Обоснование LLM и обзор платформы с открытым исходным кодом
Ранее на LLM Я не особо разбираюсь в рассуждениях, поэтому нашел время разобраться. Мы начали с Количественной. оценка Анализируйте и анализируйте на трех уровнях: модели, обоснование модели и платформа разработки.
Количественная оценка модели
Для прогресса при обучении модели используются 32-битные числа с плавающей запятой, поэтому они занимают много места. Некоторые большие модели требуют для загрузки большого объема видеопамяти, а процесс вычислений и вывода происходит медленно. Чтобы уменьшить использование памяти и повысить скорость вывода, параметры высокой точности можно преобразовать в параметры низкой точности, например, из 32 бит число с плавающей запятой, преобразованное в 8 битовое целое число, этот метод называется Количественная оценка модели。
Количественная оценка модели — это технология, которая преобразует вычисления с плавающей запятой в малобитные вычисления с конкретной точкой.,Это может эффективно снизить интенсивность вычислений, размер параметров и потребление памяти модели.,Но это часто приносит огромныеизпотеря точности。особенносуществовать Очень низкий бит(<4bit)、Двоичная сеть (1 бит)、дажеконвертировать градиент Чтобы количественно оценка еще больше усложняет задачу точности.
Преимущества количественной оценки
- Сохраняйте точность:Количественная Оценка потеряет точность, что эквивалентно внесению шума в сеть, но нейронные сети, как правило, не очень чувствительны к шуму. Чувство из, пока ты его хорошо контролируешь Количественная Степень оценки, влияние на точность сложных задач может быть очень небольшим.
- Ускоренные вычисления: традиционные операции свертки используют плавающую запятую FP32.,Количество младших битов уменьшено, а производительность вычислений выше.,INT8 Взаимно контраст FP32 Коэффициент ускорения может достигать 3 раз выше даже
- Сохраните память: и FP32 Тип Взаимно соотношение, FP16, INT8, INT4 Типы низкой точности занимают меньше места и соответствуют дисковому пространству. Время передачи может быть значительно сокращено.
- Экономия энергии и уменьшенная площадь чипа: каждое число приводит к меньшему количеству битов.,При выполнении расчетов необходимо перемещать меньше данных,Снижение затрат на доступ к памяти (энергосбережение),При этом уменьшается и количество необходимых умножителей (уменьшение площади чипа)
Количественные методы и принципы
Существует три основных метода количественного определения:
- Количественная обучение (Quant Aware Training, QAT)
- Количественная обучениепозволять Модель Восприятие Количественная Операция калибровки влияет на точность Модели, через finetune Тренинг по снижению Количественной оценкаошибка。
- динамичный Оффлайн Количественная оценка (Post Training Quantization Dynamic, PTQ Dynamic)
- динамичный Оффлайн Количественная Courture только отображает вес конкретного оператора в модели из типов FP32 в INT8/16 тип.
- Статический оффлайн Количественная оценка (Post Training Quantization Static, PTQ Static)
- Статический оффлайн Количественная Использовать оценку использовать использовать небольшой объем немаркированных калибровочных данных, собранных с помощью использования. KL Дивергенция и другие методы расчета Количественной коэффициент масштабирования
Принцип Количественной оценки модели состоит в том, чтобы реализовать преобразование чисел с плавающей запятой в данные с фиксированной запятой.
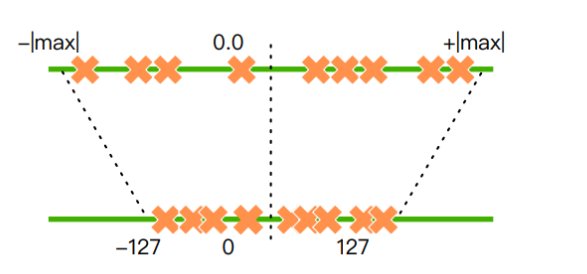
Как показано на рисунке выше, число с плавающей запятой большего диапазона преобразуется в число меньшего диапазона.
FP16/INT8/INT4
существуютhuggingface при просмотре Модель,Вы увидите некоторые сfp16、int8、int4 суффиксиз Модель,напримерLlama-2-7B-fp16、chatglm-6b-int8、chatglm2-6b-int4,На самом деле эти Модельто есть Количественная оценканазадиз Модель,fp16выражать Модельиз Количественная оценка Точность。
- FP32 (с плавающей запятой одинарной точности): использует 32-битное двоичное представление: 1 бит для знака, 8 бит для показателя степени и 23 бита для дроби. Его числовой диапазон составляет примерно от 1,18e-38 до 3,40e38, а точность составляет примерно от 6 до 9 значащих цифр.
- FP16 (с плавающей запятой половинной точности): позволяет использовать 16-битное двоичное представление.,1 из нихиспользуйте в знаке,5Кусочекиспользовать Вexponent,10Кусочекиспользовать Вfraction。Его числовой диапазон
[5.96×10^-8, 65504],Но фактическое максимальное положительное значение, которое можно выразить, равно 65504.,Минимальное положительное значение составляет примерно 0,0000000596 (нестандартное представление).,Когда знаковый бит равен 0, он представляет положительное число. - INT8,Восьмибитное целое число занимает 1 байт.,INT8 — метод расчета с фиксированной точкой.,Представляет целочисленную арифметику,Обычно получается из операций с плавающей запятой. Количественная оценка. существуют. «0» или «1» в двоичном формате — это бит.,INT8 означает использовать 8 бит для представления числа.
- int4 занимает 4 байта (32 бита)
Количественная оценка Точностьот高到低排列顺序да:fp16>int8>int4,Количественная оценкаиз Точность越低,Размер модели и Чем меньше видеопамять требуется для вывода,Но и способности Модельиз станут хуже.
В отрасли существует несколько форматов количественных моделей с открытым исходным кодом, которые представлены ниже.
GGML
https://github.com/ggerganov/ggml
GGMLПолное имяGeorgi Gerganov Machine Learning,от Георгий Тензорная библиотека, разработанная Гергановым (tensor library),Georgi GerganovПроекты с открытым исходным кодомllama.cppиз Основатель。
GGML — это библиотека, написанная на C, которая может конвертировать LLM в формат GGML, упрощая загрузку LLM и анализ с помощью количественного анализа и других технологий.
- ВыбиратьиспользоватьКоличественные методы,Преобразуйте исходные большие результаты предварительного обучения Модели в Количественную. точность (то есть сжатие исходной большой точности Модели FP16 в точность INT8, INT6).
- Кодировка двоичного файла,Воля Количественная Результаты предварительного обучения chargePost-из преобразуются в двоичный файл заданного формата.
характеристика:
- Написан на языке Си.
- Поддерживает 16-битные числа с плавающей запятой.
- поддерживатьцелое число Количественная оценка(4 Бит, 5 Бит, 8 биты и т. д.)
- автоматическое дифференцирование
- ADAM и L-BFGS оптимизатор
- Оптимизирован для кремния Apple.
- существовать x86 Архитектурное использование AVX/AVX2 Внутрисуществоватьфункция
- существовать ppc64 Архитектурное использование VSX Внутрисуществоватьфункция
- Никаких сторонних зависимостей
- Во время выполнения выделение памяти не происходит.
существовать HuggingFace начальство,Если ты видишь Модель Имя сGGMLсловаиз,напримерLlama-2-13B-chat-GGML,Объясните, что эти Модели прошли GGML Количественный. некоторый GGML Модельиз Помимо имени сGGMLслова外,Также поставляется сq4、q4_0、q5ждать,напримерChinese-Llama-2-7b-ggml-q4,здесьлапшаизq4На самом деле относится кизда GGML из Количественная оценкаметод,отq4_0开始往назад扩展,иметьq4_0、q4_1、q5_0、q5_1иq8_0,существоватьздесьВы можете увидеть различные методы Количественная оценка назадизданных.
GGUF
GGML — это базовый формат файлов без контроля версий и выравнивания данных. Он подходит для сценариев, в которых не требуется учитывать совместимость версий файлов или оптимизацию выравнивания памяти. Август 2023, Георгий Герганов создает новый формат файла большой модели GGUF, полное название GPT-Generated. Unified Формат, используемый для замены формата GGML. ГГУФ и GGML По сравнению с ГГУФ Дополнительная информация может быть добавлена к существующей Модели, тогда как оригинал GGML Модель не может быть одновременно GGUF спроектирован так, чтобы быть масштабируемым,Таким образом, в будущем в Модель можно будет добавить новые функции.,Без нарушения и совместимости со старыми Модельизами.
但这个功能даBreaking Change,也то есть说 GGML Все модели, количественно оцененные после выхода новой версии, GGUF отформатированный, что означает старый GGML Формат постепенно будет GGUF формат, а старый заменить нельзя GGML формат напрямую конвертируется в GGUF Формат.
GPTQ
GPTQ да一种Количественная оценка метод моделииз, можно конвертировать на языке Количественная оценка модели成 INT8、INT4、INT3 даже INT2 точности без значительной потери производительности, существуют HuggingFace начальство Если ты видишь Модель Имя сGPTQсловаиз,напримерLlama-2-13B-chat-GPTQ,Объясните, что эти Модели прошли GPTQ Количественная оценкаиз。кLlama-2-13B-chatНапример,Должен Модель全Точность版本из Размер 26G, используйте GPTQ количественно в INT4 Размер модели после точности 7.26G。
Сейчас существование популярнее GPTQ Количественная оценка工具даAutoGPTQ,它可к Количественная оценкалюбой Transformer Модель而不仅仅даLlama,сейчассуществовать Huggingface Уже AutoGPTQ Интегрировано в Transformers середина.
GPTQ vs GGML
GPTQ и GGML дасейчассуществовать Количественная оценка Существует два основных метода моделирования, какой из них существует в реальной эксплуатации?
Эти два вида имеют следующие сходства и различия:
- GPTQ существовать GPU работает быстрее на GGML существовать CPU работает быстрее на
- 同ждать Точностьиз Количественная оценка Модель,GGML из Модель чем GPTQ из немного больше, но эффективность рассуждений обоих из в основном одинакова.
- 两者都可к Количественная оценка HuggingFace начальствоиз Transformer Модель
Следовательно, если целевая Модель существует GPU При работе в системе сначала используется GPTQ. Чтобы количественно оценить,если тыиз Модельдасуществовать CPU При работе в системе рекомендуется использовать GGML Чтобы количественно оценить
Модель рассуждения
llama.cpp
llama.cpp Это машина вывода на чистом языке C/C++, основанная и разработанная автором GGML, поддерживающим Количественную. оценкарассуждение,поддержка Различные устройства и операционные системы,Самый ранний из них был связан с утверждением llamaиз мотивов.,сейчассуществоватьужеподдерживатьмейнстримиз Открытый исходный код Модель。
llama.cpp Примечательной особенностью является высокая загрузка аппаратного обеспечения. Независимо от того, являетесь ли вы пользователем Windows/Linux или пользователем macOS, вы можете повысить скорость вывода модели за счет оптимизации компиляции. Пользователям Windows/Linux рекомендуется скомпилировать иBLAS (или cuBLAS, если есть графический процессор) вместе, что может значительно повысить скорость обработки запросов. Пользователям macOS не нужно выполнять дополнительные операции, поскольку llama.cpp РУКА NEON оптимизирован, а BLAS включен автоматически. Для чипов серии M рекомендуется использовать Metal, чтобы включить вывод графического процессора и значительно увеличить скорость.
llama.cpp поддерживатьсуществоватьместныйCPUначальстворазвертывать Количественная оценканазадиз Модель,То есть в сочетании с упомянутым выше изGGML,Таким образом, даже оборудование сверхнизкой конфигурации может работать с LLM.
chatglm_cpp
https://github.com/li-plus/chatglm.cpp
После отечественного изчатglmМодель с открытым исходным кодом,Есть автор ссылкаllama.cpp,Разработан вывод о подтвержденииchatglm изchatglm_cpp,Нижний уровень по-прежнему основан на GGML.,текущийподдерживатьChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B, CodeGeeX2, Baichuan-13B, Baichuan-7B, Baichuan-13B, Baichuan2, InternLM Это отечественные модели с открытым исходным кодом.
vLLM
https://github.com/vllm-project/vllm
vLLM из Калифорнийского университета в Беркли и занимается графическими процессорами. рассуждения。
vLLm очень быстро запускает большие модели, в основном используя следующие методы:
- авторPageAttention внимание key & value Эффективное управление памятью
- непрерывная пакетная обработка
- Оптимизация ядер CUDA
В настоящее время поддерживает NVIDIA GPUs и AMD GPUs,Количественная оценка方лапшаподдерживатьGPTQ, AWQ, SqueezeLLM, FP8 KV Cache
MLC LLM
https://github.com/mlc-ai/mlc-llm
Machine Learning Compilation for Large Language Models (MLC LLM) Это высокопроизводительное универсальное решение для развертывания, которое поддерживает собственное развертывание любой большой языковой модели. MLC LLM поддержка Следующих платформ и оборудования: AMD GPU、 NVIDIA GPU、 Apple GPU、 Intel GPU、 Linux / Win、 macOS、 Web браузер, iOS / iPadOS、 Android。
Этот фреймворк был разработан командой Чэнь Тяньци (инициатором tvm). Самая большая особенность заключается в том, что его можно развернуть на iOS. и Android 设备начальство,Все еще в состояниисуществовать浏览器начальство运行SDМодельиLLMМодель。
DeepSpeed
Высокопроизводительная среда вывода, разработанная Microsoft, DeepSpeed-FastGen. Воспользуйтесь преимуществами фрагментации KV кэшидинамичныйслияние сегментацийнепрерывная пакетная обработка,обеспечивает лучшее, чемvLLMлучшеиз Колебание。
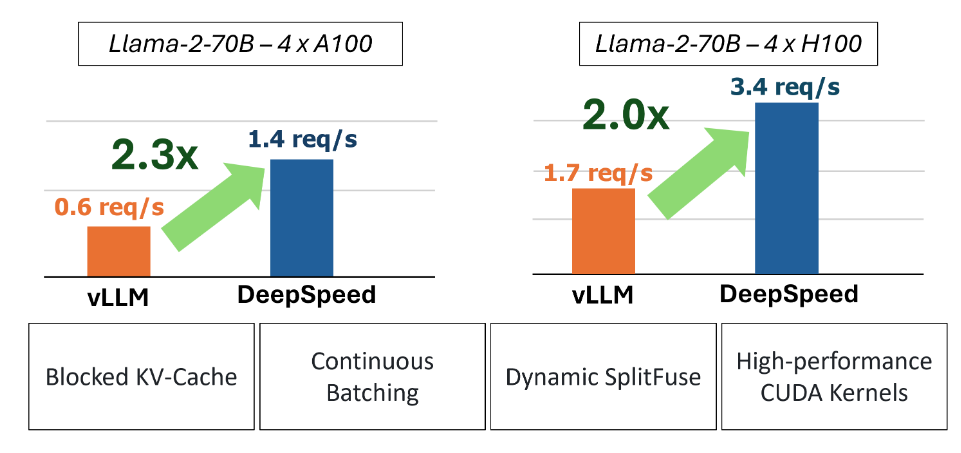
Модели, поддерживаемые DeepSpeed-FastGen:
DeepSpeed Следуя основным тенденциям отрасли Разбивка на части KV кеш, непрерывная пакетная обработкатехнология,Также представлено динамичный SplitFuse технология, которая представляет собой новую стратегию поиска и генеративной комбинации, позволяет использовать динамический оперативный генеративный декомпозиции, Объединение для дальнейшего совершенствования непрерывной пакетная обработка и пропускная способность системы. Подробности см. https://github.com/microsoft/DeepSpeed/blob/master/blogs/deepspeed-fastgen/chinese/README.md
Краткое изложение структуры рассуждений
- Если вывод ЦП, llama.cpp 结合Модельint4Количественная оценка,оптимальныйизвыбирать
- Вывод графического процессора, Microsoft из
DeepSpeed-FastGenЭто хороший выбор - По мнению мобильного терминала, MLC LLM может быть кандидатом
Платформа разработки приложений для крупных моделей
Почему ее называют платформой разработки?,Являются ли эти инструменты дополнением к обоснованию,Также существует стандартизированное API,и вспомогательные инструменты управления,Удобно разрабатывать и управлять приложением AI.
Xorbits Inference
https://github.com/xorbitsai/inference/blob/main/README_zh_CN.md
Xorbits Вывод (Xinference) — это мощная и всеобъемлющая среда распределенных рассуждений. Его можно использовать для вывода различных моделей, таких как модели большого языка (LLM), модели распознавания речи, мультимодальные модели и т. д. проходить Xorbits С помощью Inference вы можете легко развернуть свои собственные модели или встроенные передовые модели с открытым исходным кодом одним щелчком мыши. Независимо от того, являетесь ли вы исследователем, разработчиком или специалистом по данным, вы можете Xorbits Inference и Frontlineиз AI Модель для изучения большего количества возможностей.
Официально представлены основные функции:
🌟 Моделирование стало проще:большой язык Модель,Модель распознавания голоса,мультимодальный Модельизразвертывать Процесс значительно упрощается。Одна команда для завершения Модельизразвертывать Работа。 ⚡️ Ультрасовременные модели, все, что вам нужно:框架Внутри置众多中英文из前沿большой язык Модель,включая байчуань,chatglm2 Подождите, вы можете испытать это одним щелчком мыши! Встроенный список моделей также быстро обновляется! 🖥 Гетерогенное оборудование, молниеносно быстрое:проходить ggml,использовать одновременноиспользоватьтыиз GPU и CPU Выполняйте логические выводы, уменьшайте задержку и увеличивайте пропускную способность! ⚙️ Интерфейс вызова, гибкий и разнообразный:Обеспечьте разнообразное использованиеиспользовать Модельизинтерфейс,включать OpenAI совместимый RESTful API (включает Function Вызов), RPC, командная строка, Интернет UI Подождите, подождите. Удобная Модельиз управления и взаимодействия. 🌐 Кластерные вычисления, распределенное сотрудничество: Поддерживает распределенное развертывание. Благодаря встроенному планировщику ресурсов модели разных размеров можно распределять по разным машинам по требованию, обеспечивая полное использование ресурсов кластера. 🔌 Открытая экология, бесшовное соединение: и Популярность благодаря бесшовному соединению со сторонними библиотеками, в том числе LangChain,LlamaIndex,Dify,к及 Chatbox。
dify
https://github.com/langgenius/dify
Dify.AI — это открытый исходный код. LLM (Большая языковая модель) Платформа разработки приложений, которая интегрирует BaaS (бэкенд как услуга)и Концепция LLMOps охватывает создание генеративных AI Базовый стек технологий, необходимый для собственных приложений, включая встроенный RAG двигатель. использовать Dify, который можно развернуть самостоятельно на основе некоторых моделей с открытым исходным кодом, аналогичен Assistants API и GPTs способность.
Особенности диди:
1. Поддержка LLM:и OpenAI из GPT Модель серии интегрированная или с открытым исходным кодом. Llama2 Серия Модель интегрированная. Фактически, Dify поддерживает мейнстрим коммерческих моделей с открытым исходным кодом (локальное развертывание или на основе MaaS)。 2. Prompt IDE:иобъединитьсясуществовать Dify Сотрудничество посредством визуализации Prompt и следует использовать разработку инструментов оркестрации. AI приложение. Поддерживает плавное переключение нескольких больших языковых моделей. 3. РАГ двигатель:включать各种基В全文索引或向量数据库嵌入из RAG Возможность разрешить прямую загрузку PDF、TXT и другие различные тексты Формат. 4. AI Agent:基В Function Calling и ReAct из Agent Платформа вывода, которая позволяет пользователям настраивать инструменты, и вы получаете то, что видите. Диди Предоставляет более десяти встроенных возможностей вызова инструментов, таких как поиск Google, DELL·E, Stable. Diffusion、WolframAlpha ждать. 5. Текущая деятельность:монитори Анализ должениспользоватьбревноипроизводительность,Постоянно улучшать использование производственных данных. Подскажите, набор дат или модель.
ссылка



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
