Оптимизация производительности Apache Spark: устранение перетасовки для эффективной обработки данных
Apache Spark произвел революцию в обработке больших данных благодаря своим возможностям распределенных вычислений. Однако на производительность Spark может повлиять распространенная проблема, называемая «перетасовка». В этой статье мы рассмотрим, что такое перемешивание, его причины, проблемы, связанные с ним, а также эффективные решения для оптимизации производительности Apache Spark.
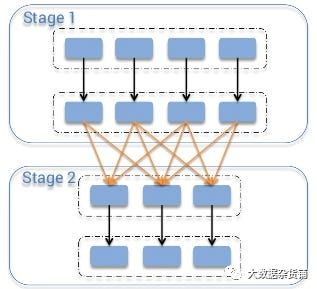
Иллюстрация: операция перемешивания
1. Понимание перемешивания
Под перемешиванием понимается процесс перераспределения данных по разделам в Apache Spark. Это побочный эффект обширных преобразований, таких как операции группировки, различения, упорядочения и объединения. Во время перераспределения данные обмениваются и реорганизуются по сети, чтобы гарантировать группировку записей с одинаковым ключом.
2. Причины перетасовки
Перетасовка в первую очередь вызвана операциями, требующими реорганизации данных по разделам. Широкая трансформация предполагает агрегацию или объединение данных из нескольких разделов, что требует перемещения и реорганизации данных по кластеру. Например, операции соединения требуют сопоставления и объединения данных из разных наборов данных, что приводит к значительному перемешиванию.
3. Проблемы, связанные с перемешиванием
Shuffle может вызвать несколько проблем с производительностью, которые влияют на эффективность и скорость заданий Spark:
- Увеличение сетевого ввода-вывода. Операции перемешивания включают обмен и передачу данных по сети, что приводит к увеличению накладных расходов на сетевой ввод-вывод (I/O). Увеличение объема данных в случайном порядке приводит к перегрузке сетевых ресурсов, что приводит к замедлению времени выполнения и снижению общей пропускной способности.
- Ресурсоемкость: Shuffle требует дополнительных вычислительных ресурсов, включая процессор, память и дисковый ввод-вывод. Повышенное использование ресурсов во время тасования может привести к конкуренции за ресурсы, увеличению времени выполнения заданий и снижению эффективности.
4. Решения, позволяющие избежать перетасовки
Чтобы оптимизировать производительность Apache Spark и смягчить влияние перемешивания, можно использовать несколько стратегий:
- Уменьшите сеть Ввод-вывод: используя меньшее количество и более крупных рабочих узлов, его можно уменьшить перемешивание сети во время объема ввода-вывода. Узлы большего размера позволяют обрабатывать больше данных локально, сводя к минимуму необходимость передачи данных по сети. Этот подход может повысить производительность за счет уменьшения задержек, связанных с сетевой связью.
- Уменьшите количество столбцов и отфильтруйте строки. Уменьшение количества перетасовываемых столбцов и фильтрация ненужных строк перед перетасовкой могут значительно сократить объем передаваемых данных. Устраняя ненужные данные на ранних стадиях конвейера, вы минимизируете влияние перестановок и повышаете общую производительность.
- Использовать широковещательное хэш-соединение. Широковещательное хэш-соединение — это метод, который передает меньший набор данных операции соединения всем рабочим узлам.,Тем самым уменьшая необходимость в перемешивании. Этот подход использует копирование в памяти и устраняет нагрузку на сеть, связанную с перетасовкой.,Тем самым улучшая производительность соединения.
- Используйте технологию сегментирования. Бактинг — это технология, которая организует данные в сегменты на основе хеш-функций. Предварительно разбивая и сохраняя данные в сегментах, Spark избавляет от необходимости перемешать. Эта технология оптимизации уменьшает перемещение данных между разделами, тем самым сокращая время выполнения.
5. Заключение
Перетасовка (процесс перераспределения данных по разделам) — распространенная проблема с производительностью в Apache Spark. Это может привести к увеличению количества операций ввода-вывода в сети, конкуренции за ресурсы и замедлению выполнения заданий. Однако влияние тасования можно смягчить, используя такие стратегии, как сокращение сетевого ввода-вывода, сокращение столбцов и фильтрация строк для минимизации размера данных, использование широковещательных хеш-соединений и использование методов группирования. Эти методы оптимизации повышают производительность Apache Spark, обеспечивая эффективную обработку данных и более быстрый анализ. Раскройте весь потенциал Apache Spark, решая проблемы, связанные с перемешиванием, и оптимизируя конвейеры обработки данных.
Автор оригинала: VivekR



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
