Одна статья раскрывает тайну NVIDIA CUDA
Привет, ребята, меня зовут Луга, и сегодня мы продолжим говорить об экологических технологиях искусственного интеллекта — фреймворке программирования графических процессоров для ускорения создания вычислительной мощности ядра ИИ — CUDA.
CUDA, как вычислительный блок современных графических процессоров (GPU), играет все более важную роль в области высокопроизводительных вычислений. Разлагая сложные вычислительные задачи на тысячи потоков для параллельного выполнения, CUDA значительно увеличивает скорость вычислений и вносит революционные изменения в такие области, как искусственный интеллект, научные вычисления и высокопроизводительные вычисления.
— 01 —CUDA что именно ?
Без сомнения, вы слышали о CUDA и знаете, что она тесно связана с графическими процессорами NVIDIA. Однако многие люди до сих пор не понимают конкретного определения и функций CUDA. Является ли CUDA библиотекой для связи с графическим процессором?
Если да, принадлежит ли он библиотеке C++ или Python? Или CUDA на самом деле является компилятором для графических процессоров? Понимание этих проблем поможет вам лучше понять основные функции CUDA и ее роль в ускорении графического процессора.
CUDA, что означает «унифицированная архитектура вычислительных устройств», представляет собой мощную платформу параллельных вычислений и структуру модели программирования, выпущенную NVIDIA, предоставляющую разработчикам комплексное решение для ускорения ресурсоемких приложений. CUDA включает в себя ядро среды выполнения, драйверы устройств, библиотеки оптимизации, инструменты разработки и богатый набор API, которые позволяют разработчикам запускать код на графических процессорах с поддержкой CUDA, что значительно повышает производительность приложений. Эта платформа особенно подходит для решения крупномасштабных параллельных задач, таких как глубокое обучение, научные вычисления и обработка изображений.
Вообще говоря, «CUDA» относится не только к самой платформе, но также к коду, написанному для полного использования вычислительной мощности графических процессоров NVIDIA. Эти коды в основном написаны на таких языках, как C++ и Python. преимущество ускорения графического процессора. С помощью CUDA разработчики могут легче переносить сложные вычислительные задачи на выполнение графическим процессором, что значительно повышает эффективность работы приложений.
Итак, подводя итоги, можно сделать следующие выводы:
CUDA — это больше, чем просто библиотека, это полноценная платформа, предоставляющая разработчикам полную поддержку эффективных параллельных вычислений с использованием графических процессоров. Основные компоненты этой платформы включают в себя:
(1) CUDA C/C++: это язык C++, расширенный CUDA для параллельного программирования и специально разработанный для написания параллельного кода на графическом процессоре. Разработчики могут использовать знакомые синтаксические структуры C++ для определения задач графического процессора с помощью конкретных моделей программирования, что позволяет более эффективно выполнять код в многопоточной среде.
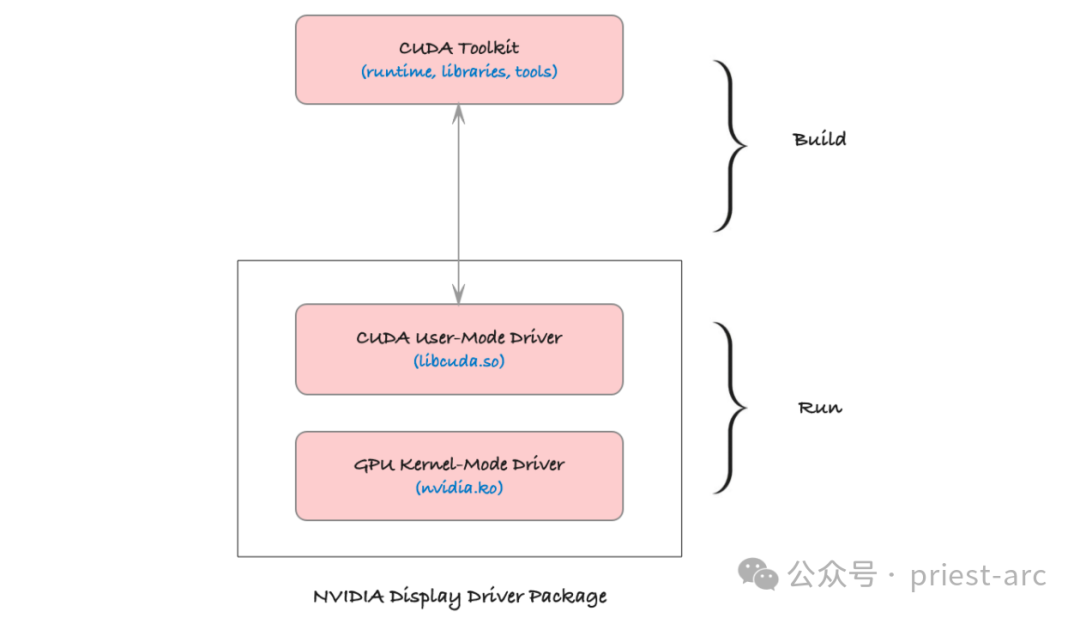
(2) Драйвер CUDA: этот компонент соединяет операционную систему и графический процессор и обеспечивает базовый интерфейс доступа к оборудованию. Основная роль драйвера — управлять передачей данных между CPU и GPU и координировать их вычислительные ресурсы. Он обеспечивает совместимость оборудования и операционных систем и является основой для эффективной работы кода CUDA.
(3) Библиотека времени выполнения CUDA (cudart): Библиотека времени выполнения предоставляет разработчикам богатый API для облегчения управления памятью графического процессора, запуска ядер графического процессора (т. е. параллельных задач), синхронизации потоков и т. д. Это упрощает рабочий процесс разработчика и делает процесс запуска параллельных программ на графическом процессоре более плавным и эффективным.
(4) Цепочка инструментов CUDA (ctk): включает такие инструменты, как компилятор, компоновщик, отладчик и т. д. Эти инструменты используются для компиляции кода CUDA в двоичные инструкции, исполняемые графическим процессором. Компилятор в цепочке инструментов обрабатывает код C++ и код ядра CUDA вместе, чтобы адаптировать его к архитектуре графического процессора, а отладчики и инструменты анализа помогают разработчикам оптимизировать производительность и устранять проблемы.
Связанные переменные среды можно найти следующим образом:
$CUDA_HOME — это путь к системному CUDA, выглядит как /usr/local/cuda, который может быть связан с конкретной версией /usr/local/cuda-X.X.
LD_LIBRARY_PATH — это переменная, которая помогает приложениям находить связанные библиотеки. Возможно, вы захотите включитьCUDA_HOME/libизпуть。
PATH должен содержать путь кCUDA_HOME/binизпуть。
Благодаря этой комплексной платформе разработки разработчики могут в полной мере использовать вычислительный потенциал графических процессоров NVIDIA и эффективно распределять сложные параллельные вычислительные задачи для графического процессора, тем самым значительно повышая производительность приложений.
— 02 —CUDA как это работает ?
Современные графические процессоры состоят из тысяч небольших вычислительных блоков, называемых ядрами CUDA. Ядра CUDA эффективно работают параллельно, позволяя графическим процессорам быстро обрабатывать задачи, которые можно разбить на небольшие независимые операции. Эта архитектура делает графический процессор подходящим не только для задач рендеринга графики, но и для неграфических задач, таких как интенсивные научные вычисления и машинное обучение.
В качестве вычислительной платформы и модели программирования, предоставляемой NVIDIA, CUDA открывает эти мощные возможности параллельной обработки специально для графических процессоров. С помощью CUDA разработчики могут писать код, который перекладывает сложные вычислительные задачи на графический процессор. Вот как работает CUDA:
1. Параллельная обработка
CUDA разбивает вычислительные задачи на несколько небольших задач, которые можно запускать независимо, и распределяет эти задачи по нескольким ядрам CUDA для параллельного выполнения. Таким образом, по сравнению с традиционным режимом последовательного выполнения ЦП, графический процессор может выполнять больше вычислений за одно и то же время, что значительно повышает эффективность вычислений.
2. Потоковая и блочная архитектура
В модели программирования CUDA вычислительные задачи дополнительно делятся на потоки, и каждый поток самостоятельно обрабатывает часть данных. Эти потоки организованы в блоки, каждый из которых содержит определенное количество потоков. Эта иерархическая структура не только облегчает управление большими потоками, но и повышает эффективность выполнения. Несколько блоков потоков могут выполняться одновременно, что позволяет быстро и параллельно выполнить всю задачу.
3. SIMD-архитектура
Ядро CUDA использует архитектуру «Одна инструкция, несколько данных» (SIMD). Это означает, что одна инструкция может выполнять операции над несколькими элементами данных одновременно. Например, числовые вычисления можно ускорить, выполняя одни и те же вычисления для большого количества элементов данных с помощью одной инструкции. Эта архитектура чрезвычайно эффективна для задач с высокой степенью параллелизма, таких как матричные операции и векторная обработка, и особенно подходит для таких областей, как обучение моделей глубокого обучения, обработка изображений и моделирование.
Основываясь на этих характеристиках, CUDA не только обеспечивает прямой подход к высокопроизводительным параллельным вычислениям, но и расширяет мощный вычислительный потенциал графических процессоров NVIDIA для научных вычислений, искусственного интеллекта, распознавания изображений и других областей, предоставляя разработчикам мощный способ ускорения работы. поддержка сложных вычислительных задач.
— 03 —CUDA модель программирования
При программировании CUDA разработчикам обычно приходится писать две части кода: код хоста и код устройства.
Код хоста выполняется на ЦП и отвечает за взаимодействие с графическим процессором, включая передачу данных и управление ресурсами, в то время как код устройства выполняется на графическом процессоре и выполняет основные вычислительные задачи. Они работают вместе, чтобы в полной мере использовать возможности совместной обработки процессора и графического процессора для достижения эффективных параллельных вычислений.
1. Код хоста. Код хоста выполняется на ЦП и отвечает за управление логическим потоком всей программы. Он управляет передачей данных между ЦП и графическим процессором, распределяет и освобождает ресурсы графического процессора, а также настраивает параметры ядра графического процессора. Эта часть кода не только определяет, как данные организуются и отправляются в графический процессор, но также содержит инструкции по запуску кода устройства, что позволяет графическому процессору выполнять задачи с интенсивными вычислениями. Хост-код играет роль управления и координации, обеспечивая эффективное сотрудничество между ЦП и ГП.
Эта часть включает в себя передачу данных, управление памятью, запуск ядра графического процессора и т. д. Конкретные функции следующие:
(1) Управление передачей данных: код хоста отвечает за передачу данных между ЦП и графическим процессором. Поскольку процессоры и графические процессоры часто используют разные системы памяти, хост-коду необходимо копировать данные между ними. Например, данные, которые необходимо обработать, передаются из памяти хоста (память ЦП) в память устройства (память ГП), а после завершения обработки результаты переносятся из памяти ГП обратно в память ЦП. Такая передача данных требует много времени, поэтому в практических приложениях необходимо минимизировать частоту передачи и оптимизировать размер данных для уменьшения задержки.
(2) Распределение памяти и управление ею. Главный код выделяет пространство памяти графического процессора для предоставления ресурсов хранения для последующих вычислений. API CUDA предоставляет различные функции управления памятью (например, cudaMalloc и cudaFree), которые позволяют разработчикам динамически выделять и освобождать память на графическом процессоре. Разумная стратегия распределения памяти может эффективно повысить эффективность использования памяти и предотвратить переполнение памяти графического процессора.
(3) Конфигурация и планирование ядра. В коде хоста разработчики могут настраивать параметры запуска ядра (например, количество потоков и блоков потоков) и решать, как ядро будет выполняться на графическом процессоре. Оптимизируя эти параметры, хост-код может значительно повысить эффективность выполнения программы.
2. Код устройства. Основная часть написания кода устройства — это вычислительная функция, выполняемая на графическом процессоре, обычно называемая ядром (ядро). Каждая функция ядра выполняется параллельно на многих ядрах CUDA графического процессора, что обеспечивает быструю обработку больших объемов данных. Код устройства ориентирован на вычислительные задачи с интенсивным использованием данных и полностью использует возможности параллельных вычислений графического процессора во время выполнения, что приводит к значительному увеличению скорости вычислений по сравнению с традиционной последовательной обработкой.
Код устройства определяет вычислительную логику графического процессора, используя ядра CUDA для параллельной обработки больших объемов данных.
(1) Функция ядра: ядром кода устройства является функция ядра, которая представляет собой функцию, которая выполняется одновременно в нескольких потоках графического процессора. Функции ядра идентифицируются ключевым словом __global__, указывающим, что функция будет выполняться на стороне устройства (GPU). Функции ядра, в отличие от обычных функций C/C++, должны быть без возврата, поскольку все выходные результаты передаются путем изменения переданного указателя или памяти графического процессора.
(2) Организация потоков и блоков потоков. В коде устройства вычислительные задачи разбиваются на несколько потоков. Эти потоки образуют блоки потоков (Блок), а несколько блоков потоков образуют сетку потоков (Сетка). CUDA предоставляет встроенные переменные, такие как threadIdx и blockIdx, для получения индекса потока, позволяя каждому потоку находить в данных свою собственную вычислительную задачу. Такой подход позволяет коду устройства очень эффективно обрабатывать каждый элемент набора данных параллельно.
(3) Оптимизация параллельного алгоритма. В коде устройства программирование CUDA может реализовать несколько методов параллельной оптимизации, таких как сокращение ветвей и оптимизация шаблонов доступа к памяти (например, сокращение доступа к глобальной памяти и улучшение использования общей памяти). Эти оптимизации помогают максимально оптимизировать использование. вычислительных ресурсов графического процессора для повышения скорости выполнения кода устройства.
3. Запуск ядра. Запуск ядра — это ключевой этап программирования CUDA. Код хоста запускает ядро кода устройства и запускает выполнение на графическом процессоре. Параметры запуска ядра определяют количество и распределение потоков на графическом процессоре, позволяя функциям ядра выполняться параллельно в большом количестве потоков, что приводит к более быстрой обработке данных. Правильная настройка ядра позволяет программировать CUDA более эффективно использовать ресурсы графического процессора и повысить вычислительную эффективность вашего приложения.
Этот шаг имеет решающее значение для всей системы, поскольку он контролирует параллелизм, эффективность и рабочее поведение кода устройства. Для получения более подробной информации, пожалуйста, обратитесь к следующему:
(1) Синтаксис запуска ядра: CUDA Используйте специальный синтаксис <<<Grid, Block>>> Запустить функцию ядра。Например:kernel<<<numBlocks, threadsPerBlock>>>(parameters);,в numBlocks Представляет количество блоков потоков, threadsPerBlock. Представляет количество потоков, содержащихся в каждом блоке потоков. Разработчики могут регулировать размер набора данных в зависимости от GPU Выберите соответствующий блок потоков и количество потоков для вашей вычислительной мощности.
(2) Управление распараллеливанием: указывая количество блоков потоков и количество потоков, запуск ядра управляет степенью параллельной детализации графического процессора. Для больших наборов данных обычно требуется больше потоков и блоков потоков, чтобы в полной мере использовать возможности параллельного процессора. Правильная настройка параметров запуска ядра может сбалансировать параллельную рабочую нагрузку графического процессора и избежать непроизводительной траты или перегрузки ресурсов.
(3) Синхронное и асинхронное выполнение: после запуска ядра графический процессор может выполнять задачи асинхронно, а процессор продолжает выполнять другие операции до тех пор, пока ему не потребуется дождаться завершения работы графического процессора. Разработчики могут воспользоваться этой асинхронной функцией для параллельного выполнения программ между ЦП и графическим процессором, чтобы добиться более высокой параллельной эффективности. Кроме того, CUDA предоставляет функции синхронизации (например, cudaDeviceSynchronize), чтобы гарантировать, что ЦП ожидает завершения всех операций графическим процессором, когда это необходимо, чтобы избежать проблем с несогласованностью данных.
Эффективно координируя эти три процесса, программирование CUDA позволяет добиться высокоскоростной параллельной обработки задач с интенсивным использованием данных, обеспечивая масштабируемое решение для высокопроизводительных вычислений.
— 04 —CUDA иерархия памяти
В программировании CUDA структура памяти графического процессора является многослойной, с разными характеристиками скорости и емкости. CUDA предоставляет несколько типов памяти для различных потребностей хранения данных. Правильное использование этой памяти может значительно повысить эффективность вычислений. Ниже приводится подробное описание каждого типа памяти:
1. Глобальная память
Глобальная память — это самая большая область хранения данных на графическом процессоре, обычно несколько гигабайт, и основное хранилище данных для графического процессора. Доступ к глобальной памяти возможен для всех потоков, и она может обмениваться данными с ЦП, но скорость доступа к ней относительно низкая (по сравнению с другими типами памяти графического процессора), поэтому следует избегать частого доступа. Операции передачи данных также требуют много времени, поэтому глобальная память часто используется для хранения больших наборов данных, но пакетная обработка или другие стратегии кэширования для доступа к данным имеют приоритет, чтобы уменьшить их частые вызовы.
Вообще говоря, глобальная память в основном подходит для хранения большей части входных и выходных данных программы, особенно данных большой емкости, которые должны совместно использоваться графическим процессором и процессором.
Пример: при умножении матриц элементы обеих матриц могут храниться в глобальной памяти, чтобы они были доступны всем потокам.
__global__ void matrixMultiplication(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0;
for (int i = 0; i < N; ++i) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}
2. Общая память
Общая память — это кеш, выделенный внутри каждого блока потоков графического процессора, доступ к которому намного быстрее, чем к глобальной памяти, но меньший по емкости (обычно 48 КБ на блок или меньше). Общая память используется потоками внутри блока потоков и подходит для хранения данных, к которым необходимо часто обращаться внутри блока потоков. Поскольку он хранится в отдельном блоке, потоки внутри каждого блока могут быстро читать и записывать данные в разделяемую память, тем самым уменьшая доступ к глобальной памяти.
По сравнению с глобальной памятью разделяемая память больше подходит для обмена данными между несколькими потоками, особенно данными, которые необходимо повторно использовать в блоке потока.
Пример: при умножении матрицы подблоки A и B могут быть загружены в общую память, чтобы все потоки в блоке потоков имели быстрый доступ.
__shared__ float sharedA[TILE_SIZE][TILE_SIZE];
__shared__ float sharedB[TILE_SIZE][TILE_SIZE];
3. Локальная память
Локальная память — это частная память, выделяемая каждому потоку и в основном используемая для хранения частных переменных потока. Хотя он и называется «локальным», на самом деле он размещается в глобальной памяти, поэтому скорость доступа ниже и приближается к скорости доступа к глобальной памяти. Из-за ограниченного объема локальной памяти и высоких затрат на доступ к ней рекомендуется использовать ее только при необходимости.
Обычно локальная память подходит для хранения временных переменных потока, личных данных или данных, которые не помещаются в регистры.
Пример: Промежуточные переменные в сложных вычислениях можно размещать в локальной памяти, чтобы не возникало конфликтов между потоками.
int localVariable = 0; // Локальное Память middle из переменной4. Константа и текстурная память
Память констант и память текстур — это типы памяти, предоставляемые CUDA и предназначенные только для чтения. Они имеют специальный механизм кэширования, который может ускорить чтение данных в определенных режимах доступа. Память констант используется для хранения постоянных данных, которые не изменяются, а память текстур подходит для хранения двухмерных или трехмерных данных. Скорость доступа можно улучшить за счет кэширования текстур.
Постоянная память: доступна для записи только процессором, но доступна для чтения всеми потоками графического процессора. Подходит для хранения небольших неизмененных данных (например, информации о конфигурации, коэффициентов и т. д.).
Память текстур: специально оптимизирована для поддержки чтения двухмерных или трехмерных данных, она имеет высокую эффективность доступа к данным в непоследовательных или разреженных режимах доступа (например, к данным изображений).
Пример. В приложении для обработки изображений загрузите данные пикселей в память текстур и позвольте графическому процессору использовать свой специальный механизм кэширования для оптимизации эффективности доступа.
__constant__ float constData[256]; // постоянный Память
cudaArray* texArray;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaMallocArray(&texArray, &channelDesc, width,height); // текстура ПамятьПлатформа CUDA предоставляет разработчикам глубокий доступ к ресурсам параллельных вычислений графического процессора CUDA, позволяя напрямую манипулировать виртуальным набором команд и памятью графического процессора. Используя CUDA, графический процессор может эффективно справляться с интенсивными математическими задачами, освобождая вычислительные ресурсы процессора, чтобы он мог сосредоточиться на других задачах. Эта архитектура фундаментально отличается от функции рендеринга 3D-графики традиционных графических процессоров, создавая новые возможности использования графических процессоров в вычислительной области.
В архитектуре платформы CUDA ядро CUDA является ее основным компонентом. Каждое ядро CUDA представляет собой независимый параллельный процессор, отвечающий за выполнение различных вычислительных задач. Чем больше ядер CUDA в графическом процессоре, тем больше задач он может обрабатывать параллельно, что значительно повышает производительность вычислений. Благодаря такому виду параллельных вычислений платформа CUDA может обеспечить параллельную обработку крупномасштабных задач в сложных вычислительных процессах, обеспечивая превосходную производительность и эффективность.
Для более интересного контента, пожалуйста, обратите внимание на последующие статьи, 3ks...
Reference :
[1] https://acecloud.ai/resources/blog/why-gpus-for-deep-learning/
[2] https://www.weka.io/learn/glossary/ai-ml/cpu-vs-gpu/
Adiós !
··································



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
