Обучение мультимодальному LLM с нуля: предварительное обучение + тонкая настройка инструкций + согласование + мультимодальное объединение + связь с внешними системами

Глубокое обучение обработке естественного языка делиться Чжиху: Побег икры
В этой статье делается попытка разобратьсяПолный мультимодальный процесс обучения LLM。включать Структура моделивыбирать、данныепредварительная обработка、Предварительное обучение модели、инструкциятонкая настройка、Выравнивание、Интегрируйте мультимодальность такжессылки на внешнюю систему и другие ссылки.
1. Этап подготовки
1 Структура модели
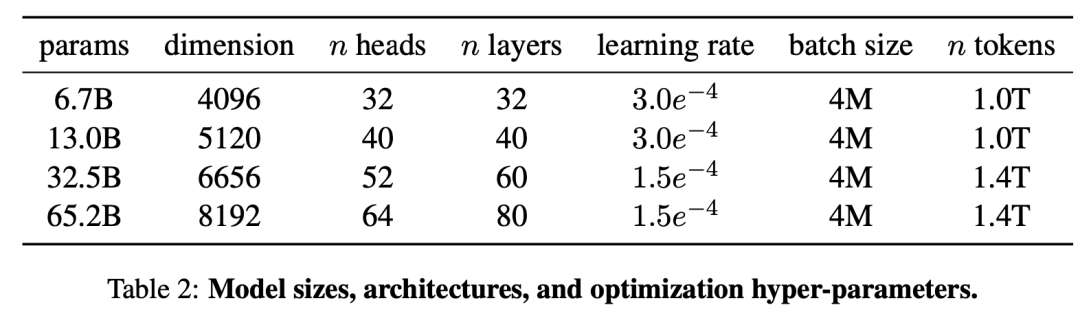
В настоящее время существует три основные архитектуры моделей: на основе декодера Transformer и на основе General. Language Model,а также эксперт по микшированию Модель. На этом этапе вы можете напрямую выбрать базовую модель с открытым исходным кодом, например семейство моделей LLaMA, основанное на архитектуре декодера Transformer, Структура. модели И некоторые важные параметры показаны ниже.。гипотезавыбиратьLLaMA-65B,Токенизатор выбирает токенизатор LLaMA на основе алгоритма BPE. Если вы хотите расширить свой словарный запас,Вы можете объединить словарные списки LLaMA после обучения их целевому языку.
2. Данные перед тренировкой
1 источник данных
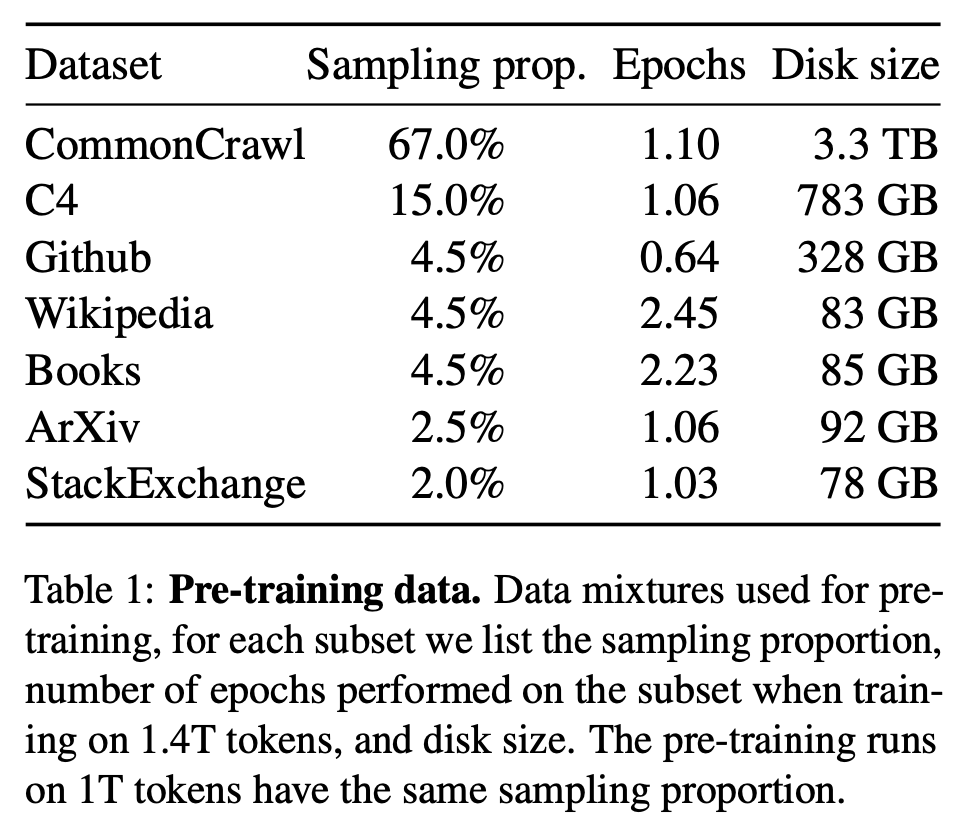
Согласно закону масштабирования Шиншиллы, для достижения оптимального использования вычислительных ресурсов количество обучающих токенов, соответствующих модели 65B, должно достигать 1,4Т. В настоящее время существует множество источников данных, используемых для обучения LLM, но высококачественные данные среди них ограничены. Эти данные являются ключом к повышению производительности модели. Кроме того, в некоторых статьях отмечается, что данные кода могут помочь улучшить логические способности модели. Поэтому необходимо смешивать данные из нескольких источников данных и разумно распределять долю еженедельных данных. Как показано на рисунке ниже, вы можете обратиться к источникам данных и пропорциям LLaMA, где размер диска представляет собой общий объем доступных данных, реквизит выборки представляет собой долю от общего количества токенов обучения, а эпохи представляют количество выборок.
2 Обработка данных
Если вы хотите повысить производительность модели, помимо использования существующих наборов данных с открытым исходным кодом, таких как The Pile, C4, OSCAR и т. д., вы также можете создавать свои собственные наборы данных. Как упоминалось в документе RefinedWeb, наборы данных, созданные на основе данных веб-страниц, также могут достичь того же эффекта, что и тщательно собранные наборы данных. Информацию о высококачественных методах обработки данных, таких как Wikipedia, Books, GitHub, ArXiv и StackExchange, можно найти в статье The Pile. Ниже представлен метод построения набора данных на основе Common Crawl. CC представляет собой массивный, неструктурированный, многоязычный набор данных веб-страниц, содержащий наборы данных веб-сканеров за более чем 8 лет, включая исходные данные веб-страницы (WARC), метаданные ( WAT) и извлечение текста (WET). Ежемесячно публикуется снимок объемом от 20 до 30 ТБ несжатого обычного текста, включая веб-страницы, полученные в результате случайного поиска и выборочные URL-адреса. Между данными, опубликованными в разные месяцы, имеется лишь очень небольшое совпадение. лет. Общий объем поступающих данных находится на уровне петабайт. Как показано на рисунке ниже, процесс обработки данных включает три этапа: подготовку документа, фильтрацию и дедупликацию. Подробную информацию об этом методе можно найти в документе RefinedWeb.

2.1 Подготовка документов
Включая чтение данных, фильтрацию URL-адресов, извлечение текста и распознавание языка;
Чтение данных
Текстовые данные можно читать как из файлов WET, так и из файлов WARC. Непосредственное использование файлов WET позволяет исключить работу по извлечению текста из файлов HTML, но содержит некоторую ненужную информацию. Таким образом, можно читать текст из файлов WARC.
Фильтровать URL-адреса
Перед формальной обработкой текстовых данных необходимо выполнить первую фильтрацию URL-адресов. Целями фильтрации являются мошеннические веб-сайты и веб-сайты для взрослых (в основном веб-сайты с порнографией, насилием, азартными играми и т. д.). Фильтрация основана на двух правилах: (1) черный список из 4,6 миллионов доменных имен; (2) оценка URL-адресов на основе определенного списка слов, собранных и взвешенных по степени серьезности. В то же время источники данных, содержащиеся в наборах данных с большим количеством текста, таких как Wikipedia и arXiv, могут быть отфильтрованы по мере необходимости.
Извлечь текст
Цель состоит в том, чтобы извлечь основной контент HTML-страницы, игнорируя меню, верхние и нижние колонтитулы, рекламу и т. д. Вы можете использовать trafilatura, jusText и другие библиотеки в сочетании с регулярными выражениями для извлечения текста. Наконец, ограничьте количество новых строк двумя последовательными строками и удалите все URL-ссылки.
Распознавание языка
Распознавание языка Может Удалить дубликаты также можно найти перед Удалить последовали дубликаты. Но когда количество документов относительно невелико, первая идентификация приведет к некоторым ошибкам классификации языков. Классификатор языка fastText можно использовать для классификации языков. Этот классификатор обучен на Wikipedia, Tatoeba и SETimes, использует n-граммы в качестве функций и использует иерархический softmax для поддержки. 176 классификацию языков и, наконец, выводит 0~1 счет. Удалите документы, у которых максимальный языковой балл ниже установленного порога. Изменяя пороговое значение, вы можете настроить долю сохраняемых документов.
2.2 Фильтрация
Качество документов, извлеченных с веб-страниц, низкое. Цель фильтрации — удалить повторяющиеся абзацы, нерелевантный контент, неестественный язык и т. д. для улучшения качества текста. Включает фильтрацию на уровне документа и строки;
Содержит дубликаты документов, удалены.
Это можно сделать на этапе дедупликации, но дешевле и проще сделать это на ранней стадии. Как правило, эвристический метод используется для формулирования ряда правил для удаления любого документа со слишком большим количеством строк, абзацев или повторений в n-граммах. Методы можно найти в статье BLOOM.
Фильтрация документов
Основная цель — сохранить документы на естественном языке, написанные людьми для людей, и удалить машинный спам, который в основном состоит из списков ключевых слов, шаблонного текста или последовательностей специальных символов. Такие документы не подходят для языкового моделирования. Используется эвристический алгоритм фильтрации качества. Подробную информацию о методе можно найти в статье BLOOM. Основное внимание уделяется удалению выбросов на основе длины документа, соотношения символов и слов и других критериев, чтобы гарантировать, что документ составлен на истинном естественном языке.
Фильтрация на уровне строк
Текст, извлеченный с помощью библиотеки трафилатуры, избегает большей части нерелевантного контента, но пропуски все же есть. Продолжайте фильтровать контент, не связанный с основным текстом (например, количество лайков, кнопки навигации и т. д.), через фильтр линейной коррекции.
2.3 Удаление дубликатов
После фильтрации качество данных улучшилось, но многие документы оказались дубликатами. Документы можно дедуплицировать посредством нечеткого сопоставления документов и точного удаления последовательности.
Размытие и дедупликация
Для удаления похожих документов можно использовать алгоритмы SimHash, MinHash: для каждого документа рассчитывается его приблизительное сходство с другими документами и удаляются пары документов с высокой степенью перекрытия. Изменяя параметры алгоритма хеширования, можно регулировать долю дедупликации.
Точная дедупликация
Обычно используется точная дедупликация подстроки, то есть дедупликация на уровне последовательности. Удалите абзацы, которые повторяют последовательные токены выше заданного порога, используя массив суффиксов для поиска точных совпадений между строками.
Дедупликация URL-адресов
Дальнейшее удаление повторяющихся посещенных URL-адресов из дампов CC.
2. Предварительное обучение модели
Метод предварительного обучения LM, основанный на архитектуре декодера Transformer, заключается в том, чтобы позволить модели выполнять Next Token Prediction Задача. Метод предварительного обучения LM, основанный на GLM, заключается в том, чтобы позволить Модели выполнить задачу авторегрессионного заполнения пробелов. Благодаря своим масштабам и большим весовым габаритам ЛЛМ имеет большое количество параметров. Существует большое количество такжеданных, которые вызовут такие проблемы, как нестабильное обучение, трудности сходимости, длительное потребление времени и огромные вычислительные ресурсы. Ниже из структуры моделиисоветы по тренировкам знакомит с некоторыми способами улучшения скорости обучения Моделиа. также Пути повышения стабильности тренировок.
1 Структурное улучшение
Используйте предварительную нормализацию, например RMSNorm, для нормализации параметров перед остаточным соединением. Некоторые параметры добавляются непосредственно к последующим параметрам, что может предотвратить взрыв или исчезновение градиентов. Используйте активацию SwiGLU вместо ReLU, чтобы улучшить производительность модели. По сравнению с традиционным кодированием абсолютного положения, кодирование относительного положения лучше работает с длинными последовательностями, такими как методы кодирования RoPE и ALiBi. Обычный запрос с самообслуживанием требует большого количества вычислительных ресурсов и ресурсов хранения. Используя Multi Query Attention и Flash Attention, можно сократить объем вычислений и повысить скорость обучения.
2 техники обучения
Конкретные методы можно найти в предыдущей статье по обучению модели: «Крупномасштабные языковые модели (LLM) — предварительное обучение — ускорение больших моделей». Во-первых, смешанная точность может использоваться для уменьшения объема вычислений, то есть веса и градиенты модели представлены с помощью float16, а оптимизатор использует float32 для представления параметров, передача данных и расчет выполняются одновременно для повышения эффективности обучения;
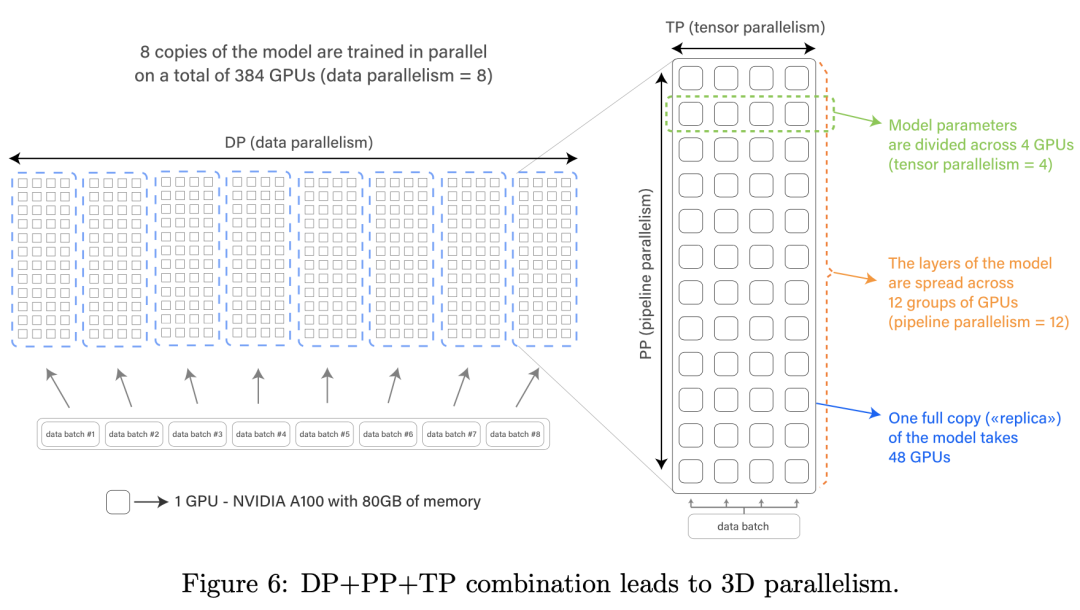
Как показано на рисунке ниже, когда LLM не может работать на одном графическом процессоре из-за его большого размера или использование одной карты низкое, необходимо принять параллельную стратегию для ускорения обучения. Предпочтителен тензорный параллелизм, за которым следует дальнейшее сочетание с конвейерным параллелизмом. В случае обильных вычислительных ресурсов параллелизм данных ZeRO дополнительно объединяется для достижения 3D-параллелизма и параллельного обучения на нескольких графических процессорах. См. статьи Megatron-Turing и BLOOM.
Когда видеопамяти одной карты недостаточно, вы также можете комбинировать некоторые приемы, такие как технология разгрузки ЦП, чтобы временно поместить рассчитанные промежуточные результаты активации в память (ЦП), а затем поместить их обратно в видеопамять (ГП). ) при необходимости с использованием дополнительной связи. Накладные расходы обмениваются на видеопамять или используется контрольная точка (перевычисление). Во время прямого распространения некоторые промежуточные результаты активации, которые временно не используются, удаляются для уменьшения объема памяти. Во время обратного распространения прямые вычисления временно выполняются. выполняется по мере необходимости или с КПП нагрузки.
3 отзыва
После предварительной тренировки,Необходимо оценить работу Модели. Обычно используемый индекс оценки LM, PPL, в основном используется для оценки того, являются ли предложения, сгенерированные LM, гладкими и гладкими. кроме,Важнее всего знаниесодержащая способность ОбзорLLM.,Включает в себя рассуждение о здравом смысле,Вопросы и ответы,Обработка кода,математикарассуждение,Понимание прочитанного и другие способности.
3.1 быстрый дизайн
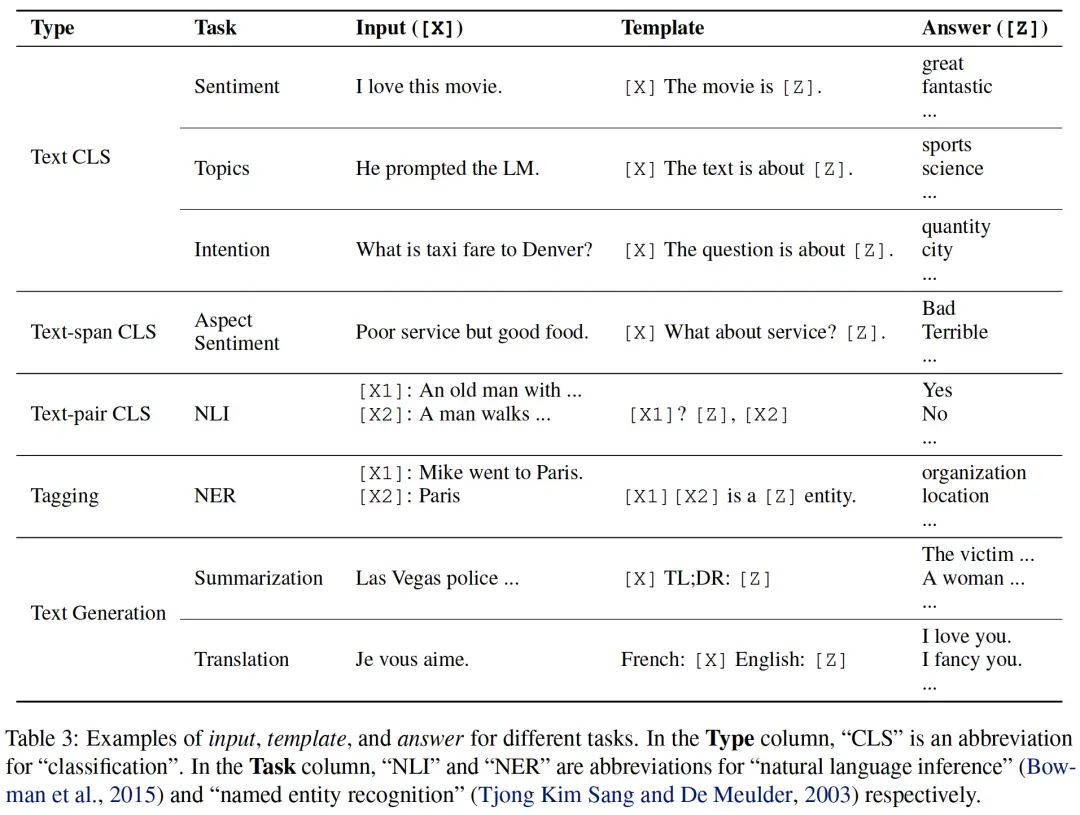
и Предыдущее обучение + тонкая от эксперта Модель Парадигма настройки» другая. В настоящее время LLM в основном принимает парадигму «предварительное обучение + контекстное обучение». Поэтому необходимо выбрать соответствующий шаблон подсказки для каждой последующей задачи, чтобы помочь Модели вспомнить знания, полученные в ходе предварительного обучения и обеспечить предварительное обучение для последующих задач. Унификация обучающих задач. Структура шаблона представляет собой текстовую строку с двумя слотами: входной слот. [X], для входных вопросов, выходной слот [Z] для промежуточного сгенерированного текста ответа Z. На практике, чтобы модель поняла задачу, получается несколько обучающих примеров путем заполнения шаблона вопросами и ответами. Затем заполните шаблон фактическими входными данными и объедините их с обучающими примерами, чтобы получить полную подсказку, и введите ее в модель. В задачах анализа настроений шаблон может иметь форму «[X], it is [Z].". Предположим, x = "I like this блюдо", полная подсказка звучит так: "Я like this dish, it is [Z].». Заполненный ответ называется закрывающей подсказкой в середине текста. подсказка,), в конце текста называется префиксной подсказкой (префикс быстрый). Сгенерированные ответы затем преобразуются в выходные данные, необходимые для выполнения задачи. В таблице ниже приведены дополнительные примеры.
3.2 Набор контрольных показателей для оценки
См. документ LLaMa, в котором производительность модели в основном оценивается по следующим аспектам: рассуждения, основанные на здравом смысле (BoolQ, PIQA, SIQA, HellaSwag, WinoGrande 、ARC easy и challenge а также OpenBookQA ), закрытая книга вопросов и ответов (Естественный Questions и TriviaQA ), понимание прочитанного (тест RACE на понимание прочитанного), математическое мышление (MATH и GSM8k), генерация кода (HumanEval и MBPP), крупномасштабный многозадачный тест понимания языка. MMLU , этот набор тестов состоит из вопросов с несколькими вариантами ответов, охватывающих гуманитарные науки, STEM и различные области знаний, такие как социальные науки, также C-Eval (набор данных для проверки знаний китайского языка, охватывающий 14 000 вопросов с несколькими вариантами ответов, всего 52 предмет. В наборе данных для Обзор Модель знание китайского языка).
3. Доработка инструкций по краудсорсингу на естественном языке.
пройти После предварительной LLM тренинга имеет обширную базу знаний,Имеет мощный естественный языкрассуждениеи Обработка кодаспособность。Но в некоторых задачахизZero-Shotспособность Очень плохо。В целях дальнейшего улучшенияLLMпо невидимым задачамизинструкцияобобщатьспособность,Это возможность Zero-Shot,Необходимо предварительно обучить Модель на естественном языке, краудсорсинговые инструкции тонкая настройка,ссылкабумагаFLAN 。тонкая Настраиваемый набор взят из общего набора тестов NLP. Шаблон инструкций для задач CoT и не CoT получается путем преобразования форматов ввода и вывода, как показано на рисунке ниже. тонкая После существовать это может значительно улучшить различные сверчки (ладонь、T5、U-PaLM)、Различные настройки обучающего примера (Zero-Shot、Few-Shot、CoT) и различные невидимые тесты оценки (MMLU、BBH、TyDiQA、MGSM、открытое поколение、Производительность на RealToxicityPrompts).
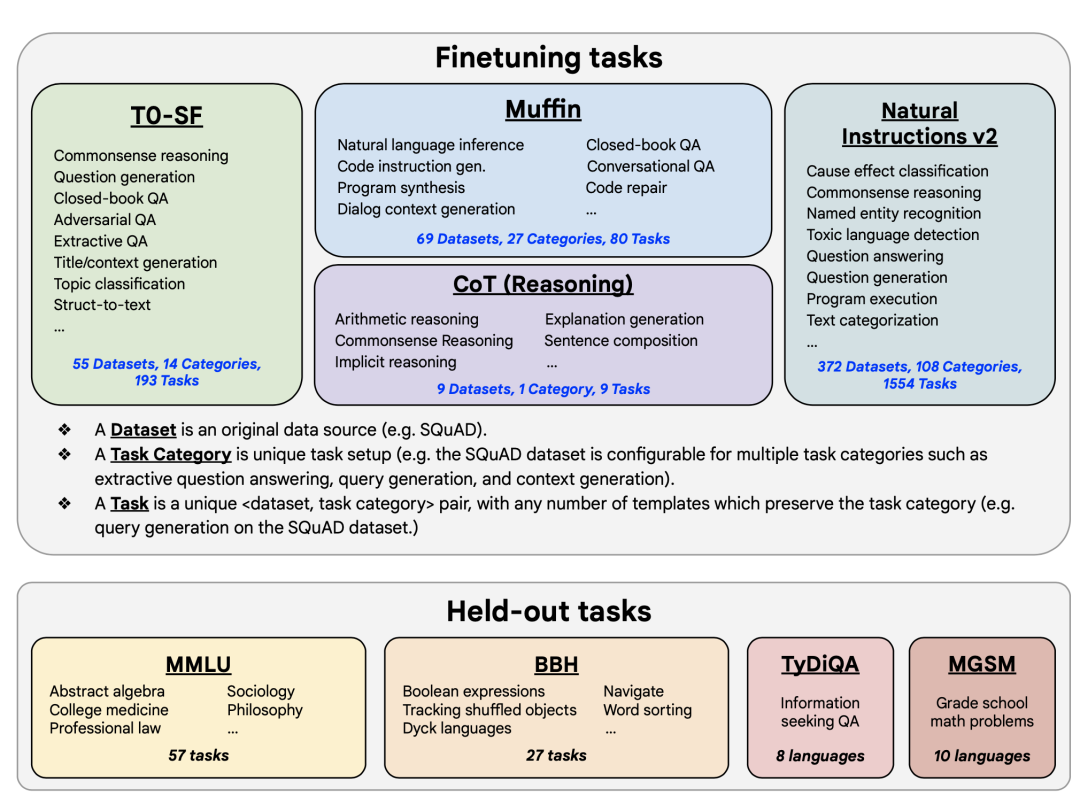
1 Построение набора данных
Всего из общего пакета естественного языка собрано 1836 эпизодов данных.,Разделены на наборы задач Muffin, T0-SF, NIV2иCoТрассование Четыре. Затем преобразуйте каждую информацию в форму командной строки, используя шаблон, предоставленный создателем задачи.,Например,Для той же задачи перевода,Общая подсказка: «Я беру свою девушку в Гуйлинь». Английский перевод: ___; командная строка: переведите это предложение: ввод: я взял свою девушку с собой в Гуйлинь, вывод: _______. Подсказка с инструкциями по выводу CoT приведена ниже:

2 тонкая настройка
Объедините несколько выборок вместе, чтобы получить одну последовательность, пока не будет достигнута максимальная длина последовательности, и выполните обучение предсказанию следующего токена.
3 отзыванабор
Цель Обзор инструкциятонкая Возможность обобщения Модели на невидимые задачи после настройки. Оценочный набор включает в себя: (1) MMLU, тестовые вопросы из 57 областей, таких как математика, история, право и медицина. (2) BBH, 23 сложных задания от BIG-Bench (3); TyDiQA, тест на ответы на вопросы, установленный на 8 разных языках (4); MGSM, многоязычный набор тестов для решения математических словесных задач.
Четыре выравнивания
Целью этого шага является выполнение Выравнивания Модели человека. Модельное обучение (SFT) с использованием реальных отзывов пользователей. / RLHF), что делает результаты LLM более соответствующими предпочтениям человека и намерениям пользователя. Сюда входят как явные намерения, такие как следование инструкциям, так и неявные намерения, такие как сохранение честности, непредвзятости или других вредных ценностей. Самый важный шаг — собрать реальные и разнообразные инструкции. также Ответить,придетсяприезжатьинструкцияследоватьданныенабор(Вопросы и форма ответов). в то же время,Вы можете смешивать некоторые разговорные инструкции с данными (впишите все предыдущие разговоры в подсказку для следующего вопроса).,Разрешите LLM общаться с пользователями в разговорной форме.
1 SFT
Собери сначаланабор Многоиз<инструкция,отвечать>данныеверно,Получите инструкцию следовать набору данных. Затем используйте данные набора команд для контролируемого выполнения настройки инструкций на ранее обученном LLM.,Получите SFTМодель. Модель SFT, полученная на этом этапе, уже может обеспечить очень хорошее Выравнивание для людей.
1.1 Построение набора данных
InstructGPT Метод состоит в том, чтобы собрать большое количество запросов, отправленных пользователями в интерфейс API, и потратить огромные суммы денег на найм профессиональной команды для опроса пользователей. Создать ответ, получите инструкции по выполнению набора данных. Но этот подход в принципе трудно воспроизвести. Помимо использования некоторых наборов команд с открытым исходным кодом, таких как Alpaca и BELLE, вы также можете обратиться к instruct Способ создания ChatGPT Подождите, пока высококачественный LLM создаст желаемый набор данных для выполнения инструкций. Конкретный метод заключается в том, чтобы вручную построить несколько выборок обучающих данных для ChatGPT смотри, используй ChatGPT Функция продолжения позволяет непрерывно генерировать новые образцы обучающих данных, делая выводы.
А. Сначала вручную создайте расширенные начальные задачи, дайте ChatGPT изучить и предложить новые инструкции для задач, как показано ниже:

Затем разрешите ChatGPT генерирует входные данные (вопросы) и выходные данные (ответы) на основе искусственно созданных примеров обучения для предлагаемой новой задачи и получает новые примеры данных обучения:

Наконец, некоторые выборки данных низкого качества отфильтровываются для получения инструкции, следующей за набором данных.
B. Далее вы можете обратиться к статье Evol-Instruct. Как показано ниже, начиная с серии инструкций, созданных вручную, ChatGPT/GPT-4 постепенно генерирует более сложные инструкции. Затем используйте ChatGPT/GPT-4 Инструкция по эволюции Создать ответ. Далее смешиваем все сгенерированные данные инструкций с тонкой настройкаязык Модель。
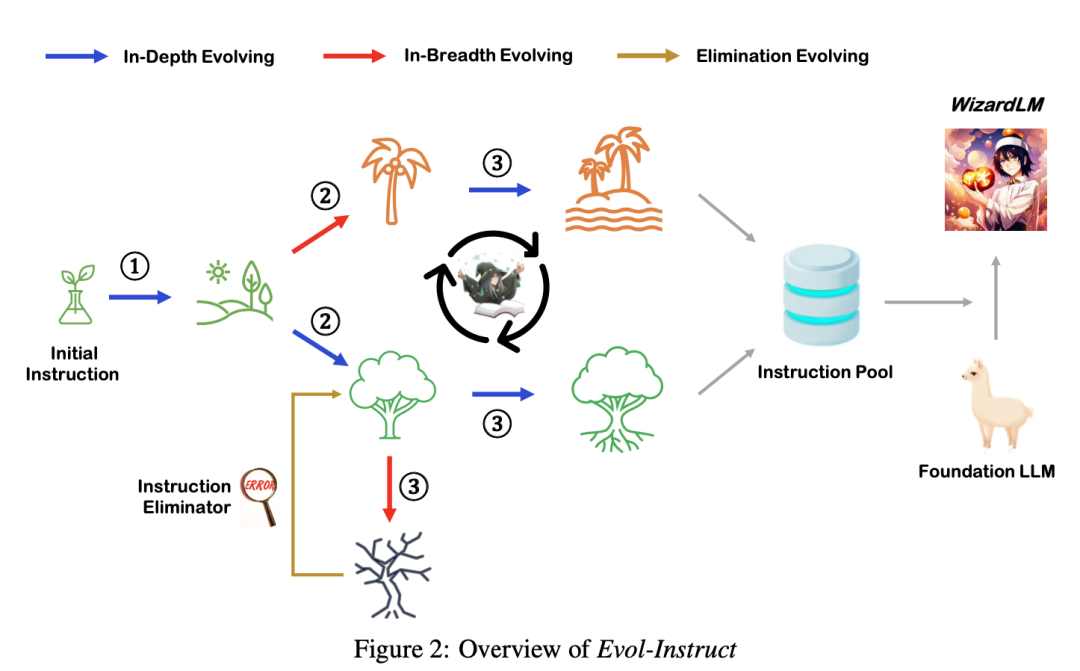
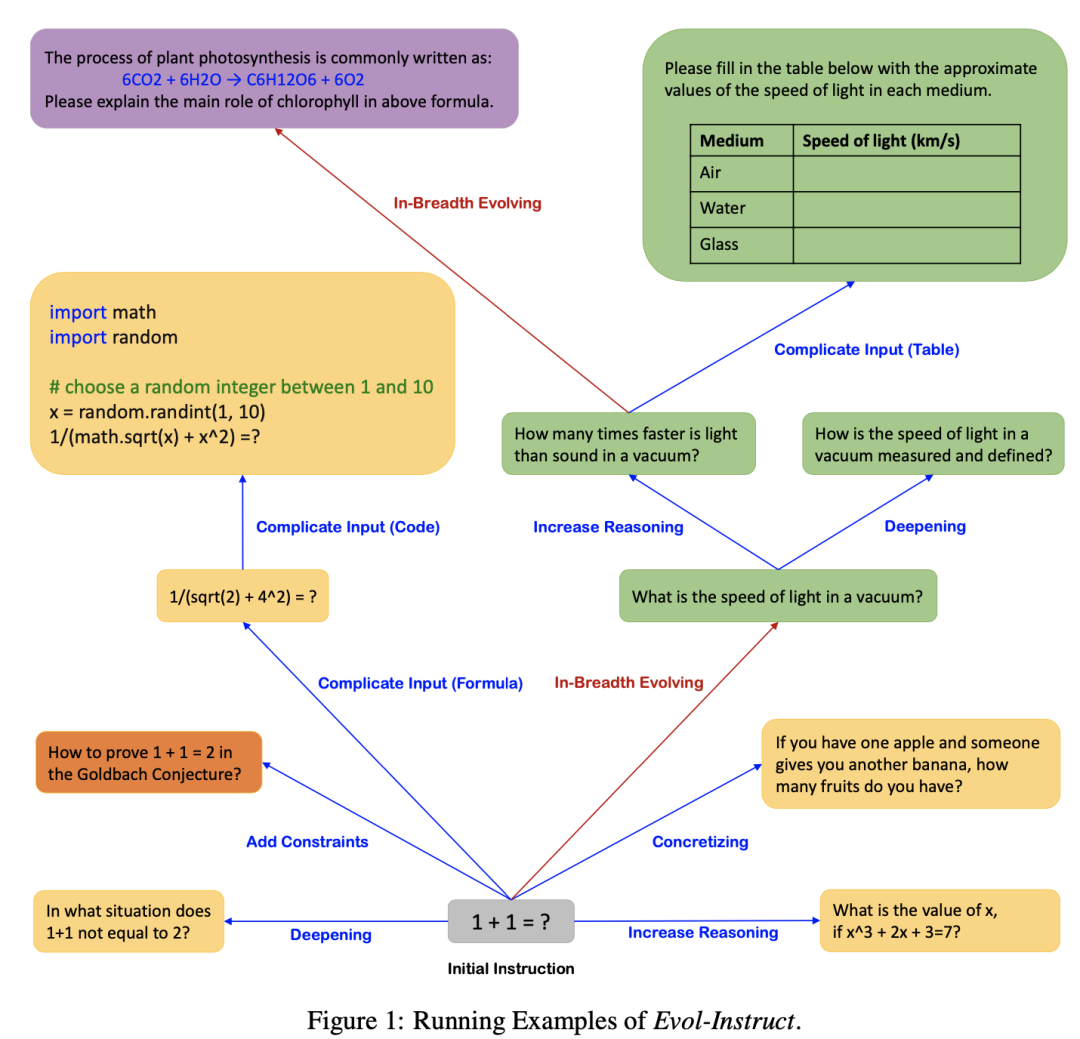
На рисунке ниже показан пример Evol-Instruct. Начиная с простой начальной инструкции «1+1=?»,Используйте подсказку, чтобы предложить LLM случайным образом выбрать эволюцию глубины (синяя линия индикатора) или эволюцию ширины (красная линия индикатора).,Начните с простых инструкций и постепенно увеличивайте сложность. Эволюция ширины включает добавление ограничений, углубление, уточнение и добавление шагов рассуждения, усложняющих ввод. Развитие ширины направлено на расширение тематического охвата, охвата навыков и разнообразия общего набора данных.,Сделайте сгенерированные инструкции совершенно новыми.,Более длиннохвостый. Поскольку развитые инструкции генерируются LLM,Иногда эволюция терпит неудачу,Поэтому необходимо удалить неудавшиеся инструкции. Повторите этот процесс эволюции в течение нескольких раундов.,Для получения достаточно инструкций данных, охватывающих различные сложности.
1.2 тонкая настройка
Стандартная директива тонкая настройка: объединить все подсказки и ответы в обучающем наборе с помощью специального token для разделения подсказокифрагмент ответа,Использование авторегрессионных целей,Не рассчитывает потери из части токена пользовательской подсказки.,Обратному распространению подлежит только токен ответа.
1.3 отзыва
Основная цель Обзора – обеспечить выполнение инструкций по Выравнивание тонкой После настройки общие способности SFTModel, приобретенные на этапе предварительного обучения. Также способность к контекстуальному обучению значительно не снизилась. Будьте осторожны, не складывайте его в кучу benchmark Посмотрите на средний балл, потому что средняя разница невелика, и многие задания не репрезентативны, дифференцированы только основные; benchmark Обзор, в том числе: способность извлечения знаний (MMLU), способность рассуждения (GSM8k / BBH ), способность кодирования (Человеческий Eval / MBPP) а также МАТЕМАТИЧЕСКИЕ СПОСОБНОСТИ (МАТЕМАТИЧЕСКИЕ ). с другой стороны,Нужен Обзор Модель, сгенерированный ответ, и человеческое Выравнивание. Выравнивание способности можно получить с помощью искусственного обзора.,Содержание оценки включает в себя подлинность,полезность,полезность,harmlessness,честность) и т. д.,Вы также можете передать достаточно большой,Обзор выполняет уже обученный РМ.
2 RLHF
Чтобы добиться лучшего согласования, вы можете продолжить обучение модели SFT с помощью обучения с подкреплением. Соберите набор реальных инструкций, используйте модель SFT для генерации ответов для каждой инструкции и ранжируйте ответы в соответствии с предпочтениями человека на основе нескольких индикаторов, основанных на аннотаторах. Используйте результаты рейтинга для обучения модели оценки (модель вознаграждения, RM), соответствующей предпочтениям человека. Наконец, алгоритм PPO используется для оптимизации модели SFT с оценкой RM.
2.1 Reward Model
Один из способов — обратиться к документу InstructGPT. , используйте Модель SFT в качестве начальной Модели, удалите последний невстроенный слой, обучите и оцените Модель для получения инструкций и ответов и выведите скалярную оценку вознаграждения. Данные обучения — это сравнение одних и тех же входных инструкций, но разных данных ответов (принять или отклонить). Используя потерю двоичного рейтинга с разными ответами в качестве меток, разница в баллах вознаграждения представляет собой логарифмический шанс того, что человек, размечающий ярлык, предпочтет один ответ другому. Как показано ниже, сначала соберите несколько реальных инструкций для пользователя, чтобы позволить SFT Модель Создать. ответ,Используйте экспертов для ранжирования ответов на основе таких критериев, как релевантность, информативность или вредность. Затем используйте результаты сортировки для обучения модели оценки. Способ обучения - для группы обучающих данных.,Предположим, что ответ 1 ранжируется раньше ответа 2 при сортировке вручную.,Затем тренируйтесьиз Цель состоит в том, чтобы поощритьRMМодельверно<инструкция,отвечать1>из Оценка, чем<инструкция,отвечать2>из Оценка выше,Теггеры подсчета очков, обученные таким образом, имеют постоянные предпочтения. Масштаб оценки модели должен быть как можно большим.,Например, используйте 175 ринггитов для перехода на ППО СФТ модели 7Б.
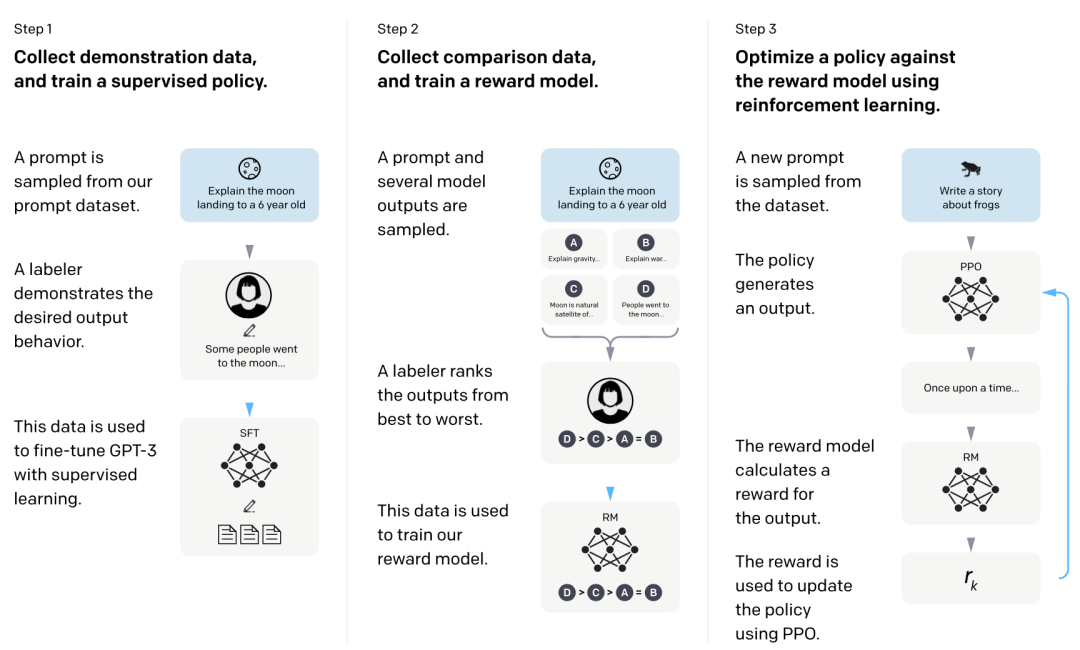
Другой подход можно найти в статье Anthropic. LLM , через три этапа обучения, включая языковое Предварительное обучение модели,Предпочтение Предварительное обучение модели,а также Предпочтение Модельтонкая настройка. Сначала предварительно обучите язык Модель на крупномасштабном корпусе. На этом этапе напрямую используется тонкая инструкция. Получите LLM после настройки. Затем получите набор данных смешанного контраста из StackExchange/Reddit/Википедии и т. д. и выполните предварительное обучение на модели предпочтений. Наконец, тонкая информация о сравнении данных с отзывами людей настройка,Модель оценки предпочтений человека при обучении. На втором и третьем этапах обучения,Добавьте специальный маркер «конца контекста» в конец образца.,как прогнозируемый результат.
2.2 PPO
Принимая SFT в качестве исходной стратегии, оценивая стратегию на основе RM и используя обучение с подкреплением для оптимизации стратегии, получается расширенная версия модели PPO. Цель обучения — добиться высокой отдачи от ответов, генерируемых PPO. Метод обучения заключается в обновлении параметров PPO в соответствии с показателем RM. Чтобы предотвратить чрезмерную оптимизацию модели со стороны RM, к вознаграждению необходимо добавить штраф KL, чтобы полученная модель PPO не слишком сильно отличалась от исходной модели политики SFT. В то же время некоторые градиенты предварительного обучения могут быть смешаны с градиентом цели оптимизации, чтобы дополнительно гарантировать, что изученная модель сохранит общие возможности SFT. Конкретные методы можно найти в документе instructGPT.
2.3 Онлайн-обучение PPO
По мере оптимизации SFT ответы, генерируемые полученной моделью PPO, все больше и больше соответствуют человеческим предпочтениям. Первоначально обученная модель вознаграждения недостаточно надежна для таких высококачественных ответов. Чтобы облегчить эту проблему, обратитесь к документу Anthropic LLM, в котором можно дополнительно использовать итеративное онлайн-обучение: используйте лучшую модель PPO, полученную в каждом раунде обучения с подкреплением, для создания сравнительных данных для ручного аннотирования. Смешайте новые данные сравнения с существующими данными, переобучите новую модель вознаграждения и, наконец, используйте новую модель вознаграждения для нового раунда обучения PPO.
2.4 отзыва
См. Обзор по ссылке SFT.
5. Интеграция мультимодальности
Чтобы в дальнейшем позволить LLM получить возможности понимания изображений, в LLM необходимо интегрировать мультимодальность. Один из подходов заключается в использовании предварительно обученной крупномасштабной языковой модели, а также визуальных кодировщиков для создания мультимодальной унифицированной модели.
1 Структура модели
Справочный документ LLaVA ,MiniGPT-4 ,BLIP2 иmPLUG-Owl ,Структура Как показано на рисунке ниже, модели состоят из визуального кодировщика, проекционного слоя и языковой модели (LLM обучен ранее). Функция визуального кодировщика заключается в извлечении характеристик изображения, обычно используется ViT-L/14. Функция слоя проекции заключается в реализации выравнивания пространства визуальных признаков и пространства текстовых признаков. Вы можете выбрать простой линейный слой или более сложную структуру, например запрос в BLIP2. Transformer(Q-Former),Целью этой структуры является извлечение визуальных функций из замороженного визуального кодировщика с использованием набора обучаемых векторов запросов.,Действовать в качестве узкого места между визуальным кодировщиком и кодировщиком текста. Вы также можете обратиться к статье mPLUG-Owl.,Замените слой проекции модулем визуальной абстракции.,Объедините плотные визуальные функции, извлеченные из визуальной базовой модели, в несколько обучаемых токенов.,Это приводит к более высокому семантическому визуальному представлению и сокращению вычислений.
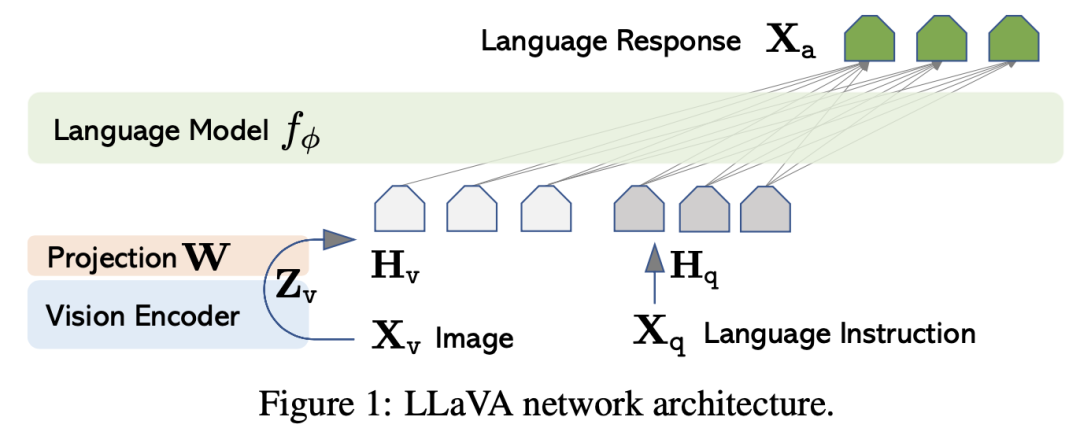
2 Выравнивание пространства визуальных объектов и пространства текстовых объектов
2.1 Построение набора данных
Данные обучения представляют собой данные пары подписей к изображениям из нескольких наборов данных, включая LAION-400M, COYO-700M, Conceptual. CaptionsиMSCOCOждать。
2.2 Предварительное обучение модели
Первый этап предварительного обучения — позволить визуальной модели эффективно захватывать семантическую визуальную информацию низкого и высокого уровня.,и объединить его с предварительно обученным языком. Модель Выравнивание,без ущерба для производительности языка Модель. во время тренировки,Заморозить параметры визуального кодировщика и LLM,Меняйте только параметры проекционного слоя,Цель обучения состоит в том, чтобы сделать визуальные функции, извлеченные визуальным кодировщиком, и встраивания текста, полученные слоем встраивания LLM. Выравнивание. Более простой метод обучения — подача изображений в визуальный кодер.,Введите текстовую визуальную информацию, извлеченную через слой проекции, в LLM.,Пусть LLM сделает прогноз следующего токена,Создание подписей к изображениям. Другой способ — заранее создать несколько инструкций, которые позволят LLM просто описывать информацию об изображении.,во время тренировки,Из которого выборочные инструкции и визуальные элементы объединяются в подсказку для ввода инструкций в LLM.,Позвольте LLM генерировать подписи к изображениям.
3 Выравнивание
После завершения предыдущего этапа,Модель способна приобретать текстовые знания об изображениях и отвечать на человеческие запросы.,Однако остаются проблемы с выработкой последовательных словесных ответов. Нужна дальнейшая тонкая настройка по изображению-текстовой инструкции, чтобы следовать данным,Способствовать лучшему Выравниванию между Моделью и человеческими инструкциями и намерениями.
3.1 Построение набора данных
Наборы данных с открытым исходным кодом, такие как LLaVA, могут использоваться напрямую. Вы также можете использовать самообучение для управления высококачественными мультимодальными моделями, такими как GPT-4/ChatGPT, для создания графически-текстовых инструкций, следующих за данными, которые используются для обучения мультимодальных языковых моделей и воплощения знаний ChatGPT в ваши собственные. модель.
Справочный документ ЛЛа ВА. Сначала попробуйте несколько пар изображение-текст из предварительно обученных данных в качестве исходных данных. Затем вручную создаются различные формы инструкций и аннотируются некоторые изображения — за инструкциями следуют данные в качестве обучающих примеров. Для каждой исходной информации выберите несколько инструкций и данных аннотаций и позвольте GPT-4/ChatGPT использовать информацию об изображении (включая подписи и границы). поля) для генерации соответствующих ответов, создания графически-текстовых инструкций, соответствующих набору данных. Существует три типа построенных форм данных: диалог, подробное описание. такжекомплексное рассуждение. Ниже приведен пример использования GPT-4/ChatGPT для создания диалога с данными.
Сначала мы вручную создадим несколько обучающих примеров, как показано ниже:

Затем,Объедините примеры учебных примеров и инструкции, а также информацию об изображениях вместе в формате командной строки и введите их в GPT-4.,Пусть он сгенерирует соответствующий ответ,Как показано ниже:

3.2 тонкая настройка
Оставьте веса визуального кодировщика неизменными и обновите веса слоя проекции и LLM. Метод обучения заключается в том, чтобы позволить модели сделать следующее. token prediction。Иголкавернообычно Вопросы и ответыданныеиверноразговариватьданные Есть два разныхизметод обучения。
Информацию о методе данных вопросов и ответов см. в документе MiniGPT-4. Введите командную строку в следующем формате, чтобы позволить модели сгенерировать ответ, где ImageFeature представляет собой объект изображения, преобразованный слоем проекции.
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
Диалог данных сначала должен следовать за данными и преобразовать собранные инструкции в следующий формат,Разговор состоит из двух раундов,каждый раундвключатьодининструкцияиотвечать。во время тренировки,Пусть Модель предскажет зеленую часть изображения.

4 отзыва
GPT-4 можно использовать для измерения качества ответов, генерируемых целевой моделью. Пусть целевая Модель такжеGPT-4 Создать на основе вопроса, ограничивающей рамки и заголовка. ответ. Затем объедините вопрос, визуальную информацию (в формате заголовка и ограничительной рамки) такжедваотвечать Войдите вместеGPT-4,позволятьGPT-4Согласно ответуизполезность、Актуальность、точностьидетальждатьаспекты из1приезжать10счет。и требуютGPT-4提供один全面изобъяснять,Чтобы лучше понять целевую модель.
6. Связь с внешними системами
Мультимодальный LLM, обученный на предыдущих этапах, обладает очень мощной способностью понимать ирассуждение.,Но есть еще некоторые недостатки,Например, не имея возможности получить новейшие знания,склонен к выдаче ложных результатов,Трудности с пониманием языков с низким уровнем ресурсов.,Отсутствие математических знаний и так далее,Ограничение, заключающееся в том, что он может использовать только статические знания, можно компенсировать путем подключения внешних инструментов к Модели. Есть два основных метода,Один из них — интеграция внешних инструментов в LLM с помощью подсказок.,Этот метод легко принятьприезжать Введите длинуизпредел。Другой способ — использовать<инструкция,API>данныенабор Есть надзоризтонкая настройкаLLM,Обеспечьте точный вызов широкого набора API.。
1 Метод, основанный на тонкой настройке
1.1
Справочный документ Горилла , через себя instructиз СпособпозволятьGPT-4生成Многоиз<инструкция,API>данныеверноLLMповедение под наблюдениемизтонкая настройка,Обеспечьте точный вызов широкого набора API.,Как показано ниже. в рассуждении,Результатом работы LLM является API, который следует называть,Никакого конкретного процесса реализации не требуется.
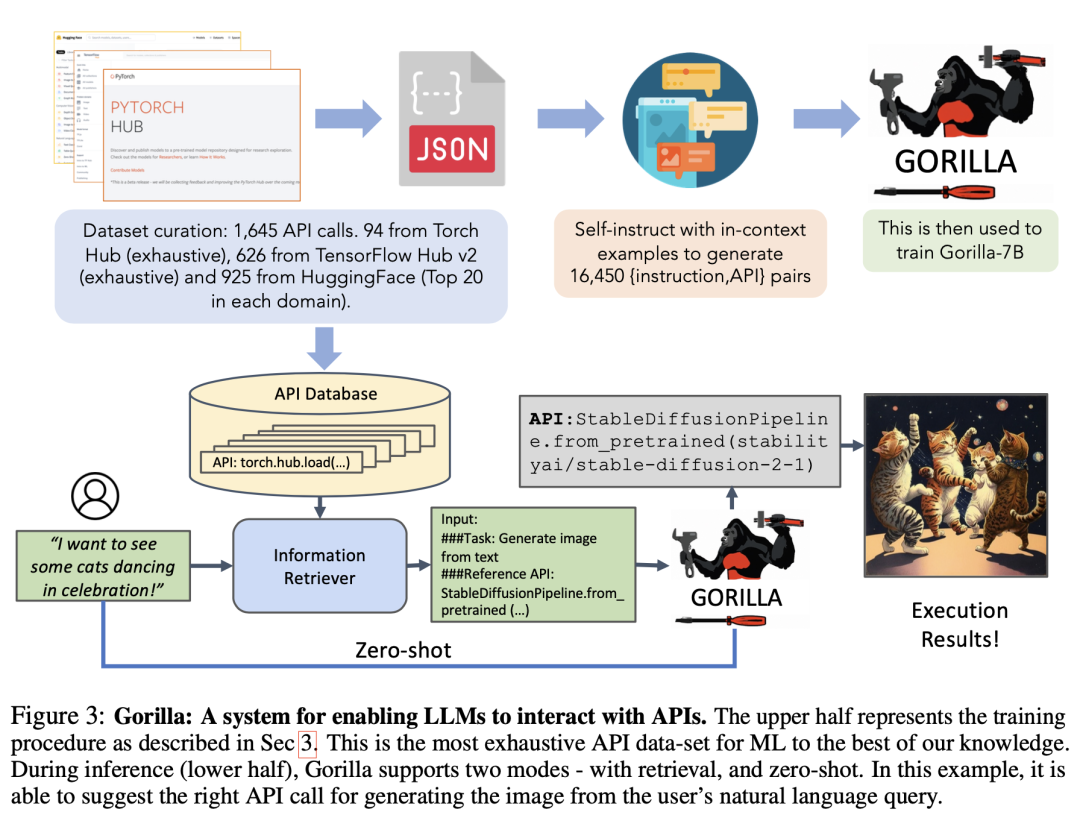
Построение набора данных
Сбор данных API: через HuggingFace, Torch Hub, а такжеTensorFlow Вызовы моделей в Hub фильтруются для сбора нескольких API. Затем преобразуйте карточку модели каждого API в объект json со следующими полями: {domain, framework, functionality, api_name, api_call, api_arguments, environment_requirements, example_code, performance, and описание.}. Инструкция данных Построение: Приведите несколько обучающих примеров с помощью метода контекстного обучения. такжеодин需要вызовизAPIссылкадокумент,намекатьGPT-4Создать вызов для этогоAPIизреальностьинструкция。Затем Воля<инструкция, API>Преобразован в стиль чата пользовательского агента.верноразговаривать,Как показано ниже:

тонкая настройка
Выполнение стандартных инструкций тонкая настройка.
Обзор
Существует несколько правильных вызовов API для одной и той же инструкции, и с помощью модульного тестирования трудно определить, является ли используемый API функционально эквивалентным эталонному API. Один из подходов заключается в сравнении функциональной эквивалентности с собранным набором данных. Чтобы отслеживать, какой API в наборе данных вызывается LLM, применяется стратегия сопоставления дерева AST. Проверяя, является ли AST вызова API-кандидата поддеревом вызова эталонного API, можно определить, какой API используется. , как показано ниже:
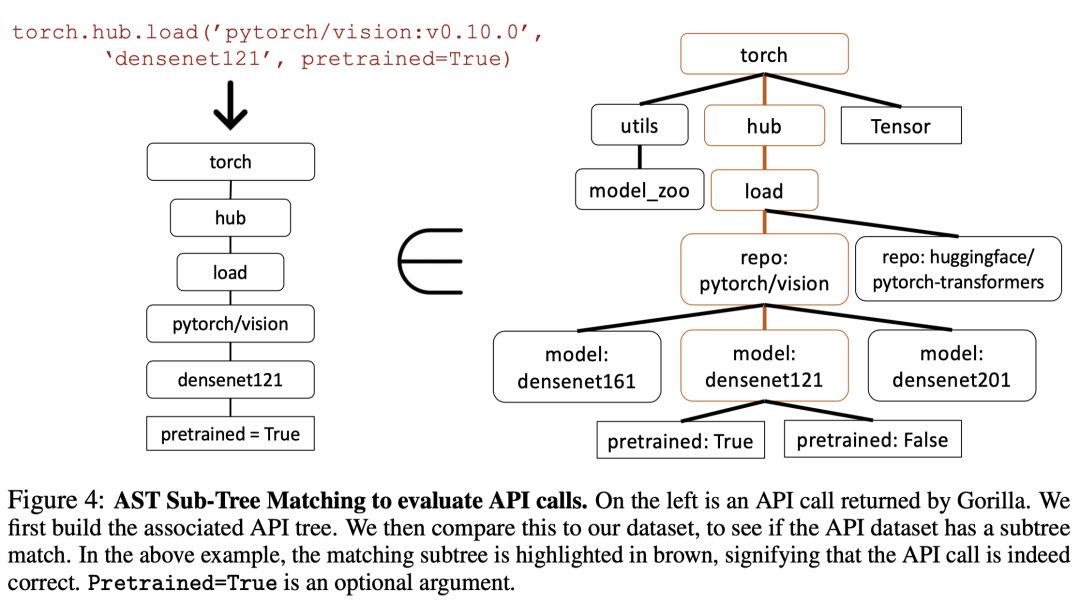
1.2
Справочный документ Toolformer , а не для конкретных задач, пусть LLM самостоятельно решает, какие API вызывать (включая калькулятор, систему вопросов и ответов, поисковую систему, систему перевода и календарь), когда их вызывать и какие параметры передавать Также Как лучше всего включить результаты в будущие прогнозы токенов. Конкретный метод заключается в том, чтобы сначала преобразовать набор данных в виде обычного текста в набор данных с расширенными вызовами API. Это делается в несколько этапов, как показано на рисунке ниже. Во-первых, возможности контекстного обучения GPT-4 и других используются для выборки большого количества потенциальных вызовов API. Затем эти вызовы API выполняются, и, наконец, полученные вызовы API фильтруются, в результате чего в LLM устанавливается расширенный набор данных. Принцип настройки, фильтр - вызов API Также Поможет ли ответ предсказать будущие токены.
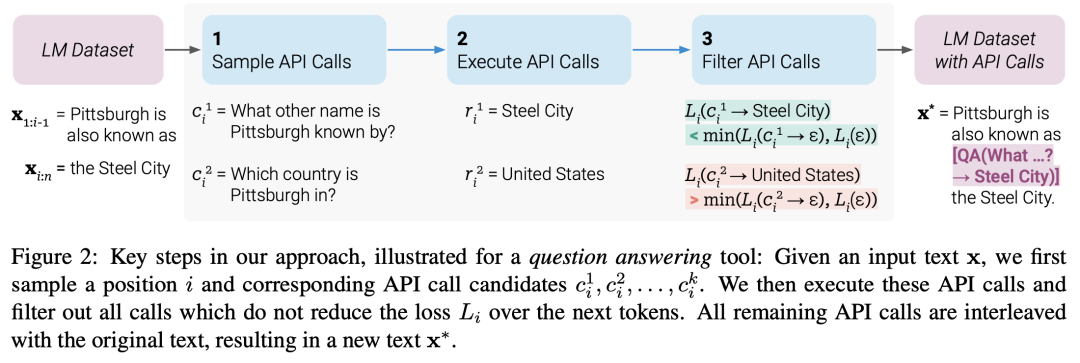
Построение набора данных
Сначала определяются специальные символы «», «» и «→», как показано на рисунке ниже. Благодаря контекстному обучению модель генерирует предложения, содержащие вызовы API. Конкретный метод заключается в выборке каждой позиции входного текста, и если вероятность вывода превышает пороговое значение, она используется в качестве позиции-кандидата. Выберите топ-k позиций из числа кандидатов, выполните звонок и получите ответ. Наконец, если вставка вызова API и ответа в соответствующую позицию входного текста оказывает положительное влияние на последующие токены исходного ввода, сохраните ее.

тонкая настройка
Выполнение стандартных инструкций тонкая настройка.
рассуждение
рассуждениечас,Когда декодирование LLM генерирует символы для вызова API,Остановить декодирование,запускатьAPIвызов Создать ответ, при вставке ответа а также После токена продолжайте декодирование. Чтобы избежать зацикливания генерации модели, API вызывается только один раз для каждого предложения.
1.3 отзыва
Обзор по конкретным последующим задачам.
2 Интегрированные методы
Справочный документ HuggingGPT , формулируя правила и шаблоны подсказок, а также описывая экспертную информацию на естественном языке, LLM могут вызывать экспертов Модель для решения задач. В частности, связав LLM с Hugging Откройте сообщества ML, такие как Face, а затем извлеките описания моделей и объедините их в подсказки. LLM служит мозгом для управления моделями ИИ (например, планирования, составления графиков и сотрудничества), вызывая эти внешние модели для решения конкретных задач. Как показано на рисунке ниже, весь процесс разделен на Четыре этапа, включая планирование. миссии,Выбор модели,Выполнение задачиа также создан ответ.
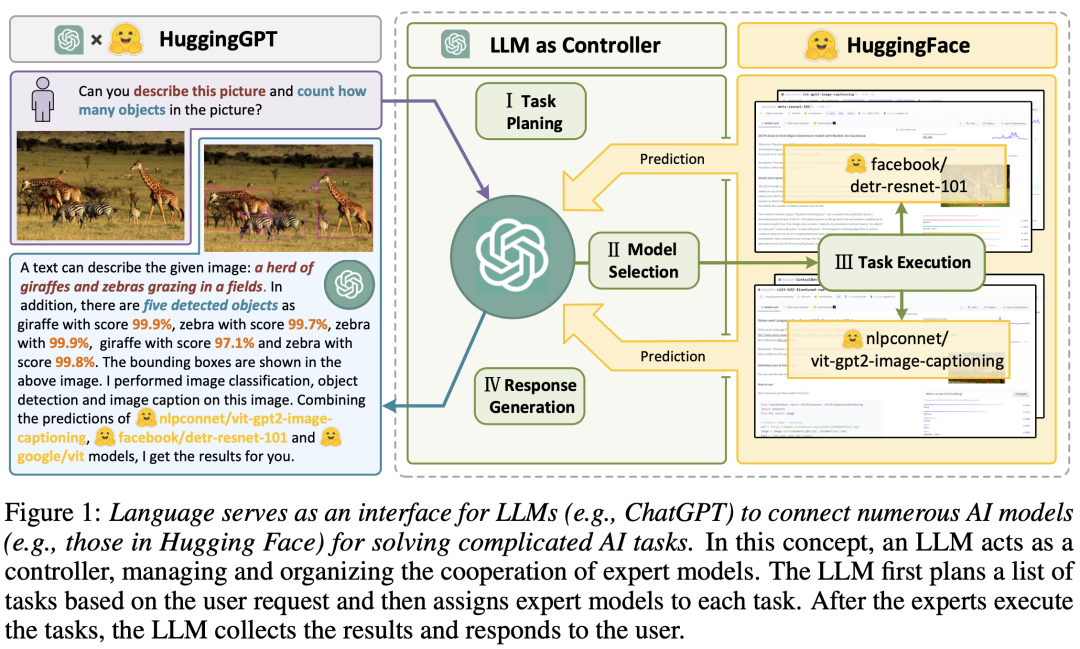
2.1 Планирование миссии
Как показано в Таблице 1,Предлагает LLM анализировать запросы пользователей на основе специального шаблона (состоящего из канонических инструкций и демонстрационного анализа).,Разбейте его на набор структурированных задач.,Включая зависимости задач и порядок выполнения,Чтобы построить их связь.
2.2 Выбор модели
Как показано в таблице 1, после анализа задачи LLM выбирает экспертную модель, размещенную на HuggFace, для выполнения задачи на основе описания модели. Из-за ограничения длины контекста конкретный подход заключается в том, чтобы отфильтровать топ-K наиболее подходящих моделей-кандидатов, записать описания их моделей в подсказки и позволить LLM выбрать наиболее подходящую экспертную модель.
2.3 Выполнение задачи
После выбора модели каждая выбранная модель вызывается и выполняется, а результаты возвращаются в LLM. Поскольку выходные данные обязательных задач генерируются динамически, перед запуском задачи также необходимо динамически указать зависимые ресурсы задачи.
2.4 Создать ответ
Наконец, LLM используется для интеграции всех прогнозов Модели и предоставления пользователю возможности Создать ответ. Как показано в таблице 1, LLM объединяет первые три этапа (планирование миссии、Выбор моделии Выполнение Вся информация из задачи интегрируется в краткое описание этого этапа в виде сгенерированного ответа.

Оригинальная ссылка: https://zhuanlan.zhihu.com/p/643611622



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
