[Обнаружение целей] Теоретическая интерпретация YOLOv9 и анализ кода
Предисловие
История серии YOLO уже очень полная. Например, в YOLOv8 были исправлены некоторые важные стратегические изменения, такие как «Отдельная голова» или «Без якоря». Ожидается, что для создания будут использоваться только некоторые трюки «подключи и работай». небольшие изменения позже.
Дип Моу, автор фреймворка mmdetection, также высказал свое мнение по поводу «Будет ли YOLOv9» на Чжиху:
Однако yolov9 был выпущен в феврале этого года. Первая работа была написана Чиен-Яо Ваном из Academia Sinica в Тайване, Китай, и это был тот же автор, что и YOLOv4 и v7.
YOLOv9бумага:https://arxiv.org/abs/2402.13616 YOLOv9склад:https://github.com/WongKinYiu/yolov9
Изменения в v9 сильно отличаются от v8. Они не улучшены на основе v8, а доработаны на основе предыдущей работы автора v7. Поэтому, чтобы понять соответствующие теории v9, вам необходимо сделать некоторый обзор v4 и v7.
История исследования
Основная проблема YOLOv9 заключается в том, что большинство методов игнорируют тот факт, что входные данные могут иметь значительную потерю информации во время процесса прямой связи.
Автор использует следующий набор рисунков для иллюстрации этой проблемы. Ниже представлена визуализация многомерных характеристик различных моделей в пространстве глубины. Предыдущие алгоритмы вызовут потерю информации и приведут к искажению визуализации.

В этой статье автор в основном вносит два вклада:
- 1. Программируемая информация о градиенте (PGI). Надежные градиенты генерируются с помощью вспомогательных обратимых ветвей, так что глубокие функции могут сохранять достаточный объем информации.
- 2. На базе ЭЛАН спроектирован обобщенный ЭЛАН (GELAN): больше свободы в выборе блоков расчета.
PGI:Programmable Gradient Information
Программируемая градиентная информация. На первый взгляд концепцию программируемой градиентной информации (PGI) немного сложно произнести. Я прочитал много статей по интерпретации, и эта концепция ограничивается только переводом статей. Здесь я расскажу о своих. понимание.
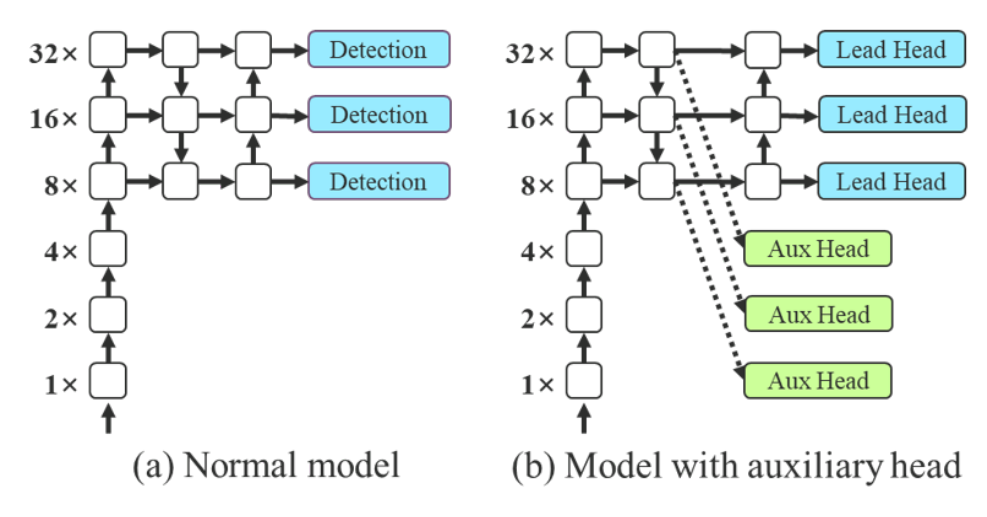
Во-первых, давайте вернемся к статье YOLOv7 [1]. Концепция вспомогательного обучения была упомянута в статье, как показано на рисунке ниже. Рисунок a представляет собой обычный процесс вывода общей модели. Рисунок a. Мелкие функции сети напрямую ведут к вспомогательной главе, и потери рассчитываются только на основе характеристик мелкой сети. Это помогает сети использовать глубокие функции для уменьшения потерь информации.
Поняв это, посмотрите на эту картинку в YOLOv9:
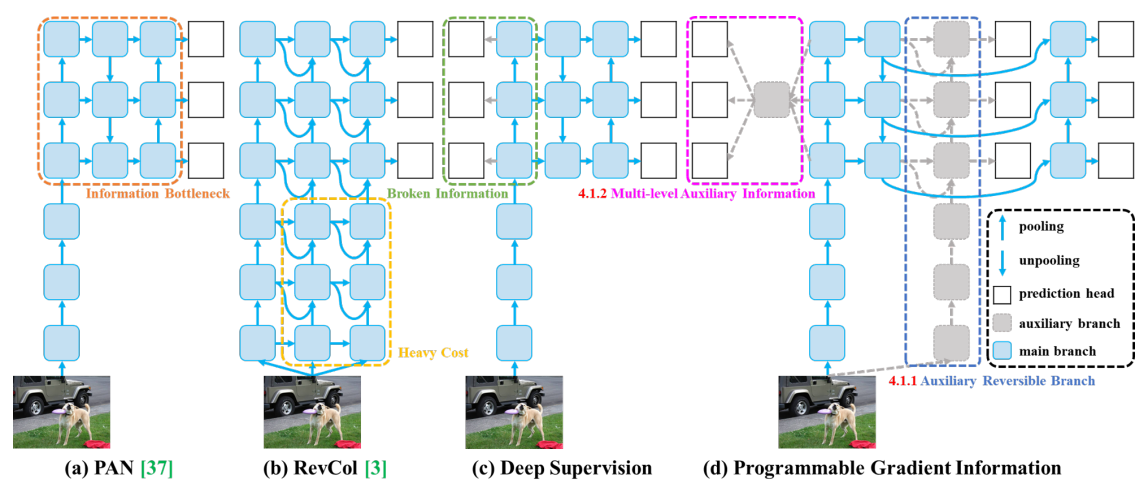
На этом рисунке четыре архитектуры:
- Рисунок а — обычный PAN, такой же, как модель Normal в v7.
- Рисунок б — RevCol.,Изменение заключается в добавлении нескольких перешейков в неглубокий слой, которые изначально влияли только на глубокие слои.,Используется для хранения информации о мелких объектах.,Однако проблема также очевидна,Накладные расходы на память слишком велики (большая стоимость)
- Рисунок c – глубокая супервизия (Deep Supervision),Идея состоит в том, чтобы скопировать головку обнаружения в неглубокий старый слой.,Это та же идея, что и на рисунке B в версии 7.
- Рисунок d — это идея pgi, предложенная yolov9. Идея довольно проста. С одной стороны, она продолжает сохранять дизайн Deep Supervision и строит головку обнаружения на мелком уровне, с другой стороны, она открывает отдельный путь. и вставляет исходное изображение во вспомогательную обратимую тренировку. Ветка), это на самом деле похоже на копирование основной ветви. Синяя часть — это исходная основная ветвь. При выполнении шейки основной ветви, с одной стороны, головка обнаружения создается непосредственно в мелком слое. , чтобы с одной стороны согласовывалось с исходной веткой. То же, идем глубже и проверяем еще раз.
Таким образом, pgi — это не конкретная сетевая структура, а вспомогательная обучающая идея. Ее можно комбинировать по различным характеристикам сети, она бесплатна, а параметры можно постоянно корректировать при обучении. По словам автора, ее можно программировать (). это искусство упаковки!)
Поскольку это вспомогательное обучение, количество параметров модели на этапе обучения станет намного больше, но это не повлияет на этап вывода. Для вывода по-прежнему используется основная ветвь, поэтому он мало влияет на скорость вывода.
GELAN: Generalized Efficient Layer Aggregation Network
Эта работа GELAN направлена не на решение проблемы недостатка информации в глубокой модели, рассматриваемой в статье, а на дополнение и оптимизацию PGI. Поскольку стратегия PGI приведет к тому, что сеть станет слишком большой, а стоимость вычислений — слишком высокой, для облегчения вычислительной нагрузки вводится GELAN.
Для интерпретации GELAN нам все равно придется вернуться к YOLOv4. В YOLOv4 автор принимает упомянутую ранее архитектурную идею CSP (Cross Stage Partial), как показано на рисунке ниже.

Рисунок а — архитектура DenseNet, Рисунок б — архитектура CSPDenseNet. Из рисунка нетрудно увидеть, что идея CSP состоит в том, чтобы разделить карту объектов сети на две части, одна часть уходит в исходную. сеть для извлечения признаков и других операций, а другая часть напрямую соединяется с выходом первой части.
YOLOv4 применяет идеи CSP к Даркнету, предложенные в версии 3, и становится CSPDarknet. Ниже приведена реализация части CSP в YOLOv5. Нетрудно увидеть, что при реальном использовании канал карты объектов делится пополам посредством двух сверток.
import torch
import torch.nn as nn
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
bcsp = BottleneckCSP(1,2)
print(bcsp)Вслед за CSP работа над ELAN строится на этой основе для дальнейшего развития архитектуры. В YOLOv7[3] архитектура ELAN также была расширена и предложен расширенный ELAN (E-ELAN), как показано на следующем рисунке:
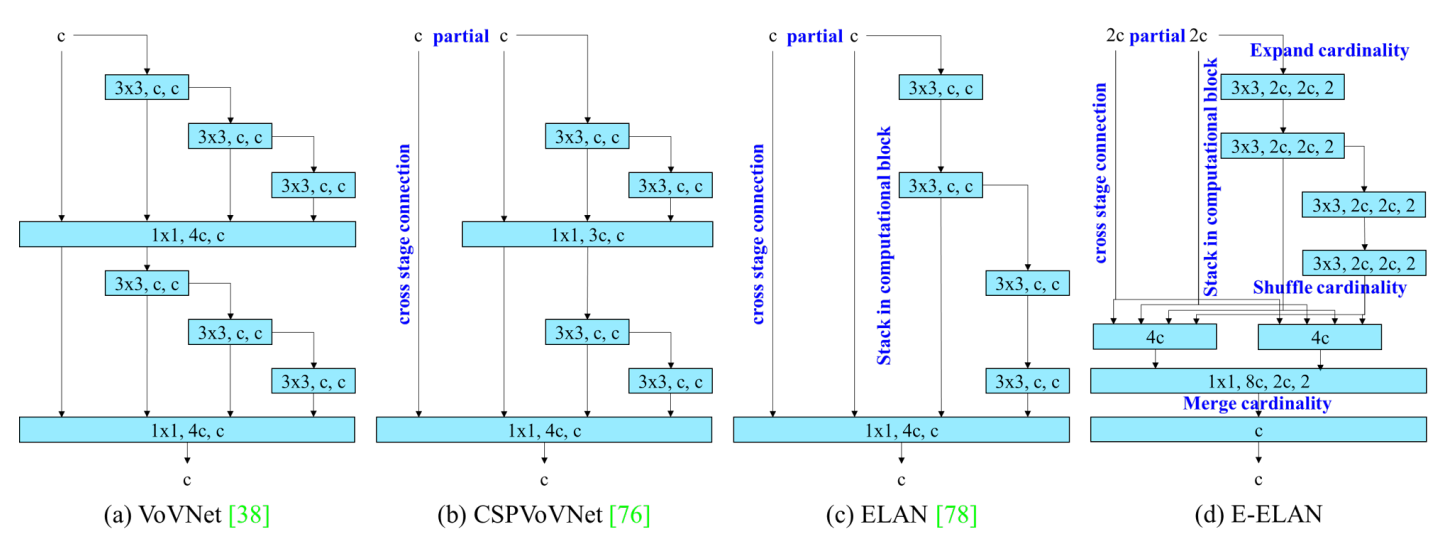
Как показано на рисунке c, ELAN характеризуется межуровневой агрегацией, то есть одновременной агрегацией мелких и глубоких функций, в основном для решения проблемы исчезновения градиента при увеличении глубины модели, а также для улучшения эффективность использования функций.
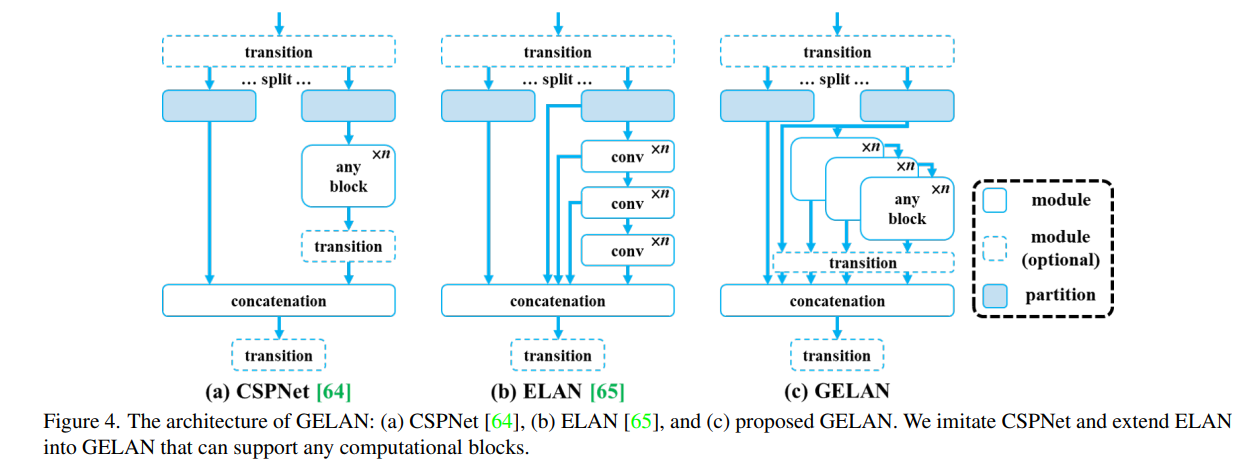
GLAN, предложенный Yolov9, не внесла особенно большие изменения в ELAN, но заменил оригинальную фиксированную серию сверточных слоев (CONS) любым блоком (любой блок). Прибрал ...
Интерпретация кода
Статью YOLOv9 фактически можно разделить на две работы: PGI и GELAN. Поэтому с точки зрения кода автор также сделал ряд разделений. Общая структура по-прежнему использует набор v5, поэтому метод обучения и структура организации данных являются общими для v5.
Этот склад содержит два набора моделей, gelan и yolov9. Yolov9 эквивалентен gelan+pgi. Судя по тестовым рендерам, приведенным автором, значение yolov9 явно выше, чем gelan. Поэтому при использовании кода yolov9 можно. полностью игнорируйте гелан.
Автор приводит здесь три поезда и три значения, а соответствующие функции следующие:
- train.py: модель поезда GELAN
- train_dual.py: Модель поезда GELAN с веткой вспомогательного обучения
- train_triple.py: Модель поезда GELAN с двумя вспомогательными ветками обучения
- Три функции val, val_dual и val_triple соответствуют трем вышеуказанным поездам.
По материалам YOLOv9,YOLOv9Модель — вспомогательное учебное подразделение GELAN+1.,Итак, обучение и проверкаv9Модель Просто используйтеtrain_dual.py、val_dual.py。
Согласно статье, YOLOv9 делится на четыре версии: от маленькой до большой: малая (yolov9-s), средняя (yolov9-m), компактная (yolov9-c) и расширенная (yolov9-e). теперь в этом репозитории есть только две последние модели с открытым исходным кодом.
Что касается train_triple, то, вероятно, это экспериментальный код автора. В статье не упоминаются экспериментальные эффекты двух вспомогательных ветвей обнаружения, поэтому не ожидается значительного улучшения эффекта.
Кроме того, на складе есть несколько экспериментальных файлов, не имеющих никакого отношения к yolov9. Это последняя работа автора: YOLOR-Based. Multi-Task Learning,Эта Работа посвящена решению множества различных задач.,Например, обнаружение целей, сегментация экземпляров, семантическая сегментация и описание изображений для продвижения друг друга.,Эта часть контента соответствуетpanoptic,Однако эта часть контента еще не созрела.,Автор не предоставил соответствующую форму организации набора данных.,Просто пропустите его при использовании.
Давайте посмотрим на некоторые детали кода, кроме структуры сети.,например,yolov9 в разделе вспомогательного обучения,Добавлен набор головок обнаружения.,Эквивалентно 6 головкам обнаружения.,Этот код соответствуетDualDDetect,
class DualDDetect(nn.Module):
# YOLO Detect head for detection models
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) // 2 # number of detection layers
self.reg_max = 16
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.inplace = inplace # use inplace ops (e.g. slice assignment)
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = make_divisible(max((ch[0] // 4, self.reg_max * 4, 16)), 4), max((ch[0], min((self.nc * 2, 128)))) # channels
c4, c5 = make_divisible(max((ch[self.nl] // 4, self.reg_max * 4, 16)), 4), max((ch[self.nl], min((self.nc * 2, 128)))) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3, g=4), nn.Conv2d(c2, 4 * self.reg_max, 1, groups=4)) for x in ch[:self.nl])
self.cv3 = nn.ModuleList(
nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch[:self.nl])
self.cv4 = nn.ModuleList(
nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3, g=4), nn.Conv2d(c4, 4 * self.reg_max, 1, groups=4)) for x in ch[self.nl:])
self.cv5 = nn.ModuleList(
nn.Sequential(Conv(x, c5, 3), Conv(c5, c5, 3), nn.Conv2d(c5, self.nc, 1)) for x in ch[self.nl:])
self.dfl = DFL(self.reg_max)
self.dfl2 = DFL(self.reg_max)
def forward(self, x):
shape = x[0].shape # BCHW
d1 = []
d2 = []
for i in range(self.nl):
d1.append(torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1))
d2.append(torch.cat((self.cv4[i](x[self.nl+i]), self.cv5[i](x[self.nl+i])), 1))
if self.training:
return [d1, d2]
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (d1.transpose(0, 1) for d1 in make_anchors(d1, self.stride, 0.5))
self.shape = shape
box, cls = torch.cat([di.view(shape[0], self.no, -1) for di in d1], 2).split((self.reg_max * 4, self.nc), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
box2, cls2 = torch.cat([di.view(shape[0], self.no, -1) for di in d2], 2).split((self.reg_max * 4, self.nc), 1)
dbox2 = dist2bbox(self.dfl2(box2), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
y = [torch.cat((dbox, cls.sigmoid()), 1), torch.cat((dbox2, cls2.sigmoid()), 1)]
return y if self.export else (y, [d1, d2])По сравнению с тем, что было до модификацииDetect,Этот новый класс наконец выводит результаты двух головок обнаружения.,Это d1 и d2,Когда позже ты терпишь убытки,Соответствует потере двух головок обнаружения:
class ComputeLoss:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.assigner2 = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.bbox_loss2 = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_labels2, target_bboxes2, target_scores2, fg_mask2 = self.assigner2(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = max(target_scores.sum(), 1)
target_bboxes2 /= stride_tensor
target_scores_sum2 = max(target_scores2.sum(), 1)
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores2.to(dtype)).sum() / target_scores_sum2 # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask2.sum():
loss0_, loss2_, iou2 = self.bbox_loss2(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes2,
target_scores2,
target_scores_sum2,
fg_mask2)
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)Из этого кода нетрудно увидеть,Потеря здесь – это потеря трёх частейbox、clsиdflПотери суммируются соответственно.,и присвоить веса различным категориям потерь,Потери от регрессии составят большую часть.
В настоящее время я запустил сеть yolov9-c. Размер модели составляет около 98 МБ, что относительно велико по сравнению с YOLOv5. После добавления вспомогательной ветви вывода понятно, что размер модели относительно велик. Однако необходимо провести некоторую оптимизацию. сделать при развертывании умозаключения, например, вырезая соответствующие весовые ветви вспомогательных рассуждений, эта часть еще не реализована.
Подвести итог
YOLOv9 продолжает работу YOLOv7 и вносит некоторые улучшения в проблему слишком больших параметров v7. Тем не менее, сеть все еще является относительно академической, а текущая трансформация и развертывание модели недостаточно зрелы. Точка входа в эту статью является относительно нишевой, и кажется, что идеи и способности автора рассказывать истории действительно заслуживают внимания. учиться у.
Ссылка
[1] WANG C Y, BOCHKOVSKIY A, LIAO H Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[J]. [2] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN[C/OL]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA. 2020. http://dx.doi.org/10.1109/cvprw50498.2020.00203. DOI:10.1109/cvprw50498.2020.00203. [3] WANG C Y, BOCHKOVSKIY A, LIAO H Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[J].



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
