Обзор крупных моделей в финансовой сфере
1 Предисловие
В этом обзоре рассматривается применение больших языковых моделей (LLM) в финансах с упором на существующие решения. Мы рассматриваем способы использования предварительно обученных моделей, точной настройки данных для конкретной предметной области и обучения пользовательских LLM с нуля, чтобы помочь финансистам выбрать правильное решение LLM на основе их потребностей в данных, вычислениях и производительности. Наконец, мы обсуждаем ограничения и проблемы использования LLM в финансовых приложениях и предоставляем план развития финансового ИИ.
2 Базовые знания языковых моделей
Языковая модель — это статистическая модель, используемая для прогнозирования распределения вероятностей последовательностей слов. Его цель — вычислить вероятность P(W), которую можно выразить как:
𝑃(𝑊)=𝑃(𝑤1,𝑤2,...,𝑤𝑛)=𝑃(𝑤1)𝑃(𝑤2|𝑤1)𝑃(𝑤3|𝑤1,𝑤2)...𝑃(𝑤𝑛|𝑤1,𝑤2, ...,𝑤𝑛−1)
Где W представляет последовательность слов.
Условная вероятность P(wi|w1,w2,...,wi-1) представляет вероятность слова wi с учетом предыдущих слов. Он претерпел эволюцию от n-граммной модели к модели, основанной на рекуррентной нейронной сети (RNN), а затем к архитектуре преобразователя. Transformer использует механизм самообслуживания, который может фиксировать долгосрочные зависимости и повышать эффективность обучения крупномасштабных наборов данных. Развитие этих моделей было обусловлено, прежде всего, развитием вычислительной мощности, доступностью крупномасштабных наборов данных и разработкой новых архитектур нейронных сетей. Языковые модели используются в широком спектре приложений, включая обработку естественного языка (NLP) и т. д.
3 Обзор приложений ИИ в финансовой сфере
3.1 Текущие применения искусственного интеллекта в финансовой сфере
в последние годы,Искусственный интеллект широко используется в сфере финансов,Включает торговлю и управление портфелем (количественная торговля), моделирование финансовых рисков, анализ финансового текста, финансовый консалтинг и обслуживание клиентов.。
Торговля и управление портфелем используют модели машинного обучения и глубокого обучения для прогнозирования цен;
Моделирование финансовых рисков использует глубокое обучение для обнаружения мошенничества, кредитного скоринга и прогнозирования банкротства;
Анализ финансового текста извлекает ценную информацию из неструктурированных данных;
Финансовые консультации и обслуживание клиентов используют чат-боты с искусственным интеллектом для обеспечения экономически эффективного обслуживания клиентов.
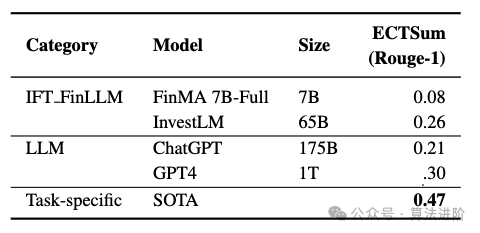
Модель глубокого обучения: способность извлекать ценную информацию из больших объемов данных за короткое время.,Предоставлять своевременную и точную информацию для финансовой отрасли.,С появлением LLM,искусственный интеллект вфинансы Потенциальные области применения в отрасли расширяются.。Ниже приводится производительность крупных моделей для распространенных финансовых задач:
- Анализ настроений (SA)

- Текстовая классификация (TC)
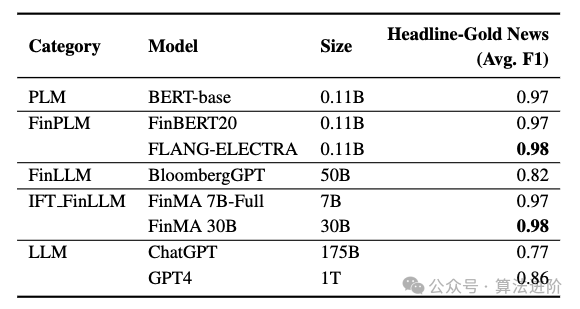
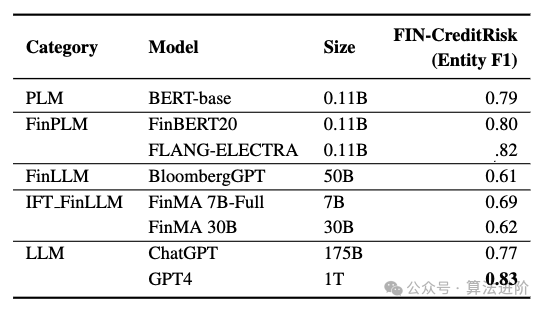
- Распознавание именованных объектов (NER)
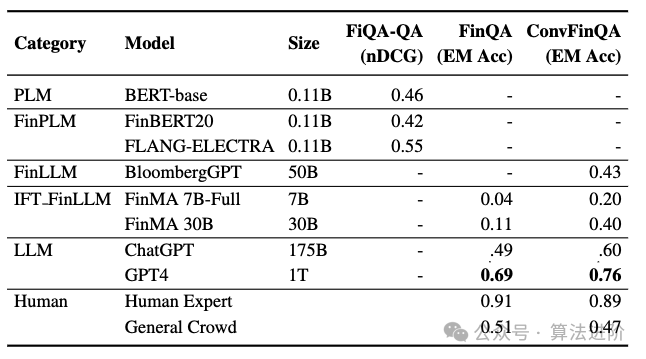
- Вопросы и ответы (QA)
- Прогнозирование тренда акций (SMP)
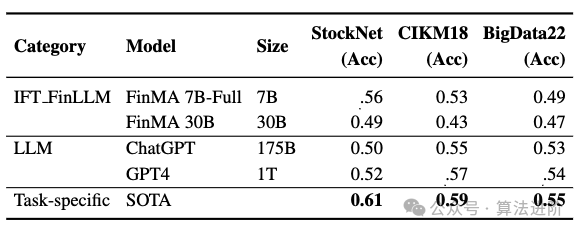
- Текстовое резюме (Summ)
3.2 Преимущества больших языковых моделей (LLM) в финансовой сфере
LLM имеет преимущества в сфере финансов,Способен обрабатывать инструкции на естественном языке, выполнять задачи посредством нулевого обучения, обладает адаптируемостью и гибкостью, а также может одновременно выполнять анализ настроений, обобщение и извлечение ключевых слов.。LLMУмеет разбивать сложные задачи на практические планы,Подходит для финансового обслуживания клиентов или консультаций. Однако,Необходимо отметить его ограничения и риски.
4 технологии LLM в финансовой сфере
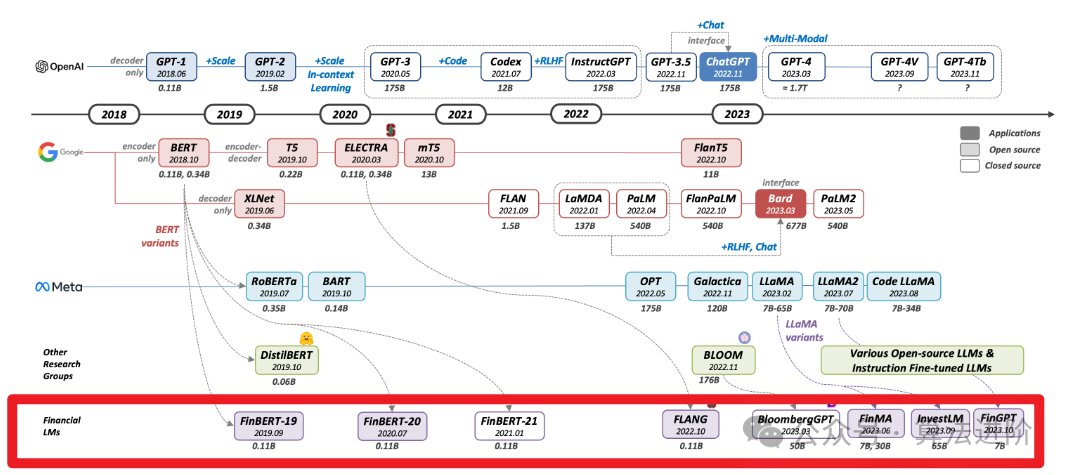
- FinBert-19: FinBERT: анализ финансовых настроений с использованием предварительно обученного языка Модель.
- FinBert-20: FinBERT: предварительно обученный язык для финансового общения Модель.
- FinBert-21: FinBERT: предварительно обученное представление языка финансов. Модель для интеллектуального анализа текста финансов.
- ФЛАНЕЦ: Когда FLUE встречается с FLANG: эталонный и крупномасштабный предварительно обученный язык в поле Модель.
- BloombergGPT: BloombergGPT:Большойфинансыязык Модель
- FinMA: PIXIU: Ориентиры для языка крупномасштабных финансов Модель, инструкции по данным и Оценивать.
- InvestLM: InvestLM: Большой инвестиционный язык Модель корректируется с помощью инструкций по финансам.
- FinGPT: FinGPT: финансовые централизованные тесты настройки инструкций для крупномасштабных языков с открытым исходным кодом Модель
4.1 Использование однократного/нулевого обучения в финансовых приложениях
Доступ к решениям LLM в финансовом секторе может быть обеспечен через API или LLM с открытым исходным кодом. Такие компании, как OpenAI, Google и Microsoft, предоставляют службы API, которые не только предоставляют базовые функции языковой модели, но также предоставляют дополнительные функции, настроенные для конкретных случаев использования. Хотя не существует специализированных услуг LLM, предназначенных специально для финансовых приложений, общие услуги LLM могут подойти для общих задач. Например, сервис GPT4 OpenAI используется для анализа финансовой отчетности. LLM с открытым исходным кодом, такие как LLAMA, BLOOM и Flan-T5, можно загрузить из библиотеки моделей Hugging Face, разместить и запустить самостоятельно. В отличие от использования API, использование моделей с открытым исходным кодом обеспечивает большую гибкость, защиту конфиденциальности и обучение с нулевой выборкой или с небольшим количеством горячих точек, но у проприетарных моделей существует разрыв в производительности.
4.2 Точная настройка модели
Точная настройка LLM в финансовой сфере может улучшить понимание языка и контекста, специфичного для предметной области, повысить производительность задач, связанных с финансами, и генерировать более точные индивидуальные результаты.
4.2.1 Общие методы точной настройки LLM
Современная технология тонкой настройки LLM делится на две категории: стандартная тонкая настройка и обучающая тонкая настройка. Стандартная точная настройка тренируется на исходном наборе данных, тогда как точная настройка обучения создает наборы данных для конкретных задач. Такие технологии, как LoRA и квантование, снижают вычислительные требования. LoRA точно настраивает коэффициенты разложения низкого ранга, чтобы уменьшить количество обучаемых параметров. Квантование использует числа с плавающей запятой более низкой точности, чтобы уменьшить использование памяти и увеличить скорость вычислений.
4.2.2 Точная настройка финансовой оценки LLM
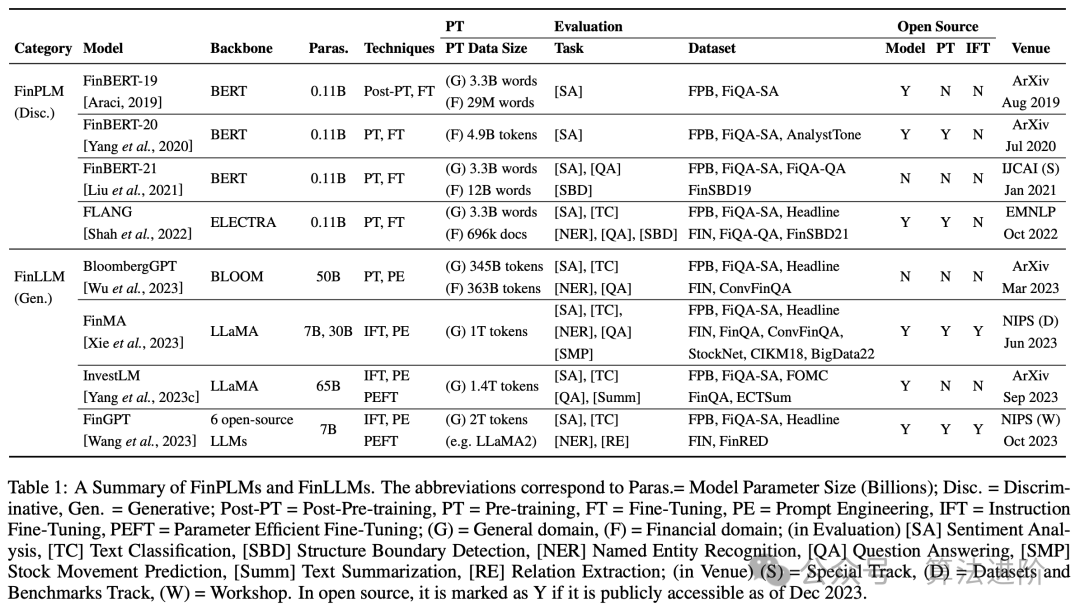
Эффективность точно настроенного финансового LLM можно оценить по двум категориям: задачи финансовой классификации и задачи финансовой генерации. Задачи классификации включают анализ настроений и классификацию заголовков новостей, а задачи генерации сосредоточены на ответах на вопросы, обобщении новостей и распознавании названных объектов. В таблице 1 представлена подробная информация обо всех тонко настроенных финансовых LLM, и мы обсудим три ключевых момента: (1) PIXIU, тонкая настройка LLaMA с 136 тысячами образцов инструкций для конкретных задач. (2) FinGPT предоставляет комплексную систему обучения и применения FinLLM для финансовой отрасли, используя технологию LoRA для точной настройки LLM с открытым исходным кодом, ограниченную задачами финансовой классификации. (3) Instruct-FinGPT, точная настройка LLaMA на 10 тысячах образцов инструкций, оценивает только задачи финансовой классификации. Тщательно настроенный финансовый LLM лучше справляется со всеми задачами в финансовой сфере, превосходя Bloomberg GPT. По сравнению с мощным LLM общего назначения, тонко настроенный финансовый LLM хорошо справляется с задачами финансовой классификации, но работает аналогично или хуже с задачами по генерированию финансовых данных, требуя большего количества наборов данных, специфичных для конкретной предметной области, для улучшения своих возможностей генерации.
Таблица 1. Краткий обзор тонкой настройки финансового LLM

4.3 Предварительное обучение с нуля
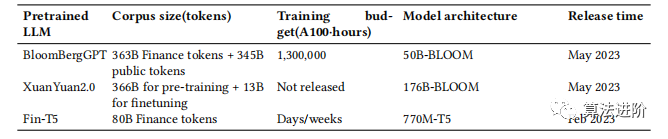
Цель обучения LLM с нуля — разработать модель, лучше адаптируемую к финансовой сфере. В Таблице 2 показаны текущие финансовые LLM, прошедшие обучение с нуля: BloombergGPT, Xuan Yuan 2.0 и Fin-T5. На этапе предварительного обучения наблюдается очевидная тенденция объединения общедоступных наборов данных с наборами финансовых данных. Примером может служить Bloomberg GPT. Его корпус состоит из смеси обычного текста и текста, связанного с финансами, и в основном опирается на него. подмножество из 5 миллиардов собственных кодовых названий Bloomberg. Bloomberg GPT и Fin-T5 показывают лучшую производительность, чем исходная модель, и достигают выдающихся результатов в активных задачах, таких как классификация рыночных настроений, мультиклассификация и классификация по нескольким меткам. Эти две модели работают значительно лучше, чем их соответствующие общие модели, в задачах генерации, связанных с финансами, достигая замечательных результатов. Они демонстрируют аналогичную или лучшую производительность по сравнению с общедоступными моделями аналогичного размера. В целом BloombergGPT показывает похвальную производительность при решении множества задач генерации общего назначения, занимая выгодную позицию среди моделей аналогичного размера.
Таблица 2. Краткий обзор финансового LLM, обученного с нуля
5 Как применить LLM к процессу принятия решений по финансовым заявкам
5.1 Определите необходимость LLM
LLM имеет преимущества, когда не хватает обучающих данных, когда требуются здравые знания или новые возможности, и он подходит для обработки внераспределенных данных и высокодифференцированных разговоров. LLM может служить оркестратором между различными моделями и инструментами, интегрируя и используя различные инструменты. Однако использование LLM сопряжено со значительными затратами, поэтому использование LLM на начальных этапах может быть ненужным или оправданным, если задача четко определена, имеется большой объем аннотированных обучающих данных или минимальная зависимость от знаний здравого смысла. или новые возможности.
5.2 Общие рекомендации по принятию решений по применению LLM к финансовым задачам
При использовании LLM для финансовых задач следуйте рекомендациям по принятию решений, чтобы обеспечить эффективную реализацию, как показано на рисунке 1. Система разделена на четыре уровня, с увеличением затрат на каждом уровне. Рекомендуется начинать с уровня 1 и обновлять его, если производительность модели неудовлетворительна. Каждый уровень имеет подробное объяснение и диапазон стоимости.
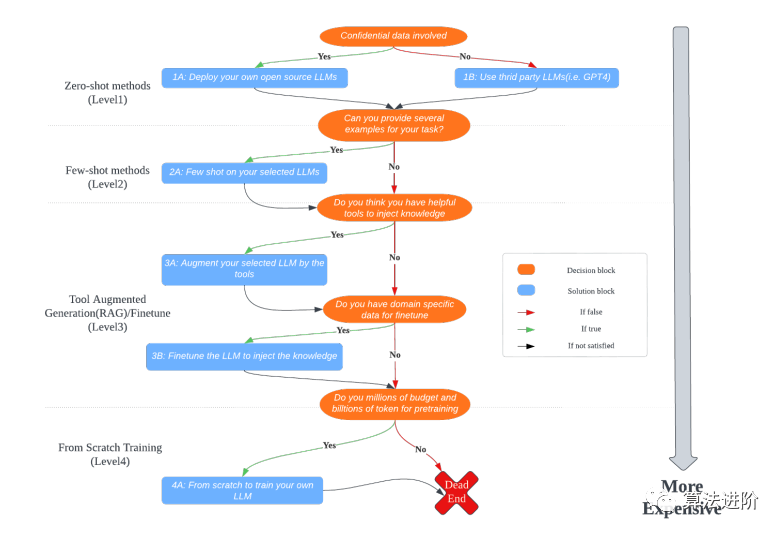
Рисунок 1. Блок-схема процесса принятия решений
5.2.1 Уровень 1: Приложение с нулевой выборкой
Блок принятия решений решает использовать существующую службу LLM или модель с открытым исходным кодом. Операции блока 1A необходимы, когда речь идет о конфиденциальных данных, включая LLAMA, OpenLLAMA, Alpaca и Vicuna. LLAMA предоставляет модели от 7B до 65B только для исследовательских целей. OpenLLAMA предоставляет модели 3B, 7B и 13B для коммерческого использования. Альпака и Викунья основаны на доработке LLAMA и предлагают варианты 7В и 13В. Для развертывания требуется локальный компьютер с мощным графическим процессором. Если конфиденциальность данных не соблюдается, рекомендуется выбрать сторонний LLM, например GPT3.5/GPT4 или Google BARD. Стоимость связана с вызовом API.
5.2.2 Уровень 2: Малократное применение
Если модель работает плохо, вы можете попробовать обучение в несколько этапов, предоставляя примеры вопросов и ответов на них. Затраты аналогичны предыдущим уровням, и каждый раз требуются примеры. Обычно требуется от 1 до 10 примеров. Задача заключается в определении оптимального количества примеров и выборе соответствующих примеров, подлежащих экспериментированию и тестированию для достижения желаемой производительности.
5.2.3 Уровень 3: Разработка усовершенствований инструмента и его точная настройка
В сложных задачах для интеграции с LLM можно использовать внешние инструменты или плагины, например калькуляторы, поисковые системы и т. д. Интеграция инструментов и LLM требует описания инструмента, что может столкнуться с такими проблемами, как высокая стоимость и ограничения на длину входных данных. Если производительность низкая, можно попробовать выполнить тонкую настройку LLM, для чего необходимы данные аннотации, вычислительные ресурсы (GPU, CPU и т. д.) и профессиональные знания, как показано в Таблице 1.
5.2.4 Уровень 4: Обучение LLM с нуля
Если результаты неудовлетворительны, необходимо обучение LLM для конкретной предметной области с нуля, но это сопровождается высокими вычислительными затратами и требованиями к данным, обычно требующими миллионы долларов и триллионы размеченных наборов данных. Процесс обучения сложен и занимает у профессиональной команды месяцы или даже годы. Следуя этой схеме, финансовые специалисты и исследователи могут делать осознанный выбор в соответствии с потребностями и ограничениями ресурсов.
5.3 Оценка
Оценка LLM в сфере финансов может осуществляться с помощью различных методов, включая непосредственную оценку эффективности модели для последующих задач. Метрики оценки можно разделить на две категории: точность и производительность. Точность включает метрики регрессии и классификации, а производительность — производительность при выполнении конкретной задачи. Оценка может проводиться на основе исторических данных, бэктестинга или онлайн-экспериментов. В дополнение к оценке конкретных задач также могут применяться общие показатели LLM, такие как комплексные системы оценки, охватывающие точность, справедливость, надежность, предвзятость и т. д.
5.4 Ограничения
Хотя LLM добилась значительных успехов в области финансов,Но необходимо признать его ограниченность.,Ключевые проблемы – дезинформация и предвзятость。Для обеспечения точности информации и уменьшения галлюцинаций,Могут быть реализованы такие меры, как генерация улучшения поиска. Для решения проблем предвзятости,Технологии модерации и вывода контента могут использоваться для контроля создаваемого контента и уменьшения предвзятости.。С точки зрения регулирования и управления,LLM имеет ограниченную интерпретируемость,Для обеспечения этичного и ответственного использования необходимы постоянные исследования и меры предосторожности.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
