Основа платформы LangChain для большой модели и примеры использования


Автор: Кевин
Картинка стоит тысячи слов,LangChainстал актуальным LLM Эта статья является фактическим стандартом для платформ приложений. LangChain Подведем итог основным понятиям и конкретным сценариям их использования.
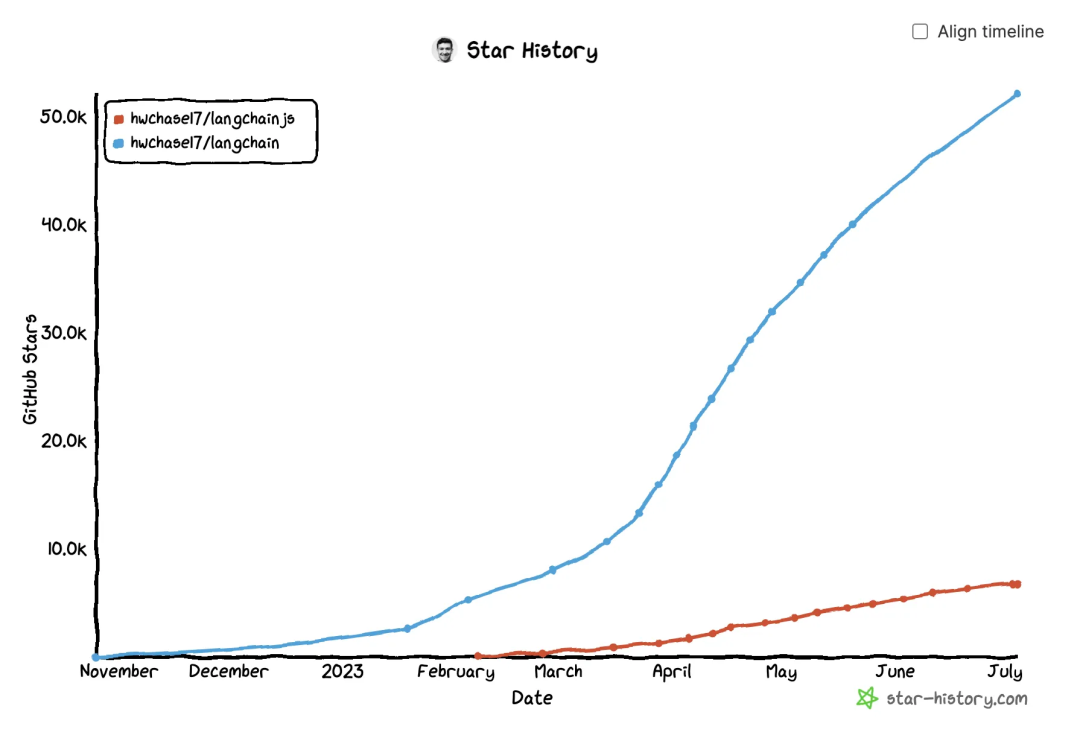
Что такое Лангчейн?
LangChainдаодинна основебольшой язык Модельизразработка приложенийрамка,В основном оно регулируется двумя способами.и Упрощенное использованиеLLMиз Способ:
- интегрированный:интегрированныйвнешнийданные(нравитьсядокумент、Другие приложения、API данныеждать)приезжать
LLMсередина; - Agent:позволять
LLMпосредством принятия решений и конкретныхизвзаимодействие с окружающей средой,И поLLMПомогите определиться с дальнейшими действиямииздействовать。
К преимуществам LangChain относятся:
- Высота абстрактаиз Компонентов:спецификацияи Упрощение и язык Модельнеобходим для взаимодействияиз Различныйабстрактныйикомпоненты;
- Широкие возможности настройки цепочек:Предусмотрено множество пресетов
Chainsизв то же время, поддерживает самонаследование BaseChain и реализовать соответствующую логику такжеразличные этапыизcallback handlerждать; - Активное сообщество и экология:
LangchainКоманда работает очень быстро,Быстро используйте новейшие возможности языка модели,В команде также есть langsmith, auto-evaluator и другие отличные проекты, а сообщество открытого исходного кода также пользуется значительной поддержкой.
Основные компоненты LangChain
этотдаодин кусочекLangChainизкомпонентыи架构图(langchain pythonиlangchain JS/TSиз Архитектура в принципе та же самая,本文середина以langchain pythonзавершить соответствующее введение),В принципе полностью описаноLangChainизкомпонентыиабстрактныйслой(callbackНетсуществоватьэтот张图середина,существования мы представим его отдельно ниже),а Также между ними существует корреляция.
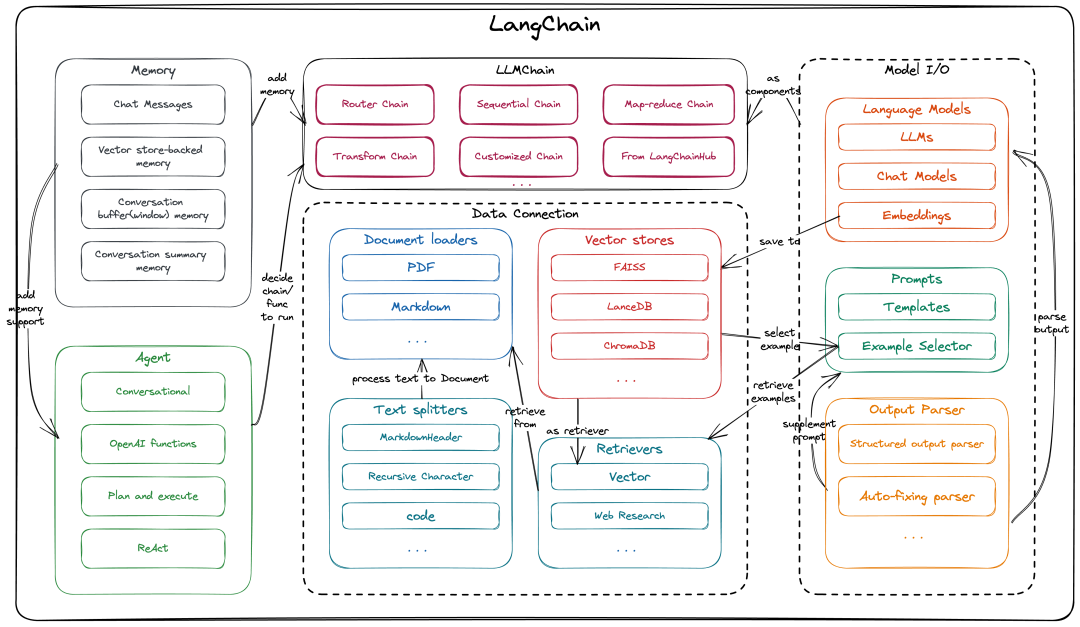
Model I/O
Во-первых, давайте начнем с самой базовой части. Модель ввода-вывода относится к процессу прямого взаимодействия с LLM.
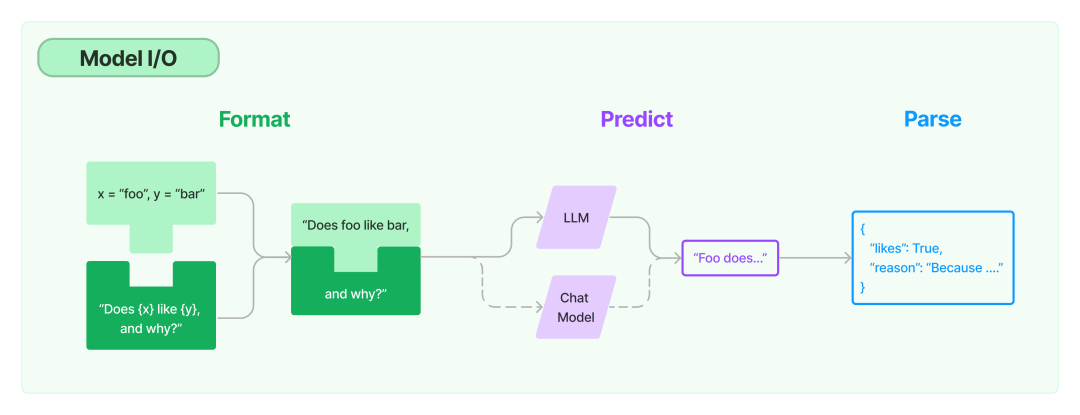
В процессе ввода-вывода модели есть три основных абстрактных компонента LangChain:
Давайте представим это ниже
⚠️ Примечание:Нижеследующее включает в себяииз Все примеры кодавOPENAI_API_KEYиOPENAI_BASE_URLНеобходимо настроить заранее,OPENAI_API_KEYобратитесь кПрокси-сервис OpenAI/OpenAIизAPI Key,OPENAI_BASE_URLобратитесь к OpenAI агентское обслуживаниеизBase Url。
Language Model
Language Modelда真толькои LLM / ChatModel Интерактивная составляющая, к которой можно относиться напрямую как к обычной openai client использовать,существоватьLangChainсередина,主要использоватьприезжатьиздаLLM,Chat ModelиEmbedding三类 Language Model。
LLM: большинство Базаизпроходить“text in ➡️ text out”模式использоватьиз Language Модель же LangChain Он также содержит большое количествоизLLM третьей стороны。
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
llm("What day comes after Friday?")
# '\n\nSaturday.'
Chat Model: LLMиз Варианты,абстрактный ПонятноChatэтот一场景Внизизшаблон использования,Зависит от“text in ➡️ text out”变成Понятно“chat messages in ➡️ chat message out”,chat messageдаобратитесь к**text + message type(System, Human, AI)**。
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(model_name="gpt-4-0613", temperature=1, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
chat(
[
SystemMessage(content="You are an expert on large language models and can answer any questions related to large language models."),
HumanMessage(content="What’s the difference between Generic Language Models, Instruction Tuned Models and Dialog Tuned Models")
]
)
# AIMessage(content='Generic Language Models, Instruction-Tuned Models, and Dialog-Tuned Models are all various types of language models that have been trained according to different datasets and methodologies. They are used in different contexts according to their specific strengths. \n\n1. **Generic Language Models**: These models are trained on a broad range of internet text. They are typically not tuned to specific tasks and thus can be used across a wide variety of applications. GPT-3, used by OpenAI, is an example of a general language model.\n\n2. **Instruction-Tuned Models**: These are language models that are fine-tuned specifically to follow instructions given in a prompt. They are trained using a procedure called Reinforcement Learning from Human Feedback (RLHF), following an initial supervised fine-tuning which consists of human AI trainers providing conversations where they play both the user and an AI assistant. This model often includes comparison data - two or more model responses are ranked by quality.\n\n3. **Dialog-Tuned Models**: Like Instruction-Tuned Models, these models are also trained with reinforcement learning from human feedback, and especially shine in multi-turn conversations. However, these are specifically designed for dialog scenarios, resulting in an ability to maintain more coherent and context-aware conversations. \n\nIn essence, the difference among the three revolves around the breadth of their training and their specific use-cases. Generic Language Models are broad but may lack specificity; Instruction-Tuned Models are better at following specific instructions given in prompts; and Dialog-Tuned Models excel in carrying out more coherent and elongated dialogues.', additional_kwargs={}, example=False)
С другой стороны, Лангчейн Он также содержит большое количествоизМодель стороннего чата
- System - Рассказывать AI Справочная информация о том, что делать;
- Human - Идентифицирует тип сообщения, переданного пользователем;
- AI - логотип AI возвращатьсяиз Тип сообщения。нижедаодин简单из
Chat ModelПример использования:
Embedding: EmbeddingВоляодиночный персонажвекторизациядляодин定长извектор,Имея представленную извекторизацию текста, мы можем сделать что-то вроде семантического поиска.,Выбор кластера и т. д. для выделения необходимых фрагментов текста.,нравиться Внизда Воляодин embed Пример произвольной строки:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
text_embedding = embeddings.embed_query("To embed text(it can have any length)")
print (f"Your embedding's length: {len(text_embedding)}")
print (f"Here's a sample: {text_embedding[:5]}...")
'''
Your embedding's length: 1536
Here's a sample: [-0.03194352, 0.009228715, 0.00807182, 0.0077545005, 0.008256923]...
'''
Prompts
Promptобратитесь к用户из一系列обратитесь к令ивходить,да РешатьLanguage ModelВыходной контентиз唯一входить,В основном используется для помогает понять контекст модели и генерировать релевантные и связные результаты, нравиться, отвечает на вопросы и улучшает предложения. итогвопрос。существоватьLangChainв相关компоненты主要有Prompt TemplateиExample selectors,а такжепозже会提приезжатьиз Вспомогательный/ПополнитьPromptиз Некоторый其它компоненты。
Prompt Template: предопределенныйиз一系列обратитесь к令ивходить参数изpromptтрафарет,Поддержка более гибкого ввода,нравитьсяподдерживать**output инструкция (инструкция формата вывода), partial ввод (заранее укажите некоторые входные параметры), examples(входитьвыход Пример)**ждать;LangChainпоставлять Понятно大量метод来创建Prompt Template,有Понятноэтот一слойкомпоненты就Можетсуществовать Нет同Language Modelи Нет同ChainВниз大量复用Prompt TemplateПонятно,Prompt Templateсерединатакже会有Вниз面Воля提приезжатьизExample selectors, Output Parserизучаствовать。
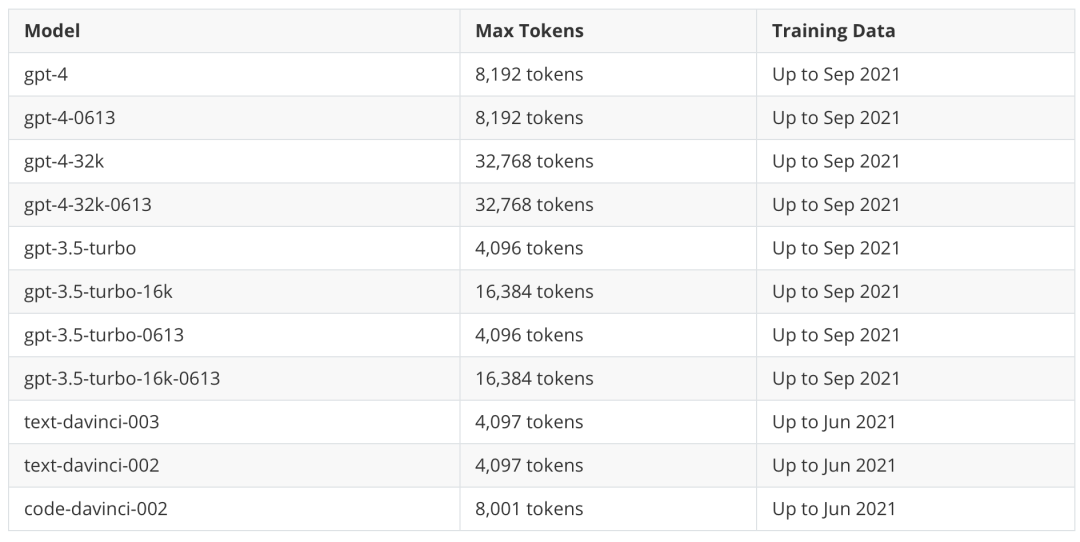
Примеры селекторов: существуют во многих сценариях,простойизinstruction + inputизpromptНет足以让LLMВыполнено качественноизаргументированный ответ,этот时候я们就还нуждатьсядляpromptПополнить Некоторый针对具体вопросиз Пример,LangChain Воляэтот一Функцияабстрактныйдля ПонятноExample selectorsэтот一компоненты,мы можем на на основе ключевого слова, сходство (в целомиспользоватьMMR/cosine similarity/ngramвычислить сходство, существоватьпозжеизвекторданные Библиотека章节середина会提приезжать)。для Понятно让большинство终изpromptНет超过Language Modelиз token верхний предел (для каждой модели token 上限见Вниз表),LangChain还поставлять ПонятноLengthBasedExampleSelector,ограничено длиной example количества, для более длинных входных данных он выбирает сигналы, которые содержат меньше примеров, а для более коротких входных данных он выбирает сигналы, которые содержат больше примеров.
Output Parser
в целоммы надеемсяLanguage Modelизвыходдазафиксированныйиз Формат,чтобы мы могли проанализировать его выходные данные в структурированные данные,LangChainВоляэтот一诉求所需из Функцияабстрактный成ПонятноOutput Parserэтот一компоненты,ипоставлять Понятно一系列изпредопределенныйOutput Parser,нравитьсябольшинство Обычно используетсяStructured output parser, List parser,а такжесуществоватьLLMвыход无法解析时发挥作用изAuto-fixing parser и Retry parser。
Output ParserнуждатьсяиPrompt Template, Chainкомбинацияиспользовать:
- Prompt Template: существовать
Prompt Templateсерединапроходитьобратитесь к定partial_variablesдляOutput Parserиз format,Вот и всесуществоватьpromptсередина Пополнить让Модельвыход所需Формат内容изобратитесь к令; - Chain: существовать
Chainсерединаобратитесь к定Output Parser,ииспользоватьChainизpredict_and_parse / apply_and_parseначало методаChain,Вы можете напрямую вывести проанализированные изданные.
Пример использования
нижедаодин完整изкомбинацияPrompt Template, Output Parser и Chainиз Конкретный пример:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo-16k-0613", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
template = """
## Input
{text}
## Instruction
Please summarize the piece of text in the input part above.
Respond in a manner that a 5 year old would understand.
{format_instructions}
YOUR RESPONSE:
"""
# Создать вывод Парсер, содержит два поля вывода и указывает тип и описание.
output_parser = StructuredOutputParser.from_response_schemas(
[
ResponseSchema(name="keywords", type="list", description="keywords of the text"),
ResponseSchema(name="summary", type="string", description="summary of the text"),
]
)
# CreatePrompt Шаблон и Volyaformat_instructions указываются непосредственно как Выходные данные через частичные_переменные. Парсерformat
prompt = PromptTemplate(
input_variables=["text"],
template=template,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
# Создать цепочку и связать подсказку TemplateиOutput Парсер (он Воля автоматически использует Output Парсер анализирует вывод llm)
summarize_chain = LLMChain(llm=llm, verbose=True, prompt=prompt, output_parser=output_parser)
to_summarize_text = 'Abstract. Text-to-SQL aims at generating SQL queries for the given natural language questions and thus helping users to query databases. Prompt learning with large language models (LLMs) has emerged as a recent approach, which designs prompts to lead LLMs to understand the input question and generate the corresponding SQL. However, it faces challenges with strict SQL syntax requirements. Existing work prompts the LLMs with a list of demonstration examples (i.e. question-SQL pairs) to generate SQL, but the fixed prompts can hardly handle the scenario where the semantic gap between the retrieved demonstration and the input question is large.'
output = summarize_chain.predict(text=to_summarize_text)
import json
print (json.dumps(output, indent=4))
Вывод следующий:
{
"keywords": [
"Text-to-SQL",
"SQL queries",
"natural language questions",
"databases",
"prompt learning",
"large language models",
"LLMs",
"SQL syntax requirements",
"demonstration examples",
"semantic gap"
],
"summary": "Text-to-SQL is a method that helps users generate SQL queries for their questions about databases. One approach is to use large language models to understand the question and generate the SQL. However, this approach faces challenges with strict SQL syntax rules. Existing methods use examples to teach the language models, but they struggle when the examples are very different from the question."
}
Data connection
тольконравитьсяясуществовать Начало статьиизЧто такое Лангчейн?一节середина提приезжатьиз,интегрированный Внешние данные для языковой модели Да LangChain обеспечивает одну из основных компетенций,такжеда На рынке много отличныхизбольшой язык Модель Заявка успешно принятаиз Один из основных(Github Copilot Chat,Помощник в веб-чате,Подвести итог Ассистент диссертации,видео на youtube Подвести итог помощник…),существоватьLangChainсередина,Data connectionэтот一слой主要包含ниже四个абстрактныйкомпоненты:
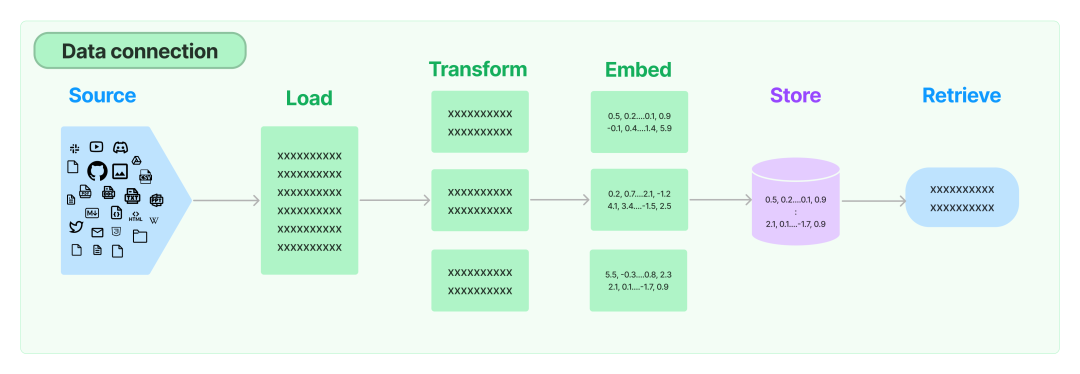
Давайте представим это ниже
Document loaders
чтобы завершить LLM из上Вниз文信息,Дайте ему достаточно подсказок,Нам нужно получать все виды данных из всех источников данных.,этоттакже就даLangChainабстрактныйизDocument loadersэтот一компонентыиз Функция。
использоватьDocument loadersМожет Воляисточниквданные加载дляDocument。DocumentЗависит от一段文本и Связанные элементыданныекомпозиция。примернравиться,Простота загрузки.txt Файл, используемый для загрузки относительно структурированного markdown Файл, используемый для загрузки любого текстового содержимого веб-страницы, даже для загрузки синтаксического анализа. YouTube Видеоскрипт.
в то же время LangChain 还收录Понятно海量изСторонние загрузчики документов,нижедаодиниспользоватьNotionDBLoaderзагрузитьnotion databaseвpageдляDocumentиз Пример:
from langchain.document_loaders import NotionDBLoader
from getpass import getpass
# getpass() предлагает пользователю ввести ключ
NOTION_TOKEN = getpass()
DATABASE_ID = getpass()
loader = NotionDBLoader(
integration_token=NOTION_TOKEN,
database_id=DATABASE_ID,
request_timeout_sec=30, # optional, defaults to 10
)
# Подробности запроса см. https://developers.notion.com/reference/post-database-query
docs = loader.load()
docs[0].page_content[:100]
Document transformers
После загрузки документов в память мы обычно также хотим максимально структурировать/блокировать их для более гибких операций.
Самый простой пример: нам часто приходится разбивать длинный документ на более мелкие части, чтобы они поместились в контекстное окно модели LangChain; Есть много встроенныхизDocument transformers(Большинство из нихдаText Spliter),Может легко разделять, объединять, фильтровать и иным образом манипулировать документами.,Некоторый Обычно используетсяDocument transformersнравиться Вниз:
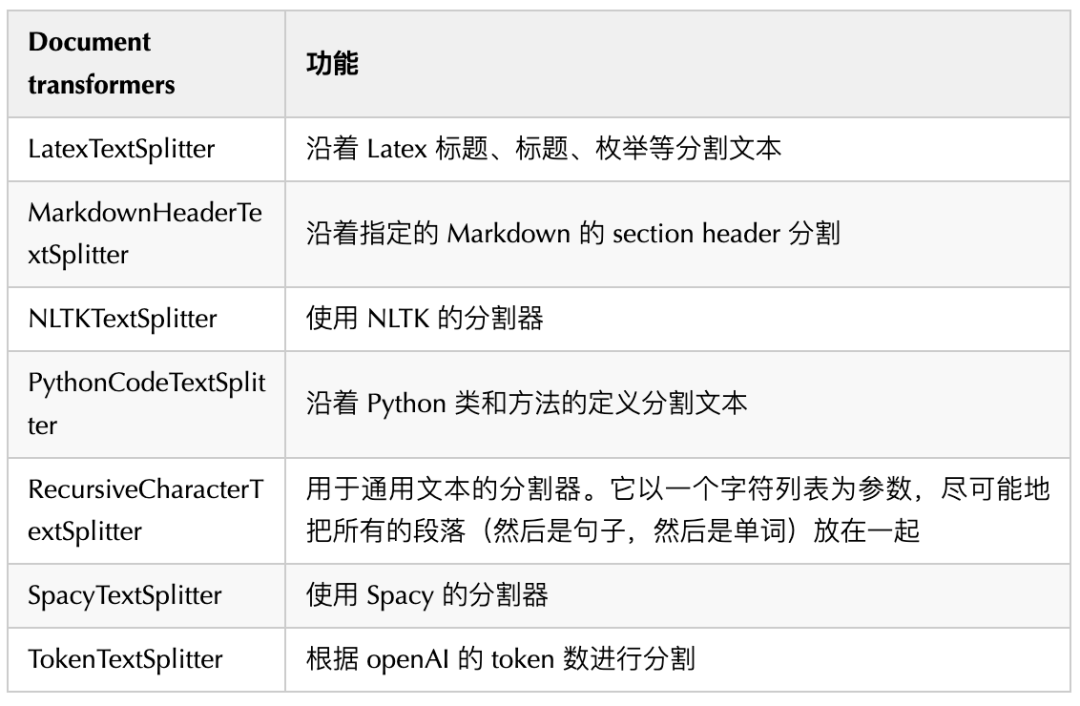
в то же время LangChain также收录Понятно很多Сторонние преобразователи документов(нравитьсяна основе Распространен среди рептилий из beautiful soup, на основе OpenAI бить metadata tag и т. д.).
Vector stores
Мы упомянули селекторы примеров в предыдущем разделе «Подсказки», так как же нам найти подходящие примеры? Часто ответом является база данных векторов.
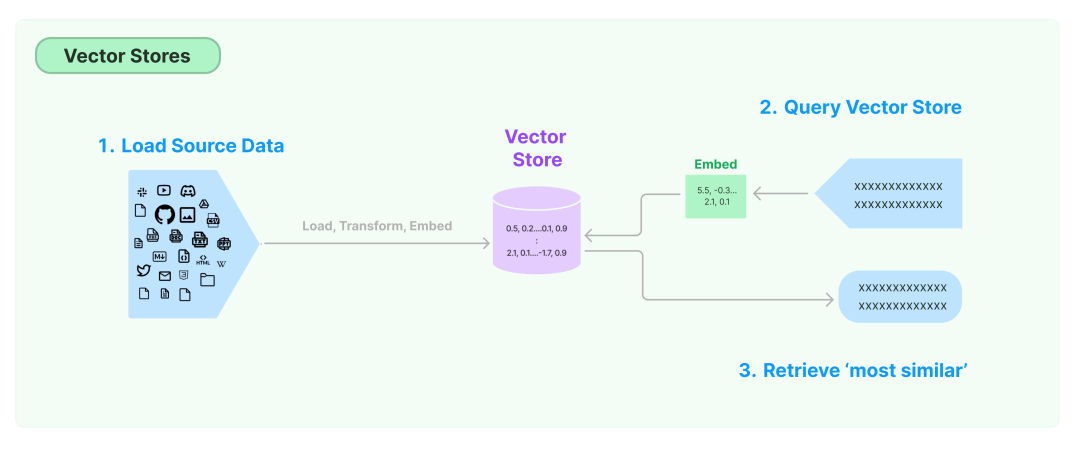
Один из наиболее распространенных способов хранения и поиска неструктурированных данныхизда Воля векторизация (встраивание) и сохранение полученного в результате вектора встраивания.,Затемсуществовать При запросевекторизация Неструктурированный поиск и внедрение запросовиз查询большинство相似извектор。Vector storesОтветственный за хранениевекторизацияданныеипоставлятьвектор搜索из Функция,общийизвекторданные Библиотека включает в себя FAISS, Milvus, Pinecone, Weaviate, Chroma и т. д., чаще всего в повседневном использовании используется FAISS。
в то же время LangChain также收录Понятно很多Сторонние векторные магазины,Обеспечивает более мощный векторный поиск и другие функции.
Retrievers
Retrieversда LangChain поставлятьиз ВоляDocumentиLanguage Modelобъединитьизкомпоненты。
LangChain Существует много разных типов Ретриверы, но наиболее широко используются VectoreStoreRetriever, мы можем напрямую использовать его как библиотеку данных векторов соединений. Language Model средний слой и VectoreStoreRetriever изиспользоватьтакже很简单,прямойretriever = db.as_retriever()Вот и все。
Конечно, у нас есть много других Retrievers нравиться Web search Retrievers Подожди, Лангчейн также收录Понятно很多Сторонние ретриверы
Пример использования 5
Ниже приведен пример приложения контроля качества с использованием базы данных векторов + VectoreStoreRetriever + цепочки контроля качества:
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Инициализировать LLM
llm = ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo-16k-0613", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL)
# Загрузить документ
loader = TextLoader('path/to/related/document')
doc = loader.load()
print (f"You have {len(doc)} document")
print (f"You have {len(doc[0].page_content)} characters in that document")
# разделить строку
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
num_total_characters = sum([len(x.page_content) for x in docs])
print (f"Now you have {len(docs)} documents that have an average of {num_total_characters / len(docs):,.0f} characters (smaller pieces)")
# инициализациявекторизация Модель
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL)
# векторизацию документа и сохранение его в библиотеке векторных данных (вектор привязки соответствует данным элемента документа). Здесь мы выбираем локальный самый обычно. используетсяFAISSданные Библиотека
# Уведомление: При этом генерируется запрос к OpenAI и взимается комиссия.
doc_search = FAISS.from_documents(docs, embeddings)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=doc_search.as_retriever(), verbose=True)
query = "Specific questions to be asked"
qa.run(query)
После выполнения verbose выход日志нравиться Вниз:
You have 1 document You have 74663 characters in that document Now you have 29 documents that have an average of 2,930 characters (smaller pieces) > Entering new chain... Prompt after formatting: System: Use the following pieces of context to answer the users question. If you don't know the answer, just say that you don't know, don't try to make up an answer. --------------- Human: What does the author describe as good work? The author describes working on things that aren't prestigious as a sign of good work. They believe that working on unprestigious types of work can lead to the discovery of something real and that it indicates having the right kind of motives. The author also mentions that working on things that last, such as paintings, is considered good work.
Chains
Следующий главный герой LangChain — Цепочки — это важные компоненты, абстрагированные в LangChain для соединения нескольких взаимодействий с языковой моделью. Он может объединять несколько компонентов для создания единой связной задачи. Вы также можете вкладывать несколько цепочек вместе или объединять их. с другими компонентами для создания более сложных цепочек.
За исключением одиноких Chain Кроме того, несколько часто используемых Chains нравиться Вниз:
Router Chain
В некоторых сценариях нам необходимо / Контекст определяет, какой из них использовать Цепь, хоть какая Prompt,Router Chain 就поставлять Понятно诸нравитьсяMultiPromptChain, LLMRouterChainждать一系列用于决策из Цепочка (это связано с тем, о чем мы упомянем позже) Agent Есть подобные места).
Цепочка маршрутизатора состоит из двух частей:
- Сама цепочка маршрутизаторов: отвечает за определение следующей целевой цепочки;
- Целевые цепочки: целевая цепочка, к которой может маршрутизироваться цепочка маршрутизаторов.
Sequential Chain
Как следует из названия, это последовательная цепочка, выполняемая последовательно. Простейшая из них, SimpleSequentialChain, очень проста и груба. Каждая подцепочка SimpleSequentialChain имеет один вход/выход, и выход одного шага является входом следующего. шаг.
SequentialChain более высокого порядка допускает несколько входов и выходов, и мы можем улучшить производительность его рассуждений, добавив память и т. д., о чем будет упомянуто позже.
Map-reduce Chain
Map-reduce Chain В основном используется для summary сценарий,для этих очень длинных документов сначала мы используем ранее упомянутый TextSpliter Разделяйте документы на более мелкие по определенным правилам. Чанки (обычно используются RecursiveCharacterTextSplitter,нравитьсяфрукты Document структурирован, рассмотрите возможность использования указанного TextSpliter), затем выполните «цепочку карт» для каждой разделенной части, соберите выходные данные всей «цепочки карт», а затем выполните «цепочку сокращений», чтобы получить окончательный результат. summary выход.
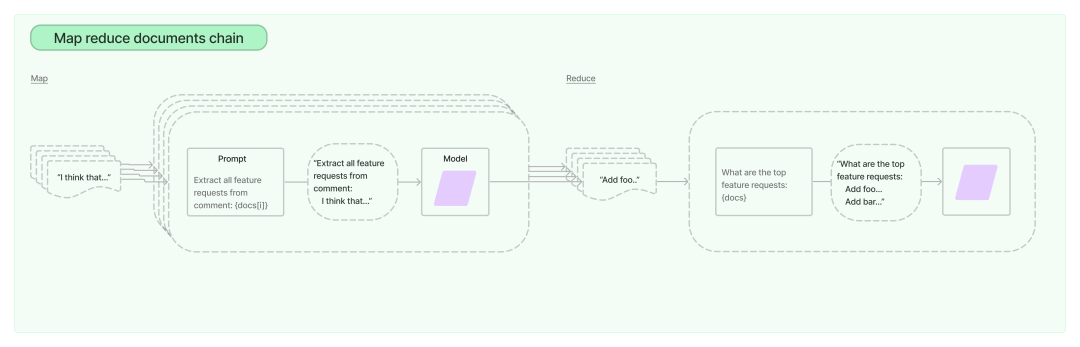
Пример использования
Вот один Router Chain вMultiPromptChainиз具体Пример:
from langchain.chains.router import MultiPromptChain
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# Определите запросы для маршрутизации
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{input}"""
# Организуйте подсказки, связанные с информацией
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template,
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template,
},
]
llm = OpenAI(temperature=0.5, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL+"/v1")
destination_chains = {}
for p_info in prompt_infos:
# Создайте для Базы цепочку назначения с каждым приглашением (включите многословие)
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
# Создайте цепочку по умолчанию. Если ни одна другая цепочка не соответствует условиям маршрутизации, будет использоваться эта цепочка.
default_chain = ConversationChain(llm=llm, output_key="text")
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
# Создайте router_prompt на основе отношения отображения Prompt_infos.
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
# Создайте router_chain (включите подробный)
router_chain = LLMRouterChain(llm_chain=LLMChain(llm=llm, prompt=router_prompt, verbose=True), verbose=True)
# Воляrouter_chainиdestination_chainsа такжеdefault_chain объединяется в MultiPromptChain (включить подробную информацию)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
# run
chain.run("What is black body radiation?")
После выполнения verbose выход日志нравиться Вниз:
Entering new chain...Prompt after formatting: Given a raw text input to a language model select the model prompt best suited for the input. You will be given the names of the available prompts and a description of what the prompt is best suited for. You may also revise the original input if you think that revising it will ultimately lead to a better response from the language model.
<< FORMATTING >> Return a markdown code snippet with a JSON object formatted to look like:
{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}
REMEMBER: "destination" MUST be one of the candidate prompt names specified below OR it can be "DEFAULT" if the input is not well suited for any of the candidate prompts. REMEMBER: "next_inputs" can just be the original input if you don't think any modifications are needed.
<< CANDIDATE PROMPTS >> physics: Good for answering questions about physics math: Good for answering math questions
<< INPUT >> What is black body radiation?
<< OUTPUT >>
Finished chain.
physics: {'input': 'What is black body radiation?'}
> Entering new chain...
Prompt after formatting:
You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know.
Here is a question: What is black body radiation?
> Finished chain.
Memory
MemoryМожет帮助Language ModelПополнить历史信息из上Вниз文,LangChainвMemoryдаодин有点模糊изтермин,Это может быть так же просто, как вспомнить сообщения, с которыми вы общались в прошлом.,Вы также можете объединить его с библиотекой векторных данных для более сложного поиска исторической информации.,Даже поддерживать связанные сущности, их отношения и конкретную информацию.,Это зависит от конкретного приложения.
Обычно Память используется для более длинных цепочек, что может в определенной степени улучшить производительность рассуждений модели.
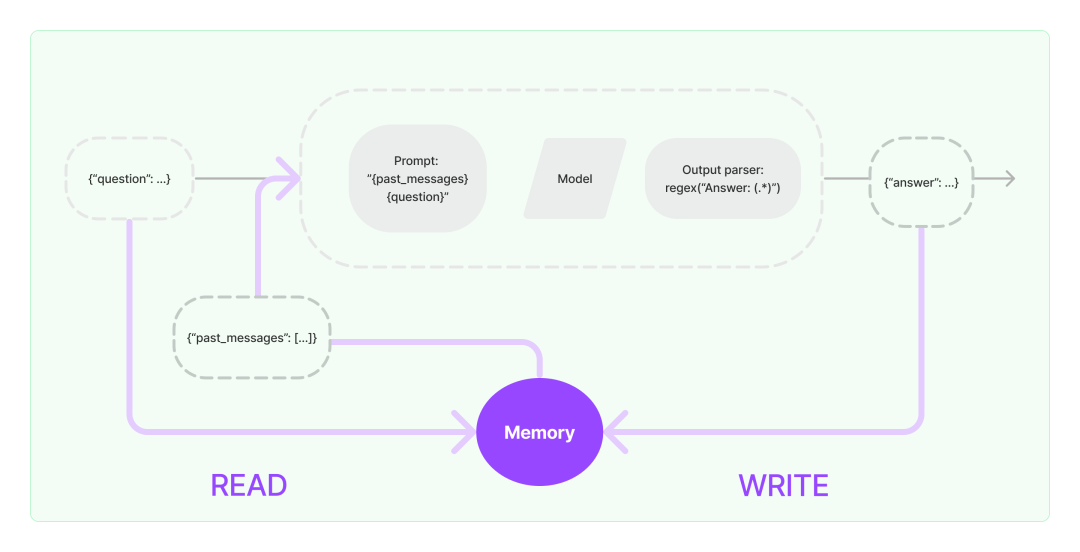
Обычно используется Memory типнравиться Вниз:
- Chat Messages Самый простой Память, Воляистория Chat Записи размещаются как дополнительная информация. prompt середина.
- Vector store-backed memory на основевекторданные Библиотекаиз Memory,Воля memory хранилищесуществоватьвекторданные Библиотекасередина,исуществовать Запрашивайте каждый раз, когда вы звонитеСамый «важный» документ Топ К. Он отличается от большинства других классов памяти тем, что не отслеживает явно порядок взаимодействий, в лучшем случае. на основе данных частичного элемента фильтровать библиотеку векторных данных из диапазона запроса
- Conversation buffer(window) memoryСохраните на определенный период временииз历史 Chat Записывать,它只использоватьПоследние K записей (сохраняется только скользящее окно недавних взаимодействий),этот样 buffer Он не станет слишком большим и не будет превышать token верхний предел.
- Conversation summary memory этот тип Memory будет следовать Chat из Создать беседу из сводки и Текущая сводка Воля сохраняется существующая Memory , для последующих разговоров history Совет такого рода; memory Схема полезна для длительных сеансов,Но часто из Подвести итоговые дайджесты будут стоить немало из token.
- Conversation Summary Buffer Memory
结合Понятно
buffer memoryиsummary memoryиз Стратегия,Некоторые наконециз все равно останутся в памяти после того, как количество чатов, записанных как буфер, и общее количество токенов в буфере достигнет заданного предела.,всем Chat запись Подвести Итог Аннотация как SystemMessage и очистить другую историю Messages;этот种 memory 方案结合Понятноbuffer memoryиsummary memoryизпреимущество,Ни часто. общее суммарное потребление токен не будет разрешен buffer Слишком много информации отсутствует。
Пример использования
Вниз面даодинConversation Summary Buffer MemoryсуществоватьConversationChainв Пример использования,包含ПонятноВосстановление оперативной памяти при переключении сеансовизметода такжеПользовательская сводная подсказкаизметод:
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI
from langchain.schema import SystemMessage, AIMessage, HumanMessage
from langchain.memory.prompt import SUMMARY_PROMPT
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL+"/v1")
# ConversationSummaryBufferMemory по умолчанию использует langchain.memory.prompt.SUMMARY_PROMPT в качестве сводки изPromptTemplate.
# Если у вас есть особые требования к его резюме по формату/содержанию, вы можете НастроитьPromptTemplate (фактическое тестовое резюме по умолчанию имеет несколько работающих учетных записей)
prompt_template_str = """
## Instruction
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new concise and detailed summary.
Don't repeat the conversation directly in the summary, extract key information instead.
## EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human inquires about the AI's opinion on artificial intelligence. The AI believes that it is a force for good as it can help humans reach their full potential.
## Current summary
{summary}
## New lines of conversation
{new_lines}
## New summary
"""
prompt = PromptTemplate(
input_variables=SUMMARY_PROMPT.input_variables, # input_variables имеет значение SUMMARY_PROMPT, а input_variables остается неизменным.
template=prompt_template_str, # шаблон заменен на переписанный выше изprompt_template_str
)
memory = ConversationSummaryBufferMemory(llm=llm, prompt=prompt, max_token_limit=60)
# Добавьте историческую память, в которой первое SystemMessage — это краткое изложение содержания исторического разговора, второе Человеческое сообщение и третье AIMessage — это окончание содержимого исторического разговора.
memory.chat_memory.add_message(SystemMessage(content="The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential. The human then asks the difference between python and golang in short. The AI responds that python is a high-level interpreted language with an emphasis on readability and code readability, while golang is a statically typed compiled language with a focus on concurrency and performance. Python is typically used for general-purpose programming, while golang is often used for building distributed systems."))
memory.chat_memory.add_user_message("Then if I want to build a distributed system, which language should I choose?")
memory.chat_memory.add_ai_message("If you want to build a distributed system, I would recommend golang as it is a statically typed compiled language that is designed to facilitate concurrency and performance.")
# Вызовите Memory.prune(), чтобы убедиться, что содержимое разговораchat_memory не превышает max_token_limit.
memory.prune()
conversation_with_summary = ConversationChain(
llm=llm,
# We set a very low max_token_limit for the purposes of testing.
memory=memory,
verbose=True,
)
# Memory.prune() будет автоматически выполняться каждый раз, когда вызывается Predict().
conversation_with_summary.predict(input="Is there any well-known distributed system built with golang?")
conversation_with_summary.predict(input="Is there a substitutes for Kubernetes in python?")
После выполнения verbose выход日志нравиться Вниз:
> Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: System: The human asks the AI about its opinion on artificial intelligence and is told that it is a force for good that can help humans reach their full potential. The human then inquires about the differences between python and golang, with the AI explaining that python is a high-level interpreted language for general-purpose programming, while golang is a statically typed compiled language often used for building distributed systems. Human: Then if I want to build a distributed system, which language should I choose? AI: If you want to build a distributed system, I would recommend golang as it is a statically typed compiled language that is designed to facilitate concurrency and performance. Human: Is there any well-known distributed system built with golang? AI: > Finished chain. > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: System: The human asks the AI about its opinion on artificial intelligence and is told that it is a force for good that can help humans reach their full potential. The human then inquires about the differences between python and golang, with the AI explaining that python is a high-level interpreted language for general-purpose programming, while golang is a statically typed compiled language designed to facilitate concurrency and performance, thus better suited for distributed systems. The AI recommends golang for building distributed systems. Human: Is there any well-known distributed system built with golang? AI: Yes, there are several well-known distributed systems built with golang. These include Kubernetes, Docker, and Consul. Human: Is there a substitutes for Kubernetes in python? AI: > Finished chain. 'Yes, there are several substitutes for Kubernetes in python. These include Dask, Apache Mesos and Marathon, and Apache Aurora.’
Agent
существовать в некоторых сценариях,я们нуждаться根据用户входить灵活地调用LLMи Другие инструменты(LangChainВоляинструментабстрактныйдля Tools этот компонент), Агент Для таких приложений предусмотрена соответствующая поддержка.
AgentМожет访问一套инструмент,и根据用户входить确定要использоватьChainилидаFunction,Мы можем просто понять, что он может динамически помогать нам выбирать и вызывать Chain или любые инструменты.
Обычно используетсяAgentтипнравиться Вниз:
Conversational Agent
Этот тип Агента может решить, использовать ли указанный Инструмент и какой Инструмент использовать, на основе выходных данных Языковой Модели (Инструмент здесь также может быть Цепочкой), а также своевременно дополнять информацию для процесса ввода-вывода Модели.
OpenAI functions Agent
Похож на диалоговый агент, но позволяет агенту дополнительно извлекать параметры указанного инструмента и т. д. и даже использовать несколько инструментов.
Plan and execute Agent
абстрактный Процесс «решения, что делать» агенту называется «планированием». what to do”и“executing the sub tasks”(этот种метод来自"Plan-and-Solve"этот一篇论文),其середина“planning what to шаг «делать» обычно полностью состоит из LLM завершено во время «выполнения the sub задач» обычно состоит из более Tools завершить.
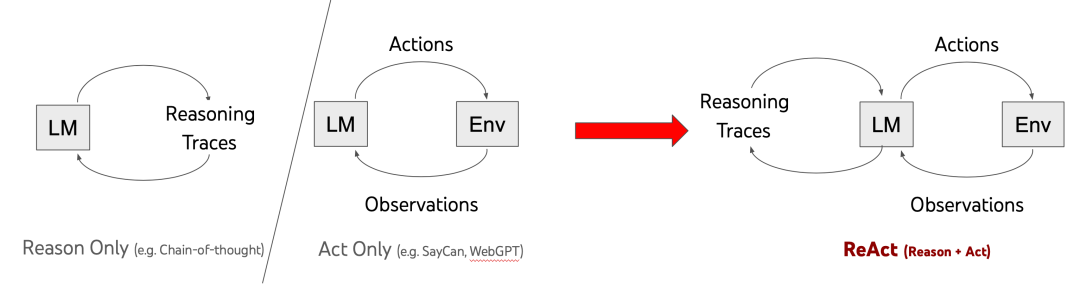
ReAct Agent
Связывающая пара LLM результат выполнения атрибуции, похожий OpenAI functions Агент предоставляет более явную структуру и методы, поддерживаемые документами.
Self ask with search
Агент этого типа будет выполнять дополнительный поиск и самопроверку с помощью LLM Output, называя себя Инструментами, а также LLM для достижения расширенного и оптимизированного вывода.
Подвести итог
LangChain в Data Connection Воля LLM Соединяйтесь со всем, дарите LangChain Создавайте приложения, которые открывают безграничные возможности, и Agent Он также обеспечивает ленивый способ «управляемой событиями» разработки, который очень распространен при разработке приложений, и оставляет работу по принятию решений ветке на усмотрение. LLM, который еще больше упрощает работу по разработке приложений в сочетании с; основевысокийабстрактныйиз Model I/O и Memory и другие компоненты, LangChain Позвольте разработчикам реализовывать быстрее, лучше и более гибко. LLM Такие приложения, как помощники и разговорные роботы, значительно сократили LLM порог использования.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
