OpenVINO и TensorRT используют обнаружение объектов YOLOv10
Экспорт модели, ввод и вывод
Скрипт экспорта ONNX модели YOLOv10 выглядит следующим образом:
from ultralytics import YOLOv10
"""Test exporting the YOLO model to ONNX format."""
f = YOLOv10("yolov10n.pt").export(format="onnx", opset=11, dynamic=False)Если вы не укажете opset=11 или 12, модель, экспортированная по умолчанию opset=10, будет очень медленной во время вывода. После указания opset=11 структура экспортированной модели будет следующей:
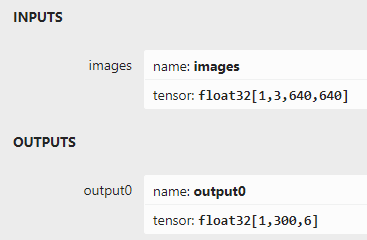
Ниже описаны форматы ввода и вывода:
Поддерживаемый формат ввода: 1x3x640x640.
Выходной формат: 1x300x6.Выходной формат 300 относится к числу выходных блоков предсказания, 6 соответственно.
x1 y1 x2 y2 score classidрассуждения на С++
Вывод OpenVINO2023 C++,Нашёл большую ОШИБКУ,То есть при использовании режима АВТО:
ov::CompiledModel compiled_model = ie.compile_model("D:/python/yolov10-1.0/yolov10n.onnx", "AUTO");
auto infer_request = compiled_model.create_infer_request();Модельное рассуждение приведет к неупорядоченным результатам видеорассуждения, как показано ниже:

Но когда я настраиваю устройство вывода на процессор, оно работает очень стабильно. Это показывает, что поддержка виртуального устройства вывода OpenVINO AUTO для YOLOv10 нуждается в улучшении.

Преобразуйте модель формата ONNX в файл ядра с помощью следующей командной строки
trtexec.exe -onnx=yolov10n.onnx --saveEngine=yolov10n.engineTensorRT8.6 C++ Демонстрация рассуждений , личный блокнот Видеокарта 3050ti.


рассуждения на Соответствующий код для С++ выглядит следующим образом:
int64 start = cv::getTickCount();
// предварительная обработка изображений - Операция форматирования
int w = frame.cols;
int h = frame.rows;
int _max = std::max(h, w);
cv::Mat image = cv::Mat::zeros(cv::Size(_max, _max), CV_8UC3);
cv::Rect roi(0, 0, w, h);
frame.copyTo(image(roi));
// HWC => CHW
float x_factor = image.cols / static_cast<float>(input_w);
float y_factor = image.rows / static_cast<float>(input_h);
cv::Mat tensor = cv::dnn::blobFromImage(image, 1.0f / 225.f, cv::Size(input_w, input_h), cv::Scalar(), true);
// Память в память графического процессора
cudaMemcpyAsync(buffers[0], tensor.ptr<float>(), input_h * input_w * 3 * sizeof(float), cudaMemcpyHostToDevice, stream);
// рассуждение
context->enqueueV2(buffers, stream, nullptr);
// Память GPU в Память
cudaMemcpyAsync(prob.data(), buffers[1], output_h *output_w * sizeof(float), cudaMemcpyDeviceToHost, stream);
// Постобработка
cv::Mat det_output(output_h, output_w, CV_32F, (float*)prob.data());
for (int i = 0; i < det_output.rows; i++) {
float tl_x = det_output.at<float>(i, 0) * x_factor;
float tl_y = det_output.at<float>(i, 1) * y_factor;
float br_x = det_output.at<float>(i, 2)* x_factor;
float br_y = det_output.at<float>(i, 3)* y_factor;
float score = det_output.at<float>(i, 4);
int class_id = static_cast<int>(det_output.at<float>(i, 5));
if (score > 0.25) {
cv::Rect box((int)tl_x, (int)tl_y, (int)(br_x - tl_x), (int)(br_y - tl_y));
rectangle(frame, box, cv::Scalar(0, 0, 255), 2, 8, 0);
putText(frame, cv::format("%s %.2f",classNames[class_id], score), cv::Point(box.tl().x, box.tl().y-5), fontface, fontScale, cv::Scalar(255, 0, 255), thickness, 8);
}
}
float t = (cv::getTickCount() - start) / static_cast<float>(cv::getTickFrequency());
putText(frame, cv::format("FPS: %.2f", 1.0 / t), cv::Point(20, 40), cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
cv::imshow("YOLOv10objectDetection + TensorRT8.6", frame);Сравнивая эквивалентные модели YOLOv5 и YOLOv8, скорость по-прежнему очень высокая. Единственное, что меня не очень устраивает, это то, что способность обнаружения небольших целей не так хороша, как у YOLOv5 и YOLOv8. Это всего лишь личное ощущение.
Освоить развертывание модели глубокого обучения
Освойте три основных направления глубоко Платформа обучения Модельразвертывания позволяет модели максимально ускорить процесс распределения на аппаратном обеспечении различных платформ, таких как ЦП, графический процессор и AMD. Академия OpenCVУже запущенДорожная карта систематического обучения по развертыванию глубокого обучения OpenVINO, TensorRT, ONNXRUNTIME。«Если рабочий хочет хорошо выполнять свою работу, он должен сначала заточить свои инструменты».,Быть инженером глубокого обучения,После изучения развернуть, потом работать,Все приходит вовремя,Это хорошее время, чтобы начать!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
