[Обзорная колонка] Угрозы, с которыми сталкиваются агенты ИИ: ключевые проблемы безопасности и пути будущего
В научных исследованиях, с методологической точки зрения, следует «видеть лес раньше деревьев». В настоящее время научные исследования в области искусственного интеллекта находятся на подъеме, и технологии быстро развиваются. Можно сказать, что тысячи деревьев конкурируют за процветание и меняются с каждым днем. Для практиков ИИ, находящихся в обширном лесу знаний, только систематически разбираясь в контексте, они могут лучше понять тенденции. С этой целью мы отобрали отличные обзорные статьи в стране и за рубежом и открыли «Колонку обзоров», так что следите за обновлениями.

Агент ИИ (ИИ) — программный объект,Он автономно выполняет задачи или принимает решения на основе заранее определенных целей и входных данных.。Агенты ИИ способны воспринимать вводимые пользователем данные, обдумывать и планировать задачи, выполнять действия и добились значительного прогресса в разработке алгоритмов и выполнении задач.。Однако,что они приносят Безопасность Проблемы остаются недостаточно изученными и недостаточно решенными。В этом обзоре подробно рассматривается возникающие угрозы безопасности, с которыми сталкиваются агенты ИИ, и они группируются по четырем ключевым пробелам в знаниях: непредсказуемость многоэтапного пользовательского ввода, сложность внутреннего выполнения, изменчивость операционной среды и взаимодействие с ненадежными объектами. взаимодействие внешних сущностей。Систематически рассматривая эти угрозы,В этой статье не только освещается прогресс, достигнутый в защите агентов ИИ.,Также выявлены существующие ограничения. Представленные идеи призваны стимулировать дальнейшие исследования.,Для устранения угроз безопасности, связанных с агентами ИИ.,Тем самым способствуя разработке более надежных и безопасных приложений-агентов искусственного интеллекта. https://www.zhuanzhi.ai/paper/2cdbfa599ada6be5d12a7ba7d7606445
Агенты искусственного интеллекта (ИИ) — это вычислительные объекты, которые демонстрируют разумное поведение благодаря автономии, реактивности, инициативе и социальным возможностям.。они чувствуют входные данные、логические задачи、Планируйте действия и используйте внутренние и внешниеинструментвыполнять задачи,Взаимодействуйте со своей средой и пользователями для достижения конкретных целей. Агенты искусственного интеллекта на базе крупномасштабных языков (LLM), таких как GPT-4.,Он произвел революцию в способах выполнения задач в различных областях, включая медицину, финансы, обслуживание клиентов и интеллектуальные операционные системы. Эти системы используют расширенные возможности LLM в рассуждениях, планировании и действиях.,Позволяя им выполнять сложные задачи с превосходной производительностью.
https://www.zhuanzhi.ai/paper/2cdbfa599ada6be5d12a7ba7d7606445
Хотя агенты ИИ добились значительного прогресса, их растущая сложность также создала новые проблемы безопасности.。потому чтоAIАгенты развертываются в различных критически важных приложениях.,Крайне важно обеспечить его Безопасность. Безопасность агентов ИИ — это меры и практики, предназначенные для защиты агентов ИИ от уязвимостей и угроз, которые могут поставить под угрозу их функциональность, целостность и безопасность. Это включает в себя обеспечение того, чтобы агент мог обрабатывать ввод пользователя, выполнять задачи,и взаимодействовать с другими сущностями,не будучи уязвимым для злонамеренных атак или случайного вредного поведения. Эти проблемы безопасности возникают из-за четырех пробелов в знаниях.,если не решить,Может привести к уязвимостям и потенциальным злоупотреблениям.
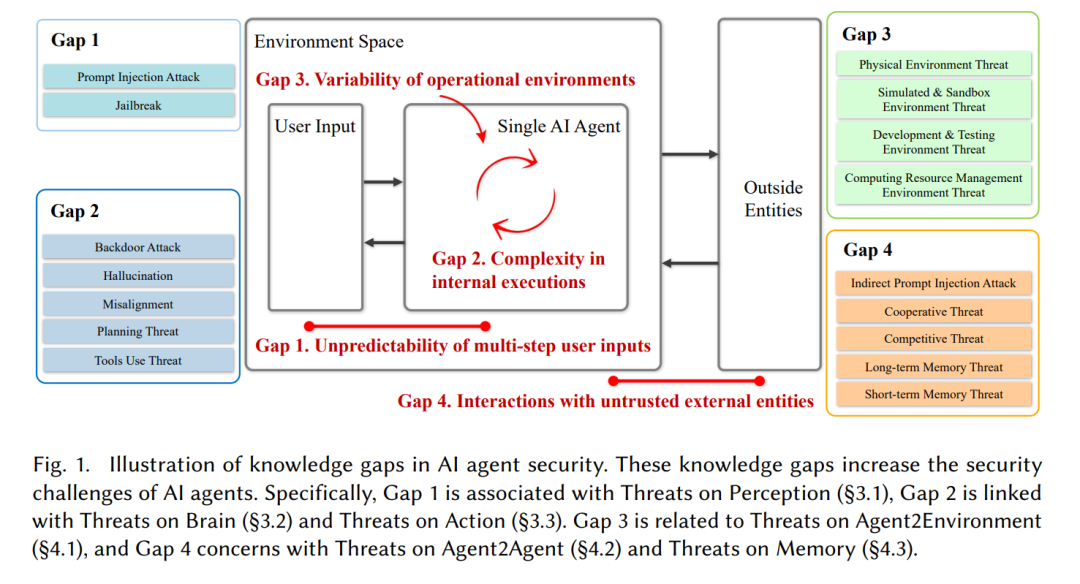
Как показано на рисунке 1, четыре основных пробела в знаниях агентов ИИ::1)Непредсказуемость многошагового пользовательского ввода,2) Сложность внутреннего исполнения,3) Изменчивость операционной среды,4) Взаимодействие с недоверенными внешними объектами. Следующие пункты подробно описывают эти пробелы в знаниях.
- Пустой 1. Непредсказуемость многошагового пользовательского ввода. Пользователи играют ключевую роль во взаимодействии с агентами ИИ, не только предоставляя рекомендации на этапе инициации задачи, но также влияя на направление и результаты во время выполнения задачи посредством нескольких раундов обратной связи. Разнообразие пользовательского ввода отражает различный опыт и опыт, помогая ИИ-агенту выполнять различные задачи. Однако этот многоэтапный ввод также создает проблемы, особенно когда ввод пользователя плохо описан, что может привести к потенциальным угрозам безопасности. Недостаточные объяснения действий пользователя не только повлияют на результаты задачи, но и могут вызвать ряд неожиданных реакций, приводящих к более серьезным последствиям. Кроме того, существуют злонамеренные пользователи, которые намеренно направляют агентов ИИ на выполнение небезопасного кода или операций, что создает дополнительную угрозу. Поэтому обеспечение ясности и безопасности пользовательского ввода имеет решающее значение для эффективной и безопасной работы агентов ИИ. Это требует разработки очень гибкой экосистемы агентов ИИ, которая сможет понимать и адаптироваться к разнообразию пользовательского ввода, обеспечивая при этом надежные меры безопасности для предотвращения злонамеренной активности и ввода пользователей в заблуждение.
- Бланк 2. Внутренняя сложность исполнения. Внутреннее состояние выполнения агента ИИ представляет собой сложную цепную структуру, включающую переформатирование подсказок для планирования задач LLM и использования инструментов. Многие внутренние состояния выполнения являются неявными, что затрудняет детальное наблюдение внутренних состояний. Это приводит к тому, что многие проблемы безопасности не обнаруживаются вовремя. Безопасность агентов ИИ требует аудита сложного внутреннего выполнения отдельных агентов ИИ.
- Бланк 3. Вариативность операционной среды. На практике этапы разработки, развертывания и выполнения многих агентов охватывают различные среды. Изменчивость этих сред может привести к противоречивым поведенческим результатам. Например, исполняющий код агента может запустить данный код на удаленном сервере, что потенциально может привести к опасным операциям. Поэтому безопасное выполнение рабочих задач в нескольких средах является серьезной проблемой.
- Бланк 4. Взаимодействие с ненадежными внешними объектами. Ключевая способность агентов ИИ — обучать большие модели использованию инструментов и других агентов. Однако текущий процесс взаимодействия между агентами ИИ и внешними объектами предполагает доверенный внешний объект, что приводит к широкой практической поверхности атак, таких как атаки с непрямым внедрением подсказок. Агентам ИИ сложно взаимодействовать с другими ненадежными объектами.
Хотя некоторые исследовательские работы направлены на устранение этих пробелов, всесторонний обзор и систематический анализ безопасности агентов ИИ все еще отсутствуют. Как только эти пробелы будут заполнены, агенты ИИ получат преимущества от более четкого и безопасного пользовательского ввода, повышенной безопасности и устойчивости к потенциальным атакам, согласованного поведения в операционной среде, а также повышенного доверия и надежности пользователей. Эти улучшения будут способствовать более широкому внедрению и интеграции агентов ИИ в критически важные приложения, гарантируя, что они смогут выполнять задачи безопасно и эффективно.
Существующие обзоры агентов ИИ в основном сосредоточены на их архитектуре и приложениях без углубленного изучения проблем безопасности и решений.。Наш обзор призван восполнить этот пробел.,Благодаря детальному рассмотрению и анализу агентов ИИ Безопасность,Определите потенциальные решения и стратегии для смягчения этих угроз. Представленные идеи призваны стимулировать дальнейшие исследования.,Для устранения угроз безопасности, связанных с агентами ИИ.,Тем самым способствуя разработке более надежных и безопасных приложений-агентов искусственного интеллекта.
В этом обзоре мы систематически рассматриваем и анализируем угрозы и решения для безопасности агентов ИИ, основываясь на четырех пробелах в знаниях, охватывающих как широту, так и глубину.。В основном мы собирали из2022Год1Месяц настал2024Год4месяц в топеAIВстреча、Лучшие сетевые конференции и высоко цитируемые статьи arXiv. Конференции по искусственному интеллекту включают, помимо прочего, NeurIP.、ICML、ICLR、ACL、EMNLP、CVPR、ICCVиIJCAI。сеть Безопасность Встреча包括但不限于IEEE S&P、USENIX Безопасность, NDSS и ACM CCS。
Эта статья организована следующим образом。Раздел 2 знакомитAIОбзор агента。В разделе 3 описывается Пустой 1и Пустой 2 связанных одного агента. Проблема безопасности. В четвертом разделе анализируются отношения с Бланком. 3–Пустой 4 связанные многоагентные задачи безопасности. В разделе 5 предлагаются будущие направления развития этой области.
### 2.1 Обзор агентов ИИ в рамках единой концептуальной основы
#### термин
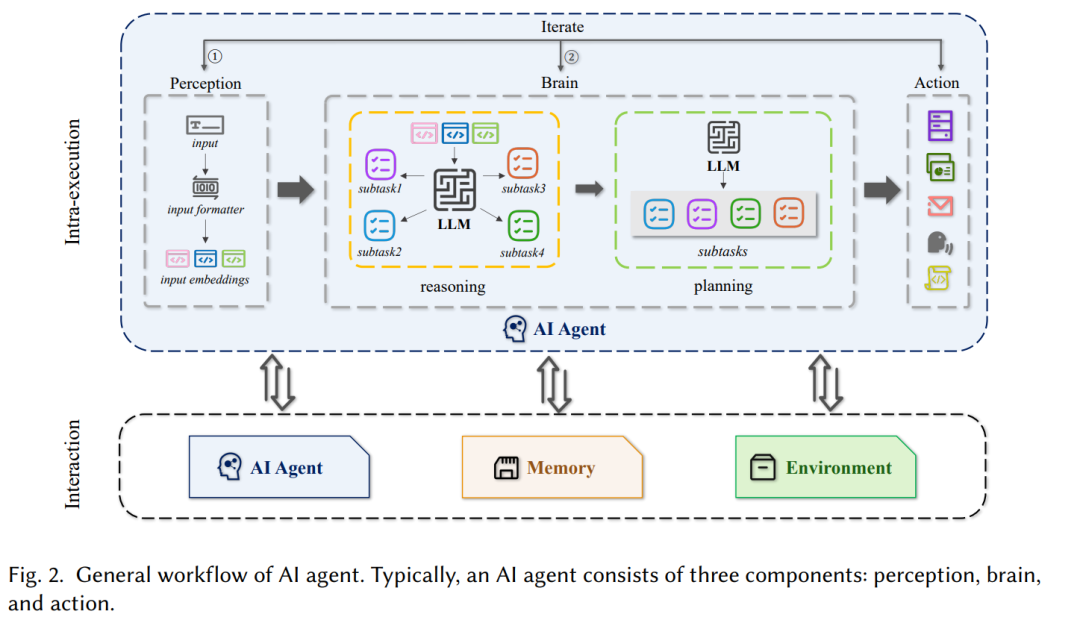
Для простоты понимания в этой статье мы введем следующие термины. Как показано на рисунке 2, пользовательский ввод можно переформатировать с помощью инструментов форматирования ввода, чтобы улучшить качество ввода за счет быстрого проектирования. Этот шаг также называется восприятием. Вывод относится к большим языковым моделям, предназначенным для анализа и получения информации, помогая делать логические выводы на основе заданных сигналов. С другой стороны, планирование относится к большой языковой модели, предназначенной для помощи в разработке стратегии и принятии решений путем оценки возможных результатов и оптимизации конкретных целей. Комбинация LLM, используемая для планирования и рассуждения, называется мозгом. Вызовы внешних инструментов в совокупности называются действиями. В этом обзоре мы называем сочетание восприятия, мозга и действия внутренним исполнением. С другой стороны, помимо внутреннего исполнения, агенты ИИ могут также взаимодействовать с другими агентами ИИ, воспоминаниями и средой, которую мы называем взаимодействием; Эти термины также можно подробно обсудить в [186].
В 1986 году Мукхопадьяй и др. в исследовании предложили сервер документов с несколькими интеллектуальными узлами для эффективного извлечения знаний из мультимедийных документов посредством пользовательских запросов. Последующая работа [10] также обнаружила потенциал компьютерных помощников во взаимодействии между пользователями и компьютерными системами, выделив важные направления исследований и приложений в области информатики. Впоследствии Вулдридж и др. [183] определили компьютерных помощников, демонстрирующих интеллектуальное поведение, как интеллектуальных агентов. В области разработки искусственного интеллекта агенты представляются как вычислительные объекты, обладающие автономией, реактивностью, инициативой и социальными способностями [186]. Сегодня, благодаря мощным возможностям крупномасштабных языковых моделей, агенты ИИ стали основным инструментом, помогающим пользователям эффективно выполнять задачи. Как показано на рисунке 2, общий рабочий процесс ИИ-агента обычно состоит из двух основных компонентов: внутреннего выполнения и взаимодействия. Внутреннее исполнение агента ИИ обычно представляет собой функции, работающие в рамках единой архитектуры агента, включая восприятие, мозг и действие. В частности, восприятие обеспечивает эффективную входную информацию в мозг, в то время как действие обрабатывает эту входную информацию и выполняет подзадачи с помощью возможностей рассуждения и планирования LLM. Эти подзадачи затем выполняются последовательно действиями по вызову инструмента. ① и ② представляют собой итерационный процесс, выполняемый внутри. Взаимодействие означает способность агента ИИ взаимодействовать с другими внешними объектами, в основном через внешние ресурсы. Это включает в себя сотрудничество или конкуренцию в рамках многоагентной архитектуры, получение воспоминаний во время выполнения задачи, а также развертывание среды и использование ее данных из внешних инструментов. Обратите внимание, что в этом обзоре мы определяем память как внешний ресурс, поскольку большинство рисков безопасности, связанных с памятью, возникают из-за извлечения внешних ресурсов.
С точки зрения базовой внутренней логики агенты ИИ можно разделить на агентов, основанных на обучении с подкреплением, и агентов, основанных на больших языковых моделях. Агенты на основе RL используют обучение с подкреплением для изучения и оптимизации стратегий путем взаимодействия с окружающей средой, стремясь максимизировать совокупное вознаграждение. Эти агенты эффективны в средах с четкими целями, такими как выполнение инструкций [75, 124] или построение моделей мира [108, 140], и они адаптируются методом проб и ошибок. Напротив, агенты на основе LLM полагаются на большие языковые модели [92, 173, 195] и преуспевают в задачах обработки естественного языка, используя большие объемы текстовых данных для управления сложностью языка для эффективного общения и поиска информации. Каждый тип агента имеет разные возможности для достижения конкретных вычислительных задач и целей.
### 2.2 Обзор угроз для агентов ИИ
В настоящее время существует несколько обзоров об агентах ИИ [87, 105, 160, 186, 211]. Например, Си и др. [186] предоставляют всесторонний систематический обзор приложений агентов на основе LLM с целью рассмотреть существующие исследования и будущие возможности. Текущая архитектура агентов ИИ обобщена в [105]. Однако они не в полной мере оценивают безопасность и надежность агентов ИИ. Ли и др. [87] не смогли учесть возможности и безопасность многоагентных сценариев. Одно исследование [160] лишь суммировало потенциальные риски, присущие научным агентам LLM. Чжан и др. [211] исследовали только механизм памяти агентов ИИ.
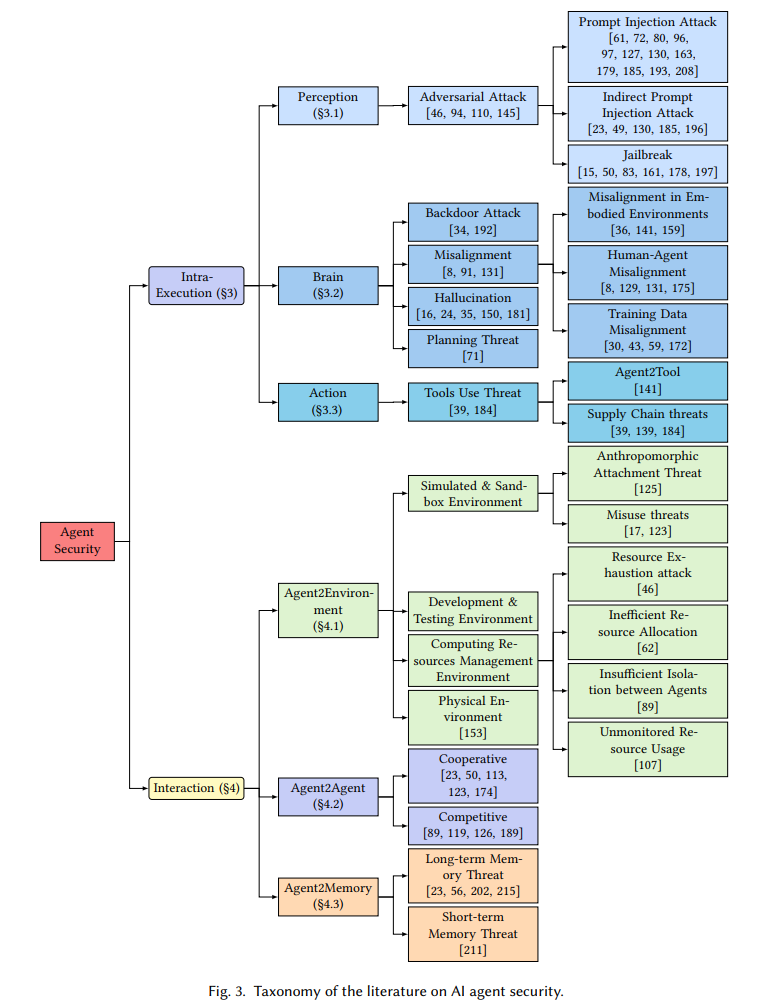
Наше основное внимание уделяется проблемам безопасности агентов ИИ, связанным с четырьмя пробелами в знаниях. Как показано в таблице 1, мы суммируем статьи, в которых обсуждаются проблемы безопасности агентов ИИ. В столбце «Источник угрозы» указаны стратегии атак, используемые на различных этапах общего рабочего процесса ИИ-агента, и он разделен на четыре поля. В столбце модели угроз указаны потенциальные злоумышленники или уязвимые объекты. Целевые эффекты суммируют потенциальные результаты проблем, связанных с безопасностью.
Мы также предлагаем новую классификацию угроз агентов ИИ (см. рис. 3).。Конкретно,Мы выявляем угрозы по месту их происхождения,Включает внутреннее исполнение и взаимодействие.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
