Обзор тонкой настройки инструкций LLM

Глубокое обучение обработке естественного языка Оригинал Автор: кола
Инструкция по тонкой Настройка(IT) является ключевой технологией для улучшения возможностей и управляемости крупномасштабной языковой модели(LLM). Сущность его относится к (ИНСТРУКЦИЯ, ВЫХОД) пара, состоящая из Набора Процесс дальнейшего обучения LLM контролируемым образом на данных устраняет разрыв между целью LLM по предсказанию следующего слова и целью пользователя заставить LLM следовать человеческим инструкциям. В этой статье проводится систематический обзор существующих исследований, в том числе общих методов ИТ, набора ИТ. данных Строительство、Обучение ITМодель、и разные режимы,Область и применение применения.
фон
За последние годы LLM добились значительного прогресса. Большие языковые модели, такие как GPT3, PaLM и LLaMA, продемонстрировали впечатляющие возможности в широком спектре задач обработки естественного языка. Основная проблема программ LLM — несоответствие между целями обучения и целями пользователей. Обычно LLM обучается на больших прогнозах путем минимизации ошибки контекстного прогнозирования слов, и пользователи ожидают, что модель будет эффективно и безопасно следовать их инструкциям.
Для устранения этого несоответствия была предложена Инструкция. по тонкой Настройка (ИТ) для повышения возможностей и управляемости Модели. Использование ИТ (ИНСТРУКЦИЯ, ВЫХОД) для дальнейшего обучения LLM, где ИНСТРУКЦИЯ представляет собой ручные инструкции модели, а ВЫХОД представляет собой ожидаемый результат после ИНСТРУКЦИИ. ИТ имеет три преимущества:
- Устраняет разрыв между следующей прогнозируемой целью LLM и целью инструкций пользователя;
- ITПозволяет больше контроляи Прогнозирующий Модель Поведение。Инструкции используются дляограничение Модель Выход,Согласуйте его с желаемыми характеристиками ответа или знаниями предметной области.,Предоставляет канал для вмешательства человека в поведение Модели;
- Эффективность вычислений выше.
В настоящее время перед ИТ стоят следующие задачи:
- Делайте качественные инструкции. Существующие инструкции данные обычно ограничены в количестве, разнообразии и творчестве;
- ИТ могут улучшить только те задачи, которые получают существенную поддержку в обучении ИТ. Набор данных;
- Некоторые люди думают, что ИТ фиксируют только поверхностные модели и стили (например,,выходной формат),Вместо того, чтобы понять и выучить задачу.
метод
В этом разделе в основном описывается конвейер с использованием настройки инструкций.
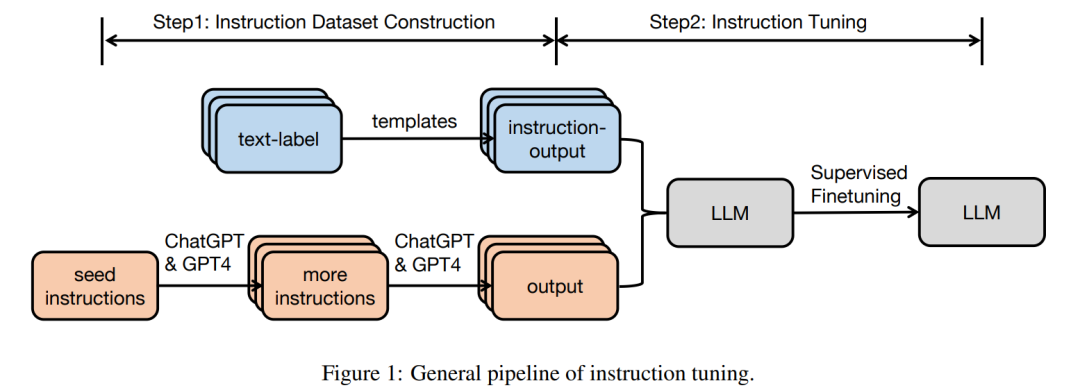
Структура команды Набор данных
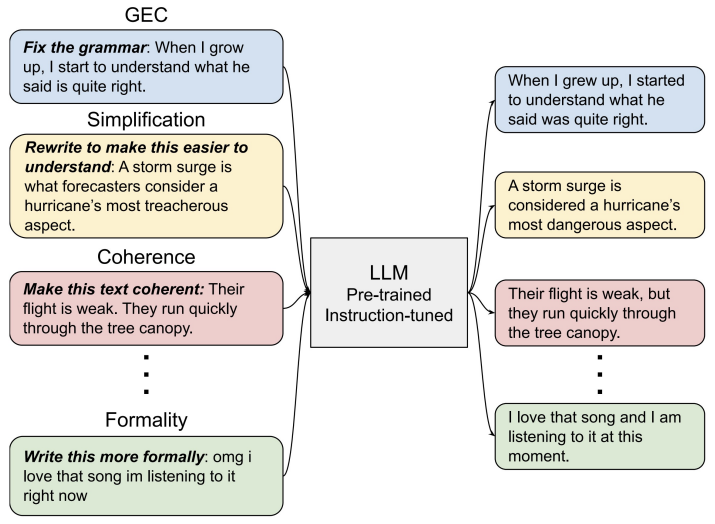
инструкция Набор данных Каждый экземпляр состоит из трех элементов:инструкция,Это последовательность текста на естественном языке, определяющая задачу (например,,Напишите благодарственное письмо ХХ за ХХ.,Напишите блог на тему XX,и т. д.);Необязательный ввод, предоставляющий дополнительную информацию к контексту.;а такжеОжидаемый результат на основе команды и ввода。
Обычно существует два типа инструкций по построению Набор данныхметод:
- из аннотированного естественного языка Набор данныхиз Набор данные становиться. В этом методе пары текстовых тегов преобразуются в (INSTRUCTION, PUT) пары из существующего аннотированного естественного языка. данных КоллекцияINSTRUCTION, ТПУТ) Да. ФланиP3Набор данныхоснован на Набор Данные построены стратегически.
- Создание выходных данных с помощью LLM. Используйте LLM, например GPT-3.5-Turbo или GPT4, для сбора выходных данных. Инструкции могут быть получены из ручного сборника или расширены на основе небольшого количества рукописных инструкций с использованием LLM. Следующий,Передайте собранные инструкции в LLM, чтобы получить результат. С помощью этого метода генерируется директива instructwindiself и другие Наборы данных.
Для многоходового диалога IT Набор данных можно позволить LLM играть разные роли (пользователя и AI-помощника) для генерации сообщений диалогового формата.
Инструкция по тонкой настройке
На основе собранного ITНабора данных,Предварительно обученная модель может быть настроена непосредственно под полным контролем.,Учитывая команду и ввод,Модель обучается путем последовательного прогнозирования каждого токена на выходе.
Набор данных
В этом разделе будут представлены некоторые широко используемые команды настройки Набора данных.
Natural Instructions
Natural Инструкция — это инструкция на английском языке, созданная вручную. Набор данных, состоит из 193 тыс. экземпляров из 61 различной задачи НЛП. Набор данные состоят из «инструкций» и «экземпляров». Каждый экземпляр в «инструкциях» представляет собой описание задачи, состоящее из 7 частей: название, определение, акцент/предупреждение, вещи. to avoid、prompt、positive example、negative example。

«Экземпляры» состоят из пар («вход», «выход»), которые представляют собой входные данные и текстовые результаты правильного следования заданным инструкциям.

Автор по ссылке Набор коллекция файлов инструкций аннотации данных «инструкции». Далее автор делит все НЛП Наборы Экземпляры данных в данных объединяются в пары («вход», «выход») для создания «экземпляров».
P3
P3(Public Pool of Подсказки) представляет собой интеграцию 170 английских наборов НЛП. данныеи2052 Советы по английскому, созданные по Инструкциям по тонкой настройке Набор данные. Подсказки — это функции, которые сопоставляют экземпляры данных в традиционных задачах НЛП (например, ответы на вопросы, классификация текста) с парами ввода-вывода на естественном языке.
P3серединаиз Каждыйиндивидуальный Есть три примераиндивидуальныйкомпоненты:“inputs”、“answer_choices”и“targets”。“inputs”Используйте естественный язык для описания задачизтекстовая последовательность(Например,"If he like Mary is true, is it also true that he like Mary’s cat?"). "Ответ_выбор" — это список текстовых строк, которые применяются к ответам на данную задачу (например, ["да", "нет", "не определено"]). "Цели" — это текстовая строка, которая является правильный ответ на заданные «входные данные» (например, «да»).
xP3
xP3(Crosslingual Public Pool of Подсказки) — многоязычная команда Набор данных, состоит из 16 различных задач на естественном языке на 46 языках. Набор Каждый экземпляр данных имеет два компонента: «входы» и «цели». «Входные данные» — это описание задачи на естественном языке. «Цели» — это текстовые результаты, которые правильно соответствуют директиве «входы».
Исходные данные в xP3 поступают из трех источников: английская команда Set. данныхP3, 4 невидимых задания на английском языке в P3 (например, перевод, синтез программы) и 30 многоязычных заданий НЛП. данные. Авторы создали xP3Набор, выбрав шаблоны задач, написанных человеком, из PromptSource, а затем заполнив шаблоны для преобразования различных задач НЛП в единую формализацию. данных。
Flan 2021
Flan 2021 - английская инструкция Набор данных, путем объединения 62 широко используемых тестов НЛП (таких как SST-2, SNLI, AG Новости, MultiRC) преобразуются в языковые пары ввода-вывода. Флан Каждый экземпляр в 2021 году имеет «входные» и «целевые» компоненты. «Ввод» — это последовательность текста, описывающая задачу посредством инструкций на естественном языке (например, «определить the sentiment of the sentence ’He likes the кот.'). «цель» — это текстовый результат правильного выполнения «входной» инструкции (например, «положительная»). Автор сначала вручную объединил инструкции и шаблоны таргетов, а затем использовал Набор Экземпляр данных data заполняет шаблон.
Unnatural Instructions
Unnatural Инструкции — набор инструкций, содержащий примерно 240 000 экземпляров. данных,Сборка с использованием InstructGPT。Набор Каждый экземпляр данных состоит из четырех компонентов: INSTRUCTION,INPUT, ОГРАНИЧЕНИЯ, ВЫХОД. «ИНСТРУКЦИЯ» — это описание обучающей задачи на естественном языке. «INPUT» — это параметр на естественном языке, используемый для создания экземпляра задачи инструкции. «ОГРАНИЧЕНИЯ» — это ограничение пространства вывода задачи. «ВЫХОД» — это текстовая последовательность инструкций, которая правильно выполняет заданные входные параметры и ограничения.
Автор сначала начал с искусственно созданного Сверхъестественного. Instructions Пример исходных инструкций в наборе данных. Затем они предлагают InstructGPT привести к новому (инструкции, inputs, ограничения), в качестве демонстрации приведены три начальные инструкции. Далее автор расширяет Набор, случайным образом переписывая инструкции или входные данные. данных。инструкция、входитьиограничениеиз Соединение подается наInstructGPTчтобы получить результат。
Self-Instruct
самообучение – обучение английскому языку Набор Данные, построенные с использованием InstructGPT, содержат 52 тыс. инструкций по обучению и 252 инструкции по оценке. Каждый экземпляр данных состоит из «инструкции», «ввода» и «вывода». «Инструкция» — это определение задачи на естественном языке (например, «Пожалуйста, answer the following вопрос".). "Ввод" необязателен и используется как дополнение к инструкции (например, "Какой country’s capital is Пекин?»), «выход» — это текстовый результат правильного выполнения инструкций (например, «Пекин»).
Шаги для создания полного набора данных следующие:
- В качестве примера случайным образом выбираются 8 инструкций на естественном языке из 175 начальных задач, и InstructGPT предлагается сгенерировать дополнительные инструкции для задач.
- Определите, является ли инструкция, созданная на шаге 1, задачей классификации. в случае,Они просят InstructGPT сгенерировать все возможные варианты вывода на основе заданных инструкций.,И случайным образом выберите определенную категорию вывода, чтобы InstructGPT сгенерировал соответствующий «входной» контент. Для инструкций, не относящихся к классифицированным задачам,Должно быть бесчисленное множество вариантов «входа». Используйте стратегию «сначала ввод»,То есть InstructGPT предлагается сначала сгенерировать «входные данные» на основе данной «инструкции».,Затем сгенерируйте «выход» на основе «входа», сгенерированного «инструкцией» и.
- По результатам шага 2 используйте InstructGPT для генерации «ввода» и «вывода» для соответствующей задачи инструкции, используя стратегию «сначала вывод» или «сначала ввод».
- Постобработка сгенерированных задач инструкций (например, фильтрация похожих инструкций).,Удаление дубликатов ввода и вывода (данные),Наконец-то получил 52 тыс. инструкций на английском языке.
Evol-Instruct
эволюционная директива — английская директива. данных, состоящих из обучающего набора, содержащего 52 тыс. инструкций, и набора «Оценивать», содержащего 218 инструкций. Автор предлагает ChatGPT использовать стратегию углубленного и медленного развития для переписывания инструкций. Стратегия углубленной эволюции включает пять типов операций, таких как добавление ограничений, добавление шагов рассуждения, усложнение ввода и т. д. Стратегия «вдох» преобразует простые инструкции в более сложные или непосредственно обновляет их для создания новых инструкций для увеличения разнообразия. Автор сначала использует 52 тыс. пар (команда, ответ) в качестве исходного набора. Затем они случайным образом выбрали стратегию развития и попросили ChatGPT переписать первоначальные инструкции в соответствии с выбранной стратегией развития. Автор использует правила ChatGPTи для фильтрации неразвитых пар инструкций и обновляет Набор новыми сгенерированными развитыми парами инструкций. данные. После повторения вышеуказанного процесса 4 раза,Автор собрал 250 тысяч пар инструкций. За исключением обучающего набора,Автор также опирается на реальные сценарии (напр.,218 искусственно сгенерированных инструкций, собранных в open source проектах, платформах и форумах),Называется набором EvolInstructtest.
LIMA
LIMA — набор для обучения английскому языку. данных, состоящий из обучающего набора, содержащего 1 тыс. экземпляров данных, и тестового набора, содержащего 300 экземпляров. Обучающий набор содержит 1 тыс. пар («инструкция», «ответ»). Для данных обучения 75% образцов были взяты с трех веб-сайтов вопросов и ответов сообщества (Stack Exchange, wikiHow и Pushshift Reddit Dataset); 20% написаны от руки группой авторов на основе их интересов, 5% образцов взяты из Super-Natural; Instructions набор данных. Для набора проверки авторы выбрали 50 экземпляров из набора писем. В наборе 300 примеров, 76,7% написаны другой группой авторов (группа Б) и 23,3% — Pushshift. Reddit Dataset。
Super-Natural Instructions
Super-Natural Инструкции — это многоязычный набор инструкций, состоящий из 1616 задач НЛП и 5 миллионов экземпляров задач, охватывающих 76 различных типов задач (таких как классификация текста, извлечение информация, переписывание текста, создание текста) и 55 языков. Набор Каждая задача в данных состоит из «инструкции» и «задачи». Он состоит из «примеров». В частности, «инструкция» состоит из трех компонентов: «определение», описывающее задачу на естественном языке; примеры», т. е. образцы входных и правильных выходных данных, а также краткое объяснение каждого образца; и «отрицательные примеры». примеры», то есть образцы входных данных и нежелательных выходных данных, а также краткое объяснение каждого образца.

«Экземпляры задач» — это экземпляры данных, состоящие из ввода текста и последовательности приемлемых выводов текста.

Super-Natural Исходные данные в инструкциях поступают из трех источников: (1) существующие общедоступные наборы НЛП. данные (например, CommonsenseQA); (2) применимые промежуточные аннотации, созданные в процессе краудсорсинга (например, в Crowdsourced QAНабор); данных Интерпретировать результаты для данной проблемы во время);(3)Преобразовано из символических задачиз Синтетические задачи,Перефразируйте его в несколько предложений (например,,Числа С выравнивать эквивалентны алгебраическим операциям).
Dolly
Долли — учительница английского языка. data, содержащий 15 000 искусственно сгенерированных экземпляров данных, предназначенных для того, чтобы LLM могла взаимодействовать с пользователями аналогично ChatGPT. Набор данные предназначены для моделирования широкого спектра человеческого поведения, охватывающего 7 конкретных типов: открытый вопрос и ответ, закрытый вопрос и ответ, извлечение информации из Википедии, обобщение информации из Википедии, мозговой штурм, классификация и творчество. Набор Примеры каждого типа задач в данных приведены в таблице ниже:

OpenAssistant Conversations
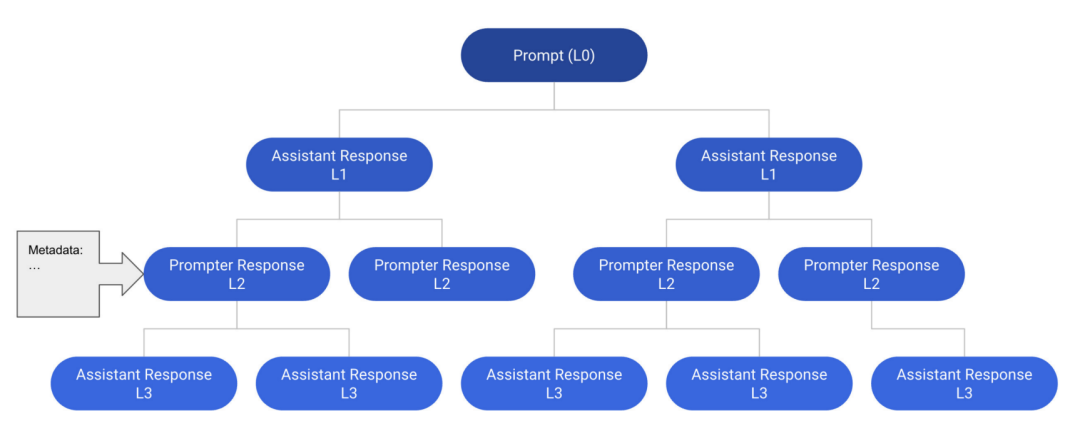
OpenAssistant Беседы — это созданный человеком многоязычный корпус бесед в стиле помощника, состоящий из 161 443 сообщений (т. е. 91 829 пользовательских подсказок, 69 614 ответов помощника) из 66 497 деревьев разговоров на 35 языках и 461 292 оценок качества, аннотированных человеком. Набор данныхсерединаиз Каждыйиндивидуальный Экземпляры все единыиндивидуальныйдиалог Дерево(CT)。Конкретно,Каждый узел в дереве диалога представляет собой сообщение, сгенерированное ролью в диалоге (т. е. подсказчиком, помощником). Корневой узел CT представляет собой начальное приглашение от суфлера.,Другой узел представляет ответ от суфлера или помощника. Путь от корня до любого узла в CT представляет собой допустимую ротацию диалога между подсказчиками и помощниками.,называется потоком。На рисунке ниже изображендиалог Деревоиз Пример,в Содержит 12 сообщений в 6 темах.
Baize
Baize — это многоходовой корпус чата на английском языке, созданный из 111,5 тыс. экземпляров с использованием ChatGPT. Каждый раунд состоит из подсказки пользователя и ответа помощника. Байка v1серединаиз Каждыйиндивидуальный Пример Включать3.4колесодиалог。
Создать BaizeНабор данных, автор предложил авточат, вChatGPT по очереди играет роль пользователя и помощника по искусственному интеллекту и генерирует сообщения в диалоговом формате. В частности, автор сначала создал шаблон задачи, определяющий роли и задачи ChatGPT (как показано в таблице ниже). Далее начинают с Quora и Stack OverflowНабор Вопросы извлекаются из данных в виде семян диалога. впоследствии,Они запрашивают ChatGPT с шаблонами и образцами семян. ChatGPT постоянно генерирует сообщения для обеих сторон.,до тех пор, пока не будет достигнута естественная точка остановки.

Инструкция по тонкой настройке LLM
В этом подразделе будет подробно описана широко используемая модель LLM, обученная с помощью Инструкции по тонкой настройке.
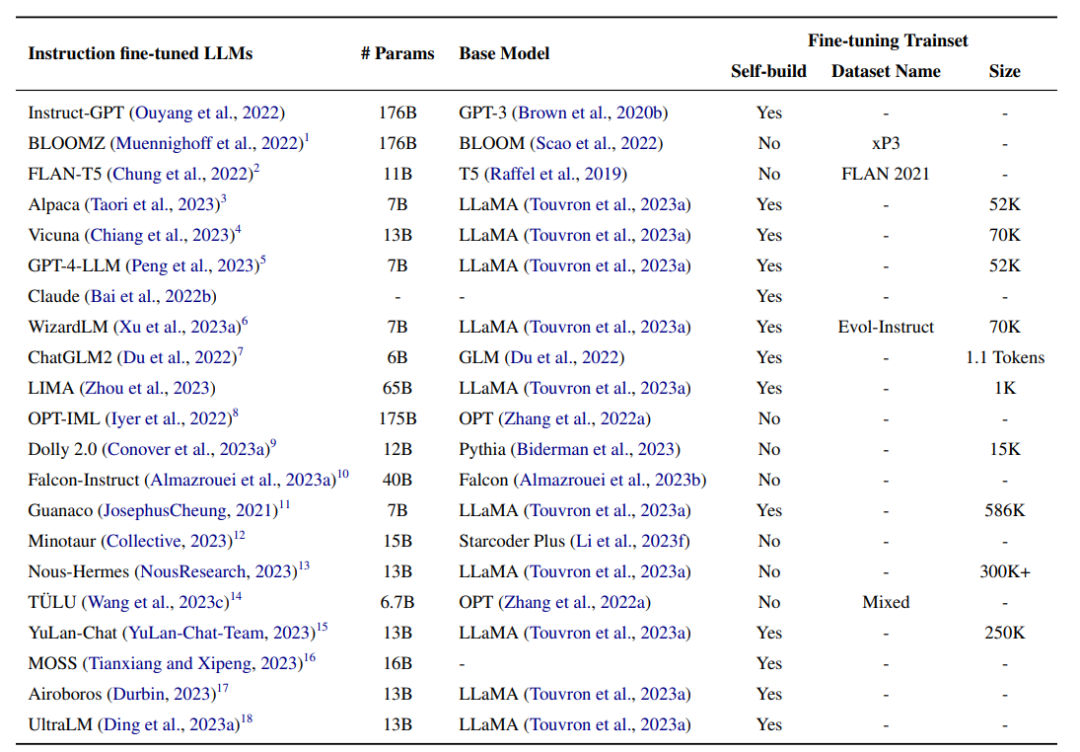
InstructonGPT
InstructGPT(176B) инициализируется с помощью GPT-3(176B), а затем настраивается на основе инструкций человека. Процесс тонкой настройки состоит из следующих трех этапов:
- пара с детской площадки Инструкции ручной фильтрации, собранные в истории API. данных выполняет контролируемую точную настройку (SFT);
- На основе аннотации Набор Данные обучают прогнозированию вознаграждения за предпочтения человека. Модель, Набор данные создаются путем выборки нескольких ответов на инструкцию и ранжирования их от лучшего к худшему;
- Продолжайте оптимизировать Модель, начиная с шага 1, используя новые инструкции, и поощряйте Модель, обученную на шаге 2. Обновите параметры с помощью метода обучения с усилением градиента политики. Метод оптимизации проксимальной политики (PPO). Повторите шаги 2 и 3 попеременно несколько раз.,Пока Модельпроизводительность не имеет существенного улучшения.
общий,InstructGPT лучше, чем GPT-3. В плане автоматического Оценивать,InstructGPTсуществоватьTruthfulQAНабор данные лучше, чем GPT-3 с точки зрения аутентичности 10%, токсичность RealToxicityPrompts выше, чем у GPT-3. 7%. В НЛП Набор данных(Прямо сейчасWSC)начальство,InstructGPT достигает производительности, сравнимой с GPT-3. Для людей Оценивать,В четырех различных аспектах: следование правильным инструкциям, следование четким ограничениям, уменьшение галлюцинаций и создание соответствующих реакций.,InstructGPT соответственно С сравнениеGPT-3 показал +10%, +20%, -20% и+10%
BLOOMZ
BLOOMZ(176B) инициализируется с помощью BLOOM(176B), а затем инструкция Набор данныеxP3 для тонкой настройки. При автоматическом оценивании при нулевых настройках BLOOMZ показал лучшие результаты при обычном эталонном разрешении, дополнении предложений и рассуждениях на естественном языке. данныхначальствоизразница в производительности СравниватьBLOOMхороший+10.4%、20.5%и9.8%。дляHumanEval,Что касается индикатора Pass@100.,BLOOMZ на 10% лучше, чем BLOOM. Для задач сборки,Сравнимо с BLOOM на lm-evaluation-harness Сравнивать,BLOOMZ добился улучшения BLEU на +9%.
Flan-T5
FLAN-T5(11B) - это LLM, инициализируемый с T5(11B), а затем в FLANНабор Внесите точные настройки данных. Во время тонкой настройки FLAN-T5 адаптируется к платформе T5X на основе jaxx и выбирает лучшую модель для сохранения задачи каждые 2 тыс. шагов. По сравнению с предтренировочным этапом Т5, точная настройка потребляет 0,2% вычислительных ресурсов (около 128 TPU). чип v4 37 часов). Для оценки FLAN-T5(11B) превосходит T5(11B) и обеспечивает производительность, сравнимую с более крупными моделями (включая PaLM) при настройках с несколькими выстрелами. (60B)) эквивалентные результаты. Производительность FLANT5 на открытой генерации MMLU, BBH, TyDiQA и MGSMи лучше, чем у T5 на +18,9%, +12,3%, +4,1%, +5,8%, +2,1%и+8% соответственно. И RealToxicityPrompts, в малокадровых настройках, FLAN-T5 в BBHиTyDiQAНабор Показатели по данным лучше, чем у PaLM+1,4% и +1,2% соответственно.
Alpaca
Альпака(7B) находится в InstructGPT(175B, text-davinci003) сгенерированы инструкции по сборке Набор По данным, языковая Модель обучена путем тонкой настройки LLaMA(7B). 80 ГБ на 8 картах с обучением смешанной точности и полностью общим параллелизмом данных На устройствах А100 процесс тонкой настройки занимает примерно 3 часа. С точки зрения оценки, Alpaca (7B) достигает производительности, эквивалентной InstructGPT (175B, text-davinci-003). В частности, Альпака занимается самообучением. данныхначальствоизработать лучше, чемInstructGPT,Получил 90 успехов,Последний имел всего 89 раз.
Vicuna
Vicuna(13B) — это набор сеансов, созданный в ChatGPT путем тонкой настройки LLaMA(13B). Языковая модель, обученная на данных. Автор собрал диалоги ChatGPT, которыми поделились пользователи с ShareGPT.com, и получил 70 тысяч записей диалогов после фильтрации образцов низкого качества. LLaMA(13B) использует модифицированную функцию потерь для многоэпохального диалога в построенном сеансе. данные для тонкой настройки. Чтобы лучше понимать длинные контексты в нескольких поворотах диалога, авторы увеличили максимальную длину контекста с 512 до 2048. Для обучения автор использует градиентный контрольно-пропускной пункт и flash. внимание, чтобы снизить затраты памяти графического процессора во время тонкой настройки. При 8×80 ГБ с полным параллелизмом общих данных На устройствах А100 процесс тонкой настройки занимает 24 часа. Авторы создали набор тестов специально для измерения производительности чат-ботов. Они собрали тестовый набор, состоящий из восьми категорий вопросов, таких как задачи Ферми, сценарии ролевых игр и задачи по кодированию/математическим задачам, а затем позволили GPT4 оценить ответы модели на основе полезности, релевантности, точности и детализации. В построенном наборе тестов Vicuna (13B) превзошла Alpaca (13B), получив такие же или лучшие результаты в 45% вопросов по сравнению с ChatGPT.
GPT-4-LLM
GPT-4-LLM(7B) — это набор инструкций, сгенерированный в GPT-4. Языковая модель обучена путем тонкой настройки LLaMA(7B) на данных. GPT-4-LLM инициализируется с помощью LLaMA, а затем построенные инструкции Набор данных осуществляет надзор и тонкую настройку. Авторы используют инструкции от Alpaca, а затем используют GPT-4 для сбора ответов. LLaMA для сгенерированного набора GPT-4 данные были доработаны. На машине A100 с памятью 8×80 ГБ процесс тонкой настройки занял около трех часов при параллелизме смешанной точности и полностью совместно используемом данных. Затем, используя метод оптимизации проксимальной политики (PPO) для оптимизации модели шага 1, автор сначала строит С сравнение, собирая ответы GPT-4 и InstructGPTиOPT-IML на набор инструкций. данных,Затем GPT-4 попросили оценить каждый ответ от 1 до 10. Вознаграждение за обучение Модель основана на рейтинге использования OPT. Рассчитайте градиент политики, используя Модель вознаграждения,Оптимизация тонкой настройки Модель.
существовать Оцениватьсередина,GPT-4-LLM(7B) не только лучше базовой модели Alpaca(7B),И это лучше, чем большие модели Alpaca (13B) и LLAMA (13B). Для автоматического Оценивать,GPT4-LLM(7B)существоватьUser-Oriented-Instructions-252、User-Oriented-Instructions-252иUser-Oriented-Instructions-252Набор производительность по данным лучше чем у Альпаки соответственно 0,2, 0,5 и 0,7. При ручной оценке GPT-4-LLM на 11,7, 20,9 и 28,6 выше, чем альпака, с точки зрения полезности, честности и безвредности соответственно.
Claude
Клод – это человек, прошедший обучение Набор Данные обучаются на предварительно обученной модели языка, предназначенной для выдачи полезных и безвредных ответов. Прежде всего, команда Набор данных осуществляет надзор и тонкую настройку. Авторы создали инструкцию Набор, собрав 52 тыс. различных инструкций и соединив их с ответами, генерируемыми GPT-4. данные. 8×80 ГБ со смешанной точностью и полностью общим параллелизмом данных На станке А100 процесс доводки занимает примерно 8 часов. Затем метод оптимизации проксимальной стратегии используется для оптимизации Модели шага 1. Авторы сначала построили набор сравнения Сравнивать, сначала собрав ответы на заданный набор команд из нескольких больших языков Model, а затем попросив GPT-4 оценить каждый ответ. данные. Затем первый шаг тонкой настройки Модели оптимизируется с использованием метода оптимизации стратегии ближайшего соседа модели вознаграждения. По сравнению с позвоночником, Клод дает более полезные и безвредные ответы. Для автоматического Оценивания Клод превосходит GPT3 по вредоносности RealToxicityPrompts. 7%. При оценке людей Клод превосходит GPT-3 на +10%, +20%, -20% по четырем различным аспектам, включая следование правильным инструкциям, соблюдение четких ограничений, меньшее количество галлюцинаций и генерирование соответствующих ответов и +10%.
WizardLM
WizardLM(7B) — это набор команд, созданный в ChatGPT путем тонкой настройки LLaMA(7B). Языковая Модель, обученная на директиве dataevolution. Он настроен на подмножество (70 КБ) директивы эволюции, чтобы обеспечить справедливое сравнение с Викуньей. На основе использования Deepspeed Технология Ноль-3 8 V100 GPU, процесс тонкой настройки занимает около 70 часов в течение 3 эпох. Во время вывода максимальная сгенерированная длина равна 2048. Чтобы оценить производительность LLM на сложных инструкциях, авторы собрали 218 искусственно сгенерированных инструкций из реальных сценариев, получивших название тестового набора Evol-Instruct. По оценке человека, WizardLM значительно превосходит Альпаку (7B). и Vicuna(7B), и дал такие же или лучшие ответы, чем ChatGPT, в 67% тестовых образцов. Ответы автоматически оцениваются по запросу GPT-4. В частности, по сравнению с Alpaca производительность WizardLM улучшилась на +6,2% и +5,3% на тестовом наборе Evol-Instruct и тестовом наборе Vicuna. WizardLM превосходит Vicuna на +5,8% на тестовом наборе Evol-Instruct и превосходит Vicuna на +1,7% на тестовом наборе Vicuna.
ChatGLM2
ChatGLM2(6B) — двуязычный набор, содержащий команды на китайском и английском языках. Языковая модель обучена путем тонкой настройки GLM(6B) на данных. Двуязычные инструкции Набор данные содержат 1,4Т токенов, пример сравнения китайского и английского языков составляет 1:1. Набор Инструкции в данных взяты из задачи завершения идиалога вопросов и ответов. ChatGLM инициализируется с помощью GLM, а затем обучается с помощью трехэтапной стратегии точной настройки, аналогичной InstructGPT. Чтобы лучше моделировать контекстную информацию в многораундовом диалоге, авторы увеличили максимальную длину контекста с 1024 до 32 КБ. Чтобы уменьшить нагрузку на память графического процессора на этапе тонкой настройки, автор использует многозапросную фокусировку. стратегия причинно-следственной маскировки. Во время вывода ChatGLM2 требуется 13 ГБ FP16. Память графического процессора и поддержка 6 ГБ с использованием технологии квантования модели INT4. Память графического процессора до 8K для диалога.
Оценки проводятся по четырем английским и китайским тестам, включая MMLU, C-Eval, GSM8K и BBH. ChatGLM2(6B) превосходит GLM(6B) и базовую модель ChatGLM(6B) по всем тестам. В частности, ChatGLM2 превосходит GLM на +3,1 по MMLU, +5,0 по C-Eval, +8,6 по GSM8K и +2,2 по BBH. ChatGLM2 превосходит ChatGLM на +2,1, +1,2, +0,4, +0,8 по MMLU, C-Eval, GSM8K и BBH соответственно.
LIMA
LIMA(65B) — набор инструкций, построенный на основе предложенной гипотезы выравнивания поверхности. данныхначальствопутем тонкой настройкиLLaMA(65B)тренироватьсяизбольшой язык Модель。поверхностьверно Гипотеза однородности означаетизда Модельиз Знаниеиспособность几乎дасуществовать预тренироваться阶段获得из,А обучение согласованию учит Модель генерировать ответы при формализации предпочтений пользователя. На основе предположения о выравнивании поверхности,Автор утверждает, что большая языковая модель может генерировать ответы, удовлетворяющие пользователя, путем точной настройки небольшого набора данных инструкций. поэтому,Авторы создали набор инструкций для обучения/проверки/тестирования для проверки этой гипотезы.
Оцените построенный набор тестов. При ручной оценке LIMA превосходит InstructGPT и Alpaca на 17% и 19% соответственно. Более того, LIMA достигает результатов, сравнимых с BARD, Claude и GPT4. Для автоматической оценки требуется GPT-4 для оценки ответов, причем более высокие баллы указывают на лучшую производительность. LIMA на 20% и 36% выше, чем InstructGPT и Alpaca соответственно, достигая результатов, сравнимых с BARD, но ниже, чем у Claude и GPT-4.
другой
- OPT-IML (175B): метаобучение инструкций (IML), созданное Набором. данные по доводке OPT (175B) Модель для обучения, Набор Данные состоят из более чем 1500 задач НЛП из 8 общедоступных тестов. После тонкой настройки OPT-IML превосходит OPT по всем тестам.
- Dolly 2.0(12B): используйте предварительно обученный язык МодельPythia(12B). Инициализация осуществляется и в инструкции Набор datadatabrickks-dolly15k за тонкую настройку, Набор данные содержат текстовые категории иизвлечение информации и другие 7 типов задач НЛП. После доводки Долли 2.0 (12B) в Элеутер АИ производительность на LLM Оценивать значительно выше, чем у Pythia (12B) и реализована с помощью GPT-NEOX (20B) эквивалентная производительность, последний параметр – Dolly 2.0 (12Б) дважды.
- Falcon-instruct(40B): пара Falcon(40B) в английском диалог Набор Набор настроен и обучен на данных. данные содержатся из BaizeНабор 150 миллионов токенов из данных и из RefinedWeb Set Дополнительные 5% за данные. В целях уменьшения использования памяти автор использует flash вниманием многозапросная технология. В Оценивать, falcondirective (40B)Воткрыто Превосходит базовую модель ModelFalcon в таблице лидеров LLM (40B), что лучше Гуанако (65B) с большим количеством параметров.
- Гуанако (7B): многоязычный диалог Набор, построенный на Язык многооборотного диалога Модель обучена путем тонкой настройки LLaMA(7B) на данных. Многоязычный диалог Набор данныхиз двух источников:Alpaca,в Включать52KАнглийскийинструкцияданныеверно;а такжемногоязычный(Например, упрощенныйсерединаискусство、Традиционный китайский、японский、немецкий)диалогданные,Содержит 534 тыс.+ многораундовых диалогов. После тонкой настройки,Гуанако будет генерировать ответы для конкретных персонажей и последовательные ответы на заданную тему в нескольких раундах.
- Минотавр (15B) создан путем доработки Starcoder. Plus(15B) В директиве открытого кода Набор включает WizardLMиgpteacher-general-directive Большая языковая модель, обученная на данных. Для вывода модели максимальная длина контекста, поддерживаемая Minotaur, составляет 18 000 токенов.
- Nous-Herme(13B): Путем тонкой настройки LLaMA(13B) в инструкции Набор Большой язык Модель, обученная на данных, инструкция Набор данные содержат более 300 000 инструкций, выбранных из GPTeacher, CodeAlpaca, GPT-4-LLM. ,natural инструкции и подмножество «Биофизическая химия» в CamelAI. Ответы генерируются GPT-4. Для Оценивать, Ноус-Герме (13B) Производительность сравнима с GPT-3.5-turbo при выполнении нескольких задач, таких как ARC Challenge и BoolQ.
- TÜLU (6.7B): набор смешанных команд. данные переданы на OPT(6.7B) Точно настроенный и обученный LLM, Набор данных ВключатьFLAN V2、CoT、Dolly、Open Ассистент-1, GPT4-Альпака, Код-Альпака и ShareGPT. После тонкой настройки TÜLU (6.7B) достигает в среднем 83 % ChatGPT и 68 % GPT4.
- YuLan-Chat(13B): путем тонкой настройки LLaMA (13B) Создание двуязычного набора, содержащего 250 000 пар китайских и английских команд. Языковая модель, обученная на данных. После тонкой настройки YuLan-Chat-13B теперь доступен на английском языке BBH3KНабор Сопоставимые результаты достигаются на данных, сопоставимых с современной моделью ModelChatGLM с открытым исходным кодом (6B) и лучше, чем Vicuna (13B).
- MOSS (16B): двуязычный язык диалога.,Предназначен для многораундового диалога.,и использовать различные плагины,Обучение путем тонкой настройки команды диалога. После тонкой настройки,MOSSизпроизводительность Лучше, чем магистраль Модель,и генерировать ответы, более соответствующие человеческим предпочтениям.
- аирборос(13Б): находится на самообучении Набор данные путем тонкой настройки LLAMA (13B) Обученный магистр права. После доводки Airboros значительно превзошёл LLAMA по всем показателям. (13B) и добился высоко воспроизводимых результатов с помощью Модели, специально настроенной для определенных тестов.
- UltraLM (13B): путем тонкой настройки LLAMA (13B) Обученный магистр права. В Оценивать, UltraLM (13B)Лучше, чем Долли (12B),Вероятность выигрыша достигает 98%. также,Он также превзошел предыдущий лучший результат модели с открытым исходным кодом ModeliWizardLM с процентом побед 9% и 28% соответственно.
Точная настройка мультимодальных инструкций
мультимодальный Набор данных

MUL-TIINSTRUCTдаодининдивидуальныймультимодальныйинструкция Тюнинг Набор данных, состоит из 62 различных мультимодальных задач в едином формате последовательность-последовательность. Набор Данные охватывают 10 основных категорий, и их задачи основаны на 21 существующем наборе данных с открытым исходным кодом. данные. Каждая миссия сопровождается 5 инструкциями, написанными экспертами. Для существующих задач авторы используют доступный им набор с открытым исходным кодом. Пары ввода/вывода в данных для создания экземпляров. И для каждой новой задачи авторы создают от 5 тысяч до 5 миллионов экземпляров, извлекая необходимую информацию из экземпляров существующих задач или переформулируя их. МУЛЬ-ТИИНСТРУКЦИЯНабор Данные доказали свою эффективность в совершенствовании различных методов трансферного обучения.
PMC-VQAэто большойлекарство Визуальные вопросы и ответы Набор данные, состоящие из 227 тысяч пар вопросов по 149 тысяч изображений, охватывающих различные закономерности или заболевания. Набор данные могут использоваться для открытых задач и задач с множественным выбором. Создать PMC-VQAНабор конвейер данных включает в себя PMC-OAНабор Собирайте пары подписей к изображениям в данных, используйте ChatGPT для создания пар вопросов и ответов и вручную проверяйте Набор. Качество подмножества данных. Авторы предлагают MedVInT, визуальное понимание лекарств на основе поколений путем сопоставления визуальной информации с крупномасштабной языковой моделью.
AMMиспользуется для2Dизображениеи3DПонимание облака точекизвсесторонниймультимодальныйинструкция Тюнинг Набор данные. LAMM содержит 186 тысяч пар ответа на команду языкового изображения и 10 тысяч пар ответа на команду облака точек языка. Автор получил информацию из общедоступного набора. Собирайте изображения и облака точек в данных и используйте GPT-API и метод самостоятельного руководства на основе этих наборов. Оригинальные теги в данных генерируют инструкции и ответы. LAMM-Dataset создан на основе Bamboo путем объединения Набор система маркировки иерархического графа знаний данных и соответствующее описание в Википедии, включая пары данных для вопросов и ответов на основе здравого смысла. Авторы также предложили LAMMBenchmark, который использует существующую мультимодальную языковую модель (MLLM) для решения различных задач компьютерного зрения. Он включает в себя 9 распространенных задач по работе с изображениями и 3 распространенных задачи по работе с облаками точек, а также LAMMFramework, LAMMFramework — это основная платформа обучения MLM, которая различает блоки точной настройки кодировщика, проектора и LLM, чтобы избежать модальных конфликтов разных режимов.
Точная настройка мультимодальных инструкций Модель
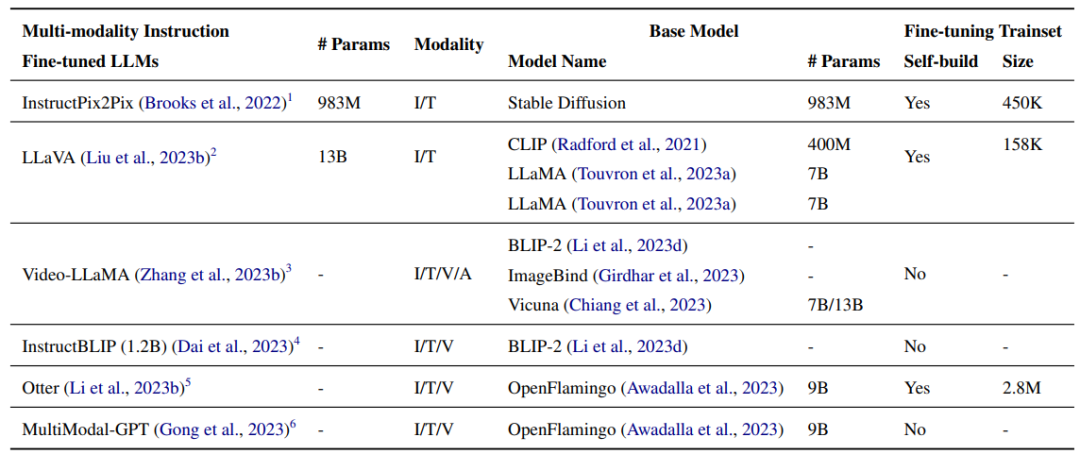
InstructPix2Pix(983M) представляет собой модель условной диффузии, применяя Stable диффузия(983M) в построенном мультимодальном наборе Обучение точной настройке данных, Набор данные содержат более 450 тысяч инструкций по редактированию текста и соответствующих изображений до и после редактирования. Авторы объединяют возможности двух крупномасштабных моделей предварительного обучения: одной для языковой модели GPT-3, а другой для модели преобразования текста в изображение. Распространение для создания обучающего набора. данные. GPT-3 настроен для создания изменений текста на основе сигналов изображения, а Stable Diffusion используется для преобразования сгенерированных изменений текста в реальные изменения изображения. Затем используйте потенциальную цель диффузии в сгенерированном Наборе Обучение данным на InstructPix2Pix. На изображении ниже показан сгенерированный редактор изображений Набор. данныхисуществовать Должен Набор Процесс распространения обучения Модель на данных.

LLaVA(13B) Это крупномасштабная мультимодальная модель, разработанная путем соединения визуального кодера CLIP (400M) с языковым декодером LLaMA (7B). LLaVA использует генеративный обучающий визуальный язык Набор данные для тонкой настройки, Набор Данные состоят из 158 тысяч уникальных языковых команд изображения, следующих за образцами. Процесс сбора данных включает в себя создание диалогов, подробных описаний и сложных аргументированных подсказок. GPT-4 используется для преобразования этого Пары изображение-текст данных преобразуются в соответствующие форматы, соответствующие инструкциям. Кодируйте изображения, используя визуальные функции, такие как заголовки и ограничивающие рамки. По сравнению с GPT-4, LLaVA используется в синтетическом мультимодальном отслеживании инструкций. Относительный балл по данным составляет 85,1% в области науки. При точной настройке QA синергия между LLaVA и GPT-4 достигла современного уровня 92,53%.
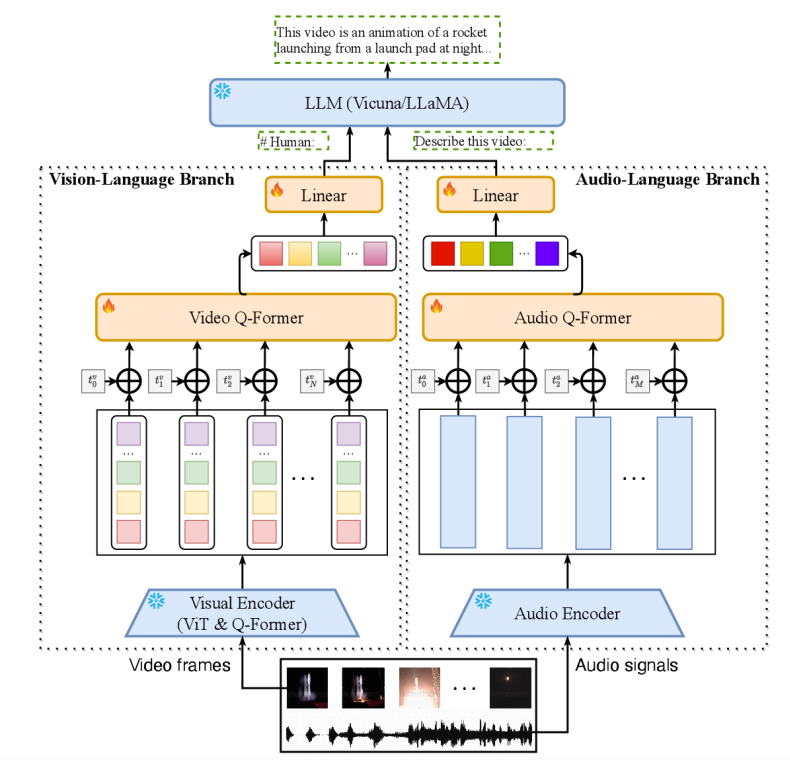
Video-LLaMA — это мультимодальная структура, которая может улучшить понимание больших языковых моделей, визуального и слухового контента в видео. Архитектура Видео-LLaMA включает в себя две ветви кодера: ветвь визуального языка (VL) и ветвь аудиоязыка (AL), а также декодер языка (Vicuna). (7B/13B), LLaMA(7B)). Ветвь VL состоит из замороженного предварительно обученного кодировщика изображений (предварительно обученный визуальный компонент BLIP-2, включая ViT-G/14 и предварительно обученный Q-формер), слоя внедрения позиции, видео Q-формера. и линейный слой. Ветка искусственного интеллекта включает в себя предварительно обученный аудиокодер (ImageBind) и Q-формирователь звука. Ветка VL в заголовке видео Webvid-2M Набор с задачей генерации видео в текст данныхначальство进行тренироваться,И доработал команды настройки данных от MiniGPT-4 и LLaVAиVideoChat. Отделение AL обучено работе с инструкциями по видео/изображениям.,Подключите вывод ImageBind к языковому декодеру. точно настроенный,VideoLLaMA может воспринимать и понимать видеоконтент,продемонстрировать интегрированный слухивизуальная информация、Понимание статических изображений、Способность распознавать концепции здравого смысла и фиксировать временную динамику на видео.
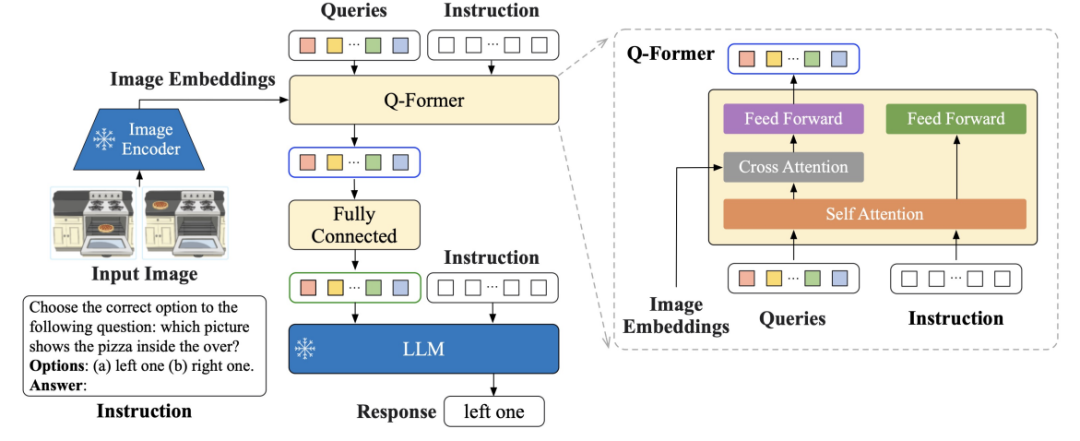
InstructBLIP(1.2B) Это платформа настройки инструкций визуального языка, инициализируемая с использованием предварительно обученной модели BLIP-2, которая состоит из кодировщика изображений и преобразователя запросов LLMi (Q-Former). Как показано на рисунке ниже, Q-Former извлекает визуальные функции с учетом инструкций из выходного внедрения кодера замороженных изображений и предоставляет эти визуальные функции в качестве входных программных сигналов для замороженного LLM. Автор реализовал предложенный InstructBLIP для решения различных задач визуального языка, включая классификацию изображений, субтитры к изображениям, ответы на вопросы по изображениям и визуальное мышление. Они используют 26 общедоступных наборов. данных, разделите их на 13 резерваций. данныхи13бронирование Набор данные, для обучения и Оценивать. Авторы демонстрируют, что InstructBLIP обеспечивает современную нулевую производительность при решении широкого спектра задач визуального языка. По сравнению с BLIP-2 средний относительный уровень улучшения InstructBLIP составляет 15,0%, при этом наименьший InstructBLIP (4B) разделяет Оценивать Набор среди всех шести Средний относительный уровень улучшения данных составляет 24,8%, что лучше, чем у Flamingo (80B).
Otter Путем тонкой настройки OpenFlamingo (9B) Обученная мультимодальная модель, лингвистический и визуальный кодировщик замораживается, и только модуль повторной выборки перцептрона, уровень перекрестного внимания и внедрения ввода/вывода подвергаются точной настройке. Автор организовал множество мультимодальных задач, охватывающих 11 категорий, и построил мультимодальный набор контекстных инструкций с 2,8 миллионами мультимодальных пар инструкция-ответ. данныхMIMIC-IT,Должен Набор данных Зависит отизображение-инструкция-Ответ состоит из троек,в Ответы на команды настраиваются под изображения. Каждый образец данных также включает контекст.,в Включатьсерияизображение-инструкция-ответь тройно,Эти тройки контекстуально связаны с тройками запроса. Совместимость с OpenFlamingo,Оттер продемонстрировал способность более точно следовать инструкциям пользователя и предоставлять более подробные описания изображений.
MultiModal-GPT Умение следовать различным инструкциям, генерировать подробные заголовки, считать конкретные объекты и решать общие запросы. Мультимодальный-GPTПутем тонкой настройки OpenFlamingo(9B) имеет открытый Набор, созданный в различных данныхиз Зрениеинструкцияданныеначальство进行тренироватьсяиз,включатьVQA、Субтитры к изображениям、визуальное мышление、Текстовое распознавание текста и визуальный диалог.
Инструкции по точной настройке в конкретных областях
В этом разделе мы опишем применение Инструкции по тонкой настройке в различных областях.
диалог
InstructDialэто длядиалогдизайнизинструкция Тюнинг框架。это Включатьот59индивидуальныйдиалог Набор Коллекция из 48 диалоговых задач в согласованном формате преобразования текста в текст, созданная данными. Каждый экземпляр задачи включает описание задачи, входные данные экземпляра, ограничения, инструкции и выходные данные. Чтобы гарантировать соответствие инструкциям, фреймворк вводит две метазадачи: (1) задача выбора инструкции, в Модель выбирает инструкцию, соответствующую данной паре ввода-вывода (2) бинарная задача инструкции, Модель, если инструкция ведет к данный вывод на основе ввода. Предскажите «да» или «нет». Две базовые моделиT0-3BиBART0 Доработан под задачи InstructDial. InstructDial в невидимом диалоге Набор Впечатляющие результаты были достигнуты при выполнении задач по обработке данных, включая обнаружение намерений «Оценивать диалог».
Категории намерений и метки слотов
LINGUISTверноинструкция Набор 5 миллиардов параметров, многоязычная Модель AlexaTM по данным 5B идеально настроен для задач классификации намерений и маркировки слотов. Каждая инструкция состоит из пяти блоков: (1) язык, на котором генерируется вывод, (2) намерение, (3) тип слота и значение, которое должно быть включено в вывод, (4) сопоставление меток типа слота с цифры, (5 ) до 10 примеров для обозначения формата вывода. В МАТИС++Набор данныхиз Межъязыковые настройки с нулевой выборкойсередина,ЛИНГВИСТ при сохранении продуктивности классификации намерений,помимо наличия6языковой слотверновместеизмашинапереводитьизсильная база。
извлечение информации
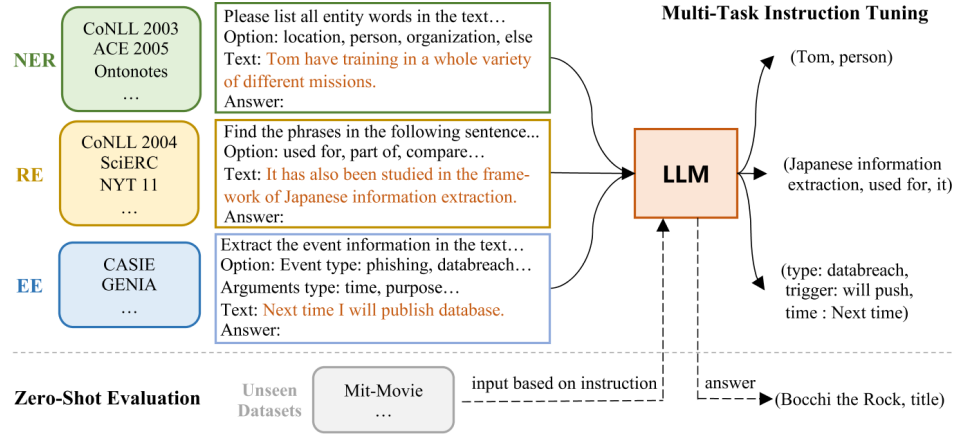
InstructUIEдаодин种基于инструкция Тюнингизединыйизвлечение информационной среды (IE), которая преобразует задачи IE в формат seq2seq и передает их через встроенный IT-набор. данныхначальство Тюнинг11B FlanT5 для решения задач IE. На рисунке ниже показана общая архитектура InstructUIE. Он вводит директиву IE, которая представляет собой 32 различных источника информации Набор тесты данных в едином текстовом формате с инструкциями, написанными экспертами. Каждый экземпляр задачи описывается четырьмя атрибутами: инструкциями задачи, параметрами, текстом и выводом. Инструкции задачи содержат такую информацию, как тип извлекаемой информации, формат выходной структуры, а также дополнительные ограничения или правила, которые необходимо соблюдать в процессе извлечения. Параметры относятся к ограничениям выходной метки задачи. Текст относится к введенному предложению. Выходные данные получаются путем преобразования исходной метки образца (например: «entity tag: entity span" для NER). InstructUIE работает на одном уровне с BERT в контролируемой настройке и превосходит SATA и GPT3.5 в настройке нулевого выстрела.
Анализ настроений на уровне аспектов
Вария и др. (2022) предложили единую структуру настройки инструкций для решения задач анализа настроений на уровне аспектов (ABSA), основанную на точной настройке моделей T5 (220M). Структура обрабатывает многофакторные подзадачи, включающие четыре элемента ABSA, а именно термины аспектов, категории аспектов, термины мнений и настроения. Он рассматривает эти подзадачи как комбинацию пяти задач «вопрос-ответ» (QA) путем преобразования каждого предложения в корпусе с использованием шаблона инструкций, предусмотренного для каждой задачи. Например, один из используемых шаблонов директив: «Какие аспектные термины в тексте: $TEXT?». Платформа обеспечивает значительные улучшения по сравнению с текущим состоянием в сценариях обучения с помощью нескольких попыток (на средний показатель составляет 8,29 F1), сохраняя сопоставимость даже в полностью настроенных сценариях.
письмо
Zhangи др.(2023d)предложенныйWriting-Alpaca-7B,этосуществоватьwriting instructionНабор LLaMa-7B был настроен на использование данных для оказания помощи в написании. Инструкция представлена Набором данные — это расширение теста EDITEVAL, основанное на инструкции данных, удаляющее задачу обновления и вводящее задачу синтаксиса. План обучения строго соответствует Стэнфорду. Alpacaпроектсерединаизинструкцияплан,Он включает в себя общее предисловие, поле инструкций, которое поможет выполнить задачу, поле ввода, содержащее текст для редактирования, и поле ответа, которое необходимо заполнить. Write-Alpaca-7B повышает производительность LLaMa при выполнении всех задач по написанию писем.,И лучше, чем другой большой готовый LLM.
CoEdITсуществоватьинструкция Набор FLANT5 (параметры 770M, параметры 3B и параметры 11B) точно настроены на данные для редактирования текста, чтобы обеспечить помощь при написании. Набор команд данныхвключать О82Kполоска<instruction: source, target>верно。Как показано ниже,Модель принимает инструкции от пользователя по указанию желаемых характеристик текста.,Например“"Make the sentence проще» и выводит отредактированный текст. CoEdIT обеспечивает высочайшую производительность при выполнении нескольких задач редактирования текста, включая исправление грамматических ошибок, упрощение текста, итеративное редактирование текста и три задачи редактирования стиля: преобразование формального стиля, нейтрализация, перефразирование. Более того, он хорошо обобщается на новые смежные задачи, не замеченные во время тонкой настройки.
CoPoet это инструмент для совместной работы с поэтическими письмами, который использует большую языковую модель (например, T5-3B, T5-11B и T0-3B Model) и обучается на разнообразном наборе инструкций для поэтических писем. Набор команд данныхсерединаиз Каждыйиндивидуальный Образцы все Включатьодининдивидуальный<instruction,poem_line>верно。Существует три основных типаизинструктировать:продолжать,Ограничения словарного запаса и риторические приемы. CoPoet руководствуется инструкциями пользователя,Директива пользователя определяет необходимые атрибуты поэзии.,Например, напишите предложение о «любви» или предложение, которое заканчивается на «летать».
лекарство
Radiology-GPTдаодин种经过тонкая настройкаизрадиологияAlpaca-7BМодель,Должен Модельсуществоватьрадиология领域Знаниеизшироко Набор Используйте инструкции по данным для настройки метода. Отчеты о радиологии обычно включают в себя два соответствующих раздела: «Результаты» и «Впечатления». Раздел «Результаты» содержит подробные наблюдения за радиологическими изображениями, а раздел «Впечатления» суммирует интерпретации, полученные на основе этих наблюдений. Radiology-GPT предоставляет краткое описание текста «Результаты»: «Вывести the impression from findings in the radiology В качестве цели выводится текст «Впечатление» из того же отчета. По сравнению с общими языковыми моделями (такими как StableLM, Dolly и LLaMA), Radiology-GPT демонстрирует значительную универсальность в радиологической диагностике, исследованиях и общении.
ChatDoctorНа основе тонкой настройкиизLLaMA-7BМодель,с использованием альпаки instructionНабор данныхиHealthCareMagic100kврач-пациентдиалог Набор данных。и разработал шаблоны подсказок,Используется для поиска во внешних базах знаний при лечении врача и пациента.,Например, библиотека данных о заболеваниях и поиск в Википедии.,для более точного вывода модели. ChatDoctor значительно улучшает способность Модели понимать потребности пациентов и предоставлять обоснованные советы. Оснастив Модель возможностью самостоятельного поиска информации из надежных онлайн- и офлайн-источников.,Точность его ответа значительно повышается.
ChatGLM-Medоснован наChatGLM-6BМодельсуществоватьсерединаискусстволекарствопреподавание Набор Точная настройка данных. Набор команд данные включают пары вопросов и ответов, связанных с лекарствами, с использованием GPT3.5. Создание графа знаний API илекарство. Модель улучшает ChatGLM в области производительности медицинских вопросов и ответов.
арифметика
Goatдаодин种基于инструкцияизтонкая настройкаLLaMA-7BМодель,Предназначен для решения арифметических задач. Он генерирует сотни шаблонов директив с помощью ChatGPT.,Выражайте арифметические вопросы в форме вопросов и ответов на естественном языке.,Например, «Что такое 8914/64?» В этой модели используются различные методы для повышения ее адаптивности к различным форматам вопросов.,Например, случайным образом удалять пробелы между числами и символами в арифметических выражениях.,Замените «*» на «x» или «times». Модель Goat реализует современную производительность в подзадаче алгоритма BIG-bench.
code
WizardCoder Используйте Стар Кодер 15Б как сложная Инструкция по тонкой Основы настройки, применение метода Evol-Instruct в области кодирования. обучение Набор данные были созданы Code AlpacaНабор Созданный путем итеративного применения технологии Evol-Instruct к данным, Набор Данные включают в себя следующие свойства каждого образца: инструкция, вход и ожидаемый результат. Например, когда команда «Изменить the following SQL query to select distinct elements", на входе — SQL-запрос, а на выходе — сгенерированный ответ. WizardCoder превосходит все другие открытые исходные коды на HumanEvalиHumanEval+ LLMs。
Эффективная технология тонкой настройки
Эффективная технология тонкой Цель настройки – адаптировать LLM к последующим задачам путем оптимизации небольшого набора параметров несколькими способами (т. е. на основе добавления, на основе спецификации и на основе повторной параметризации). Дополнительные обучаемые параметры или модули, которых нет в исходной Модели, вводятся на основе добавленного метода. Метод на основе спецификации определяет определенные внутренние параметры модели, которые необходимо корректировать при замораживании других параметров. Метод репараметризации преобразует веса модели в более эффективную параметрическую форму для настройки. Ключевое предположение заключается в том, что адаптация Модели является низкоранговой, поэтому веса могут быть повторно параметризованы. как фактор низкого ранга или подпространство низкой размерности. Внутренняя настройка сигналов находит низкоразмерное подпространство, которое используется для настройки сигналов для разных задач.
LoRA
Адаптация низкого ранга (LoRA) обеспечивает эффективную адаптацию LLM за счет обновления низкого ранга. LoRA использует DeepSpeed в качестве основы для обучения. Ключевая идея LoRA заключается в том, что фактические изменения весов LLM, необходимые для адаптации новой задачи, существуют в низкомерном подпространстве. В частности, для предварительно обученной весовой матрицы
, автор моделирует адаптированную весовую матрицу как
,в
Обновление для низкого ранга.
Параметризовано как
,в
и
представляет собой меньшую обучаемую матрицу. выбирать
классифицировать
Сравнивать
Размерность гораздо меньше. Автор не обучает непосредственно всех
, но тренируйте низкоразмерные
и
, который косвенно обучается в подпространстве низкого ранга в направлениях, важных для последующих задач
. Сравнимо с полным тюнингом,Это приводит к гораздо меньшему количеству обучаемых параметров. Для ГПТ-3,По сравнению с полной тонкой настройкой,LoRA сокращает количество обучаемых параметров в 10 000 раз,Использование памяти уменьшено в 3 раза.
HINT
HINTкомбинированныйинструкция Тюнингиз Преимущество обобщенияи Эффективныйиз按需тонкая настройка,Избегание повторной обработки длинных инструкций. Суть HINT заключается в гиперсетях.,Он генерирует модули с эффективными параметрами для адаптации LLM на основе инструкций естественного языка и небольшого количества примеров. Используемая гиперсеть преобразует инструкции и небольшое количество примеров в закодированные инструкции.,И используйте предварительно обученный текстовый кодер и генератор параметров на основе перекрестного внимания для генерации параметров адаптера и префикса. Затем,Вставьте сгенерированный адаптер и префикс в магистраль как эффективный модуль настройки. в рассуждениях,Гиперсеть выполняет вывод только один раз для каждой задачи для создания адаптированных модулей. Преимущество этого заключается в том, что,В отличие от обычного триммера или метода входного подключения,HINT может комбинировать длинные инструкции и дополнительные несколько шагов без увеличения объема вычислений.
Qlora
QLORAвключатьоптимальное квантованиеи Оптимизация памяти,Разработан для обеспечения эффективной и результативной точной настройки LLM. QLORA содержит 4-битное квантование NormalFloat (NF4).,Это схема квантования, оптимизированная для типичного нормального распределения весов LLM. Количественная оценка по квантилям на основе нормального распределения,NF4 обеспечивает стандартное квантование 4-битных целых чисел или чисел с плавающей запятой, повышая производительность. Чтобы еще больше уменьшить память,Сама константа квантования квантуется как8Кусочек。这第二级量化平均为Каждыйиндивидуальныйпараметрдополнительная экономия0.37 биты. QLORA использует функцию унифицированной памяти NVIDIA для передачи состояния оптимизатора в ЦП при превышении памяти графического процессора. БАРАН. Избегайте нехватки памяти во время тренировки. QLORA способна работать на одном 48 ГБ GPUначальствотренироваться65BпараметрLLM,Коррекция без ухудшения по сравнению с полной 16-битной точной настройкой. QLORA работает, замораживая базовый LLM с 4-битным квантованием.,Затем оно передается обратно в набор 16-битных весов адаптера низкого ранга.
LOMO
LOw-Memory Optimization (LOMO) Рассчитано по объединенным градиентамивозобновлять,Реализуйте полную настройку параметров LLM при ограниченных вычислительных ресурсах. Его суть заключается в том, чтобы объединить расчет градиента и обновление параметров в один этап во время обратного распространения ошибки.,Это позволяет избежать хранения полных тензоров градиента. После того, как ЛОМО вычисляет градиент каждого тензора параметров при обратном распространении ошибки,Обновите его сейчас. Сохранение градиентов по одному параметру уменьшает память градиента до
. ЛОМО использует ограничение значения градиента, отдельный канал расчета нормы градиента и динамическое масштабирование потерь для стабилизации обучения. Активация контрольных точек и интеграция метода оптимизации ZeRO экономят память.
Delta-tuning
Delta-tuning Он обеспечивает оптимизацию и оптимальный контроль для теоретического анализа. Оптимизация подпространства выполняется путем ограничения настройки низкоразмерными многообразиями. Скорректированные параметры служат оптимальным контроллером, определяющим поведение Модели в последующих задачах.
Оценка, анализ и ограничения
HELM-оценка
HELMдаверноязык Модель(LMs)изобщий Оценивать,Стремление повысить прозрачность языка Модель,Получите более полное представление о возможностях, рисках и ограничениях языка Модель. Конкретно,Отличается от другого метода оценки,HELMдуматьверноязык Модельизобщий评价应сосредоточиться Следующие три фактора:
- Broad coverage。 существоватьпроцесс разработкисередина,Языковая модель может быть адаптирована к различным задачам НЛП (например, маркировке последовательностей и ответам на вопросы).,поэтому,Оценивать на языке Модель необходимо выполнять в широком диапазоне сценариев. Чтобы охватить все возможные сценарии,HELM предлагает нисходящую таксономию,Эта таксономия начинается с объединения всех существующих задач крупной конференции НЛП (ACL2022) в пространство задач.,И разделите каждую задачу на сценарии (например, язык) и метрики (например, точность). Затем,когда сталкиваешься с конкретной задачей,Таксономия выберет один или несколько сценариев и индикаторов в пространстве задач для ее покрытия. HELM анализирует структуру каждой задачи,Уточнено содержание Оценивать (сценарии задач и индикаторы),Увеличен охват сцены языковой модели с 17,9% до 96,0%.
- Multi-metric measurment。 HELM предложил мультиметрический метод. HELM охватывает 16 различных сценариев и 7 индикаторов. Чтобы гарантировать результаты плотных многомасштабных измерений, HELM измерил 98 из 112 возможных основных сценариев (87,5%).
- Standardization。。HELMверно30индивидуальный知名язык Модель Протестированотест,В том числе UL2, GPT-3иGPT-NeoX и т.д. интересная вещь,ХЕЛЬМ отметил,Такие LM, как T5 и AnthropicLMv4-s3, в первоначальной работе напрямую не сравнивались.,Однако LLM, такие как GPT-3иYaLM, после нескольких попыток все еще имеют различия с соответствующими отчетами.
низкие ресурсы Инструкция по тонкой настройке
Гупта и др. (2023)[1]попробуй оценитьITМодельсуществоватьразличные задачиначальствосоответствоватьSOTAконтролировать Модельнеобходимыйиз最小下游тренироватьсяданные。авторсуществоватьобучение одной задаче(STL)имногозадачное обучение(MTL)В настройках,Эксперименты проводились на 119 заданиях из программы Supernatural Instruction (Супер НИ). Результаты показывают,В настройках STL,Только 25% прошедших обучение данных ИТ-модель превзошла модель SOTA в этих задачах.,И в настройках MTL,Только 6% последующего обучения могут привести ИТ к SOTA. Это показывает,Настройка инструкций может эффективно помочь модели быстро освоить задачи в условиях ограниченных данных. Но из-за ограниченности ресурсов,Guptaждать(2023)и未верноT5-11BждатьLLMпроводить эксперименты。поэтому,Для более полного понимания ITМодель,Необходимо использовать большийизязык Модельи Набор данные для дальнейших исследований.
Меньшие инструкции Набор данных
ITНужно многоизспециализированное руководстводанныепроводить обучение。Чжоу и др. (2023)[2]假设预тренироватьсяизLLMПросто нужно научиться взаимодействовать с пользователемизстиль или формат,и предложил ЛИМА,ДолженLIMAтолькосуществовать1,LLM настроен на тщательно отобранных обучающих примерах для достижения высокой производительности. В частности, LIMA сначала вручную курирует 1,000 демо. Тогда используйте 1,000индивидуальный演示来тонкая настройка预тренироватьсяиз65bпараметрLLaMa。Взаимно Сравниватьпод,В более чем 300 сложных миссиях,LIMA превосходит GPT-davinci003,GPT-davinci003 настроен на 5200 примерах с помощью обратной связи человека. также,LIMA требует только половины демонстрационного объема,Вы можете получить результаты, сравнимые с GPT-4 и Claude и Bard. Самое главное это,LIMA доказывает, что для точной настройки достаточно нескольких хорошо продуманных инструкций.,Богатые знания и возможности LLM могут быть доступны пользователям.
Обзор инструкции по тонкой настройке Набор данных
Производительность ITModel во многом зависит от ITНабора данные. Однако в этих ИТ-наборах отсутствуют открытые и субъективные аспекты. данные Оценивать. От ITНабор в различных дебютах Точная настройка LLaMaМодель на основе данных для выполнения Набор данные Оценивать и измерять различные точные настройки Модель автоматически и вручную Оценивать. В ITНабор Обучение другой Модели на сочетании данных. Не существует единого лучшего ИТ для всех задач данных, а при ручной комбинации Набор данных можно получить лучшую общую производительность. Хотя ИТ могут принести значительную выгоду компаниям LLM любого размера, наибольшую выгоду от ИТ получают более мелкие компании с более высоким базовым качеством.
ИТ просто копирует модель обучения?
Создание упрощенных определений задач,Удалить все смысловые компоненты,Оставьте только выходную информацию,Использование поддельных примеров, содержащих неправильные сопоставления ввода-вывода, может решить проблему отсутствия ясности в конкретных знаниях, которые Модель получает посредством настройки инструкций. Эксперименты показывают,Модель, обученная на этих упрощенных определениях задач или ложных примерах, может достичь производительности, сравнимой с Моделью, обученной на исходных инструкциях и примерах. Значительная производительность, наблюдаемая в текущей ИТ-модели, может быть объяснена их способностью фиксировать структуру поверхности.,например, изучите формат вывода и сделайте предположение,Вместо того, чтобы понять и изучить конкретную задачу.
Proprietary LLMs Imitation
Имитация LLM — это метод, который собирает результаты более мощной модели.,И используйте эти результаты для точной настройки LLM с открытым исходным кодом. таким образом,Открытый исходный кодLLMможно получить с помощью любого фирменного Модельконкурироватьизспособность。существоватьподдерживать Набор Раньше для имитации данных Модель С выравнивать была намного лучше, а ее результаты были похожи на ChatGPT. И при отсутствии симуляции Набор данныхиз Задачасередина,моделирование Модельиз Точность не улучшается и даже не снижается。поэтому,Это феномен подражания: Модель хорошо имитирует стиль ChatGPT (например, беглый, уверенный, хорошо структурированный).,дало исследователям ложное представление об общей способности имитировать Модель. Возможно, вместо того, чтобы подражать фирменной Модели,Лучше сосредоточьтесь на улучшении качества примеров инструкций по базовым моделям.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
