Одна статья поможет вам разобраться в ELK
концепция
ELK — это набор решений, а не часть программного обеспечения. Три буквы — это аббревиатуры трех программных продуктов. E означает Elasticsearch, отвечающий за хранение и извлечение журналов; L означает Logstash, отвечающий за сбор, фильтрацию и форматирование журналов; K означает Kibana, отвечающий за отображение статистики и визуализацию данных. Среди них Elasticsearch является ядром, а L и K имеют соответствующие альтернативы.
- Elasticsearch: платформа поисковой платформы, работающая почти в реальном времени, на основе Lucene, распределенная и интерактивная через Restful. Преимущество этой архитектуры в том, что ее легко построить и легко начать. Недостатком является то, что Logstash потребляет много системных ресурсов и занимает много ресурсов ЦП и памяти при работе. Кроме того, поскольку кэш очереди сообщений отсутствует, может возникнуть риск потери данных, поэтому он подходит для использования в средах с небольшим объемом данных.
- Logstash: центральный механизм потока данных ELKиз,Используется для сбора и фильтрации бревно.,Форматирование данных,С функциональной точки зрения,Он делает только три вещи:
- ввод: сбор данных
- фильтр: обработка данных, такая как фильтрация, перезапись и т. д.
- вывод: вывод данных
- Kibana: отображает данные эластичного поиска на удобных страницах и предоставляет возможности анализа в реальном времени. Несколько распространенных архитектур
- Простейшая архитектура ELK
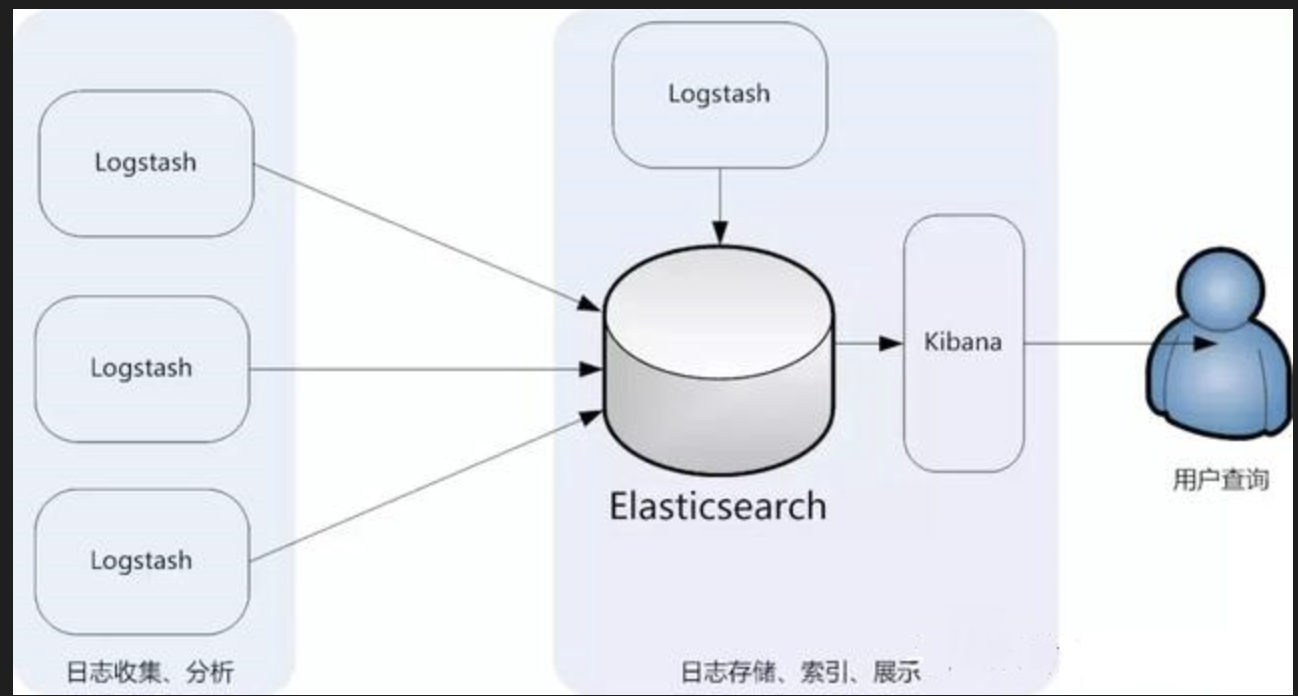
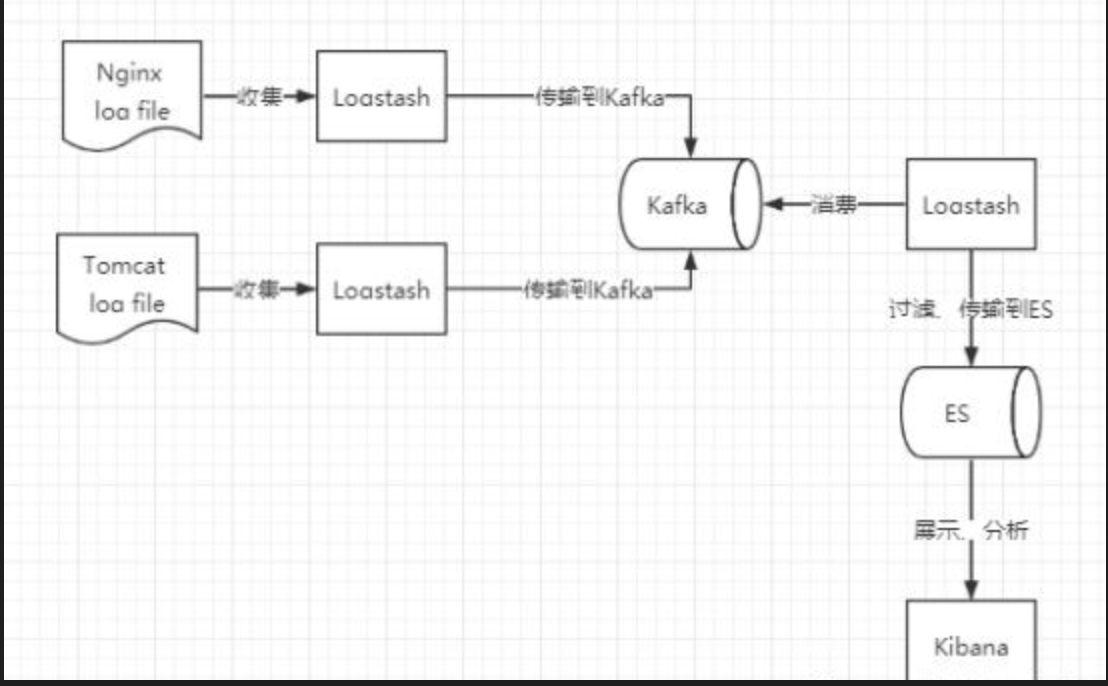
- Оптимизированная архитектура ELK
На последней диаграмме архитектуры Kafka добавляется в качестве буферного хранилища. Сборщик Logstash, работающий в источнике данных, собирает данные и передает их непосредственно в Kafka в качестве производителя. Обратите внимание, что действие фильтрации здесь опущено, что оказывает наименьшее влияние. сервер источника данных, потому что Kafka Производительность чтения и записи очень высока. С другой стороны, нам необходимо самостоятельно развернуть выделенный Logstash для потребления. Этот Logstash отвечает за фильтрацию и передачу отфильтрованных данных в ES. Позже Kibana все равно будет читать данные ES для отображения. Эта архитектура не только имеет хорошую производительность, но также имеет низкую связанность и может параллельно расширяться для разных каналов.
Обучение Elasticsearch
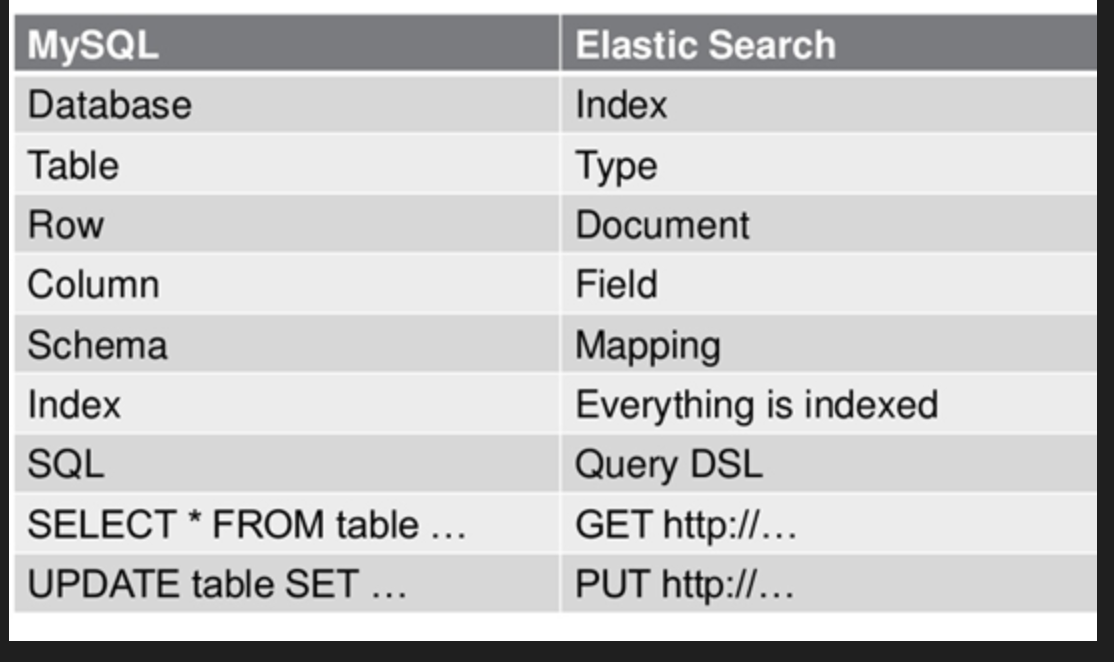
- Архитектура данных ES из основной концепции
- Сравнивая ES с реляционной базой данных Mysql, их можно изучить и запомнить по аналогии.
* Примечание: в 6.0.0 Устарело,В будущем больше нельзя будет создавать в индексе несколько типов (Type).,А тип(Type)изконцепция будет удален в более поздней версии.
кроме,Существуют также кластерные концепции, связанные с двумя концепциями.,концепция в основном универсальна
- Кластер Кластер — это набор узлов с одинаковым именем кластера. Они работают вместе для совместного использования данных и обеспечения функций аварийного переключения и расширения. Конечно, узел также может образовывать кластер. Кластеры идентифицируются по уникальному имени, которое по умолчанию — «elasticsearch». Это имя важно, поскольку узел может быть частью кластера только в том случае, если он настроен на присоединение к кластеру по имени. Обязательно используйте разные имена кластеров в разных средах, иначе узлы присоединятся не к тому кластеру. Узел, работающий экземпляр ES — это узел, который хранит данные и участвует в функциях индексирования и поиска кластера. Как и в случае с кластером, узлы идентифицируются по имени, которое по умолчанию представляет собой случайный универсальный уникальный идентификатор (UUID), присваиваемый узлу при запуске. Если вам не нужно значение по умолчанию, вы можете определить любое имя узла по вашему желанию. Это имя важно для административных целей, поскольку вы можете определить, какие серверы в вашей сети соответствуют каким узлам в вашем кластере Elasticsearch. Узлы можно настроить для присоединения к определенному кластеру по имени кластера. По умолчанию каждый узел настроен на присоединение к кластеру elasticsearch под названием «cluster». Это означает, что если вы запустите несколько узлов в сети и предполагаете, что они могут обнаружить друг друга, они автоматически сформируются и присоединятся к кластеру под названием «asticsearch». 2. Справочные документы
- Узел
- Начало работы с основами Elasticsearch



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
