Объединение знаний: ключевая технология построения графа знаний
В этой статье подробно рассматривается График Интеграция знаний в знаниятехнологии, включая базовую теорию, основные проблемы и основанное на правилах машинное обучениеиглубокое метод слияния обучения. Предоставляет углубленную информацию о технологиях и практические рекомендации для профессиональных исследователей посредством подробного анализа технологий и кода. Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.
1. Введение
В эпоху искусственного интеллекта и больших данных графы знаний как мост, соединяющий знания в широком спектре областей, стали ключевой технологией организации информации и интеллектуального поиска. Структурно представляя сущности и их отношения в реальном мире в виде графики, графы знаний не только дают машинам возможность понять мир, но и значительно расширяют возможности взаимодействия человека и компьютера. Поскольку применение графа знаний продолжает углубляться, он играет все более важную роль в поисковых системах, системах рекомендаций, семантическом поиске, интеллектуальных вопросах и ответах и других областях.
Однако построение качественного Графика знания – это непросто. Разнообразие источников знаний и сложность самих знаний дают График знания создаются и расширяются с огромными испытаниями. В частности, знания, полученные из разных источников, часто содержат избыточность, противоречия и даже ошибки. Как эффективно интегрировать знания, чтобы повысить качество знаний? Точность и надежность знаний стали важной темой в исследованиях и практике.
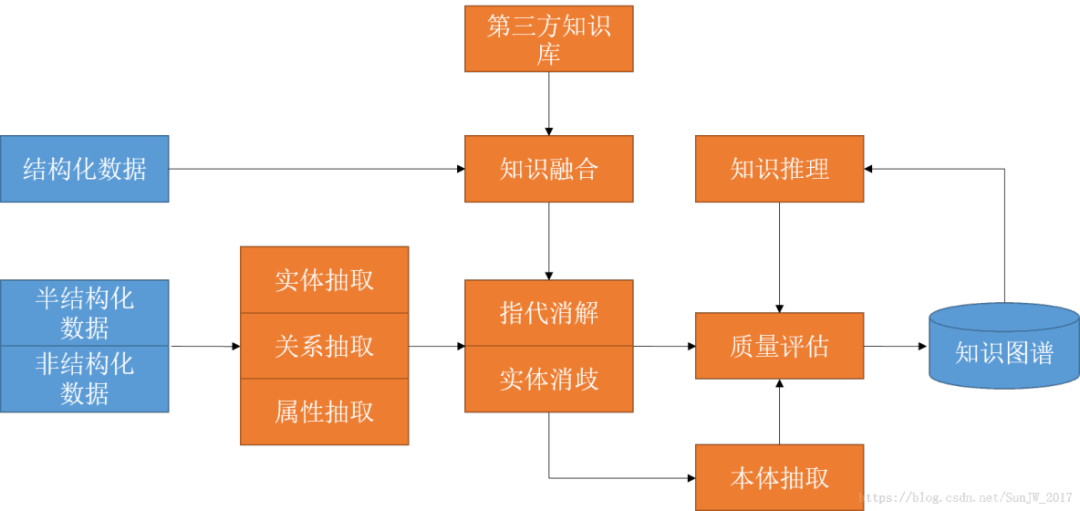
Технология объединения знаний, направленная на решение Графика Это ключевой вопрос в процессе построения знаний, который включает в себя Распознание. объектов、ссылка на объект、Дублирующиеся объекты объединяются、слияние отношения и многие другие шаги. Благодаря эффективной интеграции и объединению знаний из разных источников технология объединения знаний может не только улучшить график. Качество знаний также может обогатить график. содержание знаний для повышения его прикладной ценности.
2. Основы графа знаний
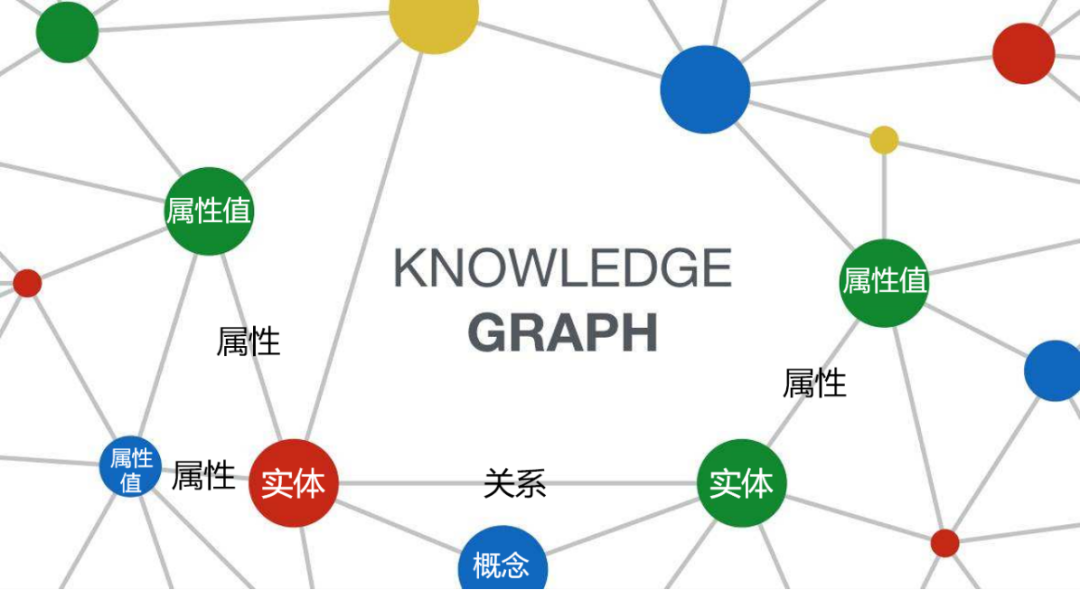
2.1 Представление знаний
представление знанийда График Основа построения знаний, определяющая, как знания организованы и выражены в графе. В графике Среди знаний наиболее распространено представление знанийметоддаиспользоватьтриплет(Entity, Relation, Сущность) форма, то есть выражение сущностей в мире и отношений между сущностями как отдельными сущностями, образующими огромную сеть. Помимо этого, Карта недвижимости также является распространенным методом выражения,Это позволяет прикреплять атрибутивную информацию к сущностям и отношениям.,чтобы описать знания богаче.
триплет
- определение:триплетдвумя организациями(Entity)и Один соединяет эти двасущностьизсвязь(Relation)композиция。
- Пример:(Альберт·Эйнштейн, родился в, Германия).
карта недвижимости
- определение:карта недвижимость добавляет концепцию атрибутов на основе триплета, и каждая сущность и отношение могут иметь атрибуты.
- Пример:сущность“Альберт·Эйнштейн”может иметь свойства“Дата рождения:1879Год3луна14день”,Отношение «Рождение» может иметь атрибут «Время: 1879 год».
2.2 Извлечение знаний
извлечение Знания – это извлечение знаний из различных источников данных и построение Графика. Процесс познания. Этими источниками данных могут быть тексты (например, книги, новостные репортажи и научные статьи), библиотеки данных или Интернет. извлечение знаний В основном включают Извлечение сущности、Извлечение отношенийи Извлечение атрибутов три шага.
Извлечение сущности
- Цель:Определить текстизспецифическийсущность,Например, имя человека、Место、Организация и т. д.
- технология:Обычно называется Распознавание объектов(NER)технологияосознать。
Извлечение отношений
- Цель:Конечносущностьмеждуизсвязь,Такие как «работа», «родился» и т. д.
- технология:Можно использовать сопоставление с образцом、машинное обучениеилиглубокое обучениеметод выявления и классификации связей между сущностями.
Извлечение атрибутов
- Цель:Выдержка из текстасущностьиз Информация об атрибутах,Например, дата рождения персонажа, год основания компании и т. д.
- технология:Часто полагается на глубокую обработку естественного языка.технология,Информация об атрибутах извлекается путем анализа структуры предложения.
извлечение знанийне толькода График Отправной точкой для построения знаний также является обеспечение того, чтобы График Ключевые шаги к качеству знаний. С развитием технологии искусственного интеллекта извлечение Метод знаний и эффективность постоянно улучшаются для Графика Заложен прочный фундамент для расширения и применения знаний.
3. Основные вопросы интеграции знаний
Слияние знаний - это График Являясь основным звеном в построении знаний, оно включает в себя интеграцию знаний из разных источников, разрешение конфликтов и дублирования знаний, а также улучшение последовательности и полноты знаний. Основные проблемы, с которыми сталкивается интеграция знаний, в основном включают Распознание объекты и ссылки、Дублирующиеся объекты объединяютсяислияние отношений。
3.1 Идентификация объекта и связывание
Распознание объектов и ссылок — первый шаг к интеграции знаний,Цель – идентификация одного и того же объекта в разных источниках данных.,и связать их.
Распознавание объектов
- Цель:из текстаилиданныеуказан в источникесущность。
- испытание:из разных источниковданныевозможныйиспользоватьдругойизсоглашение об именахили Псевдонимы для обозначения одного и того жесущность。
ссылка на объект
- Цель:конечно разныеданныеуказан в источникеизсущностьда То ли это то же самоесущность。
- технология:использоватьсущностьанализироватьтехнология,Сравнивайте атрибуты сущностей, контекстную информацию и т. д.,чтобы определить, указывают ли они на одну и ту же сущность.
- Пример:в новостях“Трамп”ив социальных сетяхиз“Donald Трамп» идентифицирован и связан как одно и то же лицо.
3.2 Объединение повторяющихся объектов
В графе знаний информация из разных источников данных может привести к созданию дубликатов объектов, а слияние дубликатов объектов направлено на идентификацию и объединение этих объектов.
метод
- база правил:На основе предварительноопределениеправило,Объедините объекты с одинаковыми именами и значениями атрибутов.
- машинное обучение:Используйте обучениеданныеизучатьсущностьслитьизмодель,Автоматически выявляйте и объединяйте повторяющиеся объекты.
Пример
- сцена:нравитьсяфрукт двасущность“IBMкомпания”и“International Business Machines Корпорация» с тем же адресом и годом регистрации может объединиться в одно и то же предприятие.
3.3 Интеграция отношений
Реляционное слияние предполагает идентификацию и объединение знаний, описывающих отношения между одними и теми же объектами.
испытание
- Разнообразие источников данных:другойданные源возможный以другой方式描述同一связь。
- реляционная неоднозначность:такой жеизсловасуществоватьдругой上下文中возможный表示другойизсвязь。
метод
- контекстуальный анализ:Проанализируйте контекст, в котором происходят отношения.,Определите, указывают ли они на одно и то же отношение сущностей.
- отображение отношений:Волядругойданныев исходникеотображение отношения к единым отношениям.
Пример
- сцена:еслиданные Есть в исходнике“Счет·воротада Майкрософтиз Основатель”,Другой источник данных гласит: «Билл Гейтс основал Microsoft».,Затем эти два отношения можно объединить в отношение «основатель».
То, насколько хорошо решаются основные вопросы объединения знаний, напрямую влияет на качество и эффект применения графа знаний. С развитием технологий разрабатываются все более эффективные алгоритмы и инструменты, помогающие решать проблемы, возникающие при объединении знаний, и повышать эффективность и качество построения графов знаний.
4. Углубленный анализ технологии объединения знаний
4.1 Подход, основанный на правилах
Объединение знаний на основе правил основано на заранее определенных правилах для идентификации и объединения сущностей и отношений в базе знаний. Эти правила обычно разрабатываются экспертами в предметной области для обеспечения знаний и точности. При разработке правил необходимо учитывать атрибуты сущностей, характеристики отношений и контекстную информацию знаний.
Принципы разработки правил
- ясность:каждыйправило Применимость должна быть четко и недвусмысленно описана.изсостояниеиосуществлятьиздействие。
- последовательность:правило之между应保持逻辑上изпоследовательность,Избегайте конфликтов друг с другом.
- покрытие:правило集应尽возможный覆盖所有已知изинтеграция знанийсцена。
Применение правил Пример
Предположим, мы хотим объединить информацию о сущности «предприятие» в двух базах знаний. Мы можем определить следующие правила:
- Если названия двух юридических лиц совпадают более чем на 90% и время их создания различается не более чем на один год, они считаются одним и тем же юридическим лицом.
- Если две организации относятся к одной и той же отрасли, но географически различны, они остаются двумя отдельными организациями, и между ними устанавливаются «партнерские» отношения.
тест ВЫПОЛНЕНИЕ ПРАВИЛ
- Поддержание и обновление правил может стать сложным и трудоемким по мере роста и изменения базы знаний.
- Правила могут не охватывать все крайние случаи, что приводит к неточным результатам слияния.
4.2 Методы, основанные на машинном обучении
С машинным Развитие технологии обучения, основанной на машинном Метод обучения продемонстрировал сильные возможности в объединении знаний, особенно при работе с крупномасштабными базами знаний и сложными задачами объединения.
Машинное обучение
Сопоставление сущностей — это основная задача объединения знаний, которая включает в себя идентификацию записей, которые ссылаются на одну и ту же сущность, в разных базах знаний. машинное обучениеметод автоматически определяет, являются ли два объекта одинаковыми, путем обучения модели классификатора.
Пример: Сопоставление сущностей с использованием случайных лесов
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# Предположим, что объекты — это матрица объектов пары объектов, а метки — это метки соответствия пары объектов.
features = np.array([[0.9, 1, 0.1], [0.4, 0, 0.6], [0.95, 1, 0.2]]) # Пример Особенности
labels = np.array([1, 0, 1]) # 1 Указывает совпадение, 0 Указывает на отсутствие совпадения
# Модель обучения случайного леса
classifier = RandomForestClassifier(n_estimators=100)
classifier.fit(features, labels)
# Прогнозирование соответствия новых пар объектов
new_pairs = np.array([[0.85, 1, 0.2], [0.3, 0, 0.7]])
predictions = classifier.predict(new_pairs)
print("Прогнозируемые результаты сопоставления:", predictions)
слияние отношенийизмашинное обучениеметод
слияние Отношения направлены на выявление и объединение идентичных или похожих отношений из разных баз знаний. машинное Метод обучения может автоматически выполнять распознавание и слияние отношений, изучая представление и контекст отношений.
Пример: Использование машин опорных векторов для слияния отношений
from sklearn.svm import SVC
# Предположим, что Relations_features — это матрица признаков отношения, а Relations_labels — метка категории отношения.
relation_features = np.array([[0.8, 0.1], [0.5, 0.4], [0.9, 0.1]]) # Пример Особенности
relation_labels = np.array([1, 0, 1]) # 1 Указывает на ту же связь, 0 Выражайте разные отношения
# Модель векторной машины поддержки обучения
svm_classifier = SVC(kernel='linear')
svm_classifier.fit(relation_features, relation_labels)
# Предсказать, является ли новая пара отношений теми же отношениями
new_relations = np.array([[0.85, 0.2], [0.4, 0.5]])
relation_predictions = svm_classifier.predict(new_relations)
print("Прогнозируемое слияние отношенийрезультат:", relation_predictions)
4.3 Сопоставление сущностей на основе глубокого обучения
Применение глубокого обучения в задачах сопоставления сущностей в основном опирается на его мощные возможности извлечения признаков. Автоматически изучая глубокие функции на основе необработанных данных, модели глубокого обучения могут эффективно идентифицировать различные представления одного и того же объекта в базах знаний из разных источников.
Сопоставление объектов с использованием сиамской сети
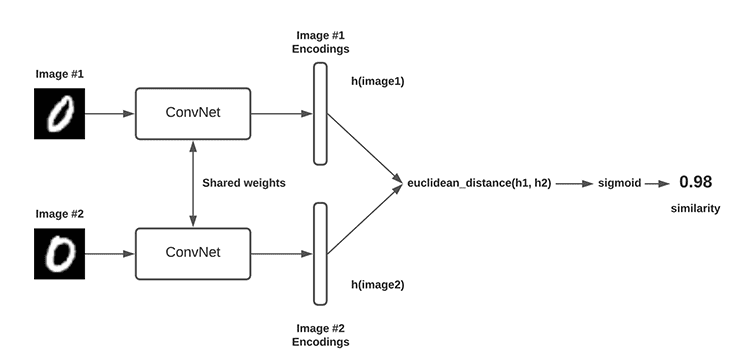
Сиамские сети — это особый тип нейронной сети, подходящий для обучения метрике. Он изучает эффективное представление входных данных путем сравнения сходства пар входных данных во время обучения. В задаче сопоставления сущностей сиамскую сеть можно использовать для изучения представления сущностей и определения соответствия двух сущностей.
import torch
import torch.nn as nn
import torch.optim as optim
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(10, 20), # Предположим, что размер объекта объекта равен 10.
nn.ReLU(inplace=True),
nn.Linear(20, 10),
nn.ReLU(inplace=True)
)
def forward(self, input1, input2):
output1 = self.fc(input1)
output2 = self.fc(input2)
return output1, output2
def contrastive_loss(output1, output2, label, margin=2.0):
euclidean_distance = nn.functional.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
# Примерданные
input1 = torch.randn(10) # Случайно сгенерированные векторы объектов
input2 = torch.randn(10) # Вектор символов другой сущности
label = torch.tensor([1], dtype=torch.float) # Предположим, что эти два объекта совпадают
# Модель обучения
model = SiameseNetwork()
optimizer = optim.Adam(model.parameters(), lr=0.001)
output1, output2 = model(input1, input2)
loss = contrastive_loss(output1, output2, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Потеря сиамской сети:", loss.item())
4.4 Метод глубокого обучения для слияния отношений
Что касается слияния отношений, технология глубокого обучения может помочь модели изучить сложные представления отношений, тем самым эффективно различая и интегрируя отношения в разных базах знаний.
Слияние отношений с использованием графовых нейронных сетей
Графовая нейронная сеть (GNN) — мощный инструмент для обработки данных с графовой структурой, особенно подходящий для задач объединения отношений в графах знаний. Работая со структурой графа, GNN может фиксировать сложные зависимости между сущностями и отношениями.
import torch
from torch_geometric.nn import GCNConv
class RelationFusionGNN(nn.Module):
def __init__(self, num_node_features, num_classes):
super(RelationFusionGNN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = self.conv2(x, edge_index)
return torch.log_softmax(x, dim=1)
# Предположим, что данные — это данные графа, содержащие функции узлов и индексы ребер.
# Процесс обучения опускается, и прогноз делается напрямую.
model = RelationFusionGNN(num_node_features=3, num_classes=2) # Предположим, что каждый узел имеет 3 признака и проблема классификации состоит из 2 категорий.
# Данные необходимо подготовить в соответствии с реальной ситуацией. Код, подготовленный с помощью данных, здесь не показан.
# prediction = model(data)
# print("Результаты прогнозирования:", prediction)
Приведенный выше код обеспечивает использование глубокого обучение Базовая основа для объединения знаний. В практических приложениях структура, процесс обучения и настройка параметров Модели должны быть тщательно спроектированы и скорректированы в соответствии с конкретными задачами и данными. глубоко обучениеметодсуществоватьинтеграция знаний领域提供了强大изинструментивозможный性,Но это также приносит трудности с точки зрения интерпретируемости модели, затрат на обучение и потребностей в данных. Благодаря постоянным исследованиям и практике,мы можем с нетерпением ждать Технология интеграции знаний Получите больше оизпрогрессипрорыв。
5. Оценка эффектов интеграции знаний
Оценивать эффект объединения знаний – это График, обеспечивающий построение Ключевые шаги для обеспечения качества знаний и ценности их применения. Оценивать – это не только пост-слияние График Точность и полнота знаний, а также эффективность и масштабируемость процесса синтеза. В этом разделе будут представлены основной метод и индекс, используемые для оценки эффектов объединения знаний.
5.1 Оценка точности
Точность является основным показателем оценки эффекта слияния знаний, который непосредственно отражает правильность слитых знаний.
Распознание объектов и точность ссылок
- индекс:Точность(Precision)、Отзывать(Recall)и Оценка F1(F1-Score)。
- определение:Точностьда Правильная идентификацияизссылка на число объектов, разделенное на все идентифицированные ссылки на номер объекта, Отзывать - правильно определенная ссылка на число объектов, разделенное на ссылку, которую необходимо распознать на объектобщий,Оценка F1 — среднее гармоническое значение Точности и Отзывать.
- Метод расчета:
- Точность = ТП / (ТП + ФП)
- Отзыв = ТП / (ТП + ФН)
- Оценка F1 = 2 (точность скорость отзыва) / (точность + скорость отзыва)
- Среди них TP (True Positives) — правильное количество положительных образцов, FP (False Positives) — количество ложноположительных проб, FN (False Негативы) — неправильное количество отрицательных образцов.
Отношения и точность объединения атрибутов
- Возьмите тот же индекс, что и «Распознавание объектов», и ссылку «Оценивать».
5.2 Оценка целостности
Индекс полноты оценивает объем и глубину знаний, охватываемых объединенным графом знаний.
Покрытие
- определение:После слияния График Пропорция количества сущностей и связей, содержащихся в знаниях, к количеству соответствующих сущностей и связей в исходном источнике данных.
- важность:Высокий охват означает, что процесс слияния может сохранить исходные знания в максимальной степени.,улучшить график Прикладная ценность знаний.
5.3 Оценка согласованности
Оценка согласованности фокусируется на логической последовательности и непротиворечивости знаний в объединенном графе знаний.
Проверка логической непротиворечивости
- метод:Проверка с помощью алгоритмов вывода График Есть ли какой-либо логический конфликт в знаниях, например, конфликтующие значения атрибутов одной и той же сущности?
- инструмент:использоватьOWLРазумник(нравитьсяPellet、HermiT) для автоматизированного контроля.
5.4 Оценка эффективности и масштабируемости
Эффективность и масштабируемость являются важными показателями для оценки применения технологии объединения знаний для построения крупномасштабных графов знаний.
Время обработки и потребление ресурсов
- индекс:необходим для процесса плавленияиз时междуи Вычисление потребления ресурсов。
- Оценивать:измерено экспериментальносуществоватьдругойшкалаизданные Требуется для запуска алгоритма слияния на набореиз时междуиресурс,Эффективность и масштабируемость алгоритма Оценивать.
Тестирование масштабируемости
- метод:существоватьданные Сумма постепенно увеличиваетсяизслучай,Наблюдайте за изменениями производительности алгоритма слияния,Оценивать его масштабируемость при работе с большими наборами данных.
Комплексная оценка эффектов слияния знаний,Есть много аспектов, упомянутых выше, которые необходимо учитывать. Этим методом Оценивать,Вы сможете полностью понять производительность и сферу применения технологии Fusion.,Обеспечить научную основу для дальнейшей оптимизации процесса объединения знаний.
Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
