Обзор ускорения нейронных сетей на графах: алгоритмы, системы и оборудование
1 Обзор
GNNсуществоватьмного Достижение высочайшего уровня выполнения миссии,Но при работе с реальными приложениями с большими объемами данных и строгими требованиями к задержке,Решение проблем масштабируемости。Для решения этих задач,было проведено много исследований о том, как ошибаться GNN. Эти методы сложности затрагивают различные аспекты GNN.,От интеллектуального обучения и алгоритма вывода к эффективной системе Пользовательское оборудование В этом обзоре представлена классификация GNNУскоряться.,Обзор существующих методов,и предложенные направления будущих исследований.
Как показано на рисунке 1, технология ускорения GNN разделена на три категории: алгоритмы, системы и специализированное оборудование. Алгоритмы включают в себя изменение графиков или выборок для уменьшения зависимости узлов, а также методы ускорения вывода, такие как сокращение, квантование и дистилляция; системы включают ускорение ядра графического процессора, оптимизацию определяемых пользователем функций, а также масштабируемое аппаратное обеспечение, включающее ускорители с различными свойствами; , поддерживающий различные уровни распараллеливания и разреженности.
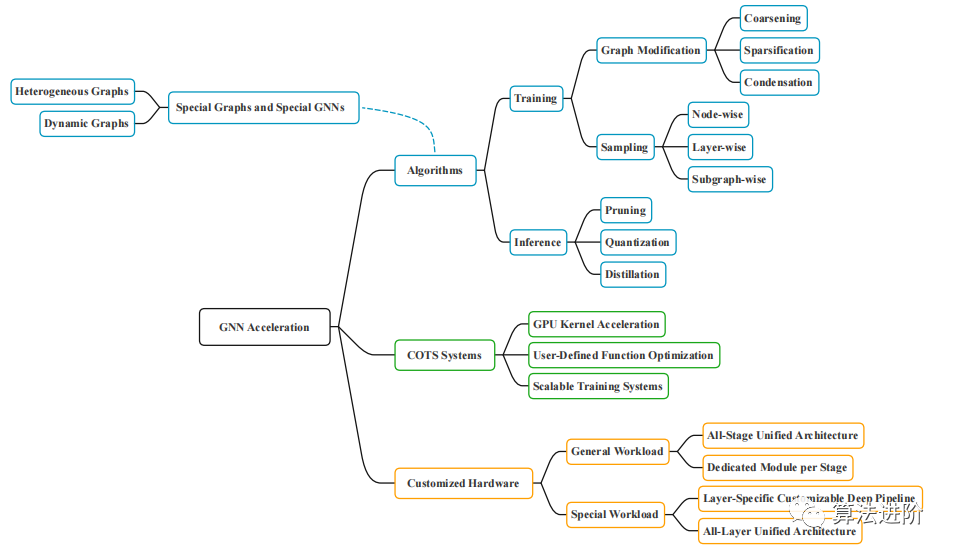
Рисунок 1. Классификация ускорения GNN.
2 GNN-ускорение: алгоритм обучения
Обучение GNN направлено на поиск оптимальных параметров 𝜃* для минимизации потерь. Задержка обучения в основном возникает из-за агрегации сообщений в рецептивном поле, а для глубоких GNN вычислительный граф может стать огромным. Общая идея ускорения обучения заключается в уменьшении вычислительного графа. Существует два метода: модификация графика и выборка. Модификация графа разделена на два этапа: сначала создается небольшой граф G', а затем выполняется обычное обучение GNN. При выборке выбирается подмножество узлов/ребер для построения вычислительного графа меньшего размера, а модификация является динамической и неявной. Оба метода ускоряют обучение, но модификации графа могут создавать новые узлы и ребра, а выборка гарантирует, что все узлы и ребра будут охвачены.
2.1 Модификация рисунка
Модификация графа ускоряет обучение GNN в два этапа. Методы модификации графа включают огрубление графа, разрежение графа и сжатие графа. Каждый из этих методов модифицирует граф G по-разному, чтобы создать свой собственный G ′ , но все G ′ представляют собой меньшие графы, которые ускоряют обучение GNN. Иллюстрация этих методов модификации графа показана на рисунке 2.
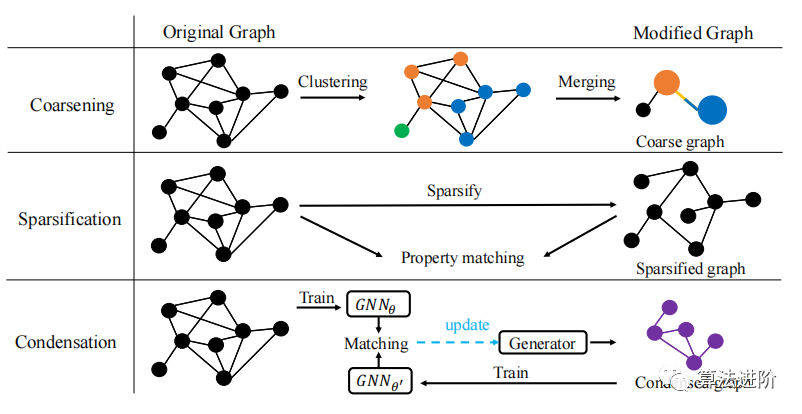
Рисунок 2. Описание метода модификации графа. Метод огрубления графа выполняет кластеризацию графа и объединяет кластеры узлов в суперузлы. Методы разрежения графа удаляют менее важные ребра. Методы сжатия графов используют случайно инициализированные генеративные модели для создания новых сжатых графов. Для модифицированного графа (самый правый столбец) черные узлы/ребра взяты из исходного графа, а цветные узлы/ребра созданы заново.
Огрубление фигуры,Это метод, позволяющий уменьшить размер графика, сохраняя при этом его общую структуру.。Путем слияния узлов одной и той же локальной структуры в“супер узел”,И объедините ребра, соединяющие суперузлы, в «суперребра».,Доступно грубое изображение. Основным этапом огрубления графов является кластеризация графов.,Обычно ассоциируется с графиками. Некоторые алгоритмы, такие как ограниченная спектральная аппроксимация и обратный лапласиан.,Используется для сохранения некоторых свойств графа. Хуанг и др. предложили общую основу для обучения GNN с использованием огрубления графов.,Разделив граф на K кластеров,И установите характеристики и метку суперузла. и другие сопутствующие работы,Такие как GOREN и GraphZoom,нососредоточиться Немного другое.
разреженность графа,проходитьудалить Избыточные ребра для уменьшения вычислительного графа,Уверенность в обучении GNN. Существующие методы часто сохраняют ключевые свойства исходного графа.,Такие как сокращение общего веса, спектральных характеристик и иерархической структуры. Метод разрежения может использоваться как этап предварительной обработки.,Уменьшите временную сложность всего пакета. В некоторых связанных работах выполняется разрежение графов на основе GNN для повышения точности или надежности GNN.,Но часто необходимо решить дополнительные задачи оптимизации.,Может замедлить обучение. обрезкаи граф разреженность разная,обычно относится кнейронная Модификация сети Модель.
сжатие изображений,проходитьсопоставить дваGNNобучающий градиент для создания сжатого графика,Тем самым уменьшая объем вычислений и использование памяти GNN. GCond — метод генерации сжатых графов.,Можно значительно уменьшить размер графа, сохранив исходную динамику обучения графа. Путем обучения двух GNN с одинаковой архитектурой на исходном графе и сжатом графе.,GCond может генерировать сжатые графики,сохраняя при этом производительность оригинального GNN. Эксперименты показывают,GCond может достичь степени сжатия менее 1% в нескольких тестах графов.,При этом сохраняется точность исходного GNN более 95%. поэтому,GCond идеально подходит для таких задач, как поиск нейронной архитектуры. Однако,Для сложности обучения одной GNN,GCond следует комбинировать с другими методами ускорения или лучшими стратегиями сжатия.
2.2 Выборка
Выборка — это метод, который ускоряет обучение GNN за счет динамического выбора подмножества узлов и ребер для сокращения вычислительного графа, тем самым увеличивая скорость обучения. Исследования показали, что выборка может поддерживать точность модели, сокращая при этом время и потребление памяти. Следует отметить, что выборка отличается от модификации графики. Выборка является динамической и неявной, и промежуточный модифицированный графический вывод отсутствует.
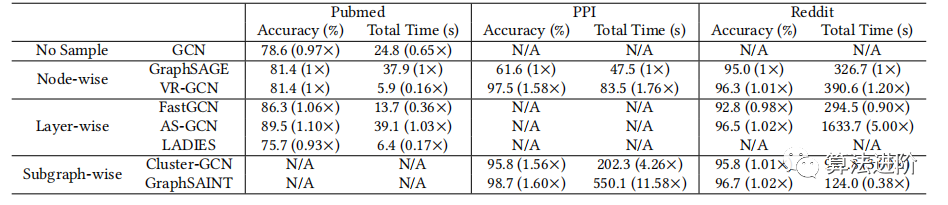
Методы выборки делятся на три категории: метод узлов, метод послойного анализа и метод подграфов. На рисунке 3 показаны различные методы выборки графа. Каждый метод имеет свои преимущества и недостатки. Эксперименты показывают, что метод послойной выборки лучше работает с набором данных Reddit, а метод выборки подграфов лучше работает с набором данных PPI. Как показано в таблице 1, существуют различия в производительности и времени работы разных методов выборки в разных наборах данных.
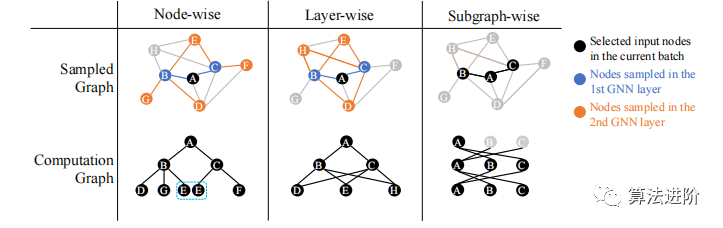
Рисунок 3. Иллюстрация различных методов выборки графов. Метод выборки узлов производит выборку каждого узла на каждом вычислительном уровне, что может привести к появлению избыточных узлов (например, узел E отбирается дважды) и отсутствующим ребрам (например, граница между узлами C и узлом D теряется); Метод выборки слоев осуществляет выборку каждого слоя на основе узлов предыдущего слоя. Метод выборки подграфа производит выборку списка узлов и производного от него подграфа, а затем выполняет передачу сообщений путем выборки всех ребер внутри подграфа.
Таблица 1. Сравнение эффективности различных методов отбора проб
узелвыборка。узелвыборка Метод применяется к каждому слою 𝑙 Каждый целевой узел 𝑣. Пример программы отбора проб представлен на рисунке. 3(a) показано.
GraphSAGE — это новаторская работа по уменьшению рецептивного поля узлов посредством выборки узлов. Для каждого слоя 𝑙 GraphSAGE равномерно отбирает фиксированное количество (𝑠 (𝑙) 𝑛𝑜𝑑𝑒 ) соседних узлов каждого узла. Алгоритм выборки GraphSAGE также можно формализовать в матричной форме, где 𝑷 (𝑙)𝑯 (𝑙-1) представляет агрегацию полных соседей, а 𝑷 (𝑙) 𝑯 (𝑙-1) представляет агрегацию выборки. VR-GCN предлагает использовать исторические внедрения в рабочем процессе GraphSAGE, чтобы уменьшить дисперсию внедрения и ускорить сходимость обучения. Помимо GraphSAGE и VR-GCN, существует множество других работ, исследующих различные аспекты выборки узлов.
Хотя метод выборки узлов может облегчить проблему масштабируемости крупномасштабного обучения GNN за счет уменьшения восприимчивого поля и может гарантировать, что каждый узел каждого уровня может иметь разумное количество подключенных соседей для обновления его скрытого представления, все же существуют ограничения.
слой за слоемвыборка。слой за слоемвыборкаметодиз того же самоговычислитьвсе в слоеузел Выберите подмножество из,Используется для построения вычислительных графиков. Каждый узел соединен с прямым соседом следующего вычислительного уровня и соседом второго перехода следующего вычислительного уровня. для каждого узла,его слоивыборка Окрестности – это слои.выборкаузел Пересечение множества и исходной окрестности。Каждый вычислительный уровень выполняет 𝑠 (𝑙) 𝑙𝑎𝑦𝑒𝑟 Операция выборки раз, выберите 𝑠 (𝑙) 𝑙𝑎𝑦𝑒𝑟 соседние узлы. Наконец, узлы выборки текущего вычислительного уровня используются для построения окрестности последующих вычислительных уровней для передачи сообщений. Пример программы отбора проб представлен на рисунке. 3(b) показано.
FastGCN решает проблему масштабируемости выборки узлов посредством иерархической выборки по важности, но сталкивается с проблемами подключения. AS-GCN предлагает адаптивный метод стратифицированной выборки, который выбирает нижний уровень на основе верхнего слоя и добавляет регуляризацию для уменьшения дисперсии. ЖЕНЩИНЫ отбирают пробы в непосредственной близости от последнего слоя, чтобы обеспечить передачу информации.
Метод иерархической выборки преодолевает ограничение экспоненциального расширения окрестностей выборки узлов с линейным временем и сложностью памяти. Однако проблемы с подключением все еще существуют и могут привести к снижению производительности модели.
подсюжетвыборка。подсюжетвыборка Метод принимает на вход весь график.,Подграф выходного примера,Используется для обучения GNN. Поскольку подграфы обычно небольшие и представляют только локальную информацию,При обучении необходимо добавлять случайность, чтобы повысить точность. Эти методы аналогичны методу Модификация фигуры.,Но это никак не меняет картину,Но динамичная выборка.
ClusterGCN делит граф на кластеры и выполняет полное пакетное обучение GNN для каждого кластера подграфа, что улучшает масштабируемость, но результаты кластеризации фиксированы. GraphSAINT предлагает четыре различных алгоритма выборки узлов, среди которых лучше работает сэмплер случайного блуждания. Shadow-GNN производит выборку различных подграфов каждого целевого узла, и разработан принцип отделения глубины GNN от размера его восприимчивого поля. Существует множество других последующих работ по выборке подграфов, таких как сэмплер RWT Ripple Walking и распараллеленная версия Zeng et al. Кроме того, для построения подграфов можно использовать некоторые методы стратифицированной выборки.
Метод выборки подграфов не опирается на модели и вложения GNN и может выполняться до обучения или параллельно. Однако рассматривается только структура графа, а динамика обучения модели не учитывается. Поэтому еще предстоит решить, как включить исследование уменьшения дисперсии в процесс выборки подграфа.
3 Ускорение GNN: алгоритм вывода
Цель ускорения вывода GNN — построить модель ~GNN𝜃~ так, чтобы ее вывод на G𝑡𝑒𝑠𝑡 имел такую же точность, что и GNN𝜃*, но быстрее. В отличие от ускорения обучения, ускорение вывода более ориентировано на модель, фокусируясь на архитектуре модели, числовой точности параметров и значениях параметров. Общие методы ускорения вывода включают обрезку, квантование и дистилляцию. Эти методы широко используются для ускорения общих DNN, а также могут применяться к графическим GNN. Основная проблема заключается в том, как сохранить информацию о структуре графа и устранить задержки, вызванные агрегацией сообщений.
3.1 Обрезка
Сокращение GNN — это метод ускорения вывода GNN путем оптимизации модели путем выбора весов GNN, подлежащих сокращению. Наиболее распространенным методом является сокращение величины веса, то есть сокращение нейронных связей с меньшими весами или уменьшение нормы L1 весов. Сокращение обеспечивает компромисс между скоростью модели и точностью: удаление большего количества весов может привести к более быстрой модели, но к меньшей точности.
Чжоу и др. предложили метод сокращения каналов, который сформулировал проблему сокращения как задачу регрессии LASSO и поочередно оптимизировал обучаемую маску и обновленную матрицу весов GNN. Гипотеза лотерейного билета (LTH) — это популярное исследование сокращения, которое показывает, что сокращенные разреженные нейронные сети можно переобучить для достижения той же точности, что и исходная нейронная сеть. Чен и др. протестировали LTH GNN с помощью итеративного сокращения амплитуды (IMP) и наблюдали прирост скорости и незначительные потери точности. Сокращение может ускорить вывод модели, но не всегда ускоряет обучение модели.
3.2 Количественная оценка
Квантование — это широко используемый метод ускорения общих моделей машинного обучения за счет снижения числовой точности параметров модели. Для DNN задержка в основном возникает из-за умножения матриц, а квантование может сократить операции MAC и ускорить вывод. Еще одним преимуществом квантования является сокращение времени доступа к памяти. Цель количественного исследования — добиться ускорения вывода при сохранении точности вывода. Квантование можно разделить на квантование после обучения (PTQ) и обучение с учетом квантования (QAT). PTQ прост в использовании и может быть применен к любой архитектуре, но имеет меньшую точность. QAT моделирует ошибку квантования во время обучения и обычно может найти лучшие модели квантования, но цена состоит в том, что время обучения модели увеличивается и требует данных. Существующие методы квантования в основном используются для CNN, а квантование GNN имеет свои проблемы и требует специальной обработки.
SGQuant и Degree-Quant — это два метода изучения квантования GNN. SGQuant — это метод PTQ, который в основном фокусируется на количественной оценке представления узлов и оптимизирует эффективность количественной оценки за счет многогранной количественной оценки. Degree-Quant — это метод QAT, который в основном определяет количественные веса GNN и представления промежуточных узлов, а также повышает точность обновления весов за счет защитных масок.
Квантование является самым простым в применении методом ускорения GNN и может значительно увеличить скорость. В сочетании с другими методами ускорения, такими как поиск сетевой архитектуры (NAS), можно добиться дальнейшего повышения скорости.
3.3 Дистилляция
Дистилляция знаний (KD) — это метод сжатия сложных моделей в более мелкие и быстрые модели. Он обучает две модели методом «учитель-ученик». Учитель выводит вектор вероятности (мягкую метку), а модель ученика выводит расстояние от мягкой метки. Минимизируя это расстояние, знания передаются от учителей к ученикам. Распространенной метрикой расстояния является дивергенция Кульбака-Лейблера (KL).
В большинстве случаев модель учителя сначала обучается отдельно, а затем модель ученика обучается фиксированным учителем. Потери при дистилляции знаний L 𝐾𝐷 используются только для обновления параметров учащихся и не применимы к учителям. KD можно применять в полуконтролируемой среде, обучая учителей использованию размеченных данных и создавая мягкие метки для неразмеченных данных для обучения студентов. KD широко использовался для сжатия и ускорения DNN, таких как CNN, а недавно был расширен до GNN. Методы GNN KD различаются главным образом в двух аспектах: 1) Каковы модели учителя и ученика? 2) Какова цель КД?
LSP, TinyGNN и GLNN — это новаторские работы по исследованию GNN с ускорением KD. LSP предлагает локальную структуру, сохраняющую потери, чтобы побудить модель ученика сохранять локальные структуры, аналогичные модели учителя. TinyGNN поощряет прямое взаимодействие между узлами, добавляя специальный слой PAM для повышения точности модели дистилляции. GLNN принимает чистую модель учащихся MLP и достигает результатов, конкурентоспособных с преподавателем GNN посредством KD. Эти методы были разработаны в разных условиях с разной применимостью и увеличением скорости. Применение КД в GNN все еще находится на ранних стадиях, и существует множество интересных открытых проблем.
Сочетание технологий ускорения вывода позволяет добиться лучших результатов. Например, объединение квантования и дистилляции, постепенное квантование весов и активаций GNN и, наконец, реализация двоичной GNN позволяет добиться 2-кратного ускорения на Raspberry Pi 4B с лишь умеренной потерей точности.
4 Ускорение GNN: система
Помимо эффективных алгоритмов обучения/вывода GNN, оптимизация базовой системы имеет решающее значение для повышения сквозной пропускной способности GNN. Существующие работы ускоряют системы GNN по трем аспектам: ускорение ядра графического процессора, оптимизация пользовательских функций (UDF) и масштабируемые системы обучения. Поскольку расчет GNN следует парадигме передачи сообщений и требует эффективных разреженных операций, были предложены различные эффективные методы оптимизации ядра GNN и UDF. Однако разработка эффективной и масштабируемой системы обучения GNN остается открытой исследовательской проблемой. В настоящее время двумя широко используемыми средами GNN являются PyG и DGL.
4.1 Ускорение ядра графического процессора
Ядро графического процессора — это программа, специально оптимизированная для графического процессора, которая может значительно повысить скорость вычислений при обучении и выводе DNN. Хотя графические процессоры широко используются для ускорения глубокого обучения, использовать графические процессоры для ускорения GNN по-прежнему сложно из-за разреженности и нерегулярности графов.
В последние годы во многих исследованиях были предложены новые ядра графических процессоров для ускорения рабочих нагрузок GNN, и в таблице 2 суммированы эти работы. PCGCN улучшает локальность данных GNN за счет разреженного режима агрегации узлов, применяет двухрежимный расчет и использует кластеризацию графов, чтобы вызвать накладные расходы на предварительную обработку. fusionGNN разработала две абстракции рабочей нагрузки агрегации GNN: GAS и GAR, которые объединяют операции для уменьшения трафика памяти и поддержки сценариев с несколькими графическими процессорами. FusedMM — это ядро ЦП, масштабируемое для ускорения графического процессора, обеспечивающее сокращение памяти за счет объединения связанных операций и использующее сегментирование с балансировкой по краям для обеспечения баланса рабочей нагрузки между потоками. TLPGNN повышает производительность за счет двух уровней параллелизма, обеспечивая балансировку нагрузки и объединение ядер. Чжан и др. разложили операцию GNN на четыре части, чтобы решить проблемы избыточных вычислений нейронных операторов, несогласованного отображения потоков и слишком большого количества промежуточных данных.
Таблица 2. Обзор методов ускорения ядра графического процессора
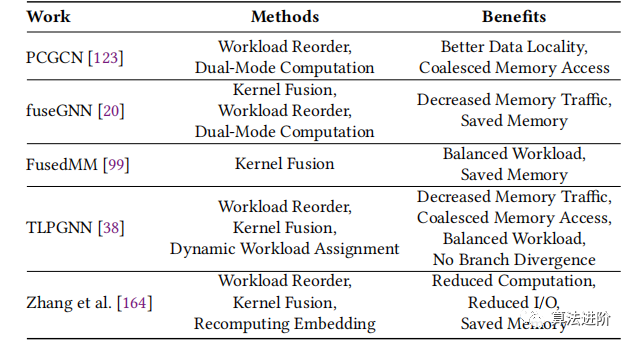
Таким образом, переупорядочение рабочей нагрузки имеет решающее значение для определения шаблонов обработки, удобных для графического процессора. Большинство заданий вычисляют выходные узлы последовательно и обрабатывают функции параллельно, чтобы обеспечить объединение ядер и объединенный доступ к памяти. Однако структура графа может быть нерегулярной, поэтому в некоторых работах используются двухрежимные вычисления и динамическое распределение рабочей нагрузки для обработки графов с различными свойствами.
4.2 Оптимизация пользовательских функций
Ключевым фактором успеха GNN в рамках парадигмы передачи сообщений является гибкость функций сообщений, агрегирования и обновления. Используя тензорные операторы в Python, пользователи могут выражать эти функции естественным образом и выполнять их через API, предоставляемый системой. Эта парадигма программирования, называемая пользовательскими функциями (UDF), может повысить модульность кода и уменьшить дублирование. Недавно разработанная работа упрощает развертывание определяемых пользователем GNN.
FeatGraph, Seastar и Grafiler — это стеки компиляторов для систем глубокого обучения, которые предоставляют гибкие интерфейсы программирования. FeatGraph поддерживает пользовательские функции, Seastar — это вершинно-ориентированный программный интерфейс, а Grafiler разработал автоматизированный инструмент для задач, связанных с разбросом/сбором. Эти инструменты совершенствуются, поскольку недавно было предложено несколько бэкэндов для разреженных операций глубокого обучения, таких как SparseTIR, который может представлять операторов, поддерживаемых вышеупомянутыми заданиями Seastar, FeatGraph и Graphier.
4.3 Масштабируемая система обучения
Для поддержки крупномасштабного обучения графов GNN в недавних работах были разработаны масштабируемые системы обучения GNN. Масштабируемость делится на вертикальную масштабируемость и горизонтальную масштабируемость. Вертикальная масштабируемость использует ограниченные ресурсы для обработки расширенных данных, а горизонтальная масштабируемость повышает эффективность за счет расширения ресурсов.
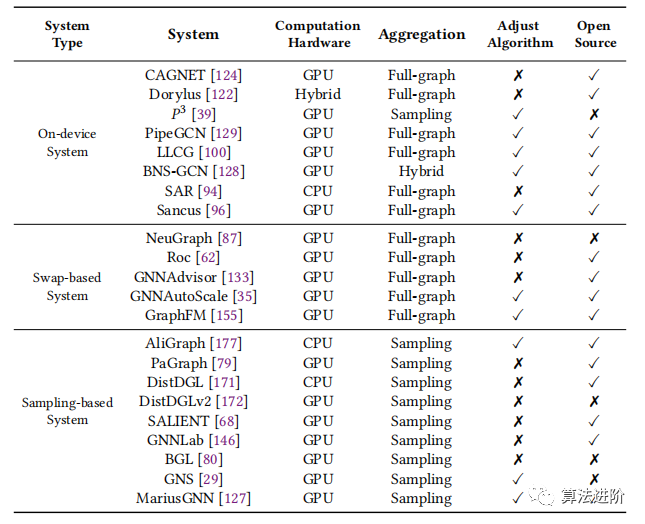
В нескольких работах обобщены и классифицированы распределенные системы обучения GNN. Мы уделяем особое внимание масштабируемому обучению GNN, включая эффективное распределенное обучение и крупномасштабное обучение. В зависимости от метода загрузки данных в вычислительное устройство мы классифицируем масштабируемые системы обучения GNN на системы на устройстве, системы на основе обмена и системы на основе выборки. На рисунке 4 показан обзор этих категорий, а в таблице 3 представлено их сравнение.
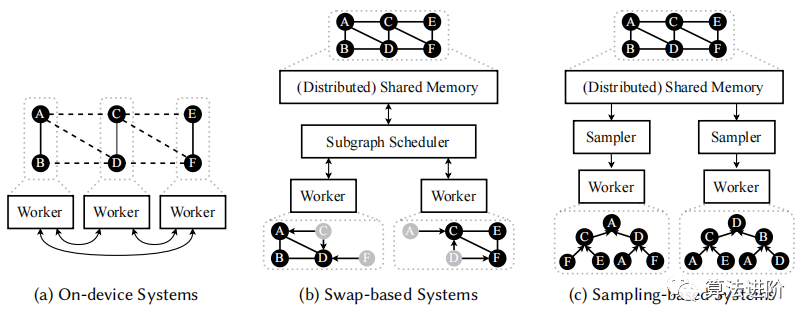
Рисунок 4. Обзор трех масштабируемых систем обучения GNN. Пунктирные линии на (а) представляют зависимости между узлами от разных рабочих, тогда как серые узлы на (б) служат только входными узлами для вычислений подграфа. Для большей наглядности синхронизация моделей между воркёрами не показана.
Таблица 3. Сравнение трех масштабируемых систем обучения GNN

Система на устройстве (рис. 4(a)) распределяет граф и связанные с ним функции по вычислительному устройству и в основном фокусируется на полной агрегации графов для использования вычислительных ресурсов, но в системе на основе обмена возникают проблемы со связью и памятью (рис. 4); (б) хранит все данные в общей памяти и выполняет вычисления путем обмена промежуточными результатами, но существуют проблемы с планированием рабочей нагрузки и задержкой итераций в системах, основанных на выборке (рис. 4(c)) Сохраните график и объекты в общей памяти, используйте выборку соседей для агрегирования соседей, устраните узкие места при перемещении данных и улучшите производительность за счет оптимизации стратегий связи и кэширования. В целом, системы, основанные на выборке, перспективны для крупномасштабного обучения графов GNN.
В таблице 4 представлена система масштабируемого обучения.
Таблица 4. Краткое описание масштабируемой системы обучения
5. Ускорение GNN: специальное оборудование
Растущий интерес к GNN привел к разработке специальных ускорителей (FPGA или ASIC) для достижения более высоких скоростей обработки. Различия в вычислительной сложности и схемах связи между GNN и CNN делают многие ускорители CNN непригодными для GNN. GNN требует наличия модулей матричного умножения и имеет нерегулярный доступ к памяти. Из-за различных моделей вычислений и связи на этапах агрегирования и обновления использование только плотных или разреженных единиц MM неэффективно для приложений GNN. Кроме того, в отличие от традиционных графовых алгоритмов, GNN использует векторы, назначенные каждому узлу. Эти различия побудили исследователей разработать специализированные аппаратные модули для эффективной работы с GNN.
5.1 Проблемы индивидуальной разработки аппаратного обеспечения
При разработке собственного ускорителя для GNN следует учитывать три момента:
Обширные слои GNN.Помимо возможного объединения графиков/подсюжет Слой объединенияи За пределами нелинейной функции активации,GNNМодель использует различные методы агрегации и обновления.,Это может повлиять на производительность и гибкость. Поддержка нескольких вычислительных моделей требует универсальности.,Может помешать оптимальной производительности.
Модель вычислений/коммуникации и разница в скорости разреженности.Различные этапы расчетаи Требования к коммуникациям могут различаться,Например,Матрица смежности очень разрежена,Весовая матрица плотная,Вложения узлов часто бывают плотными.,Однако функции активации, такие как ReLU, могут создавать разреженные матрицы. также,Многослойные персептроны, такие как MLP, также создают плотные единицы умножения. Эти различия и шаблоны доступа создают проблемы при разработке программного обеспечения GNN.,Необходимо решить проблему разреженности графа, разреженности, вносимой операторами активации и координации между модулями;
Динамический ввод и структура сети.GNNАрхитектурные решения сильно зависят от характеристик входного графа.и Модельгиперпараметры,Такие факторы, как размер графа, разреженность и размерность вектора, оказывают большое влияние на требования к памяти и вычислениям механизма GNNУскоряться. Графы разных масштабов и структур могут привести к различиям в требованиях к вычислительным ресурсам.,и дисбаланс рабочей нагрузки при изменении количества соседей узла.
5.2 Краткий обзор существующих индивидуальных ускорителей
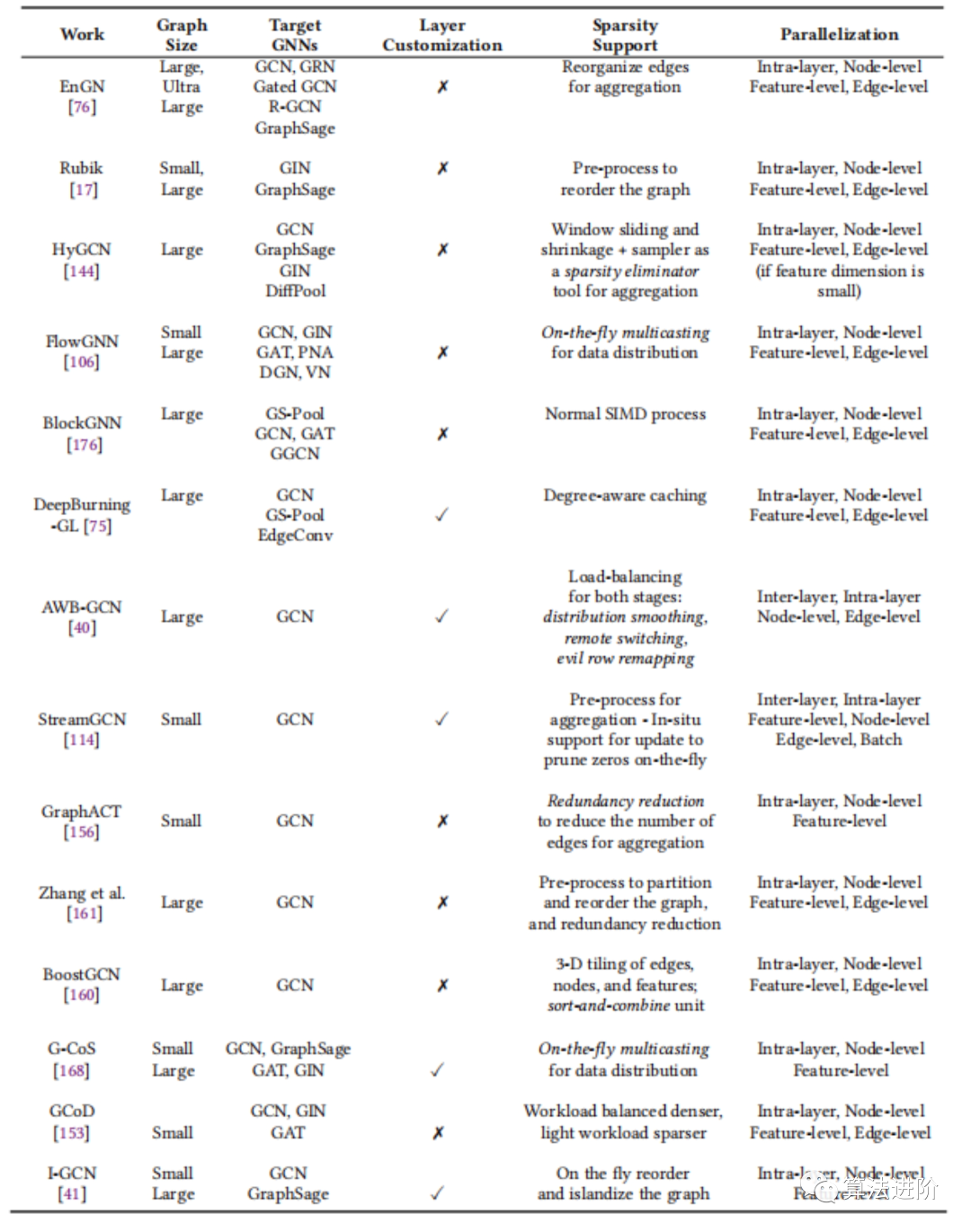
В таблице 5 сравниваются пять основных характеристик различных пользовательских ускорителей, включая размер графа, целевую GNN, поддержку настройки слоев, обработку разреженности и уровень распараллеливания. Сопутствующая работа классифицируется в соответствии с гибкостью рабочей нагрузки, включая ускорители, ориентированные на несколько алгоритмов GNN, и ускорители, ориентированные на операции GCN.
Таблица 5. Настраиваемые свойства ускорителя
5.3 Ускорители для общих задач
В этом разделе описывается работа по разработке пользовательских ускорителей для поддержки нескольких алгоритмов GNN. Эти усилия либо создают унифицированную архитектуру, которая обрабатывает все этапы вычислений, либо разрабатывают специализированные механизмы для различных режимов вычислений и связи.
Единая архитектура для всех этапов.Архитектурапроходить Разработать единый двигатель, способный обрабатывать эти этапы, чтобыускорятьсявычислить,Хотя онисуществоватьвычислитьи Существуют разные требования к общению.。EnGN、Rubik、G-CoSиGCoDи другие фреймворки, предназначенные для оптимизации графиковнейронная Производительность и эффективность сети (GNN). EnGN обрабатывает несколько GNN, использует блок обработки нейронной графики (NGPU) в качестве унифицированной архитектуры и разрабатывает стратегию переупорядочения этапов с учетом измерений для сокращения количества операций. Рубик предложил сложность для обучения GINи GraphSage, которая переупорядочивает граф через препроцессор и использует иерархическую архитектуру сложности. G-CoS — это автоматизированная среда, которая содержит однократный совместный поиск в пространстве поиска общего назначения для оптимизации производительности и эффективности GNN. GCoD — это среда совместного проектирования, которая оптимизирует алгоритмиаппаратное обеспечениеускоряться, чтобы решить проблему крайней разреженности вывода GNN. I-GCN предлагает новый метод, называемый «изолированием», для улучшения локальности данных GNN. Архитектура обеспечения включает в себя локатор острова и потребителя острова.
Отдельные модули для каждого уровня.Эта категорияGNNалгоритмосновнойвычислитьэтап разработал специальный двигатель,Возможность настройки каждого двигателя в соответствии с потребностями каждого этапа.,И поддерживает одновременное выполнение разных этапов. HyGCNускоряться делит GNNалгоритм на два этапа: агрегацию и комбинирование.,Используйте независимый механизм обработки для потоковой обработки данных. FlowGNN — это архитектура потока данных общего назначения.,Может поддерживать различные алгоритмы обмена сообщениями GNN. BlockGNN использует блочную матрицу циклических весов иFFT/IFFTускорятьсяGNN Модель для расчета фазы обновления. DeepBurning-GL — это платформа автоматизации.,используется для созданияGNNаппаратное обеспечениеускоряться и предоставляет три шаблона.
5.4 Ускорители для особых рабочих нагрузок
Исследования в этой области сосредоточены на более специализированных алгоритмах, особенно GCN. Первая подгруппа разработала глубокий конвейер с пользовательскими модификациями слоев, а вторая подгруппа использовала фиксированный аппаратный подход ко всем уровням.
Глубокие воздуховоды, которые можно наслоить и настроить по индивидуальному заказу.GCNускоряться Базовая оптимизация процессора должна снизить накладные расходы, связанные с транзакциями с памятью.。с этой целью,Построил глубокий трубопровод,Транзакции с внешней памятью между различными уровнями GCN избегаются. в то же время,Адаптировано к индивидуальным рабочим нагрузкам каждого уровня.аппаратное обеспечениепараметр。AWB-GCN и StreamGCN два эффективных GCN Архитектура ускорителя, предназначенная для использования разреженности сверточных сетей графов. AWB-GCN Для решения проблемы дисбаланса нагрузки предлагаются автоматически корректируемые методы балансировки рабочей нагрузки, включая сглаживание распределения, перераспределение злонамеренных строк и удаленное переключение. StreamGCN Эффективный и гибкий GCN ускоритель для DRAM, хост CPU и Миниатюра передачи по сети,и использовать всю доступную разреженность. Обе архитектуры поддерживают внутриуровневый и межуровневый параллелизм.,И оба основаны на умножении матрицы внутреннего продукта.
Полноуровневая унифицированная архитектура.GCNалгоритм Состоит из нескольких слоев,Каждый слой имеет разные характеристики. Исследования в этой категории предлагают создавать более адаптируемые архитектуры на разных уровнях.,и использовать один и тот же движок для всех слоев。Эти работы сосредоточены на конкретных рабочих нагрузках.(GCN)И с большими возможностями настройки。GraphACT разработал метод обучения CPUFPGA Маленькие графики гетерогенных систем GCN Генератор сложности обучается путем создания небольших графов и определения трех типов умножения. Метод Чжана и др. фокусируется на общей картине возникновения осложнений. GCN Вывод путем разделения входных данных на меньшие размеры, применения схемы уменьшения избыточности и фазы переупорядочения узлов для уменьшения доступа к глобальной памяти. BoostGCN предложил метод, направленный на оптимизацию FPGA на GCN Платформа для вывода, которая уменьшает трафик памяти и решает проблему дисбаланса рабочей нагрузки посредством агрегирования функций, ориентированного на разделы, и двух типов модулей обновления функций.
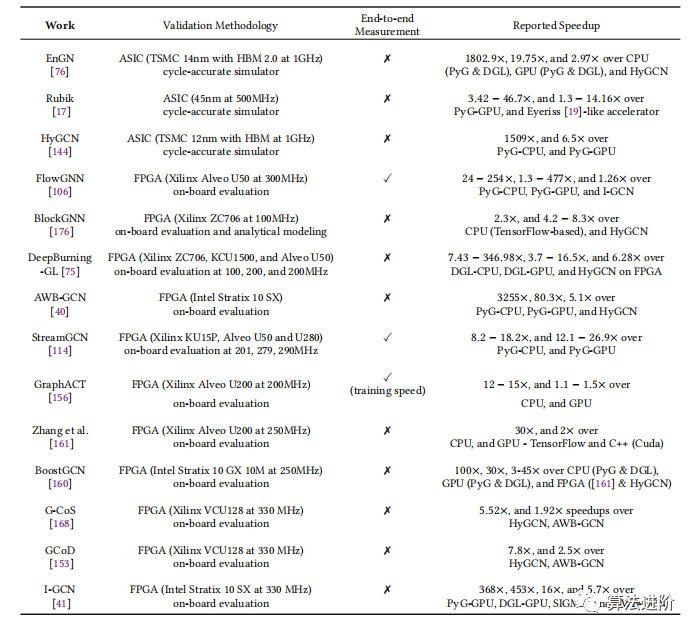
Таблица 6 отзывов о затруднение,фокуссосредоточиться Метод проверки сообщил о возникновении проблемы.
Таблица 6 Работоспособность и метод проверки настроенных ошибок
6 GNN поверить: особенная картинка и особенная GNN
В этой статье обсуждаются методы ускорения для специальных типов графов (гетерогенных графов и динамических графов) и специальных архитектур GNN (неоднородных GNN и GNN внимания).
6.1 Неоднородный граф GNN ускоряться
Гетерогенные графы — новая структура данных,Используется для представления сложных графиков в реальном мире.,где узлы и ребра имеют разные типы,имеют существенно отличающееся друг от друга значение. Например,в карте цитирования,Узлы могут быть авторами, местоположениями и статьями.,Края могут обозначать статьи, опубликованные автором, статьи, опубликованные в определенном месте и т. д.
много GNN Он предназначен для гетерогенных графов, которые сталкиваются с проблемами масштабируемости и требуют сложности. На гетерогенных графах лучший алгоритм выбора должен выполнять взвешивание, чтобы включить все типы соседних узлов. HetGNN Представляем нового гетерогенного соседавыборкаустройство,преодолел Неоднородный граф Специальный вызов. ХГТ это своего рода Transformer неоднородный граф GNN, который представляет эффективные сэмплеры, позволяет модели обрабатывать сети с миллиардами ребер. Web Масштабируйте данные графика. Голубь является промежуточным представлениемигенерация кодаустройство,используется для Неоднородный графдиаграмма отношенийнейронная Сквозное обучение и вывод сети, решаемый путем разделения семантики модели, расположения данных и графиков для конкретного оператора. RGNN проблемы с производительностью.
6.2 Динамическая графика GNN ускоряться
Пространственно-временные данные широко используются в научных исследованиях и практических приложениях.,Динамическая графика отлично подходит для решения подобных задач. Динамические графики — это графики, которые меняются со временем.,Его обучение и рассуждения сталкиваются с дополнительными проблемами. поэтому,Исследователи разрабатывают пространственно-временную GNN,Совместное моделирование пространственной и динамической эволюции. Пространственно-временная GNN применена к крупномасштабному моделированию динамических систем,Сталкивается с теми же проблемами масштабируемости, что и обычные GNN на статических графах.,Нужно вмешиваться. Пространство-время GNNУскоряться сталкивается с особыми проблемами,Потому что обучение Модели нужно проводить в хронологическом порядке.,Операции с графами должны учитывать как пространственных, так и временных соседей. В этом разделе суммированы последние работы по пространственно-временным GNNнускоряться.,Обычно применяется для изучения и рассуждения крупномасштабных динамических графиков.
TGL предлагает единую структуру для непрерывного обучения GNN,Включая структуру данных time CSR, параллельный сервер и новую технологию планирования случайных блоков. MTGNN автоматически извлекает взаимосвязи узлов с помощью модуля обучения графов.,И примените кластеризацию, чтобы уменьшить использование памяти. GraphODE сочетает в себе выразительную мощь GNN с обучающей динамической системой моделирования ODE.,Используются адаптивный решатель ОДУ и связанная функция ОДУ. GN-ETA предлагает крупномасштабную модель GNN,Расчетное время прибытия в реальном времени (ETA),Принят метод сложностииMetaGradients, основанный на суперсечениях.
Пространственно-временная GNN для динамических графов является расширением статической GNN со специальной обработкой временного аспекта. Традиционный метод использует нейронный цикл. сети, но отнимает много времени и не может уловить долгосрочные зависимости. Последние достижения, такие как позиционное кодирование и динамические GNN. аппаратное обеспечениеускоряться поддерживает различные топологии графов, но динамические и гетерогенные графы сталкиваются с проблемами. Для решения этой проблемы разработано расширяемое программное обеспечение -аппаратное. обеспечениесовместный дизайн,Включает требования для разработки графиков оценки анализатора и целевого алгоритма.,и переход к более общей архитектуре проектирования или поддержке нескольких специализированных архитектур.
7 будущих направлений
Хотя исследования GNNускоряться добились прогресса,но все еще на ранних стадиях,Не удалось угнаться за скоростью расширения данных, показанной на рисунке. В последнее время система COTS и индивидуальное аппаратное обеспечениеускоряются.,Необходимо изучить настроенную технологию для гетерогенной и динамической графики. Ниже представлены несколько направлений исследований, заслуживающих дальнейшего изучения.
Лучшая модификация фигурыалгоритм。улучшать Модификация Эффективность алгоритма фигуры, такая как огрубление, разрежение и сжатие, помогает ускорить обучение GNN. Удаление избыточных соседей на этапе предварительной обработки повышает эффективность, разреженность сохраняет локальность, а сжатие повышает эффективность обучения. Раннее определение оптимальных карт сжатия сделает этот метод более полезным. Хорошая модификация Метод фигур полезен для автоматизированного проектирования и настройки архитектуры GNN, а упрощенная предварительная обработка может значительно усложнить разработку GNN.
лучшевыборкаалгоритм。GNNвыборка В будущем метод может быть усовершенствован.,Как многослойная выборка,Используйте многомасштабную структуру графиков для повышения эффективности и захвата многомасштабных функций.,Особенно полезно для больших графиков. Метод выборки динамических графов также может быть дополнительно изучен.,Например, узлы и ребра меняются со временем.,Применение выборки к каждой временной метке индивидуально не работает.
рассуждениеускорятьсяметод。нравитьсяобрезка、Количественная Оценкаидистилляция может использоваться в сочетании для увеличения скорости. Например, веса Количественная могут быть Оценка является двоичной, при этом используется дистилляция. Поскольку фаза вывода более гибкая, эти методы можно легче комбинировать различными способами, например, комбинирование контейнера и Количественной Оценка реализует разреженную модель низкой точности или комбинирует бутылаидистилляцию с дальнейшей уточненной дистилляцией по модели студента.
система.Существующие исследования в основномсосредоточиться на повышает эффективность GNN во время выполнения, но требования к памяти по-прежнему остаются узким местом. Рематериализация, Количественная в наличии оценкаи Такие методы, как сокращение данных, уменьшают нагрузку на память.。потому чтоGNNМодельнерегулярныйвычислитьи Шаблон доступа к данным,Метод расширенного обучения/вывода может быть несовместим с системой.,Система дружественного GNNалгоритма, совместного проектирования имеет будущее. В существующей литературе отсутствует полноценная разработка GNNсистемы.,Объединение различных уровней технологий для создания сверхэффективной GNN-системы является темой исследования.
Пользовательское оборудование.GNNускорятьсяключсуществовать Чтобы уменьшить объем внешней памятиустройствообъем сбора данных。Помимо повторного использования данных、Кэширование, оптимизация и другие технологии, вы также можете изучить обрезку、Количественная сжатие оценок и другие методы. Для продвижения дизайна GNNнускоряться необходимо разработать более совершенные автоматизированные генераторы проектирования, такие как поиск нейронной архитектуры, аппаратное обеспечение на основе обучения. обеспечение оценки дизайна Модели интеллектуального проектирования освоения космоса и других технологий.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
