами. На самом деле, управляемость персонажей, действий и сцен в видеороликах Винсента очень сложно контролировать, но видеоплатформа SenseTime Vincent по-прежнему сохраняет целостность и целостность. согласованность видеоконтента.
2. «Потрясающая» уверенность мультимодальных больших моделей
На этот раз SenseTime действительно потрясающий.
Кажется, все происходит в мгновение ока. На каком этапе крупные модели Китая начали становиться разумными?
Все вышеперечисленные задачи являются мультимодальными. Мультимодальные возможности — это решающая битва за AGI и ключевая битва для Китая, чтобы обогнать его в поворотах. Однако эти ворота довольно сложно атаковать.
Самая большая проблема мультимодальности — это семантический разрыв между различными модальностями. Этот разрыв в понимании языка приведет к потере некоторой важной визуальной информации, такой как форма объекта, пространственные отношения, способность эмоционального представления и перекрытие.
Например, модель диаграммы Винсента рисует панду. Сложность заключается в том, что текстовые сигналы обозначают слова, а визуальные сигналы — это пиксели. Однако эти иерархические структуры различны, что затрудняет их выравнивание, и для сопоставления требуются локальные детали. Кроме того, существует ряд проблем, таких как производительность вычислений и память.
Только после понимания этого мы сможем понять силу большой мультимодальной модели SenseTime, показанной выше.
Почему SenseTime может работать так быстро на мультимодальных больших моделях? На самом деле всегда есть следы, по которым можно идти.
Мощный вычислительный источник питания, алгоритмы и данные
Три элемента: ИИ, вычислительная мощность, алгоритмы и данные по-прежнему остаются актуальными.
Прежде всего, мощный запас вычислительной мощности сегодня является самым дефицитным и наиболее конкурентным фактором.
Всего за два года сотни научных школ боролись с крупномасштабной моделью Китая. Однако, как технология с сильными технологиями, сильными ресурсами и сильной инвестиционной ориентацией, это, по сути, игра для крупных производителей.
Только компании с мощной вычислительной инфраструктурой, кластерами вычислительного оборудования, планированием ресурсов и другими возможностями, которые могут более эффективно использовать вычислительные ресурсы и снизить предельную стоимость моделей, имеют право стоять на ногах.
SenseTime — один из немногих крупных поставщиков вычислительной мощности в отрасли.
SenseTime вкладывает значительные средства в инфраструктуру искусственного интеллекта с 2017 по 2018 год, создав SenseCore, большое устройство искусственного интеллекта, редкую в отрасли специализированную инфраструктуру для крупных моделей с общей вычислительной мощностью 12 000P.
Среди них Shanghai Lingang AIDC после нового обновления может выдавать вычислительную мощность 8400P, что делает ее крупнейшей вычислительной платформой искусственного интеллекта в Китае.
Он имеет 45 000 графических процессоров для предоставления услуг по обучению больших моделей и выводам для внешнего мира, а также имеет возможность проводить крупномасштабное параллельное обучение от «тысяч карточек и тысяч женьшеня» до «десяти тысяч карточек и десятков тысяч женьшеня». . Кроме того, SenseCore, крупное устройство искусственного интеллекта SenseTime, завершило адаптацию и применение 58 отечественных чипов с внутренней вычислительной мощностью 1500P.
Боевые искусства в мире основаны на скорости. Тот, кто сможет быстрее оптимизировать технологию, первым найдет путь к коммерциализации.
Итерация модели также зависит от поставок вычислительной мощности. На этапе обучения, чем больше вычислительная мощность, тем больше модель, которую можно создать, и тем выше скорость обновления и итерации.
Благодаря такому мощному запасу вычислительной мощности SenseTime может выполнять итерации с максимальной скоростью в каждом модельном диапазоне 7B, 20B и 100B.
RiRiXin оправдывает свое название. С момента выпуска «Ririxin» в апреле 2023 года большие модели SenseTime быстро обновлялись со скоростью одна версия каждые 2–3 месяца. Всего за один год было обновлено 5 версий.
Давайте еще раз посмотрим на алгоритм.
Как упоминалось ранее, самой большой проблемой мультимодальности является семантический разрыв между различными модальностями.
Расположение и выравнивание различных режимов не означает, что данные в каждом режиме очищены и ввод можно выполнить.
Чем больше модальностей, тем труднее их согласовать. Каждое звено требует полного понимания и накопления большого количества данных по каждой модальности.
Поэтому SenseTime приложила большие усилия к разработке моделей алгоритмов.
Крупнейшей визуальной базовой моделью в отрасли является большая модель Google с 22 миллиардами параметров, которая использует внутренние данные JFT. Такой большой объем внутренних данных изображений трудно сопоставить в отрасли.
SenseTime выпустила 6-миллиардную модель во второй половине 2023 года. Она использует только четверть параметров и не уступает ей по типичным возможностям обнаружения и сегментации.
На примере длинных изображений с большим разрешением приведены некоторые мультимодальные окна. Поскольку разрешение изображения слишком велико, окна не могут быть распознаны. Однако модель SenseTime обеспечивает интерфейс с очень большим разрешением и может распознавать разрешения 2K✖️10 000. Высокоэффективные изображения стали основой мультимодального отличия SenseTime от конкурентов.
Возможность поддерживать такое высокое разрешение является заслугой разработки модели алгоритма.
Предыдущий путь требовал интегрированного обучения нескольких модальностей, таких как зрение, на основе большой языковой модели, преобразования результатов в более высокие измерения, такие как текст, а затем подачи их в языковую модель. Поэтому большая языковая модель также должна была быть более сильной. Когнитивные способности понимания.
В прошлом большие языковые модели должны были фокусироваться только на тексте, а формы мультимодального распределения данных и выражения были разными. Поэтому в конструкцию модели необходимо было включать больше интерактивной информации, что требовало очень сложного проектирования.
В прошлом году SenseTime грамотно разработала модель предварительного обучения, позволяющую модели определять корреляцию между различными модальностями, вводить каждый уровень информации, а также выполнять картографирование и выравнивание. Улучшение возможностей напрямую отражается на встроенном мультимодальном объекте. Модель, которая может извлекать и понимать изображения, текст, аудио и визуальные эффекты, была достигнута более значительными улучшениями и прорывами.
Модель алгоритма SenseTime спроектирована так, чтобы быть тесно связанной и обладает мощными интерактивными возможностями.
Основным преимуществом SenseTime является базовая совместимость и интегрированность всей конструкции модели.
«Многие компании имеют один продукт. Распознавание изображений и текста и Винсент Видео принадлежат разным командам и не связаны друг с другом. Максимум, можно вызвать один и тот же инструмент, а документ просто копировать в другой инструмент. Интерактивность Очень слабая ."
Лу Левэй, старший директор по исследованиям и разработкам SenseTime Technology, сказал, что в отделе исследований и разработок SenseTime 5.0 работает та же команда, дизайн модели интегрирован, возможности взаимодействия значительно улучшены, и он может динамически понимать требования к входным данным, понимать изображения и предоставлять Очень подробное объяснение.
Посмотрите на данные еще раз.
За последние десять лет в области искусственного интеллекта SenseTime был использован во многих отраслях, включая городскую разведку, торговлю, здравоохранение, финансы, автономное вождение и даже в таких отраслях, как сталелитейная промышленность, добыча угля и электроэнергетика. накопил большой объем мультимодальных данных в различных отраслях.
«Количество» присутствует, но и «качество» тоже должно быть обеспечено.
Самым важным улучшением Ririxin 5.0 является не только использование смешанных экспертов (MoE) в модели, но и устранение проблем с качеством данных. SenseTime использует более 10Т токенов на уровне знаний, что позволяет поддерживать целостность высококачественных данных.
Кроме того, SenseTime также синтезирует и конструирует данные цепочки мыслей, что является ключом к реальному улучшению возможностей модели. Если данные цепочки мышления каждой отрасли можно будет легко построить, способность к рассуждению будет значительно улучшена. В процессе будут построены сотни миллиардов данных цепочки знаний, так что возможности модели можно будет сравнить с GPT-4 Turbo.
С прошлого года SenseTime также создала очень мощный механизм обработки данных, который может выполнять задачи по очистке и дистилляции данных более чем двух триллионов токенов каждый день. Это также позволяет осуществлять непрерывную итерацию предоставления данных большой модели в сочетании с уникальными алгоритмами SenseTime Designed. завершить замкнутый цикл троицы крупных алгоритмов моделей искусственного интеллекта, данных и вычислительной мощности.
Мультимодальное накопление восприятия
Перцептивные способности лежат в основе мультимодальных возможностей.
Без дальнейших церемоний, давайте перейдем непосредственно к данным.

Эта большая мультимодальная модель с более чем 100 миллиардами параметров достигла ведущего в мире уровня возможностей восприятия изображений и текста. Она имеет комплексную систему знаний, и ее понимание реального мира значительно улучшилось.
Он не только занимает первое место в авторитетном комплексном тесте производительности MMBench для мультимодальных больших моделей с общим баллом 82,3 (превышая 77 баллов у GPT-4V), но также занимает первое место в нескольких известных списках мультимодальных моделей, таких как MathVista. , AI2D, ChartQA, TextVQA, DocVQA и MMMU. Лучшие результаты.
Это работа не дня.
Много лет назад функции «Сегодня в прошлом году» и «Счастливый час» фотоальбомов мобильных телефонов задавали тему на основе некоторых фотографий определенного периода времени и автоматически создавали специальный музыкальный клип с музыкой. Это может быть оригинальный стиль. «автоматически созданных видео».
Тан Сяоу, основатель SenseTime Technology, может быть одним из первых, кто начал изучать создание видео.
В 2012 году, в эпоху, когда основными популярными средствами массовой информации в Интернете были музыка и изображения, Тан Сяоу, как первый автор, новаторски предложил статью «Автоматическое создание музыкальных видео: перекрестное сопоставление музыки и изображений», которая также была выбрана. на ACM Multimedia 2012 (самая важная в мире конференция в области мультимедиа).
Задача на тот момент заключалась в том, как найти адаптированные изображения, чтобы согласовать их с песнями. Команда предложила систему, которая автоматически генерирует музыкальные клипы для заданной песни, извлекает связанные изображения из Интернета, используя ключевые слова в качестве запросов, и использует методы, основанные на обучении. При оценке семантических оценок между изображениями и музыкальными клипами начинает проявляться роль методов обработки естественного языка в создании видео.
С 2014 по 2015 год компания SenseTime выпустила набор данных CelebA, который включает в себя выражения лиц, эмоции, взгляды, волосы и т. д. Это эталонный набор данных, который привел к разработке генеративных моделей и положил начало развитию первого поколения состязательных генеративных сетей GAN.
В период с 2019 по 2020 год компания SenseTime объединила накопление визуальных алгоритмов с технологией GAN, чтобы запустить цифровые исследования Ruying на людях и продвигать соответствующие исследования в области графов Винсента.
Мультимодальность требует организации данных и возможностей понимания, а также понимания разнообразной визуальной информации, аудио и видео. Фактически, как компания, которая начинала с компьютерного зрения, у SenseTime было слишком много ауры и накоплений.
Vincent Video и Vincent Picture имеют одно и то же происхождение. Сегодня сфера генеративного искусственного интеллекта SenseTime продолжает бурно развиваться, извлекая выгоду из многих лет непрерывных исследований и накоплений.
Неудивительно, что SenseTime способен анализировать и понимать длинные изображения высокой четкости и интерактивно генерировать винсентские изображения. Он также может реализовывать сложное извлечение знаний из нескольких документов и отображение сводных вопросов и ответов. Он также обладает богатыми возможностями мультимодального взаимодействия.
Безупречный сервис
Кроме того, были дополнительно улучшены база знаний SenseTime, интеграция знаний, тонкая настройка и другие возможности сервиса.
Мультимодальная большая модель 5.0 имеет новый интерфейс объединения знаний, который можно оптимизировать на основе возможностей базы знаний и значительно уменьшить возникновение иллюзий модели.
SenseTime систематически систематизирует отраслевые знания. Каждая крупная отраслевая модель будет объединять знания клиентов, политику и нормативные акты, новейшие статьи и т. д., чтобы систематизировать карту знаний и сформировать богатый и своевременный резерв отраслевых знаний.
В измерении модели исследовательская группа использует предварительное обучение и контролируемую точную настройку на основе массивных графических и текстовых данных, которые могут обрабатывать несколько типов задач, включая обычные графические и текстовые задачи, а также открытые задачи с длинным хвостом.
также,Мультимодальная Модель 5.0 также построила процесс Безупречного обслуживания.,Плагин базы знаний, поддерживающий контроль качества и данные в виде обычного текста.,И может реализовать ввод документов PDF, Word и других форматов, подключив несколько вложений извне.,Может предоставлять услуги по интеграции знаний,И поддерживает Prompt, SFT, Lora и различные методы точной настройки модели.
Теоретически, когда человек обладает способностями в нескольких измерениях одновременно, имеет запас боевой мощи, высокий интеллект и зрелые мыслительные способности, логику и способность к расширению, если он также понимает знания различных отраслей и отраслей, и его служба сильна. , он может «знать астрономию сверху и географию снизу».
За высшим мастером стоят разнообразные одноточечные навыки и основная сила.
3. Путь SenseTime к общему ИИ и генеративному ИИ
Нынешняя битва сотен моделей имеет хаотичный накал.
По мнению некоторых экспертов отрасли, в настоящее время существует три типа отечественных больших моделей: оригинальные большие модели, большие большие модели с открытым исходным кодом из-за границы и собранные большие модели, то есть собирающие воедино маленькие модели из прошлого и превращающие их в параметры, которые выглядят очень большими. Большая «большая модель».
Большинство компаний в отрасли попадают в последние две категории. У них либо есть только модели и нет вычислительной мощности, либо у них есть вычислительная мощность, но не хватает оперативной вычислительной мощности, а крупным моделям не хватает дифференциации.
Вступая в год конкуренции за коммерциализацию больших моделей, ожесточенная битва за большие модели на поверхности на самом деле является битвой за оригинальные большие модели.
Без достаточно сильного накопления технологий, устойчивого высокого инвестиционного и инженерного потенциала коммерциализация будет пустым плаванием.
SenseTime, кажется, нашел общий путь Модельпуть индустриализации。Существует не только большая модель как услуга, движимая полным приводом «большая модель + большая вычислительная мощность», но также существует полнофункциональная компоновка крупных моделей в облаке, терминале и на периферии.
В 2024 году, во второй половине Войны Сотни Модов, будут соревноваться сотни компаний, конкурирующих за большие параметры, мультимодальность и длинные тексты, и мультимодальная конкуренция нажмет на кнопку акселератора.
Возможно, в ближайшем будущем вы сможете включить компьютер, ввести свои требования, и большая модель напрямую сгенерирует PPT и документы. Если вы чувствуете, что этого недостаточно, вам нужно только изложить свои требования, и они будут постоянно меняться. Например, как можно нарисовать определенную диаграмму?
Генерация PPT, создание фрагментов кино- и телеработ, непосредственное написание кода в соответствии с потребностями пользователя, генерация программ... Это направления, над которыми усердно работает большая группа исследователей моделей.
Мы с нетерпением ждем, будет ли это благо приноситься нам каждый день в будущем.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
