Обновление Олламы! Он поддерживает вытягивание всех моделей на Huggingface одним щелчком мыши, что очень удобно! (vLLM, Fastgpt, Dify, рассуждения с несколькими картами)
🍹 Insight Daily 🪺
Aitrainee | Публичный аккаунт: AI-стажер
Привет, это Aitrainee, добро пожаловать на новую статью в этом выпуске.
Я помню,Начало мечты,Получено изOllama。Статья давным-давно научила вас проходить Ollama использовать открытый исходный код LLM, первый контакт для многих людей AI Время также началось с Олламы. Оллама Что делает его замечательным, так это то, что он использует GGML Формат, который представляет собой «облегченную» версию большой языковой модели, которая работает с более низкой точностью и может быть легко адаптирована к обычному оборудованию. Это делает запуск этих моделей в локальных системах простым и эффективным. AI открывая путь к широкому применению.
Сегодня Оллама стал лучше, и это обновление довольно большое, поскольку оно по сути открывает Олламе шлюзы для непосредственного использования различных моделей.
Раньше мы могли загружать только существующие модели в реестре моделей ollama. На самом деле это довольно неудобно. Например, когда мы раньше искали, не было китайской версии. Нам приходилось заходить в Huggface. найдите его сами, а затем настройте.
Теперь вы можете запустить любую из 45 тысяч моделей GGUF на концентраторе с помощью одной команды запуска ollama без создания нового файла модели.
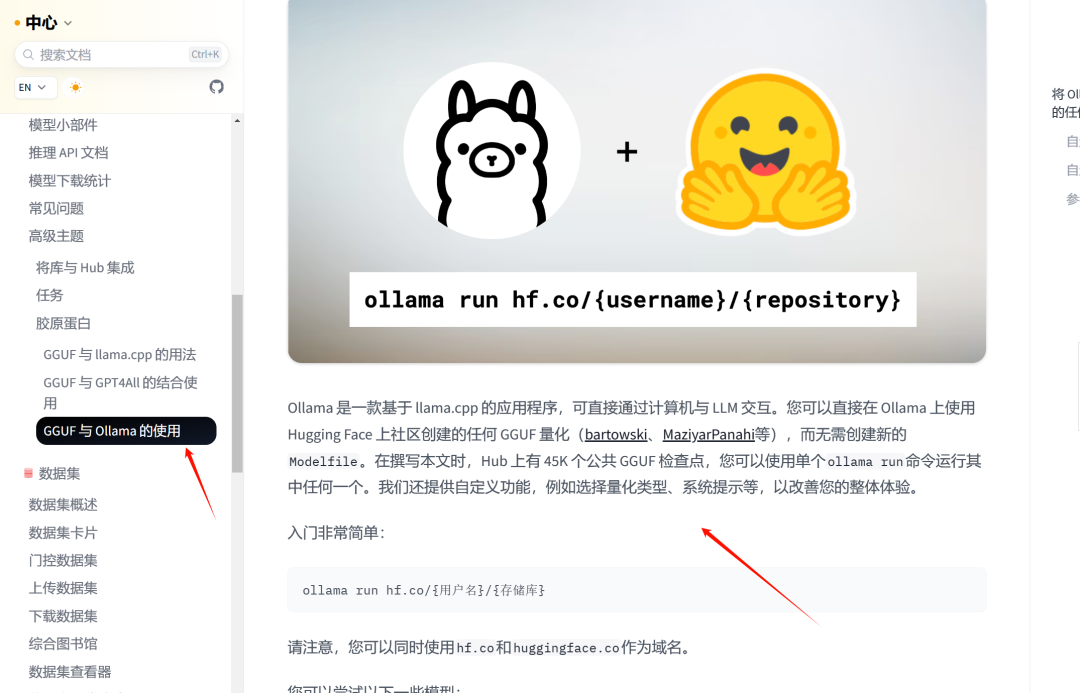
Все, что вам нужно сделать, это:
ollama run hf.co/{username}/{reponame}:latestНапример, чтобы запустить Llama 3.2 1B, вам нужно выполнить следующую команду:
ollama run hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF:latest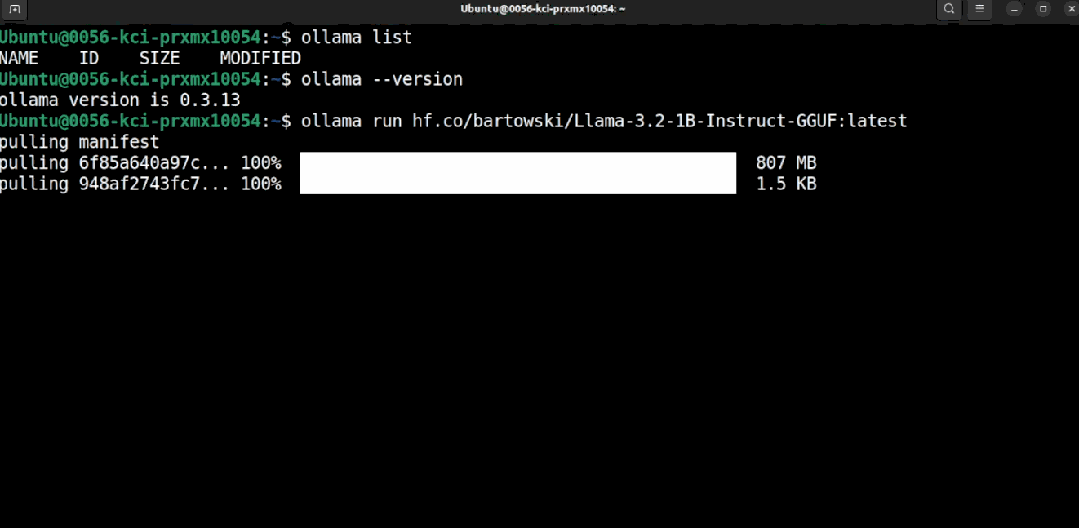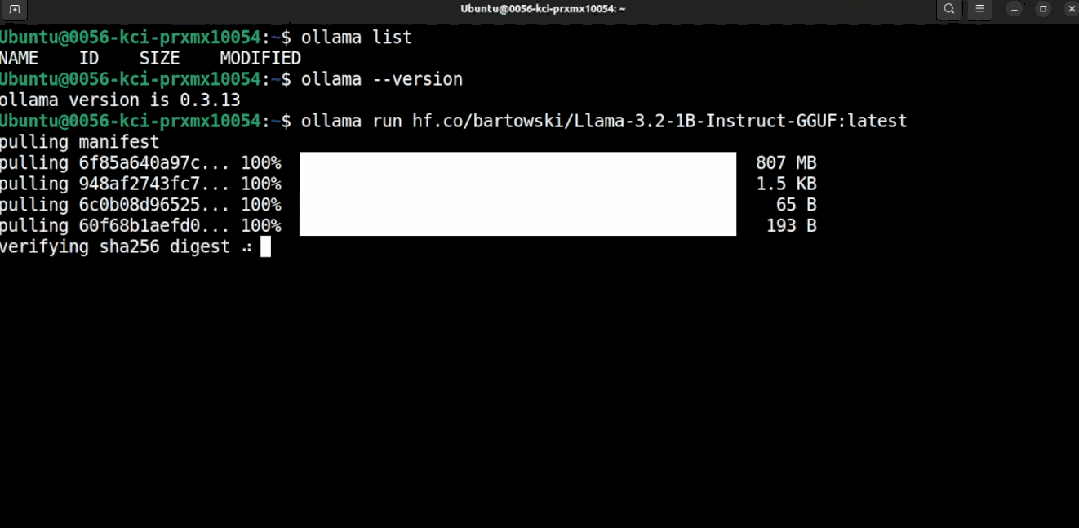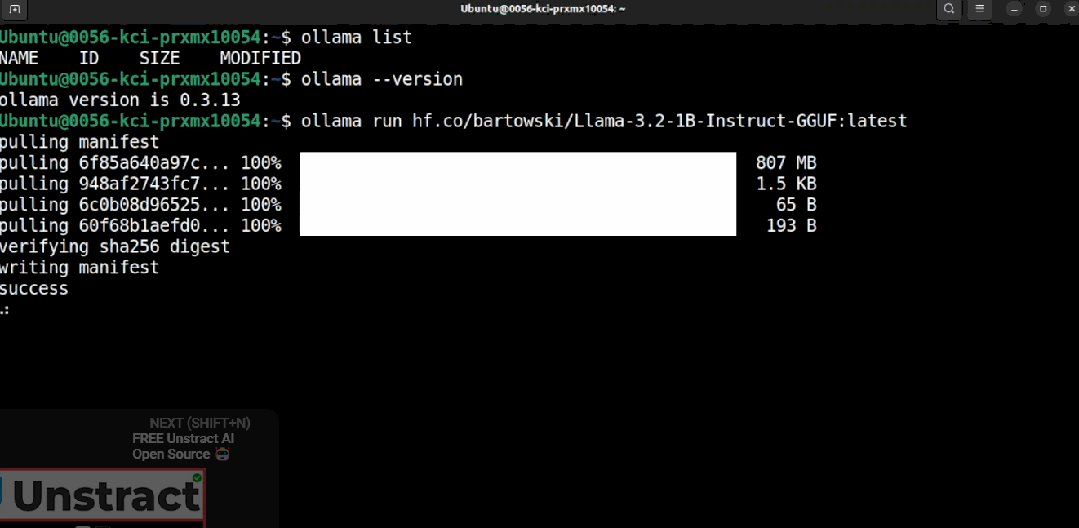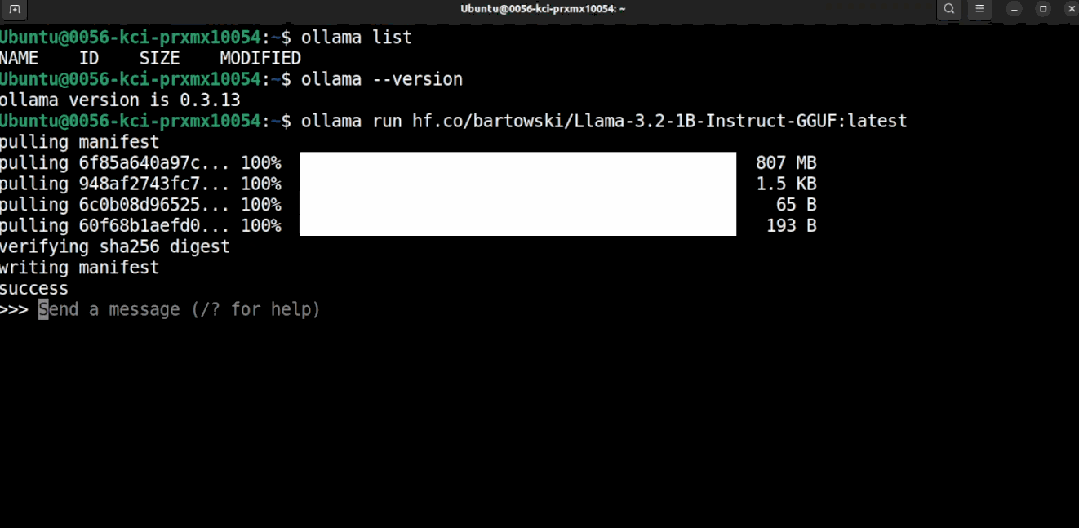
Если вы хотите запустить конкретную квантованную модель, просто укажите тип квантования:
ollama run hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF:Q8_0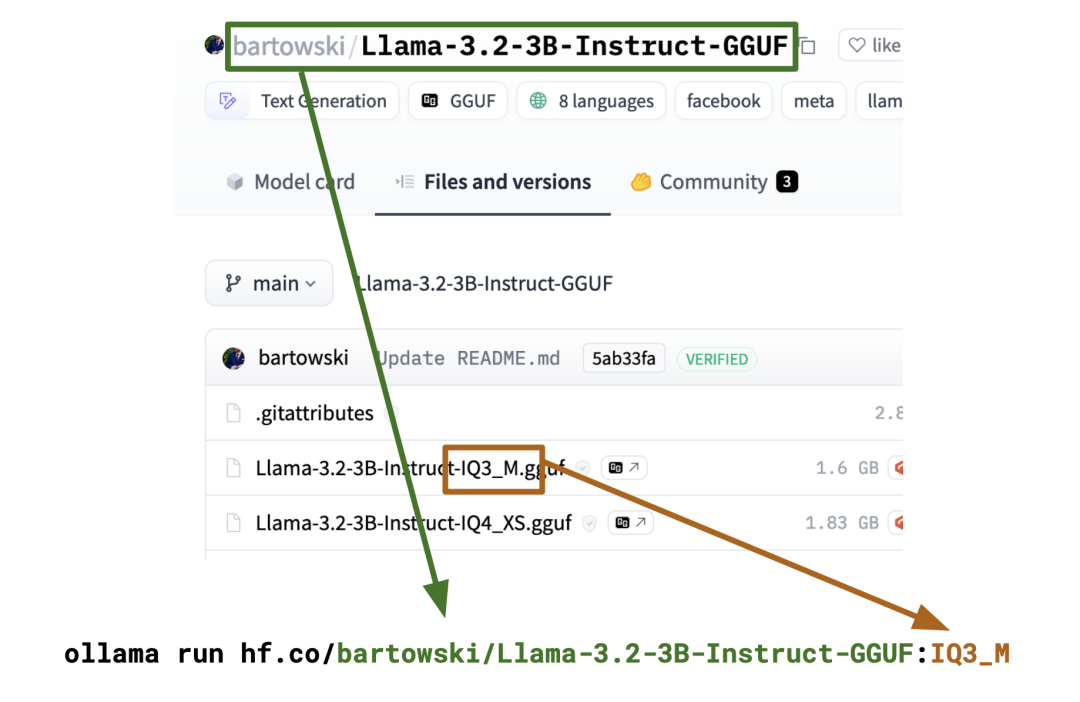
Вот и все! Благодаря этому обновлению то, что раньше представляло собой несколько шагов (то есть создание модели самостоятельно), превратилось в простую команду для загрузки, установки, настройки и запуска модели. Делает работу проще и удобнее (в этом весь смысл использования Ollama напрямую вместо llama.cpp). ⚡
Вы можете выбросить реестр Ollama в мусор уже сейчас, но, честно говоря, ждать, пока реестр Ollama станет совместимым с большим количеством моделей, совершенно невозможно, потому что это означает, что Ollama официально будет размещать все модели и станет вторым Huggface.
Обновленная ссылка на документацию Ollama: https://huggingface.co/docs/hub/en/ollama.
Вы не можете использовать ollama для прямой загрузки локально существующих файлов GGUF. Файл модели, который вы извлекаете из HF, будет переименован с помощью ollama в хэш-строку, что означает, что вы можете только повторно загрузить его и не можете использовать тот, который вы скачали ранее.
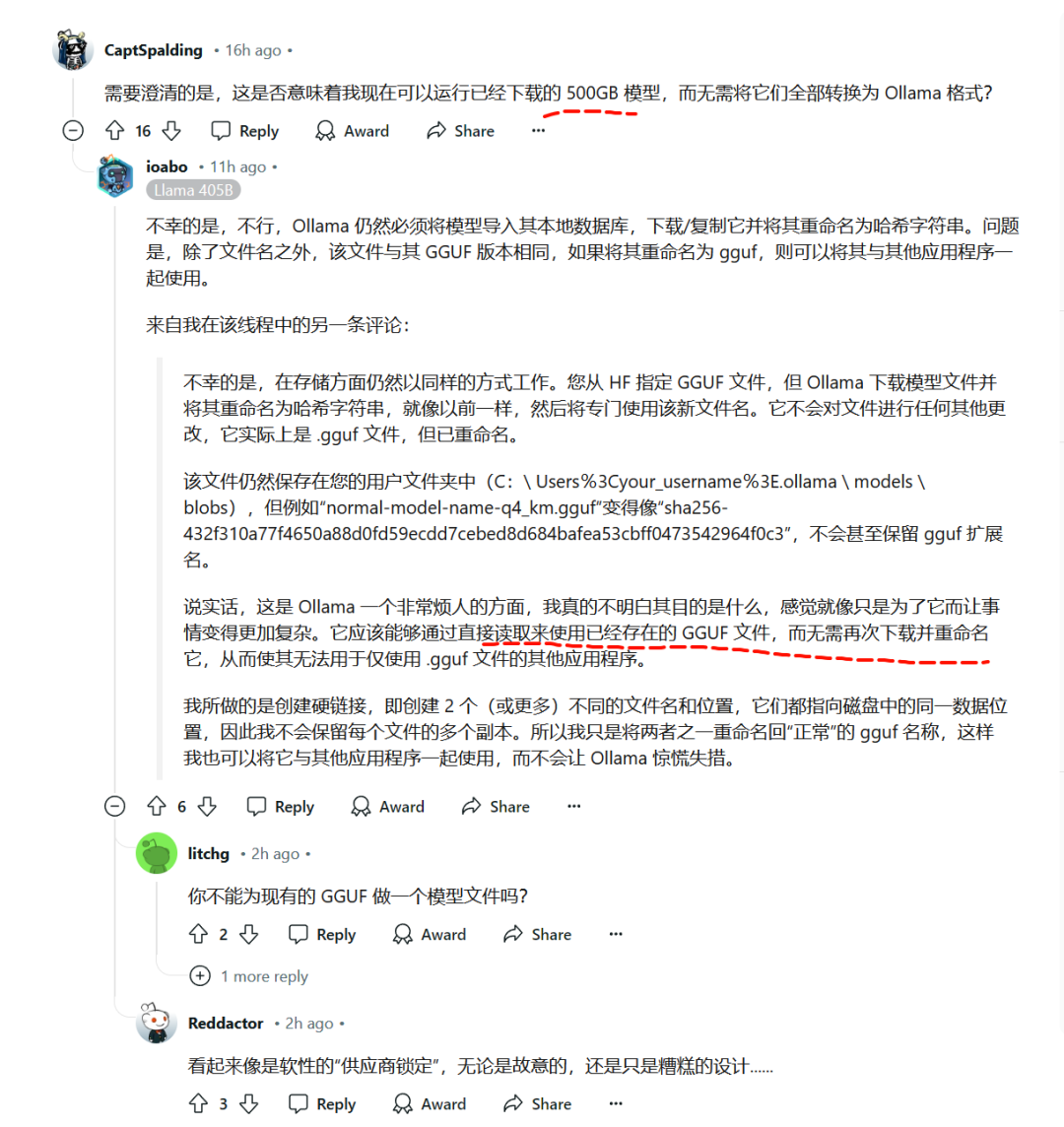
Как показано на рисунке, кто-то предположил, что потребности Ollama и других приложений могут быть удовлетворены одновременно путем создания жестких ссылок. То есть без копирования реальных данных один и тот же физический файл может существовать в системе с разными именами с помощью технических средств на уровне операционной системы, так что обе стороны могут беспрепятственно получить доступ к необходимым ресурсам.
Вот и все. Давайте поговорим еще немного.
Я продолжу знакомить вас с VLLM и «Выводом Олламы». по нескольким картам с одним узлом, ох, есть еще Huggface, modelscope Модель скачать, а потом просто доступ через Dify, Модель FastGPT, связанное Встраивание и перестановка моделейразвертывать、Использование Llama.cpp、Объединение GGUFМодель、OllamaНастроить Модельстроительство и т. д.,Это может быть немного долго.
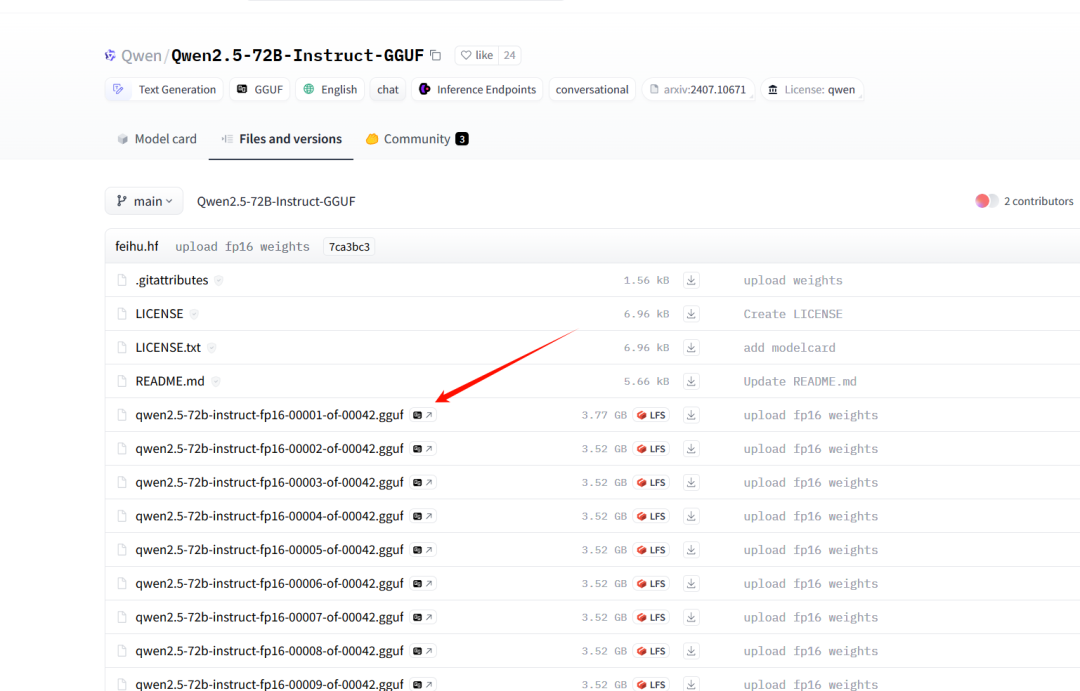
Получение модели LLM (зеркало, ModelScope)
Используя четыре метода, представленные в этой статье, Оллама использует приведенную выше модель объятий, а также необходимо изменить изображение. Подробности см. в этой статье.
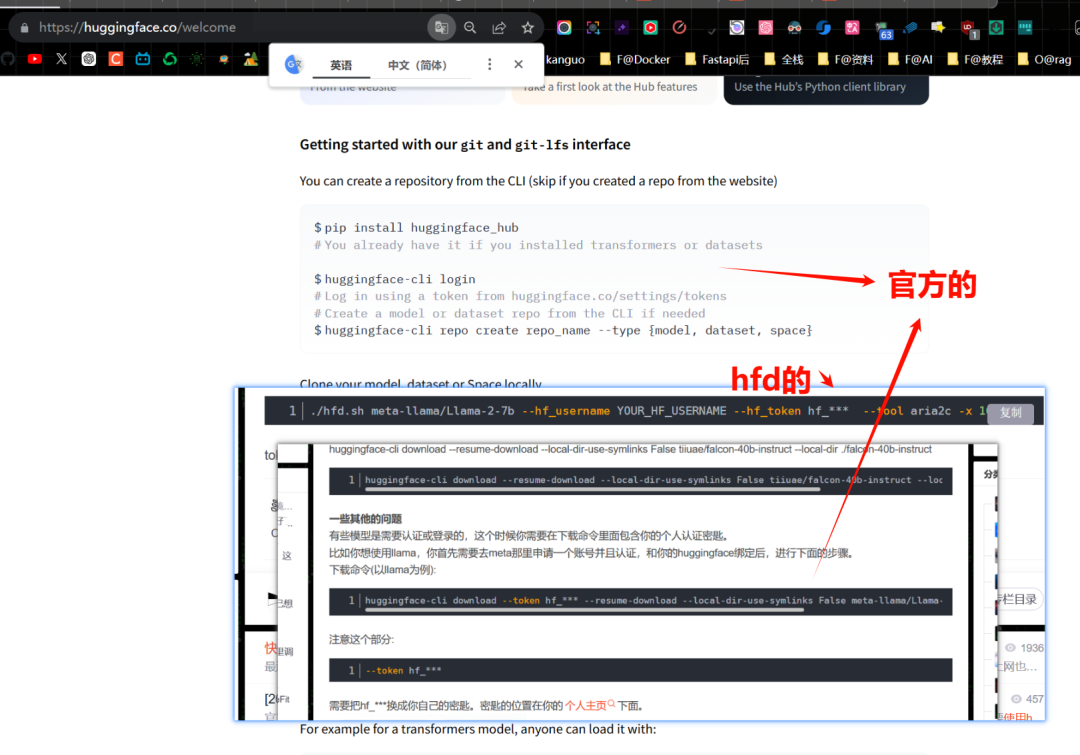
https://blog.csdn.net/m0_59741202/article/details/135025946После прочтения статьи выше мне нужно добавить несколько команд:
Иногда нам нужно скачать одну из моделей, мы можем использовать команды aria2c иhuggingface-cli.
Пакетная загрузка нескольких файлов одной модели GGUF под один склад:
huggingface-cli download --resume-download --local-dir-use-symlinks False --include "qwen2.5-72b-instruct-q8_0-*.gguf" --local-dir qwen2.5-72b-instruct-q8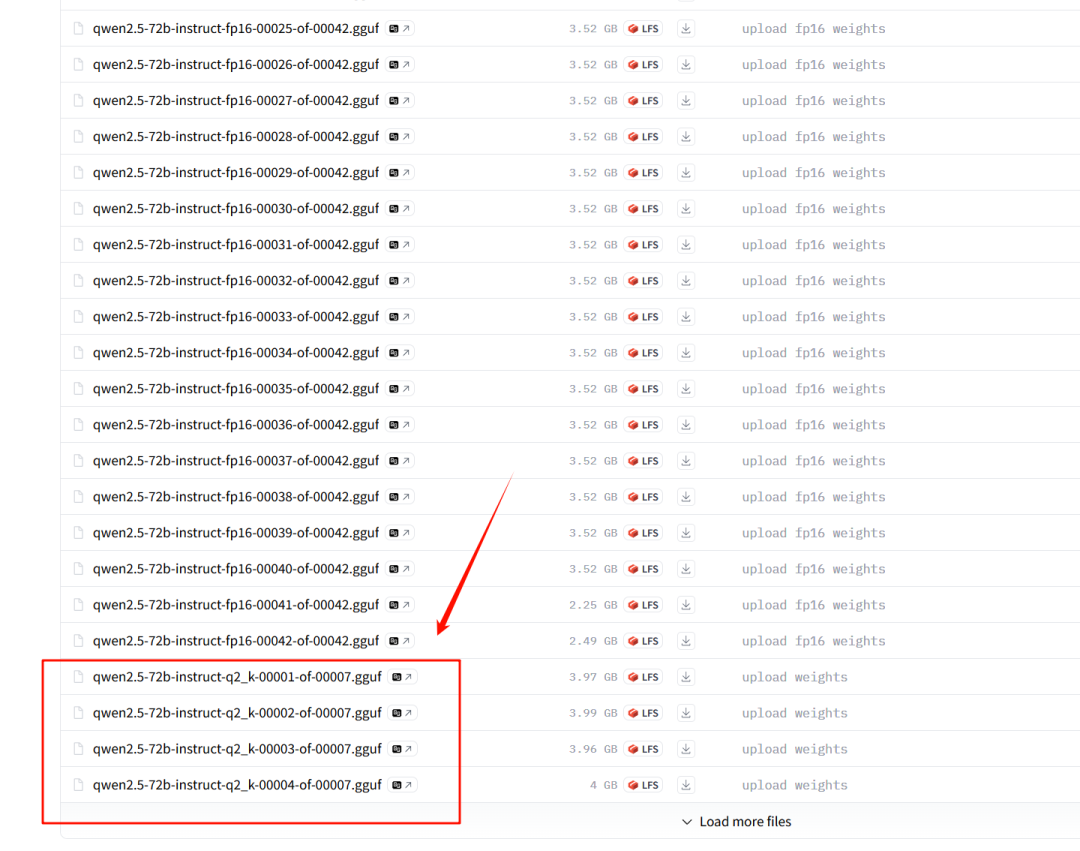
Или вы можете использовать aria2c+ для написания скриптов (циклов и т.п.)
Есть две команды для моделей, которые необходимо загрузить для сертификации в HuggingFace.
Вывод VLLM для одного узла и нескольких карт
Ollama работает слишком медленно при запуске более крупных моделей на нескольких картах, таких как 32B и 72B. Он подходит для вопросов и ответов ИИ одного человека и не подходит для предоставления производственных услуг или подключения к производственным рабочим процессам. Это одна из основных сред ускорения LLM.
В случае CUDA версии 12.1 установка VLLM относительно проста.
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.10 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllmЕсли вы хотите запустить визуальную модель, такую как Qwen2 VL, вам следует сначала установить vLLM, а затем установить разрабатываемую версию преобразователей.
pip install vllm
pip install git+https://github.com/huggingface/transformers@21fac7abba2a37fae86106f87fcf9974fd1e3830 accelerateПосле установки платформы vllm есть два способа запустить службу модели. Один из них — запустить ее напрямую. Она перейдет в HuggingFace, чтобы загрузить модель самостоятельно (не забудьте использовать зеркало).
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123Или, чтобы использовать модель из ModelScope, вам необходимо установить переменную среды:
export VLLM_USE_MODELSCOPE=TrueДругой вариант — загрузить локальную модель и запустить
vllm serve /home/ly/qwen2.5/Qwen2.5-32B-Instruct/ --tensor-parallel-size 8 --dtype auto --api-key 123 --gpu-memory-utilization 0.95 --max-model-len 27768 --enable-auto-tool-choice --tool-call-parser hermes --served-model-name Qwen2.5-32B-Instruct --kv-cache-dtype fp8_e5m2Vllm имеет множество параметров. Параметры, используемые в приведенной выше серии команд, мы обычно используем. Эти параметры по-прежнему влияют на производительность модели.
--tensor-parallel-size — это параметр, используемый для распределенных рассуждений. Установка его в единицу означает рассуждение с одной картой, то есть рассуждение с 8 картами (рассуждение Олламы находится в конце статьи). что на одной машине имеется несколько карт, рассуждения о нескольких узлах и нескольких картах относятся к рассуждениям о нескольких машинах и нескольких графических процессорах.
Влияние следующих параметров ограничено и не будет объяснено подробно.

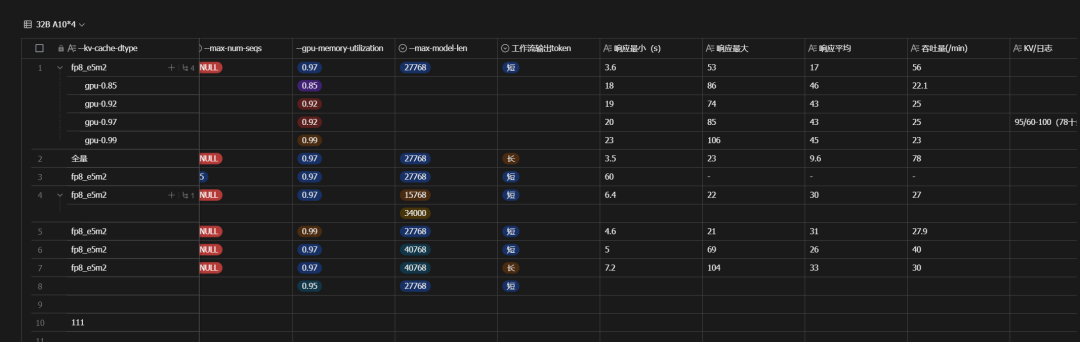
▲ Некоторые параметры Vllm влияют на таблицу одновременной производительности.
Vllm определяет определенную модель работы графического процессора следующим образом:
CUDA_VISIBLE_DEVICES=6 vllm serve /home/ly/qwen2.5/Qwen2-VL-7B-Instruct --dtype auto --tensor-parallel-size 1 auto --api-key 123 --gpu-memory-utilization 0.5 --max-model-len 5108 --enable-auto-tool-choice --tool-call-parser hermes --served-model-name Qwen2-VL-7B-Instruct --port 1236Vllm не поддерживает запуск службы и случайное переключение на другие модели (ollama поддерживает это). Обычно вам нужно запускать команду vllm отдельно для каждой модели, и каждая модель должна предоставлять свой порт. Например, ее порт по умолчанию — 8000. и Моя последняя команда использовала порт 1236. Вы можете использовать Tmux, чтобы позволить каждой из ваших служб Vllm работать в фоновом режиме, не затрагивая закрытие терминала.
Встраивание и перестановка моделей
В настоящее время Vllm, похоже, не поддерживает встраивание и перестановку этих моделей.
Текущий рейтинг встраиваемых моделей находится здесь:
https://huggingface.co/spaces/mteb/leaderboard
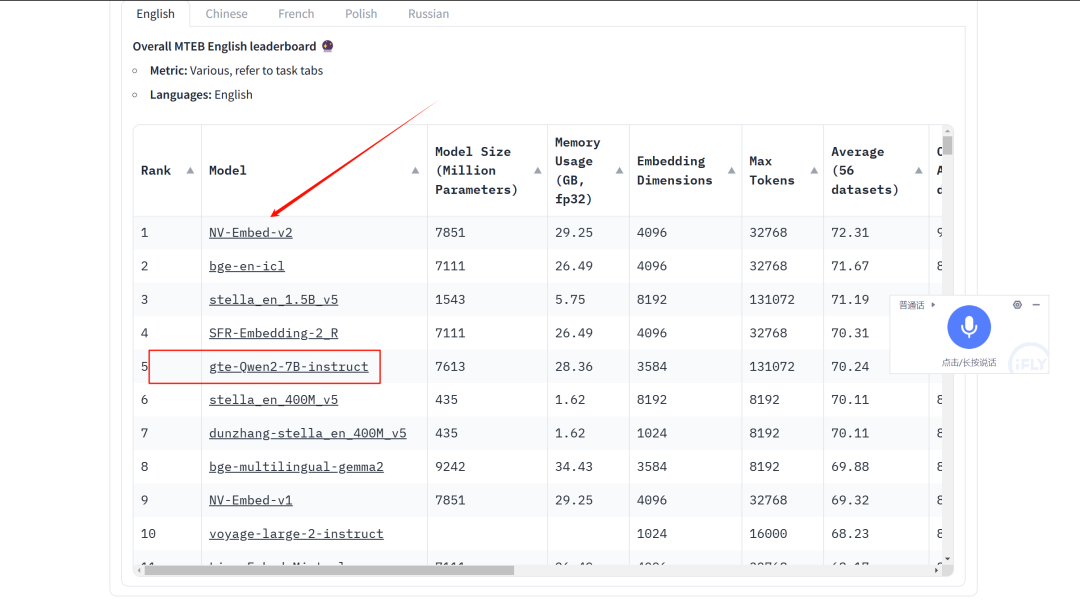
GTE от Alibaba хорош. Вы можете рассмотреть возможность использования этой модели 1.5B или 7B в китайской среде.
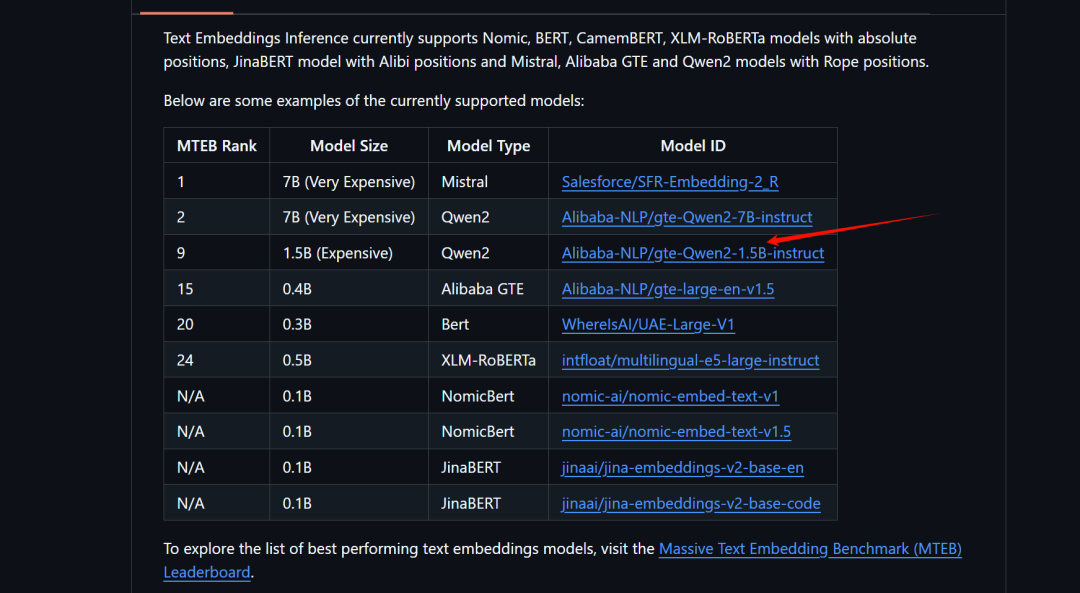
Используемая ранее версия bge-base-zh-v1.5 все еще относительно мала.
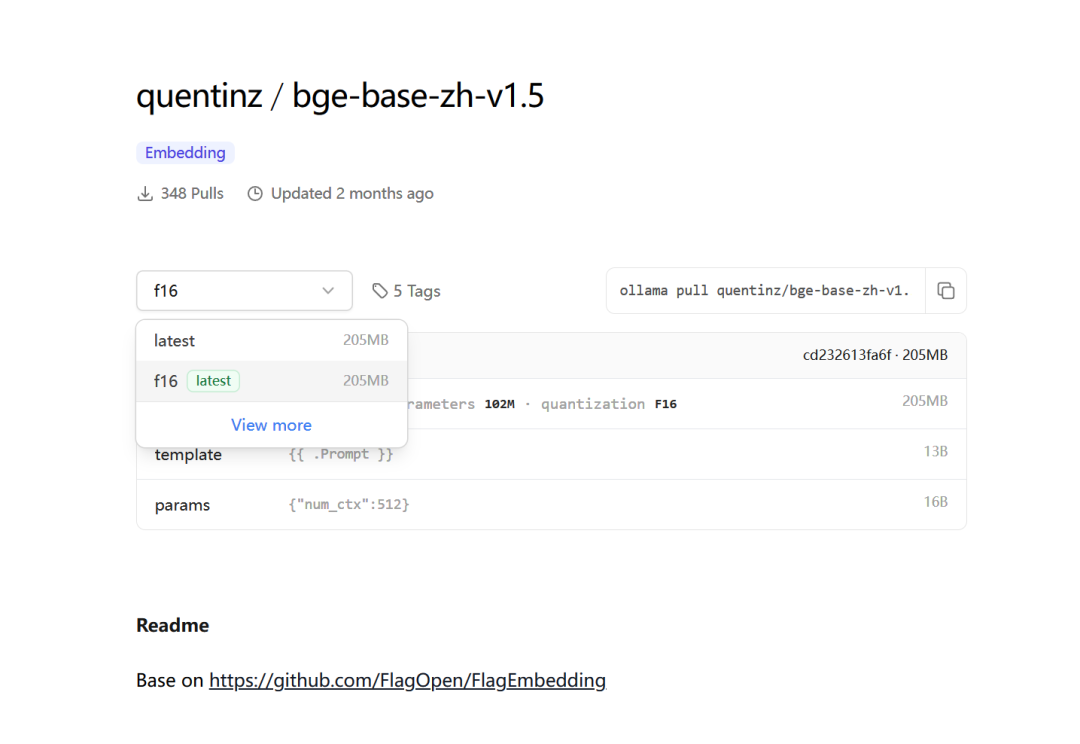
Рейтинг en-версии тоже не очень высок.
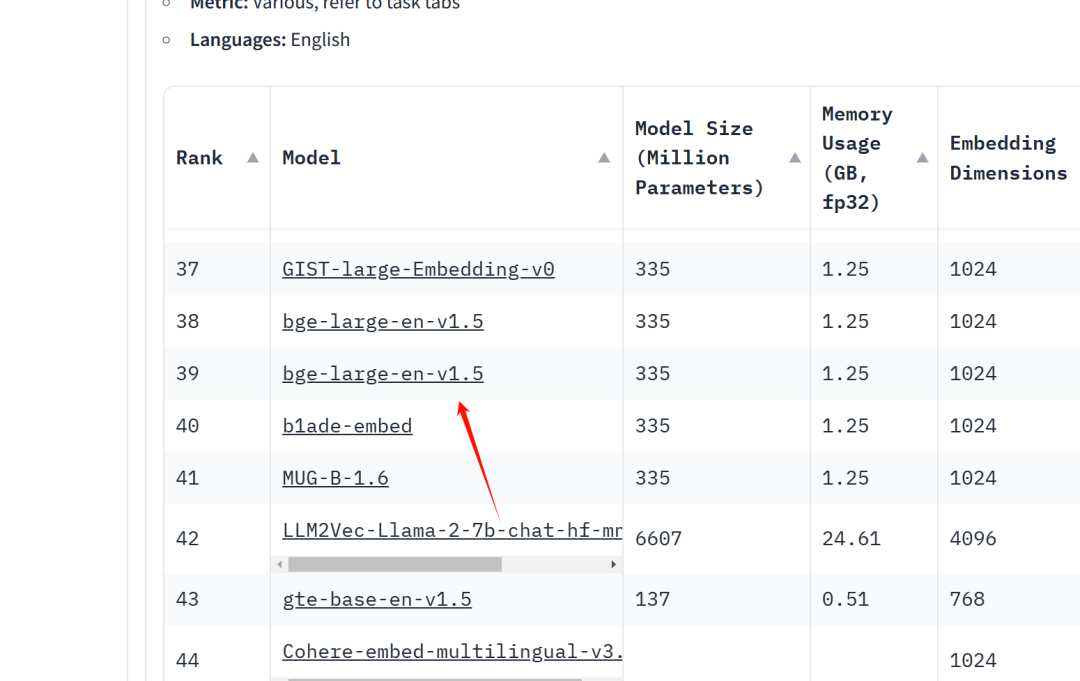
Проект text-embeddings-inference (https://github.com/huggingface/text-embeddings-inference) обеспечивает развертывание этих моделей перестановки и внедрения.

Этот проект будет использоваться для доступа к двум моделям в Dify.
Интерфейс доступа Ollama от Dify не имеет моделей перестановки.
Развертывание переставленных моделей в Docker также доступно в документации FastGPT.

# auth token для моего токена
docker run -d --name reranker -p 6006:6006 -e ACCESS_TOKEN=mytoken --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-base:v0.1FastGPT, доступ к модели с открытым исходным кодом Dify
FastGPT использует Oneapi для доступа к модели, и очень удобно настраивать различные модели, о которых я писал ранее:
Dfiy кратко объяснит:
1. Доступ к Олламе
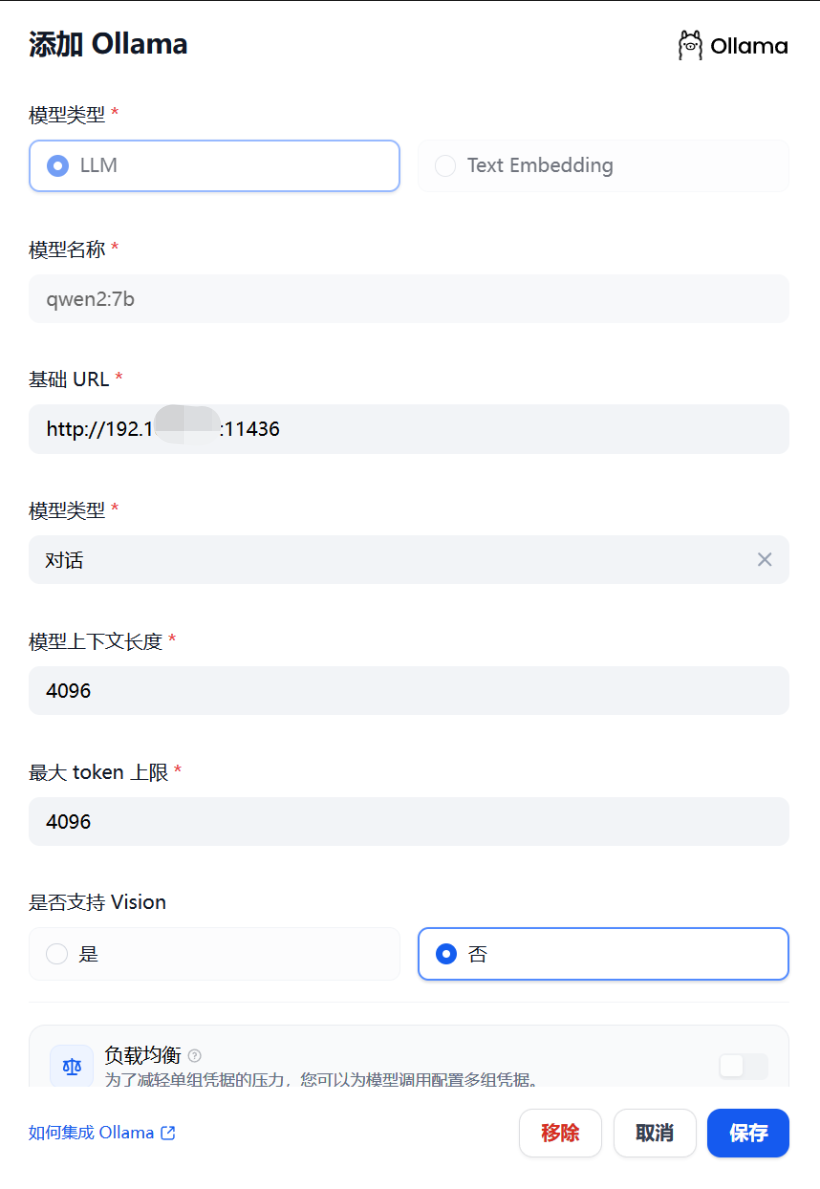
2. Наиболее часто используемый формат определенно совместим с OpenAl-API, который является форматом, совместимым с OpenAI. Например, Vllm необходимо использовать этот доступ, OpenAl-API-совместимый+Vllm (по умолчанию Vllm работает на порту 8000):
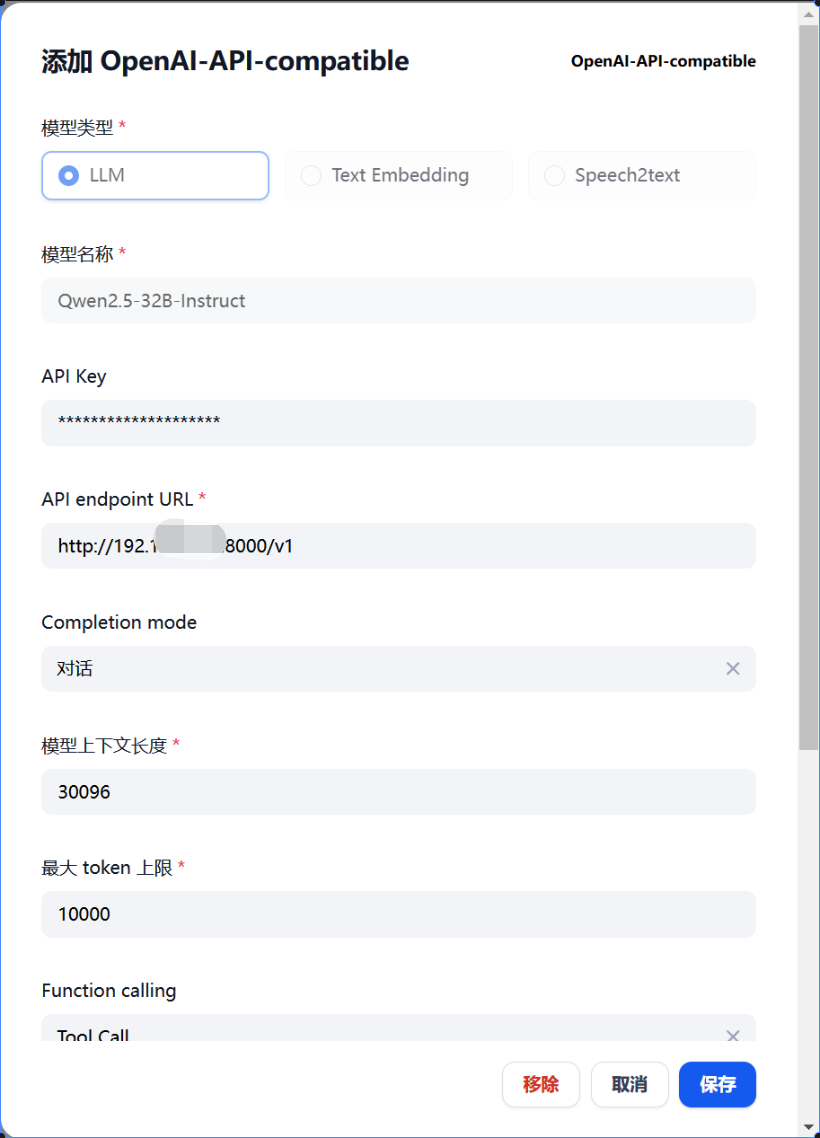
3. Совместимость с Oneapi+OpenAl-API, Oneapi — это порт 3001, не забудьте указать его ключ API:
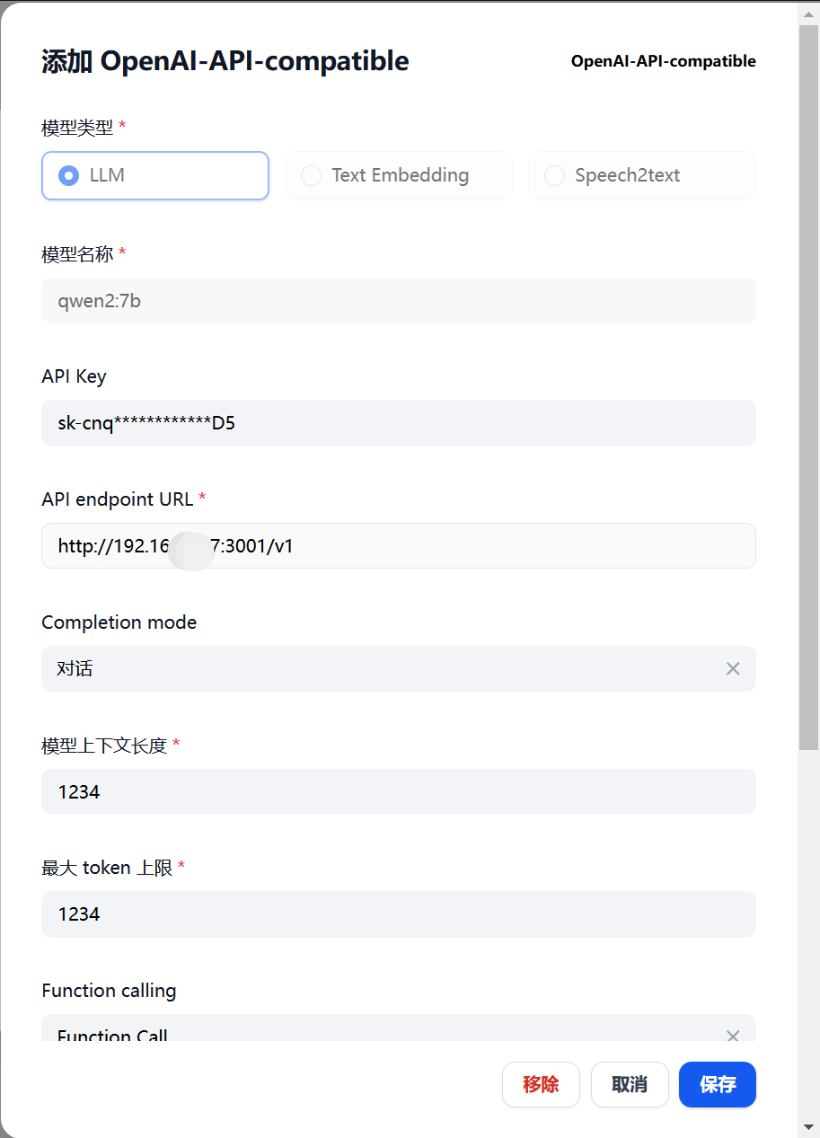
В Oneapi есть встроенная модель и тот же метод доступа.
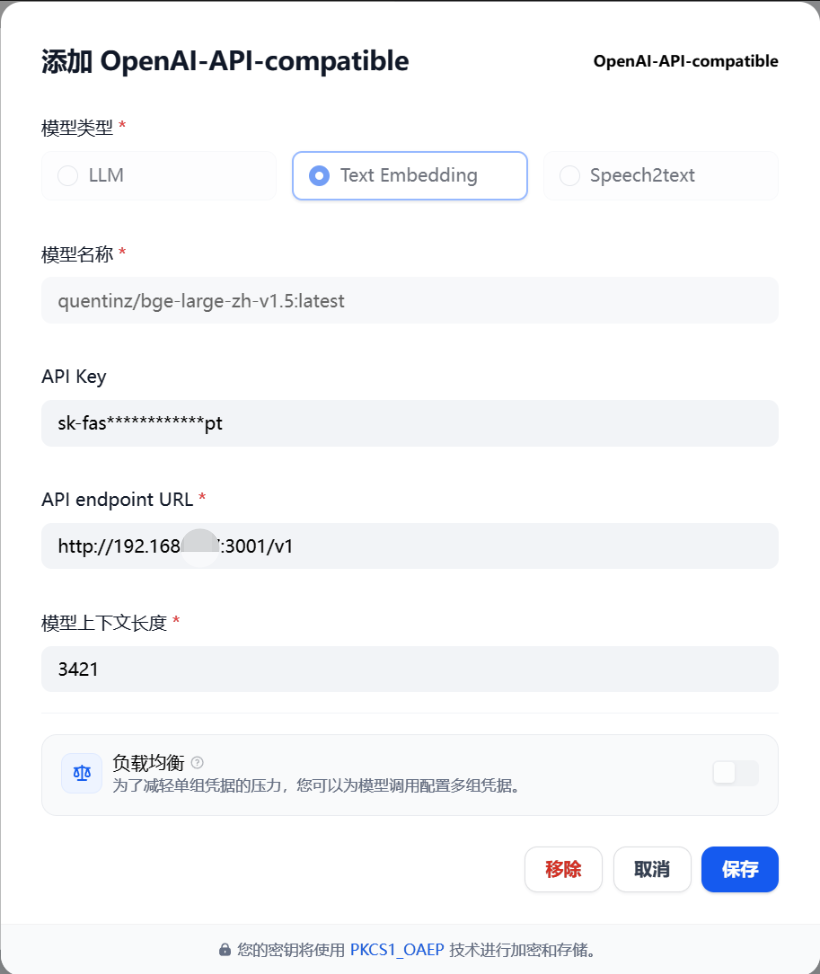
Слияние GGUF, построение модели Оллама
У Олламы есть три способа создания собственных моделей (хотя после этого обновления это нам не понадобится):
https://github.com/ollama/ollama/blob/main/docs/modelfile.md
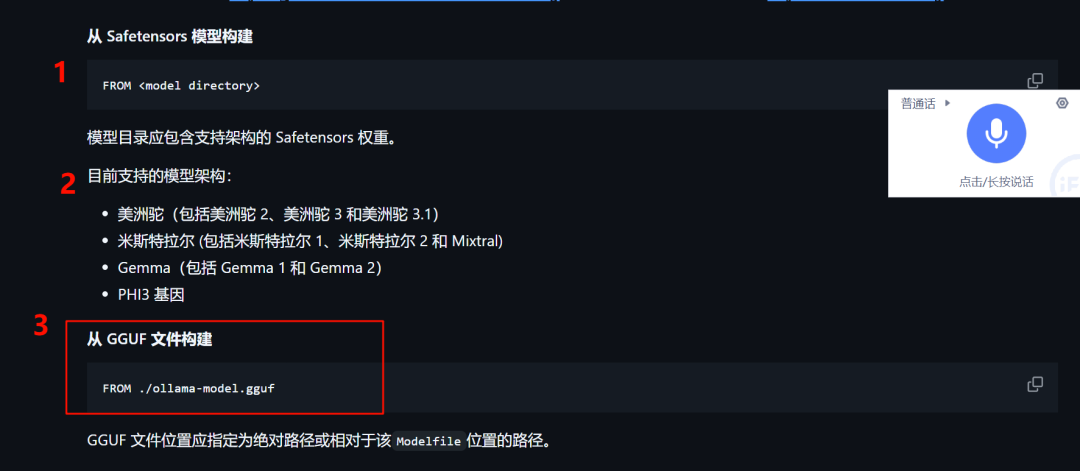
Особенно третий тип GGUF. Некоторые количественные модели GGUF необходимо объединить, прежде чем их можно будет использовать. Это также является обязательным условием для использования Ollama для создания собственной модели.
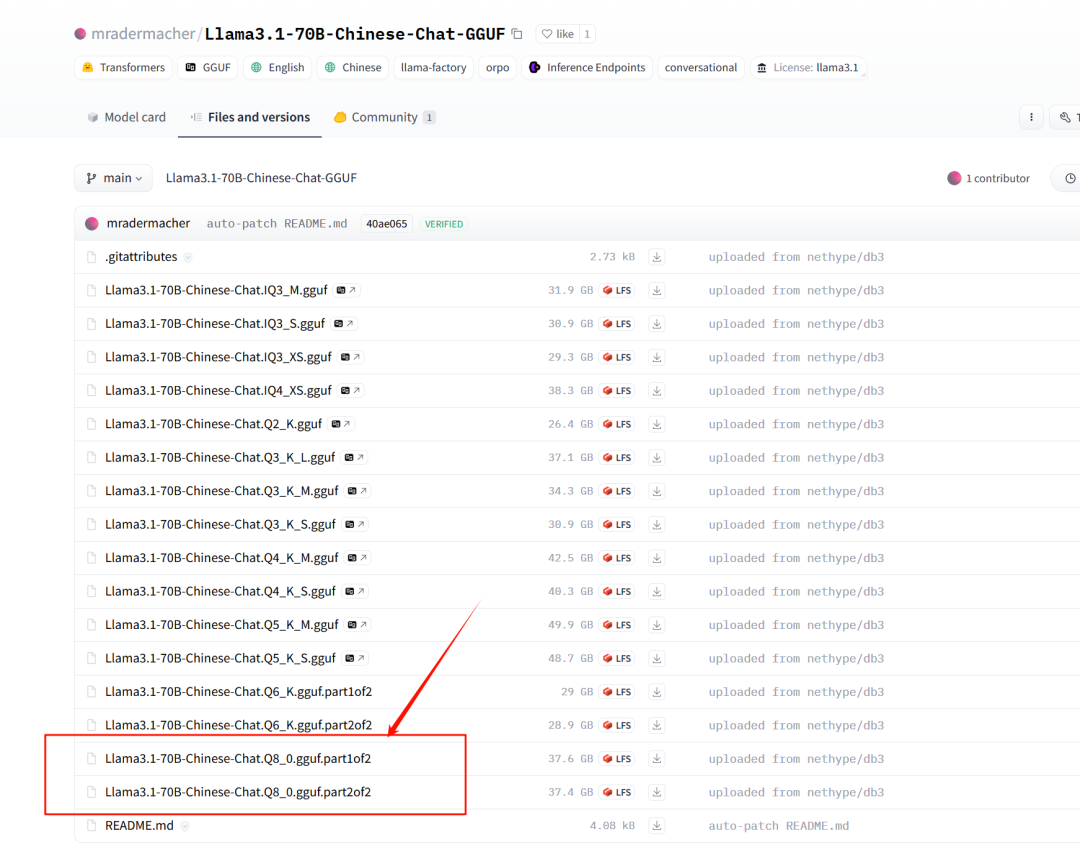
Есть два способа слияния (на некоторых складах Huggface есть инструкции. Первый — использовать cat.
cat swallow-70b-instruct.Q6_K.gguf-split-* > swallow-70b-instruct.Q6_K.gguf
cat swallow-70b-instruct.Q8_0.gguf-split-* > swallow-70b-instruct.Q8_0.ggufКажется, я объединил некоторые подобные модели, но их нельзя нормально использовать.
Второе: используйте llama.cpp.
Клонируйте репозиторий llama.cpp.
git clone git@github.com:ggerganov/llama.cpp.giЗатем используйте llama-gguf-split для слияния.
./llama-gguf-split --merge qwen2.5-7b-instruct-q4_0-00001-of-00002.gguf qwen2.5-7b-instruct-q4Помните, что вам нужно указать только первый файл gguf, например qwen2.5-7b-instruct-q4_0-00001-of-00002.gguf. Не записывайте все файлы gguf, иначе второй файл gguf будет использоваться как объединенный файл. а затем будет сброшен. Если он равен 0, это приведет к тому, что загруженный вами файл модели будет в течение длительного времени напрямую поврежден, что является огромной ямой. Изначально я прочитал такую статью и был введён в заблуждение.
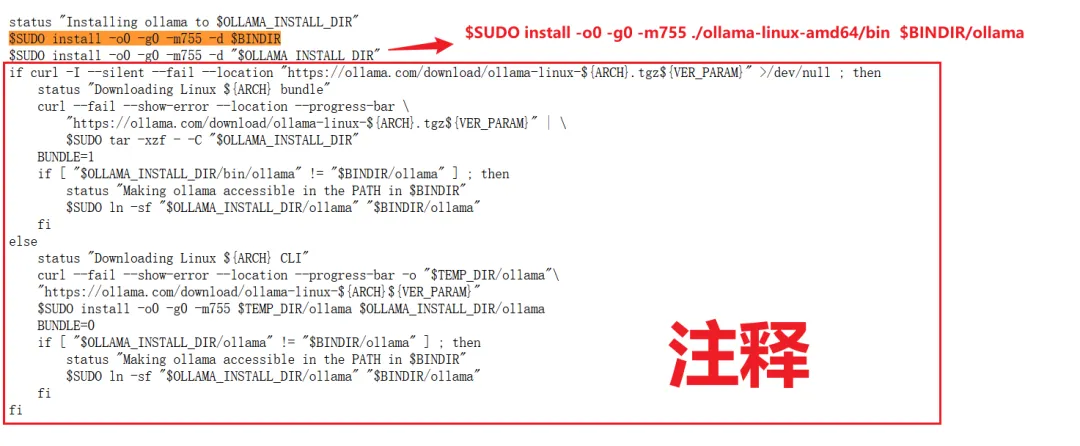
Верно,Если версию ollama Linux невозможно загрузить из-за проблем с внутренней сетью,Эта статья объясняет,Это маленькая ошибка,
Добавьте ollama после bin, а именно: ollama-linux-amd64/bin/ollama
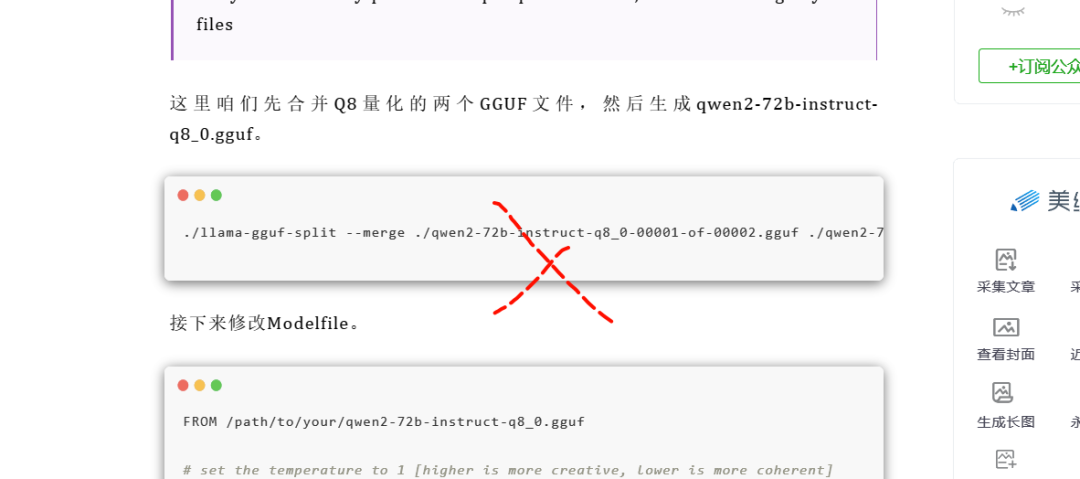
О том, как компания Ollam создает собственные модели,В Интернете есть много обучающих программ по начальству, вот откуда они.,например
https://mp.weixin.qq.com/s/q73MQWwxNwB-cnKpqVDORw
Но модель слияния статей здесь неправильная. Не записывайте в команду все файлы GGUF.
Возвращаясь к построению модели, хочу пояснить, что построение модели под Docker требует монтирования тома данных модели:
Мы запускаем докер-сервис ollama следующим образом и указываем вывод нескольких карт на 5 и 7 графических процессорах.
docker run -d -e CUDA_VISIBLE_DEVICES=5,7 -e OLLAMA_FLASH_ATTENTION=1 -e OLLAMA_NUM_PARALLEL=64 -v ollama:/root/.ollama -v /home/ly/:/mnt/data -p 11436:11434 --name ollama6 ollama/ollama serve
Файл Modelfile.txt записывается следующим образом:
FROM "/mnt/data/Qwen2.5-72B-Instruct-GGUF/merge/qwen2.5-72b-instruct-q2_k.gguf"
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"Путь /mnt/data/, на который указывает FROM, — это том внутри контейнера Ollama Docker, соответствующий модели, хранящейся в /home/ly/ на хост-компьютере.
Затем мы выполняем следующую команду для построения модели
docker exec ollama6 ollama create qwen2.5-72b-instruct-q2_k -f /mnt/data/Modelfile.txtЕго можно успешно построить и использовать так же, как модель, созданную Олламой.
Ладно, в общем, это всё. Воспользовавшись обновлением Ollama, я хотел бы поделиться некоторыми практиками развертывания LLM, хотя это немного просто.

🌟Надеюсь, эта статья будет вам полезна, спасибо за прочтение! Если вам понравилась эта серия статей, пожалуйста Нравиться / делиться / заглянуть говорит мне таким образом, что я могу использовать его для оценки творческого направления.

👽Submission:kristjahmez06@gmail.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
