Обсуждение ARM SoC
Когда производители чипов представляют клиентам свою продукцию, больше всего с точки зрения аппаратного обеспечения обсуждаются функции, производительность, энергопотребление и цена. Функция в основном зависит от того, какие интерфейсы предоставляет чип, например флэш-память, память, PCIe, USB, SATA, Ethernet и т. д. Это также зависит от внутренних вычислительных модулей, таких как устройства с плавающей запятой, декодеры, шифрование и дешифрование, графика. ускорители и сетевые ускорители и т. д. Производительность ЦП — это количество точек, которые может выполнить тестовая программа, например Dhrystone, Coremark, SPEC2000/2006 и т. д. Для различных приложений, таких как мобильные телефоны, также будет учитываться текущая оценка графического процессора, например, сеть также будет учитывать скорость пересылки пакетов; Конечно, клиенты также будут запускать некоторые из своих собственных типичных приложений, чтобы получить более точную оценку производительности. Потребляемая мощность — это сколько ватт энергии потребляет весь чип при запуске определенной программы. Обычно в это время процессор работает на самой высокой частоте, но это не означает, что все транзисторы работают. Из-за наличия схемы управления питанием и синхронизации неиспользуемая логика и блоки встроенной памяти не потребляют энергию полностью. . Когда я вижу максимальное энергопотребление процессоров, указанное производителями чипов, они обычно используют Dhrystone. У этой программы есть особая функция: она работает только с кешем первого уровня и не обращается к кешу или памяти второго уровня. Этот результат на самом деле не является истинным максимальным энергопотреблением. Но, как показывает реальный опыт, ни одно приложение не может заставить процессор потреблять больше энергии, поэтому нет ничего плохого в измерении максимального энергопотребления таким способом. Разумеется, общее энергопотребление чипа должно также включать в себя различные ускорители и интерфейсы, особенно модули, которые будут использоваться.
При проектировании SoC производительность, энергопотребление и цена конвертируются в PPA. Что такое ППА? По сути, это производительность, энергопотребление и площадь. Среди них производительность имеет два значения. В интерфейсном дизайне это означает, сколько стандартных точек тестовой программы можно выполнить за герц. При проектировании процессора есть представление о том, сколько этапов конвейера существует. Вообще говоря, чем больше этапов конвейера, тем выше максимальная частота, на которой может работать чип. Это должен знать каждый. Но это не значит, что чем выше частота, тем выше производительность. Это во многом связано с архитектурой процессора. Типичным противоположным примером является процессор Intel Pentium 4, который имеет более 30 стадий конвейера и максимальную частоту до 3G Гц. Однако, поскольку конвейер слишком длинный, если предсказание инструкций неверно, инструкции придется выполнять повторно. повторно запустить десятки этапов конвейера, что очень затратно. А его прогнозирование инструкций в значительной степени зависело от компилятора при оптимизации. В результате компилятор не успевал за ним, что приводило к низкой общей производительности. Видите ли, частота процессора MIPS или PowerPC невысока, но производительность на герц относительно хорошая, и общая производительность будет улучшена. Поэтому, оценивая производительность, смотрите на общую оценку, а не на оценку за Гц. Некоторое время назад компания Loongson воспользовалась этой лазейкой в своем продвижении, заявив, что она может догнать Xeon по герцу, но может работать только на частоте более 1 ГГц, в то время как 16-ядерный Xeon может достигать частоты почти 3 ГГц.
Другое значение производительности — это частота, которая рассматривается с точки зрения серверной части. Обычно людей, работающих на серверной стороне, не волнует, сколько баллов они могут получить за 1 Гц, их волнует только то, на скольких частотах может работать чип. Чем выше частота, тем выше общая производительность при определенном количестве баллов на Гц. Обратите внимание, что для тех программ, которые работают на кэше L1, показатель процессора на Гц не меняется с частотой. Конечно, если принять во внимание многоуровневые кэши, шины и периферийные интерфейсы, она, конечно, не увеличивается линейно с частотой. В будущем я буду постепенно расширять тему проблем производительности на уровне системы.
Итак, какие факторы будут влиять на частоту? Даже если рассматривать это только с точки зрения серверной части, существует множество ответов. Я не занимаюсь серверной частью и производственным процессом, поэтому могу записывать только то, что слышу понаслышке, исключительно для справки.
Во-первых, на это влияет мастерство. Сейчас существует всего несколько передовых заводов по производству полупроводников, включая Intel, TSMC, Samsung, UMC и GlobalFoundries. Возьмем, к примеру, TSMC. В настоящее время она обеспечивает 16-нанометровый процесс, который разделен на множество мелких узлов, таких как FFLL++ и FFC. Каждый небольшой узел имеет свои характеристики: некоторые могут работать на более высоких частотах, некоторые имеют низкое энергопотребление, а некоторые имеют низкую стоимость. В разных процессах максимальная частота, на которой может работать чип, различна, а также различаются энергопотребление и площадь.
Во-вторых, на это влияет серверная библиотека. В процессе TSMC абстрагирует параметры транзисторов и создаст комплект разработки физического уровня PDK, который будет предоставлен производителям инструментов EDA, производителям IP и производителям микросхем. Серверные инженеры этих производителей будут использовать этот комплект разработки физического уровня для создания своих собственных физических библиотек. Физическая библиотека обычно состоит из двух основных частей: логики и памяти. В зависимости от длины канала транзистора элементарная ячейка будет иметь разные характеристики и подходить для разных целей. Как рационально использовать ячейки этих библиотек с разными характеристиками в разных модулях фронтенд-дизайна — большой вопрос. Вообще говоря, чем короче длина канала, тем короче расстояние дрейфа электрона и тем выше частота, на которой он может работать. Однако чем выше частота, тем больше потребляемая мощность, и она увеличивается в геометрической прогрессии. Помимо ячейки, существует также термин 9T/12T. Здесь T означает дорожку, которая обозначает высоту ячейки. Чем больше Т, тем больше ток, тем легче добиться высокой частоты и больше соответствующая площадь. Еще одним настраиваемым параметром является порог напряжения, который определяет порог напряжения затвора. Чем ниже порог, тем больше утечка и тем выше может быть частота.
Далее, есть влияние компоновки и маршрутизации. Внутренняя часть чипа также нуждается в проводке, как и материнская плата. У каждого слоя есть коэффициент использования. Чем меньше общая площадь, тем выше коэффициент использования, но тем сложнее провести проводку. После задания некоторых начальных и ограничивающих условий программное обеспечение EDA продолжит расчет самостоятельно и, наконец, выдаст допустимую частоту и площадь.
Опять же, под влиянием совместного дизайна внешнего и внутреннего интерфейса. Например, для определенной операции доступа к памяти, если вы знаете, сколько времени потратит процессор и какие ресурсы будут использованы, вы можете закрыть свободный блок памяти для экономии энергии. Для этого могут существовать тысячи методов, и вы не узнаете об этом, пока не спроектируете процессор самостоятельно, даже если у вас есть код RTL.
Далее находится динамическое масштабирование напряжения и частоты DVFS. Здесь необходимо ввести понятие энергопотребления. Энергопотребление чипа разделено на две части: динамическое и статическое. Статическое вызвано утечкой транзистора, а его размер зависит от процесса чипа, количества транзисторов, а динамическое вызвано переключением, поэтому оно связано с количеством. транзисторов, частоты и напряжения. Конкретные формулы перечислять не буду, они есть в сети. Метод управления динамическим энергопотреблением – это тактирование. По мере уменьшения частоты динамическое энергопотребление естественным образом снижается. Метод контроля статического энергопотребления — регулирование мощности. Если вы отключите источник питания, как статическое, так и динамическое энергопотребление исчезнет. Напряжение также можно уменьшить, поэтому динамическое и статическое энергопотребление, естественно, будут небольшими. Но напряжение нельзя уменьшать бесконечно, иначе электроны не смогут дрейфовать и транзистор не будет работать. Более того, транзисторы, работающие на разных частотах, требуют разного напряжения. Если взять для примера 16 нм, оно может меняться от 0,9 В до 0,72 В, а может стать 1 В или выше. Не стоит недооценивать это небольшое изменение напряжения. Вы должны знать, что изменение динамического энергопотребления связано с напряжением в 2-3 степени. 1 В и 0,7 В, разница напряжения составляет 50%, а динамическое энергопотребление может отличаться в 3,4 раза. Данные, которые я видел, показывают, что при частоте ниже 500 МГц динамическое энергопотребление процессора меньше статического энергопотребления. Когда оно достигает 3 ГГц, оно намного превышает статическое энергопотребление.
Далее имеется программное управление питанием для контроля энергопотребления. Разработчик чипа объединяет стробирование тактового сигнала и стробирование мощности каждого большого модуля для формирования различных состояний сна. Программное обеспечение может динамически сообщать процессору, что каждый модуль переходит в другое состояние сна в зависимости от температуры и выполняемых задач, чтобы определить, когда будет выполнена задача. больше не требуется. Уменьшите энергопотребление, когда занято. Это еще одна большая тема, о которой мы поговорим позже.
Из вышесказанного мы видим, что энергопотребление и производительность на самом деле объединены. Разработчики микросхем могут использовать различные процессы и физические библиотеки для проектирования максимальной рабочей частоты, а затем программное обеспечение управляет динамической рабочей частотой и энергопотреблением чипа.
А что насчет района? На самом деле они также дополняют друг друга. Поскольку для разной логики, памяти и проводки выбраны разные ячейки физической библиотеки и разные дорожки, результирующая область чипа будет разной. Вообще говоря, чем больше высокочастотных чипов необходимо запустить, тем больше требуемая площадь. Если частоту увеличить вдвое, площадь может отличаться на десятки процентов. Не стоит недооценивать десятки процентов. Для транзисторов площадь — это стоимость. Общая площадь пластины определена, и цена определена. Чем меньше площадь одного чипа, тем ниже стоимость. процент доходности также выше.
Помимо производственных затрат, затраты на чипы также складываются из лицензионных сборов, платы за инструменты, платы за съемку ленты, эксплуатационных расходов и т. д. Обычно сложные чипы, такие как процессоры для мобильных телефонов, невозможно произвести без десятков миллионов долларов. Даже если он будет изготовлен и миллионы штук не проданы, это однозначно будет убыток.
Наконец, я хотел бы упомянуть дизайн больших и малых ядер ARM. Его первоначальная цель заключалась в разработке двух наборов ядер. Маленькое ядро имеет низкую производительность на Гц, имеет небольшую площадь и работает на низких частотах; большое ядро имеет высокую производительность на Гц, имеет большую площадь и работает на высоких частотах; . При выполнении простых задач большое ядро выключено, маленькое ядро работает на низкой частоте, динамическое энергопотребление низкое, статическое энергопотребление преобладает, а из-за небольшой площади общее энергопотребление ниже. Большие ядра выполняют сложные задачи на высоких частотах. По сравнению с простой регулировкой напряжения и частоты в x86 немного увеличивает площадь низкочастотных маленьких ядер, но по сравнению с площадью всего чипа на самом деле ненамного больше. Так почему бы не позволить маленьким ядрам выполнять сложные задачи на высоких частотах? Теоретически из-за низкой производительности на Гц маленькое ядро должно работать на более высокой частоте, чем большое ядро для той же задачи, что означает более высокое напряжение. В это время преобладает динамическое энергопотребление, имеющее кубическую зависимость от напряжения. Итоговое энергопотребление будет намного выше, чем у больших ядер. Кроме того, как мы объясняли ранее, если маленькое ядро работает на высокой частоте, площадь значительно увеличится и может быть больше, чем у большого ядра. Мы видим изнутри, что есть точка баланса. Эту точку баланса найти непросто. Возьмем, к примеру, A53/A57 на 28-нм техпроцессе. Когда они работают на частоте 1,2 ГГц, энергопотребление может быть в два раза выше, но производительность отличается только на 50%. Точка баланса может составлять 2 ГГц. Фактически, во многих чипах мобильных телефонов используется один и тот же процессор как для больших, так и для малых ядер, работающий на разных высоких и низких частотах.
Таким образом, разработка чипов во многом зависит от баланса. Факторы влияния, или подводные камни, исходят из всех аспектов: поставщиков интеллектуальной собственности, фабрик, определений рынка и инженерных групп. Вода глубокая, а яма огромная. Идеального скола не бывает, есть идеальный баланс. На данный момент Apple является типичным примером. Частота его процессора не очень высока, но его одноядерный результат в Geekbench на целых 75% выше, чем у HiSilicon A73, что близко к производительности процессоров Intel для настольных ПК. Почему? Одна из причин в том, что он использует шесть пусков, в то время как у А73 только двойные пуски, а конвейер в три раза шире. Здесь Apple пожертвовала большим количеством недвижимости ради производительности. Конечно, увеличение ширины запуска в три раза не означает увеличение производительности в три раза. Из-за корреляции данных преимущества ширины запуска уменьшаются. Кроме того, Apple использует полные 6 МБ кэш-памяти, тогда как на других чипах мобильных телефонов это число обычно составляет 1 МБ. Я провел тесты для некоторых стандартных тестов, таких как SpecInt2000/2006, улучшение производительности, вызванное кэшем L2 со 128 КБ до 256 КБ, составляет всего около 7%, тогда как улучшение, полученное с 256 КБ до 1 МБ, еще меньше, но область кэша равна 4. раз. Увеличение площади также приводит к увеличению статического энергопотребления. Однако, поскольку экосистема Apple является собственной, она ввела сложное управление питанием, напряжением и тактовой частотой и начала оптимизировать его на программном уровне, чтобы очень хорошо контролировать общее энергопотребление. Но только Apple может это сделать. Вообще говоря, компании никогда не пойдут по пути Apple, обменивая в 2-3 раза большую площадь на производительность и энергопотребление. В этом случае валовая прибыль будет слишком низкой. Без гарантии общей высокой прибыли от мобильных телефонов и без единой системы программного обеспечения для контроля энергопотребления результатом будет смерть.
Далее давайте начнем обсуждение SoC с простого вопроса доступа к памяти. Как процессор обращается к памяти? Простой ответ заключается в том, что ЦП выполняет инструкцию доступа к памяти и отправляет запросы на чтение и запись в блок управления памятью. Блок управления памятью выполняет виртуальное и реальное преобразование и отправляет команды на шину. Шина передает команду контроллеру памяти, и контроллер памяти снова транслирует адрес и обращается к соответствующим частицам памяти. После этого данные чтения или подтверждения записи возвращаются по исходному пути. Чтобы усложнить задачу, в него вставляются многоуровневые кэши. При промахе каждого уровня кэша доступ наконец достигает гранулы памяти.
Теперь, когда мы знаем полный путь, мы начинаем изучать, что представляет собой аппаратное обеспечение на каждом этапе и как в нем передаются инструкции чтения и записи. Чтобы понять аппаратное обеспечение, сначала давайте поговорим о процессоре. Базовая структура процессора не сложна и обычно делится на пять этапов: выборка инструкций, декодирование, выдача, выполнение и обратная запись. Когда мы говорим о доступе к памяти, мы имеем в виду доступ к данным, а не выборку команд. В инструкциях доступа к данным на первых трех шагах нет ничего особенного. На четвертом этапе они будут отправлены в модуль доступа и будут ожидать завершения. Когда инструкция находится в блоке доступа, возникают некоторые интересные проблемы.
Первый вопрос: в каком состоянии для инструкций чтения процессор ожидает возврата данных из кэша или памяти? Стоит ли ждать там или продолжать выполнять другие инструкции? Вообще говоря, если процессор выполняется не по порядку, он может выполнять последующие инструкции. Если он выполняется последовательно, он войдет в состояние паузы до тех пор, пока не будут возвращены считанные данные. Конечно, это не абсолютно. Прежде чем приводить контрпример, мы должны сначала уточнить, что такое внеочередное выполнение. Выполнение вне порядка означает, что для данной последовательности инструкций процессор для повышения эффективности находит инструкции, которые на самом деле не зависят от данных, и позволяет им выполняться параллельно. Однако результаты выполнения инструкций должны быть последовательными при обратной записи в регистр. Другими словами, даже если инструкция выполняется первой, результат ее работы записывается обратно в последний регистр в порядке следования инструкций. Это отличается от выполнения вне очереди, которое понимают многие программисты. Я обнаружил, что при отладке проблем с программным обеспечением некоторые люди чувствуют, что используется процессор, находящийся в неисправном состоянии, что может привести к тому, что последующий код будет выполняться первым, что сделает отладку невозможной. Они перепутали два понятия, а именно последовательность доступа к памяти и последовательность завершения инструкций. Обычные арифметические инструкции выполняются только внутри процессора, поэтому вы видите порядок обратной записи. Для инструкций доступа к памяти инструкция генерирует запрос на чтение и отправляет его за пределы процессора. Порядок, который вы видите, — это порядок доступа к памяти. Для процессоров с нарушением порядка одновременно может быть несколько запросов, и их порядок нарушается и не соответствует порядку исходных инструкций. Но в это время эти запросы на чтение, отправленные во внешнюю среду, не получили возвращаемых результатов, и инструкции не были завершены. Следовательно, это не нарушает принцип внеочередного выполнения и последовательного завершения. Если есть две инструкции чтения до и после, корреляция данных отсутствует. Даже если более поздние считанные данные возвращаются первыми, их результат не может быть сначала записан обратно в последний регистр, а должен дождаться завершения предыдущего.
Для процессора, который выполняется последовательно, также есть две инструкции чтения. Обычно перед выполнением второй инструкции необходимо дождаться завершения предыдущей, поэтому то, что вы видите за пределами процессора, — это последовательный доступ. Однако есть исключения. Например, когда чтение и запись выполняются одновременно, поскольку инструкции чтения и записи фактически выполняются по двум путям, вы можете увидеть, что они существуют одновременно. Этот вопрос будет расширен после представления более подробной структуры оборудования.
Также на последовательном процессоре даже для двух инструкций чтения может быть одновременно два внешних запроса. Например, Cortex-A7, для последовательных инструкций чтения, когда предыдущее чтение пропускает кеш первого уровня, а кеш или память следующего уровня извлекает данные, может быть выполнена вторая инструкция чтения. Следовательно, беспорядок и порядок не влияют напрямую на порядок выполнения инструкций. Разница между ними заключается в том, что при нарушении порядка требуются дополнительные буферы и логические блоки (называемые буферами повторного порядка) для расчета и хранения зависимостей между инструкциями и статусом выполнения. Последовательные процессоры не имеют буфера переупорядочения или очень простого. Эта дополнительная область немаленькая. Судя по тому, что я видел, она может занимать 40% ядра процессора. Более высокая степень параллелизма, которую они обеспечивают, не обязательно приведет к повышению производительности на 40%. Поскольку написанная нами однопоточная программа имеет множество зависимостей данных, параллелизм инструкций ограничен. Независимо от размера буфера переупорядочения, он не может решить реальные зависимости данных. Поэтому последовательное выполнение по-прежнему используется для процессоров, чувствительных к энергопотреблению.
Еще следует отметить, что в процессоре с последовательным выполнением две или более инструкций могут обрабатываться одновременно на этапах выборки, декодирования и выдачи инструкций. Например, инструкции чтения и инструкции операций без зависимостей могут быть выданы разным исполнительным блокам одновременно и начать выполнение одновременно. Но завершение еще в порядке.
Однако на некоторых процессорах ARM, таких как Cortex-A53, векторные инструкции или инструкции шифрования и дешифрования могут выполняться не по порядку, и между результатами таких операций нет зависимости данных. Пожалуйста, обратите на это пристальное внимание.
Давайте еще раз посмотрим на инструкции по написанию. Существует большая разница между записью и чтением, то есть инструкции записи не нужно ждать, пока данные будут записаны в кэш или память, прежде чем она может быть завершена. Записанные данные пойдут в буфер, называемый буфером хранилища, который расположен перед кэшем первого уровня. Пока он не заполнен, процессор может сразу перейти вниз, не останавливаясь и не ожидая. Таким образом, для последовательных инструкций записи, независимо от того, выполняется процессор по порядку или нет, можно увидеть несколько запросов на запись, висящих на шине процессора одновременно. В то же время, поскольку процессору не приходится ждать результата, как инструкции чтения, он может отправлять больше запросов на запись в единицу времени, поэтому мы видим, что пропускная способность записи обычно больше, чем пропускная способность чтения.
Упомянутые выше доступы для чтения и записи доступны только при включенном кэше, а случай его отключения будет рассмотрен позже.
Для нескольких запросов, которые существуют одновременно, есть существительное, определяющее их, называемое выдающимся. transaction,Сокращенно ОТ. это происходит с задержкой,Составляет наше описание производительности. Концепция задержки,В разных областях существуют разные определения. в сети,Задержка в сети представляет собой один пакет данных, исходящий локально.,После переключения и маршрутизации,Достичь партнера,затем вернись,Общее время, проведенное в нем. на процессоре,Можно также сказать, что задержка чтения и записи — это инструкция, выданная,Пропустить кэш,автобус,Память контроллер,Памятьчастицы,Затем время, необходимое для возврата. но,чаще,Задержка доступа к памяти, о которой мы говорим, возникает после выполнения большого количества инструкций чтения и записи.,Рассчитано среднее время доступа. Разница здесь в том,,Когда ОТ=1,Общая задержка просто суммируется。когдаOT>1,Поскольку одновременно имеется два параллельных доступа к памяти,Общее время обычно меньше накопленного времени.,А может быть гораздо меньше. Средняя задержка, полученная в это время,Также известна как задержка доступа к памяти.,и используется чаще. будь точнее,Благодаря наличию многоступенчатых трубопроводов,Предположим, что каждый этап конвейера представляет собой тактовый цикл.,Средняя задержка доступа к кэшу первого уровня составляет фактически один цикл, а для последующего второго уровня.,Кэш 3 уровня и Память,Что касается чтения инструкций,Задержка начинается с момента запуска инструкции (примечание,Не время от выборки) до окончательного возврата данных.,Поскольку процессор ожидает на этапе выполнения,Конвейер не работает. еслиOT=2, Тогда время может быть сокращено почти вдвое.。OT>1Преимущества отражены здесь。когда Однако,Это также имеет свою цену,Хранение статуса невыполненных запросов на чтение требует дополнительной буферизации.,Процессору также может потребоваться поддержка выполнения вне очереди.,что приводит к дальнейшему увеличению площади и энергопотребления. Для написания инструкций,Пока буфер хранилища не заполнен,Еще один такт. конечно,Если определенный такт в конвейере превышает один такт,Средняя задержка будет зависеть от самого медленного времени. Чтение второго уровня,Кэш 3 уровня и Памятькогда,Мы можем думать об ожидании возвращения как о такте,Тогда вы, естественно, сможете понять задержку в это время. таким образом,Мы можем получить задержку и задержку доступа к памяти каждого уровня.
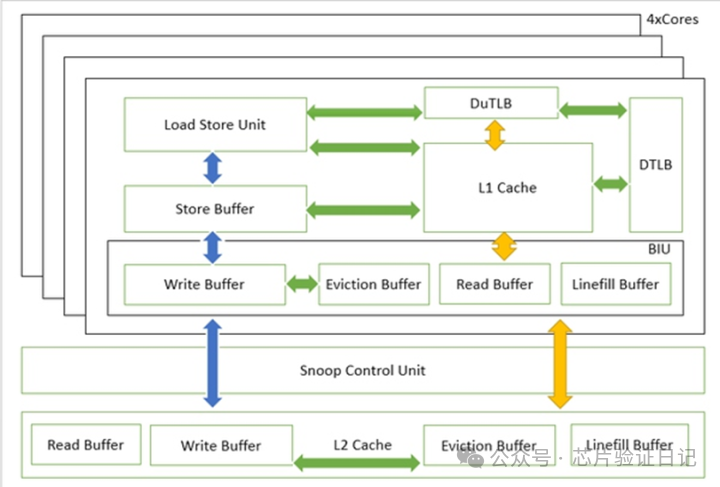
На рисунке выше показаны блоки, через которые проходят инструкции чтения и записи. Кратко опишу процесс:
Когда команда записи исходит от блока доступа LSU, она сначала проходит через небольшую очередь сохранения, а затем поступает в буфер сохранения. После этого инструкция записи может быть завершена, и процессору не придется ждать. Storebuffer обычно состоит из нескольких слотов по 8–16 байт. Он проверяет адрес каждых полученных данных, объединяет их, если их можно объединить, а затем отправляет запрос к кэшу первого уровня справа для выделения строки кэша. Чтобы хранить данные до получения ответа, это называется writeallocate. Конечно, процесс ожидания может продолжать объединять те же данные строки кэша. Если данные не кэшируются, то он рассчитает время ожидания, затем объединит данные и отправит их в буфер записи Writebuffer в блоке интерфейса шины BIU. Перед отправкой данных в кеш второго уровня буфер записи проходит через блок управления прослушиванием, чтобы обеспечить согласованность кешей четырех ядер. Процесс аналогичен описанию автобуса, поэтому не буду вдаваться в подробности.
Когда инструкция чтения исходит от модуля доступа LSU, независимо от того, является ли она кэшируемой или нет, она проходит через кэш первого уровня. Если он попадает, данные возвращаются напрямую, и инструкция чтения завершается. В случае промаха некэшируемый запрос отправляется непосредственно в буфер чтения. Если он кэшируемый, то кэш первого уровня должен выделить строку кэша, записать исходные данные в буфер вытеснения буфера замены и в то же время инициировать заполнение строки кэша и отправить их в буфер заполнения строки. Evictionbuffer отправит свой запрос на запись в Writebuffer в BIU и отправит его в интерфейс следующего уровня вместе с данными, отправленными из Store Buffer. Затем эти запросы отправляются в кэш второго уровня после проверки на согласованность блоком управления мониторингом. Конечно, возможно, что прочитанные данные существуют в кэше первого уровня других процессоров, поэтому просто хватайте их прямо оттуда.
Процесс не сложен, но программистов беспокоит, где находится узкое место этого процесса и как оно влияет на производительность чтения и записи. Мы уже объясняли, что для записи, поскольку она может быть завершена немедленно, узкое место не исходит от блока доступа для чтения, поскольку процессор будет ждать, нам нужно найти, сколько ОТ можно выдать на каждом шаге чтения; путь, каждый раз Какова длина данных каждого OT.
В качестве примера возьмем Cortex-A7. Он имеет буфер заполнения строк размером 2x32 байта и поддерживает условный промах (соседние инструкции чтения должны быть в пределах 3 тактов), то есть OT равен не более 2, а его значение равно 2. строка кэша данных. Длина составляет 64 байта, поэтому каждый OT равен половине длины строки кэша. Для чтения из кэша меня также интересуют два данных, а именно evictionbuffer и Write buffer, которые всегда сопровождаются заполнением строки. В A7 имеется 64-байтовый буфер вытеснения и буфер записи. При этих условиях я могу сказать, что для инструкций непрерывного чтения OT, которого я могу достичь, равен 2, а скорость заполнения строки такая же, как и у вытеснения и записи буфера, потому что 2x32 = 64 байта.
Верен ли этот вывод? Вы можете это выяснить, написав небольшую программу и протестировав ее. Мы можем отключить кеш второго уровня, сохранить кеш первого уровня, а затем использовать следующие инструкции для чтения большей области памяти. Все адреса выровнены по строкам кэша. Не буду вдаваться в суть выравнивания или даже пересечения границы строки кэша, превратит одну операцию в две, что определенно будет медленным. Псевдокод выглядит следующим образом:
loop
load R0, addr+0
load R0, addr+4
load R0, addr+8
load R0, addr+12
addr=addr+16
Здесь данные непрерывно считываются с помощью инструкций чтения. Я проверил процент промахов кэша следующего уровня с помощью встроенного счетчика производительности процессора, и он составил чуть более 6%. Это как раз соотношение 4/64 байт. Обратите внимание, что для новой строки кэша первые четыре байта всегда являются промахом, а следующие 15 четырех байтов всегда являются попаданием. Конечно, конкретная задержка и пропускная способность также связаны с шиной и контроллером памяти и могут быть просто проверены только через частоту попаданий.
Для некоторых процессоров они выполняются в строгом порядке и не существует механизма промаха, такого как A7, поэтому OT=1. Тот же эксперимент я проделал на Cortex-R5, длина строки его кэша — 32 байта, а 2xLinefillbuffer — 32 байта. Показатель попадания, полученный в тесте, составляет чуть более 12%. Это также полностью соответствует смете.
Но почему R5 проектирует два Linefillbuffer длиной по 32 байта? Поскольку его OT=1, не будет ли дополнительный бесполезен? Фактически, его можно использовать, и способ заключается в использовании инструкции предварительной выборки PLD. Особенностью инструкции предварительной выборки является то, что после ее выполнения процессору не приходится ждать, а запрос на чтение также будет отправлен в кэш первого уровня. В следующий раз, когда придет инструкция чтения для чтения той же строки кэша, вы можете обнаружить, что данные уже там. Его адрес должен быть выровнен по строке кэша. Таким образом, чтение также может использовать второй буфер заполнения строк, как и запись.
Давайте воспользуемся этим в предыдущем примере:
loop
PLD addr+32
load R0,addr+0;...;load R0, addr+28;
load R0,addr+32;...;load R0, addr+60;
addr=addr+64
PLD предварительно считывает адрес второй строки инструкций чтения. Тест показал, что процент промахов в это время все еще составлял 6%. Это также соответствует оценке, поскольку команда чтения второй строки всегда попадает, а процент промахов первой строки составляет 4/32, что в среднем составляет 6%. Пропускная способность теста увеличилась более чем на 80%. Просто глядя на ОТ=2, оно должно увеличиться на 100%, но на самом деле оно не может быть таким идеальным, и 80% это понятно.
Существует еще один механизм, позволяющий увеличить размер OT, — это аппаратная предварительная выборка из кэша. Когда программа обращается к последовательным или обычным адресам, кеш автоматически обнаруживает этот шаблон и заранее извлекает данные. Этот метод также не занимает процессорное время, но также использует буфер заполнения строки, буфер вытеснения и буфер записи. Поэтому, если это правило не будет найдено хорошо, это снизит эффективность.
Теперь, когда вы закончили читать, что насчет письма? Кэшируемые записи, если кеш промахивается, запускают writeallocate, что затем вызывает Linefill и вытеснение, то есть операции чтения. Многие программисты, возможно, не подумали об этом. Когда происходят записи по последовательным адресам, они сопровождаются серией операций чтения строк кэша. Иногда эти чтения не имеют смысла. Например, в функции memset данные могут быть записаны непосредственно в кеш или память следующего уровня без дополнительного чтения. Поэтому в большинстве процессоров ARM реализован механизм, который позволяет буферу хранилища отправлять данные не в кэш первого уровня при обнаружении записи по последовательному адресу, а непосредственно в буфер записи. Более того, в это время легче выполнять слияние, формировать пакетную запись и повышать эффективность. На Cortex-A7 это называется режимом выделения чтения, что означает, что выделение выделения отменяется. На некоторых процессорах это называется потоковым режимом. Многие запущенные тесты запускают этот режим, поэтому он может иметь преимущество при подсчете результатов.
Однако переход в потоковый режим не означает, что адреса, полученные контроллером памяти, являются последовательными. Представьте, что когда мы тестируем memcpy, нам сначала нужно прочитать данные с адреса источника. То, что отправляется, является непрерывным адресом и основано на строках кэша. Через некоторое время кэш израсходуется, затем появляется выселение, причем случайное или псевдослучайное, а адреса выписываются нерегулярно. Это прерывает исходный адрес непрерывного чтения. Если снова посмотреть на запись, то при записи данных по адресу назначения, если будет найден адрес непрерывной записи, это не приведет к дополнительному заполнению строки и вытеснению. Это хорошая вещь. Однако данные, записываемые непосредственно в кэш или память следующего уровня, скорее всего, не будут полной пакетной записью в кэш, поскольку буфер хранения также постоянно взаимодействует с буфером записи, а буфер записи также принимает запросы из буфера вытеснения на этапе в то же время. В результате текст разбивается на небольшие абзацы. Адреса записи этих маленьких блоков, адреса записи вытеснения и адреса чтения смешиваются, что увеличивает нагрузку на шину и контроллер памяти. Они должны использовать соответствующие алгоритмы и параметры для более быстрого объединения данных и записи их в частицы памяти.
Однако дело еще не закончилось. Мы только что упомянули, что режим потоковой передачи срабатывает, и из него также можно выйти. Условием выхода обычно является обнаружение некэшируемого строкового пакета записей. На это может влиять время отклика буфера записи. После выхода распределение записи восстанавливается, что делает адреса чтения и записи более прерывистыми, что затрудняет оптимизацию контроллера памяти, еще больше увеличивает задержку и обратную связь с процессором, что затрудняет пребывание в потоковом режиме. .
Кроме того, на самом деле существует проблема с потоковым режимом, то есть он записывает данные в кеш или память следующего уровня. А что, если эти данные будут использованы сразу? Не означает ли это, что нам все еще придется его захватить? Для решения этой проблемы в набор инструкций ARMv8 (применимо к A53/57/72) введена новая инструкция операции с кэшем DCZVA, которая может устанавливать весь строковый кэш в 0 без запуска записи. выделить. Почему? Потому что необходимо изменить все данные строки.,Вместо изменения определенного поля,Тогда нет необходимости считывать исходное значение,Так что просто выделите,Нет необходимости читать,Но это все равно повлечет за собой выселение. сродни,Мы также можем очистить и сделать недействительным определенный фрагмент кэша целиком перед его использованием.,clean&invalidate,Таким образом, выселения не будет. Но если блок тестовых данных достаточно велик,Это равносильно предварительному выселению,не может быть устранено,Пусть ваше письмо сосредоточится на определенном абзаце. Сделайте последующие чтения более непрерывными.
Все вышеперечисленное относится к кэшу первого уровня. Управление кэшем второго уровня меньше, и на него не может влиять код. Вы можете только установить регистр, включить предварительную выборку кэша второго уровня или установить смещение предварительной выборки. Что я увидел на контроллере кэша L2 PL301 от ARM, так это то, что если смещение установлено правильно и захваченные данные используются точно, полоса пропускания чтения может быть увеличена на 150% на основе оптимизации кода и кэша L1. На новых процессорах можно одновременно обнаружить несколько каналов предварительной выборки и несколько наборов шаблонов доступа к памяти, что еще больше повышает эффективность. Более того, количество OT за каждым уровнем кэша определенно больше, чем за предыдущим уровнем. Оно включает в себя различные операции чтения, записи и кэширования. Если вы правильно используете эти OT, вы можете повысить производительность.
Для некэшируемых записей он будет отправлен непосредственно в буфер записи буфером хранилища для слияния, а затем в кеш следующего уровня. Для некэшируемого чтения мы сказали, что оно сначала отправляется в кеш, чтобы проверить, есть ли попадание. Если оно промахивается, оно поступает непосредственно в буфер чтения, а затем объединяется и отправляется в кеш следующего уровня. Обычно он не занимает буфер заполнения строки, поскольку обычно он занимает от 4 до 8 байт и не требует использования буфера размером со строку кэша.
Иногда мы также можем использовать некэшируемые каналы чтения для параллельного выполнения кешируемых операций чтения, чтобы повысить эффективность. Его принцип заключается в одновременном использовании буфера заполнения строки и буфера чтения. В это время необходимо убедиться, что процессор имеет достаточное количество ОТ и не зависает.
Короче говоря, принцип программной оптимизации доступа к памяти состоит в том, чтобы поддерживать согласованность, находить больше доступных OT, смешивать доступ к памяти и предварительную выборку, поддерживать более непрерывные адреса доступа и сокращать задержку каждого канала.
Наконец, объясните причину задержки кэша. Чего программисты могут не знать, так это того, что кэши разных размеров имеют разные тактовые частоты, которых они могут достичь. Кэш первого уровня ARM, изготовленный по 16-нм техпроцессу, имеет размер 32–64 КБ и может работать на частоте около 1–2 ГГц, что соответствует частоте процессора. Независимо от того, насколько высока частота процессора, доступ к кэшу потребует 2-3 такта процессора. Кэш второго уровня медленнее, 256 Кбайт, 800 МГц было бы здорово. Это связано с тем, что чем больше кэш, тем больше индекс каталога, в котором необходимо выполнить поиск, и чем больше разветвление и емкость, тем медленнее, естественно, он будет. Кроме того, существует предпосылка для задержки доступа к кэшу, обычно упоминаемой при продвижении процессора, которая заключается в использовании индекса виртуального адреса VIPT. Таким образом, нет необходимости искать в таблице Tlb первого уровня, и адрес индекса получается напрямую. Если вы используете индекс физического адреса PIPT, потребуется дополнительное время, чтобы найти tlb первого уровня для преобразования виртуального в реальный. Если произойдет промах, вам придется перейти к таблице страниц второго уровня или даже к программной таблице, чтобы найти. это. Это явно слишком медленно. Так почему бы просто не использовать VIPT? Поскольку VIPT вызовет проблему, несколько виртуальных адресов будут сопоставлены с одним реальным адресом, в результате чего несколько записей кэша будут соответствовать одному реальному адресу. При выполнении операции записи несколько записей вызовут ошибки согласованности. Кэш инструкций обычно не имеет этой проблемы, поскольку он доступен только для чтения. Поэтому большинство кэшей инструкций используют VIPT. Поскольку частота процессора становится все выше и выше, кэш данных может использовать только VIPT. Чтобы решить ранее упомянутую проблему, ARM добавила в новый процессор дополнительную логику для обнаружения повторяющихся записей.
После такого многословия пришло время поговорить о задержке доступа к памяти в реальной системе. Прямо над картинкой:
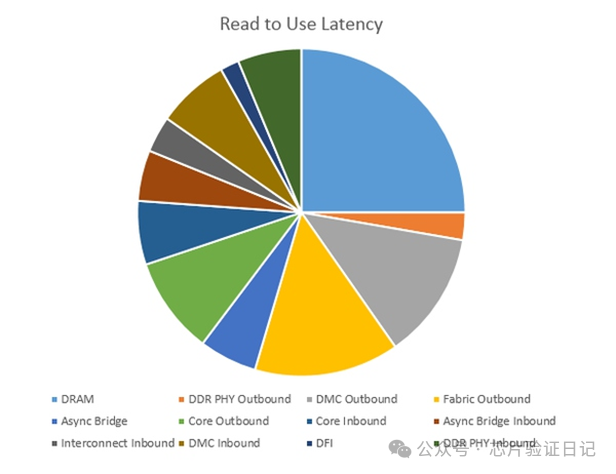
В приведенной выше конфигурации DDR4 работает со скоростью 3,2 Гбит/с, частота шины — 800 МГц, частота контроллера памяти — 800 МГц, а частота процессора — 2,25 ГГц. Отключите кеш и проверьте инструкции чтения. Задержка включает как исходящие, так и входящие направления, 69,8 наносекунд. Это оптимальный результат, когда для доступа к физической странице памяти всегда требуется 17,5 наносекунд, умноженных на 2–3. Объяснение физических страниц см. в главе «Память».
Время, потраченное на память, составляет контроллер + физический уровень + интерфейс, всего 38,9 наносекунд. Процент 55%. Если осуществляется доступ к случайному адресу, оно превысит 70 наносекунд, что составляет 70%. Время, затраченное на шину и асинхронный мост, составляет 20 наносекунд, 8 тактов шины, 28%. Процессор 11,1 наносекунд, 16%, 20 тактов процессора.
Поэтому даже на 3,2 Гбит/с DDR4 большая часть времени все равно находится в памяти, и очевидно, что с нее можно начать оптимизацию. Лишь часть времени находится в процессоре. Но с другой стороны, процессор контролирует количество заполнений и вытеснений строк, непрерывность адресов и эффективность предварительной выборки. Хотя она занимает меньше всего времени, она также является предметом оптимизации.
В планах ARM также есть не новая технология под названием stashing. Он исходит от сетевого процессора. Принцип заключается в том, что периферийный контроллер (PCIe, сетевая карта) отправляет запрос процессору и помещает определенные данные в кеш. Этот процесс очень похож на слежение. В некоторых сферах эта технология может вызвать качественные изменения. Например, процессоры Intel Xeon в сочетании с библиотекой сетевой пересылки DPDK могут получать пакеты от сетевых карт PCIe в среднем за 80 процессорных циклов, анализировать заголовки пакетов и отправлять их обратно. В чем заключается концепция 80 циклов? Посмотрев на приведенную выше диаграмму задержки доступа к памяти, вы должны знать, что процессору требуется 200-300 циклов для доступа к памяти. Эти данные передаются по DMA из порта PCIe в память, затем процессор захватывает их для обработки, а затем выходит из порта PCIe через DMA. Весь процесс должен длиться дольше, чем время доступа к памяти. Среднее время 80 циклов указывает на то, что оно должно быть отправлено в кэш раньше. Но поступает много данных, и только контроллер PCIe или сетевой карты знает, какой заголовок является пакетом, и может точно передать данные, иначе кеш будет переполнен бесполезными данными. После завершения этого процесса программное обеспечение сможет обрабатывать Ethernet или устройства хранения данных быстрее, чем аппаратные ускорители. Фактически на сетевом процессоре Freescale с помощью аппаратных ускорителей средняя задержка обработки пакетов требует 200 процессорных тактов, что уже медленнее, чем у Xeon.
Если вы ничего не чувствуете после прочтения предыдущего абзаца, то могу сказать по-другому: для ARM, который не полностью поддерживает кэширование SoC, даже если процессор работает на частоте 10 ГГц и производительность сетевого ускорителя заоблачная, простая пересылка пакетов на основе DPDK (в десятки раз быстрее, чем пересылка стека сетевых протоколов ядра Linux) все равно составляет лишь 30% от лучших и пересылка пакетов — это сеть. Один из наиболее важных показателей процессора также является одним из показателей для серверов, на которых установлено программное обеспечение для пересылки по сети. Его также можно использовать в области хранения для ускорения приложений хранения, таких как SPDK.
Кроме того, новое сетевое и серверно-ориентированное ядро ARM будет одноядерным и двухпоточным. Задача обработки пакетов, естественно, подходит для многопоточности, а одно ядро и два потока могут обеспечить более эффективное использование аппаратных ресурсов. В сочетании с кэшированием это становится еще более мощным.
После выяснения пути доступа к памяти может возникнуть вопрос: какие запросы на чтение и запись отправляет процессор? Чтобы разобраться, нам нужно представить автобусы. Ниже я расскажу о протоколе шины AXI/ACE компании ARM и полученной на его основе структуре шины. Эти два протокола широко используются в основных чипах мобильных телефонов и представляют собой стандарты AMBA четвертого поколения (усовершенствованная архитектура шины микроконтроллера).
Простая шина — это всего лишь несколько адресных линий и линий данных, и с помощью арбитра она может отправлять запросы на чтение и запись, отправленные процессором, в память или периферийные устройства, а затем возвращать данные. В этом процессе нам нужны ведущее устройство и ведомое устройство. Все передачи инициируются главным устройством и отвечают ведомому устройству. Давайте представим себе процессор и кэш, который он содержит, как ведущее устройство, а контроллер памяти — как ведомое устройство. Процессор инициирует запрос доступа. Если это чтение, шина отправляет запрос (включая адрес) контроллеру памяти, а затем ожидает ответа. Через некоторое время контроллер памяти передает данные, считанные из частиц памяти, на шину, а шина передает данные процессору. Если данные верны (проверка ECC или четности верна), то операция чтения завершается. Если это запись, процессор передает запрос на запись (включая адрес) и данные на шину, а шина передает их контроллеру памяти. После того, как контроллер памяти завершает запись, он выдает подтверждение. Это подтверждение возвращается процессору через шину, и операция записи завершается.
В вышеописанном процессе есть несколько ключевых моментов. Во-первых, одна инструкция чтения в процессоре разделяется на этапы запроса (адрес) и завершения (данные). Инструкции записи также делятся на этапы запроса (адрес, данные) и завершения (подтверждение записи). Во-вторых, будучи ведомым устройством, контроллер памяти никогда не может активно инициировать операции чтения или записи. Если вам необходимо связаться с процессором, например, если возникает ошибка чтения или записи, вы должны использовать прерывание, а затем позволить процессору инициировать запрос на чтение и запись состояния контроллера памяти. В-третьих, незавершенные инструкции чтения и записи становятся OT, и шина может поддерживать несколько OT. Однако тот факт, что шина поддерживает несколько ОТ, не означает, что процессор может отправлять столько запросов, особенно чтения. Таким образом, узким местом все еще может быть процессор.
Я сталкивался с такой ситуацией несколько раз. При запуске определенного драйвера система внезапно зависает. Однако другие устройства по-прежнему могут реагировать на прерывания, или система продолжает работать после сообщения об исключении. Если заменить вышеописанный контроллер памяти контроллером устройства, понять это явление нетрудно. Если предположить, что процессор инициирует запрос на чтение к устройству, а устройство не отвечает, процессор остановится на этом и будет ждать. Процессоры, которые я видел, включая PowerPC и ARM, не имеют механизма тайм-аута для подобных ситуаций. Если прерывания нет, процессор не может самостоятельно переключиться на другой поток (монопольный режим операционных систем, таких как Linux) и будет ждать вечно, и система будет выглядеть зависшей. Некоторые контроллеры устройств могут автоматически обнаруживать такие тайм-ауты и вызывать соответствующие исключения или обработку прерываний посредством прерываний. В обработчике прерывания можно сообщить об ошибке, изменить адрес возврата, пропустить предыдущую инструкцию и перейти вниз, и система восстановится. Существуют также некоторые процессоры, которые могут автоматически переходить к следующей строке инструкций после запуска исключения определенного типа, чтобы избежать зависания. Но если не произойдет никакого исключения или прерывания, оно будет висеть там навсегда.
Продолжайте возвращаться к автобусу. В протоколе шины AXI/ACE чтение и запись являются отдельными каналами, поскольку между ними нет необходимого соединения. Более подробно, на шине указаны пять групп, а именно: адрес операции чтения (от ведущего к ведомому), данные операции чтения (от ведомого к ведущему), адрес операции записи (от ведущего к ведомому), данные операции записи (от ведущего к ведомому), Запись подтверждения операции (от подчиненного устройства к главному). Не существует определенного порядка между двумя основными типами операций: чтением и записью. Внутри каждого типа операции существует последовательность между группами. Например, сначала отправляется адрес, а затем данные. Тактов может быть много, образуя пакетную операцию. Подтверждение выдается после того, как ведомое устройство получит данные во время операции записи. Для контроллера памяти подтверждение должно быть дано после того, как данные окончательно записаны в частицу, а не тогда, когда данные получены и помещены во внутренний кэш.
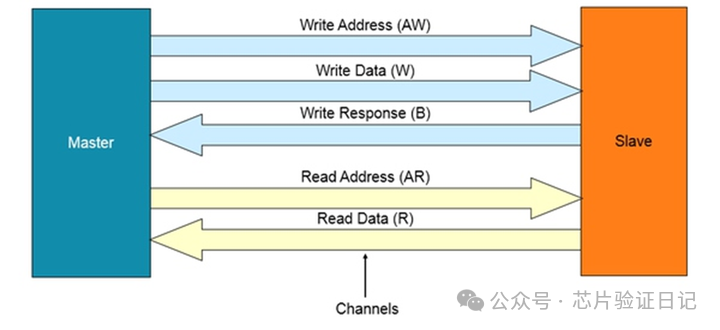
Для одного и того же канала, если получены последовательные инструкции, каков порядок между ними? Протокол AXI/ACE предусматривает, что порядок может быть нарушен. Если взять в качестве примера чтение, то данные, возвращаемые двумя инструкциями чтения до и после, могут быть не в порядке. Здесь содержится вопрос: как шина различает две инструкции чтения до и после? Это очень просто. Добавьте в группы адресов и данных несколько сигналов в качестве идентификаторов, чтобы отличать запросы чтения №0-N от завершения. Каждая пара запросов и завершений использует один и тот же идентификатор. С этим идентификатором нет необходимости ждать завершения предыдущего запроса перед запуском второго запроса, а нужно позволить им выполняться поочередно, чтобы можно было реализовать OT шины и значительно повысить эффективность. Конечно, для хранения статуса этих запросов также необходимо предоставить соответствующие буферы. А максимальное количество ОТ зависит от меньшего количества буферов и идентификаторов. Причина проста: что делать, если буфер или идентификатор исчерпан, но все операции чтения являются запросами и ни одна из них не может быть завершена? Тогда нам придется ждать новых запросов. Так существует правило шины AXI/ACE. В одном и том же канале чтения или записи запросы с одним и тем же идентификатором должны выполняться по порядку.
Иногда процессор также использует этот идентификатор в качестве внутреннего идентификатора запроса на чтение и запись, например Cortex-A7. Это нехорошо, поскольку равносильно наложению на себя ограничения. Максимальный отправляемый OT не должен превышать количество идентификаторов на канал шины. Когда в группе процессоров четыре ядра, этого может быть недостаточно, а количество ОТ искусственно ограничивается.
Наконец, не существует определенного порядка между каналами чтения и записи, даже если флаги одинаковы.
Когда вы видите это, может возникнуть проблема. В инструкциях чтения и записи действует принцип по умолчанию, то есть, когда один и тот же адрес или адреса перекрываются, доступ к памяти должен быть последовательным. Кроме того, если типом памяти, к которой осуществляется доступ, является устройство, последовательность доступа к памяти должна соответствовать инструкциям. Как это проявляется в автобусе? Шина проверит адреса, чтобы обеспечить порядок. Как правило, неправильные адреса до и после доступа к памяти не могут находиться в пределах 64 байтов, а неупорядоченные адреса до и после доступа к устройству не могут находиться в пределах 4 КБ.
В AXI/ACE соотношение каналов чтения и записи равно один к одному. На самом деле в ежедневных программах вероятность чтения больше, чем записи. Конечно, кэширование записи на самом деле сопровождается заполнением строки кэша (чтение), а кэширование чтения вызывает вытеснение строк кэша (запись), а также слияние и настройку порядка, поэтому соотношение инструкций чтения и записи не обязательно. Я видел, что для шины CCB FreescalePowerPC соотношение каналов чтения и записи составляет два к одному. Я не знаю, почему ARM не сделала подобную конструкцию для повышения эффективности. Возможно, соотношение один к одному — лучшее соотношение, исходя из статистики типичных приложений для мобильных телефонов.
На этом этапе мы уже можем мысленно представить передачу операций чтения и записи в паре каналов чтения и записи. Как это выглядит, когда объединяются несколько главных-подчиненных устройств? Это простая суперпозиция? Это затрагивает основной вопрос проектирования шин — топологию.
Среди всех текущих шинных продуктов ARM их можно разделить на три категории в соответствии с различными топологиями: серии NIC/CCI основаны на кросс-матрице (Crossbar), а серии CCN/CMN основаны на кольцевых и ячеистых шинах (Ring/Mesh). . Серия NoC представляет собой шину пересылки пакетов (маршрутизатор). Каждый из них имеет свои особенности и подходит для разных сценариев. Количество главных и подчиненных устройств, соединенных кросс-матрицей, ограничено, но наиболее эффективно запросы на чтение и запись могут достигать подчиненных устройств напрямую за 1–2 цикла. Как показано на рисунке ниже, это перекрестная матрица 5x4:
По увиденным мной данным, на 28-нм техпроцессе и в конфигурации 5х4 частота этой шины может достигать 300МГц. Если количество пар главный-подчиненный дополнительно увеличивается, то частоту необходимо увеличить путем добавления большего количества регистров из-за увеличения разветвления, увеличения емкости и дорожек. Но в этом случае задержка от ведущего к ведомому соответственно увеличится. Даже если вы сохраните конфигурацию 5x3, если вы хотите дополнительно увеличить ее до 500 МГц, вам необходимо либо использовать лучший процесс, я видел 800 МГц в 16-нм, либо вставить регистры уровня 2-3, чтобы задержка чтения и записи достигла 4; -5 тактов шины, всего для выполнения запроса требуется 10 двусторонних запросов. Если коэффициент умножения шины на процессор составляет 1:2, то только на время, проведенное на шине, процессору потребуется не менее 20 тактов. Множитель 4 занимает больше времени, 40 тактов. Необходимо знать, что задержка доступа процессора к кэшу второго уровня обычно составляет всего лишь более 10 процессорных циклов. Конечно, среднюю задержку можно уменьшить за счет увеличения количества ОТ, но поскольку количество ОТ для процессора ограничено, для последовательных процессоров она может составлять всего 1-2. Поэтому для достижения более высоких частот и поддержки большего количества устройств «главный-подчиненный» необходимо ввести серию кольцевых шин CCN, как показано ниже:
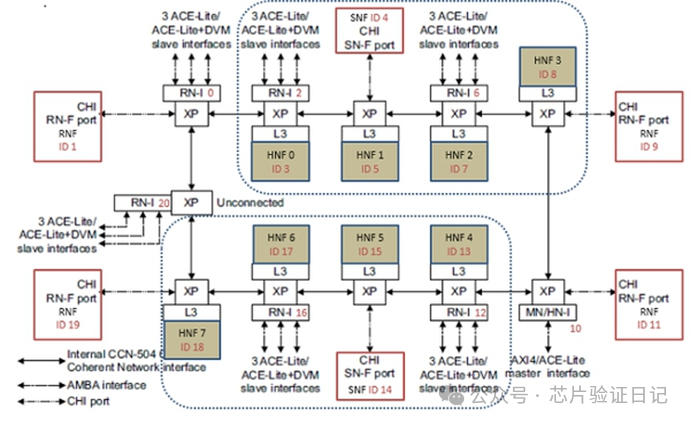
Помимо связи с двумя соседними узлами, каждый узел на шине CCN также может иметь два дополнительных компонента узла, например группы процессоров, кэш-память 3-го уровня, контроллеры памяти и т. д. Внутри узлов по-прежнему имеются пересечения, а между узлами — кольца. Это позволяет частоте шины в определенной степени избавиться от ограничения количества подключаемых устройств (разумеется, на нее еще влияют такие факторы, как проводка. При 16 нанометрах она может достигать более 1,2 ГГц). Конечно, цена — большая средняя задержка связи между узлами. Чтобы уменьшить среднюю задержку, узлы, которые часто посещают друг друга, можно размещать близко друг к другу.
В некоторых системах требуется подключение большего количества устройств, а требования к частоте выше. В настоящее время кольцевой шины недостаточно, необходима ячеистая шина CMN. Ячеистая шина ARM, соответствующая интерфейсу CHI AMBA5.0, поддерживает атомарные операции (работающие непосредственно в кеше без чтения процессору), хранение и прямой доступ (пропуск промежуточного кеша, сокращение пути) и другие функции и подходит для сервера или сетевого процессора.
Но иногда ширина данных, протокол, источник питания, напряжение и частота устройств, которые необходимо подключить системе, различаются. В этом случае требуется NoC, как показано ниже:
На этом рисунке только что упомянутая перекрестная матрица может использоваться как определенная часть всей сети. Всю систему соединяют узлы, расположенные в NoC. Каждый узел представляет собой небольшой маршрутизатор, и между ними передаются асинхронные пакеты. Таким образом, нет необходимости поддерживать большое количество соединений между маршрутизаторами, тем самым увеличивая частоту и поддерживая больше устройств. Недостатком, конечно, является более длительная задержка. По данным, которые я видел, на 16 нм частота может достигать 1,5 ГГц. А частота и топология могут быть разными для каждого субмодуля, к которому он подключен. Устройства, которые должны быть тесно связаны, например кластеры ЦП и графические процессоры, можно разместить в подсети, чтобы уменьшить задержки связи.
Интересно, замечали ли вы, что каждую из вышеперечисленных шин можно прототипировать на сетевом оборудовании? От прямого подключения устройства до кольцевой локальной сети, коммутации и маршрутизации. Их топологическая структура одинакова.
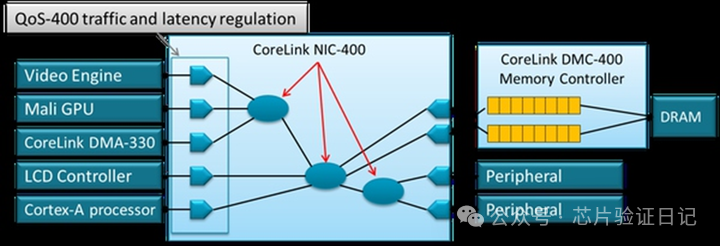
Как в реальной экосистеме ARM используются три вышеупомянутые топологии? Как правило, кросс-матрицы используются в чипах мобильных телефонов, кольцевые сети используются в сетевых процессорах и серверах, а ячеистая топология также широко используется в чипах мобильных телефонов. Причина последнего не в том, что к мобильному телефону необходимо подключить слишком много устройств, а в том, что ни один протокол AXI/ACE не поддерживает разделение одной передачи на несколько и отправку их на разные контроллеры памяти. Для этого типа передачи существует термин, называемый чередованием, перекрестным доступом. Существует множество определений перекрестного доступа. С точки зрения шины одно из них заключается в том, что порядок выполнения нескольких запросов на чтение и запись между главным устройством и подчиненным устройством может быть нарушен. Мы уже объяснили это. Второй — отправить запрос на чтение и запись с главного устройства на несколько подчиненных устройств и дождаться завершения. Зачем нужна эта передача? Потому что в мобильных телефонах графический процессор, контроллер дисплея и видеоконтроллер предъявляют очень высокие требования к пропускной способности памяти. Экран 1080p должен обновляться 60 раз в секунду, 2 миллиона пикселей, 32-битный цвет на пиксель, плюс 4 слоя, что требует 2 ГБ/с данных. Контроллер DDR3 со скоростью передачи 1,6 ГГц и 64-битными данными может обеспечить теоретическую пропускную способность только 10 ГБ/с. Из-за влияния различных факторов между теоретической пропускной способностью и фактической пропускной способностью будет большая разница. Коэффициент использования 70% является хорошим. А как насчет процессора, а что насчет других типов контроллеров? Единственный способ увеличить количество контроллеров памяти — добавить больше подчиненных устройств. Однако просто увеличить количество нельзя. Причина в том, что если вы просто отправите разные запросы физического адреса к разным контроллерам памяти, вполне вероятно, что в течение определенного периода времени все физические адреса будут соответствовать одному из них, а требования к пропускной способности все равно не могут быть удовлетворены. Решение состоит в том, чтобы разделить любой адрес на несколько запросов и отправить их разным контроллерам памяти. А с процессором этого лучше не делать (ядра ARM не поддерживают раздельное чтение и запись), потому что только шина знает, сколько там контроллеров памяти. Лучше всего, чтобы процессор просто отправлял запросы, а шина разделяет все запросы и после сбора данных возвращает их процессору.
К сожалению, шина AXI/ACE не поддерживает перекрестный доступ «один ко многим». Причина проста: произойдет тупик. Представьте себе, что есть два главных устройства и два подчиненных устройства, соединенных через перекрестную матрицу. M1 отправляет два запроса на чтение, оба с идентификаторами 1, на S1 и S2 и ожидает завершения. Затем M2 делает то же самое, все идентификаторы равны 2, и он последовательно отправляется на S2 и S1. Теперь предположим, что S2 обнаружит, что будет более эффективно, если он поменяет порядок возвращаемых данных, и он так и делает. Однако M1 не может получить возвращаемые данные от S2, поскольку согласно принципу, согласно которому одни и те же идентификаторы должны заполняться последовательно, он должен сначала дождаться возвратных данных от S1. В это время S1 не может отправить данные M2, поскольку M2 также ожидает данных, возвращенных S2, и возникает взаимоблокировка. Решение состоит в том, что ни одно главное устройство не может отправлять запросы нескольким подчиненным устройствам одновременно. Поэтому невозможно добиться перекрестного доступа к нескольким контроллерам памяти.
Сетчатая шина, основанная на пакетной передаче, не имеет этой проблемы. Все пакеты асинхронны и не имеют зависимостей. В результате появилась компания Arteris, специализирующаяся на шинах NoC. Они воспользовались этой возможностью и продали шины, поддерживающие одновременный доступ к нескольким контроллерам памяти, большинству компаний, производящих чипы для мобильных телефонов и планшетов. Пока что у ARM есть решение под названием Arachne, но практического применения оно не имеет.
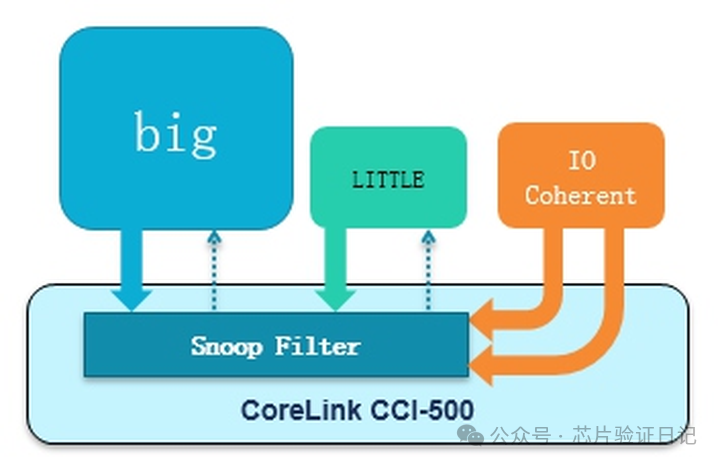
Многие современные мобильные телефоны среднего и бюджетного класса имеют 8 ядер, а согласно конструкции ARM каждая группа процессоров имеет до четырех ядер. Это требует размещения в системе двух групп процессоров, а связь между ними, включая реализацию больших и малых ядер, требует использования согласованности шины. Каждой группе процессоров также нужна согласованность внутри. Принцип тот же, что и снаружи, поэтому отдельно объяснять его не буду. Согласованности можно добиться с помощью программного обеспечения, но для этого требуется вручную сбросить содержимое кэша в кэш или память следующего уровня. Для кэша размером 64 КБ с строкой кэша 64 байта требуется 1000 обновлений, каждый раз даже по 100 наносекунд, а если OT. =4, это также занимает 25 микросекунд. Это очень большой срок для процессора. ARM использует для этого сопроцессор, и это является решением. Чтобы решить проблему с аппаратным обеспечением, ARM представила несколько шин, поддерживающих аппаратную согласованность. На рисунке ниже показано решение CCI400 первого поколения:
Как CCI400 обеспечивает согласованность оборудования? Проще говоря, группа процессоров С1 отправляет на шину специальную команду чтения и записи, содержащую информацию об адресе, а затем шина передает эту команду другой группе процессоров С2. После того, как C2 получает запрос, он постепенно ищет кэши второго и первого уровня на основе адреса. Если он обнаруживает, что он у него есть, он возвращает данные или выполняет соответствующие операции по согласованию кэша. Этот процесс называется отслеживанием. Я не буду вдаваться в конкретные операции. ARM использует протокол согласованности MOESI, который в нем определен. При этом ядро процессора в запрашиваемом C2 не участвует в этом процессе, а всю работу выполняют такие компоненты, как кэш и блок интерфейса шины BIU. Чтобы соответствовать определению, согласно которому ведомые устройства не инициируют запросы активно, требуются два набора главных и ведомых устройств, причем на каждую группу процессоров приходится одно ведущее и одно ведомое устройство. Это позволяет двум наборам процессоров оставаться согласованными друг с другом. Некоторые устройства, такие как контроллер DMA, сами не содержат кэшей и не нуждаются в мониторинге со стороны других, поэтому они содержат только подчиненные устройства, такие как оранжевая часть на рисунке выше. В определении ARM интерфейс с двунаправленными функциями называется ACE, а интерфейс, который может только слушать других, называется ACE-Lite. Помимо каналов чтения и записи AXI, они также имеют дополнительный канал прослушивания, как показано ниже:
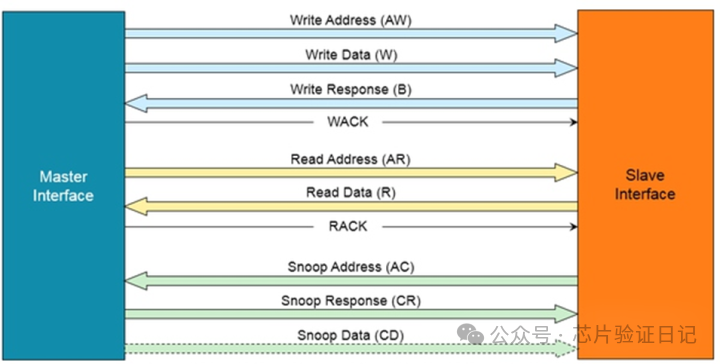
Дополнительные каналы прослушивания также имеют адрес (от ведомого к ведущему), ответ (от ведущего к ведомому) и данные (от ведущего к ведомому). Каждый набор сигналов содержит тот же идентификатор, что и AXI, для поддержки нескольких OT. Если данные обнаружены на ведущем устройстве (так называемое попадание), то будет использован канал данных. Если нет, то просто сообщите ведомому устройству о промахе, и нет необходимости передавать данные. Следовательно, вышеупомянутый контроллер DMA никогда не сможет передавать данные другим, поэтому нет необходимости в группе данных. Это основное отличие между ACE и ACE-Lite.
Мы также можем видеть, что на канале чтения имеется дополнительная линия RACK. Ее цель состоит в том, что когда ведомое устройство отправляет данные в операции чтения ведущему, оно не знает, когда ведущее устройство сможет получить данные, как мы уже говорили. Вставка регистров приводит к увеличению задержки шины. Если в это время для того же адреса А необходимо отправить мастеру новый запрос мониторинга, то возникнет вопрос: получил ли мастер уже отправленные ранее данные с адреса А? Если он не получен, он может сообщить о промахе прослушивателя. Но на самом деле данные по адресу A были отправлены мастеру, и он должен вернуть попадание. После добавления этого RACK ведомое устройство не будет отправлять новый запрос мониторинга ведущему до получения подтверждения RACK от ведущего, тем самым избегая вышеупомянутых проблем. То же самое справедливо и для WACK на канале записи.
Ранее мы рассчитали задержку на NIC400. Будет ли доступ быстрее при аппаратной синхронизации CCI400? Во-первых, согласованность оборудования предназначена не для ускорения, а для упрощения программного обеспечения. На самом деле, это может быть не быстро. Поскольку, учитывая адрес, мы не знаем, находится ли он в кеше другого набора процессоров, поэтому в любом случае требуются дополнительные действия по прослушиванию. В случае промаха это действие по мониторингу является излишним, поскольку нам все равно придется извлекать данные из памяти. Это дополнительное действие означает дополнительную задержку, 10 плюс 10, всего 20 циклов шины, увеличение на 100%. Конечно, если есть попадание, хотя на шине это тоже занимает всего 10 тактов, но получение данных из кэша происходит быстрее, чем получение их из памяти, поэтому в это время это выгодно. В совокупности, когда количество попаданий превышает определенную долю, общая польза все равно сохраняется.
Судя по реальной ситуации с применением, за исключением специально разработанных программ, процент попаданий обычно не превышает 10%. Поэтому нам нужно подумать о некоторых способах повышения производительности. Один из способов — позволить шине сначала обратиться к памяти, чтобы получить данные, независимо от того, является ли результат попаданием или промахом. Когда данные собираются, мы уже знаем результаты мониторинга, а затем решаем, какой стороне данные отправить обратно. Недостатком этого метода является повышенное энергопотребление, поскольку память все равно придется читать. Во-вторых, это снизит общую производительность, если сами обращения к памяти происходят очень часто.
Другой метод — заранее знать, что данные не кэшируются в других группах процессоров, тогда ведущее устройство, выдающее запрос на чтение и запись, может конкретно указать, что за ним не нужно следить, и шина не будет совершать это действие. Недостаток этого метода в том, что он требует вмешательства программного обеспечения. Хотя стоимость невелика, достаточно просто установить регистр при выделении страниц операционной системы. Однако требования к программистам высоки, и они должны полностью понимать целевую систему.
Разработчики шины CCI также использовали новый подход для повышения производительности. Они добавили в автобус слежный фильтр. Фактически это кэш (TAG RAM), в котором хранится информация о состоянии кэшей первого и второго уровня внутри всех групп процессоров. Кэш данных (DATARAM) не нужен, поскольку он отвечает только за проверку того, есть попадание или нет. Преимущество этого заключается в том, что запрос мониторинга не нужно отправлять каждой группе процессоров, он может быть выполнен внутри шины, что экономит почти 10 циклов шины, а энергопотребление лучше, чем при доступе к памяти. Цена - немного добавленный кэш (около 10% от первого и второго кэша). Более того, если заменяется определенная строка кэша в фильтре прослушивания (например, попадание прослушивания записи требует аннулирования строки кэша, как это определено протоколом MOESI), ту же операцию необходимо выполнить в кэшах первого и второго уровня соответствующую группу процессоров для согласованности. Этот процесс называется обратной инвалидацией, и он добавляет дополнительную нагрузку, поскольку при обновлении первого и второго кешей самому прослушивающему фильтру также необходимо отслеживать обновленное состояние, в противном случае согласованность не может быть гарантирована. К счастью, в ходе реальных испытаний выяснилось, что подобные операции происходят нечасто и, как правило, вероятность не превышает 5%. Конечно, некоторые тестовые коды будут часто запускать эту операцию, и в это время станут очевидными недостатки прослушивающего фильтра.
Вышеизложенные идеи реализованы в CCI500, принципиальная схема выглядит следующим образом:
После фактического тестирования производительности разработчики CCI обнаружили, что узкое место шины переместилось в окно доступа к этому фильтру прослушивания. Это узкое место фактически скрывало описанную выше проблему обратной инвалидации, и оно всегда обнаруживалось до обратной инвалидации. Увеличив это окно, во время тестирования я обнаружил, что если каждый интерфейс «главный-подчиненный» отчаянно передает данные (все устройства «главный-подчиненный» являются OT бесконечными, а один главный и несколько подчиненных имеют переднее и заднее кроссовер), то на главном Интерфейс ведомого устройства Часто возникает ситуация ожидания, то есть данные очевидно готовы, но устройство не успевает их получить. Поэтому для хранения этих данных были добавлены некоторые буферы. Цена немного больше по площади и энергопотреблению. Обратите внимание, что этот буфер не перекрывается с буфером состояния, хранящим OT.
Согласно фактическим данным измерений, после внесения всех усовершенствований производительность новой шины увеличивается более чем на 50% на той же частоте. Частоту можно увеличить с 500 МГц до 1 ГГц. Конечно, этот результат — всего лишь расплывчатая статистика, если учесть, что количество процессоров и контроллеров памяти ограничено, процент отслеживаемых данных разный, частота попаданий изменена и размер фильтра прослушивания, мы обязательно это изменим. получить разные результаты.
Как шина в области чипов для мобильных телефонов, она должна поддерживать несколько приоритетов передачи, то есть QoS. Потому что такие устройства, как контроллеры дисплея, предъявляют высокие требования к работе в режиме реального времени, и запросы группы процессоров также важны. В поддержке QoS нет ничего сложного. Вам нужно только помещать различные запросы в буфер и передавать их в соответствии с приоритетом. Однако в ходе реального тестирования выяснилось, что если запросов от каждого устройства слишком много и слишком часто, буфер быстро заполняется, блокируя тем самым новые высокоприоритетные запросы. Чтобы решить эту проблему, буферы группируются по приоритету, и каждая группа принимает только запросы равного или более высокого приоритета, что позволяет избежать блокировки. Эти методы идентичны проектированию защиты от перегрузок сети.
Кроме того, для поддержки нескольких доменов тактовой частоты и мощности, чтобы каждый набор процессоров мог динамически регулировать напряжение и тактовую частоту, шина серии CCI также может быть соединена с асинхронным мостом ADB (Asynchronous Domain Bridge). Это оказывает определенное влияние на производительность. Когда множитель равен 2, для прохождения сигнала через него требуется дополнительный тактовый цикл шины. Если 3, это больше. В системах с жесткими требованиями к задержке доступа это время нельзя игнорировать. Если нет необходимости в дополнительном домене питания, мы можем не использовать его и сэкономить небольшую задержку. Шина NIC/CCI/CCN/NoC естественным образом поддерживает асинхронную передачу.
С согласованностью связаны порядок доступа к памяти и блокировки, которые некоторые программисты путают. Предположим, у нас есть два ядра C0 и C1. Когда C0 и C1 соответственно обращаются к одному и тому же адресу A0, они должны гарантировать, что данные, которые они видят, непротиворечивы в любое время. Это согласованность. Затем в C0 необходимо обеспечить последовательный доступ к адресам A0 и A1. Это называется последовательностью доступа. В этот момент блокировка не требуется, необходимы только барьерные инструкции. Если два потока выполняются на C0 и C1 одновременно, когда C0 и C1 обращаются к одному и тому же адресу A0 соответственно, и необходимо убедиться, что C0 и C1 обращаются к A0 по порядку, требуется блокировка. Следовательно, одна только барьерная инструкция может гарантировать только порядок одноядерных и однопоточных операций, а порядок многоядерных и многопоточных операций требует блокировки. Согласованность гарантирует, что при выполнении операций блокировки разные копии одной и той же переменной в кэше или памяти являются согласованными.
Барьерные инструкции ARM делятся на DSB с сильным барьером и DMB со слабым барьером. Мы знаем, что инструкции чтения и записи будут разделены на две части: запрос и завершение.,Сильные барьеры требуют, чтобы предыдущая инструкция чтения и записи была завершена, прежде чем можно будет запустить следующий запрос.,Слабые барьеры требуют только того, чтобы запрос следующей инструкции чтения и записи мог быть продолжен после выдачи предыдущей инструкции чтения и записи.,и могу только гарантировать,Когда инструкции чтения и записи после него завершены,Предыдущие инструкции чтения и записи должны быть выполнены. очевидно,В последнем случае производительность выше.,OT>1。Но тестирование показывает,В случае нескольких групп процессоров,Команда шлагбаума при передаче на автобус,Это может только снизить общую производительность системы.,Поэтому в новомARMавтобус Китай не поддерживает барьеры,Должно быть на стадии проектирования чипа,Укажите процессору, чтобы он сам обрабатывал инструкции барьера через параметры конфигурации.,Не отправляйте в автобус. Но это не влияет на инструкции барьера в программе.,Процессор будетавтобусотфильтруй это раньше。
Конкретно на шине CCI как реализован барьерный механизм? Прежде всего, барьеры, такие как чтение и запись, также используют каналы чтения и записи, за исключением того, что их адреса всегда равны 0 и данных нет. Есть еще идентификаторы, и есть две дополнительные строки BAR0/1, указывающие, является ли данная передача барьером и что это за барьер. Как он это передал? Давайте сначала посмотрим на слабые барьеры, как показано ниже:
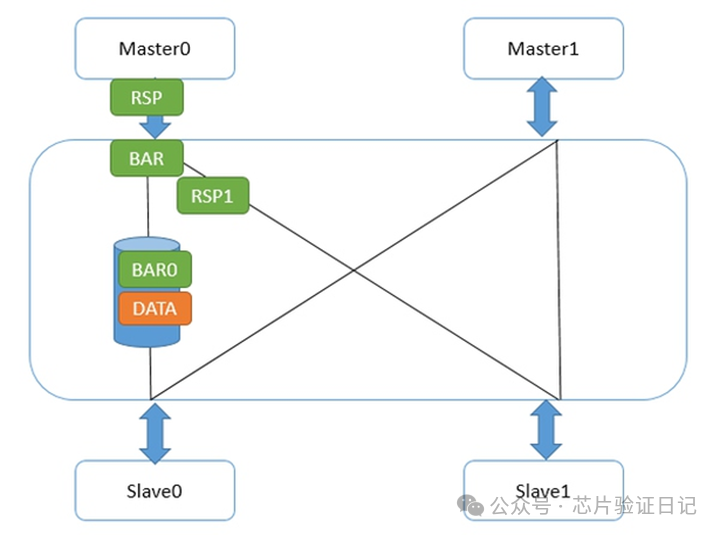
Master0 записывает фрагмент данных, а затем отправляет запрос слабого барьера. Когда CCI взаимодействует с главным устройством, как только он получает запрос барьера, он немедленно выполняет две вещи: во-первых, он отправляет ответ барьера на Master0, во-вторых, он отправляет запрос барьера на интерфейс с подчиненным устройством Slave0/1; Интерфейс подчиненного устройства 1 отреагировал быстро, поскольку на нем не было незавершенных передач. Интерфейс подчиненного устройства 0 не может ответить на барьер, поскольку данные еще не отправлены на подчиненное устройство. Запросы барьера на этом пути должны ждать и не могут обмениваться заказами с запросами на запись данных. Это не мешает Master0 отправлять вторые данные, поскольку он получил барьерные ответы от всех своих подчиненных (интерфейс Master0), поэтому он снова записывает флаг. Как показано ниже:
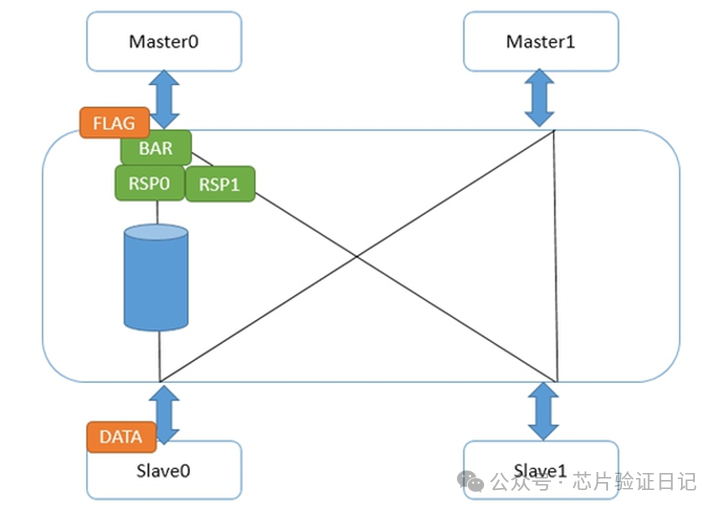
В это время флаг ожидает ответов барьера от всех своих интерфейсов нижнего уровня в интерфейсе Master0. После того, как данные достигают подчиненного устройства 0, реакция барьера достигает интерфейса мастера 0, и флаг продолжает снижаться. На данный момент нам не нужно беспокоиться о том, что данные не дойдут до подчиненного устройства 0, поскольку до этого ответ барьера с интерфейса подчиненного устройства 0 не будет отправлен на интерфейс главного устройства 0. Таким образом, гарантируется порядок слабых барьеров, и запрос флага может быть отправлен до завершения команды барьера.
Для команды сильного барьера есть только одно отличие: интерфейс Master0 не будет отправлять свой собственный ответ барьера на Master0 до того, как он получит ответы барьера от всех интерфейсов более низкого уровня. Это приводит к тому, что флаг не будет отправлен до тех пор, пока не будет завершена команда барьера. Как показано ниже:
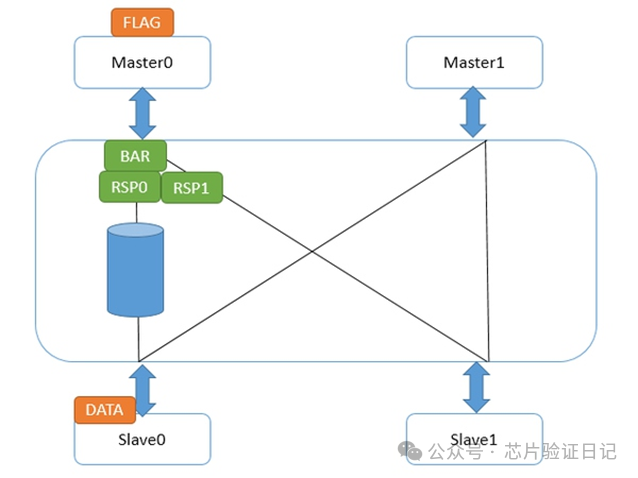
Таким образом, гарантируется, что после завершения сильного барьера следующая инструкция чтения и записи сможет выдать запрос. В это время инструкции чтения и записи перед сильным барьером должны быть завершены.
Также важно отметить, что слабые барьеры ARM предназначены только для явного доступа к данным. Что такое явный доступ к данным? Инструкции чтения и записи, операции кэширования и TLB — все это учитывается. Напротив, что такое неявный доступ к данным? В разделе о процессоре мы упомянули, что процессор будет выполнять спекулятивное выполнение и заранее выполнять инструкции чтения и записи; в кэше также имеется аппаратный механизм предварительной выборки, который автоматически выбирает возможные строки кэша на основе предыдущих шаблонов доступа к данным. Ничто из этого не включено в действующую директиву, и слабые барьеры ничего не могут с этим поделать. Поэтому помните, что слабые барьеры могут гарантировать только порядок инструкций, которые вы даете, но они не гарантируют, что никакой другой модуль не получит доступ к памяти между ними, даже если этот модуль происходит из того же ядра.
Проще говоря, если вам нужно только обеспечить порядок чтения и записи, используйте слабые барьеры, если вам нужно выполнить определенную инструкцию чтения и записи, прежде чем выполнять другие действия, используйте сильные барьеры; Все вышеперечисленное относится к обычным типам памяти. Когда мы устанавливаем тип устройства, автоматически гарантируются сильные барьеры.
Мы упоминали, что барьер существует только для одноядерных процессоров. В многоядерных и многопоточных средах, даже если используются барьерные инструкции, атомарность чтения и записи не может быть гарантирована. Есть два решения: одно — программная блокировка, другое — атомарная операция. Я видел два типа атомарных операций. Первый заключается в том, что когда шина получает запрос, вся шина напрямую блокируется, и только одно ядро может получить к ней доступ одновременно. Это очень неэффективно. Другой метод — отправить запрос блокировки на одноранговое устройство, такое как контроллер памяти, чтобы оно запретило доступ другим ядрам, в то время как шина все еще может работать, поэтому эффективность намного выше. Данные, которые я видел, уменьшаются в 10 раз. время. Однако протокол AXI/ACE не поддерживает атомарные операции. Поэтому вам нужно использовать программную блокировку.
Среди программных блокировок есть спин-блокировка, которую можно реализовать с помощью аппаратного механизма ARM с эксклюзивным доступом. Когда для записи значения по адресу используется специальная инструкция, на соответствующей строке кэша будет сделана специальная отметка, указывающая, что никакое другое ядро не записывало в эту строку кэша. Затем следующая инструкция читает эту строку. Если метка не меняется, значит, между записью и чтением никто не мешал, то блокировка получена. Если оно изменится, вернитесь к процессу записи и повторно получите блокировку. Благодаря согласованности кэша эта переменная блокировки может использоваться несколькими ядрами и потоками. Конечно, барьерные инструкции по-прежнему необходимы для обеспечения порядка во время процесса.
Для обычной памяти возникает другая проблема, то есть операции чтения и записи могут проходить через кэш, и вы не знаете, запишутся ли данные в память в итоге. Обычно мы используем операцию очистки для очистки кеша. Но сам по себе кеш — это расплывчатое понятие. Существует несколько уровней кеша: некоторые в процессоре, а некоторые после шины. Где заканчивается кеш? Кроме того, чтобы обеспечить согласованность, нужно ли мне при прошивке уведомлять другие процессоры и кэши? Чтобы стандартизировать эти проблемы, ARM представила концепции точки унификации/когерентности, внутреннего/внешнего кэширования и системы/внутреннего/внешнего/не совместного использования.
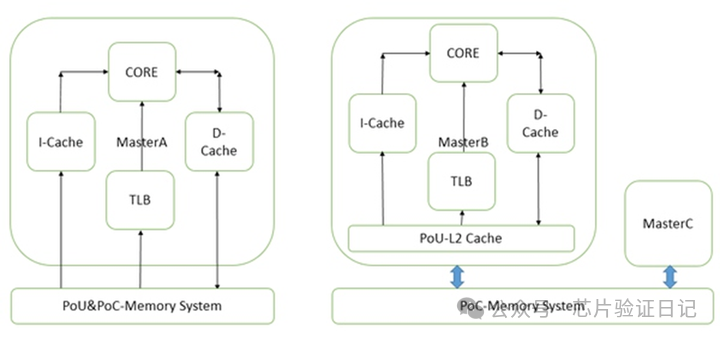
PoU означает, что для определенного основного мастера, инструкций, кэша данных и TLB, прикрепленных к нему, если в определенный момент они могут видеть согласованный контент, то эта точка является PoU. Как показано в правой части рисунка выше, MasterB содержит инструкции, кэш данных и TLB, а также вторичный кэш. Обмен данными команд, кэш данных и TLB устанавливаются в кэше второго уровня. В это время кэш второго уровня становится PoU. Для MasterA на левой стороне изображения выше, поскольку нет кэша второго уровня, инструкции, кэш данных и обмен данными TLB построены в памяти, поэтому память становится PoU.
PoC означает, что для всех Мастеров в системе (обратите внимание, что это все, а не определенное ядро), если есть точка, где их инструкции, кэш данных и TLB могут видеть один и тот же источник, то эта точка и есть PoC. Как показано в правой части рисунка выше, кэш второго уровня в настоящее время не может использоваться в качестве PoC, поскольку MasterB находится за пределами его области действия и имеет прямой доступ к памяти. Итак, в настоящее время память является PoC. На картинке слева, поскольку Мастер только один, память PoC.
Сделав еще один шаг вперед, если мы заменим память на рисунке справа кэшем L3 и подключим память за кэшем L3, то PoC станет кэшем L3.
С помощью этих двух определений мы можем указать диапазон, в который отправляются операции кэширования, а также инструкции чтения и записи. Например, в системе на картинке ниже есть две группы A15, каждая группа имеет четыре ядра, а группа содержит кэш второго уровня. PoC системы находится в памяти, а PoU A15 — в кэше L2 в собственной группе. Выполните очистку на A15, чтобы очистить кэш инструкций, а диапазон указывает PoU. Судя по всему, кэши инструкций L1 всех четырех A15 будут очищены. Так затронуты ли другие Мастера? Затем используйте «Внутренний/Внешний/Неразделяемый».
Shareable легко понять, то есть определенный адрес может использоваться другими. Мы предоставим его при определении определенного атрибута страницы. Non-Shareable означает, что его можно использовать только самостоятельно. Конечно, определение его как недоступного для совместного использования не означает, что другие не могут его использовать. Если определенный адрес A сопоставлен с общим адресом на ядре 1, ядро 2 сопоставлено с неразделяемым, и два ядра соединяются через CCI400. Затем, когда ядро 1 обращается к A, шина будет контролировать ядро 2. Когда ядро 2 обращается к A, шина напрямую обращается к памяти и не контролирует ядро 1. Очевидно, что такой подход неправильный.
Существует простое понимание Inner и Outer Shareable, то есть это одно и то же. В последних процессорах ARM серии A при настройке RTL процессора вы выбираете, отправлять ли внутреннюю передачу на порт ACE. Если имеется несколько кластеров процессоров или графических процессоров, которым требуется двунаправленная согласованность, для них необходимо настроить порт ACE. Таким образом, внутренние операции, как внутренние, так и внешние, будут транслироваться на другие порты ACE через CCI.
Высказав так много концепций, вы можете подумать, какой в этом смысл? Возвращаясь к приведенной выше инструкции очистки, PoU приводит к очистке соответствующих строк в четырех кэшах инструкций A7. Поскольку это операция кэша инструкций, атрибут InnerShareable заставляет эту операцию распространяться на шину. Шина CCI400 будет транслировать эту операцию на все возможные принимающие порты. Основная нагрузка приходится на порт ACE, поэтому четыре A15 также очистят соответствующие строки кэша инструкций. Для контроллеров Mali и DMA они ACE-Lite, поэтому очищать их нет необходимости. Но учтите, что они также подключены к интерфейсу DVM, который отвечает за отправку и получение инструкций по обслуживанию кэша, поэтому соответствующие им строки кэша инструкций также будут очищены. Но на самом деле у них нет соответствующих кэшей инструкций, поэтому они просто принимают запросы и не предпринимают никаких действий.
Возможно, вы снова задумаетесь: какой смысл в таком сложном определении? Цель состоит в том, чтобы точно определить объем обслуживания кэша и инструкций чтения и записи. Если мы изменим его и шина не поддерживает широковещательную рассылку Inner/Outer Shareable, то только группа процессоров A7 очистит строку кэша. Очевидно, что это логически неверно, поскольку A7/A15 может выполнять одну и ту же строку кода. Более того, как мы упоминали ранее, если для атрибута чтения-записи установлено значение Non-Shareable, шина не будет прослушивать другие ведущие устройства, что уменьшает задержки доступа, что может очень гибко улучшить производительность.
Возвращаясь к предыдущему вопросу, при очистке определенной строки кэша как узнать, запишутся ли данные в память окончательно? Мне очень жаль, мне очень жаль, но я до сих пор не знаю. Единственное, что вы можете сделать, это установить область действия PoC. Если PoC является кешем третьего уровня, то в конечном итоге он будет сброшен в кеш третьего уровня. Если это память, то он будет сброшен в память. Однако это логически правильно. Согласно определению, если все Мастера кэшируют унифицированные данные на третьем уровне, нет необходимости сбрасывать их в память.
Короче говоря, PoU/PoC определяет кэш или память, к которым могут получить доступ инструкции и команды. После достижения указанного места Inner/OuterShareable определяет область, в которой они транслируются.
Давайте посмотрим на внутренний/внешний кэш. Это просто определение кэша до и после. Кэш первого уровня должен быть InnerCacheable, а самый внешний кеш, например третьего уровня, может быть Outer Cacheable или Inner Cacheable. Их полезность заключается в том, что при определении атрибутов страниц памяти вы можете использовать разные стратегии обработки на разных уровнях кэша.
В руководстве по процессору и шине ARM также появятся несколько PoS (точки сериализации). Это означает, что в шине все типы запросов от ведущего устройства должны проверяться контроллером на предмет адреса и типа. Если есть конкуренция, они будут сериализованы. Это понятие не имеет ничего общего с остальными.
Глядя на изменения во всей шине, есть еще одна основная проблема, которая не была упомянута, а именно динамическое программирование, перепланирование и слияние. И процессор, и контроллер памяти имеют один и тот же модуль, который отвечает за классификацию, объединение, настройку порядка всех передач и даже прогнозирование адресов запросов чтения и записи, которые могут быть получены в будущем, для достижения максимальной эффективности передачи. . Эта проблема снова возникнет при анализе производительности. Но на уровне шины программное обеспечение может оказать очень незначительное влияние. Самым большим преимуществом четкого знания задержки шины и OT является то, что можно точно сопоставить статистические результаты счетчика производительности, чтобы увидеть, соответствует ли она ожиданиям.
Еще несколько дополнений по поводу NoC:
NoC (Arteris, Netspeed, Sonics) уже давно широко используется в процессорах мобильных телефонов и планшетов (MTK, Qualcom, Hisilicon, Spreadtrum, Samsung). Его основная цель — соединение множества устройств, отличных от процессора и графического процессора. Преимущества заключаются в следующем: По сравнению с шиной серии NIC на основе перекрестной панели ее самым большим преимуществом является то, что она может подключать несколько контроллеров памяти и поддерживать чередование и чередование доступа к контроллерам памяти. Зачем вам нужно несколько контроллеров памяти? После перехода на 1080p пропускная способность доступа к видео стала большим узким местом, и приходится использовать два или даже четыре контроллера памяти. Более того, шина должна автоматически разбивать передачу на несколько, равномерно отправлять их на несколько контроллеров памяти, а также автоматически объединять данные и отправлять их обратно на основное устройство. Буфер переупорядочения также необходим для хранения промежуточных данных для повышения эффективности. Все эти ARM-сетевые карты его не поддерживают, поэтому при подключении нескольких контроллеров памяти и чередовании доступа необходимо использовать NoC. Еще одна особенность NoC заключается в том, что он использует структуру маршрутизатора для пересылки пакетов, что позволяет уменьшить количество контактов и увеличить тактовую частоту. Нередко 16 нанометров достигают 1 ГГц. Он также поддерживает несколько тактовых доменов. Различные подсети могут работать на разных частотах и использовать разную ширину, что делает его чрезвычайно гибким. Очень часто даже медленные устройства используют NoC. Но если системе необходимо поддерживать небольшое количество основных устройств, на самом деле лучше использовать NIC, поскольку задержка NoC относительно велика. Перекрестная структура NIC может передавать данные за один цикл. Когда она достигает NoC, она должна быть. переносится 5-10 раз цикл. Конечно, если это видеопоток, из-за наличия конвейера он не чувствителен к задержке, если пропускная способность и приоритет достаточны. Теперь ARM запустила CCI и CCN, сетевые структуры, обеспечивающие согласованность оборудования. Первая по-прежнему является перекрестной, а вторая — кольцевой и ячеистой. Таким образом, для сценариев с требованиями к согласованности оборудования, таких как многопроцессорные группы, такие как графический процессор и процессор для гетерогенных вычислений, необходимо использовать CCI/CCN. По сравнению с CCI преимущество NoC заключается в том, что он поддерживает множество главных устройств. Из-за естественных ограничений структуры перекрестия CCI может достигать максимум 7x5, и частота не может быть увеличена дальше (1 ГГц при 16 нмFFC). CCN компенсирует ограничения CCI, и после использования ячеистой структуры частота может превышать 1 ГГц, а также обеспечивать согласованность. Ширина также достаточно велика для поддержки чередования и чередования нескольких контроллеров памяти. Таким образом, он стал сильным врагом NoC. Конечно, NoC не бесплатен. Он также может обеспечить поддержку согласованности, но задержка является большой проблемой. Естественно, он использует более длительную задержку, что очень губительно для широковещательной передачи, например, при проверке согласованности. Если процессор поддерживает множество одновременных обращений к памяти, его можно замедлить, уменьшив среднюю задержку. Однако, если число невелико, процессор может только ждать каждой передачи, что очень неэффективно. Конечно, эту проблему также можно решить, вставив дополнительные Теги на определенный узел шины и сохранив кэшированные флаги, но это уже другая история. Другие детали, такие как поддержка невыровненного доступа, меньшая степень детализации чередования, поддержка уменьшения идентификатора передачи, гибкая конфигурация буфера переупорядочения, поддержка большего количества интерфейсов, каналы только для чтения/только для записи и т. д., будут влиять на конструкцию система. . Это требует детального анализа со стороны компаний NoC и производителей SoC.
Короче говоря, сейчас наиболее распространенным использованием на мобильных телефонах и планшетах является то, что CCI соединяет ЦП и графический процессор как подсеть, и в сети обеспечивается согласованность оборудования. NoC соединяет подсеть, одновременно подключая остальные устройства, включая несколько контроллеров памяти, а также контроллеры видео и дисплея, не требуя когерентности. Преимущество заключается в том, что он учитывает согласованность, большую пропускную способность и гибкость. Недостаток заключается в том, что процессор/графический процессор к контроллеру памяти должны пересекать две сети, и задержка немного велика.
Последний шаг на пути доступа — это память. Некоторые программисты думают, что память — это устройство, все адреса которого имеют одинаковое время доступа. Так ли это? Это зависит.
Адрес DDR состоит из трех частей: строки, банка и столбца. После того, как эти три части определены, вы можете выбрать определенную физическую страницу, обычно размером 2–8 КБ. Когда мы покупаем память, есть три параметра производительности, например 10-10-10. Это представляет собой три времени операции, необходимые для доступа к адресу, достоверности строки (включая выбор банка), строба столбца (доступ к команде/данным) и предварительной зарядки. Первые два легко понять, но третий означает, что определенная физическая страница памяти временно не используется и должна быть закрыта для поддержания напряжения конденсатора, иначе данные будут потеряны, если страница будет использоваться снова. Если последовательные обращения к памяти находятся в одном и том же банке, то первую и третью 10 можно опустить, и каждый доступ занимает всего 10 единиц времени, если один и тот же банк находится в одном и том же банке, это означает, что новый; страницу нужно открыть, и только третьи 10 можно пропустить, всего 20 единиц времени, если вы находитесь в одном банке из разных банков, то нужно закрыть старую страницу и открыть новую. быть сохранено, в общей сложности 30 единиц времени.
Какой вывод мы делаем? Если вы хорошо контролируете физический адрес, вы можете сосредоточить все обращения к памяти в течение определенного периода времени на одной странице, сэкономив тем самым много времени. По опыту, при внезапных визитах можно сэкономить до 50%. Итак, как это сделать? Проверьте соответствие адресов физической памяти контактам памяти в руководстве по микросхеме, чтобы получить необходимый физический адрес. Затем вызовите системную функцию, чтобы присвоить этому физическому адресу виртуальный адрес, чтобы программа могла обращаться только к фиксированной странице физической памяти.
При доступе к некоторым структурам данных определенные размеры и смещения могут случайно вызвать ситуацию, когда разные строки находятся в одном банке. Это может быть худший сценарий для каждого посещения. Чтобы избежать этого наихудшего сценария, некоторые контроллеры памяти могут автоматически хешировать конечный адрес, нарушая исходные разные строки и одинаковые условия банка, тем самым в определенной степени уменьшая задержку. Мы также можем избежать описанной выше ситуации, рассчитав и настроив физический адрес программного обеспечения.
При фактическом доступе обычно нет гарантии, что доступ осуществляется только на одной странице. Память DDR поддерживает одновременное открытие нескольких страниц, например 4. Благодаря поочередному доступу мы можем использовать эти 4 страницы одновременно, не дожидаясь завершения предыдущей, чтобы начать доступ к следующей странице. Это уменьшает среднюю задержку. Как показано ниже:
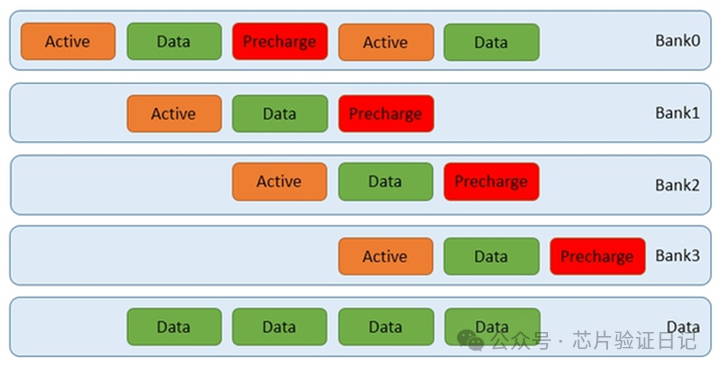
Мы можем сделать зеленые блоки данных на приведенном выше рисунке длиннее за счет пакетного доступа, и соответствующее использование будет выше. На данный момент нет необходимости даже использовать четыре банка, как показано ниже:
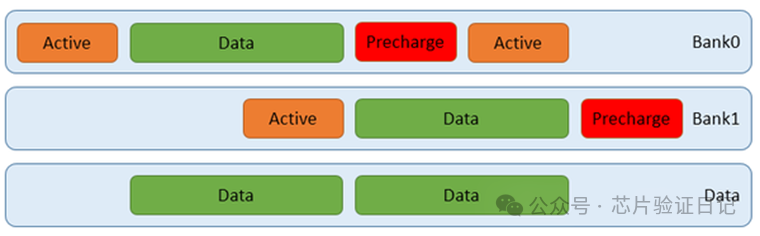
Если мы сделаем это лучше, мы сможем управлять адресом с помощью программного обеспечения, так что предварительная зарядка, показанная на рисунке выше, может быть эффективно уменьшена и может быть достигнута еще более высокая эффективность. Кроме того, неплохо было бы использовать более качественные частицы памяти, настроить параметры конфигурации, уменьшить достоверность строк, стробирование столбцов и время предварительной зарядки, а также увеличить частоту передачи данных DDR. Игроки, занимающиеся разгоном ПК, должны это понимать. Кроме того, при подключении уровня платы DDR контролируйте разницу в длине между каждым набором тактовых сигналов, линий управления и линий данных, регулируйте сопротивление проводки, выполняйте самокалибровку, устанавливайте разумные параметры контроллера памяти и настройте глазковую диаграмму. помогают улучшить качество сигнала, позволяя использовать более короткие параметры синхронизации.
Если перечислить все длины пакетов данных, то получим следующую картину:
Изображение выше содержит более интуитивную информацию. Он имитирует непрерывный доступ контроллера памяти к частицам памяти. Ось X представляет размер последовательных адресов при доступе к определенной физической странице памяти. Здесь по умолчанию предполагается, что этот адрес соответствует физической странице памяти. Ось Y показывает, сколько страниц открыто одновременно. Ось Z представляет использование полосы пропускания контроллера памяти при доступе к частицам памяти. Видим, что есть три пика, один из которых по 128 байт, с коэффициентом использования 80%. В 100% случаев длины доступа составляют 192 байта и 256 байт соответственно. Этот размер в точности кратен 64-байтовой строке кэша, что означает, что для завершения мы можем использовать три или четыре 8-битных пакетных доступа. На этом этапе нам нужно открыть как минимум 4 страницы.
Еще одна важная информация — наклон осей X и Z. По параметрам тайминга DDR он соответствует tFAW, что ограничивает количество одновременных обращений к страницам в единицу времени. Чем меньше число, тем ниже может быть производительность, но при том же энергопотреблении будет меньше.
Для разных DDR описанная выше модель будет продолжать меняться. Целью разработки контроллера DDR является максимально возможное сохранение уровня использования на уровне 100%. Для этого необходимо постоянно классифицировать, объединять и корректировать порядок полученных запросов на чтение и запись. С точки зрения программного обеспечения, генерация большего количества операций чтения и записи с выравниванием по строкам кэша, поддержание непрерывности адресов, попытка открыть открытые страницы и уменьшение переключения адресов строк и банковских адресов — все это способы уменьшить задержки доступа к памяти.
Альтернативный доступ также может улучшить производительность доступа к памяти. Чередование физических страниц было упомянуто выше, а также может быть поочередный доступ к сигналам выбора чипа. При наличии двух контроллеров памяти они также могут чередоваться между собой. Независимо от альтернативного доступа, следующая передача начинается в то же время, прежде чем будет завершен предыдущий доступ. Конечно, предпосылка должна заключаться в том, что используемое ими оборудование не конфликтует. Физические страницы, наборы микросхем и контроллеры соответствуют этому требованию. После поочередного доступа адреса, первоначально распределенные непрерывно в одном контроллере, распределяются по нескольким различным контроллерам. Конечный желаемый эффект выглядит следующим образом:
Этот метод лучше всего работает для последовательного доступа к адресу. Однако реальный доступ к памяти не так идеален, как на картинке выше, потому что даже если это непрерывное чтение, из-за существования замены вытеснения и аппаратной предварительной выборки в кеше окончательная последовательность последовательных отправленных адресов будет нарушена, и если кеш отменен и к памяти осуществляется прямой доступ, может возникнуть другая проблема: аппаратный механизм предварительной выборки и дополнительные ресурсы OT не могут быть использованы (эти два момента объяснены в разделе процессора), что делает распределение менее равномерным. По фактическим измерениям, оно может увеличиться примерно на 30%. Кроме того, из-за существования нескольких главных устройств каждое ведущее устройство генерирует разные последовательные адреса, что еще больше снижает эффект. Следовательно, только используя разделенный доступ, упомянутый в разделе о шине, мы можем действительно добиться единообразного доступа к нескольким контроллерам памяти. Конечно, длина пакета и степень детализации в этот момент должны совпадать, иначе детализация не будет равномерной, если она будет слишком большой. Более того, даже если оно однородно, оно может быть не оптимальным. Для определенного управления памятью лучше всего всегда получать запросы в пределах одной и той же физической страницы. В реальном сценарии, который я видел, разные адресные области чередовались с частицами разного размера и разными контроллерами памяти. Например, адрес от видеопроцессора разбивается на блоки по 64 байта и затем чередуется в контроллерах памяти 1 и 2. Адреса процессора не нужно чередовать или разделять. Все они обращаются к контроллеру памяти № 0. Поскольку адреса процессора относительно случайны, непрерывные адреса видео легко прервать, поэтому они не прерываются. должны чередоваться, и каждый имеет доступ к своему собственному адресу контроллера памяти.
Есть еще один момент, о котором необходимо упомянуть. Если используется память с ECC, лучше всего, чтобы все доступы были выровнены по полосе пропускания DDR (обычно 64 бита). Потому что после включения ecc все обращения к памяти выравниваются по полосе пропускания, иначе ecc невозможно вычислить. Если вы записываете данные, размер которых меньше пропускной способности, контроллер памяти должен знать, что такое исходные данные, поэтому он считывает их, изменяет их часть, вычисляет новое значение ecc и записывает их снова. Это добавляет еще один процесс чтения. По опыту, если обращений к памяти много, отключение ecc будет на 8% быстрее.
Ниже приведена оптимизация, написанная несколько лет назад и опубликованная вместе.
Оптимизация структуры процессора может начинаться со следующих направлений: попадание в кэш, прогнозирование инструкций, предварительная выборка данных, выравнивание данных, оптимизация копирования памяти, задержка доступа к DDR, оптимизация управления аппаратной памятью, оптимизация инструкций, уровень оптимизации компилятора и инструмент описания производительности.
Промахи в кэше являются одним из основных узких мест производительности процессоров. На PowerPC FSL для доступа к кэшу первого уровня требуется 3 такта, 12 для второго уровня, более 30 для третьего уровня и более 100 для памяти. Разница в скорости между кэшем первого уровня и доступом к памяти составляет более 30 раз. Можем подсчитать, что при наличии только кэша и памяти L1, 100 инструкций доступа, 100% попадания и 95% попадания, первое занимает 300 тактов, а второе 95*3+5*100=785 тактов, разница в 1,6 раза. . Предпосылкой этого результата является то, что каждое ядро PowerPC имеет только один блок доступа, поэтому несколько запусков не могут выполнить инструкции доступа быстрее. Конечно, если пропущенные инструкции хорошо распределены и перемежаются множеством других инструкций, не требующих доступа, то вы можете использовать неупорядоченные инструкции, чтобы выполнять больше задач и повышать эффективность.
Мы можем использовать прогнозирование инструкций и предварительную выборку данных.
Прогнозирование инструкций очень распространено. Процессор прогнозирует ветвь, которая будет выполнена, и сначала выбирает последующие инструкции для выполнения. Когда условия оценки действительно определены, если прогноз верен, отправьте результат. Если он неверен, отбросьте предварительно выполненные результаты и повторно получите инструкции. На этом этапе результаты по-прежнему верны, но производительность будет потеряна. Прогнозирование инструкций предназначено для уменьшения кавитации в конвейере. Невозможность прогнозирования или неправильное прогнозирование требуют очистки конвейера и повторной выборки инструкций с правильного адреса. Это наказание будет иметь большее влияние на процессоры с более глубокой глубиной конвейера, серьезно влияя на производительность процессора.
Прогнозирование инструкций обычно имеет следующие методы: предиктор ветвления (предиктор ветвления)+btb+ras (стек адресов возврата)+буфер цикла. Существует несколько комбинаций из вышеперечисленных в зависимости от типа и уровня процессора. Основная цель btb — предсказать адрес перехода инструкции перед ее декодированием. Поэтому btb в основном оптимизирован для инструкций перехода с фиксированными адресами перехода (например, переход к фиксированному адресу). Целью также является уменьшение кавитации. В противном случае, даже если переход ветвления прогнозируется при нормальных обстоятельствах, до тех пор, пока не будет декодировано, будет известно, что это команда перехода, и тогда будет инициирована выборка прогнозируемой команды на основе результата прогнозирования устройства прогнозирования ветвления. btb может инициировать выборку инструкций, сравнивая компьютер перед декодированием. Таким образом, для каждой инструкции перехода, попадающей в btb, обычно можно сохранить несколько тактов. Общий метод состоит в том, чтобы записать здесь недавние результаты перехода инструкции перехода в качестве основы для прогнозирования следующей ветки программы. Например, если цикл for выполняется 1000 раз, начиная со второго раза и заканчивая 999 раз, и каждый раз предварительно выбирается предыдущий адрес перехода, точность прогнозирования будет близка к 99,9%. Это хорошая ситуация. В плохой ситуации внутри цикла for есть if(a[i]). Предположим, что a[i] представляет собой последовательность 0,1,0,1, поэтому прогноз if будет каждый раз неверным, а эффективность предварительной выборки будет очень низкой. Метод улучшения состоит в том, чтобы разделить if на две части: одну для оценки нечетного числа раз a[i], а другую для оценки четного числа раз. Общее количество циклов уменьшается вдвое, а оценка каждого из них уменьшается вдвое. цикл удваивается, так что каждый раз он правильный. Если числа в этой последовательности заранее не видны и известно только, что они больше 0 или больше 1, то вы можете использовать ВЕРОЯТНО/НЕВЕРОЯТНО на языке C для изменения условий оценки, что также может повысить точность. Следует отметить, что записи таблицы btb будут израсходованы. Другими словами, если программа слишком долго не доходит до последней точки записи, записи будут очищены, и вам придется записывать снова при следующем запуске здесь. . Предсказание ветвей имеет интересный эффект. Если часть кода находится в ветке принятия решения, которая никогда не запускается, она все равно может повлиять на предсказание ветвей процессора, тем самым влияя на общую производительность. Если вы удалите его, вы можете обнаружить, что программа чудесным образом работает быстрее.
Предварительная выборка данных аналогична прогнозированию инструкций. Процессор сначала получает данные, которые могут быть использованы, в кэш, поэтому нет необходимости читать память позже. Он делится на два типа: программная предварительная выборка и аппаратная предварительная выборка. В аппаратном обеспечении процессор имеет собственный алгоритм, позволяющий предсказать, где получить данные. Например, при доступе к элементу структуры данных того же типа процессор автоматически выполняет предварительную выборку. следующие данные смещения. Конечно, конкретный алгоритм будет не таким простым. Предварительная выборка программного обеспечения заключается в использовании предварительно скомпилированного макроса компилятора для изменения переменной, которая будет использоваться, генерации соответствующих инструкций и ручного обращения к памяти для захвата данных, которые, по мнению программиста, будут использоваться в ближайшее время. Зачем заранее? Если предположить, что после захвата есть 100 инструкций, прежде чем данные будут фактически использованы, эти инструкции могут быть выполнены в первую очередь, а данные кэшируются, что экономит много времени.
Следует отметить, что если код не требует больших вычислительных затрат, для получения следующей инструкции доступа не потребуется 100 тактов. Скорее всего, будет один доступ к памяти на 10 инструкций. Если все промахнется, эффект предварительной выборки будет значительно снижен. Более того, не рекомендуется предварительно выбирать слишком много данных, поскольку извлекается строка кэша. Если будет выбрано слишком много данных, первоначально полезные частичные данные будут заменены. Согласно опыту, одновременно не должно выполняться более 4 предварительных выборок. Кроме того, сами инструкции предварительной выборки также занимают циклы команд. Если их слишком много, это увеличит время выполнения каждого цикла. Вы должны знать, что иногда нужно сэкономить 1% времени.
При доступе к инструкциям или данным возникает очень важный вопрос — выравнивание. Выравнивания по четырем байтам недостаточно. Лучше всего использовать выравнивание по строкам кэша, которое обычно используется при копировании памяти, DMA или назначении структур данных. Когда процессор считывает структуру данных, она выражается в строковых единицах, а длина может составлять 32 байта и более. Если структуру данных можно настроить для выравнивания строк кэша, то ее можно будет прочитать минимальное количество раз. В DMA строки кэша обычно используются в качестве единиц измерения. Если они не выровнены, будут лишние передачи или даже ошибки. Кроме того, в системе SoC при выполнении DMA на некоторых модулях устройств, если строки кэша не выровнены, то каждые 32 байта могут быть разделены на 2 сегмента для DMA соответственно, и эффективность будет удвоена.
Если используется память с ecc, выравнивание полосы пропускания DDR становится еще более необходимым. Потому что после включения ecc все обращения к памяти выравниваются по полосе пропускания, иначе ecc невозможно вычислить. Если вы записываете данные, размер которых меньше пропускной способности, контроллер памяти должен знать, что такое исходные данные, поэтому он считывает их, изменяет их часть, вычисляет новое значение ecc и записывает их снова. Это добавляет еще один процесс чтения, который происходит намного медленнее.
Другая ситуация, требующая согласования, — это назначение структуры данных. Предположим, имеется 32-байтовая структура данных, заполненная 4-байтовыми элементами. Обычная инициализация и очистка требуют 32/4=8 назначений. Есть несколько инструкций, которые могут напрямую устанавливать в строке кэша все 0 или 1. Таким образом, время становится 1/8. Что еще более важно, промах записи в кэш фактически требует чтения данных из памяти в кэш, а затем их записи. Это означает, что промахи записи занимают такое же время, как и промахи чтения. Используя эту инструкцию, инструкция сохранения может напрямую записывать все 0/1 в кэш, не считывая память. Логически это не проблема, поскольку записываемые данные (все 0/1) уже чисты, и нет необходимости читать память. Если эта строка будет заменена в будущем, данные запишутся обратно в память. Конечно, эта инструкция также имеет очень строгие ограничения. Она должна заменить всю строку кэша и не может изменить ни одного байта. На самом деле этот процесс представляет собой оптимизированную функцию memset(). Если вы скорректируете структуру больших данных, объедините все элементы, которые необходимо очистить за один и тот же период, а затем используете оптимизированный memset(), эффективность будет намного выше. Аналогично, в функции memcpy(), поскольку есть адреса источника чтения и адреса назначения записи, как упоминалось выше, могут быть два промаха и потребуется два доступа к памяти. Теперь мы можем сначала записать строку кэша (без промахов записи), затем прочитать адрес источника и записать адрес назначения, что в общей сложности составляет 1 операцию доступа к памяти. Что касается обратной записи данных, это то, что процессор сделает сам позже, так что не беспокойтесь об этом.
Аналогичным образом можно оптимизировать функции работы с памятью в стандартной библиотеке libc, а не только выравнивание по четырем байтам. Однако следует отметить, что если заданные адреса источника и назначения не выровнены по строкам кэша, то данные в начале и конце нуждаются в дополнительной обработке, иначе вся строка будет заменена, что повлияет на другие данные. Кроме того, предварительную выборку также можно комбинировать, удаляя первые и последние элементы, которые будут использоваться, а затем выполняя кучу логических суждений, что может повысить эффективность. Однако если сначала обрабатывается хвост, то при перекрытии памяти содержимое адреса источника будет перезаписано, на что необходимо обратить внимание. Если программисты проекта соглашаются использовать выравнивание строк кэша, это также может повысить эффективность библиотеки C.
Если вы определите, что определенные строки кэша не будут использоваться в будущем, вы можете использовать инструкции, чтобы пометить их как недействительные, и в следующий раз они будут заменены первыми, оставляя место для других. Но вся линия должна быть заменена. Другой момент заключается в том, что вы можете использовать некоторые 64-битные регистры с плавающей запятой и инструкции для чтения и записи, что может быть быстрее, чем 32-битные регистры общего назначения.
Давайте поговорим об оптимизации доступа к DDR. Обычно инженеры-программисты думают, что память — это устройство, все адреса которого имеют одинаковое время доступа. Так ли это? Это зависит. Когда мы покупаем память, есть три параметра производительности, например 10-10-10. Это представляет собой три времени операции, необходимые для доступа к адресу, стробу строки, задержке данных и предварительной зарядке. Первые два легко понять, но третий означает, что эта страница или блок не будут использоваться при следующем доступе к нему. Он должен быть закрыт для поддержания напряжения конденсатора, иначе данные будут потеряны при использовании этой страницы. снова. Адрес DDR состоит из трех частей: столбца, строки и страницы. Согласно этому принципу, если последовательные обращения происходят на одной и той же странице в одном ряду, каждый занимает всего 10 единиц времени на одной и той же странице в разных строках, 20 единиц на разных страницах в одной строке, 30 единиц; Итак, какой вывод мы делаем? Соседние структуры данных следует размещать на одной странице, и следует избегать появления разных страниц в одной строке. Как это рассчитать? У каждого процессора есть руководство. Просто найдите сопоставление адресов физической памяти с выводами памяти и сделайте вывод. Кроме того, DDR также имеет пакетный режим. Примером может служить DDR3. При 64-битной полосе пропускания за одной командой могут следовать 8 операций чтения, которые могут одновременно заполнить 64-байтовую строку кэша. В крайнем случае (доступ к той же странице) среднее время доступа к байтам составляет всего 10/64, что в три раза хуже, чем в худшем случае — 30/64 байт. Конечно, с памятью есть много хитростей, таких как намеренное хеширование адресов для предотвращения доступа в худшем случае, одновременный запуск двух контроллеров памяти, чередование адресов для формирования доступа к конвейеру и т. д. и т. п., и все это методы оптимизации. . Однако обычно из-за существования планировщика адреса запускаемых нами программ являются относительно случайными и не требуют такой оптимизации. Оптимизация иногда имеет негативные последствия. Кроме того, если все данные используются только один раз, то узким местом становится пропускная способность доступа к памяти, а не кеш. Таким образом, видеокарта не уделяет особого внимания размеру кэша. Конечно, у него также есть файл регистров, похожий на кэш, но не такой большой.
Каждый современный процессор имеет аппаратный блок управления памятью. Если говорить прямо, он выполняет две функции: обеспечение сопоставления адресов при поступлении виртуальных адресов и сопоставление реальных адресов периферийным модулям. Неважно, насколько сложно определение каждого поля, просто позаботьтесь о том, каким данный виртуальный адрес в конечном итоге станет реальным адресом. Здесь хотелось бы сказать, что модуль управления памятью powerpc действительно создан лаконичным и понятным. По сравнению с ним x86 слишком многословен и требует совместимости с таким количеством режимов. Конечно, обойти это невозможно. Процессорам в области связи не нужна особая совместимость. Обычно оптимизация управления памятью, которую мы можем использовать, заключается в определении большой аппаратной таблицы страниц и включении всех адресов, которые необходимо часто использовать, чтобы не было пропущенных страниц, а время вызовов исключений отсутствия страниц и поиска в таблице страниц было сохранено. . Это может значительно повысить эффективность в определенных ситуациях.
Вот самый медленный Памятьдоступ:L1/2/3кэш Непредвиденный->таблица страниц оборудования Непредвиденный->Код исключения ошибки страницы отсутствуеткэш->прочитать код->Таблица страниц программного обеспечения отсутствуеткэш->Чтение таблицы страниц программного обеспечения->последнее чтение。в то же время,Если данные, к которым осуществляется доступ на каждом этапе, согласованы на нескольких ядрах,Каждый раз интерфейсный автобус также тратит более десяти тактов на уведомление каждого ядра о кэше.,Проверьте, нет ли грязи. Обведите вот так,Требуется несколько тысяч тактов. Если часто происходит самый медленный доступ к Память,Предыдущая оптимизация очень полезна,Сэкономьте десятки раз времени. Пожалуйста, обратитесь к руководству процессора для получения информации о конкретных методах отображения.,Нечего сказать.
Существует множество оптимизаций инструкций, и у каждого процессора их немало. Общие из них включают в себя одну инструкцию, несколько потоков данных, инструкции по конкретным операциям, инструкции ветвления и т. д. Вам необходимо прочитать руководство каждого процессора, которое очень подробно. У меня есть данные здесь, быстрое преобразование Фурье. Если вы используете мягкую плавающую запятую на powerpc, производительность равна 1, тогда вы используете встроенный сопроцессор векторной арифметики (вычислительная мощность невелика, это недорогая замена модуля). устройства с плавающей запятой) Наконец, gcc автоматически компилируется, и производительность повышается в 5 раз. Затем мы вручную написали библиотеку функций оптимизации сборки и широко использовали векторные инструкции, что повысило производительность еще в 14 раз. 70-кратного улучшения достаточно, чтобы показать важность чистой оптимизации инструкций.
GCC имеет три или четыре уровня оптимизации. Как правило, использование O2 является лучшим балансом. O3 может нарушить первоначальный порядок работы программы, что усложнит отладку. Вы можете посмотреть справку GCC, в которой описаны каждую оптимизацию, поэтому я не буду здесь вдаваться в подробности. При компиляции можно попробовать оба варианта. Может быть разница в несколько процентов.
Наконец, существует инструмент описания производительности. В Linux наиболее часто используемыми являются KProfile/OProfile. Его принцип состоит в том, чтобы попасть в точку в определенное время, чтобы увидеть, куда продвинулась программа, и сообщить вам статистические результаты через достаточное время. Отсюда мы можем узнать, какие функции в программе являются горячими точками, какую долю времени выполнения они занимают и каков IPC конкретного кода. IPC означает количество инструкций за цикл. На PowerPC с двойным запуском теоретический максимум равен 2. На самом деле было бы очень хорошо, если бы общее значение достигло 1,1. Если оно слишком низкое, необходимо искать конкретные причины. В этом отношении недостаточно полагаться на Profile. Он не может точно подсчитать попадания в кэш, количество командных циклов, частоту попаданий в предсказание ветвей и т. д., а точность невысока, что иногда может вводить в заблуждение. В это время вам необходимо использовать регистр статистики производительности, который поставляется вместе с процессором. В руководстве по процессору будет подробно описано использование. Используя эти данные, мы продолжим улучшать и сравнивать результаты, чтобы наконец достичь желаемого эффекта.
Очень важно, что мы не можем полагаться на инструменты как на единственное средство суждения. Часто бывает необходимо оптимизировать один или несколько более высоких уровней. Например, после упорной работы над оптимизацией алгоритма для максимального использования процессора и повышения производительности на 20% оказывается, что сложность самого алгоритма слишком высока. Если алгоритм улучшить, улучшение может быть в несколько раз. выше. Также перед оптимизацией необходимо сначала иметь четкое представление о потоке данных, а затем использовать инструменты для подтверждения этого понимания. Точно так же, как при проектировании внешнего цифрового модуля, вы должны сначала иметь в виду приблизительную модель, а затем использовать язык описания для ее реализации, а не писать код и всесторонне анализировать результаты.
В этом разделе методы повышения скорости передачи включают:
Выравнивание кэша для сокращения времени доступа Последовательность доступа к памяти перепланируется, и аналогичные адреса объединяются для повышения эффективности. Увеличьте частоту DDR, чтобы уменьшить задержку. Увеличение пропускной способности с помощью нескольких контроллеров Включить объединение команд чтения и записи ddr3 Включите пакетный режим, чтобы разрешить доступ к строке кэша за один раз. Предварительная выборка инструкций и данных для улучшения использования простоя Если в памяти есть ecc, для записи используйте ту же инструкцию, что и разрядность памяти (например, 64 бита), в противном случае потребуется дополнительная операция чтения. Контроллеры осуществляют доступ поочередно. Например, первые 64-битные данные, к которым осуществляется доступ, помещаются в первый контроллер памяти, а вторые, к которым осуществляется доступ, во втором контроллере, так что их можно располагать в шахматном порядке. Хеширование физических адресов предотвращает многократное открытие и закрытие слишком большого количества банков DDR. Существует также хитрый трюк: вычислить физический адрес и поместить соответствующую структуру данных на одну и ту же физическую страницу DDR, чтобы уменьшить вероятность шагов 1 и 3 на трех ключевых этапах передачи DDR (выбор строки, команда, предварительная зарядка). .
Ссылки:
https://blog.csdn.net/weixin_50518899/article/details/135817574
https://blog.csdn.net/eric43/article/details/102499056



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
