Новое поколение искусственного интеллекта: освойте векторную базу данных и глубоко объедините ее с большими моделями
【Идеи выбора темы】
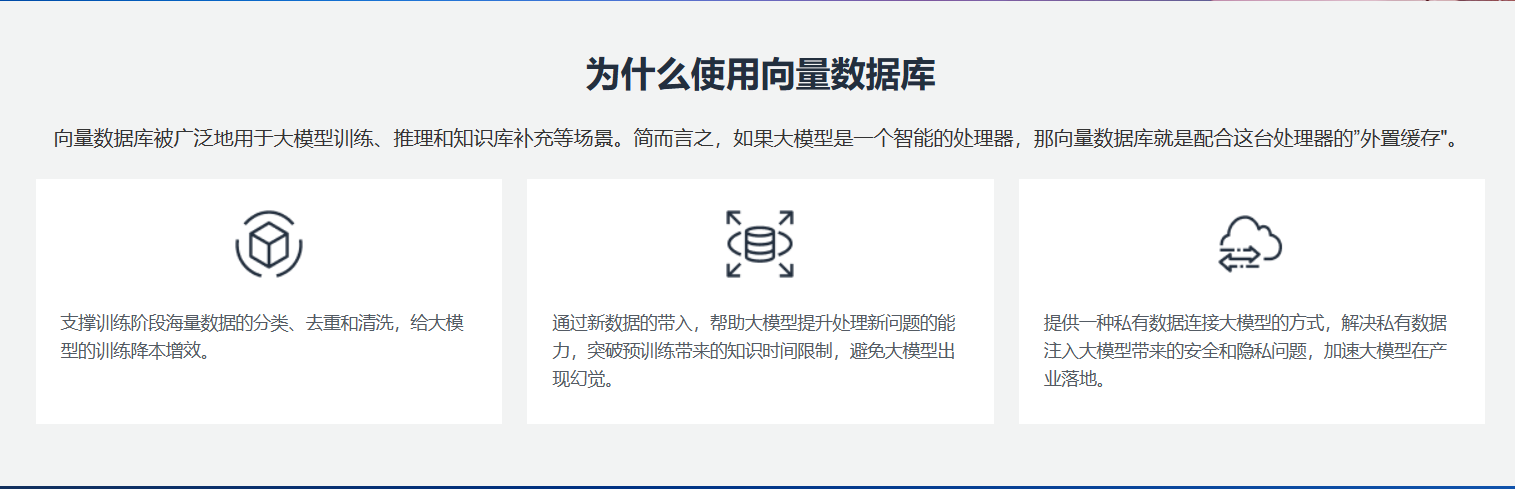
Поскольку масштаб моделей искусственного интеллекта продолжает расширяться, важным вопросом становится то, как заставить эти «большие модели» более эффективно обслуживать пользователей. База данных векторов — это база данных, которая возникла на этом фоне. Она использует векторы для эффективного хранения и извлечения данных модели, что значительно повышает эффективность запросов.
【Написание плана】
1.Что такое векторная база данных
2.Как работают векторные базы данных
3.Классификация векторной базы данных
4.Сравнительный анализ
5.Применение векторной базы данных в больших моделях
6.Оптимизация векторного индекса
7. Области применения
8.Зачем нам нужна векторная база данных для создания интеллектуальных отраслевых приложений на основе больших языковых моделей?
9. Будущее и перспективы
10 Резюме
Tencent Cloud VectorDB — это полностью управляемая, самостоятельно разработанная служба распределенных баз данных корпоративного уровня. Один индекс поддерживает масштаб векторов в 1 миллиард, а также миллионы запросов в секунду и задержку запросов на уровне миллисекунд. Он не только может повысить точность ответов на большие модели, но также может широко использоваться в рекомендательных системах, обработке естественного языка и других областях.

Что такое векторная база данных

Раньше за организацию данных отвечали традиционные реляционные базы данных. Но он больше подходит для работы со структурированными данными. Большие модели и нейронные сети чаще сталкиваются с массивными неструктурированными данными, такими как текст, аудио, видео, отношения и т. д. У них есть специальный метод обработки: «векторизация». Если вы хотите организовать данные по такой «мозговой схеме», вам понадобится специальная база данных — векторная база данных. Объединяйте сложные неструктурированные данные в значения координат в многомерном пространстве посредством векторизации (встраивания) и быстро находите наиболее подходящее приближение, вычисляя сходство или расстояние между векторами.

Vector Database — это новый тип нереляционной базы данных, которая использует технологию математической линейной алгебры для хранения и обработки структурированных и неструктурированных данных.
Базы данных векторов отображают объекты данных в векторы фиксированной размерности и сохраняют эти векторы в памяти или на диске в эффективном и плотном формате. В отличие от традиционных реляционных баз данных, она не требует предварительного определения фиксированной схемы базы данных, и можно легко добавлять новые поля.
Как работают векторные базы данных

Проще говоря, рабочий процесс векторной базы данных выглядит следующим образом:
На этапе предварительной обработки данных неструктурированные данные преобразуются в числовое векторное представление;
На этапе векторного представления обработанное векторное представление фиксируется в векторе фиксированной размерности;
На этапе векторного хранения векторное представление сохраняется и управляется в эффективном формате (например, TF-IDF, LSH и т. д.);
На этапе поиска векторов вычисление расстояния между векторами (например, косинусного сходства) используется для быстрого поиска векторов результатов, похожих на вектор запроса.
Взяв в качестве примера TF-IDF, он отображает документ в плотное векторное представление, подсчитывая частоту каждого слова в отдельном документе и во всем корпусе, и использует косинусное сходство для сопоставления документов.
Классификация векторной базы данных

В соответствии с различными форматами хранения и алгоритмами поиска основные векторные базы данных в основном включают:
База данных векторов инвертированного индекса. Используйте таблицу инвертированного индекса для преобразования слов в список идентификаторов документов, аналогично Elasticsearch.
База данных векторов TF-IDF: используйте значения TF-IDF для представления документов в виде плотных векторов, аналогично базе данных антропных векторов.
База данных векторов дерева лучей: используйте структуру дерева лучей для повышения эффективности многомерного запроса векторного расстояния, аналогично Faiss.
Локально ориентированная база данных хэш-векторов: использует алгоритм LSH для приблизительного запроса ближайшего соседа, аналогично Nephrite.
Представительская работа: милвус
Milvus — это векторная база данных с открытым исходным кодом, предназначенная для поддержки встроенных приложений поиска по сходству и искусственного интеллекта. Milvus делает поиск неструктурированных данных более доступным, обеспечивая единообразный пользовательский опыт независимо от среды развертывания.
Milvus 2.0 — это облачная векторная база данных, хранилище и вычисления которой разделены в зависимости от конструкции. Все компоненты в этой обновленной версии Milvus не имеют состояния для повышения отказоустойчивости и гибкости.

Сравнительный анализ

Традиционные слова, такие как NoSQL и SQL.
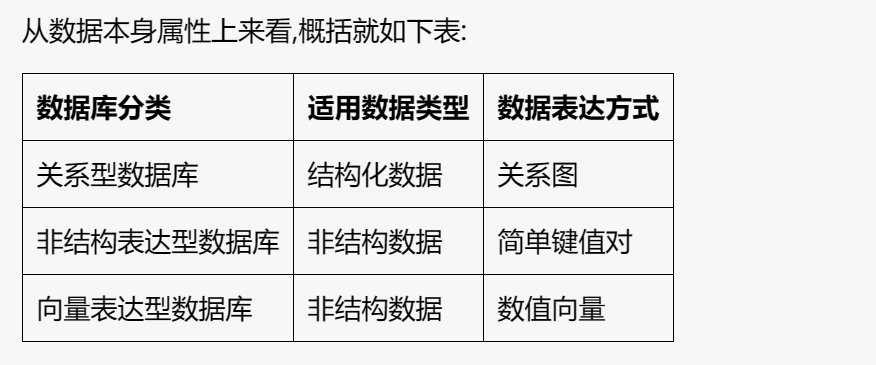
Классифицировать базы данных на основе выразительности данных
База данных реляционных выражений: выражает структурированные данные в реляционном графе таблиц, представленном реляционной базой данных.
База данных неструктурированных выражений: использует ключ-значение, документ и другие простые методы для непосредственного выражения неструктурированных данных, представленных базой данных «ключ-значение» и базой данных документов.
База данных векторных выражений: использует технологию линейной алгебры для выражения неструктурированных данных в виде цифровых векторов фиксированной длины, представленных в виде баз данных векторов.
Основные различия заключаются в нескольких основных направлениях.
Подход к моделированию данных
Традиционные базы данных обычно используют табличные и реляционные модели для моделирования данных, сохраняя данные в виде структурированных строк и столбцов. База данных векторов представляет #данные в виде векторов.
Метод запроса данных
Традиционные базы данных используют язык SQL для запроса и получения необходимых данных путем указания условий и отношений. База данных векторов выполняет запросы, вычисляя сходство между векторами.
Возможности обработки данных

Векторные базы данных обладают превосходной производительностью и эффективностью при обработке многомерных векторов и крупномасштабных данных. Он использует высокооптимизированные алгоритмы индексации векторов и запросов для быстрого поиска и извлечения похожих векторов в больших объемах данных. Традиционные базы данных часто неэффективны при работе со сложными связями данных и запросами к нескольким таблицам.
База данных SQL с векторной поддержкой
PostgreSQL от Tencent, Clickhouse
По сравнению с реляционными базами данных преимуществами векторных баз данных являются:
Никакую структуру данных не нужно определять заранее, что упрощает расширение;
Основанный на вычислении векторного расстояния, он поддерживает нечеткое сопоставление, а не точный запрос;
Эффективно храните и извлекайте большие объемы векторных данных в сжатом и плотном формате.
По сравнению с неструктурированными базами данных документов:
Замените документы о заболеваниях числовыми представлениями для поддержки более сложных операций запроса;
Базовый алгоритм оптимизирован, а эффективность поиска выше;
Интегрируйте возможности глубокого обучения и поддерживайте функции динамического обучения.
В сценариях применения больших моделей векторные базы данных демонстрируют более заметные преимущества. В следующем разделе мы представим типичные случаи применения в этом отношении.

Применение векторной базы данных в больших моделях

Служба рассуждений Сиюань: использует граф знаний векторной модели управления базой данных для поддержки более быстрого поиска вопросов, ответов и утверждений.
Антропный помощник: используйте векторные базы данных для улучшения моделей диалога на естественном языке и получения более контекстуальных и семантических ответов.
Служба машинного перевода: использует векторные базы данных для ускорения сопоставления семантических графов знаний и обеспечения справочной информационной поддержки для машинного перевода.
Система анализа настроений: в сочетании с векторной базой данных для управления корпусом эмоциональных знаний она может эффективно определять эмоциональные тенденции потребностей пользователей.
Поддержка принятия медицинских решений: используйте базы данных векторов для управления медицинскими знаниями и случаями, чтобы помочь диагностировать сложные клинические проблемы.

Применение векторной базы данных

распознавание лиц
векторная база Данные могут хранить большой объем векторных данных о лицах и обеспечивать быстрое распознавание с помощью технологии векторного индексирования. лица и сравните.
Поиск изображений
векторная база data могут хранить большие объемы векторных данных изображений и обеспечивать быстрый поиск с помощью технологии векторного индексирования. изображения и сопоставление сходства.
распознавание звука
векторная база data может хранить большие объемы аудиовекторных данных и обеспечивать быстрое распознавание с помощью технологии векторного индексирования. звук и совпадение.
обработка естественного языка
Базы данных векторов могут хранить большие объемы текстовых векторных данных и обеспечивать быстрый текстовый поиск и сопоставление по сходству с помощью технологии векторного индексирования.
Система рекомендаций
База данных векторов может хранить большой объем пользовательских векторных данных и векторных данных элементов, а также обеспечивать быстрое сопоставление рекомендаций и сходства с помощью технологии векторного индексирования.
интеллектуальный анализ данных
векторная база Данные могут хранить большие объемы векторных данных и обеспечивать быструю интеллектуальную работу с помощью технологии векторного индексирования. анализ данныхи анализ。

Поисковая оптимизация, инкрементальный вектор TF-IDF для хранения инвертированных таблиц для улучшения расчета релевантности.
Оптимизация векторного индекса

Векторное индексирование — ключ к повышению эффективности поиска. Общие алгоритмы оптимизации включают в себя:
NMSLIB: поддерживает структурную оптимизацию, такую как KMeans, для ускорения запросов к ближайшему соседу.
HNSW: используйте несбалансированный многоуровневый индекс для уменьшения сложности запросов.
FAISS: поиск сходства в реальном времени с использованием методов оптимизации, таких как квантование продукта.
РАЗДРАЖЕНИЕ: предоставление рекомендаций в режиме реального времени с помощью поиска соседей по индексу дерева дорог.
Поиск информации, кластеризация документов и т. д. позволяют достичь соответствия на семантическом уровне посредством векторного представления.
Идентификация домена, извлечение именованных объектов и классификация с помощью обучения с подкреплением векторного представления.
Рекомендации системы строят портреты пользователей и дают персонализированные рекомендации за счет векторного сходства.
Биоинформатика для быстрого анализа выравнивания с помощью векторизованных последовательностей/структур.

Благодаря эффективному управлению векторными базами данных эти службы больших моделей могут обеспечить более эффективный поиск знаний, тем самым предоставляя пользователям персонализированный опыт обслуживания.
Зачем нам нужна векторная база данных для создания интеллектуальных отраслевых приложений на основе больших языковых моделей?
База данных векторов может эффективно управлять отраслевыми знаниями и предоставлять структурированный интерфейс запросов к модели. Большие языковые модели больше не полагаются на внутренние знания для достижения истинного внешнего интеллекта.
Унифицированное представление структурированных и неструктурированных данных в виде векторов обеспечивает единый интерфейс данных для модели. Крупным моделям полезно изучить отраслевые профессиональные термины и связанные с ними модели.
Поддерживает запросы приблизительного сопоставления на основе расстояния для удовлетворения требований модели к доступу в реальном времени к знаниям о семантическом сходстве.
Через интерфейс оптимизации обучения модель можно объединить с векторной базой данных для онлайн-обновления и быстрого усвоения новых бизнес-знаний.
Если взять в качестве примера робота для медицинских консультаций, то если для управления медицинскими знаниями используется векторная база данных, она включает в себя:
Таблица векторов соответствия симптом-болезнь
Таблица векторов соответствия пунктов проверки заболеваний
Таблица векторов соответствия заболевания-рецепта
При ответе на вопросы пациентов большая языковая модель может выполнять следующие эффективные операции на основании описанных пользователем симптомов:
Используйте косинусное сходство, чтобы найти возможные соответствующие заболевания в таблице симптомов.
Найдите соответствующую информацию об этих заболеваниях в других таблицах, например, в предметах обследования и назначениях, и дайте предложения по выбору наиболее вероятных.
Если предложение неуместно, используйте график знаний, чтобы исправить его и представить заново.
При этом процесс взаимодействия записывается для онлайн-обучения модели и непрерывной оптимизации возможностей обработки.
Таким образом, граф отраслевых знаний, основанный на управлении векторными базами данных, может эффективно помочь большим языковым моделям достичь перехода от «общего» к «профессиональному» и обеспечить более эффективные интеллектуальные услуги. Именно здесь векторные базы данных играют важную роль в построении отраслевой аналитики.
Посмотрите, продолжает ли семантический поиск становиться «лучшей практикой искусственного интеллекта» во всех отраслях. В будущем, включая построение и оптимизацию графов знаний, область применения технологии векторных баз данных станет более широкой. Это поможет большим языковым моделям стать важной частью отраслевой интеллектуальной системы.

В будущем, с развитием искусственного интеллекта, большие модели и векторные базы данных неизбежно будут интегрированы на более глубоком уровне для совместного создания интеллектуальной системы обработки и обслуживания знаний. Это будет способствовать дальнейшему продвижению искусственного интеллекта в промышленных целях.
Справочные ссылки:
https://cloud.tencent.com/developer/techpedia/1953
https://github.com/milvus-io/milvus
https://aws.amazon.com/cn/campaigns/what-is-a-vector-database/



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
