OpenAI Sora Реальность создания 1-минутного видео больше не существует!
Предисловие:
We’re teaching AI to understand and simulate the physical world in motion, with the goal of training models that help people solve problems that require real-world interaction.
Introducing Sora, our text-to-video model. Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt.
Мы учим искусственный интеллект понимать и моделировать физический мир в движении с целью обучения моделей, которые помогут людям решать проблемы, требующие взаимодействия в реальном мире.
Представляем Sora, нашу модель текстового видео. Sora может создавать видеоролики продолжительностью до минуты, сохраняя при этом визуальное качество и следуя подсказкам пользователя.
Сегодня красные команды могут использовать Sora для оценки опасностей или рисков в критических областях. Мы также предоставили доступ ряду художников, дизайнеров и кинематографистов, чтобы получить отзывы о том, как улучшить модель, чтобы сделать ее максимально полезной для творческих профессионалов.
Мы будем делиться результатами наших исследований как можно раньше, чтобы начать работать и получать отзывы от людей, не входящих в OpenAI, а также информировать общественность о будущем ИИ.
Делюсь каталогом в этом выпуске
1. Принцип работы Сора
2.Сценарии применения Сора
3. Тенденции технологических изменений под руководством Стабильная диффузия в оттенках серого 3 Сравнение бумаги
Официальный адрес сайта
Официальные технические документы
https://openai.com/research/video-generation-models-as-world-simulators
Официальная видеоколлекция
https://cloud.tencent.com/developer/video/79994


В 2 часа ночи 16 февраля различные группы внезапно взорвались. Openai выпустила Sora, которая может генерировать длинное видео 60S без мерцания. Моменты друзей заполонили экран. Реальности больше не существует.
На самом деле, независимо от того, выпущена «Сора» или нет, в настоящее время существует множество творческих короткометражных и художественных фильмов с искусственным интеллектом стоимостью в миллионы долларов. Благодаря редактированию и дубляжу можно добиться того же эффекта, что и у короткометражных фильмов и блокбастеров. нужно то же самое: творчество.
Некоторые люди говорят, что творческий ИИ также может генерировать...
На вчерашнем обсуждении Соры все большие парни также поделились своими мыслями о нынешнем выпуске Соры. Некоторые считали, что это нанесло серьезный ущерб кино- и телеиндустрии, но оно также открыло новые возможности, снизило затраты и повысило эффективность...

1. Принцип работы Сора
1. Почему ее называют Моделью Мира?
В большом количестве официальных и внутренних бета-видео Sora мы видим больше движений камеры, что соответствует законам физики, например, черепаха, идущая по пляжу, толкающая песок ногами, создающая ощущение гравитации и покидающая пляж. След на пляже. Другой пример: дама в темных очках. В черной куртке и красной юбке иду по шумным улицам Японии. Ночью улицы мокрые от дождя, неоновые огни, маршрут, по которому идет персонаж, и переход «зебра» отражаются на солнцезащитных очках при переключении. вид крупным планом. Все это отражается. Сора соответствует законам физики.

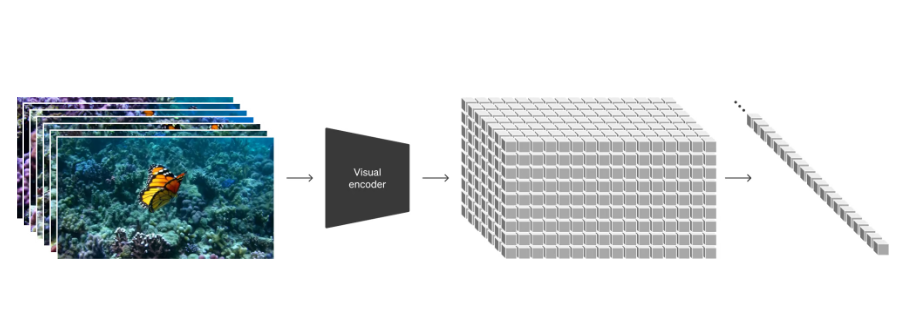
Технология реализации демонтажа
Входное видео рассматривается как матрица HxW, состоящая из N кадров изображений, которые сегментируются на пространственно-временные фрагменты с помощью кодировщика. Эти сегменты затем преобразуются в одномерные векторы и вводятся в диффузионную модель. Согласно информации OpenAI, этот кодировщик может представлять собой преобразователь видео (Video Transformer), который делит видео на несколько кортежей (tuplets), и каждый кортеж преобразуется в токен. Эти токены обрабатываются с помощью механизма пространственно-временного внимания для захвата пространственных и временных характеристик видео, тем самым генерируя эффективные токены представления видео, как показано серыми квадратами на рисунке.

Video generation models as world simulators
Мы исследуем масштабное обучение генеративных моделей на видеоданных. В частности, мы совместно обучаем модель условной диффузии текста на видео и изображениях разной длительности, разрешения и соотношения сторон. Мы используем архитектуру преобразователя, которая работает с пространственно-временными сегментами скрытых кодов видео и изображений. Наша самая крупная модель Sora способна создавать высококачественные одноминутные видеоролики. Наши результаты показывают, что расширение видеогенеративных моделей — это реальный путь к созданию общих симуляторов физического мира.
Рабочая технология Sora основана на нескольких ключевых компонентах, которые вместе позволяют Sora генерировать высококачественный видеоконтент. Ниже приведены основные части технических принципов Соры:
- Единое представление визуальных данных:
- Сора преобразует данные видео и изображений в пространственные и временные патчи (патчи).,Эти блоки аналогичны текстовым токенам в моделях большого языка (LLM). Этот метод представления позволяет модели обрабатывать визуальные данные различного разрешения, длительности, пропорций и размеров.
- сеть сжатия видео:
- Сора использует сеть для уменьшения размерности визуальных данных,Эта сеть сжимает исходный видеовход в низкомерное скрытое пространство.,Сжатие во времени и пространстве одновременно. так,Сора при создании видео,Все они выполняются внутри этого сжатого потенциального пространства.
- потенциальный блок пространства-времени:
- Извлеките последовательность пространственно-временных фрагментов из сжатого входного видео.,Эти блоки маркируются как трансформаторы. Такое блочное представление позволяет обучать Sora генерировать видеоизображения с переменным разрешением, длительностью и соотношением сторон.
- диффузионная модель:
- Сора диффузионная модель,Он принимает входные блоки с шумом,и обучены предсказывать исходные блоки из «чистых». Этот процесс включает постепенное восстановление четких изображений или видеокадров от шума.
- Архитектура преобразователя:
- Soraиспользовать Архитектура преобразователя для обработки блоков пространства-времени. Трансформеры продемонстрировали значительную масштабируемость во многих областях, таких как языковое моделирование, компьютерное зрение и генерация изображений. В этой работе исследователи обнаружили, что диффузионные преобразователи одинаково эффективны в видеомоделях.
- Генерация текста в видео:
- Сора может создавать видео на основе текстовых подсказок. Для этого требуется большой объем видеоданных с соответствующими текстовыми титрами. Исследователи применили DALL·E Техника повторных титров, представленная в разделе 3, сначала обучает модель создания наглядных подписей, а затем использует ее для создания текстовых подписей для всех видео в обучающем наборе.
- Возможности редактирования изображений и видео:
- Сора может генерировать больше, чем просто видео с помощью текстовых подсказок,Видео также можно создавать из существующих изображений или видео в качестве входных данных. Это позволяет Sora выполнять широкий спектр задач по редактированию изображений и видео.,Например, создание идеального цикла из видео, анимированных неподвижные изображения、Развернуть видео вперед или назад и т. д.
- Возможности моделирования:
- При обучении в больших масштабах,Видеомодель демонстрирует некоторые интересные и новые возможности.,Например, согласованность 3D, согласованность на больших расстояниях и постоянство объектов. Сора иногда может имитировать простые действия, влияющие на состояние мира.,Например, оставляя стойкие мазки на холсте.,Или смоделировать цифровой мир,Как видеоигры.
Вместе эти технические принципы составляют основу Sora, позволяющую создавать высококачественный видеоконтент и в определенной степени моделировать объекты, животных и людей в физическом и цифровом мирах.
Модель Сора — это общая модель визуальных данных, способная генерировать видео и изображения различной длительности, соотношений сторон и разрешений, вплоть до одной минуты видео высокой четкости. Исследователи черпают вдохновение в крупномасштабных языковых моделях, которые достигают общих возможностей за счет обучения на данных в масштабах Интернета. Модель Сора использует визуальные пятна в качестве «текстовых маркеров», которые являются эффективным представлением видеоданных.
Sora — это диффузионная модель, которая принимает зашумленные входные патчи (а также условную информацию, такую как текстовые сигналы) и обучена прогнозировать исходные «чистые» патчи. В процессе обучения Соры по мере увеличения объема обучающих вычислений качество выборки значительно улучшается.
Модель Сора также демонстрирует некоторые интересные новые возможности, такие как согласованность 3D, согласованность на больших расстояниях и устойчивость объектов, а также способность взаимодействовать с миром. Например, Сора может имитировать художника, оставляющего на холсте стойкие мазки, или человека, который ест гамбургер и оставляет следы от укусов. Сора также может моделировать цифровые миры, например одновременно управлять игроками в Minecraft и визуализировать мир и его динамику с высокой точностью.
Хотя Сора добилась прогресса в моделировании, у нее все еще есть много ограничений, таких как неспособность точно моделировать физику многих основных взаимодействий, таких как разбитие стекла. В документе также приводятся другие распространенные способы отказа моделей, такие как несоответствия или спонтанное появление объектов на длинных выборках.
Авторы полагают, что возможности, продемонстрированные Сорой на данный момент, указывают на то, что дальнейшее расширение видеомоделей является многообещающим путем к разработке симуляторов физического и цифрового мира, которые смогут моделировать объекты, животных и людей внутри них.
2.Сценарии применения Сора
Взгляды Чжоу Хунъи на Сору
Если вы говорите приезжатьаудио видеоиз Сценарии Если предположить, что продолжительность обычного фильма составляет 120 минут, то теоретически мы можем отладить 120 видеороликов Сора, чтобы сформировать красивый фильм, включая спецэффекты, сценарии и раскадровки. Прежде чем Сора, давайте посмотрим на другие продукты в той же категории, будь то Runway. , пищуха и Gen2 обычно генерируют 4 и 12.
Длина видео около 100%, а управляемость не очень хорошая. Хотя Animatediff может создавать длинные видеоролики, он слишком сильно полагается на видеопамять, и управляемость по-прежнему неудовлетворительна даже в V3. По сравнению с этим именно в этом причина. Сора ниспровергает мир.
Закрытие кино- и телекомпаний связано скорее с режиссерскими доработками и неоднократными переделками.
Экология этой отрасли претерпит большие изменения и позже может стать сферой услуг.
Фабрика кинопроизводства, киноцех. Мудрый человек никогда не умрет с голоду.
Занимайтесь концептуальными и творческими отвлечениями, а также мобилизацией эмоций. Эта точка зрения очень интересна и ее стоит практиковать.
Во-первых, это подрыв процесса производства фильмов и телевидения. Креативные директора (которые впервые использовали ИИ) делают это ради вдохновения и снижения затрат на коммуникацию. В будущем инструменты ИИ определенно будут использоваться.
Сократит затраты.
Меня не особенно беспокоит то, что ИИ заменит кинопроизводство. Sora особенно дружелюбен к сценаристам, поскольку его можно использовать для визуализации некоторых сцен в видео. Это улучшит визуальную эстетику каждого и вызовет эстетическую усталость от особенно красивых вещей, поэтому требования к способности рассказывать истории возросли. --Ли Дундун/Директор-компьютерщик
Когда снимаешь фильмы, не имеющие ничего общего с реальностью, восприятие тем научной фантастики/фэнтези не так однозначно. До Соры основное внимание уделялось этим двум областям.
Что меня больше всего волнует, так это функция видео в видео. Взяв несколько классических клипов, если они являются тем, что я хочу сделать, посредством передачи видео, при условии контроля последовательности и стабильности, можно создать множество работ. (стоит потренироваться)
Первый повод для беспокойства заключается в том, что в короткометражном фильме есть метавселенная, и другие методы могут помочь нам завершить ее. Наша способность контролировать текущую сцену — основа помощи режиссеру в творчестве. --Сяньрен Икунь
Технических проблем нет, играю в AI уже давно. Я не буду сейчас говорить о вопросе снижения затрат. Я хочу спросить у всех, заработал ли кто-нибудь больше денег с помощью ИИ. Если никто не вкладывает деньги, то какой смысл в таком сокращении затрат? не сделает каждого Каждый становится творцом, но творчество увеличится в размерах.
Я считаю, что красные и белые таблетки в определенной степени эволюционировали. Почему VR и ИИ развиваются одновременно? Видео настолько дешевое, что партии А больше не существует. Эл перешел на более высокую перспективу, основанную на 3D, чтобы создавать истории непосредственно в виртуальной реальности. Не смотрите видео ради дальнейшего развития. VR реорганизует и генерирует медиа-нарративы, как фильмы. Лет 7-8 назад я перестал учиться моделированию и перестал заниматься этими трёхмерными вещами, потому что рано или поздно меня бы заменили.
Синяя таблетка — вернуться в реальность, организовать цифровые культурные реликвии, а существующие вещи станут цифровыми якорями. Я быстро собрал цифровые активы 2-3 года назад. Конечно, сейчас уже немного поздно это делать.
Вам нужно обновить видео до чего-то с более высоким лерфом. Традиционная индустрия, а также кино- и телеиндустрия пострадают.
Когда впервые появился рисунок Ала, все говорили, что живопись будет жить вечно, но в реальной жизни она не имеет никакого влияния. Конечно, средства массовой информации не будут создаваться так быстро.
С другой стороны, «хомяк» цифровых активов — это цифровые активы реального мира. Потому что в будущем эти вещи перестанут иметь ценность. В будущем реальные вещи будут стоить дороже. --Контоев
3. Тенденции технологических изменений под руководством Соры
Тенденция технологических изменений, возглавляемая Сорой, должна упомянуть Stablediffusion3, который также очень популярен в данный момент. Это не потому, что эти два продукта находятся в одном и том же направлении, а потому, что они реализованы в одной и той же архитектуре. выпущен, подтверждено, архитектура Stablediffusion3 и Sora согласована.

16 февраля, с выпуском крупнейшей в мире модели OpenAI Sora, компания Stability_ai также выпустила свою последнюю модель Stablediffusion3. Если одно из них — направление аудио и видео, а другое — направление генерации изображений, то они не обязательно связаны, но Sora. и Stablediffusion3. Архитектура на удивление согласована, а основная часть использует метод Difusion Transformer (называемый DiT в Stablediffusion3).

Сегодня мы публикуем исследовательскую работу, в которой подробно рассматривается технология, лежащая в основе Stable Diffusion 3.
Основываясь на оценках человеческих предпочтений, Stable Diffusion 3 превосходит современные системы генерации текста в изображения, такие как DALL-E 3, Midjourney v6 и Ideogram v1, с точки зрения типографики и своевременности.
Наша новая архитектура мультимодального диффузионного преобразователя (MMDiT) использует отдельные наборы весов для представления изображения и языка, улучшая понимание текста и возможности правописания по сравнению с предыдущими версиями SD3.

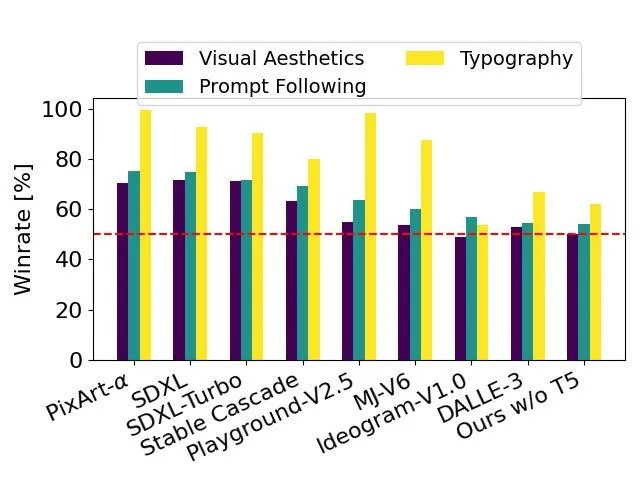
Мы сравниваем выходные изображения Stable Diffusion 3 с различными другими открытыми моделями, включая SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 и Pixart-α, а также с системами с закрытым исходным кодом, такими как DALL-E 3, Midjourney v6 и Идеограмма v1) сравнивалась для оценки производительности на основе отзывов людей. В этих тестах оценщикам были предоставлены примеры выходных данных каждой модели и предложено оценить, насколько точно выходные данные модели соответствуют контексту заданной подсказки («следуйте подсказке») и насколько хорошо она отображает текст на основе подсказки (). «Типографика») и какое изображение имеет более высокое эстетическое качество («Визуальная эстетика»), чтобы выбрать лучший результат.

Prompt: A surreal and humorous scene in a classroom with thewords 'GPUs go brrrrrr' written in white chalk on a blackboard. IIn
front of the blackboard, a group of students are celebrating. Theese students are uniquely depicted as avocados, complete with
little arms and legs, and faces showing expressions of joy and excitement. The scene captures a playful and imaginative
atmosphere, blending the concept of a traditional classroom witth the whimsical portrayal of avocado students
переводить:
Сюрреалистическая и юмористическая сцена в классе с надписью «GPUs go brrrrr», написанной белым мелом на доске. IIIn
Перед доской празднует группа студентов. Этих студентов уникально изображают как авокадо.
Маленькие ручки и ножки, с выражением радости и волнения на лице. Эта сцена представляет собой веселую и творческую
атмосфера, сочетающая концепции традиционных классов с причудливыми образами учеников Авокадо.
Основываясь на результатах тестирования, мы обнаружили, что Stable Diffusion 3 находится на одном уровне с современными системами генерации текста в изображения или превосходит их по всем аспектам, упомянутым выше.
В ходе раннего неоптимизированного тестирования вывода на потребительском оборудовании нашей самой большой модели SD3 с 8 битами параметров, которая помещалась в 24 ГБ видеопамяти RTX 4090, потребовалось 34 секунды для создания изображения с разрешением 1024x1024 с использованием 50 выборочных шагов. Кроме того, в первом выпуске Stable Dispersion 3 будет доступен в нескольких вариантах, от параметрических моделей от 800 м до 8B, чтобы еще больше устранить аппаратные барьеры.
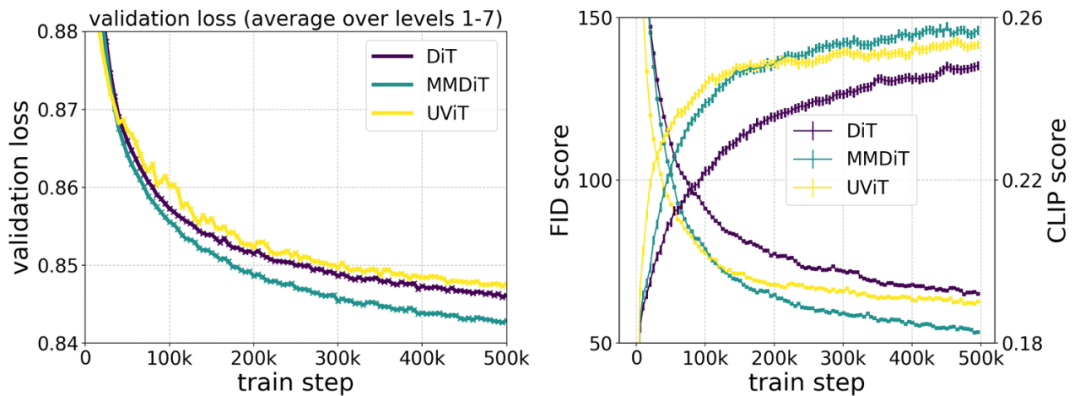
Наша новая архитектура MMDiT превосходит традиционные магистральные сети преобразования текста в изображение, такие как UViT (Hoogeboom et al., 2023) и DiT (Peebles and Xie, 2023), при измерении визуальной точности и выравнивания текста во время обучения.

Благодаря улучшенному отслеживанию сигналов в Stable Diffusion 3 наша модель способна создавать изображения, фокусирующиеся на различных темах и качествах, а также обладая при этом высокой гибкостью в стиле самого изображения.
картина

Prompt: Translucent pig, inside is a smaller pig.
Полупрозрачная свинья со свиньей поменьше внутри.
Prompt: A massive alien space ship that is shaped like a pretzel.
Гигантский космический корабль пришельцев в форме кренделя.
Сравнение производительности
Мы сравниваем выходные изображения Stable Diffusion 3 с различными другими открытыми моделями, включая SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 и Pixart-α, а также с системами с закрытым исходным кодом, такими как DALL-E 3, Midjourney v6 и Идеограмма v1) сравнивалась для оценки производительности на основе отзывов людей. В этих тестах оценщикам были предоставлены примеры выходных данных каждой модели и предложено оценить, насколько точно выходные данные модели соответствуют контексту заданной подсказки («следуйте подсказке») и насколько хорошо она отображает текст на основе подсказки (). «Типографика») и какое изображение имеет более высокое эстетическое качество («Визуальная эстетика»), чтобы выбрать лучший результат.
Основываясь на результатах тестирования, мы обнаружили, что Stable Diffusion 3 находится на одном уровне с современными системами генерации текста в изображения или превосходит их по всем аспектам, упомянутым выше.
В ходе раннего неоптимизированного тестирования вывода на потребительском оборудовании нашей самой большой модели SD3 с 8 битами параметров, которая помещалась в 24 ГБ видеопамяти RTX 4090, потребовалось 34 секунды для создания изображения с разрешением 1024x1024 с использованием 50 выборочных шагов. Кроме того, в первом выпуске Stable Diffusion 3 будет доступен в нескольких вариантах, от параметрических моделей от 800 м до 8B, чтобы еще больше устранить аппаратные барьеры.
Архитектурные детали
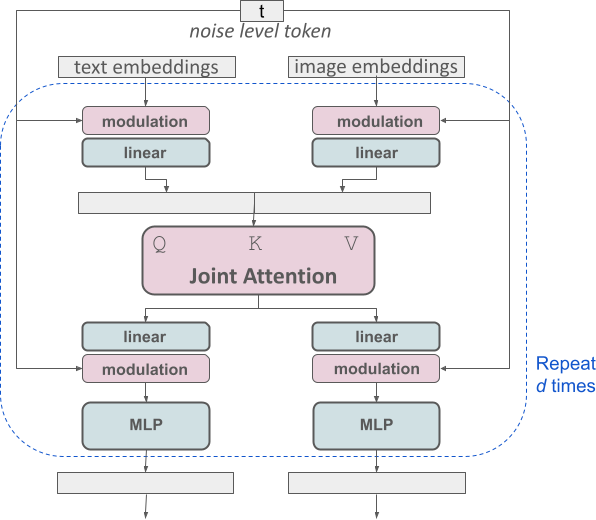
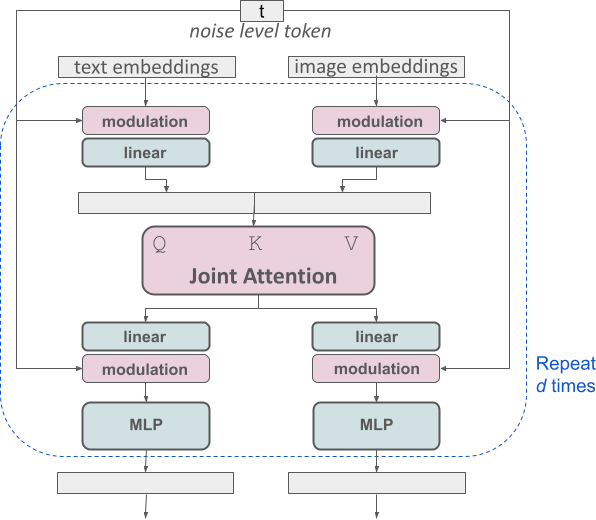
Для текста приехать изображение создано,Наша модель должна учитывать как текстовый, так и графический режимы. поэтому,Мы называем эту новую архитектуру MMDiT. означает его способность работать с несколькими режимами. Как и в предыдущих версиях стабильной диффузии, мы используем предварительно обученные модели для получения соответствующих представлений текста и изображений. В частности, мы используем три разные модели встраивания текста — две CLIP Модель и T5 — для кодирования текстовых представлений и использования улучшенной модели автоматического кодирования для кодирования тегов изображений.
SD3 Архитектура на основе диффузионного преобразователя («Ди Т», Peebles). & Xie,2023). Поскольку встраивание текста и встраивание изображений концептуально сильно различаются.,Поэтому мы используем два разных набора весов для двух режимов. Как показано на картинке выше,Это эквивалентно установке двух независимых трансформаторов для каждой модальности.,Но объединение двух модальных последовательностей для операций внимания,Таким образом, оба представления могут работать в своих соответствующих пространствах.,Также примите во внимание другой вид пространства.
картина
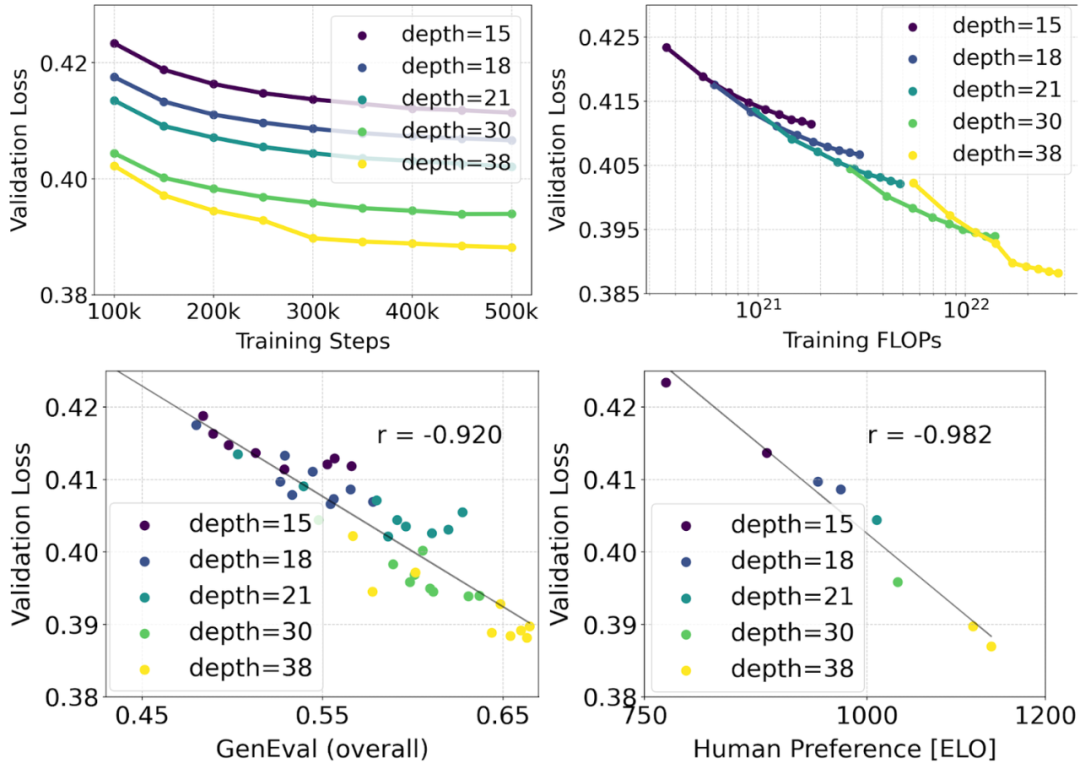
Используем перевзвешенную формулу ректификации MMDiT Backbone обеспечивает расширенные исследования в области синтеза текста в изображение. Модель, которую мы обучили, начинается с 450M параметры 15 плитка с 8B параметры 38 плитка различается,Обратите внимание, что потери при проверке плавно уменьшаются по мере увеличения размера модели и шагов обучения (верхний ряд). Чтобы проверить, приводит ли это к значимым улучшениям результатов модели.,Мы также оцениваем метрику автоматической регистрации изображений (GenEval) и оценку предпочтений человека (ELO) (нижний ряд). Наши результаты показывают, что,Существует сильная корреляция между этими метриками и потерями при проверке.,Это говорит о том, что последний может хорошо предсказывать Модель из Общая производительность. также,Тенденции Zoom не показывают признаков насыщения,Это вселяет в нас оптимизм в отношении дальнейшего улучшения производительности модели в будущем.
Поскольку исходная статья была слишком большой, я воспользовался услугами Кими, чтобы обобщить ее.
Название этой статьи — «Масштабирование выпрямленных трансформаторов потока для синтеза изображений высокого разрешения», а авторы — несколько исследователей из Stability AI. В статье в основном изучается, как обучить модель Rectified Flow путем улучшения существующей технологии дискретизации шума для достижения более высокой производительности при синтезе изображений с высоким разрешением. Ниже приводится обзор содержания статьи:
Абстрактный:
диффузионная модель создает данные, изменяя их прямой путь в сторону шума.,Стал мощной технологией генеративного моделирования.,Подходит для многомерных перцептивных данных, таких как изображения и видео.
Rectified Flow — новый тип генеративной модели.,Он соединяет данные и шум в прямую линию. Хотя теоретически превосходит,Но это еще не стало стандартной практикой на практике.
Это исследование улучшает метод обучения моделей выпрямленного потока за счет смещения методов выборки шума в воспринимаемых масштабах и демонстрирует превосходную производительность этого метода при синтезе текста в изображение с высоким разрешением.
Автор предлагает новую архитектуру на базе Transformerиз.,Для текста приехать изображение из генерации,В архитектуре используются независимые веса для обеих модальностей (изображение и текст).,и включить двунаправленный поток информации между изображением и текстовой разметкой,Улучшено понимание текста, форматирование и оценка человеческих предпочтений.
благодаря масштабным исследованиям,Авторы демонстрируют, что эта архитектура следует предсказуемым тенденциям масштабирования.,Более низкие потери при проверке тесно связаны с улучшением производительности синтеза изображений, измеряемой различными показателями и человеческой оценкой.
Введение:
диффузионная модель Обратный путь данных к случайному шуму посредством обучения,В сочетании с нейронной сетью со свойствами аппроксимации и обобщения,Могут быть созданы новые точки данных.
диффузионная модель стала де-факто методом создания изображений и видео высокого разрешения на основе естественного языка.
Чтобы улучшить эти Модель изэффективность обученияи/Или ускорить выборку,Исследователи изучили более эффективные формулы тренировок.
Обучение потоков без моделирования:
Авторы рассматривают генеративные модели, которые определяют отображения распределений шума в распределения данных, выраженные в форме обыкновенных дифференциальных уравнений (ОДУ).
с целью повышения эффективности,Автор предложил прямую регрессию векторного поля,Это векторное поле генерирует вероятностный путь между p0 и p1.
Траектории потока выпрямленного потока:
Авторы рассмотрели различные варианты траектории течения, в том числе Ректифицированный. Flow、EDM、Cosineи(LDM-)Linear。
Архитектура преобразования текста в изображение:
Для обработки условной выборки текстового изображения,Модель должна учитывать модальности как текста, так и изображения. Автор использовал предварительно обученную модель для получения подходящего представления.,и описывает основу распространения архитектуры.
Эксперименты:
Автор провел масштабное исследование,Сравнил различияиздиффузионная модельиRectified Формула потока и демонстрирует преимущества новой формулы.
Улучшив автокодировщик, улучшив заголовок и улучшив текст, можно получить основу изображения.,Автор улучшил Модель изпроизводительность。
Заключение:
Это исследование демонстрирует потенциал модели Rectified Flow в синтезе текста в изображение и предлагает новый метод выборки с временным шагом, который повышает производительность.
Автор также продемонстрировал преимущества архитектуры MM-DiT на основе Transformer и провел исследование масштабирования модели, доказав, что уменьшение потерь при проверке тесно связано с улучшением производительности модели.
Основные вклады этой статьи включают в себя:
к разнымдиффузионная модельиRectified Flow Formula провела крупномасштабные систематические исследования для определения оптимальных настроек.
Разработана новая масштабируемая архитектура синтеза изображений, которая обеспечивает двунаправленное смешивание потоков разметки текста и изображений внутри сети.
На модели было проведено исследование масштабирования, которое продемонстрировало предсказуемые тенденции масштабирования.
При синтезе изображений высокого разрешения используется MM-DiT (мультимодальный режим) на основе трансформатора. Diffusion Transformer) архитектура предназначена для обработки двух модальностей текста и изображений. Основная идея архитектуры MM-DiT заключается в использовании сети Transformer для одновременной обработки текстовой и графической информации, а также улучшения понимания текста, набора текста и оценки человеческих предпочтений посредством двустороннего потока информации. Ниже приведен пример архитектуры MM-DiT. работы:
Подведите итог:
Сора пришла, будущее наступило, Сора не так страшна, как представляли, замените это, замените то, ведь неважно, до выхода Соры или после, есть много прекрасных творцов, которые уже выпустили качественные произведения В финале. анализ, он по-прежнему является инструментом, вспомогательным инструментом для людей, позволяющим повысить эффективность работы,




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
