Обзор LoRA и ее вариантов: LoRA, DoRA, AdaLoRA, Delta-LoRA.
LoRAМожно сказать, что он может эффективно обучать большие языки для конкретных задач.Моделькрупный прорыв。Он широко используется во многих приложениях.。в этой статье,Мы объясним основные понятия самой LoRA.,Затем представьте несколько вариантов, которые по-разному улучшают функциональность LoRA.,Включая LoRA+, VeRA, LoRA- fa、LoRA-drop、AdaLoRA、DoRA「Дельта-LoRA。
Lora
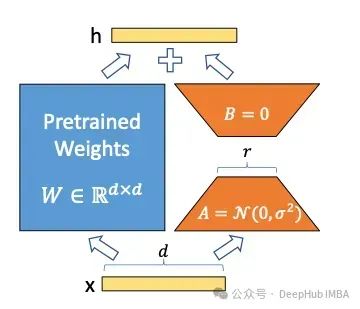
Низкоранговая адаптация (LoRA) [1] — это технология, которая в настоящее время широко используется для обучения больших языковых моделей (LLM). Большие языковые модели могут генерировать для нас все виды контента, но для решения многих задач мы все равно хотим обучить LLM конкретной последующей задаче, такой как классификация предложений или генерация ответов на заданный вопрос. Но если точная настройка используется напрямую, это требует обучения больших моделей с миллионами и миллиардами параметров.
LoRA предоставляет альтернативный метод обучения, который выполняется быстрее и проще за счет уменьшения количества обучаемых параметров. LoRA вводит две матрицы A и B. Если размер исходной матрицы параметра W равен d × d, то размеры матриц A и B равны d × r и r × d соответственно, где r намного меньше (обычно меньше, чем 100). Параметр r называется рангом. Если используется LoRA с рангом r=16, форма этих матриц равна 16 x d, что значительно уменьшает количество параметров, которые необходимо обучать. Самым большим преимуществом LoRA является то, что по сравнению с точной настройкой для него требуется меньше параметров обучения, но он может обеспечить практически ту же производительность, что и тонкая настройка.
Техническая деталь LoRA: вначале матрица A инициализируется случайными значениями со средним значением, равным нулю, но с некоторым отклонением от среднего значения. Матрица B инициализируется как полностью нулевая матрица. Это гарантирует, что матрица LoRA никогда не меняет выходные данные исходного W случайным образом с самого начала. Как только параметры A и B будут скорректированы в желаемом направлении, обновления A и B на выходе W должны дополнять исходный результат.
LoRA значительно снижает потребление ресурсов обучения LLM. Таким образом, существует множество различных вариаций исходного метода LoRA, которые по-разному улучшают исходный метод.
LoRA+

LoRA+[2] представляет более эффективный способ обучения адаптеров LoRA, вводя разные скорости обучения для матриц a и b. Когда LoRA обучает нейронную сеть, скорость обучения применяется ко всем весовым матрицам. А авторы LoRA+ могут доказать, что только одна скорость обучения неоптимальна. Установка скорости обучения матрицы B намного выше, чем скорость обучения матрицы A, может сделать обучение более эффективным.
Математика, необходимая авторам для доказательства, довольно сложна (если она вас действительно интересует, ознакомьтесь с оригинальной статьей [2]). Давайте дадим простое и популярное объяснение: матрица B инициализируется значением 0, поэтому для нее требуется больший шаг обновления, чем для случайно инициализированной матрицы a. Установив скорость обучения матрицы B в 16 раз выше, чем у матрицы A, авторы смогли получить небольшое улучшение точности модели (около 2%), одновременно ускорив время обучения таких моделей, как RoBERTa или lama-7b, за счет коэффициент 2.
VeRA
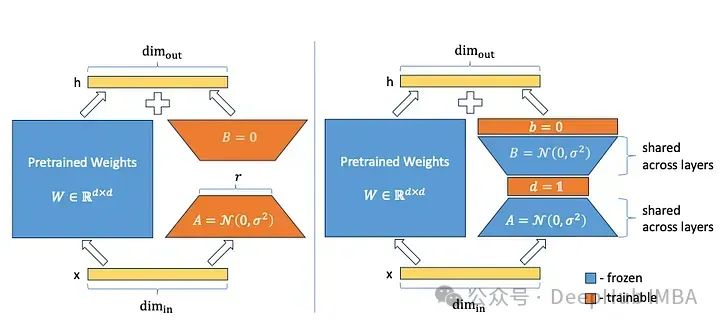
VeRA (векторная адаптация случайной матрицы) [3] представляет метод, позволяющий значительно уменьшить размер параметра LoRA. Вместо обучающих матриц A и B они инициализируют эти матрицы с общими случайными весами (т. е. все матрицы A и B во всех слоях имеют одинаковые веса) и добавляют два новых вектора d и B при точной настройке. Обучают только векторы d и B.
A и B — матрицы случайных весов. Как они могут способствовать повышению эффективности модели, если их вообще не обучают? Этот подход основан на интересной области исследований, известной как стохастическое прогнозирование. Существует большое количество исследований, показывающих, что в большой нейронной сети только небольшая часть весов используется для управления поведением и обеспечения ожидаемой производительности модели при выполнении задачи обучения. Таким образом, из-за случайной инициализации определенные части модели (или подсети) с самого начала более склонны к желаемому поведению модели.
Но в этом случае все параметры необходимо обучать в процессе обучения, что ничем не отличается от полной тонкой настройки. Авторы VeRA обучают эти соответствующие подсети только путем введения векторов d и b, в отличие от исходного метода LoRa матрицы A и b замораживаются, а матрица B больше не устанавливается в ноль, а инициализируется случайным образом, как и матрица А
Этот подход дает множество параметров, которые намного меньше полных матриц a и b. Если в GPT-3 ввести лора-слой 16-го ранга, то будет 755 000 параметров. При использовании VeRA потребуется всего 2,8 миллиона (сокращение на 97%). Какова производительность при таком небольшом количестве параметров? Авторы VeRA провели оценку с использованием обычных тестов, таких как GLUE или E2E, а также моделей на базе RoBERTa и GPT2 Medium. Результаты показывают, что модель VeRA обеспечивает производительность, которая лишь немного ниже, чем у полностью настроенной модели или модели, использующей оригинальную технологию LoRa.
LoRA-FA
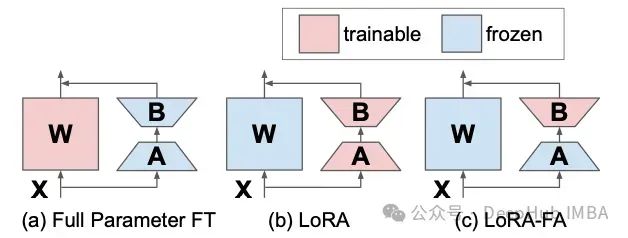
LoRA-fa[4] — это аббревиатура LoRA и Frozen-A. В LoRA-FA матрица A замораживается после инициализации и поэтому служит случайной проекцией. Вместо добавления новых векторов матрица B обучается после инициализации нулями (как и в исходном LoRA). Это сокращает количество параметров вдвое, сохраняя при этом производительность, сравнимую с обычным LoRA.
LoRa-drop
Матрицы Лора можно добавлять в любой слой нейронной сети. LoRA-drop [5] представляет алгоритм, позволяющий решить, какие слои точно настраиваются с помощью LoRA, а какие нет.
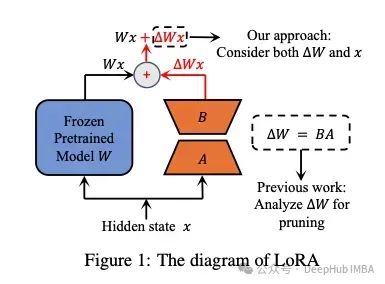
LoRA-drop состоит из двух этапов. Выборка подмножества данных на первом этапе,тренироватьсяLoRAСделайте несколько итераций。Затем добавьте каждыйLoRAВажность адаптера рассчитывается какBAx,где A и B — матрицы LoRA,х — вход. Это выходные данные LoRA, добавленные к выходным данным замороженного слоя. Если этот выход большой,Объясните, что это меняет поведение более радикально. если он маленький,Это показывает, что LoRA оказывает небольшое и незначительное воздействие на замерзший слой.
Существуют также разные способы выбора наиболее важных слоев LoRA: можно агрегировать значения важности до достижения порогового значения (это контролируется гиперпараметром) или брать только самые важные n фиксированных n слоев LoRA. Какой бы метод ни использовался, также требуется полное обучение на всем наборе данных (поскольку на предыдущем этапе использовалось подмножество данных), а другие слои фиксируются на наборе общих параметров, которые больше не будут меняться во время обучения. .
Алгоритм LoRA-drop позволяет обучать модель, используя только подмножество слоев LoRA. Согласно доказательствам, представленным авторами, есть лишь небольшое изменение точности по сравнению с обучением всех слоев LoRA, но время вычислений сокращается из-за меньшего количества параметров, которые необходимо обучать.
AdaLoRA
Существует много способов решить, какие параметры LoRA важнее других, AdaLoRA [6] — один из них, авторы AdaLoRA предлагают рассматривать сингулярные значения матрицы LoRA как показатель ее важности.
Важным отличием от LoRA-drop, описанного выше, является то, что адаптеры в LoRA-drop либо полностью обучены, либо не обучены вообще. А AdaLoRA может решить, что разные адаптеры имеют разные ранги (в исходном методе LoRA все адаптеры имеют одинаковый ранг).
По сравнению со стандартным LoRA того же ранга, AdaLoRA имеет в общей сложности такое же количество параметров, но распределение этих параметров другое. В LoRA ранги всех матриц одинаковы, тогда как в AdaLoRA некоторые матрицы имеют более высокие ранги, а некоторые — более низкие, поэтому итоговое общее количество параметров одинаково. Эксперименты показывают, что AdaLoRA дает лучшие результаты, чем стандартные методы LoRA, что указывает на лучшее распределение обучаемых параметров по частям модели, которые особенно важны для конкретной задачи. На изображении ниже показан пример того, как AdaLoRA присваивает рейтинг данной модели. Как мы видим, более высокие ранги присваиваются слоям ближе к концу модели, что указывает на то, что адаптация к ним более важна.

DoRA
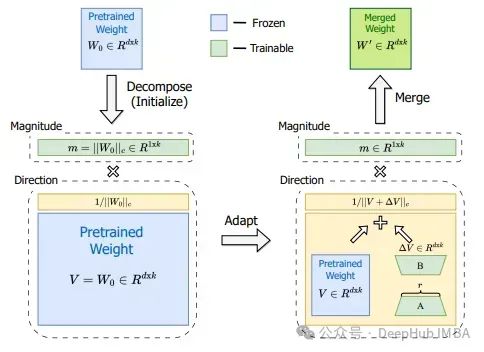
Еще одним методом модификации LoRa для повышения производительности является адаптация низкого ранга с разложением по весу (DoRA) [7]. Потому что любую матрицу можно разложить на произведение величины и направления. Для векторов в двумерном пространстве это легко представить так: вектор — это стрелка, начинающаяся с позиции 0 и заканчивающаяся в определенной точке векторного пространства. Для элементов вектора, если ваше пространство имеет два измерения x и y, вы можете сказать x=1 и y=1. Или одну и ту же точку можно описать по-разному, указав размер и угол (т.е. направление), например m=√2 и a=45°. Это означает, что начиная с точки 0 и двигаясь в направлении 45°, длина стрелки равна √2. получит ту же точку (x=1,y=1)
Это разложение по величине и направлению также можно выполнить с помощью матриц более высокого порядка. Авторы DoRA применяют это к весовой матрице, которая описывает обновления во время этапов обучения для модели, обученной с помощью обычной точной настройки, и модели, обученной с помощью адаптера LoRA. Сравнение этих двух технологий можно увидеть на изображении ниже:
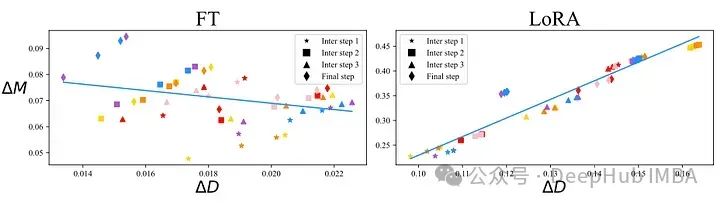
Точная настройка модели (слева) и модель, обученная с помощью адаптера LoRA (справа). Изменение направления можно увидеть по оси X, а изменение амплитуды — по оси Y. Каждая точка разброса на рисунке принадлежит одному слою модели. Между этими двумя методами обучения есть важное различие. На левом изображении наблюдается небольшая отрицательная корреляция между обновлениями направления и обновлениями амплитуды, тогда как на правом изображении наблюдается более сильная положительная корреляция. Вам может быть интересно, какой из них лучше и имеет ли это какой-то смысл. Но на самом деле основная идея LoRA — использовать меньшее количество параметров для достижения той же производительности, что и при тонкой настройке. Другими словами, пока стоимость не увеличивается, обучение LoRA можно проводить, используя максимально возможное количество атрибутов. На приведенном выше рисунке мы также можем видеть, что взаимосвязь между направлением и амплитудой в LoRA отличается от взаимосвязи при полной точной настройке, что может быть одной из причин, почему LoRA иногда не так хорош, как тонкая настройка.
Авторы DoRA представили метод независимого обучения размера и ориентации путем разделения матрицы предварительного обучения W на вектор размера m и матрицу ориентации V размера 1 x d. Затем матрица направлений V дополняется B*a, а затем m обучается как есть. В то время как LoRA имеет тенденцию изменять как величину, так и направление (на что указывает высокая положительная корреляция между ними), DoRA может легче регулировать оба по отдельности или компенсировать изменения в одном отрицательными изменениями в другом. Таким образом, взаимосвязь между направлением и размером DoRA может больше напоминать тонкую настройку:

В нескольких тестах DoRA превосходит LoRA по точности. Разбивка обновлений веса по величине и направлению позволяет DoRA выполнять обучение, более близкое к тому, что делается при точной настройке, при этом используя меньшее пространство параметров LoRA.
Delta-LoRA
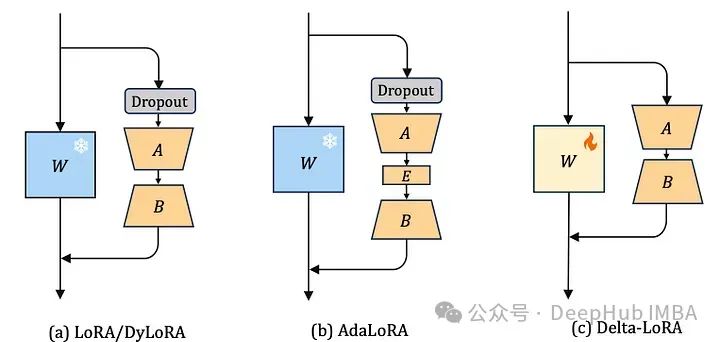
Delta-LoRA [8] предлагает еще одну идею по улучшению LoRA, позволяющую матрице предварительного обучения W снова сыграть свою роль. Основная идея LoRA — не корректировать предобучающую матрицу W, потому что это слишком ресурсозатратно. LoRA представляет новые матрицы A и b меньшего размера. Эти матрицы меньшего размера менее способны к обучению последующих задач, поэтому производительность модели, обученной LoRA, обычно ниже, чем производительность точно настроенной модели.
Delta-LoRAАвтор предлагает использоватьAградиент B для обновления матрицы W, ABГрадиентA*BРазница между двумя последовательными временными шагами。Этот градиент использует гиперпараметрыλУвеличить,λ контролирует, какое влияние новая тренировка должна оказать на предварительно обученные веса.

Это вводит больше параметров для обучения практически без вычислительных затрат. Вместо вычисления градиента всей матрицы W, как при точной настройке, обновите ее градиентом, уже полученным во время обучения LoRA. Авторы сравнили этот подход в ряде тестов с использованием таких моделей, как RoBERTA и GPT-2, и обнаружили, что этот подход повышает производительность по сравнению со стандартным подходом LoRA.
Подвести итог
Область исследований LoRA и связанных с ней методов — очень активная область исследований, в которую каждый день вносятся новые данные. В этой статье объясняются основные идеи некоторых методов. Если вас интересуют эти методы, ознакомьтесь со статьей:
[1] LoRA: Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., … & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
[2] LoRA+: Hayou, S., Ghosh, N., & Yu, B. (2024). LoRA+: Efficient Low Rank Adaptation of Large Models. arXiv preprint arXiv:2402.12354.
[3] VeRA: Kopiczko, D. J., Blankevoort, T., & Asano, Y. M. (2023). Vera: Vector-based random matrix adaptation. arXiv preprint arXiv:2310.11454.
[4]: LoRA-FA: Zhang, L., Zhang, L., Shi, S., Chu, X., & Li, B. (2023). Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning. arXiv preprint arXiv:2308.03303.
[5] LoRA-drop: Zhou, H., Lu, X., Xu, W., Zhu, C., & Zhao, T. (2024). LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation. arXiv preprint arXiv:2402.07721.
[6] AdaLoRA: Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y., Chen, W., & Zhao, T. (2023). Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512.
[7] DoRA: Liu, S. Y., Wang, C. Y., Yin, H., Molchanov, P., Wang, Y. C. F., Cheng, K. T., & Chen, M. H. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv preprint arXiv:2402.09353.
[8]: Delta-LoRA: Zi, B., Qi, X., Wang, L., Wang, J., Wong, K. F., & Zhang, L. (2023). Delta-lora: Fine-tuning high-rank parameters with the delta of low-rank matrices. arXiv preprint arXiv:2309.02411.
Автор: Дориан Дрост



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
