Обновление одной таблицы в PowerBI можно выполнить следующим образом.
На выходных студент задал такой вопрос:
Учитель хотел бы спросить, pbi подключил файлы sql и onedrive, но sql находится в интранете, я думаю, он может только автоматически обновлять файлы onedrive? Я настроил обновление и продолжал получать сообщение об ошибке, сообщающее, что sql не может быть обновлен.
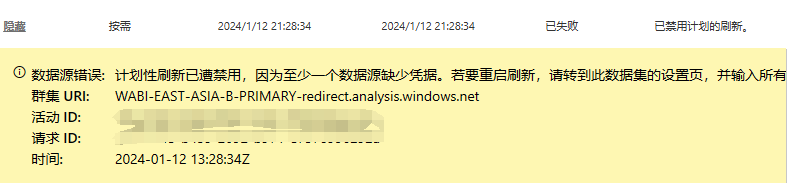
Если вы нажмете «Обновить» обычным способом, что-то обязательно пойдет не так. Обновление вручную приведет к обновлению всех таблиц и источников данных. Если в одном источнике данных отсутствуют учетные данные, произойдет сбой.
И в этом случае запланированное обновление вообще невозможно настроить.
Вариант 1
Первое решение, которое приходит на ум, — отменить «включить в обновление отчета» в powerquery.
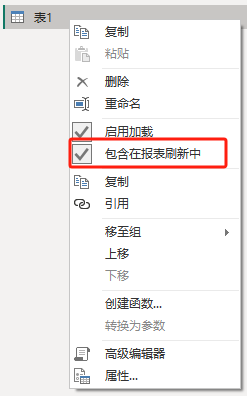
Но на самом деле этот метод невозможен. Он только контролирует таблицу, которая будет игнорироваться при всех обновлениях рабочего стола. При фактической публикации в облаке для обновления вам все равно необходимо настроить учетные данные источника данных.
Вариант 2
В связи с этим пришло на ум другое решение: асинхронное обновление.
Если вы не знакомы с концепцией асинхронного обновления, вы можете посмотреть следующее видео:
Асинхронное обновление, также называемое расширенным обновлением. Вы можете обновить одну таблицу или даже часть одной таблицы, и эффект будет даже более мощным, чем при добавочном обновлении.
но,Для этого пользователю необходимо быть【Администратор powerbi】и будет Конфигурация Связанный контент;В противном случае администратор арендатора должен Конфигурацияи предоставить соответствующие услуги。
Предположим, что существуют таблица A (файл onedrive) и таблица B (база данных внутренней сети). Теоретически, если между таблицей A и таблицей B нет никакой связи, обновление одной таблицы A вообще не требует участия таблицы B, поэтому даже если таблица B не предоставляет учетные данные источника данных, таблица A должна быть обновлена успешно.
Но после тестирования выяснилось, что это все же не удалось:
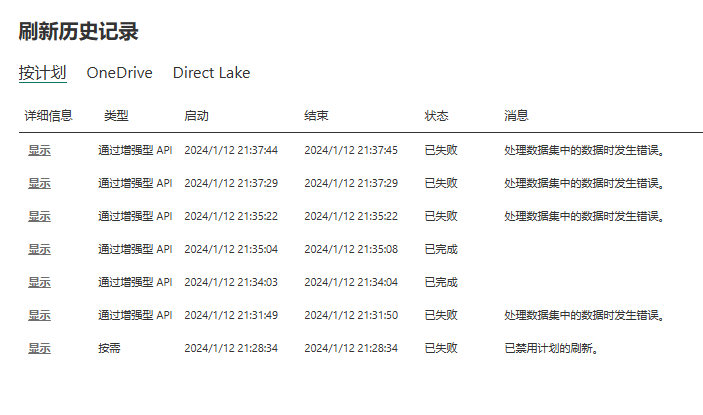
Сообщение об ошибке следующее:
Ошибка источника данных: {"error":{"code":"DMTS_DatasourceHasNoCredentialError","pbi.error":{"code":"DMTS_DatasourceHasNoCredentialError","details":[{"code":"Path","detail":{"type":1,"value":"d:\\onedrive\\B.xlsx"}},{"code":"ConnectionType","detail":{"type":0,"value":"File"}}],"exceptionCulprit":1}}}
Из содержимого, выделенного жирным шрифтом, мы видим, что причина ошибки заключается в том, что таблица B не имеет учетных данных источника данных. Но мы должны отметить, что мы выполняем обновление одной таблицы для таблицы A. На самом деле проблем с таблицей B и учетными данными источника данных таблицы B вообще нет. Так почему же обновление завершается неудачно?
Причина на самом деле кроется в «учетных данных источника данных», которые нельзя настроить. Хотя с учетными данными файлового источника данных в onedrive проблем нет, в базе данных не установлен шлюз, поэтому он не может настроить. Таким образом, все учетные данные для этого источника данных недействительны.
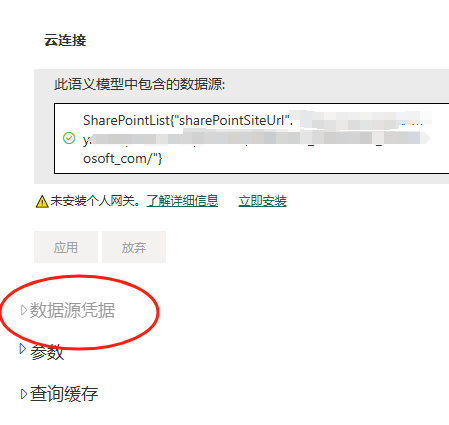
Первым шагом при любом обновлении данных является определение допустимости учетных данных источника данных, что приведет к сбою.
Однако мы обнаружили, что по-прежнему было два успешных обновления отдельных таблиц.
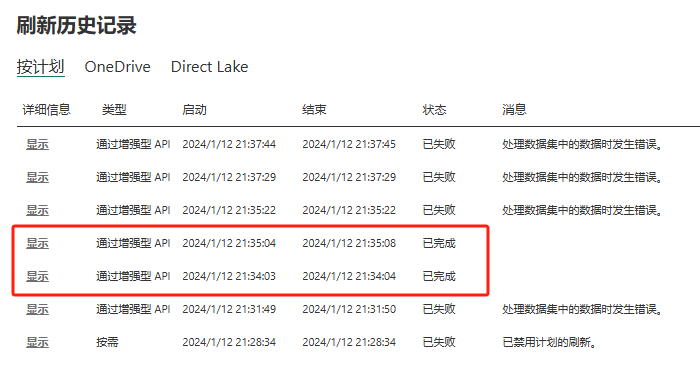
Однако эти два обновления не обновляют таблицу A, а обновляют таблицу дат C и таблицу D, созданные путем ввода данных вручную.
Причина на самом деле очень проста, поскольку эти две таблицы вообще не предполагают настройку учетных данных источника данных, поэтому при обновлении они не будут проверять, являются ли учетные данные источника данных нормальными, и будут обновляться напрямую.
Вариант третий
Обе вышеперечисленные догадки не оправдались.
Но из этого можно сделать два вывода. Во-первых, учетные данные источника данных должны быть настроены правильно, что является основой для обновления; во-вторых, две таблицы необходимо разделить, независимо от формы разделения, как и при обновлении одной таблицы. сейчас это тоже форма разделения.
Учетные данные источника данных настроены правильно, поэтому окончательный набор данных не должен поступать непосредственно из базы данных интрасети. Должен быть промежуточный шаг для передачи данных базы данных в определенное место и последующего получения данных.
Итак, вопрос в том, куда мне его передать и получить?
Давайте начнем со «сбора» и посмотрим, как PowerBI получает данные. Интересно, вы сразу видите ответ?
Правильно, это «Семантическая модель PowerBI», которая представляет собой предыдущий набор данных.
Идея такова: сначала получить данные из базы данных интрасети на рабочем столе, опубликовать их в службе, а затем получить опубликованную семантическую модель на рабочем столе. На данный момент вы создали «гибридную модель»:

Затем снова опубликуйте гибридную модель в облаке. После настройки учетных данных источника данных ее можно будет обновить в обычном режиме.

Подвести итог
В этой статье предлагаются три решения особой проблемы. Хотя окончательно решено только третье, первые два решения также очень эффективны в других сценариях.
В частности, асинхронное обновление в сочетании с onedrive для бизнеса и powerautomate позволяет поместить новую таблицу в локальную папку (которая сама содержит множество таблиц) и автоматически запустить обновление этой новой таблицы, достигая приращения, о котором мечтают многие люди.
Третье решение, гибридный режим, может решить большое количество других проблем, таких как: несколько таблиц обновляются отдельно, и отдельные запланированные обновления вообще не затрагиваются; несколько человек организуют несколько наборов данных и составляют отчеты вместе; размер отдельных наборов данных не может превышать лимит в 1 ГБ и т. д.
Конечно, я также хочу сказать, что независимо от того, изучаете ли вы PowerBI или другие навыки, процесс мышления зачастую гораздо важнее результатов. Особенно в эпоху быстрого развития искусственного интеллекта, позволяя ИИ выполнять за вас определенные функции, можно быстро и точно.
Недавно я также обновил свои статьи в базе знаний Yuque. Я думаю, что там также имеется большое количество корпоративных решений по развертыванию PowerBI и приложений PowerBI.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
