Одна статья, чтобы понять принцип и реализацию текущей лимитирующей стратегии
Всем привет, я Чжан Чжан, автор паблика «Дорога к улучшению архитектуры».
введение
Текущая политика ограничения в основном используется для управления скоростью запросов интерфейса службы в сценариях с высоким уровнем параллелизма и большим трафиком.
Например, флэш-распродажи Double Eleven, срочные покупки, сбор билетов, сбор заказов и другие сценарии.
Например, предположим, что количество запросов в секунду, которое может обработать интерфейс, составляет 1 тыс. В это время поступает 10 000 запросов. После текущего модуля ограничения сначала будут выпущены 1 тыс. запросов, а остальные запросы будут заблокированы на определенный период времени. Вместо того, чтобы просто и грубо возвращать 404, он позволяет клиенту повторить попытку и в то же время может сыграть роль в снижении пикового трафика.
В процессе итеративного развития бизнеса стабильность и надежность системы становятся все более важными. Среди них текущий алгоритм ограничения является одним из очень важных технических средств.
Текущий алгоритм ограничения может эффективно помочь системе контролировать запрошенный трафик и предотвратить сбой системы из-за чрезмерного трафика. В случае высокого параллелизма, если нет текущего механизма ограничения, система может реагировать медленно или даже быть парализованной из-за слишком большого количества запросов. Кроме того, текущий алгоритм ограничения также может защитить систему от вредоносных атак, вредоносных сканеров и других неправомерных действий, повышая безопасность и стабильность системы.
В этой статье мы обсудим реализацию общих алгоритмов ограничения тока, основанных на стратегии ограничения тока, а также то, как разработать полезное решение для реализации ограничения тока от 0 до 1.
1. Введение
Разработка набора алгоритмов ограничения тока в основном включает в себя следующие три этапа:
- Статистика трафика: запись количества потоков, пройденных за определенный период времени, за которым следует Текущее ограничительное решение обеспечивает основу.
- Текущее ограничительное решение: Определите, может ли текущий поток проходить нормально.
- контроль поток: для запросов с ограниченным потоком требуется специальная обработка.
2. Статистика трафика
Существует два основных метода статистики трафика: статистика фиксированного окна и статистика скользящего окна.
2.1 Статистика фиксированного окна
Статистика фиксированных окон делит время на временные окна фиксированной длины и подсчитывает количество запросов, проходящих через систему в каждом временном окне. Например, на рисунке ниже время разбито на временные окна по 1 секунде и подсчитано количество запросов, проходящих через систему в секунду. В статистике фиксированного окна счетчик каждого временного окна будет очищен в конце окна, а количество запросов в следующем окне будет подсчитано снова.
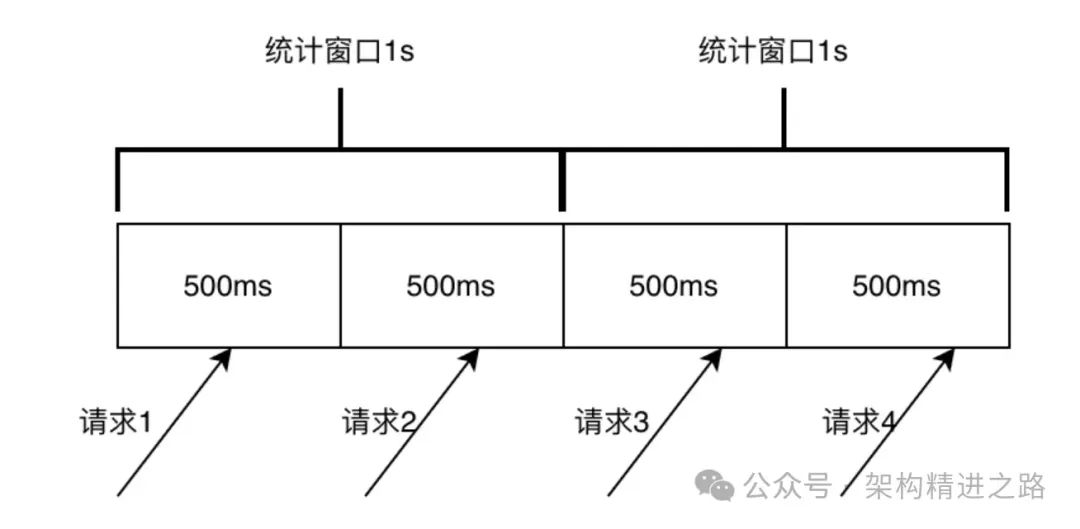
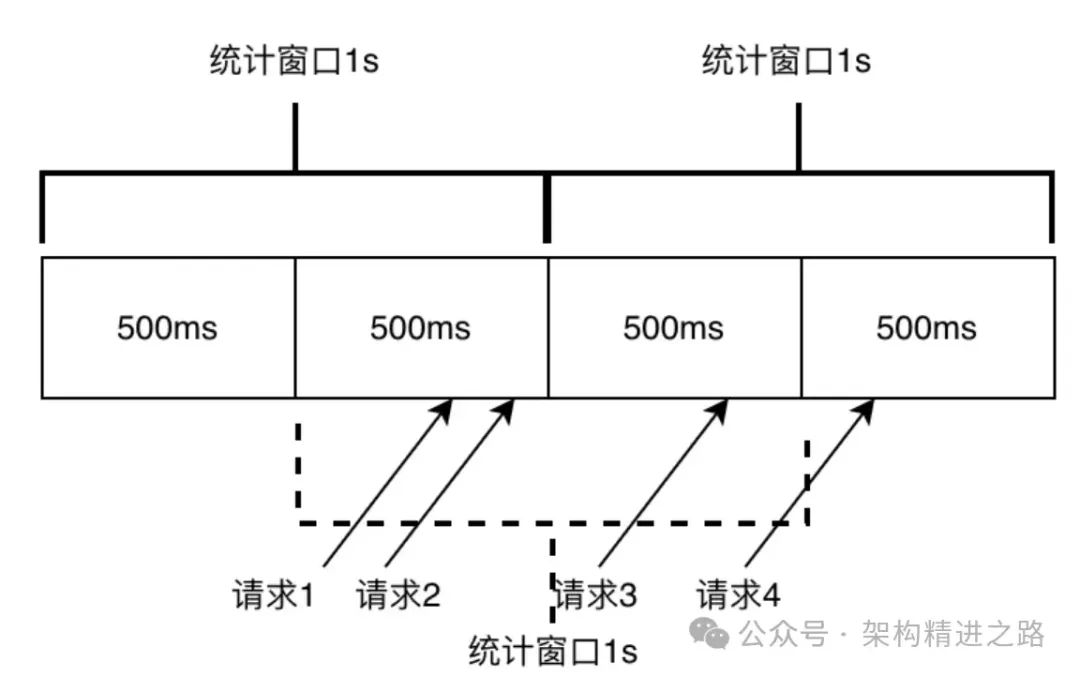
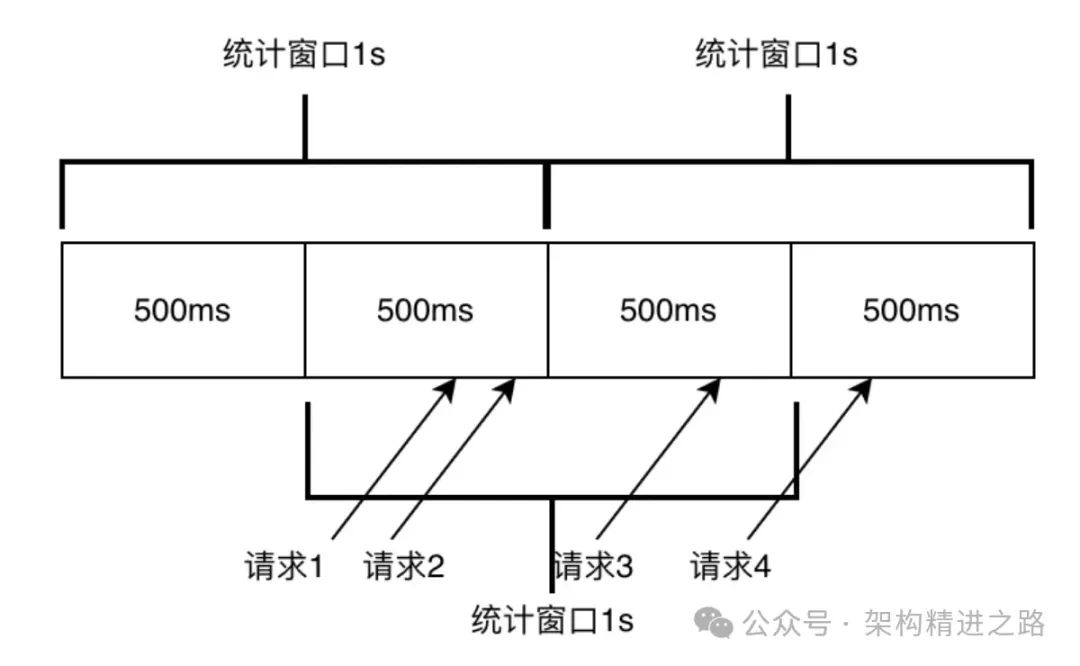
Этот статистический метод легко понять и реализовать, но он подвержен внезапным проблемам с трафиком, когда трафик неравномерен, что приводит к неточному ограничению тока. Как показано на рисунке ниже, предположим, что текущий лимит установлен на 2 QPS в 1 секунду. Поскольку окно статистики очищается через 1 секунду, памяти для 2 запросов, прошедших в интервале 500мс-1000мс, не остается. -1500м s запросы могут проходить нормально, но на самом деле количество запросов в интервале 500мс-1500мс уже 3, что превышает установленный текущий лимит 2. В крайних случаях реальный трафик фиксированного окна может достигать лимита в 2 раза. значение потока.
Поскольку фиксированное окно легко реализовать, оно часто используется, когда точность ограничения тока невысока. Ниже приведен фактический сценарий применения шлюза Apinto, использующего фиксированное окно для ограничения тока.
//Исправленная структура окна
type rateTimer struct {
// Запрошенное количество
requestCount int64
// ограниченное количество
limitCount int64
timerType int
expire time.Duration
startTime time.Time
}
// Проверьте, превышен ли лимит
func (r *rateTimer) check() bool {
if time.Now().Sub(r.startTime) > r.expire {
r.reset()
return true
}
c := atomic.LoadInt64(&r.requestCount)
localCount := c + 1
r.add()
if localCount > r.limitCount {
return false
}
return true
}
2.2 Статистика скользящего окна
Статистика скользящего окна — это метод статистики трафика. Он делит время на временные окна фиксированной длины, но время начала и окончания каждого временного окна изменяется динамически в зависимости от текущего времени. В каждом временном окне подсчитывается количество запросов, проходящих через систему, и статистика обновляется по мере скольжения окна.
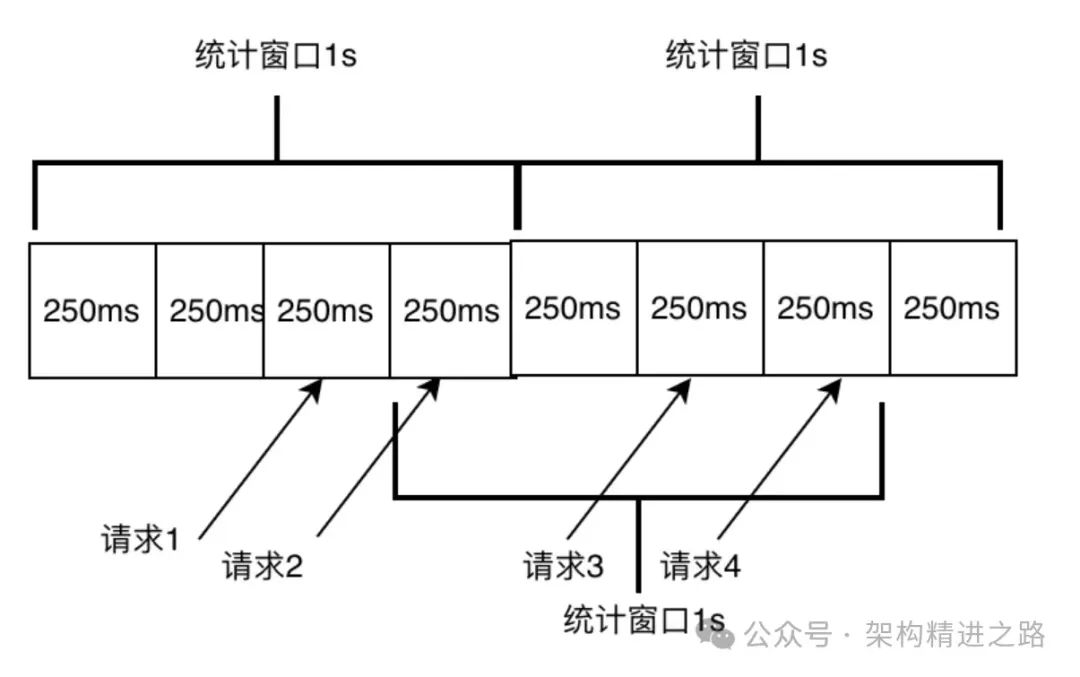
В статистике скользящего окна используются две основные концепции:
- цикл статистики: где цикл статистики — это период выборки.,Например, установите максимум 2 запроса в 1 секунду.,1 здесь — это статистический цикл.
- Размер окна: наименьшая единица статистики за период статистики.,Например, картинка ниже,1с разделен на 4 маленьких окошка,Размер выборки, отвечающий за каждое окно, составляет 250 мс.,Чем меньше окно,Чем больше окон в цикле статистики,Тогда статистика будет более точной (поскольку последнее маленькое окно всегда находится в состоянии незавершенной статистики).,Фактический цикл статистики всегда меньше установленного цикла статистики).
Структура данных небольшого окна в скользящем окне должна включать «время начала» статистики окна и основную информацию «элемента, подлежащего подсчету» (здесь в основном количество запросов, переданных текущим окном). Структура данных дизайна окна такая же, как показано в BucketWrap.
//Дизайн маленького окна
type BucketWrap struct {
// BucketStart represents start timestamp of this statistic bucket wrapper.
BucketStart uint64
// Value represents the actual data structure of the metrics (e.g. MetricBucket).
Value atomic.Value
}
type AtomicBucketWrapArray struct {
// The base address for real data array
base unsafe.Pointer // Адрес первого элемента массива окон
// The length of slice(array), it can not be modified.
length int // Длина оконного массива
data []*BucketWrap //массив окон
}
В то же время статистический цикл состоит из нескольких последовательных небольших окон. Чтобы избежать бесполезной траты памяти, в конструкции используется атомное колесо времени для соединения маленьких окон с концом, а данные располагаются в круговой очереди. Структура — AtomicBucketWrapArray, схематическая диаграмма выглядит следующим образом.
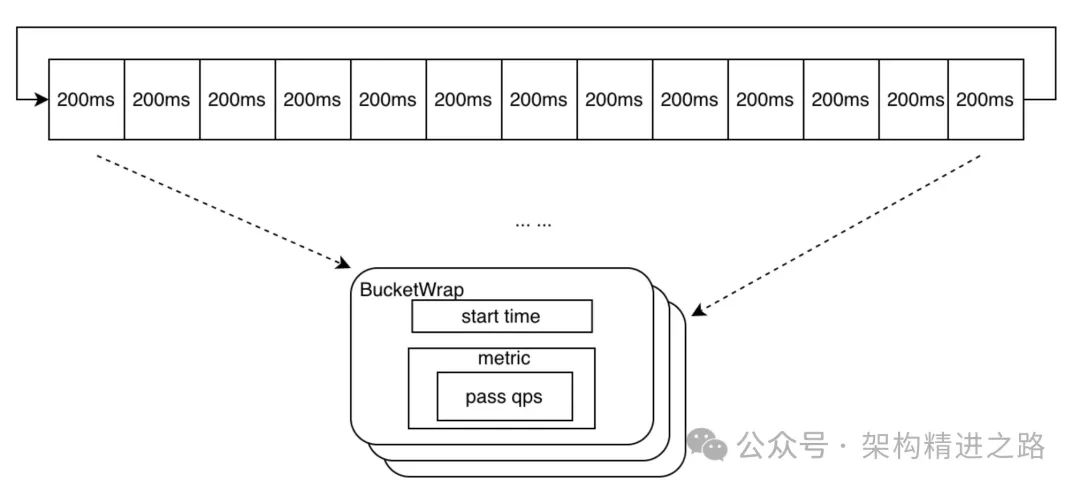
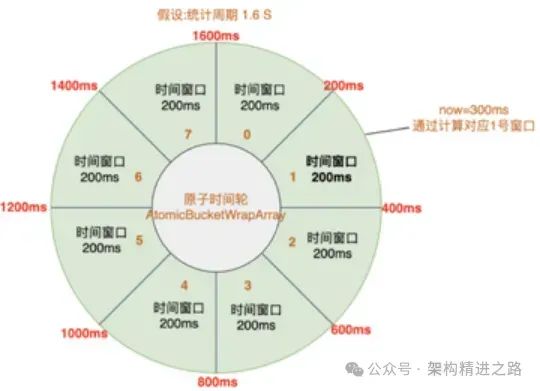
Окно, соответствующее текущему времени, можно получить, вычислив временную метку по модулю. Если запрос находится в текущем окне, запрос записывается, и количество запросов в пределах окна обновляется. Если текущее время превысило текущее окно, запускается новый период выборки, то есть время начала окна и счетчик запросов сбрасываются.
Например, временная метка в этот момент равна 300 мс, индекс для расчета текущего момента — (300/200)%8=1, а время начала текущего окна — 200 мс, если вычисленное время начала окна соответствует; с текущим временем запрос фиксируется. Если время выделено для следующего периода выборки, например, время в этот момент равно 1801 мс, расчетный индекс равен (1801/200)%8=1, а время начала составляет 1800 мс с момента начала окна. запись составляет 200 мс, это представляет данные текущего окна. Период выборки превышен. Сбросьте время начала окна с индексом от 1 до 1800 мс и запишите окно сброса как новый период выборки для статистического подсчета.
// Рассчитать время начала
func calculateStartTime(now uint64, bucketLengthInMs uint32) uint64 {
return now - (now % uint64(bucketLengthInMs))
}
// индексная позиция окна
func (la *LeapArray) calculateTimeIdx(now uint64) int {
timeId := now / uint64(la.bucketLengthInMs)
return int(timeId) % la.array.length
}
Чтобы получить количество запросов, прошедших в течение периода выборки скользящего окна, основным методом является перемещение по атомарному временному колесу и накопление статистики о количестве запросов в окне выборки, которое соответствует условиям.
// Сопоставить соответствующие окна
func (la *LeapArray) ValuesConditional(now uint64, predicate base.TimePredicate) []*BucketWrap {
if now <= 0 {
return make([]*BucketWrap, 0)
}
ret := make([]*BucketWrap, 0, la.array.length)
for i := 0; i < la.array.length; i++ {
ww := la.array.get(i)
if ww == nil || la.isBucketDeprecated(now, ww) || !predicate(atomic.LoadUint64(&ww.BucketStart)) {
continue
}
ret = append(ret, ww)
}
return ret
}
3. Текущее ограничительное решение
Благодаря конструкции вышеуказанного окна выборки мы можем получить количество запросов, переданных за любой период выборки. С помощью статистики трафика мы можем получить объем запроса и связанные с ним данные в текущем временном окне и сравнить его с текущими правилами ограничения, чтобы определить, соответствует ли текущий запрос условиям прохождения. Если запрос соответствует условиям прохождения, он может пройти напрямую. В противном случае требуются текущие ограничительные меры.
Обычно используемый метод определения ограничения тока — это алгоритм ведра токенов. Алгоритм основан на концепции корзины токенов, где токены добавляются в корзину токенов с фиксированной скоростью. Каждый запрос должен получить токен из корзины токенов, прежде чем его можно будет обработать. Если в корзине токенов недостаточно токенов, запрос будет временно заблокирован или отклонен до тех пор, пока в корзине токенов не будет получено достаточное количество токенов.
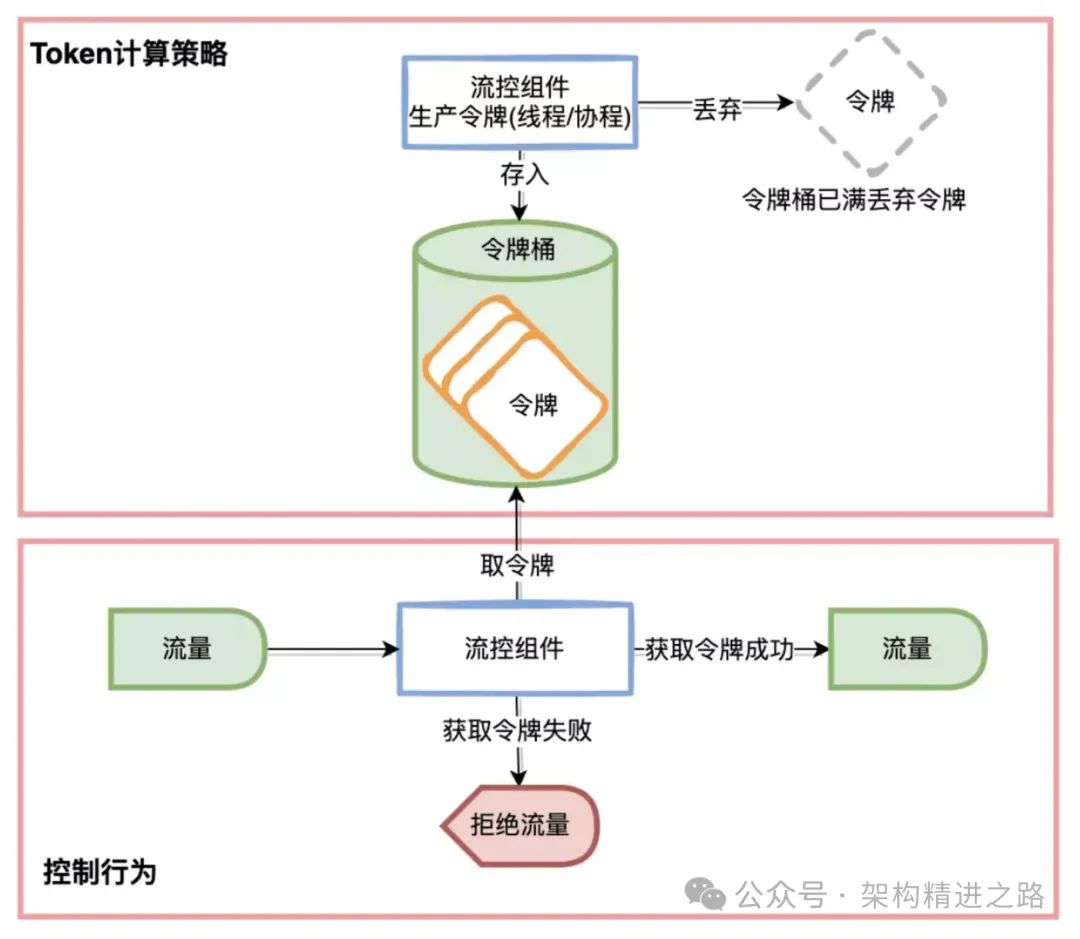
Суть текущего лимитного решения заключается в расчете количества токенов, разрешенных для прохождения в текущий момент, то есть стратегии расчета токенов. Основные вычислительные стратегии включают фиксированный порог, предварительный нагрев и адаптацию памяти.
3.1 Фиксированный порог (Threshold)
Эта стратегия расчета токенов относительно проста. Это означает, что количество запросов, разрешенных для прохождения в течение статистического периода, фиксировано. Вам нужно только сравнить количество переданных запросов, подсчитанных за статистический период, и пороговое значение, чтобы определить, нужно ли регулировать текущий запрос.
func (d *DirectTrafficShapingCalculator) CalculateAllowedTokens(uint32, int32) float64 {
return d.threshold
}Однако существует проблема с методом фиксированного порога, то есть в случае внезапного увеличения трафика количество переданных запросов мгновенно достигнет порога, что может легко вызвать большую нагрузку на нижестоящую систему. Положите, если он слишком жесткий, он легко сломается. Поэтому на свет появилась еще одна стратегия прогрева заранее.
3.2 Разминка
Существует проблема со схемой расчета токена, основанной на фиксированных порогах, то есть в случае внезапного увеличения трафика количество пропущенных запросов мгновенно достигнет порога, что легко может вызвать большее давление на нижестоящую систему. . Поэтому ожидается, что скорость потока может достичь порогового значения после периода прогрева, что может дать последующей системе определенное буферное время.
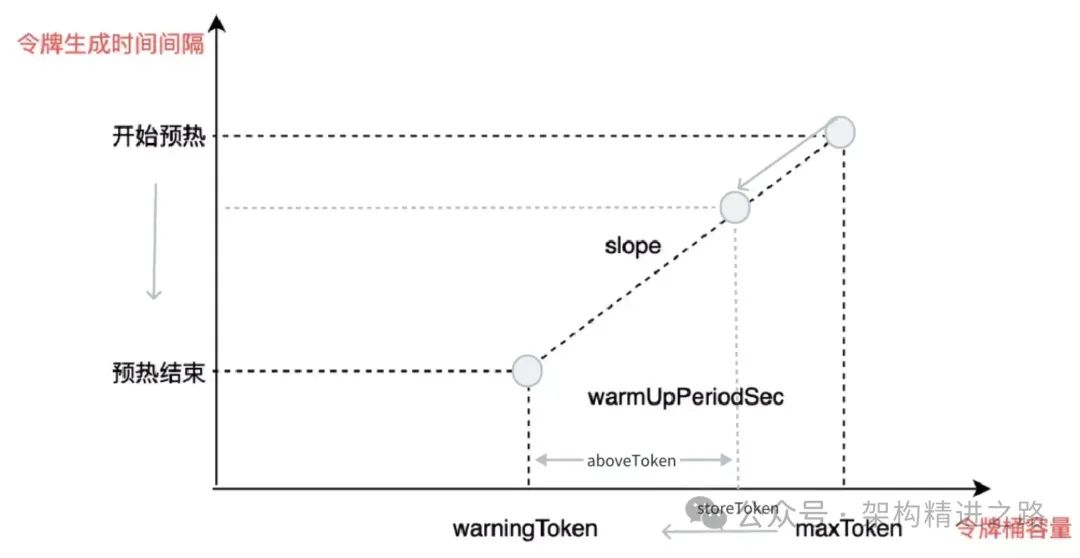
На рисунке ниже показана зависимость количества разрешенных запросов с течением времени в процессе прогрева (холодного запуска). Ключевые требования к проектированию схемы включают в себя:
- Когда поток ниже,Нет ограничения тока。(Изображение ниже1->3)
- Когда достигается порог потока холодного запуска, срабатывает стратегия холодного запуска системы. (Изображение 3 ниже)
- После периода прогрева количество разрешенных запросов достигает установленного порога и остается неизменным. (Изображение 2 ниже)
- Когда поток уменьшается, а затем внезапно снова увеличивается,Стратегию холодного запуска также необходимо запустить снова.

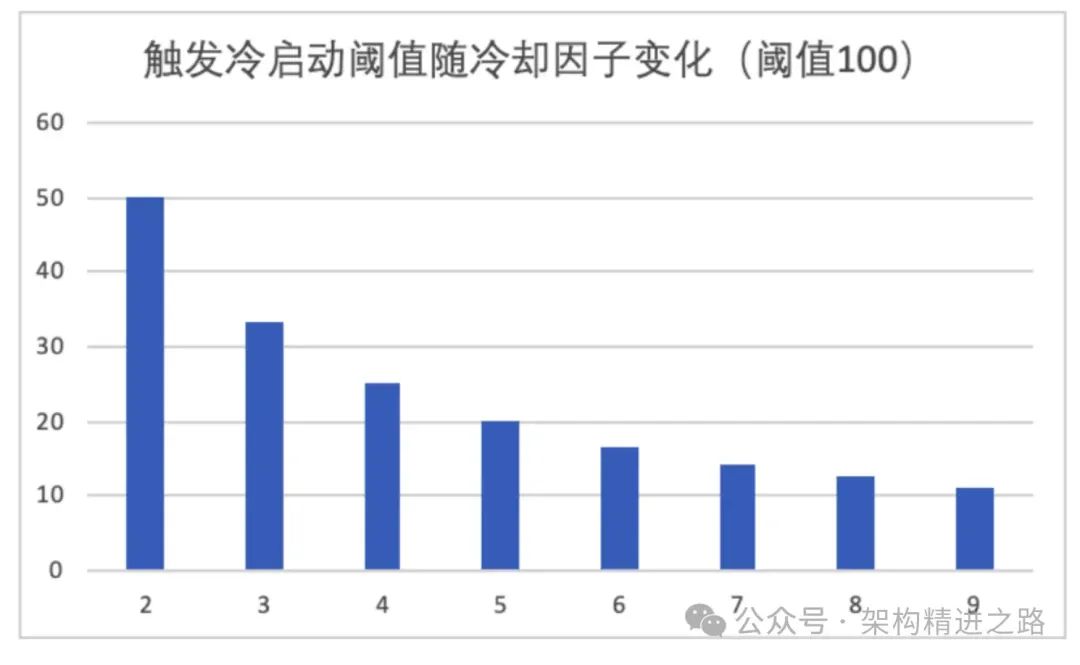
Чтобы удовлетворить проектные требования, нам необходимо разработать алгоритм прогрева, в котором очень важна конструкция порога запуска. С этой целью мы вводим понятие коэффициента охлаждения (coldFactor), который контролирует предпосылки для запуска холодного запуска. В частности, количество запросов, необходимое для запуска холодного запуска, равно Threshold/coldFactor, как показано на рисунке ниже. Видно, что чем меньше коэффициент охлаждения, тем выше порог начала предварительного нагрева. Например, если коэффициент охлаждения равен 2, перед началом предварительного нагрева необходимо достичь половины порогового значения.
В процессе предварительного нагрева необходимо разработать некоторые переменные для управления работой корзины токенов. В частности, мы можем использовать следующие переменные:
- storeToken: представляет текущее количество токенов в корзине токенов. Эта переменная отрицательно связана с количеством запросов, которые разрешено пройти, то есть чем меньше storeToken, тем больше запросов разрешено пройти до тех пор, пока не будет достигнут указанный порог.
- maxToken: представляет максимальную емкость сегмента токенов. Во время прогрева значение storeToken равно maxToken.
- alertToken: представляет количество предупреждений в сегменте токенов. В конце прогрева значение storeToken равно alertToken.
- вышеToken: представляет количество токенов, оставшихся до окончания предварительного нагрева, то есть разницу между storeToken и alertToken. Эта переменная используется для расчета количества разрешенных в данный момент запросов.
- наклон: представляет наклон, используемый для расчета интервала времени, необходимого для генерации каждого токена.
warningToken := uint64((float64(rule.WarmUpPeriodSec) * rule.Threshold) / float64(rule.WarmUpColdFactor-1))
maxToken := warningToken + uint64(2*float64(rule.WarmUpPeriodSec)*rule.Threshold/float64(1.0+rule.WarmUpColdFactor))
slope := float64(rule.WarmUpColdFactor-1.0) / rule.Threshold / float64(maxToken-warningToken)
//Разрешить подсчет количества переданных запросов. Когда restToken=warningToken, процесс прогрева завершается.
if restToken >= int64(c.warningToken) {
aboveToken := restToken - int64(c.warningToken)
warningQps := math.Nextafter(1.0/(float64(aboveToken)*c.slope+1.0/c.threshold), math.MaxFloat64)
return warningQps
} else {
return c.threshold
}
Ниже приведены условия производства токенов:
- Достигнут порог alertToken: то есть фаза прогрева заканчивается и достигается указанный порог.
- Количество переданных запросов passQps ниже Threshold/coldFactor: условия предварительного нагрева не соблюдены и токены производятся нормально.
Подводя итог, можно сказать, что генерация токенов будет остановлена во время процесса предварительного нагрева при возникновении внезапного трафика. Этот процесс будет продолжать потреблять токены до тех пор, пока количество токенов в корзине не достигнет значения alertToken, затем предварительный нагрев завершится, и токены будут созданы снова.
oldValue := atomic.LoadInt64(&c.storedTokens)
if oldValue < int64(c.warningToken) {
newValue = int64(float64(oldValue) + (float64(currentTime)-float64(atomic.LoadUint64(&c.lastFilledTime)))*c.threshold/1000.0)
} else if oldValue > int64(c.warningToken) {
if passQps < float64(uint32(c.threshold)/c.coldFactor) {
newValue = int64(float64(oldValue) + float64(currentTime-atomic.LoadUint64(&c.lastFilledTime))*c.threshold/1000.0)
}
}
Процесс предварительного нагрева (вид справа налево на рисунке выше):
- Когда поток проходит меньше,Корзина токенов постоянно пополняется новыми токенами.,Потому что для не прогрелся порог (threshold/coldFactor) и количество израсходованных токенов меньше количества выделенных токенов,в ведре жетонов storeToken Постепенно заполняйтесь, близко к Оставайтесь стабильными после maxToken.
- Когда поток внезапно увеличивается,порог прогрева оборудования,В это время корзина токенов перестает генерировать новые токены.,Но поскольку запросы продолжают поступать,Токены в хранилище токенов постоянно расходуются.,привести к storeToken из верхнего правого угла maxToken в левый нижний угол warningToken двигаться.
- По истечении заданного времени прогрева емкость сегмента токенов достигает номера предупреждения alertToken. В это время значение параметра вышеToken равно 0. Прогрев завершен, и количество разрешенных запросов достигает максимального порога. В это время создаются токены. равны потребленным токенам. Пусть количество токенов в ведре остается стабильным.
Мы провели моделирование предварительного нагрева. Ниже приведен процесс моделирования. Если для параметра Threshold установлено значение 10, а для параметра codeFactor установлено значение 3, параметры изменяются со временем, как показано на рисунке ниже.
- Первая стадия: резкое увеличение потока,Обычный процесс холодного запуска,В это время storeToken переходит от максимального значения к alertToken.,Разрешенные проходы постепенно увеличиваются до определенного порога в 10.
- Второй этап: текущий этап ограничения, запросы, превышающие порог в 10, будут ограничены.
- Третий этап: объем запроса падает до 2, ниже Threshold/coldFactor (3.33), токены выделяются в storeToken нормально, а первичный ключ storeToken перестает увеличиваться после достижения maxToken. В это время запросы проходят нормально.
- Четвертый этап: поток снова внезапно увеличивается, повторяя процесс холодного запуска до достижения порога запроса на обеспечение.
- Пятая стадия: стадия ограничения тока
- Этап 6. Объем запроса падает до 4, что меньше порогового значения и превышает пороговое значение/coldFactor (3.33). На этом этапе storeToken обычно распределяет токены, если оно меньше, чем alertToken, и прекращает выделение токенов, когда оно больше. alertToken, но он будет основан на фактическом объеме запроса. Потребляйте токен, заставляя storeToen прыгать влево и вправо рядом с alertToken.
С помощью моделирования можно обнаружить, что при возникновении всплеска трафика количество запросов, которые фактически разрешены для прохождения, требует периода прогрева, прежде чем достигнет указанного порога. А по мере изменения фактического объема запросов процесс предварительного нагрева может продолжаться взад и вперед в соответствии с ожиданиями проекта предварительного нагрева.

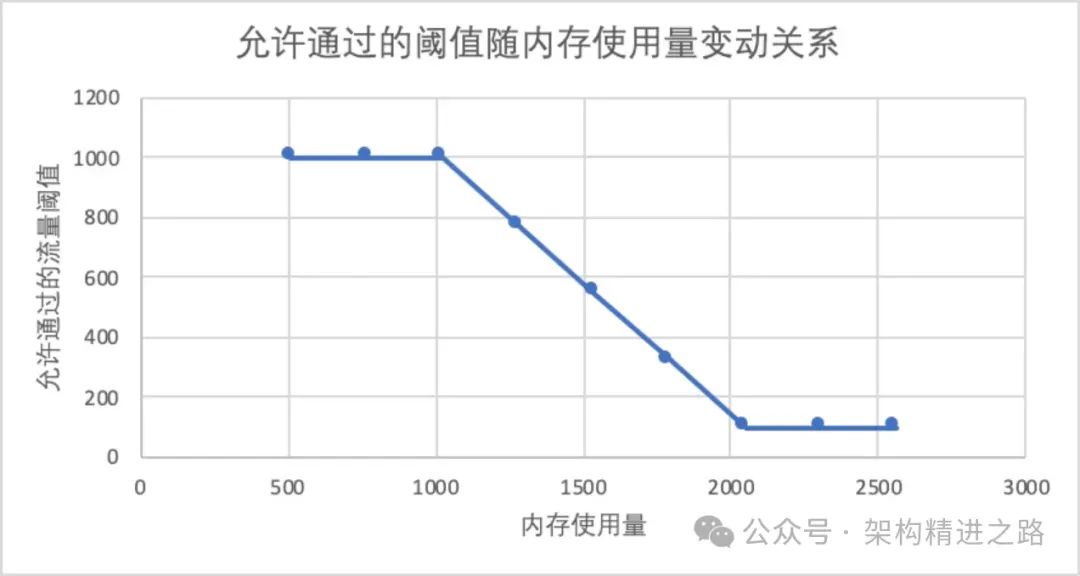
3.3 Адаптация памяти
Это метод расчета, который динамически регулирует количество токенов в зависимости от объема памяти, используемой машиной. Основная идея заключается в том, что когда память используется меньше, количество разрешенных запросов увеличивается, а когда памяти используется больше, количество разрешенных запросов будет меньше; Этот метод будет корректироваться линейно по мере увеличения использования памяти в соответствии с установленным пороговым диапазоном.
{
Resource: resName,
TokenCalculateStrategy: flow.MemoryAdaptive,
ControlBehavior: flow.Reject,
StatIntervalInMs: 1000,
LowMemUsageThreshold: 1000, // Порог ограничения расхода при низком уровне воды
HighMemUsageThreshold: 100, // Порог ограничения расхода при высоком уровне воды
MemLowWaterMarkBytes: 1024, // байты памяти нижней границы
MemHighWaterMarkBytes: 2048, // Байты памяти верхнего предела
}
В приведенной выше конфигурации график ниже показывает фактическое использование памяти в зависимости от количества разрешенных запросов. Однако в реальных онлайн-ситуациях в большинстве случаев увеличение объема ЦП происходит из-за увеличения объема запросов, а не из-за необходимости ограничения тока из-за внезапного увеличения использования памяти. Поэтому этот метод ограничения тока используется редко. или что-то в этом роде. Идея состоит в том, чтобы реализовать разработку метода ограничения тока, основанного на адаптивном методе ЦП.
4. Управление потоком
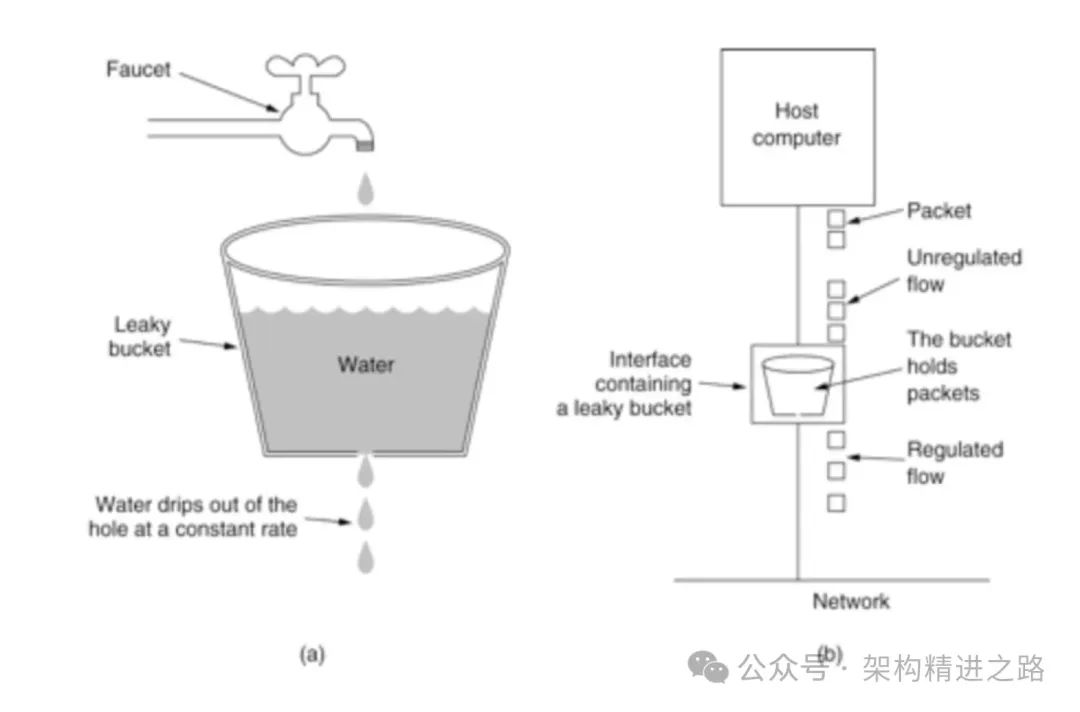
Согласно результатам текущего ограничивающего решения, обычно существует два метода для запросов, требующих управления потоком: один — напрямую отклонить запрос и вернуть код состояния HTTP 429, другой — заблокировать запрос, контролировать скорость запроса и; перезапустите через некоторое время. Выполните последующие операции запроса. Обычно используемый алгоритм — это алгоритм дырявого ведра.
Алгоритм дырявого ведра — это алгоритм формирования трафика, который можно использовать для сглаживания сетевого трафика и ограничения скорости передачи данных. Основной принцип заключается в передаче данных в «дырявое» ведро фиксированного размера с постоянной скоростью. Когда дырявое ведро заполнится, лишние данные переполнятся и будут удалены. Каждый раз, когда делается запрос, токен сначала извлекается из дырявого ведра. Если токенов недостаточно, запрос отклоняется.
В частности, алгоритм дырявого ведра поддерживает дырявое ведро фиксированного размера и передает данные с фиксированной скоростью. Всякий раз, когда поступает запрос, емкость дырявого ведра уменьшается на количество запрошенных данных. Если в этот момент пропускной способности недостаточно, запрос отклоняется, в противном случае пропускная способность остается неизменной, и запрос разрешается пройти.
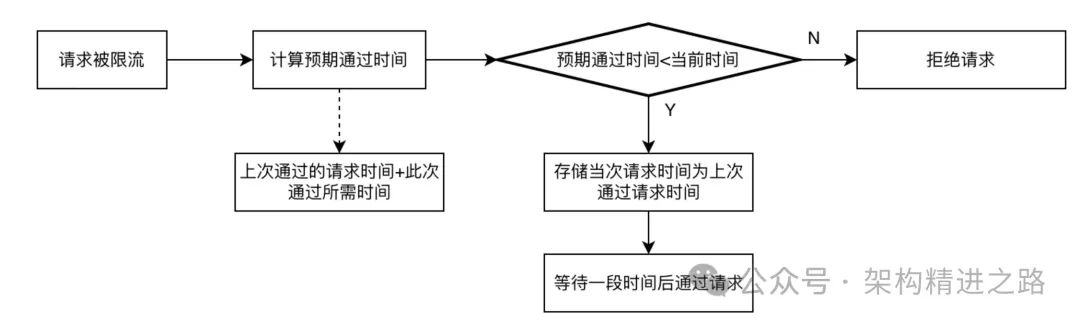
С точки зрения конкретной реализации размер сегмента определяется интервалом времени буферизации и размером интервала времени каждого запроса в очереди. Предположим, что интервал времени равен 1 с, время ожидания каждого запроса составляет 200 мс, весь сегмент. Размер равен 5, и 5 запросов могут быть помещены в буфер, поскольку последовательность запросов в очереди выполняется после сна, чтобы последующие запросы, превышающие лимит, будут напрямую отклонены.
Модульное тестирование дырявого сегмента: установите разрешенный интервал времени для сегмента равным 2 с, время ожидания каждого запроса в очереди на 200 мс, а значение состояния каждого запроса после ввода 15 запросов и время ожидания выполнения триггера будут следующими:
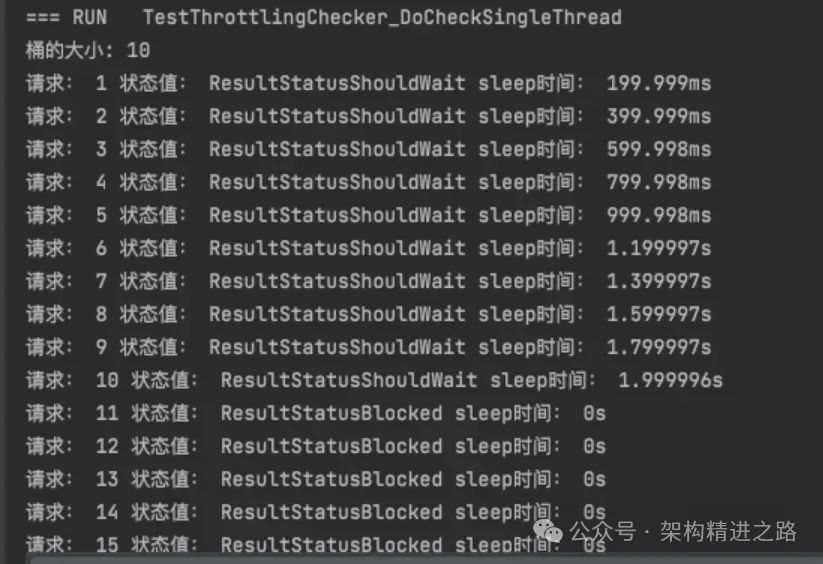
На данный момент мы завершили процесс проектирования полного набора систем ограничения тока. В процессе мы разработали основные сценарии применения, такие как счетчики, корзины токенов и принципы дырявого корзины, и объединили их соответствующие характеристики.
5. Приложение
В реальных бизнес-сценариях ограничение тока широко используется при флэш-продажах, розыгрышах мероприятий, шлюзах и других сценариях. Служба шлюза обычно используется для пересылки и предварительной обработки трафика. Ограничение тока также является неотъемлемой частью этой шлюзовой системы. Путем настройки часто используемых алгоритмов ограничения тока, таких как пороговые значения скользящего окна и предварительный нагрев, можно эффективно обеспечить поддержку возможности ограничения тока подключенной системы.
6. Резюме
В описанном выше процессе эта статья начинается с реальных бизнес-сценариев и обсуждает, как разработать полный набор систем ограничения тока с трех аспектов: статистика трафика, оценка ограничения тока и управление потоком. Также объясняется система ограничения тока путем объединения исходного кода. анализ, моделирование и другие средства. Роль каждого звена в ограничении тока.
В реальных бизнес-сценариях пороговые значения и текущие политики ограничения необходимо устанавливать соответствующим образом на основе реальных условий, чтобы избежать чрезмерных ограничений на запросы реальных пользователей. Текущая система ограничения является лишь средством обеспечения стабильности системы, а не целью. Поэтому необходимо сформулировать соответствующие текущие стратегии ограничения, основанные на реальных условиях, не только для обеспечения стабильности системы, но также для обеспечения удобства пользователей и преимуществ для бизнеса. Существующую систему ограничений необходимо постоянно оптимизировать и совершенствовать, чтобы лучше адаптировать к различным бизнес-сценариям и изменениям трафика.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
