Общие сведения о тестировании производительности в одной статье
Концепции тестирования производительности
Концепции, которые мы часто видим тестирования производительности, некоторые называют это стратегией производительности или производной метод истительности, или также известный как классификация сцен производительности, вы, вероятно, можете увидеть Тестирование производительности、нагрузочный тест、стресс-тест、Тест интенсивности и другие объяснения кучи имен собственных.
Что касается этих концепций, я не знаю, почувствуете ли вы то же, что и я, когда увидите их: хаос! Небольшой тест производительности расширяет так много концепций, а границы между концепциями очень размыты.
Возьмем три понятия: «стресс-тестирование», «тестирование мощности» и «тестирование пределов».
Объяснения этим трем терминам в Интернете следующие:
стресс-тест Стресс-тест – это оценка работы системы при нагрузке, равной ожидаемой или превышающей ее. стресс-тест – сосредоточиться на Дело в том,система Возможности обработки при пиковой нагрузке или превышении максимальной нагрузки。Поскольку уровень стресса постепенно увеличивается,системапроизводительность должна медленно снижаться, как и ожидалось,Но оно не должно развалиться. стресс-тест также может найти критическую точку краха системы,Тем самым обнаруживая слабые звенья в системе.
Тест емкости Определите максимальное количество одновременных пользователей, которые может обрабатывать система, и задействуйте в системе избыточную емкость данных, чтобы выяснить, сможет ли она справиться с этим правильно.
Экстремальное тестирование Нагрузочное тестирование при чрезмерном количестве пользователей.
«Стресс-тест — это работа системы при превышении ожидаемой нагрузки», «Тестирование мощности — это работа системы при избыточной емкости данных с целью определить, сможет ли она правильно с ней справиться».
Да ладно, даже если я плохо говорю по-китайски, я все равно умею читать. Может кто-нибудь сказать мне, в чем разница между ними? Только слова другие.
Если говорить об этих понятиях на более абстрактном уровне, то они описывают разные аспекты тестирования производительности. Однако сами по себе эти аспекты не представляют собой стратегии или методы. Их нельзя назвать концепциями или теориями.
Как только эта статья будет опубликована, кто-то обязательно скажет: раз уж вы прокомментировали нынешнюю концептуальную путаницу, какие у вас есть хорошие предложения? Поскольку тема, которую можно подвергнуть коллективной бомбардировке, теперь, когда она вынесена на обсуждение, я все еще рискую своей жизнью, чтобы дать то, что я считаю разумным определением:
Тестирование производительности направлено на показатели производительности системы, устанавливает модели тестирования производительности, формулирует планы тестирования производительности, разрабатывает стратегии мониторинга, выполняет сценарии производительности в условиях сценария, анализирует и определяет узкие места производительности и настраивает их и, наконец, получает результаты производительности для оценки показателей производительности системы. он соответствует установленному значению.
Это единственное разумное определение понятия, которое я думаю, я подробно объясню это понятие ниже.
Для тестирования производительности необходимы индикаторы
Некоторые говорят, что когда мы работаем над проектом, нет показателей. Начальник говорит только одно, и система будет перегружаться, пока ее не раздавят. Звучит по-детски, но такие сцены не редкость. На мой взгляд, развал системы – это тоже показатель. Что касается того, какие средства вы используете для «подавления» системы, это вопрос реализации. Вы можете использовать множество методов, чтобы сказать своему начальнику, что система мертва, прежде чем ее можно будет подавить! Это и ваш вклад.
Что касается определения «наличия индикаторов», то индикаторами, которые теоретически обоснованы и должны быть включены, являются: индикаторы времени, индикаторы мощности и индикаторы использования ресурсов.
И показатели здесь будут разделены, а понятие подразделения — путаница. Эту тему мы опишем позже.
Для тестирования производительности требуется модель
Какова модель? Это абстракция реального сценария, которая может рассказать тестировщику производительности о том, как выглядит бизнес-модель. Например, у нас есть 100 типов бизнеса, но не каждому бизнесу необходимо иметь параллелизм. Может быть, только у 50 предприятий он есть. Тогда нам нужно посчитать эти предприятия с параллелизмом. Это соотношение? следует контролировать, когда он находится под давлением.
Данные, необходимые для этого подхода, обычно собираются из данных в производственной среде. Многие компании, которые не решаются напрямую проводить стресс-тестирование в режиме онлайн, делают это.
С всесторонним развитием розничной торговли и облачной инфраструктуры в Интернете некоторые компании напрямую перенаправляют онлайн-трафик для тестирования производительности. Это изменение в мышлении происходит из-за развития архитектуры и реальных потребностей отрасли. Но это не значит, что для тестирования производительности не требуется модель, поскольку эта модель импортирована из производственного трафика. Вам все равно придется это признать.
Но для некоторых других отраслей, таких как финансовые учреждения и банки, никакая онлайн-транзакция не может быть неправильной. Было бы слишком сложно сделать это, как описано выше. Поэтому в этих отраслях по-прежнему необходимо использовать бизнес-модели в тестовой среде для моделирования производственного трафика.
В то же время, пожалуйста, поймите, что нынешний стресс-тест полнофункциональной связи не так хорош, как о нем хвастаются. Многие компании лишь оказывают давление на онлайн-аппаратные ресурсы, и это не настоящая модификация логической ссылки.
Меня часто спрашивают на работе, если трафик производительности направляется из продакшена, можно ли отказаться от тестеров производительности? Будут ли исключены тестеры производительности?
Это слишком недальновидно. Все ориентированы на новейшие технологии, методы и концепции. Лидеры всех уровней также имеют свои предпочтения в знаниях. Если будет принято решение, которое повлияет на конечный результат, оно может повлиять на многих людей. .
В команде, которую я возглавлял раньше, архитекторы разработки с самого начала планировали очень подробную микросервисную архитектуру и говорили, что она очень хороша. Я говорю, что вы решаете это сами, мне просто нужно получить здесь полезные результаты. В результате менее чем за два месяца разработки все микросервисы были объединены, и нам приходилось каждый день работать сверхурочно, чтобы реконструировать систему, оставив лишь несколько основных компонентов среднего уровня. Почему это? Потому что это не применимо.
Точно так же при тестировании производительности следует выбирать метод, который соответствует бизнес-логике вашей собственной системы, и выполнять действия с наименьшими затратами и в кратчайшие сроки.
Тестирование производительности требует плана
В содержании, предусмотренном планом, есть несколько ключевых моментов, а именно: тестовая среда, тестовые данные, тестовая модель, показатели производительности, стратегия давления, вход и выход, а также плановый риск. В принципе, достаточно иметь это содержимое, но конкретная информация об этом содержании должна быть точной.
Вы можете сказать, почему нет плана тестирования? Я предлагаю использовать инструмент управления проектами для отдельного составления плана тестирования, например, с помощью такого инструмента, как Project или OmniPlan. Это связано с тем, что в плане при написании плана тестирования можно, по сути, написать только одну веху. Если быть более детальным, в него можно добавить несколько крупных этапов. Но планирование с помощью инструмента управления проектами отличается. Он может не только подразделять элементы, но и отслеживать динамический ход каждой работы. Вы можете устанавливать и уменьшать зависимости, а также заполнять ресурсы и затраты для расчета отклонений проекта.
Требуется мониторинг во время тестирования производительности
Мониторинг этой части должен иметь возможности многоуровневого и сегментированного мониторинга, а также возможности глобального мониторинга и направленного мониторинга. Я объясню это подробно в третьем модуле.
Тестирование производительности должно иметь заранее определенные условия.
Условия здесь включают программную и аппаратную среду, данные испытаний, стратегию выполнения испытаний, компенсацию давления и т. д. В целях расширения эти условия следует определить до выполнения сценария.
Некоторые говорят, что мы также динамично расширяемся в условиях стресса. Нет проблем, но условия или условия оценки для динамического расширения также имеют определенные стратегии. Например, когда мы считаем, что загрузка ЦП достигает 80% или время отклика ввода-вывода достигает 10 мс, мы выполним динамическое расширение. Это тоже заранее определенные условия.
Что касается этого момента, то в своем опыте работы я часто встречаю инженеров по тестированию производительности, которые не имеют четкого представления о программных и аппаратных ресурсах, тестовых данных и стратегиях выполнения и даже не понимают, почему на добавление нескольких потоков уходит несколько минут. В этом случае нельзя ожидать, что сценарий будет эффективным.
В тестировании производительности должны быть сценарии
Можно сказать, что термин «сценарий производительности» занимает центральное место в тестировании производительности, но многие из нас не понимают, как следует определять «сценарий». Сценарий происходит от английского сценария. Более достоверное описание «сценария» в сценарии производительности звучит так: в установленной среде (включая динамическое расширение и другие стратегии), установленные данные (включая изменения данных во время выполнения сценария), установленное выполнение. стратегии, выполнять сценарии производительности под установленным мониторингом, наблюдать за изменениями параметров состояния производительности на каждом уровне системы и определять в режиме реального времени, соответствует ли сценарий анализа ожиданиям.
Это настоящая сцена.
Сценарии производительности также необходимо классифицировать. По моему ограниченному опыту работы, сценарии производительности никогда не выходили за рамки этих категорий.
- Сценарий эталонной производительности: здесь речь идет о емкости одной транзакции.,Подготовьтесь к смешанной мощности (не говорите мне, что запуск сценария три или пять раз в нескольких потоках называется эталонным тестом).,по моему мнению,Это просто предварительное выполнение перед выполнением сцены.,Используется для определения наличия каких-либо основных проблем со сценарием и дизайном сцены.,Это нельзя назвать классификацией).
- Сценарий производительности мощности: эта ссылка должна быть основной частью выполнения производительности. В зависимости от сложности бизнеса,Эта часть сцены будет спроектирована с использованием множества,Я не буду подробно останавливаться на концептуальной части.,Я подробно расскажу об этом в следующей статье.
- Сцена стабильности производительности: Тест стабильности должен представлять собой классификацию сцены производительности. Только сейчас в реальном проекте,Стабильность в принципе не соответствует производству. в тесте стабильности,Очевидно, что ключевым элементом является время (бизнес-модель была определена в сценарии мощности).,Настройка времени должна исходить из цикла эксплуатации и технического обслуживания.,Вместо психологической безопасности, которая исходит от начальников, продуктов, архитектуры и т. д.
- Сцена с аномальной производительностью: сделать сцену с аномальной производительностью.,Обязательное условие – должно быть давление. поток под давлением,Имитировать исключения. Определение этого исключения очень широкое.,в следующей статье,Давайте углубимся в подробности.
Многие инженеры по тестированию производительности называют сценарии тестовыми примерами. Если имя просто другое, я думаю, это приемлемо. Ключ в том, что в содержании есть большое отклонение. Это отклонение заключается в том, что вариант использования ограничивается описанием тестовых сценариев и тестовых данных и не описывает необходимость. суждение в реальном времени и динамический анализ. Это серьезно влияет на следующую концепцию: результаты производительности.
Анализ и настройка должны быть включены в тестирование производительности.
У людей всегда были разные аргументы о том, нужна ли настройка в проектах тестирования производительности или же инженеры по тестированию производительности должны заниматься настройкой.
Судя по общему состоянию рынка производительности, среди инженеров по тестированию производительности не так много людей, которые могут оценивать узкие места, анализировать производительность и оптимизировать. Поэтому многие люди на других должностях позиционируют тестирование производительности как проверку производительности, которая не включает в себя проверку производительности. Тюнинговая часть. Итак, существует множество проектов производительности, которые определяются в течение недели или двух. Этот тип проекта, по сути, представляет собой проверку производительности и не может называться проектом полной производительности. Когда вы добавляете часть настройки, проект производительности усложняется. Для большинства команд анализ узких мест может занять много времени, что включает в себя корреляционный анализ, анализ тенденций, поиск цепочки доказательств и другие средства.
Поэтому не стоит выполнять тюнинг. Я сделал следующие деления.
Перформанс-проекты делятся на следующие категории.
- Новая категория тестирования производительности системы:Такие проекты обычно требуюттествнесистемамаксимальная вместимость,В противном случае я буду чувствовать себя неуверенно, когда выйду в Интернет.
- Класс тестирования производительности для старой системы и новой версии:Такие проекты обычно сравнивают со старыми версиями.,Пока производительность не снижается, мощность можно оценить на основе исторических данных.,Требования к настройке, как правило, невелики.
- Новый класс оптимизации теста производительности системы:такого родасистемане толькотествнемаксимальная мощность,Это тоже требует настройки в лучшую сторону.
Обязанности исполнительной группы заключаются в следующем.
- Проверка работоспособности:по заданному показателю,Просто сделай Проверка работоспособность. В основном этим занимаются сторонние тестовые агентства.
- Тестирование производительности:для данногосистема,сделать всеобъемлющий Тестирование производительности,Можно получить максимальную мощность системы,Но никакого тюнинга здесь нет.
- Тестирование производительности+Анализ и настройка:для данногосистема,сделать всеобъемлющий Тестирование производительности, при этом доводя систему до оптимального состояния.
Когда команда, которая может выполнять только проверку производительности, сталкивается с проектами тестирования производительности старой системы, новой версии и новой оптимизации тестирования производительности системы, такая команда может выполнять только проекты тестирования производительности новой системы.
Командам по тестированию производительности по-прежнему очень сложно сталкиваться с проектами, требующими тестирования и оптимизации производительности новой системы. Такая команда может выполнить первые два проекта.
Только третья команда может выполнить проект третьего типа.
Результаты тестирования производительности должны быть сообщены.
Как определяются результаты деятельности? С учетом предыдущего определения мониторинга и процесса выполнения сценария сгенерированные данные должны быть организованы в отчет о результатах. Эта работа с документацией также очень важна и является важным аспектом, отражающим профессионализм исполнительной команды. Речь идет не только об организации Word, но и об украшении формата. Отчеты об испытаниях необходимо сообщать или архивировать.
Если это внутренний проект, отчет об испытаниях может представлять собой форму, которую можно заполнить, отправив электронное письмо. Также требуется архивирование. По некоторым проектам с участием Стороны А и Стороны Б требуется отчетность.
Итак, как сообщить?
Нам нужно знать, что большинство начальников и начальников волнуют результаты теста, а не бессмысленные цифры, например, сколько людей было задействовано и сколько времени было потрачено. Мы также должны написать таблицу сравнения TPS, времени отклика и ресурсов до и после настройки отчета.
Я полагаю, что благодаря приведенному выше анализу вы получили четкое представление об определении тестирования производительности. Это определение фактически описывает, что необходимо делать при тестировании производительности.
Конечно, некоторые могут выскочить и сказать, что вы слишком резко говорите и недостаточно расторопны. Разве сейчас не все используют DevOps? Вам все еще придется проходить эту процедуру еще раз?
Очевидно, люди, которые так говорят, не понимают сути того, что я пытаюсь сказать. Вышеуказанный контент относится к полному проекту или развитию системы или компании. Ситуация будет иной для некоторых людей, которые просто следуют версии и новым требованиям в середине итерации, потому что такие люди видят только текущую часть, а не весь процесс.
И этот процесс постоянно развивается итеративно.
Будь то гибкий процесс разработки или DevOps, вы можете внимательно проанализировать каждое звено проекта по отдельности (я говорю о всем проекте с нуля), и оно не выскочит из приведенного выше определения. Если да, то почувствуйте. свяжитесь со мной, я могу изменить определение. :)
Кратко иллюстрируя концепцию Подвести итог:
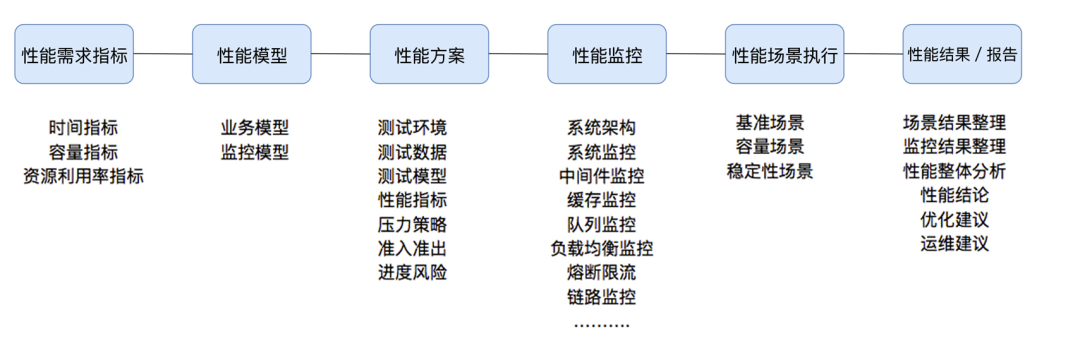
С этой схемой становится понятнее.
так,Вышеупомянутые стресс-тест, Тест емкости, нагрузочный тест и т.п.,В ходе фактического процесса реализации проекта,Ни один из них не имеет общей руководящей ценности. Я лично думаю,Вам следует отказаться от этих понятий, которые кажутся очень разумными, но на самом деле бесполезны в области производительности.
Сценарий производительности TPS и время отклика
Ранее мы говорили, что производительность должна иметь сценарии, а также мы говорили, что сценарии производительности должны включать сценарии базовой производительности, сценарии производительности емкости, сценарии стабильности производительности и сценарии аномальной производительности. Ниже я приведу однозначное соответствие упомянутым выше понятиям.
Люди, изучающие производительность, наверняка видели картинку, от которой вырвало, и теперь я хочу, чтобы вас вырвало снова. следующее:
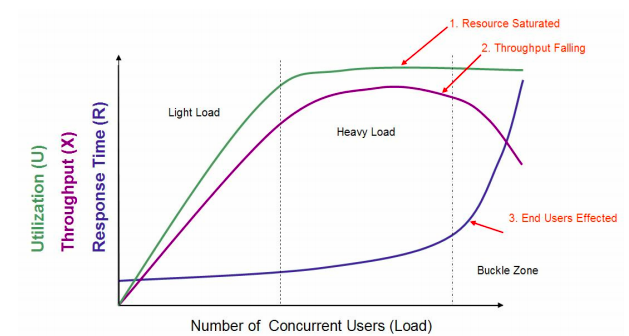
На этом рисунке определены три кривые, три области, две точки и три описания состояния.
- Три кривые: кривая пропускной способности (фиолетовая), кривая использования (зеленая) и кривая времени отклика (темно-синяя).
- Три зоны: легкая нагрузка, тяжелая нагрузка и зона пряжки.
- Два момента: оптимальное количество пользователей (The Optimum Number of Concurrent Пользователи), максимальное количество пользователей ( Maximum Number of Concurrent Users)。
- Три описания состояния: «Насыщение ресурсов», «Падение пропускной способности» и «Затронуто конечные пользователи».
Я видел отсылки к этой картинке во многих местах. Надо сказать, что как схематическая диаграмма она действительно классическая и описывает базовое состояние. Однако схематические представления можно использовать только в качестве схематических представлений. В конкретных проектах нам все равно приходится принимать собственные четкие суждения.
Нам нужно знать, что в некоторых местах этой картинки могут быть ошибки относительно реальной ситуации.
Прежде всего, во многих случаях время между насыщением ресурсов в области большой нагрузки и достижением максимального значения TPS не совпадает при одинаковом количестве одновременных пользователей. Например, когда загрузка ресурсов ЦП достигает 100%, по мере увеличения нагрузки очередь постепенно увеличивается и время ответа увеличивается. Однако, поскольку увеличение количества пользователей превышает увеличение времени ответа, TPS все равно будет. То есть после того, как использование ресурсов достигнет насыщения, пройдет некоторое время, прежде чем TPS достигнет верхнего предела.
В большинстве случаев кривая времени отклика не будет такой крутой, как показано на рисунке, и она не обязательно резко возрастает в зоне коллапса, но с большей вероятностью внезапно поднимется в зоне большой нагрузки.
Кроме того, кривая пропускной способности не обязательно будет снижаться и останется ровной в некоторых хорошо контролируемых системах. Когда-то в проекте, поскольку TPS поддерживал уровень, а количество пользователей и время ответа все время увеличивалось, тайм-аута не было, потому что время ответа было слишком быстрым. Я поспорил с парнем из моей команды, который прессинговал три часа, и сказал ему, что продолжать прессинг нет смысла, он просто ждет тайм-аута. Он упрямо сказал, что, поскольку об ошибке не сообщалось и время все еще можно контролировать, ему приходится продолжать добавлять его. Я также могу упомянуть об этом противоречии в следующей статье.
Оптимальное количество параллелизма обычно является всего лишь ощущением, и не существует абсолютных данных, подтверждающих это. В процессе эксплуатации и обслуживания производства большинство из нас на самом деле более осторожны и не устанавливают эту точку как оптимальную параллелизм, а скорее как более высокую точку.
Максимальное количество параллелизма совершенно необоснованно. Производительность снижена. Максимальное количество параллелизма должно быть на более высоком уровне. Это предполагает недопонимание взаимосвязи между максимальным количеством пользователей или потоков в инструменте давления и TPS. При реализации конкретного проекта опытных тестировщиков производительности будет больше волновать количество запросов, которые может обработать сервер, то есть TPS, а не количество потоков в стресс-инструменте.
Эта картина не учитывает необоснованные сценарии настройки, такие как блокировки или потоки, и такие сценарии относительно распространены. Другими словами, если TPS не может быть загружен, ресурсы нельзя использовать. Таким образом, эта диаграмма по умолчанию предполагает, что пока можно использовать потоки, ресурсы будут продолжать увеличиваться.
Первоначально эта картинка была просто схемой, иллюстрирующей некоторые взаимосвязи. Но позже в индустрии производительности многие люди, которые не до конца понимали эту диаграмму, использовали ее как очень разумную «модель» для некоторых людей, что вызывало все больше и больше недоразумений.
Самым ранним источником этой диаграммы является технический документ «Методология тестирования производительности», написанный консультантом PSO компании Quest Software в 2005 году. Эта картинка обсуждается на стр. 18. Отрывок из оригинальной статьи выглядит следующим образом:
You can see that as user load increases, response time increases slowly and resource utilization increases almost linearly. This is because the more work you are asking your application to do, the more resources it needs. Once the resource utilization is close to 100 percent, however, an interesting thing happens – response degrades with an exponential curve. This point in the capacity assessment is referred to as the saturation point. The saturation point is the point where all performance criteria are abandoned and utter panic ensues. Your goal in performing a capacity assessment is to ensure that you know where this point is and that you will never reach it. You will tune the system or add additional hardware well before this load occurs.
Согласно этому описанию, этот человек просто описывает явление, основанное на своих ощущениях и ничем больше. Например, точка насыщения — это точка, в которой все критерии производительности отбрасываются, и наступает полная паника. Фактически, по моему опыту работы, до точки насыщения показатели производительности уже могут показывать проблемы, и они уже являются причиной паники. Затем мы добавляем давление, чтобы сделать индикатор более очевидным, чтобы мы могли принять правильное суждение. На самом деле настройка заключается в контроле системы до точки насыщения. Здесь возникает проблема с уровнем воды, которого достигает регулирующая способность, и является целью тестирования и анализа производительности.
Мы упростим другой график, чтобы проиллюстрировать более прямую связь. Как показано ниже:
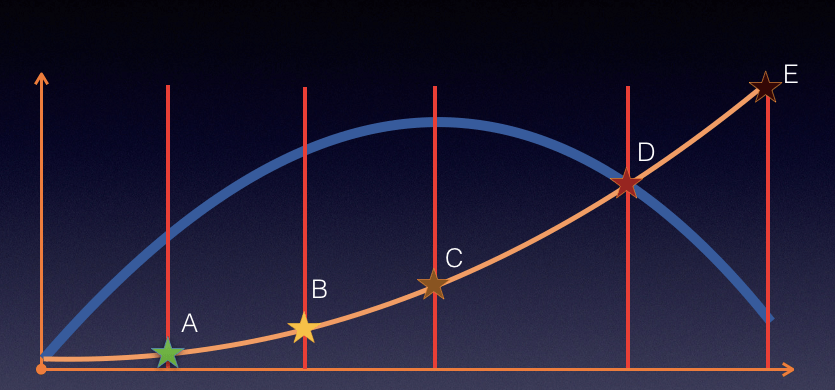
На рисунке выше синяя линия представляет TPS, а желтая линия — время отклика.
В процессе увеличения TPS время отклика изначально будет находиться в низком состоянии, то есть до точки А. Затем время отклика начинает увеличиваться до момента времени B, когда бизнес сможет это выдержать. В это время TPS еще есть куда расти. Затем увеличьте давление, и когда оно достигнет точки С, будет достигнуто максимальное значение TPS. Мы продолжаем увеличивать давление, и время ответа продолжает увеличиваться, но TPS будет уменьшаться (обратите внимание, что это не является неизбежным. Некоторые системы хорошо справляются с очередью и будут поддерживать стабильный TPS, и тогда дополнительные запросы будут дружественными . отклонять).
Наконец, время ответа было слишком большим, достигнув точки тайм-аута.
В моей работе такого рода логические связи больше соответствуют реальным сценам. Я не хочу описывать ресурсы в этих отношениях, потому что это слишком запутанно.
Зачем так подробно описывать вышесказанное? Вот как некоторые сравнивают Свет на первой картинке Нагрузка соответствует тестированию производительности, Heavy Нагрузка соответствует нагрузочному тестированию, Пряжка ZoneСоответствуетстресс-тест……Существует множество соответствующих отношений。
На самом деле это неразумно.
Ниже я заменю эти запутанные понятия определениями сценариев.
Почему я так разделяю? Потому что на оперативном уровне конкретных сценариев,Конкретно работоспособна только конфигурация в сцене. Вообще говоря, то, что все называют Тестирование производительности, нагрузочное тестирование, стресс-тест, находится на операционном уровне.,Разница лишь в количестве витков в стресс-инструменте.,Все остальное на уровне анализа ресурсов,И анализ глазами многих людей,Даже не рассматривался как тест.
В качестве примера возьмем тестирование конфигурации и инкрементное тестирование.
Что касается производительности, у нас есть множество конфигураций, таких как параметры JVM, параметры ОС, параметры БД, параметры сети, параметры контейнера и т. д. Если мы назовем тестирование этих параметров конфигурации «тестированием конфигурации», я думаю, что это слишком узко. Потому что это всего лишь простое изменение параметров конфигурации, но на самом деле никаких изменений в сценарии производительности не происходит. До и после изменения конфигурации для оценки эффекта будет использоваться один и тот же сценарий производительности. В лучшем случае будет добавлено некоторое давление на внешний интерфейс. Фактический сценарий вообще не изменился, поэтому я думаю, что он не достоин внимания. отдельная категория.
Другой пример — инкрементное тестирование. С точки зрения производительности, будь то сценарий базовой производительности или сценарий производительности мощности, какой из них не нужно увеличивать? Я знаю, что сегодня на рынке часто встречаются инженеры-тестировщики, которые напрямую запускают в работу сотни или тысячи потоков (пожалуйста, не говорите мне, что это нормальный сценарий, учитывая, что мой дух ограничен и я не могу вынести такого давления). За исключением сцены флэш-продажи, я никогда не видел сцены, где все потоки авторизовались бы одновременно. В общих сценариях производительности приращение является важным процессом. При этом процесс приращения должен быть непрерывным, а не разрозненным выполнением сценариев в 100 потоков, 200 потоков и 300 потоков, что неразумно. Мы будем подчеркивать этот момент во многих местах. Поэтому я не думаю, что инкремент заслуживает отдельной категории.
Другие концепции не будут опровергнуты одна за другой. На самом деле, при тестировании производительности и реальной реализации проекта нам не нужно так много концепций, и эти разные концепции не способствуют развитию области тестирования производительности. Когда дело доходит до таких концепций, как облачные вычисления, искусственный интеллект и большие данные, они сами определяют направление.
Тестирование производительности классифицируется как «тестирование», которое является слабым звеном в жизненном цикле программного обеспечения, и текущее развитие рынка не является хорошим. На самом деле не стоит того, чтобы эти концепции нарушали логический ход мыслей, который должен существовать.
Понимание показателей производительности, таких как TPS, QPS, RT и пропускная способность.
Обычно мы определяем показатели спроса для сценариев производительности на двух уровнях: бизнес-показатели и технические показатели.
Между этими двумя уровнями должна быть установлена взаимосвязь, и технические индикаторы не могут быть отделены от бизнес-показателей. Уйдя, вы обнаружите, что можете ответить на вопрос «Сколько TPS может поддерживать система при каком времени отклика», но не можете ответить на вопрос «Каков статус бизнеса?»
Например, если системе необходимо поддерживать 10 миллионов человек в сети, вы можете проверить, что система может поддерживать 10 000 TPS. Но если вы спросите, возникнут ли какие-либо проблемы с 10 миллионами людей в сети? Наверное, сложно ответить.
Здесь я нарисую диаграмму, чтобы вы могли понять взаимосвязь между бизнес-показателями и показателями производительности.
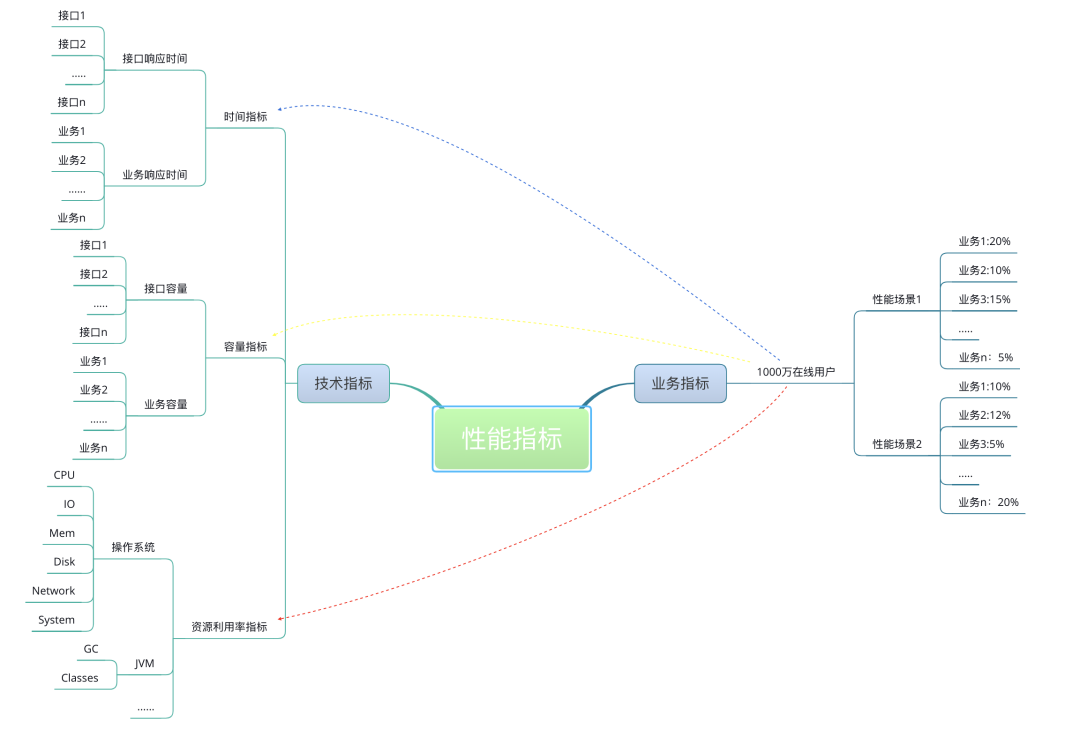
Это указание, очевидно, недостаточно подробное, но оно также может объяснить взаимосвязь. Все технические индикаторы формулируются на основе бизнес-сценариев, и между техническими индикаторами и бизнес-показателями должен быть проведен подробный процесс преобразования. Таким образом, технические индикаторы не будут анклавом. В то же время, отвечая на вопрос, достигнуты ли технические показатели, он также может ответить, могут ли быть достигнуты бизнес-показатели.
Учитывая такую корреляцию, давайте посмотрим на представления показателей производительности, обычно используемые в индустрии тестирования производительности.
Я перечислил показатели эффективности, которые сейчас можно увидеть в Интернете, и которые не включают показатели ресурсов. Поскольку тип ресурса более конкретен, и ошибка понимания невелика, но разница между типами бизнеса относительно велика.
В чем заключаются недопонимания относительно этих показателей эффективности?
Помню, в молодости не было таких понятий, как QPS, RPS и CPS, только TPS. В то время небо всегда было таким синим, а время всегда было таким медленным: «Люди поймут, если их запереть».
QPS изначально использовался для описания количества выполнения SQL в секунду в MySQL. Весь SQL называется запросом. Позже, из-за переноса некоторых статей, QPS постепенно был перенесен в инструмент давления для описания пропускной способности, поэтому здесь возникли некоторые недопонимания. Какова связь между QPS и TPS?
RPS означает количество запросов в секунду. Буквальный смысл этой концепции легко понять, но легко понять одну вещь: к какому уровню Запроса она относится? Если мы говорим о HTTP-запросе, какое отношение он имеет к количеству обращений в секунду?
HPS, это тоже концепция, которую легко понять буквально. Что такое Хит? Некоторые люди приравнивают это к HTTP-запросу, а некоторые — к количеству кликов пользователей.
CPS используется сравнительно немногими людьми, и масштабы непонимания, которые он вызывает в индустрии производительности, невелики. В то же время есть и те, кто любит использовать CPM (Calls Per Minute, звонков в минуту). Эти два индикатора обычно используются для описания количества вызовов уровня Сервиса другими сервисами в единицу времени. Именно поэтому в индустрии производительности практически нет недопонимания, поскольку тестеры производительности не просматривают уровень Сервиса много раз.
Чтобы различать эти понятия, давайте сначала поговорим о TPS (транзакциях). Per Второй). Мы все знаем, что TPS — это ключевая концепция показателя производительности в области производительности, которая используется для описания количества транзакций в секунду. Мы также знаем, что степень детализации, определяемая TPS, различна в разных отраслях и разных сферах бизнеса. Так что где бы вы ни использовали TPS, должно быть обязательное условие, то есть Все участники должны знать, как определяется ваш Т.。
Люди часто спрашивают, как следует определять TPS? Никаких конкретных «юридических положений» на этот счет на самом деле нет, а значит, вы можете решать все, что захотите.
Обычно мы определяем степень детализации TPS в зависимости от цели сценария. Если это тест производительности уровня интерфейса, T можно напрямую определить как уровень интерфейса, если это тест производительности бизнес-уровня, T можно напрямую определить как каждый бизнес-шаг и полный бизнес-поток.
Для иллюстрации воспользуемся схематической диаграммой.
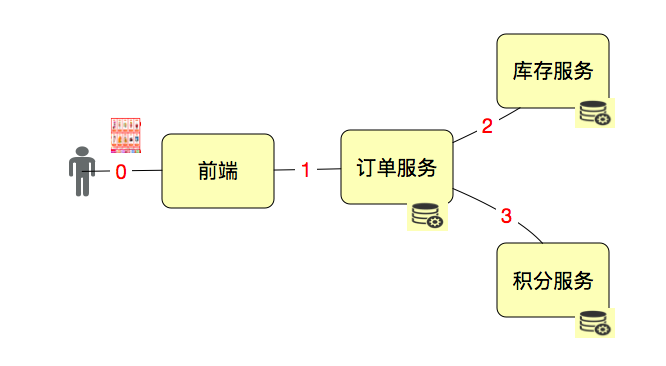
Если мы хотим протестировать интерфейсы 1, 2 и 3 по отдельности, то T — это уровень интерфейса; если мы хотим разместить заказ с точки зрения пользователя, тогда 1, 2 и 3 должны находиться в одном T, то есть бизнес-уровне.
Конечно, сейчас нам также необходимо проанализировать, как устроена система. Обычно мы работаем асинхронно, когда дело касается точек, но инвентаризация не может быть асинхронной. Таким образом, вы можете думать об этом бизнесе как о наличии только двух интерфейсов 1 и 2, но при таком давлении на бизнес-уровне интерфейс 3 также необходимо отслеживать и анализировать.
Следовательно, определение T в TPS в производительности зависит от цели сценария и роли T. В общем, будем решать дела таким образом.
- Скрипт уровня интерфейса: —— Начало транзакции (интерфейс 1) Интерфейс 1 скрипт —— Завершение транзакции (интерфейс 1) —— Начало транзакции (интерфейс 2) Скрипт интерфейса 2 —— Завершение транзакции (интерфейс 2) —— Начало транзакции (интерфейс 3) Скрипт интерфейса 3 —— Завершение транзакции (интерфейс 3)
- Сценарий уровня интерфейса бизнес-уровня (то есть использование интерфейсов для объединения полного бизнес-потока): —— Начало транзакции (Бизнес А) Скрипт интерфейса 1 - Интерфейс 2 (синхронный вызов) Скрипт интерфейса 1 — интерфейс 3 (асинхронный вызов) —— Завершение транзакции (Бизнес А)
- сценарий пользовательского уровня —— Начало транзакции (Бизнес А) Нажмите 0 – Интерфейс 1 Скрипт – Интерфейс 2 (синхронный вызов) Нажмите 0 — сценарий интерфейса 1 — интерфейс 3 (асинхронный вызов) —— Завершение транзакции (Бизнес А)
Какой уровень транзакций вы хотите создать, полностью зависит от цели теста.
В обычных обстоятельствах мы будем тестировать один за другим сверху вниз, чтобы путь был четко прописан и можно было легко обнаружить проблему.
Переосмыслить концепции показателей эффективности.
Теперь, когда мы разобрались, что такое Т ТПС, давайте поговорим о том, что такое ТПС. Буквальный смысл очень легко понять, а именно: транзакций в секунду。
Во время тестирования производительности причина важности TPS заключается в том, что она может отражать вычислительные возможности системы. Я уже говорил во многих сценариях, что транзакция — это статистика времени выполнения скрипта и не имеет особого значения. А теперь добавилось еще несколько концепций.
Первый — это QPS. Если он описывает количество запросов в секунду в базе данных, то, судя по приведенной выше диаграмме, он фактически описывает количество выполнений SQL в секунду в базе данных, подключенной к сервису. Если он описывает количество внешних запросов в секунду, он не включает операции вставки, обновления и удаления. Очевидно, что такие показатели недостаточно полны, чтобы описать общую производительность системы. Поэтому не рекомендуется использовать QPS для описания общей производительности системы во избежание недоразумений.
RPS (Запрос в секунду), количество запросов в секунду. Вроде бы простое понимание, но количество запросов зависит от уровня, на котором запросы рассматриваются, потому что слово запрос действительно слишком широкое. Давайте немного изменим приведенный выше рисунок, чтобы описать количество запросов.
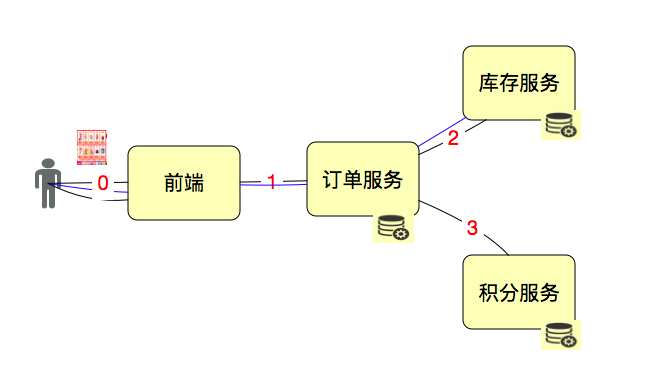
Если пользователь щелкает один раз, отправляет 3 HTTP-запроса, дважды вызывает службу заказов, дважды вызывает службу инвентаризации и один раз вызывает службу точек, то как следует рассчитывать этот запрос? Если вы эксперт в расчете ВВП, я думаю, это может быть так: 3+2+2+1=8 (раз). В конкретных проектах мы будем описывать каждый сервис отдельно, чтобы вести статистику производительности. Если мы хотим описать целое, то существует не более 3 RPS. Если понимать его с точки зрения протокола HTTP, HTTP-запрос является относительно точным описанием, но его определение не включает бизнес. Если вы придаете этому бизнес-значение, то его можно использовать для описания производительности.
HPS (Hits Per Second), кликов в секунду. Hit обычно используется для описания HTTP-запроса при тестировании производительности. Однако некоторые люди используют его для описания количества кликов, которые реальный клиент совершает на интерфейсе. Что касается этого, то это может быть указано только в конкретных проектах. Когда он описывает HTTP-запрос, если RPS также описывает HTTP-запрос, то эти две концепции абсолютно одинаковы.
CPS/CPM: Звонков в секунду/Вызовов в минуту, количество звонков в секунду/минуту. Это описание часто используется на уровне интерфейса, например, в сервисе заказов выше. Видимо один клик по интерфейсу клиента вызывается дважды. Это легче понять. Однако на уровне операционной системы мы часто слышим системные вызовы, называемые вызовами. Например, при использовании strace вы увидите имена столбцов, такие как Calls.
В этих концепциях самих по себе нет ничего плохого, но когда вышеупомянутые концепции используются для описания производительности системы, это становится запутанным. Я думаю, что есть несколько способов справиться с этой ситуацией:
- Объедините их одной концепцией. Думаю, достаточно просто использовать TPS. Остальные описаны с ограничениями на разных уровнях. Например, если интерфейс вызывает 1000 вызовов/с, это не вызовет путаницы.
- Четко определите иерархию терминологии внутри команды.
- Если уровень использования не определен, вы можете добавлять соответствующие фоновые условия только при разговоре об определенной концепции.
Поэтому, когда вы и ваши коллеги обсуждаете концепции, используемые в показателях эффективности, вам следует быть более конкретными. В команде сначала должно быть единое определение этих терминов, а потом уже соответствие показателям эффективности.
Время откликаRT
В производительности еще одним важным понятием является время отклика. Это легче понять. Затем мы используем эту схематическую диаграмму, чтобы проиллюстрировать:
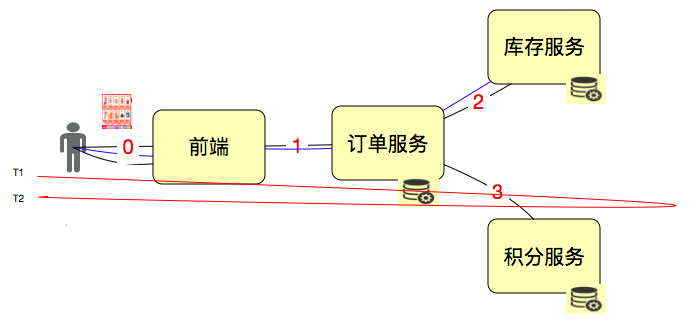
РТ = Т2-Т1. Метод расчета очень прост и понятен. Однако нам нужно знать, что на этот раз включается ряд последующих ссылок.
Концепция времени отклика чрезвычайно проста, но позиционирование времени отклика сложно.
Инструменты тестирования производительности будут фиксировать время отклика, но не сообщат вам, где серверная ссылка работает медленно. Часто, когда кто-то задает вопрос, просто скажите его прямо, мое время ответа очень медленное. В чем проблема? В этом случае единственный ответ: не знаю.
Потому что нам нужно сначала нарисовать схему архитектуры, посмотреть на ссылки запроса, а потом искать слой за слоем. Например:
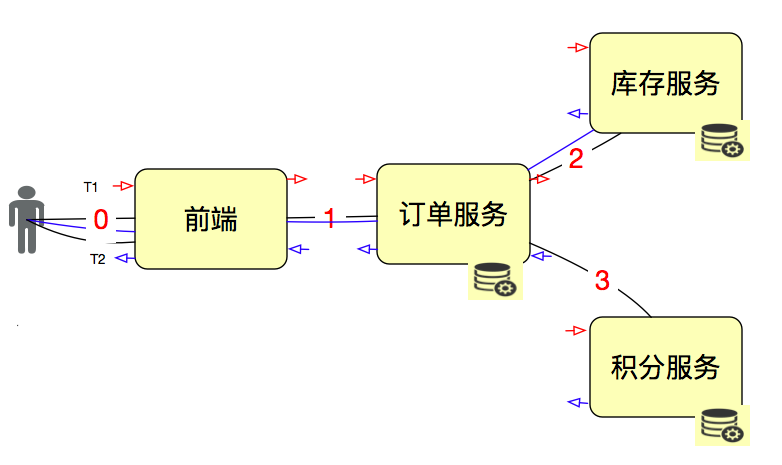
Просто запишите импорт и экспорт всех услуг, а затем посчитайте результаты. Эта функция в основном учитывается при построении таких систем, как шлюзы и шины.
Теперь, с развитием технологий, использованием инструментов мониторинга ссылок и некоторых метрик, это требование значительно упростилось. Например, этот дисплей:
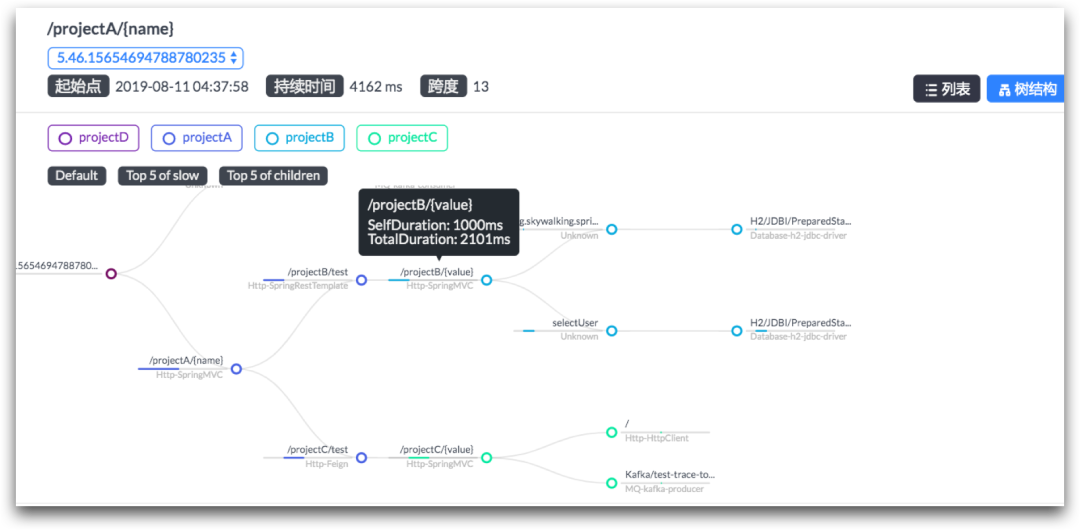
Он интуитивно показывает время, затраченное каждым узлом на ссылку запроса, и продолжительность запроса.
Я хотел бы упомянуть здесь о состоянии настройки в текущем проекте производительности.
Что касается времени отклика, позиционирование с разделением времени является очень важной частью анализа позиционирования узких мест производительности. Но обратите внимание, что эта ссылка не последняя ссылка для инженеров по тестированию производительности.
На работе я часто вижу многих инженеров по тестированию производительности, которые даже не распределяют время. Они только сообщают время отклика, наблюдаемое в инструменте стресса, и выдают заключение «пройдено или не пройдено» без какого-либо позиционирования.
Кроме того, некоторые инженеры по тестированию производительности используют различные средства для анализа точек потребления времени, но они также чувствуют, что их работа окончена, без проведения анализа первопричин или координации других команд для анализа.
Конечно, в разных компаниях роли и требования к анализу различаются, поэтому он также должен основываться на реальной текущей ситуации в компании.
По моему мнению, если производительность только измеряется, но не корректируется, это работа по проверке производительности, и ее нельзя назвать полноценным проектом производительности. Это могут сделать сторонние агентства по тестированию производительности, но если вы сделаете это внутри предприятия, ценность команды производительности определенно значительно снизится.
Но сейчас многие люди не считают настройку производительности работой команды производительности. Основные причины заключаются в следующем:
- Люди в команде «Тестирование производительности» имеют ограниченные способности;
- производительность Тюнинг стоит дорого,Кропотливый,Не стоит этого делать.
В проектах производительности, которые я возглавляю, в основном работой по настройке занимается моя команда. Конечно, команда производительности не может быть полностью свободна от технических недостатков, поэтому во многих случаях она координирует работу людей из других команд для анализа узких мест. Так почему же моя команда возглавляет этот процесс анализа?
Поскольку определение узкого места в производительности у каждого технического специалиста разное, если конкретное значение счетчика не уточнено в соответствии с проблемой, вероятность неправильного понимания очень высока.
Когда я консультировал по производительности на крупной розничной фабрике, там было полно технического персонала из отделов разработки, эксплуатации и обслуживания, а также администраторов баз данных. В результате появилось узкое место в производительности, и все говорили, что с их стороны все в порядке. Поэтому я спросил их одного за другим, как они оценивают, какой счетчик они оценивают и какова его ценность. Оказывается, суждения многих людей об узких местах отличаются от того, что я себе представлял.
Например, если загрузка ЦП БД достигает более 90%, администратор базы данных считает, что проблемы нет, поскольку это все бизнес-SQL, а не проблема самой БД. Разработчик считает, что медленное выполнение SQL связано с проблемой с БД, а не с проблемой самой записи, поскольку бизнес-логика не является неправильной. Проблема должна заключаться в том, что индексы и конфигурации в БД. являются необоснованными.
Видите ли, у всех разные мнения по одной и той же проблеме. Конечно, нельзя исключать, что некоторые люди просто хотят уйти от ответственности.
Что делать в это время? Если вы сможете достать план выполнения и рассказать всем, что индекс должен быть создан здесь, а бизнес-условия должны быть изменены там, то он будет конкретным.
Количество потоков и пользователей в инструментах стресса по сравнению с TPS
Всегда есть много людей, которые колеблются между количеством одновременных потоков и TPS, и они не понимают взаимосвязи и разницы между ними. Суть путаницы между этими двумя понятиями заключается в том, что, как если бы потоки были реальными пользователями, количество одновременных потоков описывает количество реальных пользователей.
Но любой, кто занимается производительностью, знает, что количество одновременных потоков сильно отличается от реальных пользовательских операций без моделирования реальных пользовательских операций.
Когда LoadRunner был еще относительно популярен, Меркьюри предложил концепцию BTO, то есть оптимизации бизнес-технологий. Концепция «времени на размышление» также предлагается в LoadRunner. Фактически, термин «время на размышление» не используется в других инструментах повышения производительности. Этот термин был придуман для инструментов производительности, имитирующих реальных пользователей.
Однако, поскольку статус тестирования производительности продолжает снижаться, а некоторые концепции и термины продолжают пониматься неправильно, многие люди теперь не понимают взаимосвязь между количеством потоков в стресс-инструментах, пользователями и TPS. Опять же, давайте нарисуем схематическую диаграмму для иллюстрации.
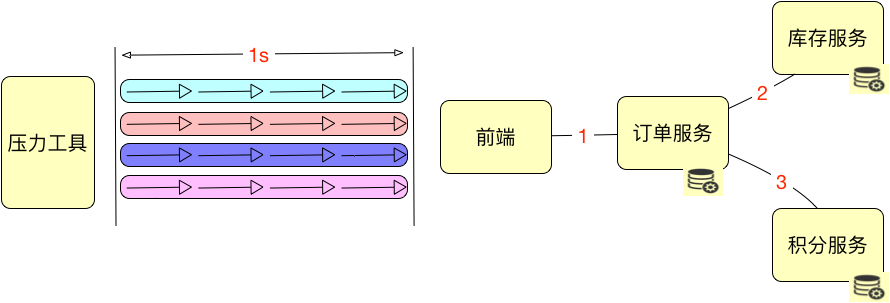
Вот предпосылка. В поле выше есть четыре стрелки, каждая из которых представляет одну и ту же транзакцию.
Прежде чем говорить об этой диаграмме, мы должны сначала объяснить, на каких данных опирается концепция «параллелизма».
Выше мы говорили о множестве индикаторов, но для реализации параллелизма требуются определенные индикаторы. Вы можете сказать, что мой параллелизм — 1000TPS, или 1000RPS, или 1000HPS, это решать вам. Но в конкретном проекте, когда вы говорите о безразмерном слове, таком как 1000 параллелизма, вы должны дать всем понять, что это такое.
На диаграмме выше инструмент давления на самом деле представляет собой 4 параллельных потока. Поскольку каждый поток может выполнить 4 транзакции за одну секунду, общее количество TPS равно 16. Это очень легко понять. В понимании большинства нетехнических людей этот сценарий означает, что количество параллелизма равно 4, а не 16.
Очень сложно объяснить это ясно. Мой подход заключается в том, чтобы просто сказать другим, что параллелизм равен 16, не беспокоясь о 4 потоках. Во всех моих проектах это примерно одинаково, и никогда не было недоразумений.
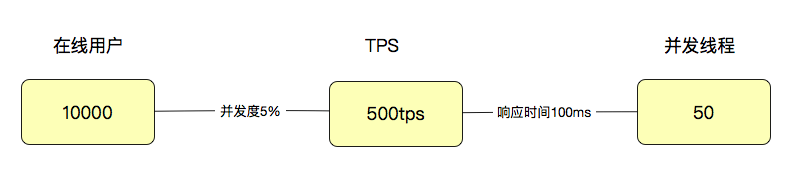
Так как же определить количество пользователей? С пользователями будет сложнее. Поскольку пользователи имеют бизнес-значение, некоторые люди думают, что если в системе 10 000 пользователей онлайн, она должна тестировать 10 000 параллельных потоков. Такая логика действительно нетехническая. Обычно мы анализируем параллелизм онлайн-пользователей. Во многих компаниях параллелизм будет ниже 5% или даже ниже 1%.
При расчете 5% получается 10 000 пользователей x5% = 500 (TPS на уровне пользователя). Обратите внимание, что это TPS, а не количество одновременных потоков. Если время ответа в это время составляет 100 мс, то, очевидно, количество одновременных потоков равно 500TPS/(1000 мс/100 мс) = 50 (параллельных потоков).
С помощью такой простой логики вычислений мы можем увидеть взаимосвязь между количеством пользователей, количеством потоков и TPS.
но! Время отклика точно не всегда будет 100мс. Обычно вышеуказанное соотношение не является фиксированным, но по мере увеличения количества одновременных потоков будет наблюдаться тенденция.
Поэтому при анализе производительности я подчеркиваю одно слово: тренд!
Что это за 28 принципов бизнес-моделей?
Я видел некоторые статьи о том, что при написании тестов производительности количество одновременно работающих пользователей должно рассчитываться по принципу 28. Общий смысл таков: если в день ею пользуются 10 миллионов пользователей и система открыта 10 часов, то при подсчете количества одновременных пользователей оно будет рассчитано за 2 часа, то есть 10 миллионов пользователей могут завершить бизнес. в течение 2 часов.
Я хочу сказать, что эта логика не имеет ценности в конкретной бизнес-системе. Потому что параллелизм каждой системы определяется бизнесом, а не полагается на так называемые законы управления бизнесом.
Если мы проведем большой анализ выборочных данных и, наконец, получим соотношение 28, я думаю, это нормально. Но если вы не анализируете какие-либо данные и напрямую используете коэффициент 28 для оценки и расчета, это ничем не отличается от мошенничества.
Как получить бизнес-модель? Есть два более разумных пути:
- Составьте статистику пропорций бизнеса на основе статистической информации о производственной среде.,Затем установите его в инструмент давления. Существует множество систем, которые невозможно выполнить напрямую онлайн.,Все получают бизнес-модели таким образом.
- Вы можете выполнять репликацию трафика непосредственно в производственной среде или использовать инструменты давления для прямого давления на производственную среду. Многие люди называют этот метод полноканальным стресс-тестированием. Собственно способ проведения стресс-теста на производстве,Самая важная работа — не технология,Но способность организации и координации. Я считаю, что каждый, кто участвовал, может понять вес этого предложения.
Разумно ли правило 258 для времени ответа?
Что касается времени отклика, многие люди до сих пор говорят, что время отклика 258 или 2510 является распространенным стандартом в отрасли. Тогда я спросил их, откуда взялся этот стандарт? Кто это написал? Каков фон? Почти никто не знает. Действительно невообразимо, что принцип, происхождение которого никто не знает, может распространиться так широко. Это похоже на слух. После того, как он выйдет наружу, источник уже никогда не будет найден.
Фактически, это был опрос, проведенный британскими ИТ-СМИ о службах буферизации музыки в 1980-х годах. В ту эпоху удовлетворенность клиентов была хорошей через 2 секунды; удовлетворенность падала через 5 секунд, но прибыль все еще была, а через 8 секунд прибыли уже не было; Итак, они опубликовали эти статистические данные, и появился принцип 258. После перевода на китайский язык он стал похож на теорему, которая оставалась неизменной на протяжении тысячелетий, глубоко затронув многих людей.
Прошло почти 40 лет с момента появления этого статистического результата. Развитие ИТ достигло неба. Сейчас это время совершенно неприменимо. Поэтому не упоминайте принцип времени отклика 258/2510, когда будете выходить в свет в дальнейшем. Это слишком непрофессионально.
Так как же обеспечить более разумное время отклика? Вот две идеи, рекомендуемые вам.
- Сравнительные данные из той же отрасли.
- Найдите выборочных пользователей с помощью системы (чем больше, тем лучше),Сделайте по ним статистику,Вынести результаты,Это стандарт для установки наиболее эффективного времени отклика.
Как рассчитываются показатели эффективности
Мы часто видим, как люди цитируют эти формулы в Интернете.
Формула (1):
Общая формула расчета количества одновременно работающих пользователей:
Среди них C — среднее количество одновременных пользователей; n — количество сеансов входа в систему; L — средняя продолжительность сеансов входа в систему; T относится к продолжительности исследуемого периода времени.
Формула (2):
Пиковое количество одновременных пользователей:
C’ относится к пиковому количеству одновременных пользователей, а C — это среднее количество одновременных пользователей, полученное по формуле (1). Эта формула рассчитана при условии, что сеанс входа пользователя соответствует распределению Пуассона.
После тщательного поиска вы обнаружите, что источником этих двух формул является статья под названием «Метод оценки количества одновременных пользователей», написанная человеком по имени Эрик Ман Вонг в 2004 году. Я неоднократно видел множество статей как на китайском, так и на английском языке. В то же время я также увижу в Интернете несколько статей, описывающих эту статью как «признанный в отрасли» метод расчета.
В исходном тексте есть несколько проблем.
- C не является одновременно пользователем,Но онлайн-пользователи.
- Эти две формулы содержат много предположений.,Например, оно соответствует распределению Пуассона или чему-то подобному. Почему это предположение проблематично? Все мы знаем, что распределение Пуассона представляет собой колоколообразное распределение.,Он анализирует общее состояние системы в полном цикле.
- Если вы хотите, чтобы это было практично в реальных проектах, вам понадобится большой объем статистических данных в качестве образцов и подставить их в формулу расчета, чтобы проверить ее достоверность.
- Пиковый расчет,я больше ничего не скажу,Я думаю, если вы занимаетесь производительностью,Вы должны сразу понять, что это соотношение не соответствует логике большинства реальных систем.
- Некоторые сравнивают эти две формулы с законом Литтла. Я бы сказал, что закон Литтла — это самый основной закон теории массового обслуживания.,А этот закон лишь гласит, что: среднее количество объектов в системе равно произведению средней скорости поступления объектов в систему и среднего времени пребывания объектов в системе. Я думаю, что это предложение,Это то же самое, что в опере Цинь говорится: «Когда вы выходите, вы чувствуете, что ваша спина повернута назад».
Некоторые говорят, как оценить емкость системы. Многие из наших текущих оценок системы основаны на определенных предположениях. Причина, по которой они являются оценками, означает, что система еще не существует или не достигла этого уровня. В этом случае мы можем провести статистический анализ и модели теории массового обслуживания на основе существующих данных, а затем сделать вывод о будущей пропускной способности системы.
Но все мы, кто работает над производительностью, должны знать, что мощность системы развивается, и точные значения невозможно получить на основе оценок.
Подвести итог
В концепции тестирования производительности показатели производительности, модели производительности, сценарии производительности, мониторинг производительности, реализация производительности и отчеты о производительности являются не только ключевыми словами в концепции, но также методами и процессами тестирования производительности.
Эти понятия очень важны в нашей реальной работе. Потому что хотят сгладить недоразумения в общении. Это позволяет людям на разных уровнях и в разных ролях общаться, используя одни и те же знания, а также позволяет тем, кто что-то делает, иметь четкие логические идеи. Это также оказывает положительное влияние на развитие общения между сверстниками.
Стратегии тестирования производительности, сценарии тестирования производительности и индикаторы тестирования производительности — это ключевые концепции, которые глубоко влияют на многих людей, занимающихся тестированием производительности. Мы упрощаем его логику и нам нужно запомнить всего несколько ключевых слов, а другие использовать нет необходимости.
- Концепции тестирования производительностисередина:производительностьиндекс、производительность Модель、производительностьсцена、производительностьмонитор、производительностьосуществлять、производительность Отчет。
- Сцена производительности: базовая сцена、Сценарий мощности、Сценарий стабильности、Необычная сцена.
- производительностьиндекссередина:TPS、RT。 (Помните, что определение Т основано на разных целях)
В конкретных проектах производительности сценарии производительности являются очень важной концепцией. Потому что он будет включать стратегии инициирования давления, бизнес-модели, модели мониторинга и данные о производительности (данные в производительности, я никогда не называю это моделью, потому что на уровне данных тест не выполняет никаких абстрактных действий, он просто использует), программное обеспечение и аппаратная среда, модели анализа и т. д.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
