Основной принцип двухпотокового соединения Flink
Введение в основополагающие принципы
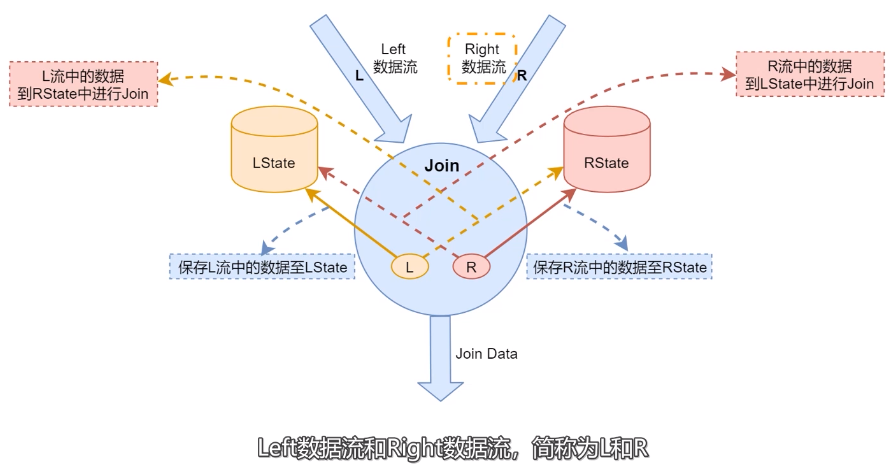
- Состояние: сохраняет данные в потоке данных координат.
- RState: сохраняет данные в потоке данных справа.
- Когда поступают данные левого потока данных, они будут сохранены в LState и объединены в RState. Отправьте данные результата, сгенерированные соединением, в нисходящий поток.
- Когда данные в потоке данных справа поступают, они будут сохранены в RState, объединены в LState, а затем данные результата соединения будут отправлены вниз по течению.
Чтобы гарантировать, что данные, которые необходимо объединить в левом и правом потоках, появятся в одном и том же узле, Flink SQL будет использовать условия включения в соединении для разделения одних и тех же условий ассоциации. Данные распределяются в один и тот же раздел.
Обычное двухпотоковое соединение
Существующие таблица заказов A и таблица платежей B связываются для получения сводной таблицы C. Исходные данные таблицы заказов и таблицы платежей следующие:
Таблица A: Данные таблицы заказов
order_id | timestamp |
|---|---|
1001 | 2023-02-04 10:00:00 |
1002 | 2023-01-04 10:01:02 |
Таблица B: Данные таблицы платежей
order_id | pay_money |
|---|---|
order_id | pay_money |
1001 | 80 |
1002 | 100 |
inner join
Когда поступает каждый фрагмент данных в таблице A, он будет связан с данными в таблице B:
- Когда вы можете относиться к данным,Выведите результаты на поверхность результатов;
- Когда данные не могут быть связаны,Результаты не будут выводиться на поверхность результатов;
Таким образом, результат соединения приведенных выше таблиц A и B:
order_id | timestamp | pay_money |
|---|---|---|
1002 | 2023-01-04 10:01:02 | 100 |
Когда в таблицу Б поступает 1001 новых данных, новые данные выглядят следующим образом:
order_id | pay_money |
|---|---|
order_id | pay_money |
1001 | 80 |
На данный момент данные в таблице результатов следующие:
order_id | timestamp | pay_money |
|---|---|---|
1002 | 2023-01-04 10:01:02 | 100 |
1001 | 2023-02-04 10:00:00 | 80 |
Уведомление
Внутреннее соединение не генерирует поток восстановления.
left join
Когда данные в таблице A поступают, он активно выполняет связанный запрос с данными в таблице B, но никаких связанных данных нет. Результаты также будут выведены, а недостающие поля будут заполнены значением null.
После поступления данных 1002 в таблице B и данных 1001 и 1002 в таблице A данные в таблице C после ассоциации будут следующими:
order_id | timestamp | pay_money |
|---|---|---|
1001 | 2023-02-04 10:00:00 | null |
1002 | 2023-01-04 10:01:02 | 100 |
Когда поступают данные 1001 в таблице B, они также будут активно связаны с данными в таблице A. Если данные в таблице уже имеют выходные результаты и отсутствующее поле имеет значение NULL, то Будет сгенерирован поток коррекции, ранее выведенные данные будут удалены -D, а полные данные будут повторно выведены +I.
order_id | timestamp | pay_money | / |
|---|---|---|---|
1001 | 2023-02-04 10:00:00 | null | +I |
1002 | 2023-01-04 10:01:02 | 100 | +I |
1001 | 2023-02-04 10:00:00 | null | -D |
1001 | 2023-02-04 10:00:00 | 80 | +I |
Уведомление
left Join создаст поток коррекции.
Right Join
Когда в таблицу B поступает 1001, а данные в таблицу A не поступают, данные все равно будут выведены, а недостающие поля будут заменены нулевыми. Когда поступают данные 1002 в таблице B, данные в таблице A Данные 1002 поступили и могут быть связаны с данными. Результаты ассоциации следующие:
order_id | timestamp | pay_money |
|---|---|---|
1001 | null | null |
1002 | 2023-01-04 10:01:02 | 100 |
Когда поступают данные 1001 в таблице A, они будут активно связаны с таблицей B. В это время данные о 1001 будут выведены в результате, и будет сгенерирован поток восстановления.
order_id | timestamp | pay_money | / |
|---|---|---|---|
1001 | null | null | +I |
1002 | 2023-01-04 10:01:02 | 100 | +I |
1001 | null | null | -D |
1001 | 2023-02-04 10:00:00 | 80 | +I |
Уведомление
Right Join создаст поток коррекции.
Full Join
Когда данные 1001 в таблице B поступают первыми, они активно переходят к таблице A для выполнения связанного запроса. Если данные не могут быть связаны, результат все равно будет выведен.
Когда данные в таблице A поступают, он активно выполняет связанный запрос с данными в таблице B. В настоящее время в таблице B имеется только 1001 данных. Если данные недоступны, результат все равно будет выведен.
Таким образом, результат корреляции на данный момент выглядит следующим образом:
order_id | timestamp | pay_money |
|---|---|---|
1001 | null | null |
1002 | 2023-01-04 10:01:02 | null |
Когда поступает 1001 в таблице A, связанный запрос будет выполнен с таблицей B. Когда появится 1002 в таблице B, связанный запрос будет выполнен с таблицей A. Результаты следующие:
order_id | timestamp | pay_money | / |
|---|---|---|---|
1001 | null | null | +I |
1002 | 2023-01-04 10:01:02 | null | +I |
1001 | null | null | -D |
1001 | 2023-02-04 10:00:00 | 80 | +I |
1002 | 2023-01-04 10:01:02 | null | -D |
1002 | 2023-01-04 10:01:02 | 100 | +I |
Уведомление
Полное соединение сгенерирует поток восстановления.
Interval Join
Интервальное соединение представляет собой ограниченное соединение по сравнению с двухпотоковым соединением UnBounded. То есть каждый фрагмент данных в каждом потоке будет относиться к другому временному интервалу в другом потоке. Выполните JOIN для данных.
грамматика
SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSIONЕсть два способа записи TIMEBOUND_EXPRESSION:
- L.time between LowerBound(R.time) and UpperBound(R.time)
- R.time between LowerBound(L.time) and UpperBound(L.time)
- Сравнительное выражение поверхности с атрибутом времени (L.time/R.time).
Семантика Interval JOIN заключается в том, что каждый фрагмент данных соответствует интервалу данных во временном интервале. Например, существует таблица заказов Orders(orderId, ProductName, orderTime) и таблицу платежей Payment(orderId, payType, payTime). Предположим, мы хотим подсчитать информацию о заказе, который оплачен в течение одного часа с момента размещения. SQL-запрос выглядит следующим образом:
SELECT
o.orderId,
o.productName,
p.payType,
o.orderTime,
cast(payTime as timestamp) as payTime
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND
p.payTime BETWEEN orderTime AND
orderTime + INTERVAL '1' HOURЗаказы Данные заказа
orderId | productName | orderTime |
|---|---|---|
001 | iphone | 2018-12-26 04:53:22.0 |
002 | mac | 2018-12-26 04:53:23.0 |
003 | book | 2018-12-26 04:53:24.0 |
004 | cup | 2018-12-26 04:53:38.0 |
Оплата Платежные данные
orderId | payType | payTime |
|---|---|---|
001 | alipay | 2018-12-26 05:51:41.0 |
002 | card | 2018-12-26 05:53:22.0 |
003 | card | 2018-12-26 05:53:30.0 |
004 | alipay | 2018-12-26 05:53:31.0 |
Семантически ожидаемый результат Информация с идентификатором заказа 003 не отображается в результатах.,Потому что время заказа2018-12-26 04:53:24.0, Срок оплаты составляет
2018-12-26 05:53:30.0превосходить1почасовая оплата。
Тогда информация об ожидаемом результате будет следующей:
orderId | productName | payType | orderTime | payTime |
|---|---|---|---|---|
001 | iphone | alipay | 2018-12-26 04:53:22.0 | 2018-12-26 05:51:41.0 |
002 | mac | card | 2018-12-26 04:53:23.0 | 2018-12-26 05:53:22.0 |
004 | cup | alipay | 2018-12-26 04:53:38.0 | 2018-12-26 05:53:31.0 |
Таким образом, заказ с идентификатором 003 является недействительным заказом, и запасы можно обновить, чтобы продолжить продажи.
Далее наглядно проиллюстрируем семантику Interval JOIN на диаграмме. Немного меняем требования приведенного выше примера: Заказы можно оплачивать заранее (можно ли). Разумно это или нет, мы лишь объясняем семантику) то есть оплата в течение 1 часа до и после заказа действительна. Оператор SQL выглядит следующим образом:
SELECT
...
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND
p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND
orderTime + INTERVAL '1' HOURПодвести итог
- Ассоциация потоков Flink в настоящее время поддерживает только ассоциацию двух потоков.
- Flink поддерживает соединения потоков на основе EventTime и ProcessingTime.
- Интервальное соединение уже поддерживает внутреннее, левое внешнее, правое внешнее, полное внешнее и другие типы соединений. Отсюда следует поддержка интервального соединения на официальном сайте. Описание поддержки типов недостаточно точное.
- Очистка сообщений двух потоков в текущей версии интервального соединения основана на объединенном водяном знаке, общем для двух потоков (водяной знак меньшего потока).
- Водяные знаки потока не будут использоваться для прямой фильтрации сообщений.,Мгновенное сообщение опаздывает на поверхность водяного знака в этом потоке.,Однако просроченные сообщения будут перенаправлены непосредственно Соответствующий тип соединения либо выводится, либо отбрасывается.
Таблица размеров
Таблица измерений — это концепция, основанная на моделировании хранилища данных. В модели хранилища данных таблица фактов (таблица фактов) относится к таблице, в которой хранятся записи фактов, например системной Журналы, записи о продажах и т. д. Таблица измерений представляет собой таблицу, соответствующую таблице фактов. Она сохраняет соответствующую подробную информацию об указанных атрибутах в таблице фактов и может быть связана с таблицей фактов. Соединение эквивалентно извлечению и стандартизации часто повторяющихся атрибутов таблицы фактов и управлению ими в одной таблице.
В реальном производстве у нас часто возникает потребность на основе исходного потока данных связать большое количество внешних таблиц для дополнения некоторых атрибутов. Эта операция запроса Типичная таблица размерностей JOIN.
Преимущества использования таблиц измерений
- Уменьшен размер фактической поверхности.
- Облегчает управление и обслуживание измерений.,Добавление, удаление и изменение атрибутов измерения,Нет необходимости вносить изменения в обширную запись фактов поверхности.
- Размеры поверхности можно повторно использовать для нескольких фактов.,сократить дублирование работы.
Таблица измерений Использование JOIN
Поскольку таблица измерений является постоянно изменяющейся таблицей (статическая таблица считается частным случаем динамической таблицы), таблица измерений JOIN Когда необходимо указать пару снимков таблицы измерений, связанных с этой записью. время. Флинк SQL таблица размеров JOIN грамматика введена Temporal Table Стандартная грамматика используется для объявления того, с каким снимком поверхности измерения связаны данные потока.
Необходимо Уведомление есть, на данный момент родное Flink SQL таблица размеров JOIN Поддерживается только связь таблицы фактов со снимком таблицы измерений в текущий момент (семантика времени обработки), а факты не поддерживаются. поверхность rowtime Соответствует таблице Корреляция снимков размеров (семантика времени события).
грамматикаиллюстрировать
Flink SQL используется вграмматикаfor SYSTEM_TIME as of PROC_TIME()Чтобы определить размерыповерхностьJOIN。Поддерживает толькоINNER JOINиLEFT JOIN。
SELECT
column-namesFROM
table1 [AS <alias1>][LEFT]
JOIN table2 FOR SYSTEM_TIME AS OF table1.proctime [AS <alias2>]
ON table1.column-name1 = table2.key-name1Уведомление:
table1.proctimeповерхность Показыватьtable1изproctimeПоле。
Пример использования
Ниже приведен простой пример, демонстрирующий размер поверхности. JOIN грамматика. Предположим, у нас есть Orders Поток данных заказа, надеюсь, на основе пользователя ID Полное количество пользователей в заказах информацию, поэтому вам нужно следить Customer Измерьте поверхность для корреляции.
CREATE TABLE Orders (
id INT,
price DOUBLE,
quantity INT,
proc_time AS PROCTIME(),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'rows-per-second' = '10'
);
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
CREATE TABLE OrderDetails (
id INT,
total_price DOUBLE,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/orderdb',
'table-name' = 'orderdetails'
);
-- enrich each order with customer information
INSERT INTO OrderDetails
SELECT
o.id,
o.price,
o.quantity,
c.country,
c.zipFROM
Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.id = c.id;Процесс выполнения Flink SQL
Apache Calcite — это инструмент анализа SQL с открытым исходным кодом, который широко используется в различных проектах по работе с большими данными и в основном используется для анализа операторов SQL. Порядок выполнения SQL Обычно делится на четыре основных этапа:
- Parse: разбор грамматики, постановка SQL Высказывание преобразуется в абстрактное грамматическое дерево (AST), в Calcite Китайское использование SqlNode Приходитьповерхность Показывать;
- Validate:грамматикапроверять,Проверка на основе информации метаданных,Например, запросите поверхность, существует ли используемая функция и т. д.,проверять Еще после этого SqlNode структура выращенное грамматическое дерево;
- Оптимизация: оптимизация плана запроса, включающая два этапа, 1) SqlNode Преобразование дерева грамматики в выражение поверхности отношения RelNode структуру в логическое дерево, 2) использовать лучшее Оптимизатор выполняет эквивалентные преобразования на основе таких правил, как перемещение предикатов, сокращение столбцов и т. д., и после оптимизации оптимизатором получается оптимальный план запроса;
- Выполнение. Преобразуйте план логического запроса в план физического выполнения, сгенерируйте соответствующий исполняемый код и отправьте его для выполнения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
