OFC2024: Оптическое соединение, управляемое искусственным интеллектом
На конференции OFC в этом году было проведено множество докладов и семинаров, посвященных спросу на оптическое соединение в условиях бума искусственного интеллекта и машинного обучения. Вот краткое изложение соответствующей информации для вашей справки.
Производительность вычислительных чипов увеличивается примерно в 3,3 раза каждые два года, пропускная способность чипов HBM увеличивается в 1,4 раза каждые два года, а пропускная способность межсоединений (PCIe, IB, NVLink и т. д.) увеличивается в 1,4 раза каждые два года, как показано в рисунок ниже. Видно, что существует большая разница в скорости развития вычислительной производительности и пропускной способности Интернета. 3,3/1,4=2,4, количество межсоединений необходимо увеличить в 2,4 раза, чтобы компенсировать разницу в скорости разработки между ними.
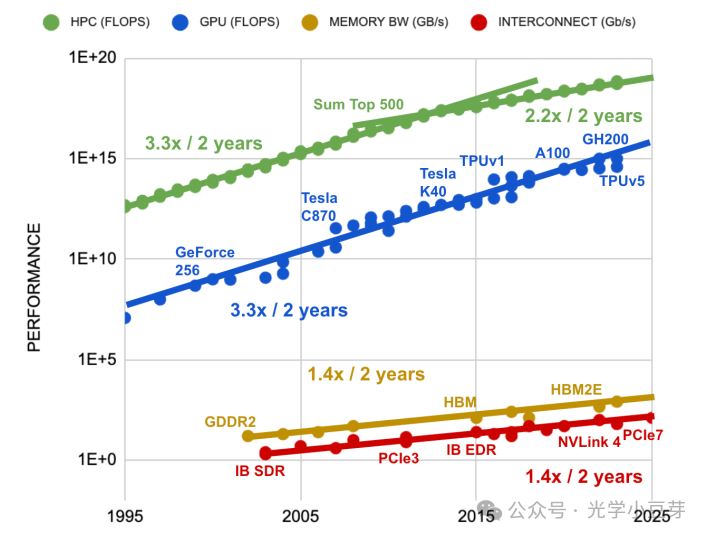
В то же время благодаря AIGC спрос на вычислительные мощности ИИ вырос в геометрической прогрессии, удваиваясь каждые 2–3 месяца и увеличиваясь более чем в 100 раз за два года, как показано на рисунке ниже.
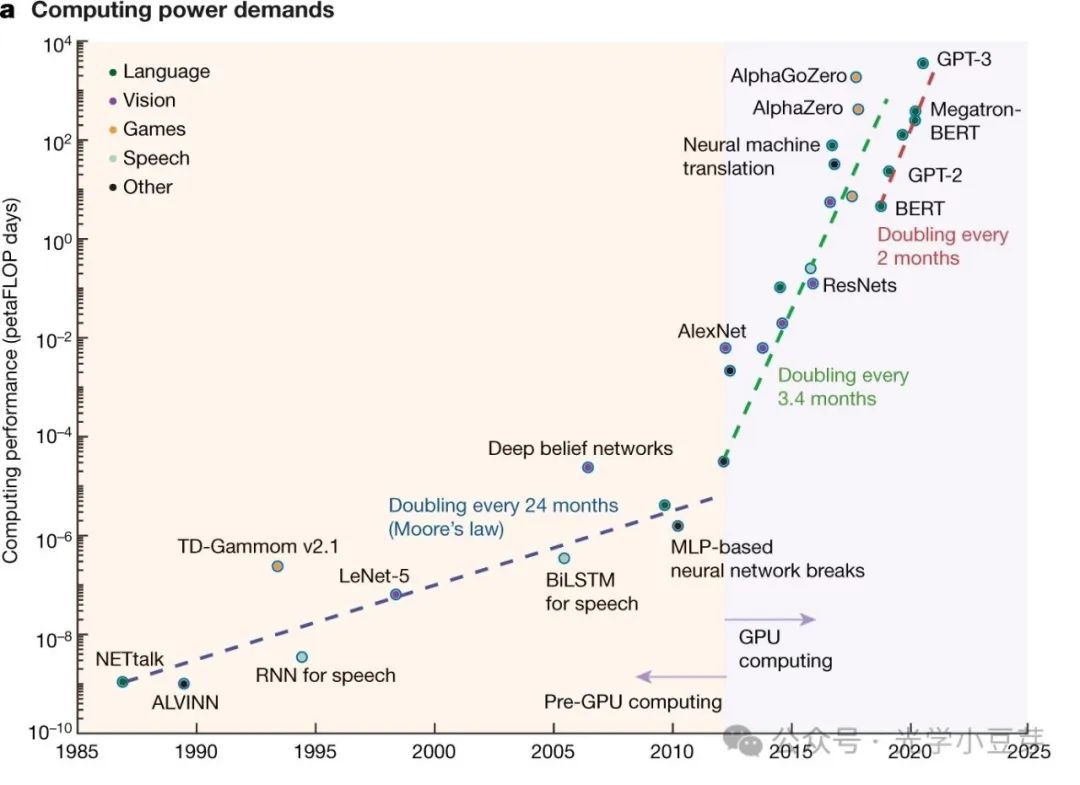
(Изображение взято с https://www.nature.com/articles/s41586-021-04362-w)
По простым расчетам, увеличение вычислительной мощности в 100 раз требует увеличения производительности вычислительных чипов в 3,3 раза, поэтому количество вычислительных чипов необходимо увеличить более чем в 30 раз. Учитывая предыдущую разницу в 2,4 раза, общее количество межсоединений необходимо увеличивать более чем в 70 раз каждые два года. Как решить эту проблему? С одной стороны, это увеличивает пропускную способность оптического модуля. Тенденция его развития заключается в удвоении пропускной способности каждые четыре года, включая увеличение скорости одного канала, увеличение количества каналов и использование большего количества длин волн. С другой стороны, увеличение общего количества оптических модулей и улучшение плотности полосы пропускания портов ввода-вывода позволяет разместить больше интерфейсов в ограниченном пространстве.
Глядя на другой набор данных, пропускная способность соединения между графическим процессором и памятью составляет 5 ТБ/с, а пропускная способность электрического соединения между графическими процессорами составляет 900 ГБ/с, но пропускная способность оптического модуля составляет 400 Гбит/с, что составляет 100-кратную разницу. . Как эффективно передавать большие объемы данных с компьютерных чипов, стало главным приоритетом. Технология оптического ввода-вывода стала одним из важных технических направлений.

Для микросхемы Switch, предполагая, что размер кристалла составляет 32 мм * 32 мм, можно оценить соответствующую плотность полосы пропускания при различных полосах пропускания, как показано в таблице ниже. Соответствующая плотность полосы пропускания при полосе пропускания 51,2T/102,4T/204,8T составляет 0,4/0,8/1,6 Тбит/с/мм соответственно.
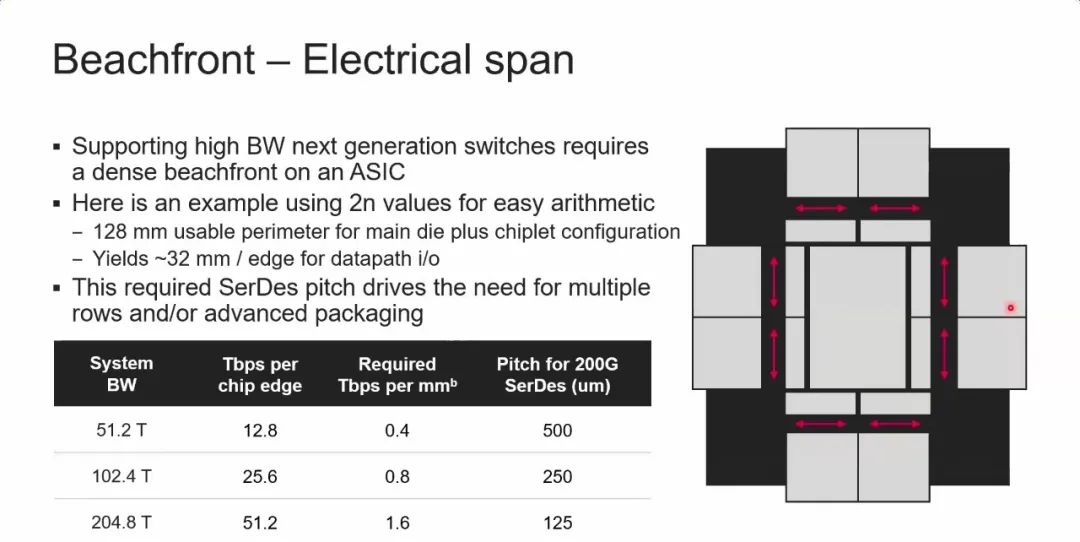
В то же время можно рассчитать плотность полосы пропускания ввода-вывода решения для упаковки CPO. Если используется одна длина волны, лазерный чип DFB поддерживает 4 канала, расстояние между каналами оптического порта составляет 127 мкм, скорость одного канала — 200 Гбит/с, а соответствующая плотность полосы пропускания — около 0,7 Тбит/с/мм. Путем введения нескольких длин волн, увеличения мощности лазера и оптимизации потерь в канале можно еще больше увеличить плотность полосы пропускания, чтобы удовлетворить потребность в увеличенной полосе пропускания электрических чипов.

Что касается применения CPO в кластерах ИИ, разногласия в основном касаются таких вопросов, как надежность, ремонтопригодность и тестируемость CPO. В большинстве выпускаемых в настоящее время решений продуктов CPO оптический механизм вставлен в подложку в виде гнезда. Перед упаковкой оптические двигатели сначала проверяются, а те оптические двигатели, характеристики которых соответствуют требованиям, отбираются для повышения производительности. Кроме того, продукты CPO требуют углубленного сотрудничества с компаниями-производителями чипов ASIC, поэтому в настоящее время продукты CPO в основном запускаются самими компаниями-коммутаторами или тесно с ними связаны, включая Broadcom, Marvell, Cisco и т. д.

В кластере AI новую сетевую архитектуру можно внедрить через оптический коммутатор OCS (коммутатор оптических цепей), как показано на рисунке ниже. Оптические переключатели можно использовать для подключения плат графического процессора для гибкого переключения топологии сети, а также для соединения аппаратных ресурсов между различными стойками для формирования новой вычислительной сети и повышения эффективности использования оборудования. При развертывании большого количества графических процессоров в кластерах ИИ необходимо добиться высокоэффективного соединения сигналов между графическими процессорами и увеличить вычислительную мощность за счет масштабирования соединения. В противном случае соединение будет сильно ограничивать производительность системы и не сможет эффективно работать. использовать вычислительную мощность кластера графического процессора.

В связи с быстрым развитием кластеров искусственного интеллекта оптическое соединение породило новые требования и проблемы, но основные требования вполне очевидны — низкое энергопотребление, высокая пропускная способность и соединение сигналов с малой задержкой. Кто сможет воспользоваться этой возможностью и проложить путь? Давайте подождем и посмотрим!
Если в статье есть ошибки или неточности,Я надеюсь, что вы все это укажете,Каждый может оставить сообщение для обсуждения. На данный момент все три группы Вичата заполнены.,Сяодуя открыла новую дискуссионную группу Вичат 4,Друзья, которым нужны технические обсуждения или бизнес-консалтинг, могут напрямую добавить мой профиль.Вичатphoton_walker。



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
