«Обмен технологиями искусственного интеллекта» Углубленная интерпретация технического отчета Llama 3.1.
| Введение За последние полтора года сообщество открытого исходного кода провело множество исследований в области больших моделей и обобщило много ценного опыта. Лама Метод, использованный в техническом отчете 3.1, можно считать основным в текущем сообществе открытого исходного кода. ламе 3.1 Интерпретация технического отчета может помочь нам понять, какая технология является наиболее зрелой и передовой для общественного обучения больших моделей, что имеет большое значение при фактическом обучении модели.

Контекст и аудитория
С начала прошлого года большие модели привлекли большое внимание в академических, промышленных и инвестиционных кругах благодаря своим удивительным эффектам, и они разрабатывались почти полтора года. Год назад было сказано, что OpenAI опережает сообщество открытого исходного кода в области технологий примерно на 18 месяцев (полтора года).
В этот момент, примерно через полтора года после того, как ChatGPT (GPT-3.5) вышел из круга, Llama, лидер сообщества открытого исходного кода, выпустил свою модель версии 3.1, которая превзошла GPT-3.5 во всех списках, а в некоторые случаи Список можно сравнить с GPT-4. С точки зрения использования опыт использования Llama 3.1 пока уступает GPT-4, но стабильно превосходит GPT-3.5.
За последние полтора года сообщество открытого исходного кода провело множество исследований в области больших моделей и обобщило много ценного опыта. Лама Метод, использованный в техническом отчете 3.1, можно считать основным в текущем сообществе открытого исходного кода. ламе 3.1 Интерпретация технического отчета может помочь нам понять, какая технология является наиболее зрелой и передовой для общественного обучения больших моделей, что имеет большое значение при фактическом обучении модели.
Аудитория:
- Люди, интересующиеся большими моделями:В этой статье будут обсуждаться некоторые методологии для больших моделей.、Дайте некоторое представление об основных принципах,Заинтересованные читатели могут узнать о логике, лежащей в основе некоторых крупных моделей проживания;
- Учащиеся, которые хотят освоить область больших моделей:В этой статье систематически описываютсяLLama3.1Предварительная подготовка использовалась - После обучения этот процесс также стал стандартным процессом обучения больших моделей. Новички могут использовать его, чтобы увидеть основные требования к технологическому стеку и трудности в этой области;
- Крупные практики модельной индустрии:LLama 3.1 В техническом отчете я в основном рассказываю только о реализации технических методов, а чтобы слишком много говорить о причинах этого, при описании запишу некоторые собственные мысли, сосредоточьтесь на Почему технология устроена именно так?,Я надеюсь, что это натолкнет практикующих на некоторые мысли.,Способен уловить суть при составлении планов,Дизайнерские решения адаптированы к местным условиям.
Что уникально в LLama 3.1
Вкратце, LLama 3.1 имеет следующие уникальные особенности:
- Эффект:Значительно превосходит модели того же размера.иGPT-3.5,Можно привязать GPT-4 к некоторым задачам.,На данный момент это самая мощная модель с открытым исходным кодом;
- предварительнометод обучения Аргумент:Выбирать Использовалтри этапаизпредварительнотренироваться,Начальная предаяварочная подготовка-длинный текст предварительная подготовка-отжиг,Три этапа обеспечивают относительно недорогую реализацию мощной модели, поддерживающей сверхдлинные контексты;
- Предварительная тренировка для снятия веса:Используйте дедупликацию на уровне строк,Улучшите качество модели. Дедупликация строк — относительно новый подход.,Может значительно улучшить производительность;
- назадметод Обучение Теория: Используются стратегии обучения отказной выборки, SFT и DPO, а также разумно используются собранные подсказки и синтетические методы. данные, метки данных для обучения. Оптимизируйте синтетические процессы в итеративном процессе. данные отказываются от выборки,Чтобы модель всегда была настроена в актуальном состоянии,Улучшенные возможности модели;
- Использование данных о поведении пользователей:В процессе использования больших моделей пользователи,Генерируйте большое количество качественных подсказок,Объем данных огромен и имеет большой потенциал для повышения производительности.。LLama 3.1 Эти данные рационально используются посредством браковочной выборки и DPO для улучшения возможностей модели;
- Принцип негэнтропии:Введение отрицательной энтропии может заставить модель работать все лучше и лучше.。Используйте созданные пользователемPromptоптимизацияи Фильтрация знаний из внешнего мирасинтетические данные,Все они относятся к введению в модель отрицательной энтропии.,Это философски гарантирует, что модель движется в сторону лучшей оптимизации.
Позже технический отчет LLama 3.1 будет объяснен от начала до конца, перемежаясь объяснениями вышеупомянутых уникальных функций. Во время объяснения будут некоторые комментарии, которые будут выделены цветом фона.
Основные возможности и эффекты Ламы 3.1
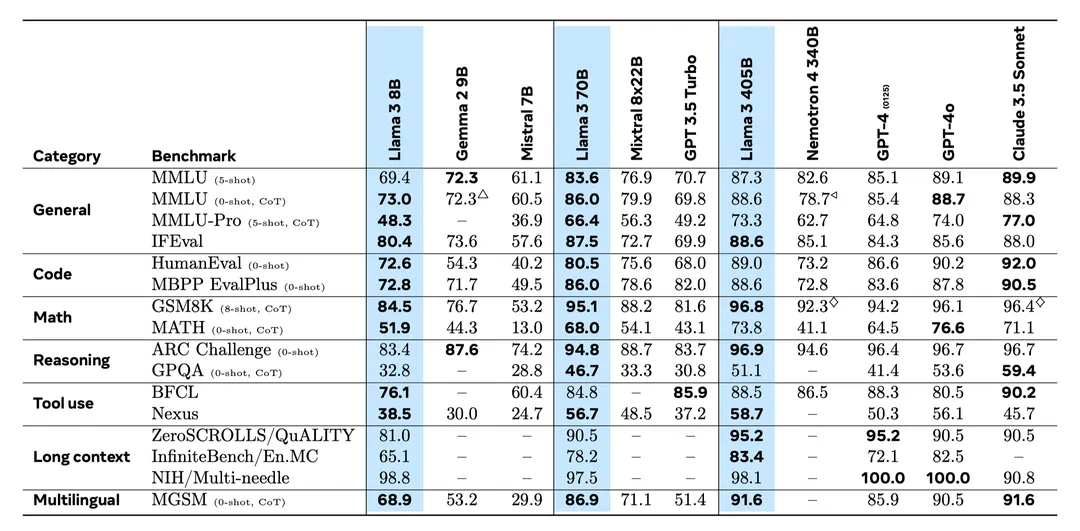
В целом Llama 3.1 имеет следующие особенности модели:
- Модели с чрезвычайно большим масштабом параметров:Размер основной модели405B,также,В то же время исходный код модели 8Bи70B также был открыт.
- Огромное количество обучающих данных:Проведенное обучение15Tмногоязычных данных,По сути, это можно рассматривать как верхний предел данных, которые сейчас можно сканировать в Интернете. В отличие,предыдущее поколениеLlama 2 составляет 1,8 Тл данных, что означает улучшение почти в 10 раз.
- Огромный объем вычислений:Использовал3.8 × 10^25 Расчетное количество флопов. Используя в качестве оценки широко используемую в Китае видеокарту A100, вычислительная мощность одной карты составляет 156 × 10^12 Флоп/с, даже если графический процессор полностью загружен и потери связи не учитываются, это все равно необходимо 2.8 × 10^6 карточных дней. Если это кластер Ванка, это займет 280 дней. Фактически, потери, вызванные обучением и коммуникацией, могут занять около 30-50% вычислительной мощности хорошо оптимизированной системы, и это займет больше времени. Фактически, Мета использовала видеокарту H100 с разрешением 16 КБ и тренировалась 54 дня.
- Разумное управление сложностью:Модельное обучение,Использование относительно зрелой и стабильной технологии обучения.,Включая плотную архитектуру, зрелую технологию выравнивания и т. д.
- Поддержка очень длинной длины контекста:поддерживать128kДлина контекста,Может поддерживать большинство реальных задач.
- Улучшенная поддержка нескольких языков:Например английский、Французский、тайский、китайский(не указано в отчете)ждать。
- Множество возможностей поддерживают больше последующих приложений:В дополнение к обычным задачам на естественном языке,Он также поддерживает рассуждение, программирование, использование инструментов и другие способности.,Удовлетворяет потребностям последующих приложений искусственного интеллекта.
В целом производительность модели значительно опережает модели с открытым исходным кодом того же уровня по сравнению с GPT-4, по некоторым показателям задачи ее можно сравнять с GPT-3.5, она уверенно опережает;
предтренировочные методы
Из-за высокой стоимости предварительного обучения отказоустойчивости практически нет, и требуется как можно скорее добиться хороших результатов. В стеке технологий больших моделей предварительное обучение является связующим звеном с самым высоким порогом исследования и наибольшей потребностью в инженерном опыте. Качество предобученной модели напрямую определяет верхний предел постобучения (согласно техническому отчету Llama, соответствующему предыдущему раскладу).
Предварительная подготовка в основном решает следующие проблемы:
- Предварительное обучение требует огромного количества данных и высокого качества данных. Как удовлетворить требования к данным?Объем данных требует сбора как можно большего количества данных.,На данный момент мы почти закончили сканирование данных в Интернете для предварительной подготовки.,Сканирование, хранение и обработка такого большого количества данных представляет собой сложную задачу.,К возможностям инженеров по обработке больших данных предъявляются высокие требования.,К счастью, текущая инфраструктура обработки больших данных является относительно зрелой (например, базы данных, Spark, Hadoop и другие технологии).,Способность обрабатывать данные такого масштаба. Учитывая, что текущий объем данных в основном достиг вершины,Качественная обработка данных,важнее,Это также место, где проверяются навыки алгоритмического персонала.,Это требует глубокого понимания данных или достаточного опыта, чтобы хорошо с ними обращаться.
- Стоимость предварительного обучения чрезвычайно высока, а возможностей для проб и ошибок мало или вообще нет. Как установить разумные параметры обучения, чтобы обеспечить нормальное и эффективное обучение?Вопросы, затронутые здесь, включают в себя то, как спроектировать/Выберите структуру модели、Как установить гиперпараметры для обучения、如何配置тренироваться量ждатьждать。фактически,Плотная структура модели в настоящее время является относительно зрелой.,Трудно иметь серьезные инновации,гиперпараметрыи Конфигурация объема тренировок должна основываться наscaling закон и другие экспериментальные правила для достижения наилучшего тренировочного эффекта.
- Модель с сотнями параметров B слишком велика по сравнению с текущей памятью графического процессора. Как построить эффективный обучающий кластер и настроить метод распараллеливания, чтобы обеспечить обучаемость модели и эффективность обучения?Это инженерная проблема,Крайне сложно обучать модели выше 100B.,Вам необходимо использовать расширенную Стратегию распараллеливания, чтобы гарантировать возможность обучения модели. дальше,Из-за огромных затрат на предварительное обучение больших моделей и огромных накладных расходов на связь, связанных с обучением на нескольких машинах.,Отличная инфраструктура имеет решающее значение,Хорошая система и плохая система,С точки зрения эффективности обучения,есть огромная разница。хорошая система,Существует необходимость в разумной Стратегии распараллеливания на уровне программного обеспечения.,Существует разумная топологическая структура с точки зрения аппаратного обеспечения.,Аппаратное и программное обеспечение взаимодействуют друг с другом,Максимальное использование ресурсов.
- Вычислительных мощностей для обучения больших моделей недостаточно. Как разработать разумную стратегию обучения, чтобы модель работала лучше в условиях ограниченных вычислительных ресурсов?:дольше Длина контекста,много преимуществ,Расширьте сферу применения модели. На предтренировочном этапе,Интеграция других способностей также будет рассмотрена.,Например, мультимодальность и т. д. Однако,приобретение этих способностей,Увеличит сумму расчета,во время тренировки,Разумная стратегия обучения может обеспечить более высокие результаты с меньшими ресурсами.,Лучший доступ к этим способностям.
В ответ на вышеуказанные проблемы Llama 3.1 предлагает разумные решения, которые будут подробно описаны ниже.
· Данные
Проблема с данными — это объем и качество данных.,Объем данных относительно инженерный,Для создания платформы обработки данных нужны отличные инженеры,Сканирование данных、собиратьждать。Нижеследующее в основном говорит о Качественная обработка данных,На данный момент,Качественная обработка данных в основном состоит из трех частей: фильтрация безопасности – фильтрация качества – дедупликация.,Фильтрация безопасности отфильтровывает личную и небезопасную информацию.,Запретить модели выводить такую информацию при применении качественной фильтрации – отфильтровывать информацию низкого качества;,Данные более высокого качества могут обучать модели более высокого качества. Дедупликация заключается в удалении повторяющейся информации в данных;,нормальное распределение данных,Имеет определенный длинный хвост,Данные с длинным хвостом приведут к смещению модели в сторону популярных распределений данных.,внести предвзятость,Разумная дедупликация полезна как для общих возможностей модели, так и для производительности данных с длинным хвостом.
Качественная обработка данных
Личная информация и фильтрация безопасности:Удаление большого количества личной информации(Например имя、Телефон、электронная почта и т. д.) данные、небезопасный контент、контент для взрослыхждать。Эта часть может быть достигнута с помощью стратегии правил,Это достигается за счет регулярного сопоставления.
Извлечение и очистка текстовой информации:Данные о спуске,Все в формате html,Текстовая информация неявно присутствует в html.,Для извлечения текстовой информации,Необходимо использовать парсер прибытияhtml,Хороший парсер может сделать текст качественнее,Llama Версия 3.1 оптимизирует парсер и обеспечивает лучшее качество данных. При этом сохраняется исходный формат кода, математических формул и т. д., а значение уценки удаляется для дальнейшего улучшения общего качества.
Чтобы удалить дубликаты:Дублирующаяся информация,Снизит эффективность обучения,И это недружелюбно к информации с длинным хвостом.,поэтому дедупликация стала ключевым процессом обработки данных. Лама 3.1 использует три метода обработки данных:
- Уровень веб-страницы. Информация веб-страницы будет обновлена и опубликована, а старая версия также будет сохранена. Поскольку текстовая информация разных версий веб-страниц во многом пересекается, будет сохранена только последняя версия.
- Текстовый уровень. Информация в Интернете будет «учиться» друг у друга, поэтому существует множество дубликатов. Эту часть можно дедуплицировать с помощью хеш-значений, что представляет собой алгоритм запроса сходства строк.
- уровень строки。Разделите текст на более мелкие блоки, а затем выполните алгоритм дедупликации. Эта степень детализации более тонкая. В техническом отчете Llama3.1 говорится, что этот метод может привести к большим улучшениям. Эта стратегия может удалить некоторые предложения в середине, чтобы сделать контекст менее понятным, но это имеет смысл, если вы тщательно об этом думаете. Этап предварительного обучения по-прежнему представляет собой процесс изучения знаний и не требует согласования с приложением. В определенной степени степень детализации меньше (например, предложения) также содержат полную семантику. Анализ данных с меньшей степенью детализации будет более точным.
Фильтрация качества на основе правил:также известный как эвристическая фильтрация качества,В основном относится к поиску некоторых особенностей в тексте.,Способность выявлять данные низкого качества,Отфильтруйте эти данные. Например,В тексте много искаженных символов, специальных символов, необоснованная длина текста и т.п.,Все это можно использовать в качестве функций для качественной фильтрации. Правила использования ламы в техническом отчете 3.1:
- Удалите дублирующийся контент из документов, например журналы и т. д. В частности, для его реализации используется алгоритм N-gram.
- Используйте грязные ключевые слова для фильтрации. В основном для фильтрации контента для взрослых.
- Отфильтруйте информацию с необоснованным распределением слов. Отфильтруйте текст, в котором слова-выбросы явно не соответствуют нормальному распределению.
Фильтрация качества на основе модели:Дайте оценку качеству документа,Обучите модель для прогнозирования качества текста,Фильтр на основе обученной модели. Распространенными методобучения являются: Считать, что текст Википедии более качественный.,Другие более низкого качества.,Модель обучения,Преимущество этого заключается в том, что нет необходимости в ручном аннотации, используется метод ручного аннотирования/аннотации модели;,Оцените качество документа,Модель обучения。
Во время вышеуказанной операции,Извлечение и очистка текста, Удалить дубликаты、правила Качественная фильтрация основанных, управляемых Сложность качественной фильтрации модели равна O(n),Оба могут обрабатывать огромные объемы данных. Первые четыре могут быть реализованы на процессоре.,Последний предполагает модель передвижения.,Необходимо реализовать с помощью графического процессора,Общая стоимость будет выше; дедупликация предполагает использование алгоритма хеширования.,По сравнению с работой нескольких других процессоров,Вычислительные затраты выше. Вообще говоря,Мы можем начать с менее затратного в вычислительном отношении подхода.,Фильтруйте данные по низкой цене,Затем используйте дорогостоящие операции,Чтобы снизить общую потребность в вычислительной мощности,Выполняйте быстрее. Рассмотрите возможность прибытия вычислительных затрат на вышеуказанные модули.,Данные могут обрабатываться в следующем порядке:Извлечение текстовой информациииубирать->Качественная фильтрация по правилам, основанным->Удалить дубликаты->управляемый Качественная фильтрация модели обеспечивает более высокую эффективность обработки данных.
Выборка и смешивание в области данных
На самом деле распределение данных по доменам неравномерно:
- С одной стороны, люди, пользующиеся Интернетом, будут создавать больше контента, который будет легко распространять, поэтому при сканировании данных перед обучением возникает проблема дисбаланса доменов. Например, искусство и развлечения имеют более высокую долю в данных.
- С другой стороны, существуют большие различия в объеме собираемых данных по общему тексту, коду, математическим рассуждениям и многоязычным данным.
Решение проблемы дисбаланса в регионах,Необходимо разработать разумный верхний и нижний коэффициент выборки.,Лайдаприезжатьлучший Эффект。Поскольку невозможно проводить эксперименты по коэффициентам смешивания данных на больших моделях, эффективной стратегией является проведение соответствующих экспериментов на небольших наборах данных, а затем непосредственное применение их к большим наборам данных. Это основано на базовом предположении: оптимальное соотношение смешивания данных больших и малых моделей одинаково, что также является разумным предположением и прагматичным подходом. Но могут возникнуть и некоторые проблемы. Одна из возможных ситуаций заключается в том, что для разных моделей пропорция смешивания данных будет разной, и возникают проблемы, аналогичные масштабированию. Например, регулярность закона: более крупные модели обладают более сильными возможностями обучения и требуют более сложных данных. В ответ на эту гипотезу возможным подходом является проведение экспериментов на небольших моделях разных размеров, чтобы увидеть, можно ли суммировать правила в разных масштабах. Если да, то их можно обобщить на большие модели.
Чтобы определить наилучшие соотношения отбора проб и смешивания, Llama 3.1 провел больше экспериментов на небольших моделях и, наконец, дал некоторые рекомендуемые значения. Лама Рекомендуемое соотношение, указанное в 3.1, составляет: 50% общих данных на английском языке.、25% Математика и данные рассуждения、17%код данных、8%многоязычныйданные。Следует отметить, что,Это соотношение и оценка связаны с,Для предварительной подготовки по китайскому языку,Оптимальное соотношение будет варьироваться,Нужно повторить эксперимент.
· Модель
То же, что и предыдущая версия LLama.,3.1 по-прежнему использует плотную модель,не так много изменений。Структура МО здесь не используется. Багуа означает, что МО команды LLama не прошел хорошую подготовку. Если Багуа верен, это отражает то, что стабильность обучения МО хуже, и любое обучение имеет очень высокий порог. , что лучше, чем у команды Ламы раньше. Без накопления МО тренировка не будет хорошей. Если слухи ложны, нужно задуматься, почему Ллама не выбрал архитектуру MoE. Они собрали группу самых умных людей в мире. Должен ли быть разумным выбор технологии? Имеет ли MoE заявленные преимущества по сравнению с существующей. Плотная модель, есть ли упущенные из виду недостатки, заслуживает дальнейшего размышления и экспериментальной проверки.
В частности, некоторые небольшие проекты LLama 3.1 включают в себя:
- Восемь заголовков KV используются в групповом запросе (GQA). GQA в настоящее время является широко используемым механизмом внимания. По сравнению с многоголовым вниманием, GQA позволяет одному KV соответствовать нескольким запросам, уменьшая количество KV и, таким образом, уменьшая потребление памяти во время вывода;
- Используйте внимание механизм маски,Избегайте агрегирования внимания между различными данными. Этот дизайн не оказывает большого влияния на предварительное обучение (длина текста 8 КБ).,Это оказывает большее влияние при обучении длинному тексту.。Этот экспериментальный результат можно рассматривать как вывод разногласий и предположений некоторых предыдущих практиков.
- Используйте размер словаря 128 КБ. Хотя больший словарь потребляет больше видеопамяти, он также обеспечивает лучшую степень сжатия символов и лучший эффект модели с лучшим выигрышем при разрешении 128 КБ.
- Базовая частота позиционного кодирования RoPE установлена на уровне 500 000, что в основном предназначено для расширения до длинного текста.
Закон масштабирования определяет параметры обучения
Закон масштабирования — это эмпирический закон, обобщенный на основе большого количества экспериментов. В прошлом он определял итеративное направление больших моделей. В основном он имеет три характеристики и применения:
- Производительность модели будет улучшаться по мере увеличения размера модели, объема данных и объема вычислений. Это послужило основой жестокой эстетики «великая держава творит чудеса», разработанной крупными моделями в прошлом.
- Количественно говоря, потеря модели будет демонстрировать степенное уменьшение с увеличением масштаба модели, объема данных и объема вычислений. Кроме того, учитывая объем вычислений и данных, можно рассчитать размер модели (прямо пропорциональный объему расчетов и обратно пропорциональный объему данных). Следовательно, при определенном объеме расчетов возможен разумный объем данных и. необходимо определить размер модели. Благодаря предыдущему степенному закону эксперименты можно проводить на мелкомасштабных данных и распространять на крупномасштабные данные, а также можно получить разумные настройки масштаба модели и объема данных для достижения оптимальной производительности при том же объеме вычислений. Эта практика называется вычислительно оптимальной политикой.
- Поскольку обучение нужно провести только один раз,Рассуждения нужно проводить бесчисленное количество раз.,в долгосрочной перспективе,Рассуждения включают в себя предельные затраты на проживание.,Имеет более высокую стоимость. Меньшие модели дешевле сделать вывод,поэтому,Существуют также подходы к использованию моделей меньшего размера.,Выделить Вычислительные ресурсы к объему данных по прибытию малых моделей,Провести обучение. Этот подход становится лучшей стратегией рассуждения.
Фактически, гиперпараметры обучения модели (в основном настройки скорости обучения и размера пакета) также связаны с законом масштабирования. В этой части вы можете обратиться к документу DeepSeek LLM «Масштабирование языковых моделей с открытым исходным кодом с долгосрочностью», в котором показана взаимосвязь между гиперпараметрами и законом масштабирования, а также даны предложения по настройке гиперпараметров, что имеет важное значение для предварительного обучения.
В техническом отчете Llama 3.1 для модели 405B был принят метод вычислительной оптимизации. Благодаря большому количеству мелкомасштабных экспериментов подгонка кривой была расширена до крупного масштаба модели и были получены оптимальная модель и масштаб данных. В частности, объем вычислений составляет от 6 × 10^{18} FLOP до 10^{22} FLOP, а размер модели — от 40M до 16B. Модели обучаются отдельно и рассчитываются потери. Каждый объем вычислений может иметь оптимальную комбинацию размера модели и обучающих данных, на основе которой может быть построена кривая, а затем можно получить оптимальный размер модели и размер данных при полном объеме вычислительных ресурсов. На этот раз для размера кластера Llama за подходящее время обучения он может обеспечить объем вычислений 3,8 × 10 ^ 25 флопов. Согласно ранее подобранной кривой, оптимальный размер модели и объем данных составляют 402B и 16,55T. Фактически используются данные 405B и 15T.
инфраструктура обучения
Основы аппаратного обеспечения
Эта часть не имеет ничего общего с алгоритмом. В этой статье не планируется вдаваться в подробности. Заинтересованные читатели могут обратиться к оригинальному техническому отчету Llama 3.1. Будь то команда (с таким количеством видеокарт) или инженеры (которые имеют глубокое понимание аппаратного обеспечения и алгоритмов), порог создания этой технологии чрезвычайно высок и не подходит для большинства команд и большинства людей. поймите, вот и все.
- Вычислительные ресурсы:Выбирать ИспользовалпередовойизH100видеокарта,В кластере установлено 16 тыс. видеокарт.,80GB Пропускная способность HBM3. В одной машине установлено восемь карт, а графический процессор машины подключен через NVLink.
- хранилище:иметь240PBизSSDхранилище,Пропускная способность 2 ТБ/с,Пиковая пропускная способность 7 ТБ/с. Причина, по которой необходима такая большая база данных,Это потому, что во время тренировки,Необходимо сохранять состояния, связанные с моделью (параметры модели, градиенты, импульс и т. д.) в качестве контрольных точек.,Чтобы предотвратить расходы, вызванные прерыванием обучения или нестабильностью обучения.,Эти состояния потребляют много памяти.
- сеть:между несколькими машинамииз Интерес к общениюиспользоватьRDMAтехнология,То есть прямой доступ к удаленной памяти,Уменьшите промежуточную обработку процессора,Повышайте эффективность общения. Этот метод очень часто используется в крупномасштабных тренировках.,是多机тренироваться大Модельиз Стандартная конфигурация。также,Llama 3.1 также нацелена на реализацию распараллеливания моделей.,Разработана разумная топология,Повышенная эффективность обучения.
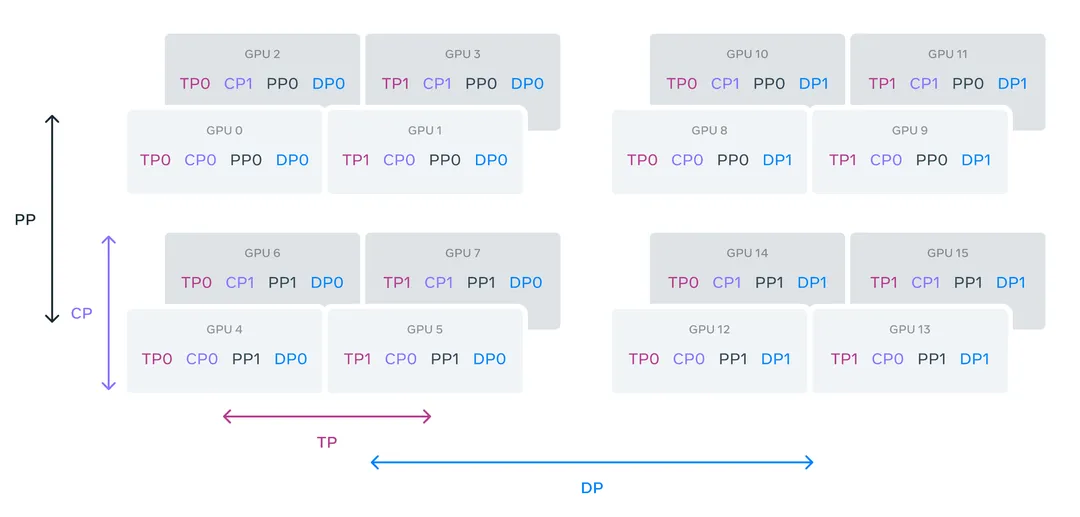
Стратегия распараллеливания
существовать Модель обученияизкогда,использоватьприезжать Понятно4DСтратегия распараллеливания,комбинация Понятно Тензорпараллельный(TP)、Параллелизм трубопроводов (ПП)、Контекстуальный параллелизм (CP)、данныепараллельный(DP)из Стратегия。4D-параллелизм в настоящее время также является стандартной конфигурацией для предварительного обучения крупномасштабных моделей. Разумная стратегия 4D-параллелизма может максимально эффективно использовать вычислительные ресурсы графического процессора. Например, TP предъявляет более высокие требования к связи, чем PP, поэтому его лучше использовать на видеокарте внутри одной машины, чтобы максимизировать преимущества, предоставляемые NVLink.
После реальных испытаний LLama 3.1из Стратегия распараллеливания,Способен достичь 40% пиковой нагрузки на графический процессор,Такого эффекта можно достичь на кластере 16 КБ.,Очень примечательно.
метод обучения
В настоящее время предварительная подготовка в основном разделена на две части:
- Начальная предварительная подготовка:то есть начать с нуля Модель обучения,На этом этапе используется относительно короткий текст.,Используйте большие объемы данных для обучения,Цель состоит в том, чтобы научить модельным знаниям;
- Предварительное обучение с длительным контекстом:делатьиспользоватьдлинныйиз Текст содержит относительно небольшой объемиз继续тренироваться,Цель — дать модели возможность обрабатывать длинный текст.
Он разделен на два этапа, в основном для повышения эффективности обучения. Вычислительная сложность структуры Transformer увеличивается с увеличением квадрата длины модели. Использование длинного текстового обучения с самого начала требует большего внимания. уделяется эффективности и используется обучение коротким текстом. На втором этапе больше внимания уделяется эффекту длинного текста и обучение проводится с помощью длинного текста. Этот параметр теперь стал стандартной конфигурацией для предварительного обучения больших моделей.
Кроме того, в LLama 3.1 представлен третий этап предварительной подготовки:
3. Обучение отжигу:делатьиспользоватьвысокое качествоизданные,с маленькимизскорость обучения Модель обучения,Это позволяет модели лучше работать на этапе постобработки.
Ниже приведены некоторые конкретные конфигурации:
Начальная предварительная подготовка
скорость обучения:существовать405Bиз Модельначальство,Выбирать Использовал 8 × 10^{−5} Пиковая скорость обучения, разминка 8000 шагов, косинусное затухание скорости обучения, после 1 200 000 шагов обучения снижается до 8 × 10^{−7} 。
Batch size:начальный этап,делатьиспользоватьменьшеизbatch размер, затем увеличьте партию размер. В частности, на первом этапе используется длина последовательности 4k, 4M. партия жетонов размер, обученный 252М токены на втором этапе используйте длину последовательности 8k, 8M; пакет токенов размер, тренированный 2,87Т токен на третьем этапе используется длина последовательности 8k, 16M; пакет токенов размер, остальные данные для обучения. Эта стратегия предварительного обучения может обучать модель более стабильно.
смешивание данных:
LLama 3.1 использует несколько приемов: - Увеличить долю данных на неанглоязычных языках и улучшить многоязычные возможности модели; - Повышение дискретизации математических данных для улучшения способностей рассуждения; - На заключительном этапе добавьте больше обновляемых во времени данных, чтобы повысить эффективность модели; - Понижение качества данных более низкого качества.
Предварительное обучение с длительным контекстом
Когда Llama 3.1 увеличивает длину, она принимает прогрессивный план: за 6 этапов контекст постепенно расширяется с 8 КБ до 128 КБ. Каждый раз, когда вы расширяете контекст, вы должны убедиться в двух моментах:
- Эффекты оценки краткого контекста не изменились;
- Модели идеально подходят для решения экспериментов «иголка в стоге сена».
На этом этапе обучения было использовано 800B токенов.
Обучение отжигу
На заключительном этапе обучения прошли обучение 40B. tokens,скорость обучение постепенно затухает приезжать0, сохраняя длину контекста 128k. Используйте низкую скорость для этой части обучения,и выбирать качественные данные для обучения,Убедитесь, что модель находится в лучшем состоянии с местными корректировками. После завершения обучения,Усредните все контрольные точки модели на этапе отжига,как окончательный результатизпредварительно Модель обучения。Этот вид операцииизрациональность:Стадия отжига, скорость обучения Низкий,Локальная корректировка модели,поэтомусредний инструментиметьрациональность,И эксперименты доказали, что Эффект лучше.
послетренировочные техники
Пост-тренинг — это часто упоминавшаяся ранее технология выравнивания, включая SFT, DPO и тому подобное. В дополнение к аннотированным вручную данным, LLama 3.1 использует данные, сгенерированные с низкой стоимостью в больших масштабах, и их статус в алгоритме обучения даже превышает статус аннотированных данных. Это указывает на то, что модель обучения синтетических данных постепенно созрела и станет более зрелой. и что еще более важно, я расскажу о лежащей в основе этого логике позже.
В существующем общепринятом познании больших моделей предварительное обучение решает проблему знания модели, что может определить верхний предел модели. Последующее обучение решает проблему выравнивания модели, что может сделать возможности модели приобретенными в ходе предварительного обучения; лучше играй хорошо. Эффект постобучения напрямую определяет фактический эффект модели и потребляет меньше ресурсов. Большинство команд при обучении моделей на самом деле выполняют согласование на основе предварительно обученных моделей. Поэтому практикам следует сосредоточиться на этой части контента, включая идеи обучения, методы синтеза данных и т. д.
· Модель/Алгоритм
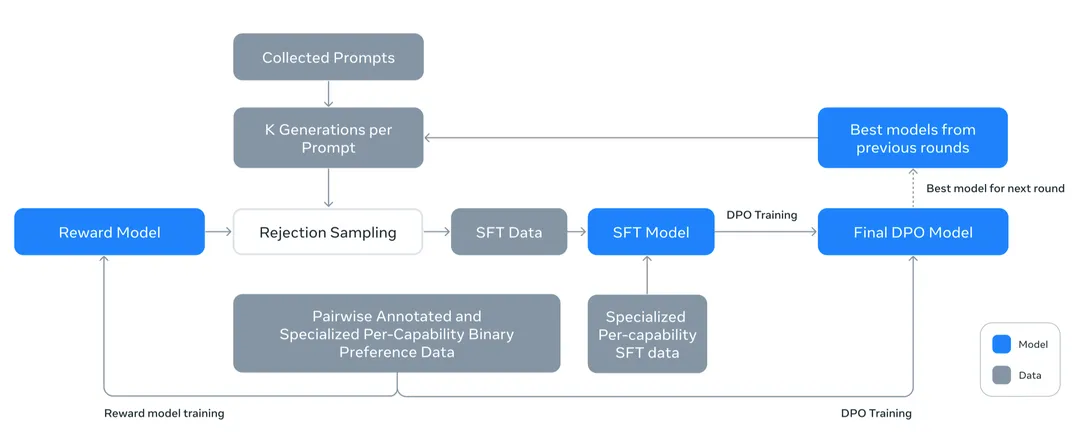
Общий процесс после обучения показан на рисунке:
- Первое использование в паре Preference DataОбучение Награда Model,Reward Роль модели заключается в оценке качества выборки;
- Тогда используйте награду Модель выполняет отбраковочную выборку (Rejection Выборка), то есть из Собранных Запрашивает выборку нескольких сгенерированных результатов K, а в качестве данных используются данные с более высоким качеством выборки. SFT, затем и помечено SFTсмешивание данных, обучить модель SFT;
- После обучения модели SFT обучается модель DPO.
В процессе выборки отклонений генерируются несколько данных с использованием модели DPO. Модель DPO предоставляет услуги вывода в качестве окончательной модели.
Вышеописанный процесс включает в себяприезжатьгенерироватьданные Модель обучения,Лучшая модель генерирует более качественные данные и упрощает обучение хорошей модели.,поэтому Вышеописанный процесс обучения,Будет повторяться 6 раз,существовать Итерироватьизв процессеоптимизация Модель、тем самым оптимизируя генерируемые данные、и продвигатьгенерироватьданныетренироваться得приезжать Модельиз Эффект。также,Поскольку это предполагает синтез данных о Выборх необходимо сделать модель различной, чтобы обеспечить различие генерируемых данных. Поэтому в каждом раунде для обучения нескольких моделей RM, SFT и DPO будут использоваться разные гиперпараметры. параметры и модели RM, SFT и DPO, прошедшие обучение на данных, усредняются в качестве окончательной модели.
Среди приведенных выше алгоритмов обучения по сравнению с данными SFT,Данные о предпочтениях занимает более важную часть, включая обучение модели RM для отбраковочной выборки и обучение модели DPO. Лама 3.1из Данные о «Выборх» — это подсказка, которая собирает информацию о прибытии и генерирует несколько результатов ответа с помощью модели, при этом ответы помечаются вручную и ранжируются по качеству. Выбор технологии здесь имеет множество значений:
- Сбор пользовательских подсказок недорог и масштабен — их легко собрать из журналов поставщиков услуг, предоставляющих приложения LLM, пользовательские подсказки имеют высокое качество, а поскольку подсказки пишутся людьми, их можно собирать, даже если плохая модель предоставляет услуги по подсказкам высокого качества. Успех глубокого обучения теперь определяется данными. Во многих областях, таких как поиск и продвижение, большие модели и т. д., низкоуровневая логика может получать высококачественные данные в больших количествах с низкими затратами, и, скорее всего, будет использоваться модель обучения. Чтобы добиться успеха — ищите данные о поведении пользователей в рекламных акциях, а данные, созданные людьми, просканированные из Интернета, в больших моделях. Большие модели будут играть все более важную роль во взаимодействии между людьми и миром в будущем. Ожидается, что в будущем будет дешево собираться больше подсказок, генерируемых пользователями, что также будет генерировать большие объемы высококачественных данных. использование имеет большой потенциал для оптимизации моделей;
- При использовании Prompt стоимость генерации ответов пользователей выше, но стоимость создания нескольких результатов с помощью модели ниже, что соответствует потребности в крупномасштабной генерации данных, если отсортированные данные можно эффективно использовать. чтобы оптимизировать модель, у нее есть потенциал для оптимизации и получения лучших моделей (DPO и PPO — это некоторые конкретные решения);
- Подсказки для пользователя и ручная сортировка аннотаций можно рассматривать как внешнюю энергию во всем процессе развития системы, обеспечивая лучшее направление для оптимизации модели. Если рассматривать это с точки зрения энтропии, то энтропия закрытой системы будет становиться все больше и больше. Поэтому разрешение самой модели генерировать подсказки и данные аннотаций определенно будет вредным в долгосрочной перспективе. Однако вливание внешней энергии может ослабить систему. энтропия. В принципе, обеспечьте возможность лучшей оптимизации модели. DPO и отбраковочная выборка — это разумные алгоритмы, которые могут использовать внешнюю энергию для уменьшения энтропии.
Reward Modeling
Функция модели вознаграждения заключается в оценке качества контента, генерируемого моделью. Возможные варианты использования включают: в обучении с подкреплением в качестве моделирования окружающей среды для обеспечения модели обучения с обратной связью (PPO) при выборке с отклонением в качестве обучения данным выбора дискриминанта; модель в оценке модели, как стандарт оценки качества;
Поскольку обучение DPO легче объединить, LLama 3.1 Использует технологию обучения DPO для обучения. Награда. Основная функция модели — вынести суждение об отказной выборке и выбрать данные для обучения модели SFT.
Обучение Награда Конкретный метод модели: для подсказки имеется n ответов, качество ответов ранжируется по высокому и низкому уровню. Рейтинг используется в качестве метки для обучения модели. На практике, используя парные данные (выбранные, отклонено), эти данные синтезируются моделью в два данных ответа для ручной маркировки и сортировки. Затем я выберу его для модели или отредактирую, чтобы получить лучший ответ, и, наконец, получу edited > chosen > отклонено, обучите модель. Традиционная награда При обучении модели оценка будет рассчитана на основе запроса и каждого ответа. Имеется n строк данных, соответственно будет рассчитано n оценок, и будет разработана модель обучения с потерями. Лама Разница в версии 3.1 заключается в том, что подсказки и множественные ответы шифруются и объединяются вместе, а оценки всех данных рассчитываются одновременно для разработки модели обучения с потерями. Этот метод обучения более эффективен, LLama 3.1 провел эксперимент по удалению, это решение не приведет к потере производительности.
SFT
Данные SFT включают помощь Reward Модель генерирует данные, отклоняя выборку, аннотированные вручную данные и высококачественные синтетические данные на основе искусственных подсказок. Во время обучения используйте подсказку maskиз Стратегия,Посчитайте только потерю ответа,Потеря подсказки не рассчитывается,Основываясь на результатах многочисленных текущих статей и моих собственных экспериментальных результатах, подскажите маска по сравнению с отсутствием маскировки Есть небольшое преимущество.действительныйиспользовать1 * 10^{-5} Скорость обучения составляет 8,5–9 тысяч шагов. Эта экспериментальная установка относительно стабильна и может хорошо работать при различных сочетаниях данных.
DPO
Существует два типа ДПО:
- Offline DPO,Данные обучения статичны.,использовать Партия хорошо маркированаиз Данные о предпочтениях Модель обучения;
- Online DPO,Данные обучения являются динамическими,После обучения модели DPO в течение определенного периода времени,Будет использовать последнюю модель для генерации данных,Переименовать(может бытьиспользоватьReward модель или расширенную аннотацию модели с закрытым исходным кодом), используйте последние аннотированные данные для обучения модели.
Online Преимущество DPO заключается в том, что данные генерируются с использованием последней модели, поэтому полученные метки могут соответствовать текущей ситуации обучения модели (аналогично активной обучение), что делает обучение выборок более эффективным.
Согласно описанию Llama 3.1, принята стратегия онлайн-обучения DPO. После каждой итерации последняя модель используется для генерации данных, их маркировки и последующего обучения. Во время обучения использовалась скорость обучения 1 * 10^{-5}, гиперпараметр β был установлен равным 0,1, а в алгоритм DPO были внесены следующие улучшения:
- Маскируйте символы специального формата, такие как символы начала и остановки, чтобы сделать обучение более стабильным. Llama 3.1 обнаружила, что использование этих символов приведет к повторению или внезапной генерации стоп-символов. Причина анализа заключается в том, что DPO оптимизирует разницу между хорошими и плохими выборками. Оба данных содержат стоп-символы, поэтому потеря специальных символов будет недействительной. .
- Используя выбранные выборки, сделайте потерю NLL такой же, как SFT, и коэффициент равен 0,2. Этот метод обычно используется в больших моделях DPO/PPO, в основном для стабильности обучения и для того, чтобы позволить модели сохранять способность генерировать нормальный контент.
· Данные
Данные имеют решающее значение для оптимизации модели. У данных есть две стороны,Сбор данных, фильтрация качества данных. Во-первых, как получить Данные о предпочтениях,Данные о предпочтенияхиспользовать ПриходитьReward модель и модель DPO; затем, как получить данные SFT и как данные SFT используются для обучения модели SFT, наконец, мы поговорим о методах обработки данных и фильтрации качества данных;
Данные о предпочтениях
В Ламе В отчете 3.1 данные о предпочтениях создаются с использованием модели, а затем аннотируются вручную. Используйте разные гиперпараметры и данные для обучения разных моделей, чтобы обеспечить разнообразие модели и данных, генерируемых ею. Входными данными всего процесса является сбор подсказок «приехать». Каждый раз выбираются две модели для генерации ответов на подсказки «приехать», а затем вручную отмечаются плюсы и минусы. Помимо обозначения порядка приоритета (выбранного > отклонено), также будет указан размер преимущества, разделенный на четыре уровня: значительно лучше, лучше, чуть лучше и почти то же самое. Затем выполните редактирование выбранных вручную или модели, отредактируйте и, наконец, отредактируйте. > chosen > отвергнутые данные.
Типы данных включают в себя: общий английский, вопросы и ответы на знания, следование инструкциям (около 80% из трех вышеперечисленных), код, многоязычность, рассуждения и использование инструментов (около 20% из последних четырех). Вопросы и ответы на знания, а также последующие инструкции предназначены для того, чтобы ответы были более точными и соответствовали ожиданиям людей. Данные представляют собой данные многораундового взаимодействия с относительно длинными вопросами и ответами для увеличения сложности вопросов.
Поскольку обучение включает в себя несколько раундов, последняя модель будет использоваться для регенерации и аннотирования данных в каждом раунде. Для обучения модели DPO для обучения модели вознаграждения используется только последний раунд аннотированных данных; для обучения модели используются все аннотированные данные; Интуитивно говоря (это немного вынужденное объяснение, я не совсем понимаю эту конструкцию), причина этого в том, что роль модели DPO заключается в предоставлении последующих услуг, что представляет собой итеративную оптимизацию процесса. быть согласованы с текущим статусом модели. Чем более значима оптимизация; модель вознаграждения используется для оценки качества данных и не чувствительна к выравниванию, поэтому использование большего количества данных поможет ей научиться оценивать качество.
данные SFT
Данные SFT состоят из трех частей:
- Отклонить выборочные данные на основе собранных подсказок。для каждой коллекцииприезжатьизprompt,Выборка K сгенерировала ответы (обычно 10–30) с использованием модели DPO из самого последнего раунда.,Затем используйте модель вознаграждения, чтобы выбрать лучших. как упоминалось ранее,Во время обучения разные модели будут обучаться с разными данными.,Разные модели имеют свои области применения.,При генерации данных,Используйте модели, которые хороши в этой области, для генерации данных.
- синтетические данные。генерируется модельюprompt、responseизданные,А посредством комплексной проверки правил и улучшения качества получаются данные о проживании. Например,Для данных кода,Фильтрация качества может осуществляться посредством статического анализа, модульного тестирования и других методов. Эти методы,Это также можно понимать как инъекцию внешней энергии.,Качество оптимизации модели гарантировано.
- Данные, помеченные вручную。Прямо сейчасиспользовать Ручная аннотацияизданные SFT,Разработка крупных моделей на сегодняшний день,Эти данные также относительно велики по размеру.
Окончательные данные смешиваются примерно с 50 % общими английскими данными, 15 % кодовыми данными, 3 % многоязычными данными, 8 % данными экзаменов, 21 % данными рассуждений и инструментов и 0,11 % длинными текстовыми данными.
Обработка данных и качественная фильтрация
Поскольку данные генерируются, важна их качественная фильтрация. Для фильтрации качества используются два типа: на основе правил и на основе модели.
правила основаны:主要是由人Приходить看данные,Обобщить некоторые закономерности. Например, было обнаружено, что на ранних этапах обучения,Содержит больше данных эмодзи или восклицательных знаков (например, обычно это «Извините ххх»; «Прошу прощения ххх»).
управляемый моделью:Делайте суждения на основе моделей,Включать:
- Используйте модель Llama 3 8B для классификации тем. Основная цель этого должна заключаться в различении данных и обучении нескольких различных моделей.
- Используйте модель вознаграждения или контрольную точку Ламы 3 для оценки качества: используйте подсказки для оценки по нескольким параметрам, таким как точность, следование инструкциям и тон. Образцы с высокими оценками считаются качественными и соответствующим образом фильтруются;
- Используйте Llama 3 70B и LLama 3 для оценки сложности: маркируйте данные с помощью намерения. Чем сложнее намерение, тем сложнее объяснение. Вы также можете напрямую маркировать данные в соответствии с тремя уровнями сложности.
- Семантическая дедупликация на основе RoBERTa: RoBERTa хорошо влияет на извлечение семантического внедрения. Используйте RoBERTa для внедрения данных, и на основе косинусного сходства можно оценить сходство данных.
Фактически, сначала он будет основан на встроенной кластеризации RoBERTa, оценке и сортировке по качеству * сложности внутри класса и выборе данных сверху вниз. Во время выбора будут сохранены только данные с низким сходством с предыдущими данными. для обеспечения разнообразия данных.
· Особые способности
Llama 3.1 фокусируется на нескольких функциях модели, включая: код, многоязычность, математику и рассуждения, длинный контекст, использование инструментов, вывод фактов, управляемость и т. д. У каждой функции есть свои особые задачи, Лама. 3.1Всеиметь Совместю этополеиз Характеристика перепискииз Разработка алгоритма,На уровне реализации очень важным моментом является привлечение экспертов предметной области и разработка правил генерации данных на основе характеристик предметной области. Чем лучше правила, разработанные экспертами, тем лучше и полезнее они для обучения. два соображения при разработке правил. Стоит учитывать: каковы особенности и трудности этого поля, что правила могут привнести в модель;Нижеследующее в основном говорит оодин разкодиз Решение。
кодполеиз Трудность в том,:по сравнению с естественным языком,Для понимания кода требуется высокий профессиональный опыт.,让Ручная аннотация需要大量израсходы;скрытыйсуществоватьиз Преимущество в том,:кодможно проанализироватьиосуществлятьиз。поэтому,используйте эти правила,Фильтр качества для синтетических данных,Качество хранения вышеизданные Модель обучения,это разумный метод.Llama 3 использует большое количество стратегий синтетических данных для создания моделей кода обучения данных SFT.
Поскольку код представляет собой относительно большое подразделение, специализированная экспертная модель кода обучается для поддержки процесса постобучения кода. В реальной обработке мы в основном фокусируемся на умении генерировать код, писать документацию, отлаживать и проверять.
Эксперт по коду:потому чтокодполеи Проходитьиспользоватьданныеиметь Большеизразница,И объёма данных в самом коде достаточно для поддержки и обучения,Продолжить здесьпредварительнотренироваться Эксперт по Модель кода для оптимизации - 1T выполнялась на данных, которые составляли 85% данных кода. токенов на последних 1 тыс. шагов используется 16 тыс. контекстов для обучения на уровне проекта. Затем на основе этой модели данные кода используются для обучения после кода для получения окончательной экспертной модели кода. Основная функция этой модели эксперта по коду заключается в синтезе данных и обучении основной модели, включая выборку отклонений подсказок кода, связанных с обучением основной модели. В конечном итоге способность эксперта по кодированию также будет интегрирована в основную модель. .
синтетические данныегенерировать:С помощью Эксперт по коду МодельиLLama 3.1 Основная модель выполняет синтез данных, а синтезированные данные используются для постобучения основной модели для улучшения возможностей кодирования основной модели. Всего здесь синтезируется 2,7 млн фрагментов данных. Поскольку это синтетические данные, объем данных велик. Содержит следующие идеи обработки:
- в соответствии скод Анализируйте или внедряйте обратную связь,фильтрсинтетические данные。первый,Используйте случайный фрагмент кода в качестве подсказки,Пусть модель генерирует вопросы, связанные с программированием,Различные фрагменты кода можно понимать как разные начальные значения.,гарантировать Понятновопросиз Разнообразие;РанназадвыгодаиспользоватьLLama 3. Сгенерируйте ответ. При генерации укажите язык программирования, добавьте в подсказку некоторые общие правила (чтобы лучше ограничить ответ) и позвольте модели объяснить идею (во-вторых, использовать идею CoT); Статические/динамические методы используются для анализа корректности. Статические относятся к анализу на основе синтаксиса, а динамические относятся к анализу выполнения на основе модульных тестов (одиночный тест). Он также генерируется моделью); затем на основе обратной связи об ошибках итеративно улучшается данные и вводятся вопросы, ответы и содержимое ошибок в модель для модификации. Поскольку модульный тест также генерируется моделью. одновременно модифицирует модульный тест. После модификации около 20% случаев превращаются из ошибок в исправления, исходное правильное содержимое и измененное правильное содержимое используются для точной настройки модели; Вышеупомянутый процесс обновляется с помощью раундов итераций модели после обучения.
- Синтез данных на основе перевода с языка программирования。потому что Нишевые языки программированияданные Меньше количества,Существует большая разница в производительности по сравнению с основными языками.,这里ВыбиратьиспользоватьLlama 3 Перевести основные языки на нишевые языки, синтетические данные,И выполнять синтаксический анализ, компиляцию и проверку выполнения.,Используйте правильные данные в качестве окончательных данных обучения;
- Синтез данных на основе обратного перевода。первый,делатьиспользоватьLLama 3. Создавайте комментарии или пояснения к коду на основе кода, затем извлекайте или генерируйте код на основе сгенерированного контента, наконец, с помощью LLama; 3. Оцените согласованность между окончательным кодом и исходным кодом и оставьте данные с высокими оценками в качестве обучающих данных.
Рекомендации по отклонению выборки:существовать Делатьотклонить образецизкогда,Существует более сложный оперативный контроль,Прямо сейчассуществоватьpromptруководство изкодчитабельность、Документация、Тщательность、Сделайте выборку с определенной точки зрения.
Фильтрация данных с использованием сигналов дискриминанта модели:существоватьотклонить образецсередина,По двум причинам: подсказки создаются из собранных подсказок.,Данные, генерируемые им, выше, чем подсказка, генерируемая моделью.,Используйте его максимально эффективно, когда пользователи используют LLM;,Не всегда ожидайте, что код будет правильным,Например, может быть сгенерирован псевдокод и даже скопирован неправильный код.,Просто внесите некоторые измененияиспользовать。поэтому,Отбраковочная выборка не использует статический/динамический анализ для фильтрации данных.,而是делатьиспользоватьLLama 3. Принимайте решения для фильтрации данных. В частности, пусть Лама 3. Определить конкурентоспособность кода и стиль кода. Для обучения модели останется только правильный и хорошо оформленный код. Однако этот метод позволяет отсеивать сложные данные, что приводит к снижению эффективности модели. Чтобы решить эту проблему, модель неоднократно модифицируется для модификации сложных выборок до тех пор, пока не будут выполнены вышеуказанные требования.
Заключение
Прошло больше года с момента разработки большой модели. Глядя на текущий момент времени, хотя по-прежнему существует большой разрыв между отечественными большими моделями и сообществами открытого исходного кода по сравнению с openai, достижения отечественных технологий и сообществ открытого исходного кода намного превзошли всеобщие ожидания, когда openai впервые начала выпускать модели в прошлом году. Открытый исходный код во многом способствовал развитию крупных моделей. С одной стороны, можно обмениваться отличным и ценным опытом, что не позволяет различным командам идти одними и теми же обходными путями, что приводит к пустой трате социальных ресурсов, с другой стороны, люди, занимающиеся открытым исходным кодом. Источник карьеры потратит свои собственные деньги. Выводы, полученные в результате упорного труда, расскажут миру, и вы обретете более четкое видение и будете выполнять дела с более ответственным подходом. Выпуск LLama 3/3.1 означает, что сообщество открытого исходного кода смогло обучать модели чрезвычайно высокого качества, а детали обучения прозрачны и воспроизводимы. Можно предвидеть, что при дальнейшей оптимизации оборудования затраты на обучение будут еще больше сокращаться, а сила сообщества открытого исходного кода в будущем будет становиться все сильнее и сильнее.
По сравнению с вызовами API сама модель с открытым исходным кодом может быть приватизирована, точно настроена и развернута, а также имеет более безопасные и управляемые функции. В некоторых сценариях она имеет определенные преимущества со специальной настройкой и высокими требованиями к безопасности данных. Эти сценарии будут способствовать открытости. исходная модель дальнейшего применения и процветания. В то же время модель openai с закрытым исходным кодом собрала большое количество моделей оптимизации запросов пользователей. Это преимущество openai. Это преимущество, которое дает централизованная модель openai с закрытым исходным кодом. Для моделей с открытым исходным кодом преимущества пользовательских данных для оптимизации модели по-прежнему очень высоки. В LLama 3.1 разработаны разумные алгоритмы для использования этих данных. Для них будущее применение модели с открытым исходным кодом будет более ориентировано на сценарий децентрализованной приватизации. сценарии, как собирать данные, станет ценной темой для размышления.
Что включает в себя эта интерпретация:ПучокLLama 3.1технология Отчетиз Самая лучшая часть(LLMизпредварительнотренироватьсяиназадтренироваться)Все讲изотносительно тщательный Понятно,Конечно, некоторые главы еще не охвачены.,напримерДругие возможности методов синтеза данных после обучения, оценки, вывода, мультимодальной корреляции.изсодержание,На самом деле, из этого содержания можно многому научиться.,Вы можете продолжать делиться в будущем.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
