[Обучение большим данным] Анализ и визуализация данных на основе информации из книги Дангдан (8)
Анализ и визуализация данных на основе информации из книги Дангдан
1. Экспериментальная среда
(1) Linux: Ubuntu 16.04. (2)Питон: 3,5 (3) Hadoop: 3.1.3 (4) Spark: 2.4.0 (5) Веб-платформа: flask 1.0.3 (6) Инструмент визуализации: Echarts (7) Инструменты разработки: код Visual Studio.
2. Члены команды и разделение труда
(1) Члены: Линь Хайин, Ван Хуэйлин, Чэнь Цзяи, Го Шинянь.
(2) Разделение труда: xxx отвечает за часть xxxx, xxx отвечает за часть xxxx и xxx отвечает за часть xxxx.
3. Сбор данных
3.1 Описание набора данных
Сканируемый веб-сайт: http://search.dangdang.com/?key=java — информационный веб-сайт книг Данданга по Java. Файл данных: java_books.xlsx. Он содержит 1661 фрагмент данных, связанных с информацией о Java-книгах.
Формат данных:
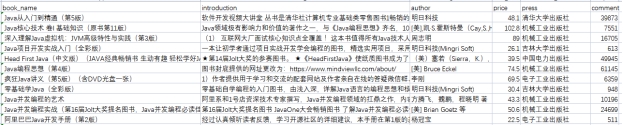
Рисунок 3.1 Формат собираемых данных
Данные включают следующее: (1)book_name: название книги.
(2) Введение: Введение в книгу
(3) автор: автор книги (4) цена: цена книги (юань/книга)
(5) пресса: книжное издательство (6) комментарий: Рецензии на книги
3.2. Процесс сканирования наборов данных и сохранения их в локальных файлах на диске D.
(1) Выберите страницы, которые необходимо просканировать, пройдите и просканируйте их.
(2) Соберите необходимые данные с помощью регулярных выражений.
(3) Преобразуйте просканированные данные в формат dataframe и сохраните их как файл xlsx на диске D.
4. Очистка и предварительная обработка данных
4.1 Данные, извлеченные во время предварительной обработки

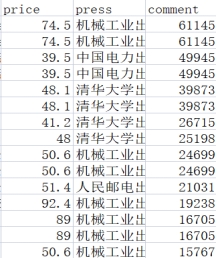
Рисунок 4.1 Формат данных до обработки данных и столбцы проблемных функций
4.2 Формат данных после очистки и предварительной обработки

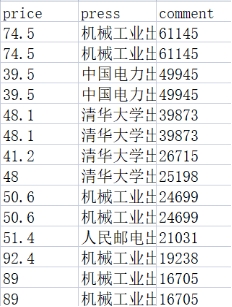
Рисунок 4.2 Формат данных и столбцы признаков после обработки данных
4.3 Процесс очистки и предварительной обработки
(1) Сначала проверьте структуру данных и наличие недостающих данных.
(2) Было обнаружено, что формат данных столбца функции book_name неправильный, поэтому обработка была преобразована в целочисленный тип.
(3) Было обнаружено, что формат данных столбца функции цены был неправильным, поэтому обработка была преобразована в тип с плавающей запятой.
(4) Очистка данных столбца введения контента и удаление выбросов.
(5) Сохраните очищенный и предварительно обработанный набор данных.
5. анализ искровых данных
5.1 Цели анализа данных
(1) Распределение цен продажи книг (наблюдайте за сегментом, в котором обычно концентрируются цены на книги, чтобы получить тенденцию цен на книги)
(2) Статистика количества книг, изданных некоторыми книжными издательствами.

(3) Автор книги публикует книгу (обратите внимание, какой автор опубликовал больше всего книг)
(4) Распределение рецензий на книги (наблюдайте, в каком сегменте обычно концентрируются рецензии на книги, чтобы получить тенденцию рецензий на книги)
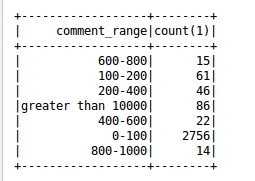
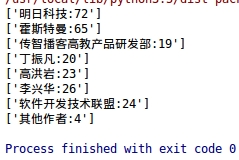
(5) Статистика количества авторов некоторых книг.
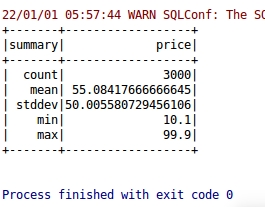
(6) Проанализируйте максимум, минимум, среднее значение, дисперсию и медиану цен.
6. Визуализация данных
Визуализация этого эксперимента основана на mutplotlib.
6.1.Визуальная среда
Используйте jubiter и vscode в anaconda для выполнения визуальных операций. Окончательная структура кода выглядит следующим образом.
6.2 Отображение диаграммы и анализ выводов
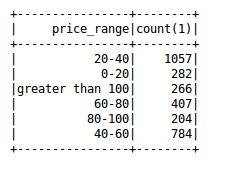
(1) Распределение цен продажи книг (наблюдайте за сегментом, в котором обычно концентрируются цены на книги, чтобы получить тенденцию цен на книги)
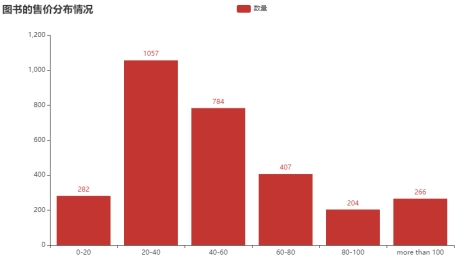
Рисунок 6.2.1 Распределение цен продажи книг
Вывод анализа: Из этой гистограммы мы видим, что цены продажи книг сконцентрированы здесь, в 2060 году. Это показывает, что большинство людей склонны покупать книги по средним ценам. Например, в 2040 году книги по более низким ценам будут продаваться больше. Поскольку цена на 6080 здесь растет, его покупают относительно меньше людей, а объем продаж также снижается. Из этого также можно сделать вывод, что объем продаж 2060 года составляет 1841, тогда как объем продаж 20 и ниже и 60 и выше составляет 1159. Поэтому можно смело предположить, что количество людей со средним доходом в моей стране примерно в 1,6 раза превышает количество людей с низким и высоким доходом.
(2) Статистика количества книг, изданных некоторыми книжными издательствами.
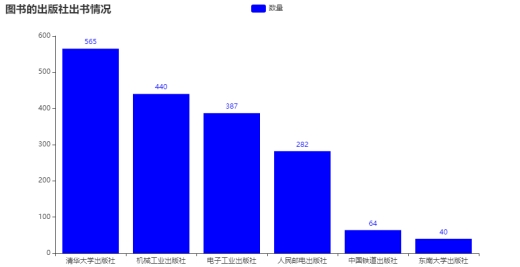
Рисунок 6.2.2 Статистика количества книг, изданных некоторыми книжными издательствами
(3) Автор книги публикует книгу (обратите внимание, какой автор опубликовал больше всего книг)
(4) Распределение рецензий на книги (наблюдайте, в каком сегменте обычно концентрируются рецензии на книги, чтобы получить тенденцию рецензий на книги)
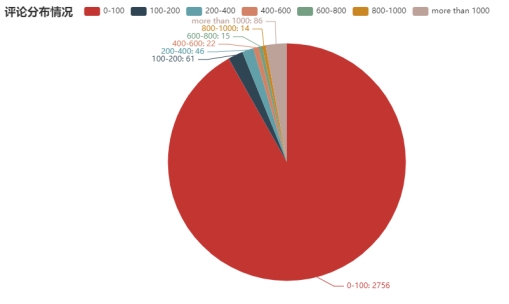
Рисунок 6.2.4 Распределение рецензий на книги
Вывод анализа: на этом графике мы видим, что 92% рецензий на книги имеют оценку от 0 до 100. Другими словами, 92% людей не любят комментировать книги, а оставшиеся несколько человек будут комментировать книги. Итак, мы можем смело предположить, что большинству людей сейчас не нравятся мнения о книгах, которые они прочитали до их выхода.
(5) Статистика количества авторов некоторых книг.руководитьданные Визуализациякартинаанализ таблицы
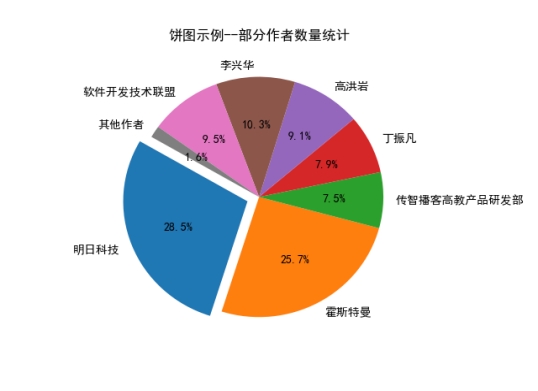
Рисунок 6.2.5 Статистика количества авторов
Вывод анализа: Из этого рисунка мы видим, что около 54% найденных нами авторов написали менее 65 книг (это соответствует анализу данных в части 5), что также иллюстрирует данные. Около 50% авторов написали менее 65 книг. написано не так много книг по Java, то есть менее 50% авторов могут не специализироваться в области Java, а также могут включать и другие области. Большинство книг по Java написаны организациями и авторами, специализирующимися в этой профессии.
(5) Проанализируйте максимум, минимум, среднее значение, дисперсию и медиану цен.
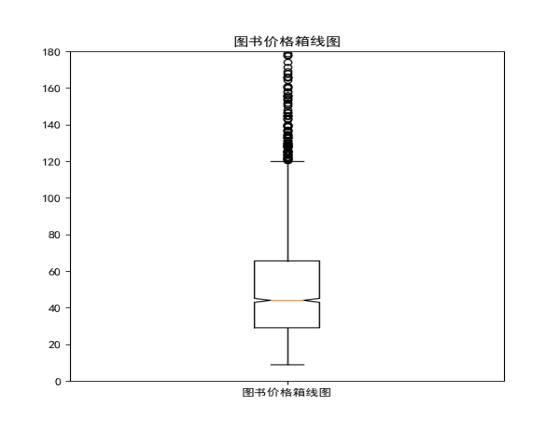
Рисунок 6.2.6 Анализ максимума, минимума, среднего значения, дисперсии и медианы цен
Вывод анализа: на этом рисунке мы видим, что медианное и среднее значение цен на книги составляет около 55 юаней, а отклонение составляет около 50, что доказывает, что колебания цен на книги не очень велики, исходя из максимальных и минимальных значений. Видно, что максимальная цена самых дешевых книг составляет около 10 юаней, а самых дорогих книг — около 120 юаней, поэтому общая средняя цена покупки книги по Java составляет около 55 юаней.
Часть кода: опущена



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
