Observable Platform-2: решение с открытым исходным кодом
Обзор
Создание системы мониторинга и сигнализации для сложной прикладной системы включает в себя множество компонентов, таких как внешний интерфейс, API на различных внутренних языках, шлюзы, очереди сообщений (MQ), кеши (Cache) и базы данных (DB). Автоматическое построение диаграммы топологии компонентов прикладной системы и корреляция состояний соответствующих компонентов — сложный процесс, обычно требующий следующих шагов:
- Сбор и интеграция данных Во-первых, вам необходимо убедиться, что все компоненты (интерфейсные, серверные службы, шлюз API, MQ, кэш, БД и т. д.) могут генерировать данные мониторинга. Используйте такие инструменты, как Prometheus, Graphite и т. д., для сбора данных мониторинга этих компонентов. Для сбора и анализа данных журналов вы можете использовать ELK Stack (Elasticsearch, Logstash, Kibana) или Fluentd.
- Обнаружение сервисов и автоматическое рисование топологии Используйте инструменты обнаружения сервисов (такие как Consul, Zookeeper и т. д.) для динамической идентификации различных компонентов в системе. Используйте механизмы обнаружения сервисов в инструментах мониторинга (таких как функция обнаружения сервисов Prometheus) для автоматического выявления и мониторинга новых или измененных сервисов. Используйте специализированные инструменты (такие как Dynatrace, Datadog) или пользовательские сценарии для отображения топологии компонентов вашего приложения.
- Мониторинг производительности и оповещение Настройте правила мониторинга производительности и сигналов тревоги в инструментах мониторинга (таких как Prometheus, Grafana). Убедитесь, что ключевые показатели производительности каждого компонента (такие как время отклика, частота ошибок, пропускная способность и т. д.) отслеживаются, а также установлены разумные пороговые значения сигналов тревоги. Для управления сигналами тревоги вы можете использовать Alertmanager или другие инструменты управления сигналами тревоги, чтобы настроить маршрутизацию сигналов тревоги, подавление дубликатов и методы уведомления.
- Ассоциация и отображение статуса В Grafana или аналогичном инструменте визуализации создайте информационные панели, которые отображают состояние и показатели производительности каждого компонента. Используйте диаграммы топологии, чтобы показать зависимости между компонентами и визуально отразить состояние работоспособности компонентов на диаграмме. Интеграция журналов и данных о производительности обеспечивает более полное представление о системе в едином интерфейсе.
- трассировка ссылок Для процесса запросов в распределенной системе используйте инструменты отслеживания ссылок (такие как Jaeger, Zipkin) для отслеживания и записи потока запросов между службами. Данные трассировки каналов могут помочь выявить узкие места производительности и точки сбоя.
- Тестируйте и оптимизируйте После развертывания системы мониторинга и сигнализации проведите достаточное тестирование, чтобы гарантировать, что состояние всех компонентов можно точно отслеживать и своевременно подавать сигналы тревоги. Корректируйте стратегии мониторинга и пороговые значения сигналов тревоги на основе реальных условий эксплуатации, чтобы обеспечить эффективность и точность системы мониторинга. Благодаря этим шагам можно построить комплексную систему мониторинга и сигнализации, которая может не только автоматически рисовать и обновлять диаграмму топологии компонентов прикладной системы, но также коррелировать и отображать состояние каждого компонента в режиме реального времени, тем самым эффективно поддерживая работу. и обслуживание сложных прикладных систем.
Интеграция программного обеспечения с открытым исходным кодом
Для систем мониторинга и оповещения, обсуждавшихся выше, существует несколько вариантов программного обеспечения с открытым исходным кодом, которые могут помочь в создании комплексного решения для мониторинга. Вот некоторые из основных инструментов с открытым исходным кодом:
Инструменты с открытым исходным кодом, такие как ClickHouse, Neo4j, VectorDB, PromQL, LogQL, OpenTracing, Prometheus, Grafana, AlertManager и DeepFlow.
Эти инструменты можно интегрировать друг с другом для создания комплексной системы мониторинга и оповещения, охватывающей все аспекты от внешнего до внутреннего интерфейса и от уровня приложений до уровня данных. Выбор правильной комбинации инструментов зависит от конкретного сценария приложения, технологического стека и требований к производительности. Решение платформы наблюдения с открытым исходным кодом автоматизирует предоставление сервисов создания через GitHub Actions.
Ссылка на проект:https://github.com/open-source-solution-design/ObservabilityPlatform.git
Схема архитектуры

В этом решении используется следующее программное обеспечение с открытым исходным кодом:
- Сбор данных: Синхронизируйте данные из системных компонентов, приложений и облачных учетных записей с помощью таких инструментов, как Prometheus, OpenTelemetry, Deepflow-agent, Promtail, CloudQuery и т. д.
- Хранение данных: используйте ClickHouse, Neo4j, VectorDB и другие инструменты для хранения данных наблюдений.
- Анализ данных: используйте такие инструменты, как Prometheus и Grafana, для анализа данных наблюдений.
- Визуализация данных: используйте такие инструменты, как Grafana, для визуального представления наблюдаемых данных.
Он может предоставлять информацию о состоянии ресурсов, производительности и надежности системы или приложения, диагностировать и решать проблемы, оптимизировать производительность системы или приложения, а также функциональный анализ и т. д., включая следующие сценарии применения:
Преимущества
- Открытый исходный код: решение использует инструменты с открытым исходным кодом.,Поэтому стоимость низкая.
- Масштабируемость: решение использует масштабируемый стек технологий, поэтому может удовлетворить различные потребности.
- автоматизация:Долженрешениеиспользовать GitHub Actions Автоматизированная доставка создает сервисы, которые можно быстро развертывать и обслуживать.
CICD
Файл конфигурации конвейера
Файл конфигурации находится по адресу .github/workflows/pipeline.yaml и состоит из четырех этапов:
- Тест сборки. На этом этапе приложение создается из исходного кода и запускается набор тестов, чтобы убедиться, что приложение работает правильно.
- Образ Docker: на этом этапе создается образ Docker, содержащий приложение.
- Настройка K3s. На этом этапе настраивается кластер K3s на удаленном сервере.
- Развертывание приложения. На этом этапе приложение развертывается в кластере K3s.
Описание роли Playook
- Библиотека конфигурации платформы наблюдения предоставляетсяк Следующий ролевой состав:
- Контейнерный кластер Связанный Связанныйиз Ansible playbook roles
- k3s: Обеспечить управление k3s Кластерные задачи.
- k3s-addon: развертывать k3s Дополнения.
- k3s-reset: Воля k3s Кластер возвращается в исходное состояние.
- secret-manger: развертывать secret-manager для управления конфиденциальными данными.
- cert-manager: развертывать cert-manager выдавать TLS Сертификат.
- clickhouse: развернуть Clickhouse хранит и анализирует данные временных рядов.
- observability-agent: существует развертывание агента наблюдения на узлах k3s.
- observability-server: развернуть наблюдаемость Служить серверный компонент.
- mysql: развертывать MySQL хранить Данные Deepflow и информация о конфигурации Grafana.
- alerting: хранилище Prometheus Alertmanager Rules 。
- Неконтейнерный кластер Связанныйиз Ansible playbook roles
- node-exporter: развертывать node_exporter для сбора системных метрик.
- prometheus-transfer: Вперед Передача индикатора Прометея Воля на удаленную хранилище.
- promtail-agent: развертывать Promtail Собирайте логи с узлов.
- Контейнерный кластер Связанный Связанныйиз Ansible playbook roles
курок
Конвейеры запускаются следующими событиями:
- Когда запрос на включение открыт или обновлен.
- Когда код отправляется в главную ветку.
- Когда рабочий процесс планируется вручную.
переменные среды
Переменные ENV, определенные в файлах YAML или конфигурациях конвейера CI/CD:
- TZ: Азия/Шанхай: установите часовой пояс Азия/Шанхай.
- REPO: «artifact.onwalk.net»: укажите URL или идентификатор библиотеки хранилища.
- IMAGE: base/${{ github.repository }}: имя образа контейнера, созданного на основе хранилища GitHub.
- ТЕГ: ${{ github.sha }}: Воля зеркального тега настройки фиксации SHA для репозитория GitHubхранилище из.
- DNS_AK: ${{ secrets.DNS_AK }}: используйте ключ GitHub, чтобы установить ключ доступа к DNS Alibaba Cloud.
- DNS_SK: ${{ secrets.DNS_SK }}: используйте ключ GitHub для установки DNS-ключа Alibaba Cloud.
- DEBIAN_FRONTEND: неинтерактивный: Воля Настройка интерфейса Debian находится в неинтерактивном режиме.,Этот существующий скрипт автоматизации очень полезен,Интерактивные подсказки можно запретить.
- HELM_EXPERIMENTAL_OCI: 1: включить экспериментальную поддержку OCI (Open Container Initiative) в Helm, что позволяет использовать Helm с образами OCI.
Если вы хотите запустить эту демо-версию в своей учетной записи, вам нужно всего лишь https://github.com/open-source-solution-design/ObservabilityPlatform.git Форкнуть этот склад Перейдите в свою учетную запись Github и одновременно
Settings -> Actions secrets and variables: Что необходимо определить для добавления конвейера secrets переменная
Server Связанный secrets переменная
- HELM_REPO_USER Имя пользователя для аутентификации хранилища артефактов
- HELM_REPO_REGISTRY Адрес сертификации склада артефактов
- HELM_REPO_PASSWORD Пароль аутентификации хранилища артефактов
- HOST_USER развертыватьK3Sиз Имя пользователя для входа в ОС хоста
- HOST_IP развертыватьK3SизIP-адрес хоста
- HOST_DOMAIN развернутьK3Sдоменное имя хоста
- SSH_PRIVATE_KEY Закрытый ключ SSH хоста, который обращается к K3S.
- DNS_AK Alibaba Cloud DNS Service AK (используется для автоматической выдачи SSL-сертификатов и обновления записей разрешения, а также публикации входящего трафика)
- DNS_SK Alibaba Cloud DNS Service SK (используется для автоматической выдачи SSL-сертификатов, обновления записей разрешения и публикации входящего трафика)
клиент Связанный secrets переменная
- APP_HOST_USER развертыватьAPPкластеризmaster Имя пользователя для входа в ОС хоста
- APP_HOST_IP развертыватьAPPкластеризmaster IP-адрес хоста
- APP_HOST_DOMAIN развертыватьAPPкластеризmaster IP-доменное имя хоста
Когда все будет готово, вы сможете это увидеть. В этом рабочем процессе CI образ автоматически завершается и отправляется в специальное хранилище, упаковывается, после чего завершается инициализация кластера K3S, а также развертывание приложения в кластере K3S.
Конфигурация после развертывания
Конфигурация сервера
- Конфигурация источника данных к https://grafana.onwalk.net Например, к admin Логин, данные sources -> Add new data sources Вы можете выбрать соответствующий тип источника данных для доступа в соответствии с вашими потребностями.
- Импортировать настройки Dashboard, загрузить Dashboard Json Файл шаблона, выберите соответствующий источник данных ObservabilityPlatform Репозиторий предоставляет для справки несколько панелей от сообщества. https://github.com/open-source-solution-design/ObservabilityPlatform/blob/main/charts/server/example/dashboard/ Grafana Сообщество предлагает многоизпанель,Вы можете выбрать в соответствии с вашими потребностями,
- Настройка нескольких кластеров deepflow-agent Конфигурация требует, чтобы сначала существовала сторона Сервера, используя deepflow-ctl domain create получить K8sClusterID:
unset CLUSTER\_NAME
CLUSTER\_NAME="k8s-1" # FIXME: K8s cluster name
cat << EOF | deepflow-ctl domain create -f -
name: $CLUSTER\_NAME
type: kubernetes
EOF
deepflow-ctl domain list $CLUSTER\_NAME # Get K8sClusterID- Конец коллекции
Настройте дополнительный доступ к кластеру, выполните шаг 2, запишите K8sClusterID и deepflowserverip и запишите их в playbook/init_observability-agent, а затем выполните конвейер .github/workflows/setup-agent.yaml.
демонстрационный пример
Запрос журнала

Состояние ресурса узла узла
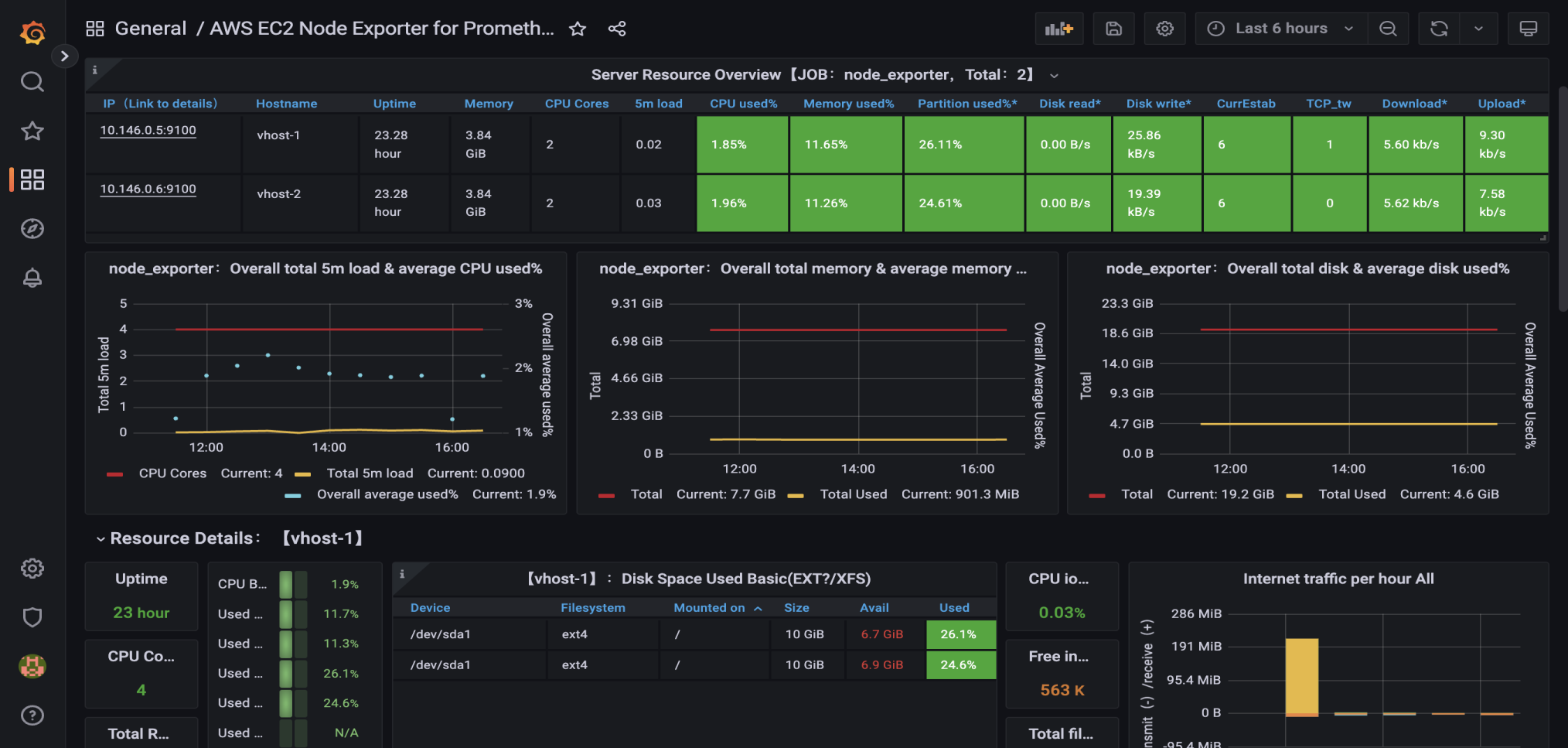
Статус ресурса приложения кластера
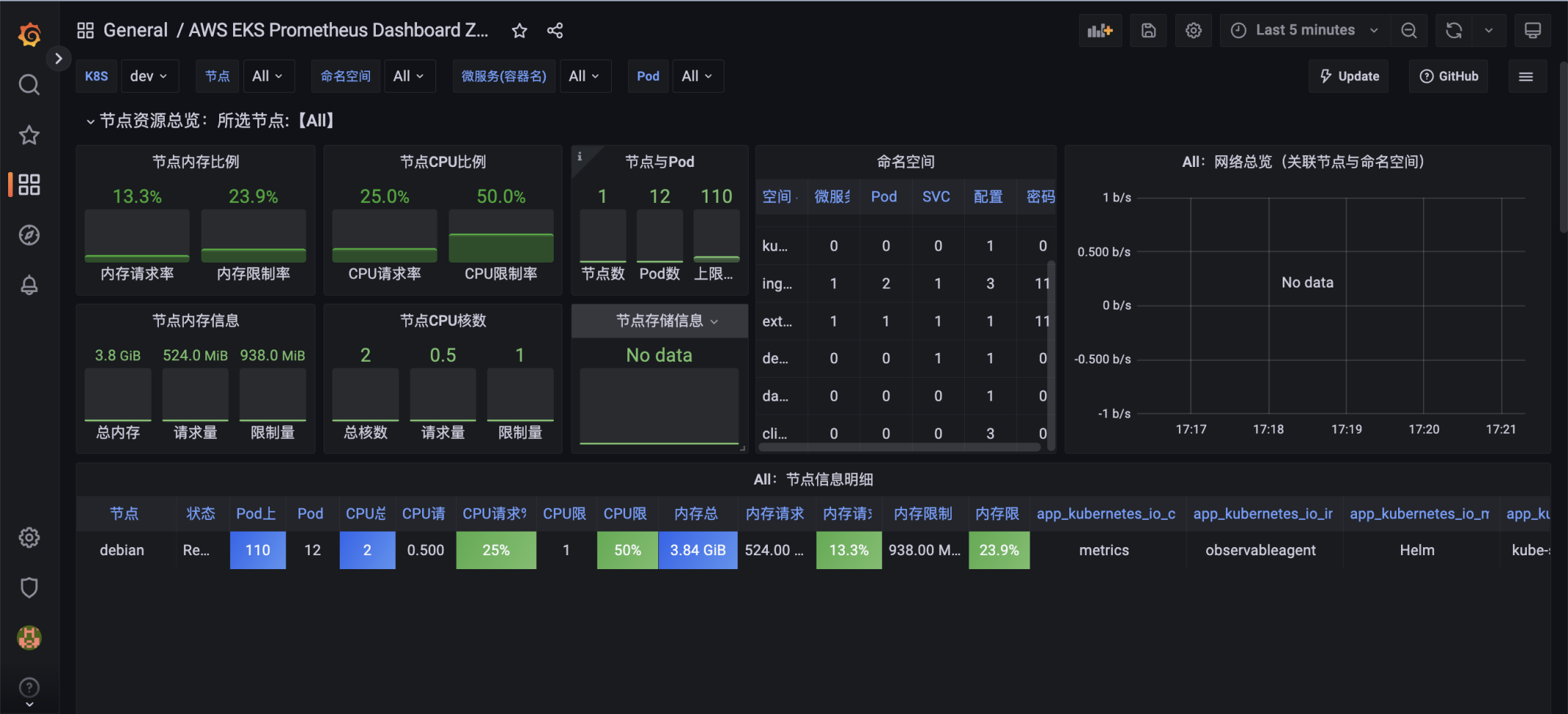
Карта топологии ресурса
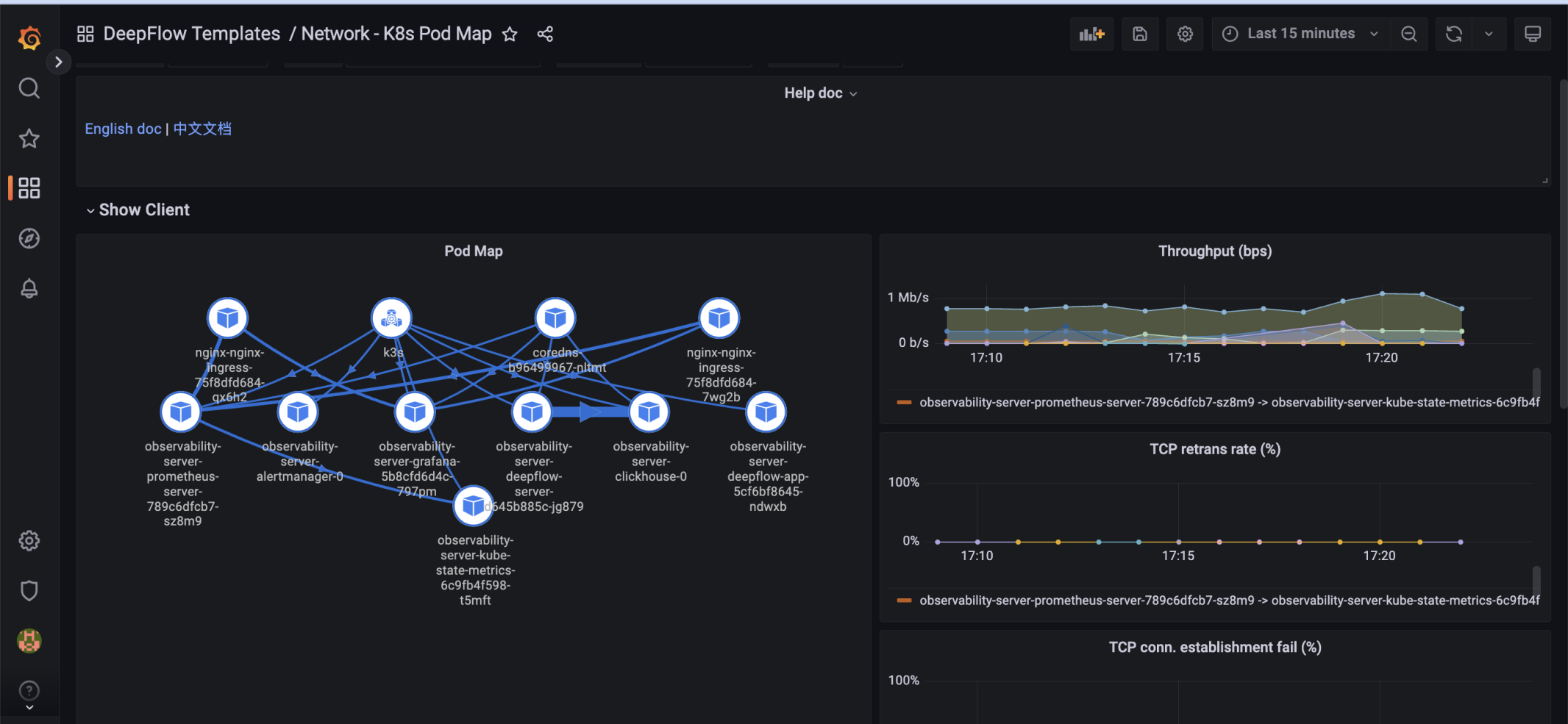
Наблюдение за производительностью сети
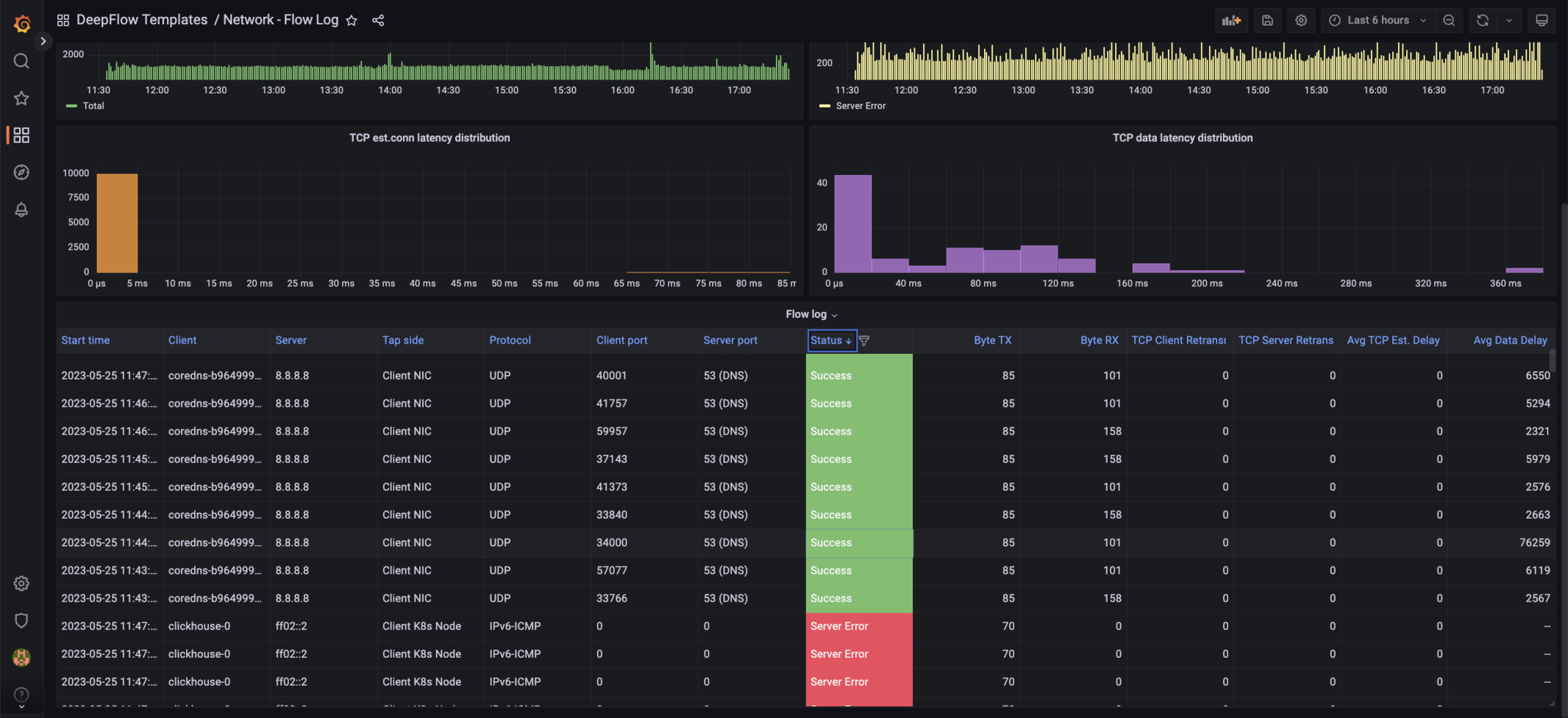
Мониторинг доступности услуг

Справочный раздел
API Endpoint
name | URI |
|---|---|
querying(promql, logql, tempo) | http://data-gateway.<domian> |
metrics_query | https://prometheus.<domian>/api/v1/query |
metrics_remote_write | https://prometheus.<domian>/api/v1/remote/write |
logql_remote_write | https://data-gateway.<domian>/loki/api/v1/push |
traces_tempo_push | https://data-gateway.<domian>/tempo/api/push |
traces_zipkin_push | https://data-gateway.<domian>/api/v2/spans |
traces_oltp_push | https://data-gateway.<domian>/v1/traces |
Благодарности
- Сообщество открытого исходного кода: Нет сообщества открытого исходного кода для обмена,Самостоятельно выполнить сложное техническое решение невозможно. Спасибо всем участникам сообщества открытого исходного кода.,ихиз Тяжелая работа дает нам ценныеизресурси Знание。
- Prometheus:Prometheus Это ведущая система мониторинга с открытым исходным кодом. мы используем Prometheus приди и собериихранилищенаблюдаемые данные。
- Grafana:Grafana является ведущим инструментом визуализации с открытым исходным кодом. мы используем Grafana для визуализации данных наблюдения.
- AlertManager:AlertManager Это ведущая система сигнализации с открытым исходным кодом. мы используем AlertManager для отправки оповещений о данных наблюдения.
- DeepFlow:DeepFlow Это программное обеспечение с открытым исходным кодом, разработанное Yunshan Technology на основе eppf. Примените программное обеспечение для анализа наблюдаемости.
- GCP Cloud: Нет Google Щедрые 300 долларов Бесплатные ресурсы для тестирования, невозможно завершить проверку решения
- Платформа разработчика Tencent: Платформа разработчика Tencent предоставляет нам платформу для обмена. Благодарим вас за поддержку, оказанную платформой разработчика Tencent.
Я участвую в третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 с эссе, получившими приз, и сформирую команду, которая разделит приз!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
