Обзор | Понимание генеративного представления времени и больших моделей времени в одной статье
Данные временных рядов повсеместно распространены в различных областях, что делает анализ временных рядов крайне важным. Традиционные модели временных рядов ориентированы на конкретные задачи, имеют единственную функцию и ограниченные возможности обобщения. Недавно крупномасштабные модели на основе языка продемонстрировали свои превосходные возможности в переносимости между задачами, обучении с нулевым/несколько раз и интерпретируемостью решений. Этот успех вызвал интерес к изучению базовых моделей для одновременного решения нескольких задач, связанных с временными рядами.
В настоящее время существует два основных направления исследований, а именно предварительное обучение базовых моделей для временных рядов с нуля и адаптация базовых моделей большого языка к временным рядам. Все они облегчают разработку обобщаемых, универсальных и простых для понимания унифицированных моделей для анализа временных рядов.
книга ОбзорПредоставляет структуру анализа 3E,для всестороннего обзора соответствующих исследований. Конкретно,Исследователи рассматривают три измерения(即有效性、эффективностьи Интерпретируемость)изучить существующие работы。в каждом измерении,Основное внимание уделяется тому, как смежные работы могут разрабатывать индивидуальные решения с учетом уникальных проблем области временных рядов. также,Исследователи такжеПредоставляет таксономию доменов, чтобы помочь подписчикам идти в ногу с прогрессом в конкретных областях.,и представляет широкий спектр ресурсов, которые продвигают эту область,Включая сбор данных, проект с открытым исходным кодом и библиотеку временных рядов.

【Название статьи】A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Model
[Бумажный адрес]https://arxiv.org/abs/2405.02358
【Библиотека ресурсов】https://github.com/start2020/Awesome-TimeSeries-LLM-FM
Обзор бумаги
За последние несколько десятилетий машинное обучение и глубокое обучение добились значительного прогресса в различных областях, особенно в компьютерном зрении (CV) и обработке естественного языка (NLP). В отличие от статистических методов, эти методы могут обрабатывать более крупные и разнообразные наборы данных более автоматизированным образом, сокращая требования к человеческому вмешательству и экспертным знаниям. Эти методы представляют собой сложную архитектуру, способную обнаруживать более сложные закономерности, и вызвали значительный интерес со стороны сообщества специалистов по временным рядам. Таким образом, для различных потребностей моделирования временных рядов появилось множество эффективных архитектур с разными основами, включая модели RNN, CNN, GNN, трансформаторы и диффузионные модели.
Хотя эти мощные архитектуры подняли анализ временных рядов на новую высоту, эта область все еще сталкивается с несколькими нерешенными проблемами:
- Первая проблема – возможность передачи знаний。временной рядданные Сезонныйи Тенденции,Также содержит случайность или шум. В связи со сдвигом дистрибуции,Эти характеристики могут существенно различаться в разных областях или в разное время в одной и той же области.,Повышена сложность миграции моделей или представлений поверхности временных рядов.
- Вторая проблема связана с разреженностью данных.。Традициявременной рядданные Установить по дням、Собраны и разрежены по месяцам или годам.,и с учетом ограничений конфиденциальности,Такие данные, как данные классификации электрокардиограммы, получить трудно. Нехватка данных ограничивает эффективное обучение модели глубокого обучения,Существующих наборов данных часто недостаточно для поддержки высококачественного обучения Модели.
- Третья проблема связана с мультимодальным обучением.。в мультимодальном режимевременной ряданализироватьсередина,Интеграция данных различных модальностей может улучшить Модельпроизводительность Интерпретируемость. Например,Интеграция информации из социальных сетей в прогнозы тенденций акций может повысить точность прогнозов. Но согласование мультимодальных данных с разной частотой или интервалами для отражения временных отношений является сложной задачей.,И разные режимы требуют разных технологий для сбора информации.,Интегрируйте эту информацию в целостный комплекс Модели.
- наконец,Интерпретируемость также весьма востребована。Модель Генерируйте прогнозы или выявляйте закономерностииз Подробные объяснения могут значительно улучшитьвременной рядизполезностьиприемлемость。Например,Коммунальным компаниям необходимо обосновать свои решения по прогнозам спроса на энергию перед регулирующими органами и потребителями. Однако,Существующие модели временных рядов в основном представляют собой черные ящики.,Отсутствие объяснения поведения или прогнозов Модели.
Было предпринято несколько попыток решить вышеупомянутые проблемы, такие как перенос обучения для временных рядов, увеличение данных временных рядов, мультимодальный анализ временных рядов и интерпретируемый искусственный интеллект временных рядов. Однако большинство этих работ посвящено отдельным проблемам. Кроме того, модели должны демонстрировать способность беспрепятственно интегрировать данные из разных модальностей и предоставлять понятные объяснения процессов принятия решений.
Привлеченный сильными возможностями обобщения крупномасштабных языковых моделей в различных последующих задачах, основным направлением исследований является применение крупномасштабных языковых моделей (т. е. LLM) к задачам временных рядов. Преимущества больших языковых моделей в обобщении перекрестных задач, обучении с нулевым/несколько раз и выводе могут решить такие проблемы, как передача знаний, нехватка данных и интерпретируемость при анализе временных рядов.

Рисунок 1. Базовая модель применялась в различных задачах и областях анализа временных рядов.
В этом обзоре представлен углубленный анализ прогресса в разработке фундаментальных моделей временных рядов. Обзор основан на четырех исследовательских вопросах, представленных на рисунке 2, и охватывает три аналитических измерения (т. е. результативность, результативность, интерпретируемость) и одну классификацию (т. е. классификацию предметной области).
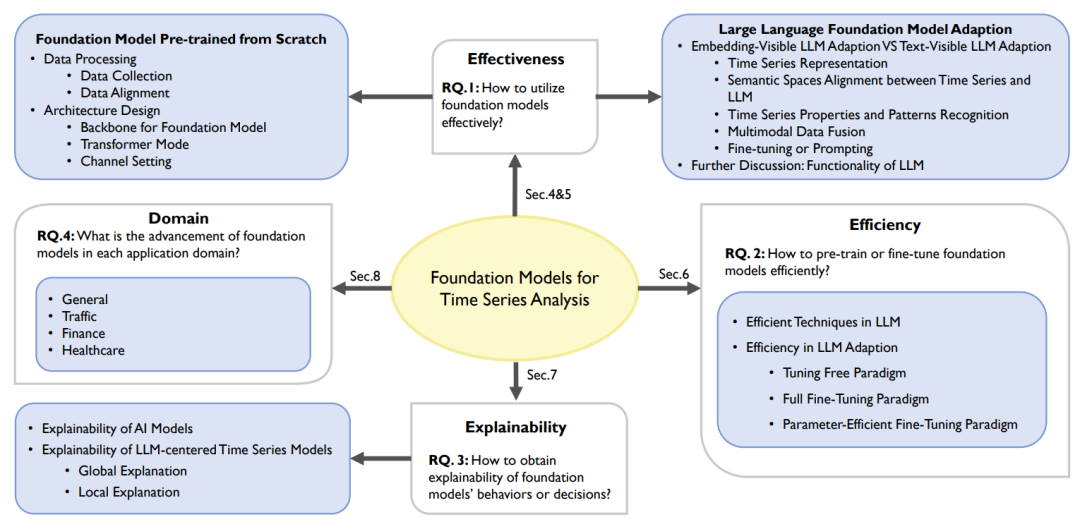
Рисунок 2. Четыре вопроса исследования и соответствующее им содержание и главы.
(1) Как эффективно адаптировать базовую модель в контексте анализа временных рядов?
Исследователи делят соответствующую работу на две категории: предварительное обучение базовых моделей временных рядов с нуля и адаптация LLM к временным рядам. В первом случае обсуждаются сбор и согласование данных, а также проектирование архитектуры. Для последнего были определены две парадигмы адаптации: видимая для внедрения и видимая по тексту, а также обсуждалось использование LLM, извлечения временных рядов и мультимодального объединения данных. Извлечение временных рядов включает в себя такие задачи, как получение соответствующих представлений, выравнивание пространства и выявление атрибутов и закономерностей. Кроме того, разнообразные роли LLM еще больше повышают эффективность адаптации.
(2) Как эффективно предварительно обучить или точно настроить базовые модели для задач временных рядов?
Учитывая, что эта область развивается, современные эффективные методы заимствованы из области НЛП. Поэтому исследователи сначала предоставляют краткий обзор передовых и эффективных методов в области НЛП, которые могут быть применены в этой области. Затем мы обсудим эффективность при различных парадигмах тонкой настройки и подведем итоги использованных эффективных методов.
(3) Как добиться интерпретируемости поведения или решений базовой модели в приложениях временных рядов?
Практическое применение моделей требует интерпретируемости. Исследователи сначала исследовали концепцию объяснимости в ИИ, уделяя особое внимание глобальным и локальным объяснениям. Затем анализируется и уточняется прогресс в области интерпретируемости в существующих исследованиях.
(4) Каков прогресс базовой модели в каждой области применения временных рядов?
Чтобы ответить на этот вопрос, исследователи ввели таксономию доменов. Эта таксономия позволяет сравнивать цели, вклад и ограничения существующих исследований в каждой области. Кроме того, в документе представлены богатые ресурсы, такие как код, наборы эталонных данных, библиотеки временных рядов и инструменты для ускорения LLM, для поддержки будущих исследовательских усилий.
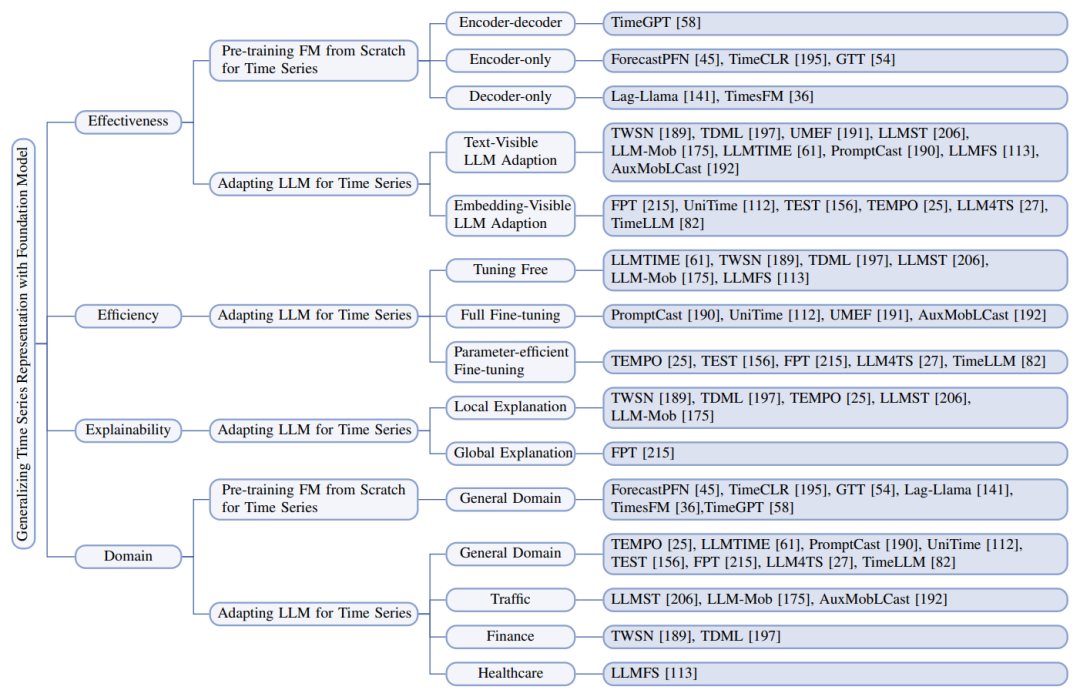
Рисунок 3. Классификация исследованных работ по четырем темам исследований.
Главы настоящего обзора организованы следующим образом:
- Раздел 2 представляет соответствующий Обзор анализа временных рядов База Модели.
- Раздел 3 предоставляет Базе Модели знания о задачах временных рядов.
- Раздел 4 Глубокое погружение во временные ряды этапы предварительного обучения базовой модели。
- Раздель 5 Изучите методы LLM (Large Language Model), адаптированные к задачам временных рядов.
- Раздел 6 обсуждать Модельтонкая настройкаивыводнойэффективность。
- Раздел 7 Подвести итог Изучение объяснения модели поведения или решений.
- В разделе 8 представлен прогресс в каждой области.
- Раздел 9 Предоставляет ресурсы, включая наборы эталонных данных, код, библиотеки временных рядов и инструменты LLM.
Из-за ограниченного объема в этой статье основное внимание уделяется только краткому содержанию разделов 4–7. Заинтересованные друзья могут прочитать исходный текст статьи для получения более подробной информации.
Ключевые этапы предварительного обучения базовой модели
Базовая модель — это модель, которая настроена для адаптации к множеству последующих задач после обучения на крупномасштабных и разнообразных наборах данных. Эти модели основаны на глубоком обучении и сочетают в себе обучение с самоконтролем и трансферное обучение. По мере увеличения масштаба они демонстрируют мощные возможности обучения с нулевым/несколько раз и цепного мышления, особенно в области НЛП и CV.
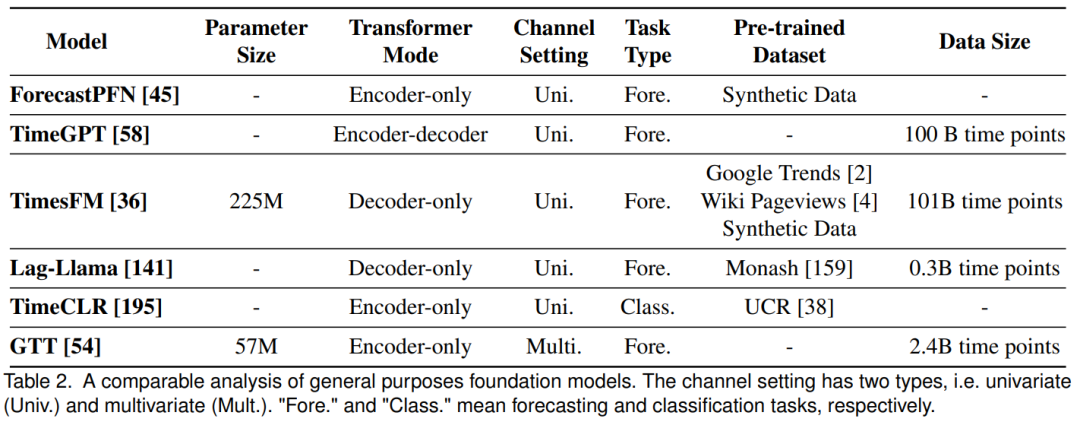
Традиционный анализ временных рядов затрудняет обучение сложных моделей из-за недостаточности данных, поэтому сообщество ожидает, что базовые модели покажут отличную производительность на ограниченных данных. Хотя базовые модели в области НЛП и CV быстро развиваются, базовых моделей, основанных на временных рядах, мало, главным образом из-за небольшого размера набора данных. Однако появились такие модели, как ForecastPFN и TimeGPT. В таблице 2 представлено сравнение этих моделей. В этом разделе также рассматриваются ключевые этапы, влияющие на эффективность базовой модели, такие как обработка данных и проектирование архитектуры.
01. Обработка данных
(1) Сбор данных
Возможности обобщения больших языковых моделей (LLM) выигрывают от крупномасштабной высококачественной предварительной подготовки текста. Аналогичным образом, при анализе временных рядов обширные и высококачественные данные имеют решающее значение для построения эффективной базовой модели. В этом исследовании рассматриваются методы сбора данных, включая разделение данных, источники и масштаб, улучшение и качество.
- Разделение данных:Следование стандартным протоколам в здании База Модельчас,Набор данных для предварительного обучения разделен на набор для обучения и набор для проверки. на этапе тонкой настройки,Модель будет подвергаться воздействию набора целевых данных, которых не было на этапе предварительного обучения.,Каждый набор данных далее делится на обучающий набор, набор проверки и набор тестов.
- Источники данных и масштаб:в существующихизвременной рядпредсказывать База Модельсередина,Лаг-Ллама предварительно обучен на складе временных рядов Монаша,GTT собрал 180 000 временных рядов.,TimesFM выбирает Google Trends и другие источники данных,TimeGPT создает хранилище из более чем 100 миллиардов точек данных,Но это не обнародовано.
- увеличение данных:Расширить предварительную подготовкуданныенабор,В существующих работах использовались различныеувеличение данныхтехнология。Lag-Llama использовать Freq-Mix и Freq-Mask для создания большего количества обучающих выборок во избежание переобучения. ВремяCLR Принято путем увеличения методы данных (такие как сглаживание, искажение времени, обрезка) для генерации большего количества данных, что делает модель инвариантной к искажениям, различным типам шума и т. д. ПрогнозPFN Вместо предварительного обучения на реальных данных мы предварительно тренируемся на полностью синтетическом распределении данных.
- Качество данных:Качество данные необходимы для обеспечения эффективности Модели. Общие проблемы с данными временных рядов включают пропущенные значения, шум и выбросы. Чтобы устранить различные выбросы, которые могут привести к взрыву градиентов, ForecastPFN Сначала замаскируйте недостающие значения, затем обрежьте все 3σ Выбросы. Аналогично, ГТТ За счет исключения нормируемых значений, превышающих 9 точки данных для устранения крайних выбросов.
В целом, данные временных рядов, использованные в текущем исследовании, в основном общедоступны, за исключением внутренних источников GTT. С точки зрения объема данных, TimeGPT собрала самое большое на сегодняшний день хранилище данных временных рядов, хотя оно до сих пор не является общедоступным.
(2) Выравнивание данных
Базовая модель предварительно обучается на нескольких разнородных наборах данных и должна быть выровнена и сбалансирована для расширения возможностей обобщения. Обработка данных временных рядов сталкивается с проблемой изменчивости диапазонов значений, для которой традиционные методы масштабирования не подходят. GTT и Lag-Llama используют специальную технологию нормализации выборки для повышения удобства модели. GTT обрабатывает многоканальные данные с фиксированным номером канала и длиной контекста, тогда как TimesFM использует переменную длину контекста для достижения балансировки данных. Ключевые меры по согласованию модели включают масштабирование значений, обработку изменений входной и выходной длины, управление многоканальными данными и реализацию сбалансированной выборки, что имеет решающее значение для стабильного обучения и предотвращения снижения производительности.
02. Архитектурное проектирование
В этом разделе рассматриваются ключевые факторы, влияющие на архитектуру базовой модели, включая выбор базовой модели, варианты преобразователя и стратегии токенизации входных данных. Во всех исследованиях в качестве основы используются трансформаторы, но существуют разные варианты со своими преимуществами и недостатками. Обсуждение также посвящено тому, как обрабатывать настройки канала для данных временных рядов, чтобы учесть конструкцию преобразователя для помеченных входов.
(1) Основа базовой модели
Модели глубокого обучения, особенно преобразователи, стали предпочтительной основой моделей больших языков (LLM) из-за их преимуществ распараллеливания и возможностей расширения параметров. При анализе временных рядов TimeCLR сравнила несколько моделей и обнаружила, что трансформаторы работают лучше всего. TimesFM и Lag-Llama также подчеркнули преимущества преобразователей при обработке данных разной длины и извлечении исторической информации. Хотя были предложены и другие архитектуры, такие как PatchTST, N-BEATS, Transformer++ и модели в пространстве состояний, Transformer по-прежнему остается распространенным выбором для существующих базовых моделей. Различия в основном отражаются в режиме преобразователя, токенизации входных данных и объектах прогнозирования, включая Transformer++. и модели в пространстве состояний.
(2) Режим трансформатора
Модель трансформатора включает в себя кодер и декодер и имеет три режима: только кодер (например, BERT), только декодер (например, серия GPT) и кодер-декодер (например, BART и T5). Модели, использующие только декодер, хорошо работают при обучении с нулевым и малым количеством кадров, типичным примером является GPT-3. Только модели кодировщика подходят для задач, которые обрабатывают всю входную последовательность, таких как классификация и анализ настроений, тогда как модели декодера подходят для задач последовательной генерации, таких как генерация текста. Модель кодера-декодера выгодна в сложных задачах благодаря разделению ввода-вывода. GTT и ForecastPFN разрабатывают модели только для кодировщиков для прогнозирования временных рядов, а TimesFM и Lag-Llama выбирают режим декодера. TimeGPT использует модель кодировщика-декодера для обработки сложных данных.
(3) Настройки канала
Другой проблемой, связанной с архитектурным проектированием базовых моделей временных рядов, является настройка каналов, в частности независимость каналов и смешивание каналов. Независимость канала означает прием входных данных одномерной последовательности, тогда как смешивание каналов предполагает использование входных данных многомерной последовательности. Эти разные настройки канала приводят к разным методам токенизации временных рядов и требуют разных конструкций моделей.
- Независимость канала:Независимость канала предполагает единыйпеременнаяввод последовательности,И Микс Выбор использует несколько входных переменных последовательности. Конструкция одиночной переменной модели относительно проста, так как количество каналов для нескольких переменных может варьироваться. Большинство исследований имеют тенденцию использовать независимость канала, преобразуя одиночные переменные последовательности в векторные последовательности с помощью различных методов, таких как PatchTST, TimesFM, Lag-Llama и TimeCLR.
- Микс каналов。 Микс каналовнососредоточиться Отношения между различными каналами в многопеременной последовательности, такие как GTМодель, путем изменения формы переменного канала до размера пакета для обработки многопеременного ввода.
Методы LLM для задач временных рядов
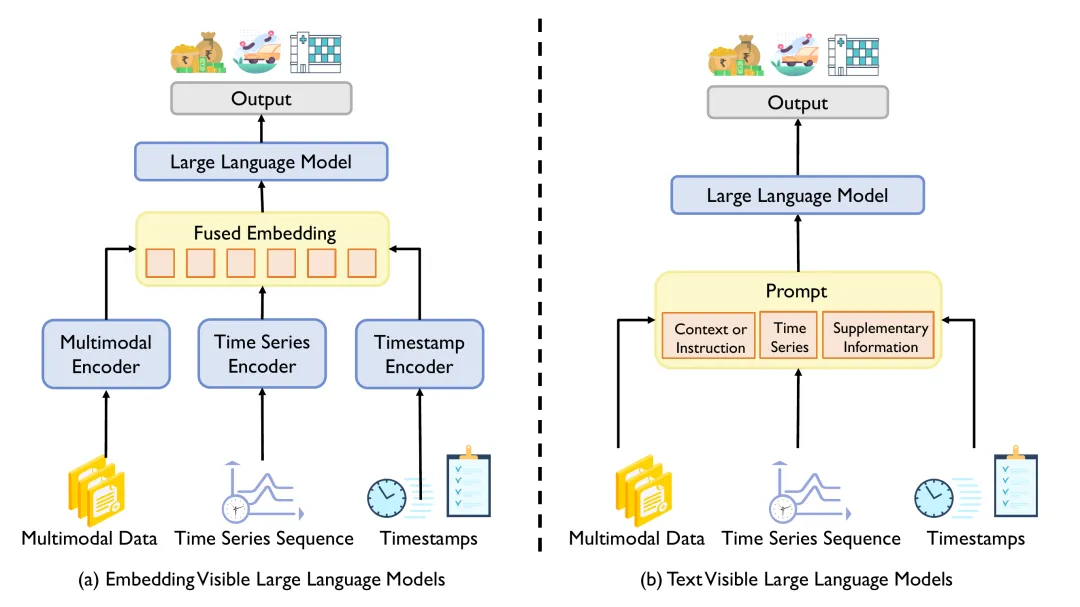
Рисунок 4. Существует две парадигмы адаптации LLM временных рядов: (a) Адаптация LLM, видимая для внедрения, которая адаптируется к задачам временных рядов путем перепроектирования LLM для непосредственного определения встраивания временных рядов. (b) Текстово-видимая адаптация LLM, адаптированная к задачам временных рядов путем формулирования ввода-вывода временных рядов пословно.
Эти две парадигмы различаются методами ввода-вывода, использованием LLM и объединением данных. LLM используется не только для прогнозирования, но также действует как усилитель, генератор данных и интерпретатор, расширяя его функциональность в различных приложениях. В этом разделе будут представлены ключевые концепции, проанализированы ключевые этапы каждой парадигмы и исследованы многочисленные роли LLM в проблемах временных рядов.
01. Встроить видимую регулировку LLM
Встроенная видимая настройка LLM использует традиционную парадигму «предварительного обучения и точной настройки» для перепроектирования LLM и точной настройки его для последующих задач временных рядов. В соответствии с этой парадигмой LLM переработан, чтобы напрямую воспринимать встраивания временных рядов вместо традиционного текстового ввода.
(1) Векторизованное представление временных рядов
При применении LLM для анализа временных рядов данные временных рядов сначала необходимо преобразовать в векторную последовательность, которая может быть обработана LLM. При корректировке LLM, видимой для внедрения, временные ряды векторизуются, а LLM перепроектируется для непосредственного восприятия этих вложений временных рядов. Вдохновленные стратегией разделения модели Transformer, исследователи разделили временной ряд на блоки фиксированной длины в качестве входных маркеров для LLM, чтобы сохранить локальную семантическую информацию. Временные ряды с несколькими переменными часто разлагаются на ряды с одной переменной, а затем обрабатываются в блоки. Однако модель TEST обрабатывает временные ряды в режиме смешивания каналов, подчеркивая, что нельзя игнорировать зависимости между переменными.
(2) Выравнивание семантического пространства между временными рядами и LLM
После преобразования временного ряда в векторную последовательность необходимо устранить модальный разрыв с пространством когнитивного внедрения LLM. Исследователи привели временные ряды в соответствие с размерным пространством LLM, перепроектировав входной уровень внедрения и точно настроив LLM для конкретного набора данных. В таких исследованиях, как Time-LLM и TEST, используются встраивания перепрограммирования текстовых прототипов для согласования функций временных рядов с элементами языка посредством контрастного обучения и уровней многоголового внимания, чтобы улучшить понимание временных рядов LLM.
(3) Характеристики и распознавание закономерностей временных рядов
Существуют существенные различия в шаблонах и атрибутах между временными рядами и естественным языком, что создает проблемы при применении LLM к задачам временных рядов. Уникальные характеристики временных рядов включают многомерные зависимости, сдвиги распределения и сложные временные закономерности. Хотя модели на основе Transformer хорошо справляются с некоторыми задачами, они могут игнорировать уникальные свойства временных рядов, такие как тенденции и сезонность. Исследования показывают, что Transformer временных рядов может быть не таким надежным, как другие модели, а LLM не имеет возможности определять характеристики временных рядов на этапе предварительного обучения. Поэтому крайне важно учитывать эти характеристики при применении LLM для анализа временных рядов.
- Режим времени:TEMPOМетод будетпеременная Серия разбивается на тренды、сезониостаток,Прогнозы LLM упрощены,И делитесь временным шаблоном с помощью обучаемого пула быстрых кодов. Разложенные части нормализуются, исправляются и встраиваются.,Введите модуль GPT вместе с подсказками. Эксперимент подтвердил эффективность декомпозиции и быстрого объединения. AuxMobLCast добавляет вспомогательный модуль классификации POI в архитектуру кодера-декодера.,Чтобы определить шаблоны доступа, связанные с различными категориями POI,Исследования абляции показывают, что этот модуль значительно улучшает производительность BERT-кодировщиков.
- Многовариантные зависимости:временной рядданныечасто многопеременная,Такие как цена акций иECGданные,И текст одинарный переменный. Многие исследования адаптировали LLM для обработки нескольких переменных временных рядов.,Но TEST указывает, что метод независимости канала игнорирует множественные зависимости. TEST напрямую обрабатывает несколько переменных временных рядов.,Разрежьте его на маркеры разной длины.,Входной кодер генерирует временное внедрение,Чтобы уловить взаимозависимость между переменными.
- Информация о временной метке:Исследоватьповерхностьяркий,на основеTransformerиз Модельсерединаприсоединитьсяинформация о временной метке,Как в прогнозировании заболеваний и прогнозировании транспортных потоков.,Может улучшить Модельпроизводительность. LLM4TS присваивает начальную временную метку каждому патчу временного ряда.,Кодируйте временные атрибуты и объединяйте их во временные вложения.,В сочетании с внедренными тегами и позициями для создания окончательного внедрения.
- Смещение распределения:FPTиTEMPOИспользуйте обратную нормализацию экземпляра(RevIN)Один на одинпеременная Входная последовательность для нормализации,чтобы смягчить сдвиги в распределении и облегчить передачу знаний. Однако,LLM4TS отмечает, что обучаемое аффинное преобразование RevIN не работает с авторегрессионной моделью, такой как GPT-2.,Поэтому на этапе контролируемой тонкой настройки стандартные экземпляры нормализуются.
(4) Мультимодальное объединение данных
Мультимодальное обучение широко изучается в областях НЛП и CV, таких как визуальные ответы на вопросы и генерация текста и изображений. Мультимодальные сценарии также существуют при анализе временных рядов, например наборы финансовых и медицинских данных, которые могут содержать текстовую или графическую информацию. Абстрактная природа данных временных рядов усложняет семантический анализ и передачу знаний, но дополнение мультимодальной информации может улучшить изучение модели сложных временных закономерностей и улучшить возможности представления, возможности обобщения и интерпретируемость. Вдохновленные успехом мультимодального LLM, исследователи разработали мультимодальные модели для анализа временных рядов, которые были разделены на две категории в зависимости от детализации сигнала.
(5) Мультимодальное слияние на уровне выборки
Исследователи используют мультимодальные сигналы, такие как текстовые отчеты, чтобы обогатить детали выборок временных рядов и расширить внутренние знания. METS объединяет сигналы ЭКГ с клиническими отчетами, использует модель ClinicalBert для извлечения диагностических знаний и направляет обучение кодированию ЭКГ. TEMPO объединяет квартальные новости и отчеты, прогнозирует финансовые показатели и использует встраивание времени и программные подсказки для извлечения сводной информации. Эти методы повышают глубину и точность анализа временных рядов за счет мультимодальной информации.
(6) Мультимодальное объединение на уровне задач
Другое направление исследований использует мультимодальные знания для улучшения возможностей обобщения модели и передачи знаний между наборами данных, включая уровни задач или предметной области. UniTime помогает модели идентифицировать источники данных и корректировать стратегии прогнозирования с помощью инструкций предметной области. Инструкции содержат знания предметной области в форме предложений и интегрированы с внедрением времени. Time-LLM использует технологию Prompt-as-Prefix для улучшения представления временных рядов с помощью подсказок, содержащих знания предметной области, инструкции по задачам и статистику данных, чтобы способствовать рассуждению LLM и распознаванию образов.
(7) Точная настройка
Точная настройка предварительно обученного LLM имеет решающее значение для его применения в конкретной задаче и включает в себя перенастройку уровней ввода/вывода и целевых функций. UniTime достигает наилучшей производительности в междоменном прогнозировании временных рядов за счет полной настройки GPT-2, но полное обновление параметров может привести к катастрофическому забыванию и увеличению требований к ресурсам. Чтобы решить эти проблемы, такие исследования, как FPT, TEMPO и LLM4TS, используют частичное обновление параметров, а TEST и TimeLLM используют замороженный LLM в сочетании с обучаемыми программными сигналами. Эти методы направлены на сокращение обновления параметров при сохранении производительности и требуют согласования вложений временных рядов с текстовым пространством LLM. Кроме того, возможности LLM в анализе временных рядов дополнительно расширяются за счет выявления временных закономерностей и интеграции мультимодальной информации.
02. Настройка LLM для видимого текста
Текст-видимая настройка LLM следует парадигме «предварительного обучения, подсказок и прогнозирования», меняет структуру задачи временных рядов и использует технологию подсказок для активации возможностей LLM. В соответствии с этой парадигмой пары ввода-вывода задач временных рядов реструктурируются в текстовые подсказки.
(1) Текстовое представление временных рядов
В текстовых корректировках LLM данные временных рядов преобразуются в строки для плавной интеграции с подсказками. Исследователи использовали LLM, чтобы напрямую сделать вывод о задаче без тонкой настройки посредством задачи форматирования предложений. Числовые данные описываются как предложения естественного языка и объединяются с контекстной информацией. Для конкретных задач, таких как прогнозирование передвижения людей, задачи здравоохранения и прогноз погоды, LLM настраивается, и задача формулируется в форме естественного языка.
(2) Выравнивание семантического пространства между временными рядами и LLM
В работе по преобразованию временных рядов в предложения LLM понимает строки посредством токенизации, но исходный метод токенизации может не подходить для числовых значений, что приводит к сегментации непрерывных числовых значений и игнорированию временного значения, что увеличивает сложность арифметических операций. LLMTIME рекомендует предварительно обработать временной ряд перед токенизацией, например добавить пробелы. Настройка подсказок служит потенциальным решением, помогающим LLM понять информацию временных рядов путем добавления обучаемых вложений для оптимизации входных данных.
(3) Атрибуты временных рядов и распознавание образов
В отличие от извлечения признаков временных рядов при настройке встроенного видимого LLM, текстово-видимый LLM идентифицирует уникальные свойства и закономерности временных рядов путем интеграции соответствующей информации в сигналы.
- временной шаблон。 LLM-MobуказатьLLMТрудно остановиться прямо из комплекса.данныесередина提取有用信息进行人类移动性предсказывать,Поэтому предлагается разложить данные на историческую и контекстную последовательность.,Помочь LLM понять долгосрочные и краткосрочные модели движения. AuxMobLCast находит категории POI, связанные с пассажирским режимом.,Путем интеграции вспомогательного модуля классификации POI в архитектуру кодера-декодера.,Значительно повышает производительность кодера BERT.
- Межпоследовательные зависимости。为了解决股票предсказыватьсерединаиз Межпоследовательные зависимостивопрос,TDML предоставляет множество примеров из аналогичных акций.,создавать контекстные обучающие подсказки,Доказано, что LLM может эффективно интегрировать информацию о перекрестных последовательностях. LLMST объединяет все траектории в одной подсказке,Чтобы увидеть, может ли Модель учитывать взаимодействие между траекториями.,Откройте для себя это возможное повышение производительности. TWSN использует несколько исторических характеристик акций.,Преобразование нескольких ценовых характеристик в строку в формате поверхности.,и интегрированы в текстовые подсказки,Используется для прогнозирования тренда акций.
- информация о временной метке。 UMEFВоляинформация о временной метке, интегрированной в шаблон прогноза энергопотребления. LLM-Mob учитывает временную информацию о целевом времени пребывания при прогнозировании мобильности людей и направляет LLM для анализа изменений в моделях мобильности, включая факты, связанные со временем и датой. AuxMobLCast включил информацию о дате в подсказки по мобильности и обнаружил, что производительность падает после удаления информации о времени и дате, а очистка поверхности помогает LLM фиксировать временную информацию. шаблон。
(4) Мультимодальное объединение данных
Меньше исследований мультимодального обучения в текстовых условиях LLM. При мультимодальном слиянии данных на уровне выборки TWSN объединяет исторические цены на акции и твиты для создания мультимодальных подсказок для оценки способности ChatGPT прогнозировать динамику акций. При мультимодальном слиянии данных на уровне задачи информация на уровне задачи добавляется к подсказкам в качестве дополнения для повышения производительности модели.
(5) Советы
Вдохновленные способностью LLM к обобщению в НЛП, исследователи используют подсказки, чтобы активировать возможности LLM в задачах временных рядов, интегрировать входные данные в текстовые подсказки и направлять LLM для генерации желаемого результата на естественном языке. Подсказки делятся на два типа: без параметров и с тонкой настройкой. Первый оценивает производительность при настройках с нулевой или малой выборкой без точной настройки, а второй позволяет точно настроить LLM и обновить параметры. В обзоре суммируются оба подхода и обсуждаются их преимущества и недостатки.
- Нет советов по настройке параметров:Исследовать Автор подсказывает через инструкцию по оформлению,Использование внутренних знаний LLM для вывода с нулевым или малым количеством шагов,Обновление параметров не требуется. Структура запроса на оптимизацию TDML,Было обнаружено, что подсказки CoT с нулевой выборкой могут значительно повысить производительность. TWSN оценивает эффективность ChatGPT в прогнозировании акций,Было обнаружено, что хотя технология ЦТ и улучшилась, она не так хороша, как специализированные методы. LLMF тестирует нулевой образец PaLM-24B на предмет здоровья,Было обнаружено, что он плохо справляется с численными задачами. LLMSTиLLM-Mob оценивает производительность LLM при обнаружении аномалий мобильности с помощью проектных подсказок.,Акцент на важности оперативного проектирования. LLMFS обнаружила, что PaLM может справиться со здоровьем с помощью обучающих данных за несколько кадров.,Но производительность падает при настройке нулевой выборки. LLMTIME поверхность,Путем тщательной предварительной обработки временного ряда,LLM можно напрямую использовать в качестве предсказателя с нулевой выборкой.,Никакой дополнительной текстовой информации не требуется.
- Советы, основанные на подталкиваниях:Для преодоления используйте толькоLLMприсущие знанияизограничение,Некоторые исследования сочетают в себе традиционные подталкивания и советы.,Обновите параметры LLM в соответствии с конкретными задачами временных рядов. PromptCast использует точную настройку инструкций для прогнозирования временных рядов общего назначения.,Разработаны подсказки на основе инструкций с нулевым выстрелом.,Используется для прогнозирования погоды, энергетики и пассажиропотоков. Точная настройка прогнозов энергопотребления без инструкций UMEF,Преобразуйте данные в описательные предложения. AuxMobLCast использует точную настройку без инструкций для прогнозирования движений человека.,В сочетании с мобильными данными, меткой времени и информацией о POI,Точная настройка архитектуры кодера-декодера. LLMFS разработала подсказки на основе вопросов и ответов для оздоровительных задач.,Заморозьте LLM и добавьте обучаемые встраивания подсказок.,Понять временную последовательность выполнения различных задач данных. Эти методы объединены тонкой настройкой и хинтингом.,Улучшена производительность LLM в задачах временных рядов.
Подводя итог, можно сказать, что основной вклад исследований, использующих сигналы, заключается в том, что они разрабатывают сложные сигналы для конкретных сценариев временных рядов. Чтобы повысить эффективность подсказок, некоторые исследования также включают дополнительную информацию, такую как характеристики временных рядов, альтернативные методы получения данных и экспертные знания. Такие методы, как непрерывное мышление (CoT), применялись в нескольких работах, демонстрируя потенциал улучшения производительности модели.
03. Дальнейшее обсуждение: функции LLM
В этом разделе обсуждаются разнообразные роли LLM в текущих исследованиях.
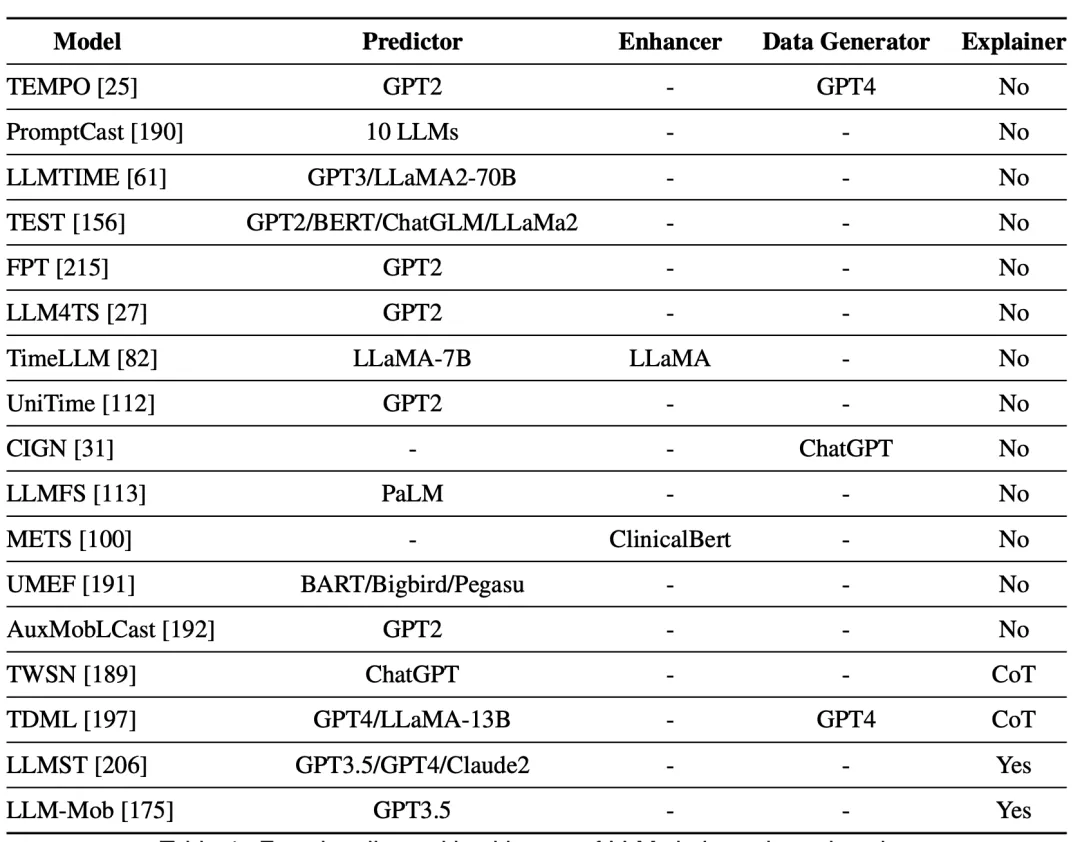
Таблица Функции и основа LLM, использованных в исследовании
(1) Предсказатель
В частности, LLM считается предиктором, если он в первую очередь принимает в качестве входных данных представление временных данных и выдает выходные данные. Во всех работах, проанализированных в этом разделе, LLM используется в качестве предиктора, основного модуля для задач временных рядов. Различия между этими работами заключаются в возможности настройки LLM, токенизации временных рядов, методах подсказок и улучшенном дизайне моделей для различных задач временных рядов. Более подробная информация представлена в предыдущих подразделах.
(2) Усилитель
В качестве усилителя LLM отвечает за извлечение расширенной информации из других модальных данных и помощь основному модулю в прогнозировании. Такие исследования, как METS, TWSN, TEMPO и TimeLLM/UniTime, используют текстовую информацию, такую как медицинские отчеты, твиты, новости и знания предметной области, для обогащения представления данных временных рядов. LLM Enhancer обычно фиксированы и не требуют обучения или тонкой настройки и могут состоять из специализированных или общих LLM, при этом специализированные LLM больше подходят для извлечения информации, специфичной для конкретной предметной области.
(3) Генератор данных
Вдохновленные обширными знаниями LLM и мощными возможностями генерации языков, исследователи используют LLM для генерации дополнительных данных в дополнение к исходным данным. CIGN использует ChatGPT для извлечения информации о компании из финансовых новостей и построения графиков для анализа тенденций акций. TDML использует GPT-4 для создания описаний компаний и показателей акций, а также для извлечения сводок новостей и ключевых слов. TEMPO использует ChatGPT для сбора новостей и отчетов компаний в качестве контекстной информации для финансовых прогнозов. Будучи генераторами данных, LLM могут эффективно генерировать необходимые данные, однако следует отметить, что генерируемые ими данные могут содержать неточности.
(4) Переводчик
При анализе временных рядов решающее значение имеет интерпретируемость поведения модели и прогнозов, особенно в сценариях высокого риска. Хотя LLM часто рассматриваются как черные ящики, их возможности генерации текста позволяют им действовать как естественные интерпретаторы, генерируя удобочитаемые объяснения своих решений. Используя методы подсказок, такие как цепочка мыслей (CoT), LLM может шаг за шагом демонстрировать процесс рассуждения и предоставлять подробные объяснения прогнозов. Такие исследования, как LLMST, LLM-Mob, TWSN и TDML, используют LLM для создания объяснений, повышающих интерпретируемость моделей в таких задачах, как обнаружение аномалий, прогнозирование движения людей и прогнозирование цен на акции.
эффективность
глубокое обучениесерединаизэффективностьсосредоточиться —Эффективное использование вычислительных ресурсов, включая вычислительное время, загрузку процессора, требования к памяти и энергопотребление. Предварительно обученные временные ряды Модельи Модель, ориентированная на LLM, демонстрирует сильную способность к обобщению, но сопровождается повышенным потреблением ресурсов. Использование Когда большие языки модели, такие как GPT-3, обрабатывают временные ряды, обучение и вывод данных могут занимать много времени, что влияет на приложения реального времени. Эффективные методы в области временных рядов заимствованы из НЛП, исследователь Подвести В заключении представлена методика эффективности LLM, которую можно перенести в анализ временных рядов, и исследуются проблемы эффективности в различных парадигмах настройки.
01. Эффективные технологии в LLM
Модели больших языков (LLM) сталкиваются с высокими требованиями к вычислительным ресурсам и памяти из-за больших размеров параметров.,продвижение эффективности на протяжении всего ее жизненного цикла. Полностью настроенная LLMэффективность низкая,Поэтому используется эффективная точная настройка параметров (PEFT).,нравитьсяадаптер、Советы по тюнингу、Приставка тюнинги Адаптация низкого ранга (LoRA) для уменьшения параметров обучения и экономии ресурсов. Эти методы широко используются в исследованиях временных рядов, ориентированных на LLM.
адаптер。адаптериз Концепция, первоначально разработанная в области компьютерного зрениясерединапредлагатьиз,Затем он применяется к обработке естественного языка. Он внедряет небольшую нейронную сеть после слоя нейронной сети внимания и прямой связи (FNN) в преобразователе. адаптер, вероятно, имеет меньше 4.
Советы по тюнингу。с добавлением доп.изFFNслойизадаптердругой,Советы по Тюнингу оборачивает обучаемые тензоры во входные представления Модели, часто называемые «мягкими подсказками». Поскольку Модель увеличивается в размерах, Советы по тюнингу становятся эффективнее,Ее эффективность улучшается быстрее, чем увеличивается размер Модели.
Приставка тюнинг。Прямая оптимизация наблюдается Советы по Мягкие подсказки в тюнингу в некоторых случаях работают нестабильно. Вместо пересылки мягких подсказок на входной уровень Приставка Тюнинг добавляет обучаемые векторы (то есть префиксные токены) к каждому промежуточному слою. Исследования поверхности показывают, что при обновлении только параметров 0,1, Приставка тюнингизпроизводительностьпочти завершентонкая настройка。
Адаптация низкого ранга (LoRA)。ВнутреннийSAIDизнизкий рангтонкая настройка Мысльиз Вдохновлять,LoRA разлагает матрицу весов LLM на произведение двух матриц низкого ранга. В процессе доводки,Исходная матрица заморожена,И две матрицы низкого ранга обновляются. Хотя LoRA эффективен,Но это требует обновления матриц низкого ранга всех слоев LLM на каждой итерации.
Следует отметить, что хотя LoRA является методом, основанным на репараметризации, остальные методы являются аддитивными.
02、Корректированиесерединаизэффективность
В этом разделе,Исследователи обсудили проблему эффективности при адаптации LLM к анализу временных рядов. первый,Количество обновленных параметров в соответствии с архитектурой центра LLM,Для существующей работы представлена таксономия парадигм настройки. Эта таксономия имеет три ветви,То есть парадигма без настройки (параметры не обновляются), парадигма полной тонкой настройки (обновляются все параметры магистрали LLM) и парадигма тонкой настройки с эффективными параметрами (только небольшая часть параметров модели обновляется). обновлено).
(1) Нет парадигмы настройки
В решениях временных рядов, основанных на LLM, парадигма корректировки нулевого параметра при прямом вызове интерфейса API является наиболее эффективной стратегией. Например, TWSN и TDML используют ChatGPT/GPT-4 для нулевого вывода без обновления параметров. Этот подход основан на присущих LLM возможностях и оперативном проектировании. Однако недавние исследования показывают, что эта стратегия имеет низкую производительность при выполнении определенных задач и требует высоких затрат на вызовы API.
(2) Полная парадигма тонкой настройки
Из-за плохой производительности свободной парадигмы с настройкой параметров некоторые исследования предпочитают тонкую настройку LLM для адаптации к последующим задачам временных рядов. Стратегии полной точной настройки обычно перепроектируют входные слои для кодирования данных временных рядов и перепроектируют выходные слои для соответствия последующим задачам. Эта стратегия может лучше направлять выполнение LLM для конкретных задач временных рядов, таких как AuxMobLCast для прогнозирования мобильности людей, UniTime и TEMPO для общего прогнозирования. Однако это обычно требует значительных вычислительных ресурсов и длительного времени обучения, поскольку предполагает обновление всех параметров большой языковой модели.
(3) Парадигма эффективной точной настройки параметров
Чтобы сбалансировать эффект и эффективность,Исследователи приняли стратегию эффективной точной настройки параметров (PEFT). FPTиTEMPO замораживает основные параметры GPT-2,Перепроектируйте входной слой,И используйте встраивание позиций и LoRA для точной настройки. LLM4TS представляет двухступенчатую точную настройку,Включает частичное замораживание, LoRA и линейное обнаружение. TESTиTimeLLMиспользовать полностью замороженную LLM,Представляем мягкие подсказки и обучаемые встраивания патчей для точной настройки. LLMFS добавляет в подсказки мягкие обучаемые вложения,Чтобы помочь LLM понять данные временных рядов. Эти методы работают путем замораживания большинства параметров и тонкой настройки некоторых.,Улучшена производительность модели в задачах временных рядов.
Таким образом, LoRA используется как в TEMPO, так и в LLM4TS. Аналогично, TEST, TimeLLM и LLMFS используют настройку подсказок. Однако при анализе временных рядов, ориентированном на LLM, конкретные стратегии эффективного проектирования архитектуры и сжатия моделей еще не изучены.
Интерпретируемость
Интерпретируемость — важная тема в области искусственного интеллекта и временных рядов.,Прозрачность, включающая модель поведения и прогнозирующую силу. В таких ключевых областях, как автономное вождение, медицинское обслуживание и финансы.,Интерпретируемость важна для доверия пользователей и безопасности модели. Несмотря на сложность большой модели,Но метод искусственного интеллекта Интерпретируемость все же можно применить. В этом разделе рассматривается метод Интерпретируемости содержания для анализа временных рядов больших моделей.,Подвести Итог Вклад существующих исследований в повышение Интерпретируемости.
01、ИИМодельиз Интерпретируемость
Хотя такие инструменты, как деревья решений, имеют естественную привлекательность благодаря своей интуитивно понятной структуре, инструменты глубокого обучения часто представляют собой черные ящики с непрозрачными внутренними механизмами. Чтобы решить эту проблему, область объяснимого искусственного интеллекта (XAI) может разработать методы, позволяющие сделать внутренние механизмы или результаты модели глубокого обучения понятными для людей. Методы XAI делятся на локальные интерпретации (сосредоточиться Обоснование решения в конкретном случае) и глобальное объяснение (раскрывающее общий механизм Модели). Методы объяснения делятся на априорные (разработка для объяснения структуры Модели) и апостериорные (объяснение поведения Модели без изменения структуры) методы.
02. Интерпретируемость модели времени, ориентированной на LLM
Углубленное исследование использования LLM в анализе временных рядов, включая локальные и глобальные интерпретации.
(1) Глобальное объяснение
Глобальное объяснение направлено на понимание того, что узнал LLM и как он интерпретирует числовые временные ряды. Внутренний механизм LLM непрозрачен,Интерпретация его адаптивности во временных рядах является сложной задачей. Текущие изменения в структуре LLM в основном ориентированы на производительность, а не на Интерпретируемость. Поверхность задания FPT прозрачная,Модуль самообслуживания LLM аналогичен PCA.,Может использоваться в качестве общего калькулятора для задач временных рядов.,Выполнять задачи, не связанные с задачей.
(2) Местное объяснение
LLM может генерировать объяснения на естественном языке с помощью подсказок цепочки мыслей.,Повысить прозрачность принятия решений в Модели. LLMSTиLLM-Mob направляет LLM с помощью подсказок, объясняющих результаты обнаружения.,Улучшите способность рассуждения модели. TWSNиTDML усовершенствовал цепочку мышления с нулевой выборкой для прогнозирования тенденций акций,Заставьте ChatGPTиGPT-4 предоставлять последовательные объяснения. TEMPO предоставляет первое локальное объяснение видимого встроенного LLM (GPT-2),Вклад различных компонентов измеряется с помощью модели обобщенной аддитивности. Эти исследования поверхности показывают,LLM может генерировать убедительные объяснения,Улучшите модель Интерпретируемость в анализе временных рядов.
Подвести итог
В этом обзоре,Исследователи исследовали База Модель анализа временных рядов,Включает в себя База Модели, предварительно обученные с нуля для крупномасштабных языков. База Модель, перепрофилированная для задач временных рядов. Диссертация предоставляет структуру анализа 3E, из трех ключевых аспектов эффекта: эффективностьи Интерпретируемость Подвести итог Связанный Исследовать,Обсуждает, как решать проблемы с временными рядами при применении База Модель к задачам с временными рядами. в то же время,Предоставляется другая таксономия домена.,отслеживать прогресс в каждой области. Целью данного обзора является предоставление любителям временных рядов комплексной концептуальной основы.,Способствовать более глубокому пониманию База Модель.,и стимулировать инновации в будущих исследованиях.
Для более подробного обзора заинтересованные друзья могут прочитать оригинальный текст статьи.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
