Новейший алгоритм рекомендаций Meta: унифицированные генеративные рекомендации впервые победили систему глубоких рекомендаций с иерархической архитектурой?
Привет всем, это Нью Би НЛП. Ознакомьтесь с последним алгоритмом Meta сегодня рекомендацийбумага,«Унифицированная генеративная рекомендация» (GR) впервые заменяет парадигму иерархической модели с массивными функциями, которая использовалась в индустрии рекомендаций в течение последних десяти лет в основной линейке продуктов.。

Адрес: https://arxiv.org/pdf/2402.17152.pdf.
Автор: Сяо Се
Ссылка: https://www.zhihu.com/question/646766849/answer/3428951063
Дипломная работа была весьма интересной. В прошлом существовала такая работа, как AutoInt, которая использовала преобразователи для автоматического объединения функций, а также была такая работа, как Transformers4Rec, которая использовала преобразователи для моделирования последовательностей. Эта работа помещала портреты пользователей, поведение пользователей и даже целевую информацию в очень длинные последовательности. в сочетании с несколькими слоями (если это 3-уровневое точное планирование, 6-слойный отзыв, до 24 слоев) трансформатором для моделирования, что очень просто.
Статья может быть коротким видео-рекомендательным бизнесом Meta. Поскольку мы не знаем конкретной ситуации с базовым онлайн-режимом, мы предполагаем, что источник эффекта может быть следующим:
- Более широкие возможности кроссовера функций:Непосредственно представляйте портреты пользователей иtargetинформационный крест,без потери информации,Кроссовер стал более полноценным. Большая часть работы по пересечению функций выполняется над пользовательскими представлениями, которые были сжаты после обработки пользовательского моделирования.,Потери информации относительно велики. Конечно, существуют также такие работы, как декартово произведение и CAN, которые основаны на оригинальном поведении пользователя.,Однако возможности моделирования могут быть слабее, чем у многослойной структуры трансформатора. Кроме того, если посмотреть на размер встраивания работы в бумагу, это может быть размер 512.,Поэтому мощность модели также должна быть достаточной. Кроме того, я не знаю, есть ли в базовой версии закрытые сети, такие как senet или ppnet.,если не,Новая Архитектура также должна иметь больше улучшений эффектов.
- Полнее используйте информацию: Для разреженных параметров далее следует авторегрессионное прогнозирование. По сравнению с потерей перекрестной энтропии исходного измерения выборки, потеря элемента может обеспечить более полное градиентное обновление параметров, и эффективность использования выборки будет выше. Это очень похоже на вспомогательную потерю в DIEN.
- Более подробное представление о поведении пользователей и более широкие возможности моделирования последовательностей.:Пока не уверенbaselineЕсть ли моделирование поведения пользователей?,И насколько поведение пользователей базовой версии соотносится с новой Архитектурой?,Новую Архитектуру можно использовать для более продолжительного поведения пользователя. Или время поведения пользователя одинаковое,Но в новой Архитектуре могут появиться более подробные сигналы о поведении пользователей (например, в базовой версии используются только клики).,Новая Архитектура ввела экспозицию и т. д.). Кроме того, даже если поведение пользователя точно такое же,Способность новой Архитектуры моделировать поведение пользователей, очевидно, будет сильнее.,Это также должно иметь усиление эффекта.
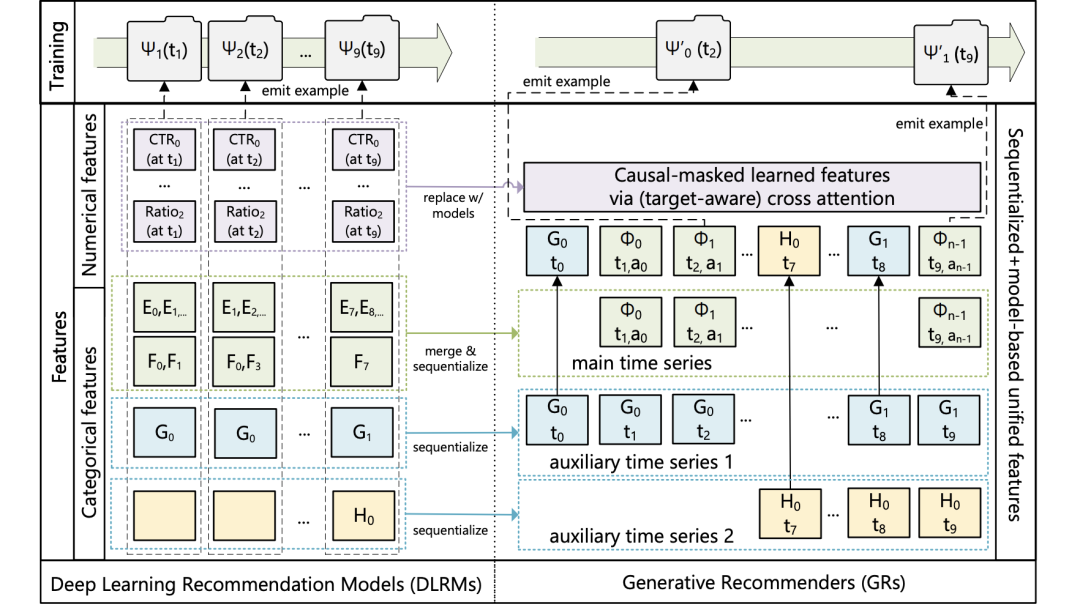
Крест в бумаге Реализация внимания кажется довольно интересной. Если структура статьи реализована в сценарии рекомендации CTR, то можно объединить экспозицию и поведение кликов в последовательность, а время появления элемента Информация об атрибутах, такая как разница и категория, аналогична позиции. embeddingвведен путем добавления,Также добавьте тип поведения в последовательность.,Форма последовательности аналогична:item1,Экспозиция не нажата,item2,Нажмите,item3,Нажмите。。。 Есть следующий следующий item Потеря прогноза, но только предсказывает, следует ли щелкнуть, а другие части маскируются.
Масштабирование, которое появляется в документе Законодательное явление захватывающее , но масштабирование LLM В законе упоминается, что количество параметров и размер набора данных должны увеличиваться одновременно, если будет увеличен только один, будет штраф за увеличение эффекта. Я не знаю, как изменился размер набора данных. когда в статье проводился эксперимент и было ли достаточно данных для подтверждения.
Кроме того, документ о законе масштабирования LLM исключает уровень внедрения при обсуждении количества параметров расчета. Этот документ не должен исключать его. Я не знаю, есть ли разница между рекомендацией и законом масштабирования большой модели НЛП.
Хотя в статье и отказываются от искусственно созданных статистических признаков, она по-прежнему обучается на основе системы ID и не вводит мультимодальную информацию. Некоторые текущие исследования показали, что мультимодальная информация в некоторых случаях может равняться системе ID. Интересно, произойдет ли какой-то качественный скачок в сочетании с увеличением сложности модели и объема данных? Я все еще жду этого.
Структура статьи позволяет объединять сотни наборов кандидатов в последовательность во время онлайн-рассуждений и выполнять рассуждения одновременно. Это должно сэкономить определенное количество вычислительной мощности. Кроме того, поскольку требуется меньше обработки признаков, расчет части извлечения и обработки признаков будет относительно простым, что также должно сэкономить много машин. Стоимость вычислительной мощности статьи, которую можно использовать для вывода, аналогична базовой мощности. Возможности инженерной оптимизации Meta действительно очень сильны. Если вы попытаетесь реализовать это позже, пространство эффекта может зависеть от пересечения функций текущей базовой линии и уровня технологии пользовательского моделирования. Кроме того, проблема инженерной оптимизации также будет относительно большой.
Автор: Лунармония
Ссылка: https://www.zhihu.com/question/646766849/answer/3417573481
Как один из соавторов этой статьи, я постараюсь ответить.
Прежде всего, в этой статье есть много основных моментов, включая, помимо прочего,
- «Унифицированная генеративная рекомендация» (GR) впервые заменяет парадигму иерархической модели с массивными функциями, которая использовалась в индустрии рекомендаций в течение последних десяти лет в основной линейке продуктов.;
- новый кодер (HSTU) от новой Архитектуры + Разреженность алгоритмов повышает качество модели за пределами Transformer + Фактический коэффициент эффективности обучения FlashAttention2 (На данный момент самая быстрая реализация Transformer) в 15,2 раза быстрее;
- Мы достигли 700-кратного ускорения на стороне вывода (сложная модель в 285 раз, QPS вывода в 2,48 раза) благодаря новому алгоритму вывода M-FALCON;
- от новой АрхитектурыHSTU+ Алгоритм обучения GR,Общий объем расчетов нашей модели увеличился в 1000 раз.,Впервые достигаем GPT-3 175b/LLaMa-2 70b и другие вычислительные мощности для обучения LLM, и впервые мы наблюдали масштабирование языкового режима в рекомендуемом режиме. law;
- По сравнению с классическим SASRec, традиционные наборы тестов, такие как MovieLens Amazon Reviews, улучшились на 20,3–65,8% NDCG@10;
- На практике рейтинг одного конкретного интерфейса увеличился на 12,4% после запуска многопродуктового интерфейса;
- etc.
Тогда ответьте на главный вопрос:
- 12% — это электронные задания онлайн (табл. 6). «Мы сообщаем об основном событии взаимодействия («E-Task») и главном событии потребления («C-Task»)». Электронное задание — это наш основной индикатор онлайн-вовлечения, который можно рассматривать как лайки и ретвиты. C-Task можно представить как такую задачу, как завершение трансляции и ее продолжительность. Остальные 12,4% — это просто результат этапа простого ранжирования. Если сложить два этапа запоминание + ранжирование, получится 12,4% (таблица 6) + 6,2% (таблица 5) = 18,6%. .
- Во время авторегрессионного обучения выборка необходима, поскольку рекомендуемый основной словарный запас сцен превышает уровень миллиарда. Здесь также есть некоторые улучшения алгоритма, которые не включены в эту статью из-за ограничений места. Последующий технический отчет или дополнительный документ могут быть обновлены.
- Для настройки рейтинга см. последний параграф 2.2. «Мы решаем эту проблему, чередуя элементы и действия в основном временном ряду. Результирующий новый временной ряд (до категориальных признаков) равен x0, a0, x1, a1, , xn−1, an−1, где маска. m_i — это 0 для позиций действия». Мы достигаем перекрестного внимания с осознанием цели в авторегрессионной настройке, чередуя содержание элемента и последовательность действий с ним. В приложении фотографии будут добавлены позже.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
