Одна статья, чтобы понять отсутствие якоря и основу якоря при обнаружении целей.

CV - компьютерное зрение | ML - машинное обучение | RL - обучение с подкреплением | NLP обработка естественного языка
Эта статья предназначена только для академического обмена. Если есть какие-либо нарушения, свяжитесь с нами, чтобы удалить ее.
Автор丨Longchang Источник Просвещения丨Чжиху https://zhuanlan.zhihu.com/p/273646465 Редактор丨AiCharm
1.anchor base
Что такое метод обнаружения целей на основе привязки? Если бы вас попросили установить правило для кадрирования объекта на изображении, что бы вы сделали? Самый простой и самый жестокий метод — это, конечно, «метод поиска с фиксированным шагом». Если вы не знаете, что такое метод поиска с фиксированным шагом, это не имеет значения! Давайте сначала успокоимся, предположим, что у вас на фотографии есть кот, и вам нужно выделить его из кадра.

Один из самых простых способов подумать об этой проблеме. В качестве размера шага вы используете 16 пикселей и делите картинку на множество маленьких сеток 16×16 (а почему именно 16, мы поговорим позже). Вы не можете себе это представить? Вы когда-нибудь играли с головоломками, когда были ребенком? Наверное, это именно то, на что это похоже. Если вам повезет, большая часть тела вашей кошки должна поместиться в определенную коробку размером 16×16. Правильно, так что у нас по крайней мере есть рамка, чтобы «подставить» вашего кота.

Следовательно, первый разработанный вами алгоритм поиска объектов с фиксированным размером шага должен выглядеть так:
Нарисуйте на картинке множество прямоугольников с фиксированной высотой и шириной. Здесь мы сначала установили их в виде прямоугольников. Далее надейтесь, что ваш котенок прячется в одной из коробок, как показано на рисунке выше. Таким образом, вы сможете выделить свою кошку из картины. На этот раз для вас нужно сделать всего две вещи:
шаг 1. Согласно правилам построения сетки, вычислите координаты четырех точек всех сгенерированных блоков.
шаг 2. Для каждого поля определите, содержит ли оно слово «кот».
Step2 возвращает координаты ящика, содержащего кота. На данный момент вы получите окончательный результат.
Сканируйте круг, как указано выше, и кажется, что рядом с целью может быть прямоугольник, но проблема в том, что ваш объект слишком велик (например, «пропорции» вашей кошки на картинке слишком велики) (Это слишком большой), что делать, если я не помещаюсь в маленькую рамку?

Офигенный одноклассник в это время встанет: «Учитель, если ты не можешь справиться с маленькой рамкой, то поменяй ее на большую. Ну, похоже, самые продвинутые учёные ненамного умнее твоего приятеля». , Давайте использовать большую рамку для перемещения и меньшую рамку для перемещения...
Что это значит? Это означает, что на предыдущем этапе процесса «генерации сетки» каждая сетка будет иметь свой собственный центр, и каждая маленькая сетка может быть абстрагирована в прямоугольник с указанным размером 16 пикселей, сгенерированный в ее собственном центре. назовите эти центры «точками привязки», а прямоугольник в каждой точке привязки называется «коробкой привязки».

Теперь для каждой точки привязки, чтобы обнаружить котят, вам необходимо создать небольшой прямоугольник в каждой точке привязки, а для обнаружения больших кошек вы можете установить блок большего масштаба в положении каждой точки привязки. Попробуйте использовать рамку To. более крупные объекты:

На данный момент ваш алгоритм обнаружения целей должен быть разработан следующим образом.
Выберите определенные опорные точки на изображении с определенным размером шага. Нарисуйте несколько коробок фиксированной высоты и ширины, используя каждую центральную точку в качестве центра коробки. Далее вы надеетесь, что ваш котенок просто спрячется в коробке определенного масштаба, чтобы вы могли убрать свою кошку с картинки. рамка кончилась.
Здесь стоит отметить три момента:
1. По сравнению с алгоритмом, разработанным в прошлый раз, теперь мы требуем, чтобы контент, генерируемый изометрией, больше не был самим блоком, а точкой привязки. Мы по-прежнему требуем, чтобы точка привязки располагалась с шагом 16, но теперь мы этого не требуем. поле должно быть " "рядом с другим", мы только просим создать поле фиксированного размера в каждой точке привязки
2. Высота и ширина блока не обязательно должны соответствовать размеру шага, который вы установили для создания центра блока. В самом деле, как лучше всего согласовать расположение объектов на картинке? (Так устроено знаменитое йоло)
3. Всегда учтите, что наша задача — найти объекты на картинке, а правила оформления кадра — это всегда только наш собственный «дизайн».
Тогда у замечательных учеников всегда возникает много вопросов: «Учитель, вы говорите об этом коте. Он ходит горизонтально и вертикально. Уместно ли мне использовать рамку одного размера?» На самом деле, такая ситуация часто встречается в реальной жизни? Да, нельзя рассчитывать на то, что для обрамления всех объектов будет использоваться квадратная рамка, поэтому продвинутые учёные сказали: «Студенты, обратите внимание, я начну деформировать!» Так родился знаменитый метод, основанный на якорях!
Проще говоря, их подход заключается в том, что для каждого квадратного ящика с фиксированной высотой, умноженной на ширину, сохраняя при этом площадь постоянной, я могу установить высоту и ширину ящика в разных соотношениях (в конце концов, ваш дом, когда расстояние между кот и камера остаются постоянными, он будет только лежать или стоять, а общая площадь останется прежней, и площадь не станет внезапно больше или меньше...), как показано ниже:

Здесь мы по-прежнему рассматриваем создание опорных точек с размером шага 16. На данный момент, если предположить, что желтая опорная точка на изображении изначально создает поле привязки, представленное желтым прямоугольником, изначально она не может кадрировать объект. , если мы не только сгенерируем квадратный опорный кадр с этой областью, но также создадим кадр с той же площадью, что и он, но с соотношением сторон 2:1 в этой опорной точке, который может обрамлять кота.
В качестве отступления, здесь нарисовано только несколько полей привязки для отображения. На самом деле точки привязки очень плотные с размером шага 16 бит. На рисунке ниже представлен реальный вид.
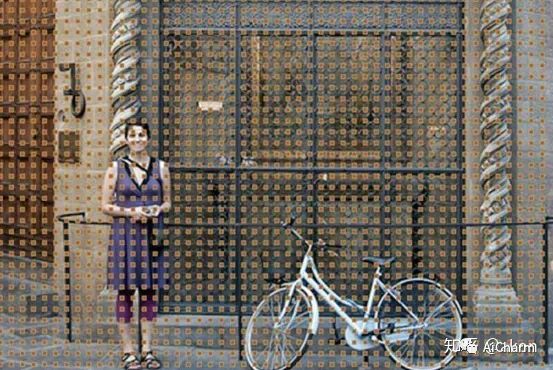
На этой основе наконец был получен следующий метод генерации якоря.
Выберите опорные точки на изображении с определенным размером шага. Создайте несколько кадров с фиксированной высотой и шириной, используя каждую центральную точку в качестве центра кадра, и для каждого кадра области создайте три новых кадра с разными соотношениями сторон (следующее все еще абсурдно). Далее Просто надейтесь, что ваш котенок окажется спрятаться в кадре с определенным соотношением сторон и в определенном масштабе, чтобы вы могли выставить своего кота из кадра.
Самая подробная картинка в Интернете, объясняющая этот процесс, такая:
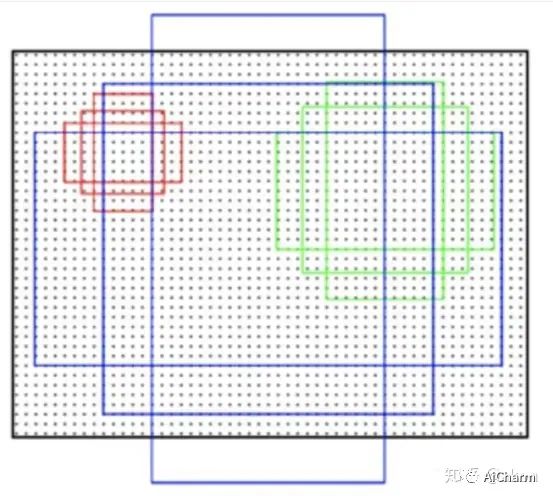
По сути, эта картина на самом деле очень обманчива. Если объяснять внимательно, то ее следует понимать так:
шаг1 Фоном является изображение. Плотные черные точки на изображении являются «точками привязки», определяемыми в соответствии с фиксированной длиной шага. шаг 2 В каждой опорной точке будут созданы квадратные рамки трех размеров (красные, зеленые и синие). шаг 3 Для каждого квадратного блока будут созданы два расширенных масштабных блока (два других прямоугольника каждого цвета). шаг4 Таким образом, в каждой точке привязки будет создано 9 якорей.
Так что, вероятно, это выглядит так
Процесс якоря и глубокое обучение не имеет ничего общего. Накройте вас в конечном объекте.
Недостатки базы Anchor
1. Производительность обнаружения очень чувствительна к размеру, соотношению сторон и количеству полей привязки, поэтому гиперпараметры, связанные с полями привязки, необходимо тщательно настраивать.
2. Размер и соотношение сторон поля привязки фиксированы. Поэтому детектору трудно обрабатывать объекты-кандидаты с большими деформациями, особенно для небольших целей. Предопределенные поля привязки также ограничивают возможности детекторов по обобщению, поскольку они должны быть разработаны для объектов разных размеров или соотношений сторон.
3. Чтобы повысить скорость запоминания, на изображении необходимо разместить плотные якорные рамки. Большинство этих якорных ячеек принадлежат отрицательным образцам, что вызывает дисбаланс между положительными и отрицательными образцами.
4. Большое количество полей привязки увеличивает объем вычислений и использование памяти при расчете коэффициента пересечения и объединения.
2.anchor free
Всего существует три метода обнаружения целей на основе отсутствия якоря.
(1) Обнаружение цели без якоря на основе угловых точек
(2) Алгоритм обнаружения цели без якоря на основе центральной точки
(3) Обнаружение цели без якоря на основе полной свертки
(1) Обнаружение цели без якоря на основе угловых точек
Методы обнаружения объектов на основе углов объединяют пары угловых точек, полученные из карт объектов. предсказать ограничивающую рамку. Этот метод не требует проектирования анкерных ящиков. Уменьшает различные расчеты для якорных ящиков, Таким образом, это становится более эффективным способом создания высококачественных границ. Угловой анкер бесплатное обнаружение целей Модели в основном включают в себяCornerNetиCornerNetоптимизацияCornerNet-Lite.
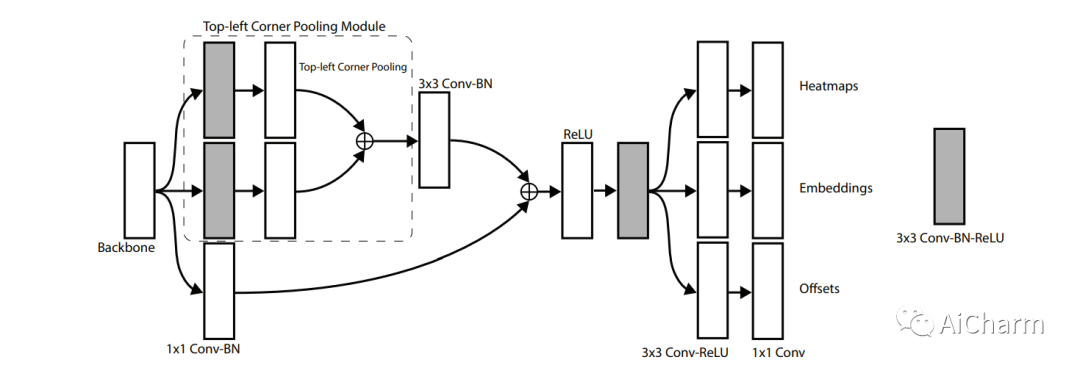
Общая идея сети CornerNet заключается в том, чтобы сначала извлечь функции через сеть «Песочные часы», а затем ввести функции, полученные сетью, в два модуля: объединение верхнего левого угла и объединение нижнего правого угла для извлечения характеристик ключевых точек. . Для каждого угла Модуль объединения классифицирует ключевые точки в верхнем левом углу и правом нижнем углу целевого кадра (тепловые карты), находит пару ключевых точек (встраивания) для каждой цели и уменьшает смещение при обратном вычислении целевой позиции на основе по координатам (смещения). Общая структурная схема сети выглядит следующим образом:
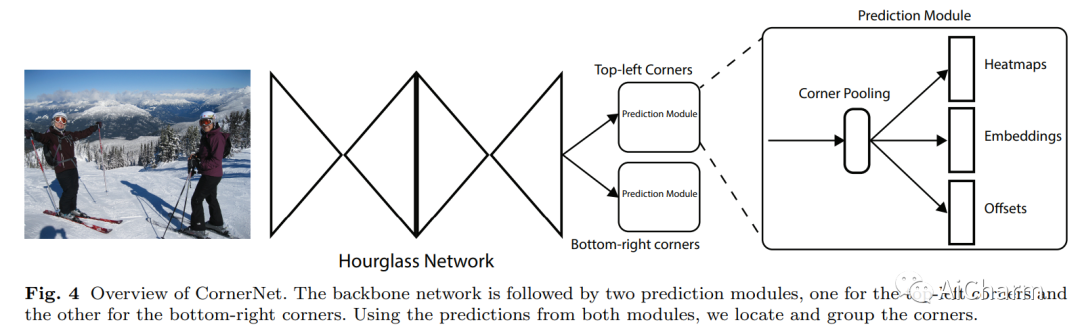
Очевидно, что ядро CornerNet состоит из четырех частей:
· Объединение двух углов
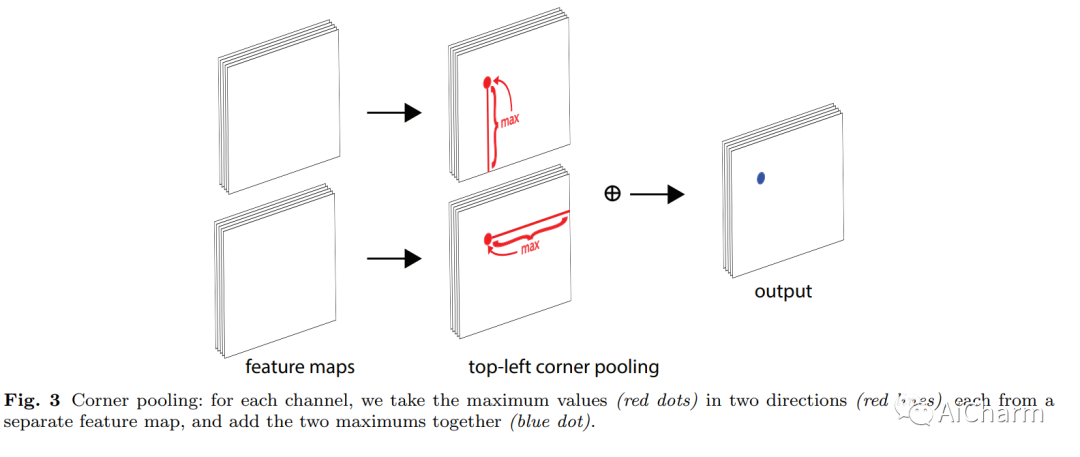
На рисунке ниже показана схематическая диаграмма объединения в верхнем левом углу. Чтобы характеристики ключевых точек могли характеризовать характеристики целевой области, содержащиеся в ключевых точках в верхнем левом углу и правом нижнем углу, автор предложил. Стратегия объединения углов, как показано ниже, например следующая. Как показано на рисунке, чтобы найти характеристики ключевой точки верхнего левого угла, вам необходимо найти максимальное значение левой области в той же строке текущего ключа. точку и максимальное значение нижней области в том же столбце и добавьте два максимальных значения, чтобы получить текущую позицию ключевой точки в верхнем левом углу.
· Модуль тепловых карт
С помощью модуля «Тепловые карты» сеть прогнозирует категорию, к которой принадлежит каждая ключевая точка. Функция потерь, используемая в этом процессе, выглядит следующим образом:
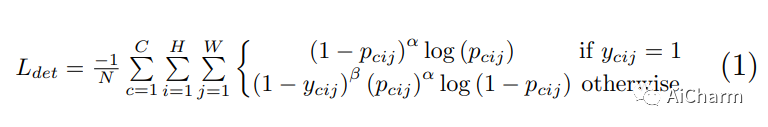
Приведенная выше формула представляет собой функцию потерь для прогнозирования угловых точек (карты головы) и, как правило, представляет собой улучшенную версию потери фокуса. Значение нескольких параметров:
Представляет прогнозируемые тепловые карты в c-м канале (категория c).
Стоимость позиции,
представляет основную истину соответствующей позиции, а N представляет количество целей.
Функция потерь в то время легко понять: это фокусная потеря. Параметр α используется для контроля веса потерь трудно классифицируемых образцов;
Выражается при равенстве другим значениям
Логически говоря, в данный момент эта точка не является целевой угловой точкой категории c.
должно быть 0 (так обрабатывает большинство алгоритмов), но здесь
Оно не равно 0, а рассчитывается с использованием распределения Гаусса на основе угловых точек основной истины, поэтому оно относительно близко к основной истине.
точка точка
При значении, близком к 1, эта часть контролирует вес через параметр β, который отличается от потери фокуса. Зачем использовать функции потерь с разными весами для разных отрицательных точек выборки? Это связано с тем, что кадр прогнозирования, состоящий из неправильно обнаруженных углов, близких к основной истине, по-прежнему будет иметь большую область перекрытия с основной истиной, как показано на рисунке ниже.

На рисунке красная сплошная рамка представляет собой основную истину; оранжевый кружок нарисован на основе верхней левой угловой точки, нижней правой угловой точки и установленного значения радиуса основной истины. Радиус основан на сформированной сумме ячеек. по угловым точкам в круге. Значение IOU основной истины установлено больше 0,7. Значения точек в круге представляют собой двумерное распределение Гаусса от центра зеленой пунктирной линии; — это поле предсказания. Вы можете видеть две угловые точки этого поля предсказания и землю. На самом деле это не пересекается, но поле прогнозирования в основном определяет цель, поэтому это полезное окно прогнозирования, поэтому необходимо возвращать потери с определенным весом. Вот почему для разных функций потерь используются разные значения веса. отрицательные точки выборки.
· Модуль встраивания
При прогнозировании категорий ключевых точек в модуле Headmaps невозможно узнать, какие две ключевые точки могут составлять цель, поэтому поиск двух ключевых точек цели является работой по внедрению модуля.
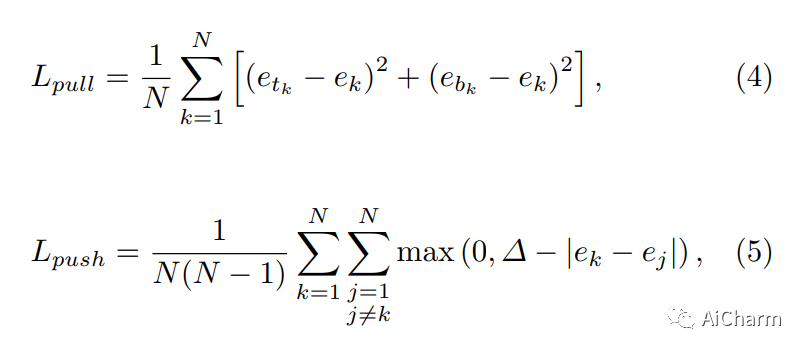
Обучение этой части внедрения достигается с помощью двух функций потерь, которые представляют вектор внедрения верхней левой угловой точки, принадлежащей целевой k-категории, и представляют собой вектор внедрения ключевой точки в нижнем правом углу, принадлежащей k -цель категории, представляющая среднее значение и . Формула 4 используется для уменьшения вектора внедрения (и расстояния) двух ключевых точек, принадлежащих одной и той же цели (цель k-типа). Формула 5 используется для увеличения вектора внедрения двух угловых точек, которые не принадлежат одной и той же цели. цель.
· Модуль смещений
Этот модуль в основном используется для компенсации потери точности при обратном вычислении исходных положений ключевых точек из-за карты объектов, полученной путем понижения дискретизации сети. Как показано в следующей формуле, из-за округления в меньшую сторону произойдет потеря точности, и автор использует потерю L1, чтобы уменьшить эту потерю точности.
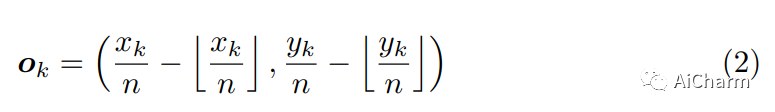
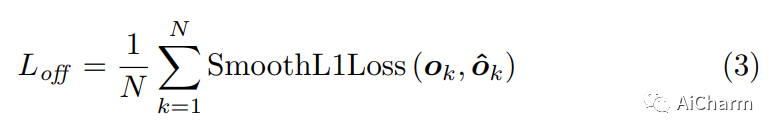
Наконец, как показано на рисунке ниже, результаты сети для верхней половины ветви следующие. В конечном итоге сеть состоит из двух ветвей.
(2) Алгоритм обнаружения цели без якоря на основе центральной точки
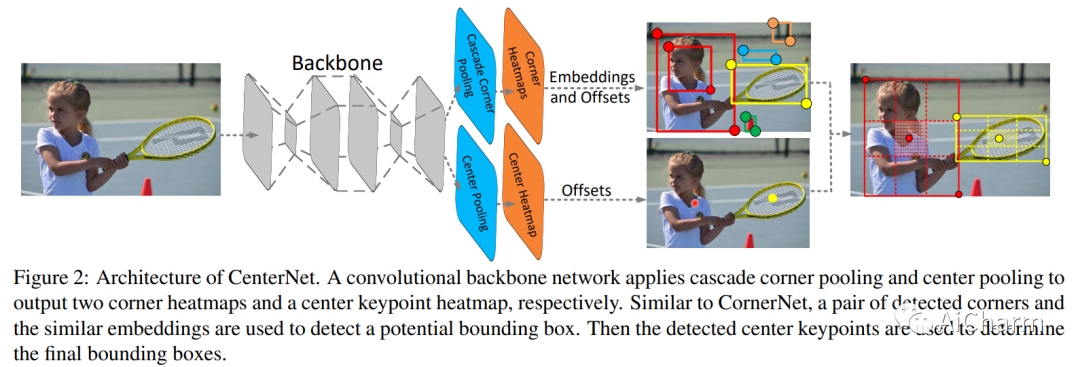
Метод обнаружения цели, основанный на центральной точке, предназначен для прогнозирования вероятности того, что каждая позиция карты объектов является центральной точкой цели. И спрогнозируйте ограничивающую рамку без предварительной рамки привязки. Привязка по центральной точке бесплатное обнаружение T Модели в основном включают в себя вещество (центральная точка и угловая точка) и CenterNet (центральная точка)
Сеть CenterNet (центральная и угловая точки) в основном основана на проблемах, существующих в сети CornerNet, и представляет собой сеть, основанную на обнаружении целей по ключевым точкам. На данный момент он достигает самого высокого MAP среди одноэтапных алгоритмов. Автор CenterNet обнаружил, что CornerNet определяет цель, обнаруживая верхнюю левую угловую точку и нижнюю правую угловую точку объекта. Однако в этом процессе CornetNet использует объединение углов, чтобы извлечь только особенности целевого края, что вызывает CornetNet. производить множество ложных срабатываний. Основываясь на этом, CenterNet использует тройку ключевых точек, а именно центральную точку, ключевую точку в левом верхнем углу и ключевую точку в правом нижнем углу, вместо двух точек для определения цели, что позволяет сети получать внутренние характеристики цели. . В документе CornerNet также говорится, что наиболее важной частью ограничения производительности сети является извлечение ключевых точек, поэтому CenterNet предложила центральное объединение и каскадное угловое объединение, чтобы лучше извлекать три ключевых момента, предложенных в этой статье.
1) Тройное предсказание
Как показано на рисунке ниже, сеть получает категории ключевых точек в левом верхнем и правом нижнем углах посредством каскадного объединения углов. И получите категорию ключевой точки центральной точки посредством объединения центров. Затем используются смещения для максимально точного сопоставления трех позиций ключевых точек с соответствующими позициями входного изображения, и, наконец, используются встраивания, чтобы определить, принадлежат ли три точки к одной и той же цели.
При прогнозировании объектов центральной точки определите центральную область для каждого поля прогнозирования и определите, содержит ли центральная область каждого целевого блока центральную точку. центральная точка, а верхний левый угол является ключевым. Среднее значение достоверности между точкой и ключевой точкой в правом нижнем углу. В противном случае оно будет удалено. Очевидно, что для центральной области каждого блока прогнозирования нам необходимо адаптировать ее к размеру блока прогнозирования, потому что, если центральная область слишком мала, мелкомасштабные неправильные блоки прогнозирования не могут быть удалены, и если центральная область слишком велико, крупномасштабные поля предсказания ошибок не будут удалены. Неправильно предсказанные поля удалить невозможно. Поэтому автор предлагает следующие стратегии:
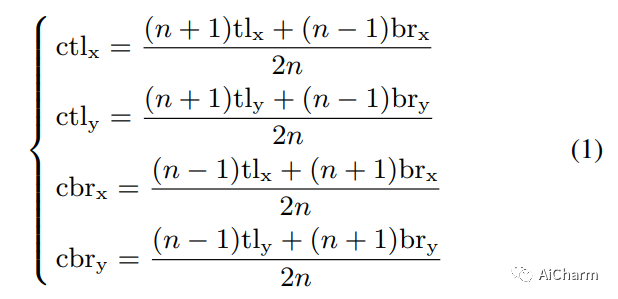
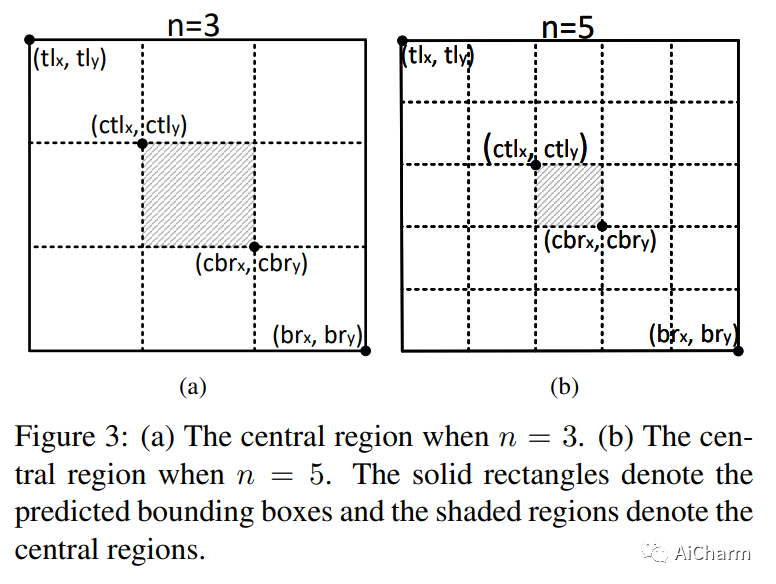
Как показано на рисунке выше, когда размер окна предсказания больше, площадь полученной нами центральной области также станет меньше, и, соответственно, когда размер окна предсказания меньше, площадь Центральная площадь также станет больше.
2)Center Pooling
На основе серии идей Corner Pooling автор предложил идею Center Pooling, чтобы особенности центральной точки, извлеченные сетью, могли лучше характеризовать целевой объект.
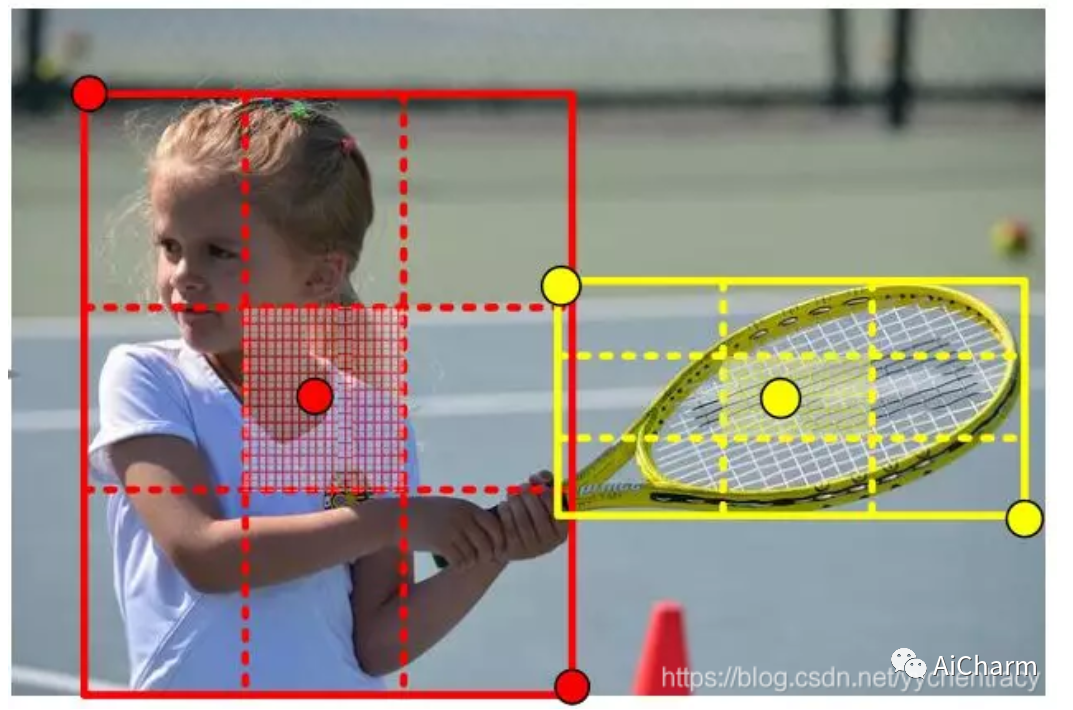
Центр объекта не обязательно содержит четкую семантическую информацию, которую легко отличить от других категорий. Например, голова человека содержит сильную смысловую информацию, которую легко отличить от других категорий, но ее центр часто располагается посередине человека. Мы предлагаем объединение центров для обогащения функций центральной точки. На рисунке выше показан принцип метода. Объединение центров извлекает максимальное значение центральной точки в горизонтальном и вертикальном направлениях и складывает их вместе, чтобы предоставить центральной точке информацию, отличную от ее местоположения. Эта операция дает центральной точке возможность получить смысловую информацию, которую легче отличить от других категорий. Центральное объединение может быть достигнуто за счет сочетания угловых объединений в разных направлениях. Операцию максимального значения в горизонтальном направлении можно реализовать последовательным объединением слева и справа. Аналогично, операцию максимального значения в вертикальном направлении можно реализовать путем последовательного объединения сверху и снизу, как показано на рисунке 6.
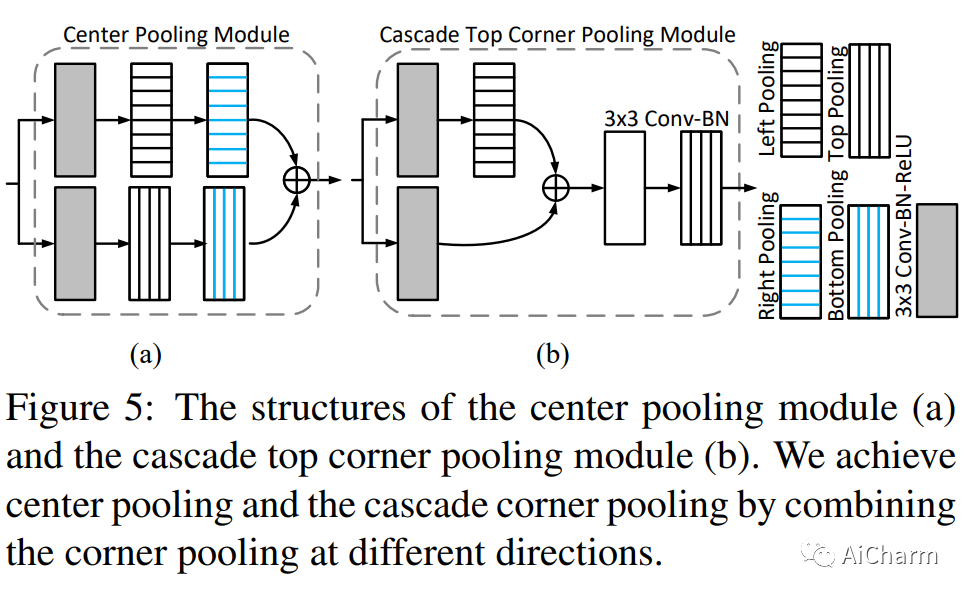
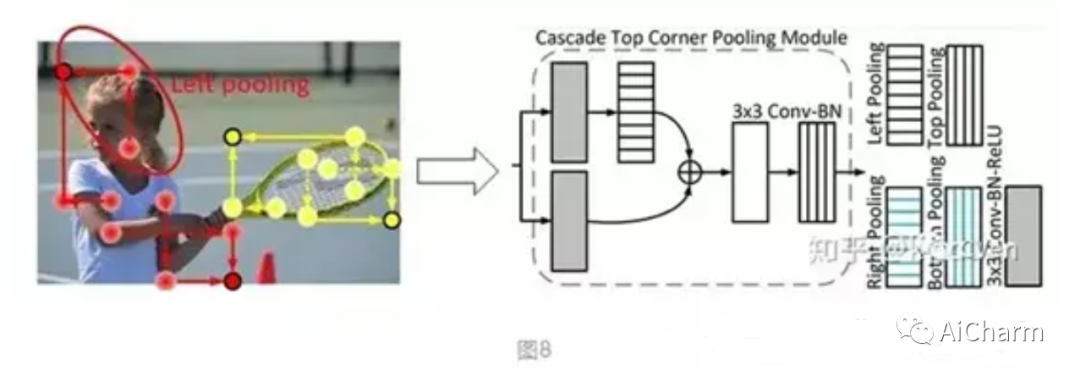
3)cascade corner Pooling
На основе серии идей Corner Pooling автор предложил идею каскадного Corner Pooling, чтобы особенности центральной точки, извлеченные сетью, могли лучше характеризовать целевой объект.
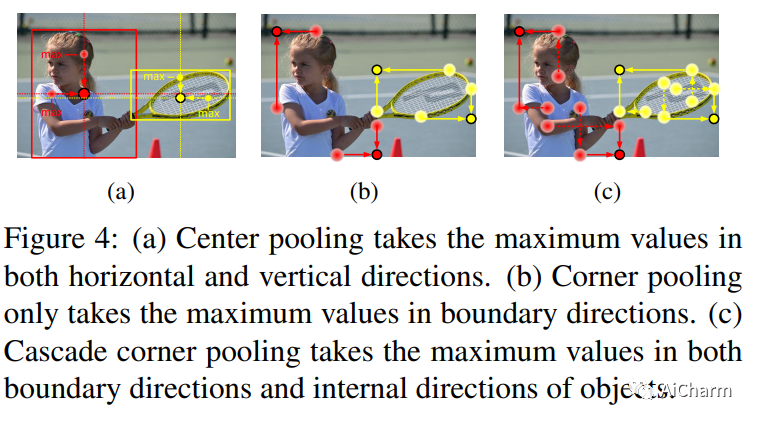
Как правило, угловые точки расположены вне объекта, и их местоположения не содержат семантической информации, связанной с объектом, что затрудняет обнаружение угловых точек. На рисунке выше (б) показан традиционный метод, называемый «угловым объединением». Он извлекает максимальное значение границы объекта и добавляет его. Этот метод может предоставить только семантическую информацию, относящуюся к краю объекта, и трудно извлечь более богатую внутреннюю семантическую информацию объекта. На рисунке (c) выше показан принцип каскадного группирования углов. Сначала извлекается максимальное значение границы объекта, а затем продолжается извлечение максимального значения на максимальном значении границы внутрь (в направлении пунктирной линии на рисунке). ) и добавляет его к максимальному значению границы. Предоставляет угловым объектам более подробную семантическую информацию о связанных объектах. Каскадное объединение углов также может быть достигнуто за счет комбинации объединения углов в разных направлениях, как показано на рисунке 8. На рисунке 8 показан принцип каскадного объединения левых углов.
Наконец, CenterNet добавил прогнозирование центральных точек и изменил метод извлечения признаков ключевых точек на основе CornerNet, что значительно уменьшило ошибочное обнаружение сети и позволило добиться лучших результатов в одноэтапной серии алгоритмов.
(3) Полностью основанный на свертке якорь бесплатное обнаружение целей
Подробное введение FCOS
1) Преимущества FCOS
1. FCOS унифицирован со многими идеями на основе FCN, поэтому идеи для этих задач можно легче использовать повторно.
2. Детектор реализует предложение без привязки и без якоря, что значительно сокращает количество проектных параметров. Параметры проектирования часто требуют эвристической корректировки, и при проектировании существует множество хитростей. Кроме того, устраняя поля привязки, новый детектор полностью позволяет избежать сложных вычислений IOU и сопоставления между полями привязки и реальными ограничивающими рамками во время обучения, а также сокращает общий объем обучающей памяти примерно в 2 раза.
3. FCOS может использоваться в качестве сети предложения регионов (RPN) для детекторов второго порядка, и ее производительность значительно лучше, чем у алгоритма RPN на основе привязки.
4. FCOS можно расширить для решения других задач машинного зрения с минимальными изменениями, включая сегментацию экземпляров и обнаружение ключевых точек.
2) Подробное введение в алгоритм
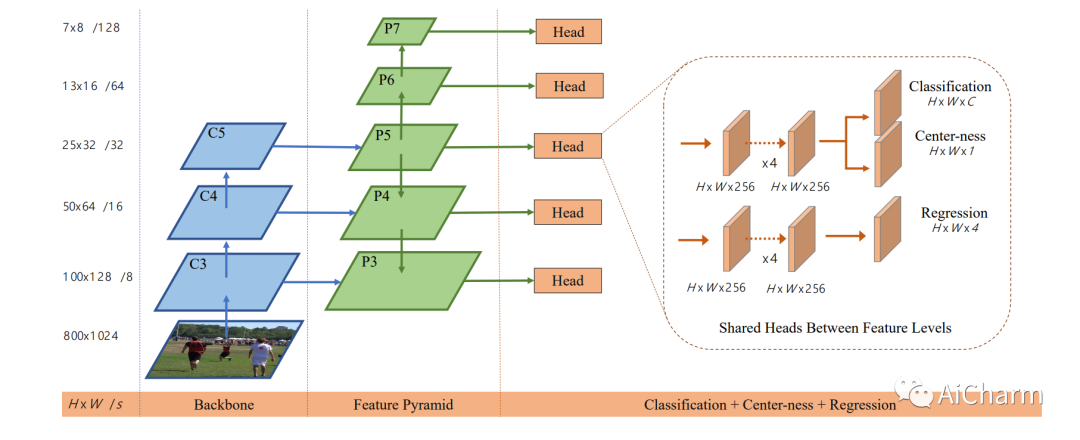
1. Полностью сверточный детектор первого порядка.
FCOS сначала использует Backone CNN (CNN магистральной архитектуры, используемую для извлечения функций), а � — общее количество шагов перед картой функций.
Отличия от якорных детекторов
Первый пункт
· Алгоритм на основе привязки использует положение входного изображения в качестве центральной точки поля привязки и выполняет регрессию для этих полей привязки.
· FCOS напрямую регрессирует ограничивающую рамку, соответствующую исходному изображению, в каждой позиции на карте объектов. Другими словами, FCOS напрямую использует каждую позицию в качестве обучающей выборки. Это то же самое, что и FCN для семантической сегментации.
Соответствующая связь между позицией на карте объектов алгоритма FCOS и исходным изображением. Если позиция на карте объектов равна (x, y), позиция, сопоставленная с входным изображением, равна.
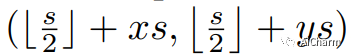
Второй пункт
· В процессе обучения алгоритм на основе привязки маркирует выборки следующим образом: если коэффициент пересечения между соответствующим кадром привязки и основной истиной превышает определенный порог, он устанавливается как положительная выборка, а категория с наибольшей Коэффициент пересечения указан как категория для этого местоположения.
· В FCOS, если позиция (x, y) попадает в любую реальную ограничивающую рамку, она считается положительной выборкой, и ее класс помечается как класс этой реальной ограничивающей рамки.
Это вызовет проблему. Если аннотированные реальные границы перекрываются и позиция (x, y) отображается на несколько реальных границ в исходном изображении, эта позиция считается нечеткой выборкой. Мы поговорим об использовании многоуровневого прогнозирования. позже решение состоит в том, чтобы решить проблему нечетких выборок.
Третий пункт
· Предыдущие алгоритмы обучали многомерный классификатор
· FCOSтренироватьсяCдвоичный классификатор(Cэто количество категорий)
Сходство с якорными детекторами
Подобно алгоритму на основе якоря, цель обучения алгоритма FCOS также включает в себя две части: местоположение и категорию.
Функция потерь алгоритма FCOS:
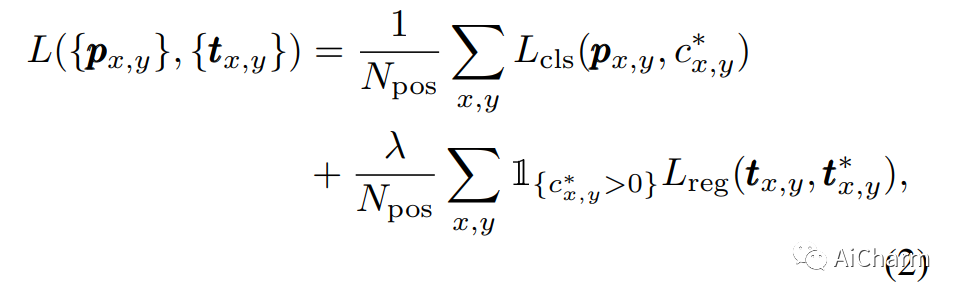
Среди них потеря категории L_cls, потеря пересечения L_reg и потеря коэффициента объединения.
2. Используйте FPN для многоуровневого прогнозирования FCOS.
Сначала проясните два вопроса:
1. Детектор якорной базы имеет низкую скорость отзыва из-за большого шага, который необходимо компенсировать за счет уменьшения показателя коэффициента пересечения, требуемого для положительного якоря: в алгоритме FCOS показано, что своевременные шаги также могут получить лучшую скорость запоминания и может быть даже лучше, чем детектор якорной базы.
1. Перекрытие в реальных ограничивающих прямоугольниках может вызвать неуправляемую неоднозначность во время обучения, и эта неоднозначность приводит к ухудшению производительности детекторов на основе fcn: в FCOSzhong метод многоуровневого прогнозирования может эффективно решить проблему неоднозначности с привязкой по сравнению с базовым нечеткий детектор, нечеткий детектор на основе нечеткого контроллера имеет лучшую производительность.
Как упоминалось ранее, чтобы решить проблему двусмысленности и низкой скорости отзыва, вызванную реальным перекрытием границ, FCOS использует многоуровневое обнаружение, аналогичное FPN, которое обнаруживает цели разных размеров на разных уровнях слоев объектов.
Отличия от коробки привязки
· Детекторы на основе полей привязки назначают поля привязки разных размеров разным уровням векторных слоев.
FCOS назначает путем прямого ограничения диапазона регрессии ограничивающих рамок на разных уровнях объектов.
Кроме того, FCOS распределяет информацию между различными векторными слоями, что не только повышает эффективность параметров детектора, но и повышает производительность обнаружения.
3.Center-ness

После многоуровневого прогнозирования было обнаружено, что между FCOS и детекторами на основе якорного ящика все еще существует определенное расстояние. Основная причина заключается в том, что многие прогнозируемые границы низкого качества генерируются далеко от центра цели.
В FCOS предлагается простая, но эффективная стратегия для подавления этих прогнозируемых ограничивающих рамок низкого качества без введения каких-либо гиперпараметров. В частности, FCOS добавляет одноуровневую ветвь параллельно с ветвью классификации для прогнозирования местоположения «центральности».
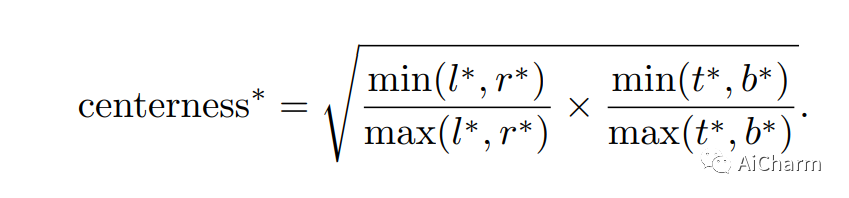
Центрированность (можно понимать как концепцию с функцией измерения, называемой здесь «центральностью»), значение центральности находится в диапазоне от 0 до 1, а потеря перекрестной энтропии используется для обучения. И добавьте потерю к упомянутой ранее функции потерь. Во время тестирования прогнозируемая центральность умножается на соответствующую оценку классификации для расчета окончательной оценки (используется для ранжирования обнаруженных ограничивающих рамок). Таким образом, центральность может уменьшить вес ограничивающих рамок, расположенных далеко от центра объекта. Следовательно, эти ограничивающие рамки низкого качества, скорее всего, будут отфильтрованы финальным процессом немаксимального подавления (NMS), что значительно улучшает производительность обнаружения.
3. На основе сегментации
Mask-RCNN
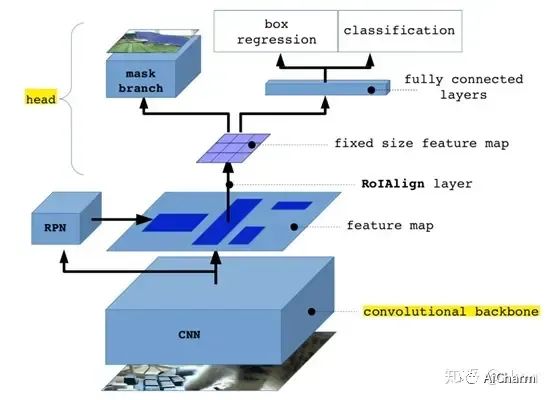
В чем новшество?
· Улучшения в рентабельности инвестиций и предложенном RoIAlign
· Чтобы решить проблему смещения пикселей, используется билинейная интерполяция для более точного поиска соответствующих характеристик каждого блока.
В общем, основная функция RoI Align состоит в том, чтобы исключить операцию округления при объединении RoI и обеспечить лучшее совмещение функций, полученных для каждой RoI, с областью RoI на исходном изображении.
· Может быть легко распространен на другие задачи, такие как оценка позы человека и т. д.;
· Без помощи Хитрости эффект лучше, чем у всех текущих одиночных моделей по каждому заданию;
В чем проблема или контекст?
· От ROI на входной карте до объекта RoI на карте объектов, объединение ROI — это результат, полученный непосредственно путем округления. Каковы последствия этого?

Синяя часть на правом рисунке представляет собой квадрат, содержащий информацию о кузове автомобиля. Операция округления слоя пула RoI приводит к его смещению.
При преобразовании объектов, соответствующих каждой области интереса, в размеры фиксированного размера используется операция округления. Каковы последствия этого?
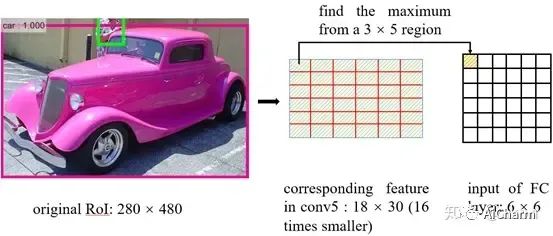
При получении соответствующей карты объектов из RoI выполняется округление, описанное в вопросе 1. Как после получения карты объектов получить входные данные полносвязного слоя 6×6? Объединение RoI делает следующее: делит карту объектов, соответствующую RoI, на блоки 6×6, а затем находит максимальное значение непосредственно из каждого блока. Например, в приведенном выше примере размер области интереса исходного изображения составляет 280×480, а соответствующая карта объектов — 18×30. Разделите карту объектов на 6 блоков, размер каждого блока — 3×5, а затем выберите максимальное значение в каждом блоке и поместите его в соответствующую область 6×6.
Эта операция округления (называемая квантованием в Mask R-CNN) мало влияет на классификацию RoI, но она вредна для цели попиксельного прогнозирования, поскольку признаки, полученные для каждой RoI, не совпадают с RoI. Таким образом, Mask R-CNN улучшает объединение RoI и предлагает RoI Align.
Что такое квантование?
Количественная оценка и оцифровка представляют собой целочисление в пулинге.
Mask R-CNN
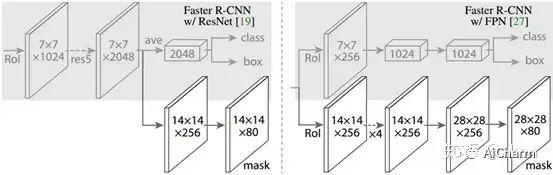
Как показано на рисунке выше, для создания соответствующей маски в статье предлагаются две архитектуры: Faster R-CNN/ResNet слева и Faster R-CNN/FPN справа. Для архитектуры слева наша магистральная сеть использует предварительно обученный ResNet и предпоследний уровень ResNet. Входная ROI сначала получает функцию ROI 7x7x1024, а затем увеличивает ее размерность до 2048 каналов (исходная архитектура сети ResNet здесь модифицирована), а затем имеет две ветви: верхняя ветвь отвечает за классификацию и регрессию, а нижняя ветвь. отвечает за создание соответствующей маски. Из-за предыдущей свертки и объединения, которые уменьшили соответствующее разрешение, ветвь маски начала использовать деконволюцию для улучшения разрешения, уменьшая при этом количество каналов до 14x14x256 и, наконец, выдавая шаблон маски 14x14x80.
Справа используется магистраль FPN. Это новая сеть. Введя одномасштабное изображение, можно наконец получить соответствующую пирамиду функций. Если вы хотите узнать ее подробности, обратитесь к документу. Было подтверждено, что эта сеть может в определенной степени повысить точность обнаружения, и ее используют многие современные методы. Поскольку сеть FPN уже содержит res5, она может использовать функции более эффективно, поэтому здесь используется меньше фильтров. Архитектура также разделена на две ветви, которые оказывают одинаковое влияние на первую, но ветвь классификации и ветвь маски сильно отличаются от первой. Возможно, это связано с тем, что сеть FPN может получить много полезной информации о признаках разных масштабов, поэтому при классификации используется меньше фильтров. В ветке маски выполняется несколько операций свертки. Сначала ROI меняется на объект 14x14x256, а затем та же операция выполняется 5 раз (принцип здесь не знаю, и жду вашего объяснения). а затем выполняется операция деконволюции. Наконец, выводится маска 28x28x80. То есть выводится маска большего размера, и можно получить более подробную маску по сравнению с прежней.
RoIAlign
· Можете ли вы сравнить RoIPooling и RoIAlign?
1)ROI Pooling
Самая большая разница между ROI Pooling и ROIAlign заключается в том, что первый использует две операции квантования, а второй не использует операции квантования и использует алгоритм линейной интерполяции. Конкретное объяснение следующее.
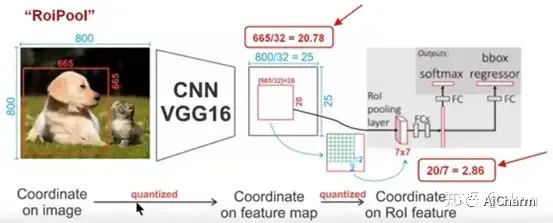
Как показано на рисунке выше: Чтобы получить карту объектов фиксированного размера (7X7), нам необходимо выполнить две операции количественной оценки: 1) координаты изображения — координаты карты объектов, 2) координаты карты объектов — координаты объекта ROI. Давайте поговорим о конкретных деталях. Как показано на рисунке, мы вводим изображение размером 800x800. На изображении есть две цели (кошки и собаки). Размер BB (ограничивающей рамки) собаки после прохождения через сеть VGG16. Мы можем получить соответствующую карту объектов. Если мы выполним операцию заполнения на сверточном слое, наше изображение сохранит свой первоначальный размер после прохождения через сверточный слой, но из-за существования слоя объединения мы наконец получим карту объектов. . Оно будет уменьшено на определенный коэффициент по сравнению с исходным изображением, который зависит от количества и размера слоя объединения. В этом VGG16 мы используем 5 операций объединения, каждая операция объединения — 2 объединения, поэтому мы в конечном итоге получаем размер карты объектов 800/32 x 800/32 = 25x25 (что является целым числом), но BB собаки (ограничивающий поле) соответствует карте объектов, и результат, который мы получаем, равен 665/32 x 665/32 = 20,78 x 20.78, результатом является число с плавающей запятой, содержащее десятичные дроби, но значение нашего пикселя не имеет десятичных знаков, поэтому автор выполняет над ним операцию квантования (т. е. операцию округления), то есть результат становится 20 х 20, здесь первая ошибка квантования; однако на нашей карте объектов есть ROI разных размеров, но сеть позади нас требует, чтобы у нас были фиксированные входные данные. Поэтому нам нужно преобразовать ROI разных размеров в фиксированные функции ROI, которые здесь используются. Рентабельность инвестиций 7x7 Функция, то нам нужно сопоставить ROI 20 x 20 с функцией ROI 7 x 7. Результат: 20/7. Давайте выполним округление, которое вносит вторую ошибку квантования. Фактически, введенная здесь ошибка приведет к отклонению между пикселями изображения и пикселями объекта. То есть будет большое отклонение в сопоставлении рентабельности инвестиций в пространстве признаков с исходным изображением. Причины следующие: например, используя для анализа ошибку, которую мы ввели во второй раз, первоначально мы определили ее как 2. В этот период была введена ошибка 0,86. Кажется, это очень маленькая ошибка. ошибка, но вы должны помнить, что это В пространстве признаков существует пропорциональное соотношение между нашим пространством признаков и пространством изображения. Здесь оно составляет 1:32, поэтому разрыв, соответствующий исходному изображению, составляет 0,86 x 32 = 27,52. Этот зазор не мал, и при этом учитывается только ошибка вторичного квантования. Это сильно влияет на производительность всего алгоритма обнаружения и поэтому является серьезной проблемой.
2)ROIAlign
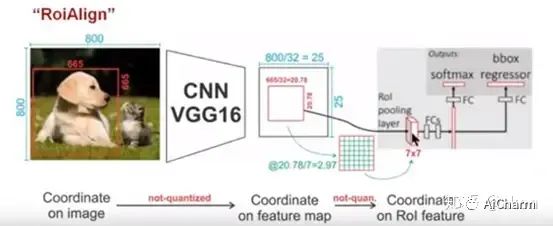
Как показано на рисунке: Чтобы получить карту объектов фиксированного размера (7X7), технология ROIAlign не использует операции квантования, то есть мы не хотим вводить ошибки квантования, такие как 665/32 = 20,78, мы используем 20,78, и не используйте для его замены 20. Например, 20,78/7 = 2,97, для замены мы используем 2,97. Это первоначальное намерение ROIAlign. Итак, как нам быть с этими числами с плавающей запятой? Наше решение — использовать алгоритм «билинейной интерполяции». Билинейная интерполяция — лучший алгоритм масштабирования изображения. Он полностью использует четыре действительные точки вокруг виртуальной точки в исходном изображении (например, 20,56, число с плавающей запятой, все позиции пикселей представляют собой целые значения, без значений с плавающей запятой). Значение пикселя совместно определяет значение пикселя в целевом изображении, то есть может быть оценено значение пикселя, соответствующее точке виртуального положения 20,56.
Конкретный метод показан на рисунке ниже:
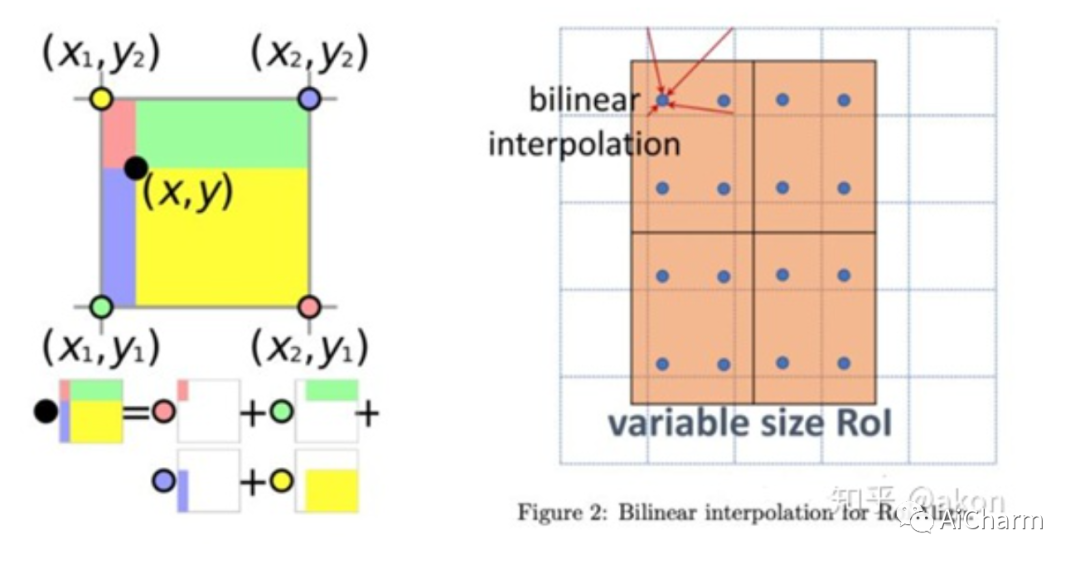
1. Разделите область bbox на равные части в соответствии с размером, необходимым для вывода. Очень вероятно, что после равного деления каждая вершина не попадет на реальную точку пикселя.
2. Выберите 4 фиксированные точки в каждом интервале (после экспериментов автор обнаружил, что 4 более эффективны), это синяя точка в правой части рисунка 2.
3. Для каждой синей точки взвесьте значения четырех ближайших к ней реальных пикселей (билинейная интерполяция), чтобы найти значение этой синей точки.
4. В бине будут рассчитаны четыре новых значения, и из этих новых значений будет взято максимальное значение в качестве выходного значения этого бина.
5. Наконец, вы можете получить результат 2x2.
билинейная интерполяция
1) Линейная интерполяция
Учитывая данные и , нам нужно вычислить значение y от x на прямой в определенной позиции интервала, как показано на рисунке ниже.
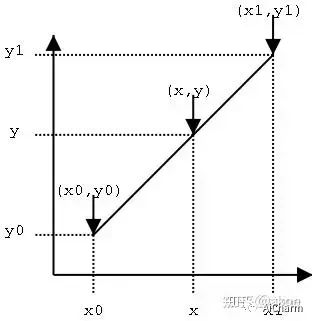
Метод расчета очень прост. Зависимость между y и x можно построить путем выравнивания наклонов следующим образом:
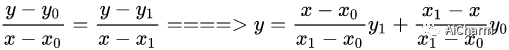
Если вы внимательно посмотрите, расстояние от , используется как вес (деление на – это функция нормализации), для
и взвешивания. Эта идея очень важна, потому что зная эту идею, понимая билинейную интерполяция очень проста.
2)билинейная интерполяция
билинейная интерполяция — это по сути линейная интерполяция в двух направлениях.
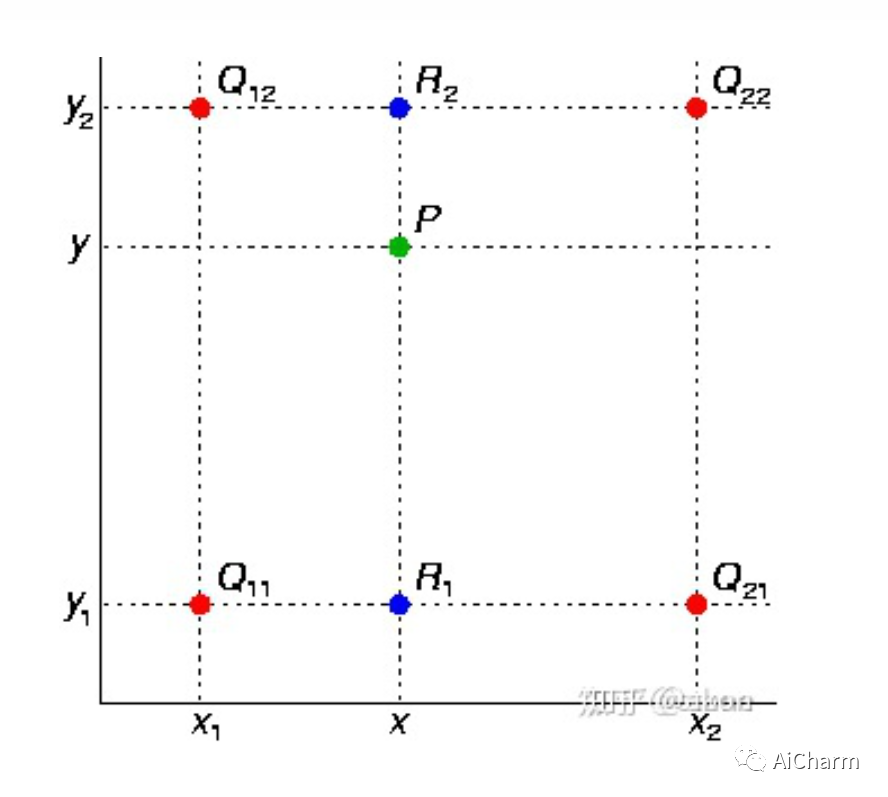
Как показано на рисунке, предполагая, что мы хотим получить интерполяцию точки P, мы можем сначала и Линейная интерполяция между , То же самое. затем в направлении и Выполните линейную интерполяцию, чтобы получить окончательный P. На самом деле, если вы это знаете, вы уже понимаете билинейную Значение мужской, если оно выражено в формуле, заключается в следующем (примечание f Предыдущие коэффициенты легко понять, если рассматривать их как веса).
первый в x Выполните линейную интерполяцию в направлении, чтобы получить
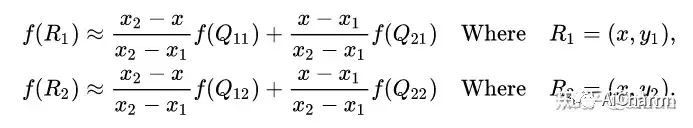
затем в y Выполните линейную интерполяцию в направлении, чтобы получить
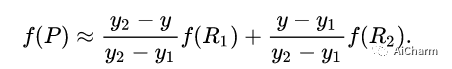
Это даст вам желаемый результат �(��,�)
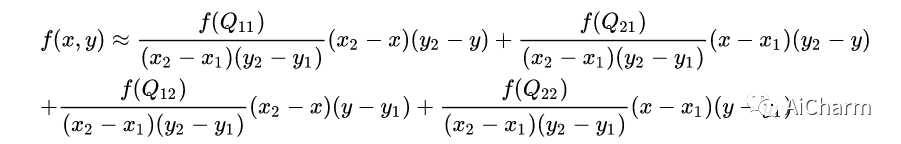
ссылка:Википедия:билинейная интерполяция
Каков принцип расчета Lmask в LOSS?
Благодаря добавлению ветви маски функция потерь каждой рентабельности инвестиций выглядит следующим образом:
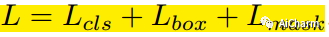
ви иFaster То же, что определено в r-cnn. Для каждой ROI ветвь маски имеет размерный выход, который кодирует маску размера , каждая маска имеет K категорий. Мы использовали попиксельный сигмовидная и будет определяется как average binary cross-entropy loss . Соответствует рентабельности инвестиций, принадлежащей k-й категории в GT, Он определяется только на k-й маске (выход других k-1 масок не вносит вклад в общую потерю).
что мы определяем Позволяет сети генерировать маску для каждого класса, не конкурируя с другими классами. Мы полагаемся на метки классов, предсказанные ветвью классификации, для выбора выходной маски. Это разлагает генерацию классификационной маски. Это отличается от использования FCN для семантической сегментации, где обычно используется попиксельная сигмовидный многочлен cross-entropy loss , в данном случае идет конкуренция между масками и так как мы используем попиксельную; sigmoid и двоичный файл loss , конкуренции между разными масками нет. Опыт показывает, что это улучшает сегментацию экземпляров.
Маска кодирует входное пространственное расположение объекта, метку категории и BB (ограничивающую box) смещения, им обычно необходимо пройти через слой FC, в результате чего он выводится в виде коротких векторов. Мы можем получить информацию о пространственной структуре маски через соответствие пикселей и пикселей, обеспечиваемое сверткой. В частности, мы используем FCN для прогнозирования маски размера на основе каждой области интереса, что позволяет каждому слою в ветви маски явно поддерживать пространственную компоновку, не сворачивая ее в вектор, лишенный пространственных измерений.
Отличие от предыдущего метода использования слоя fc для предсказания маски заключается в том, что наши эксперименты показывают, что наша маска требует меньше параметров и является более точной. Такое поведение от пикселя к пикселю требует наших функций рентабельности инвестиций, которые обычно представляют собой меньшие функции. карта, над которой проводилась операция. Чтобы последовательно и лучше поддерживать четкое однопиксельное пространственное соответствие, мы предложили операцию ROIAlign.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
