Новейшее руководство по Flink в 2024 году: от основ до трудоустройства, каждый может учиться вместе — развертывание кластера Flink.
1. Роль кластера Flink
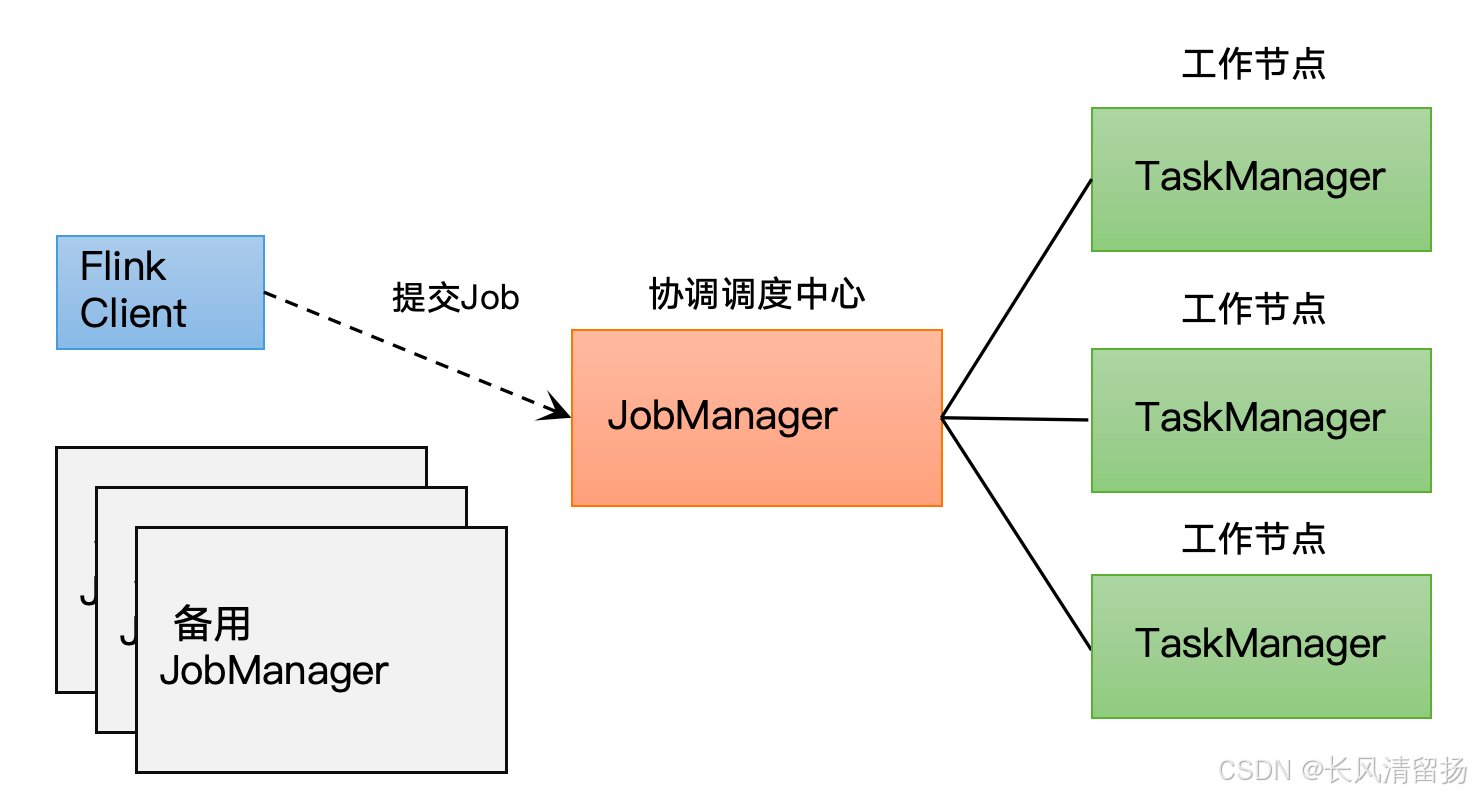
Flink — это платформа обработки потоков с открытым исходным кодом для вычислений с отслеживанием состояния неограниченных и ограниченных потоков данных. В кластере Flink разные роли берут на себя разные обязанности и работают вместе для выполнения задач по обработке данных. Ниже приведен подробный анализ основных ролей в кластере Flink:
Клиент:Код получается и конвертируется клиентом,Затем отправьте его в JobManger. TaskManager:Это реально“люди, которые работают”,Они несут ответственность за все операции по обработке данных. В Flink выполнением операторов и некоторой логикой обработки управляет TaskManager. JobManager:то естьFlinkкластервнутри“стюард”,Централизованно планирует и управляет заданиями и после этого получает задание для выполнения;,Конверсия будет обработана дальше.,Затем распределите задачи по многочисленным диспетчерам задач. На самом деле, JobManager является начальником,Потому что Flink — это механизм распределенной обработки.,Естественно, будет несколько узлов.,Тогда должно быть что-то для управления несколькими узлами.,JobManager отвечает за управление
Примечание. Flink — это очень гибкая платформа обработки. Она поддерживает множество различных сценариев развертывания (например, пряжи или самоуправление) и может легко интегрироваться с различными платформами управления ресурсами. Итак, далее мы дадим краткое введение, чтобы дать всем предварительное понимание, а затем подробно расскажем о применении Flink в различных ситуациях.
1. JobManager
Роль Описание:
JobManager — это главный узел в кластере Flink, который играет роль менеджера кластера и отвечает за координацию и управление всем процессом выполнения заданий. Это основной процесс, контролирующий выполнение приложения. Каждое приложение должно контролироваться и выполняться уникальным JobManager.
Основные обязанности:
- планирование работы:Отвечает за прием работ, представленных клиентами.,И назначьте задание TaskManager для выполнения.
- Управление заданиями:Управление статусом выполнения задания,Контролируйте производительность работы,При необходимости выполните перепланирование и восстановление заданий.
- Управление статусами:Отвечает за управление информацией о статусе задания.,Включая создание и управление данными о состоянии, такими как контрольные точки и точки сохранения.
- Распределение ресурсов:КResourceManagerЗапросить ресурсы,и будет Распределение ресурсы в TaskManager для запуска задания.
Высокая доступность:
Высокая доступность JobManager имеет решающее значение для стабильности и надежности всего кластера. В настройке высокой доступности может быть несколько JobManager, один из которых всегда является ведущим, а остальные — резервными.
2. TaskManager
Роль Описание:
TaskManager является рабочим узлом в кластере Flink и отвечает за фактическое выполнение заданий. За выполнение вычислений фактически отвечает работник, также известный как «работник».
Основные обязанности:
- Выполнение задачи:перениматьJobManagerпоставленные задачи,И выполнить вычислительную логику задачи локально.
- Управление статусами:Сохранение и восстановление информации о состоянии задачи,Включая состояние памяти и состояние персистентности.
- обмен данными:с другимиTaskManagerмеждуобмен данные и связь, реализуя передачу и поток данных.
Управление ресурсами:
TaskManager управляет информацией о ресурсах на узле, где он расположен, например, память, диск, сеть и т. д., и сообщает о состоянии ресурса JobManager при его запуске. Чтобы изолировать ресурсы и увеличить количество разрешенных задач, TaskManager вводит концепцию слота. Каждый слот представляет собой поток, используемый для выполнения одного или нескольких операторов.
3. ResourceManager
Роль Описание:
ResourceManager — это менеджер ресурсов в кластере Flink, отвечающий за унифицированное управление и распределение вычислительных ресурсов кластера.
Основные обязанности:
- Планирование ресурсов:В соответствии с потребностями работы,Выделение вычислительных ресурсов для JobManager в кластере,Убедитесь, что работа может быть выполнена плавно.
- Управление отказоустойчивостью:мониторкластер Статус узла и использование ресурсов в,исуществовать Происходит сбойчасруководить Планирование ресурсы и их перераспределение.
- Динамическое расширение и сжатие:В зависимости от загруженности работы икластеризменения в ресурсах,Динамическая настройка размера кластера,Для улучшения использования ресурсов и эффективности выполнения заданий.
4. Dispatcher
Роль Описание:
Диспетчер — это планировщик в кластере Flink, отвечающий за получение заданий, отправленных клиентами, и распределение заданий в JobManager для выполнения.
Основные обязанности:
- планирование работы:перениматьпредставление клиентаиз Операция,И назначьте задание JobManager для выполнения.
- Управление заданиями:Управление статусом выполнения задания,Контролируйте производительность работы,При необходимости выполните перепланирование и восстановление заданий.
Dispatcher также предоставляет интерфейс REST для отправки приложений Flink на выполнение и запуска нового JobMaster для каждого отправленного задания. Он также запускает Flink WebUI для предоставления информации о выполнении заданий.
5. Blob Server
Роль Описание:
Сервер Blob — это сервер распределения ресурсов в кластере Flink, отвечающий за управление и распределение зависимых ресурсов заданий.
Основные обязанности:
- Управление ресурсами:Сохраняйте и управляйте ресурсами, зависящими от задания,Например, пакеты JAR, файлы библиотек и т. д.
- Распределение ресурсов:КJobManagerиTaskManagerРаспределите зависимые ресурсы задания,Убедитесь, что работа может быть выполнена плавно.
6. ZooKeeper
Роль Описание:
ZooKeeper — это служба координации в кластере Flink, которая отвечает за управление метаданными и информацией о состоянии в кластере.
Основные обязанности:
- Управление метаданными:держатьиуправлятькластер Метаданные в,Например, конфигурация задания, информация о состоянии и т. д.
- Государственная синхронизация:Держатькластермежду каждым узлом в Государственная синхронизация, обеспечивающая согласованность и надежность кластера.
7. Client
Роль Описание:
Клиент — это клиент, предоставленный программой Flink, и не является частью среды выполнения и выполнения программы.
Основные обязанности:
- Когда пользователь отправляет программу Flink,Клиент будет создан первым. Клиент сначала предварительно обработает программу Flink, отправленную пользователем.,И отправьте его на обработку во Флинккластер.
- Клиенту необходимо получить адрес JobManager из конфигурации программы Flink, предоставленной пользователем, установить соединение с JobManager и отправить задание Flink в JobManager.
Подвести итог
Кластер Flink обеспечивает эффективную и надежную обработку потока данных благодаря совместной работе нескольких ролей. Каждая роль предполагает определенные обязанности, которые в совокупности обеспечивают бесперебойное выполнение заданий и стабильную работу кластера.
2. Построение кластера
1. Кластерное планирование
узловой сервер | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
Роль | JobManager TaskManager | TaskManager | TaskManager |
Разверните менеджер JobManager на 102 и разверните TaskManager на 102, 103 и 104.
2. Загрузите и разархивируйте установочный пакет.
(1) Загрузите установочный пакет flink-1.17.0-bin-scala_2.12.tgz и загрузите пакет jar по пути /opt/software узла сервера Hadoop102.
Все информационные пакеты jar и информация для flink 1.17 находятся здесь. Если вы считаете, что баллы необоснованны, оставьте сообщение в области комментариев.
https://download.csdn.net/download/qq_51431069/89625288

https://download.csdn.net/download/qq_51431069/89625288

(2) Разархивируйте flink-1.17.0-bin-scala_2.12.tgz по пути /opt/software в путь /opt/module.
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/3. Измените конфигурацию кластера.
(1) Введите путь к конфигурации, измените файл flink-conf.yaml и укажите сервер узла Hadoop102 в качестве JobManager.
vim /opt/module/flink-1.17.0/con/flink-conf.yamlИзмените следующее содержимое
# Адрес узла JobManager.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# Адрес узла TaskManager необходимо настроить как имя текущего компьютера.
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
(2) Измените рабочий файл и укажите Hadoop102, Hadoop103 и Hadoop104 в качестве диспетчеров задач.
vim /opt/module/flink-1.17.0/con/flink-conf.yaml/workersИзмените следующее содержимое:
hadoop102
hadoop103
hadoop104(3) Измените мастер-файл.
vim /opt/module/flink-1.17.0/con/flink-conf.yaml/mastersИзмените следующее содержимое:
hadoop102:8081(4) Кроме того, компоненты JobManager и TaskManager в кластере также можно оптимизировать и настроить в файле flink-conf.yaml. Основные элементы конфигурации следующие:
- jobmanager.memory.process.size: настройте всю память, которая может использоваться процессом JobManager.,Включает метапространство JVM и другие накладные расходы.,По умолчанию 1600M.,Его можно соответствующим образом настроить в соответствии с масштабом кластера.
- Taskmanager.memory.process.size: настройка всей памяти, которая может использоваться процессом TaskManager.,Включает метапространство JVM и другие накладные расходы.,По умолчанию — 1728M.,Его можно соответствующим образом настроить в соответствии с масштабом кластера.
- Taskmanager.numberOfTaskSlots: Настройте количество слотов, которые может выделить каждый диспетчер задач. Значение по умолчанию — 1, которое можно определить на основе количества процессоров, которые машина, на которой расположен диспетчер задач, может предоставить Flink. Так называемый слот — это вычислительный ресурс, выделенный специально для запуска задачи в TaskManager.
- parallelism.default:FlinkВыполнение Степень параллелизма задачи, по умолчанию равна 1. Приоритет ниже, чем конфигурация параллелизма, заданная в коде, и уровень параллелизма, указанный с помощью параметров при отправке задачи.
4、Каталог установки дистрибутива
(1) После изменения конфигурации отправьте каталог установки Flink на два других узловых сервера.
xsync flink-1.17.0/(2) Измените Taskmanager.host Hadoop103.
Введите Hadoop103
vim /opt/module/flink-1.17.0/conf/flink-conf.yamlИзмените следующее содержимое:
# Адрес узла TaskManager необходимо настроить как имя текущего компьютера.
taskmanager.host: hadoop103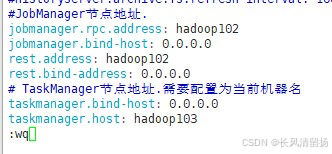
(3) Измените Taskmanager.host Hadoop104.
vim /opt/module/flink-1.17.0/conf/flink-conf.yamlИзмените следующее содержимое:
# Адрес узла TaskManager необходимо настроить как имя текущего компьютера.
taskmanager.host: hadoop104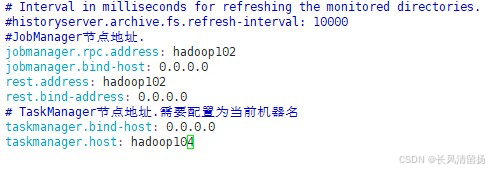
5、Запустить кластер
(1) Запустите start-cluster.sh на сервере узла Hadoop102, чтобы запустить кластер Flink:
cd /opt/module/flink-1.17.0
bin/start-cluster.sh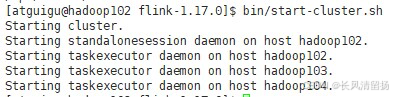
(2) Проверьте прогресс:
jpsall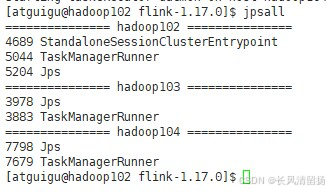
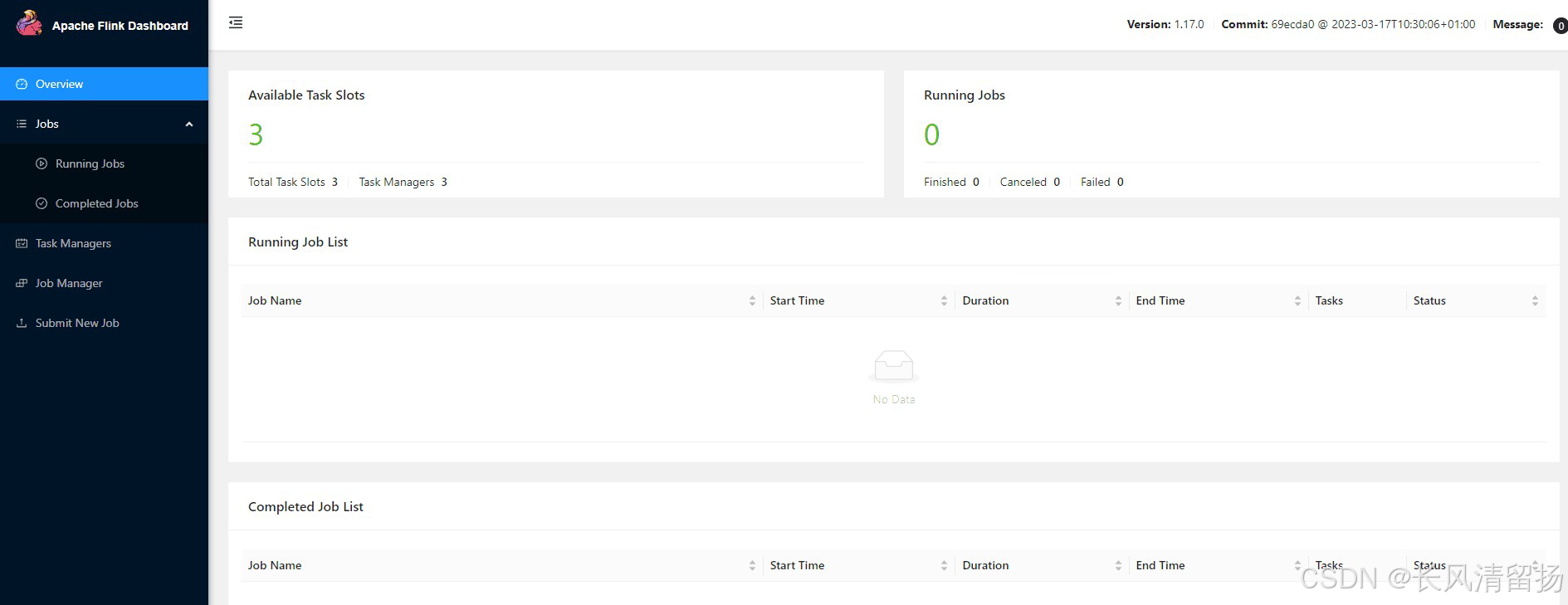
6、Доступ к веб-интерфейсу
После успешного запуска вы также можете посетить http://hadoop102:8081 для мониторинга и управления кластером и задачами Flink.
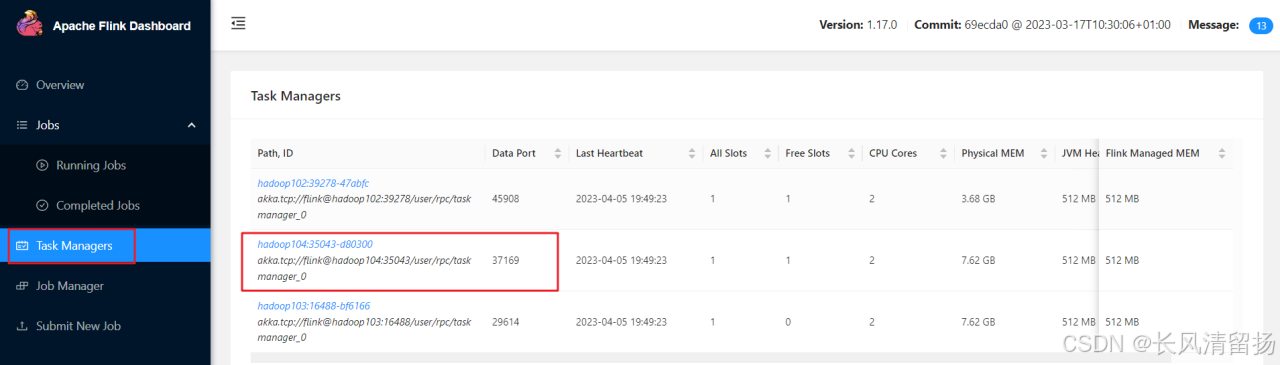
Здесь ясно видно, что количество диспетчеров задач в текущем кластере равно 3, поскольку количество слотов по умолчанию для каждого диспетчера задач равно 1, общее количество слотов и количество доступных слотов равны 3;
3. Отправьте задания в кластер
существоватьПоследний учебник Flink в 2024 году: от основ до трудоустройства, давайте учиться вместе — Начало работы — Блог CSDNВ этой статье мы написали, чтобы прочитатьsocketПрограммный кейс для отправки слов и подсчета количества слов。На этот раз мы будем использовать программу в качестве примера,Демонстрирует, как отправлять задачи в кластер для выполнения. Конкретные шаги заключаются в следующем.
1. Подготовка среды
Примечание. В исполняемой программе, поскольку это сокет, адрес подключения должен быть изменен на адрес, по которому в данный момент находится Hadoop102, иначе будет сообщено об ошибке.
DataStreamSource<String> socket_DS = env.socketTextStream("hadoop102", 9999);Выполните следующую команду в Hadoop102, чтобы запустить netcat.
nc -lk 99992. Упаковка программы
(1) плагин упаковки pom-файлов
существоватьПоследний учебник Flink в 2024 году: от основ до трудоустройства, давайте учиться вместе — Начало работы — Блог CSDNв этой статьеpom.xmlДобавьте конфигурацию упакованного плагина в файл,Подробности следующие
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>(2)оFlinkизпредоставленный объем
Следующее добавлено в зависимости Flink.
<scope>provided</scope>Как правило, если вы выполняете развертывание в производственной среде, лучше всего добавить этот раздел и указать указанную область. Предоставленное означает, что зависимости, связанные с flink, не будут упаковываться во время упаковки, поскольку при развертывании этих зависимостей в кластере происходит развертывание кластера. Он уже существует, поэтому нет необходимости упаковывать его снова.
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId> <!-- фликнуть основные зависимости -->
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId> <!-- флик-клиент -->
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>В среде Maven,когда тысуществоватьpom.xmlЗависимость в файле(dependency)добавить в<scope>provided</scope>час,Это означает, что зависимость требуется на этапах компиляции и тестирования.,носуществоватьбегатьчасне будет Зависит отMavenизбить Сумкаплагин(нравитьсяmaven-jar-plugin)Сумка СодержитсуществоватьфинальныйизjarВ сумке。Это因длябегатьчассреда(Сравниватьнравитьсясервер приложенийилиопределенные рамкинравитьсяApache Ожидается, что Flink) предоставит эти зависимости.
Для Apache Flink, когда вы используете Flink в качестве рабочей среды, многие собственные библиотеки и API Flink предоставляются средой выполнения, поэтому вам не нужно включать эти библиотеки в jar-пакет приложения. Сюда входит основная библиотека Flink, API потоковой обработки, API пакетной обработки и т. д.
существоватьFlinkприложениеизpom.xmlсерединадобавить в<scope>provided</scope>из Распространенные сценарии Сумкавключать:
- Клиентская библиотека Flink:
flink-client_<scala-version>(используется сFlinkкластеркоммуникацияизклиентская библиотека)Обычно устанавливается наprovided,Потому что Flinkкластер уже включает в себя эти библиотеки.,Вашему приложению не нужно снова включать их при отправке в кластер. - библиотека Скала:нравиться Если тыизFlinkПриложение используетсяScalaписатьиз,и ты хочешь убедитьсябиблиотека Версия Скала соответствует версии, используемой во Флинккластере, вы можете обратиться к библиотеке. Скалаотмечен как
provided。но,пожалуйста, обрати внимание,Из-за совместимости версий проблемы библиотеки Скала могут быть более сложными.,Эта практика не всегда необходима или рекомендуется. - Сторонние библиотеки, если они предусмотрены средой Flink.:нравиться Если некоторые сторонние библиотеки также Сумка СодержитсуществоватьFlinkизбегатьчассредасередина(Это сравнительно редко),Вы также можете установить их на
provided。
Однако,Для большинства приложений Flink,основнойизFlinkЗависимости(нравитьсяflink-streaming-java_<scala-version>、flink-connector-kafka_<scala-version>ждать)Обычно не устанавливаетсяprovided,Потому что они не предоставляются напрямую Flinkкластером.,Скорее, вашему приложению требуются эти библиотеки при выполнении.
в общем,Воля Зависимостинастраиватьдляprovidedдадля了确保финальныйбить СумкаизприложениеjarНет Сумка Содержит那些существоватьбегатьчассредасередина已经存существоватьиз Библиотека,Это уменьшает размер jar-пакета и уменьшает потенциальные конфликты путей к классам. В контексте Флинка,В основном это касается Клиентской библиотека Flink и некоторые библиотеки, которые могут быть тесно связаны с версией Flinkкластера.
(3)настраиватьПроблемы, возникающие после предоставленного
Когда ручкаflinkиз Объемнастраиватьстановитьсяпосле предоставления,Оказывается, локальная программа сообщит об ошибке.
Программа ссылается на эту мою статью.Последний учебник Flink в 2024 году: от основ до трудоустройства, давайте учиться вместе — Начало работы — Блог CSDN
Что касается программы Socket для потоковой обработки, то если вы снова запустите программу локально, может появиться ошибка, указывающая на то, что зависимости не могут быть найдены. Фактически, при компиляции предоставляются блоки, связанные с зависимостями Flink.

(4) Решения предоставленных проблем
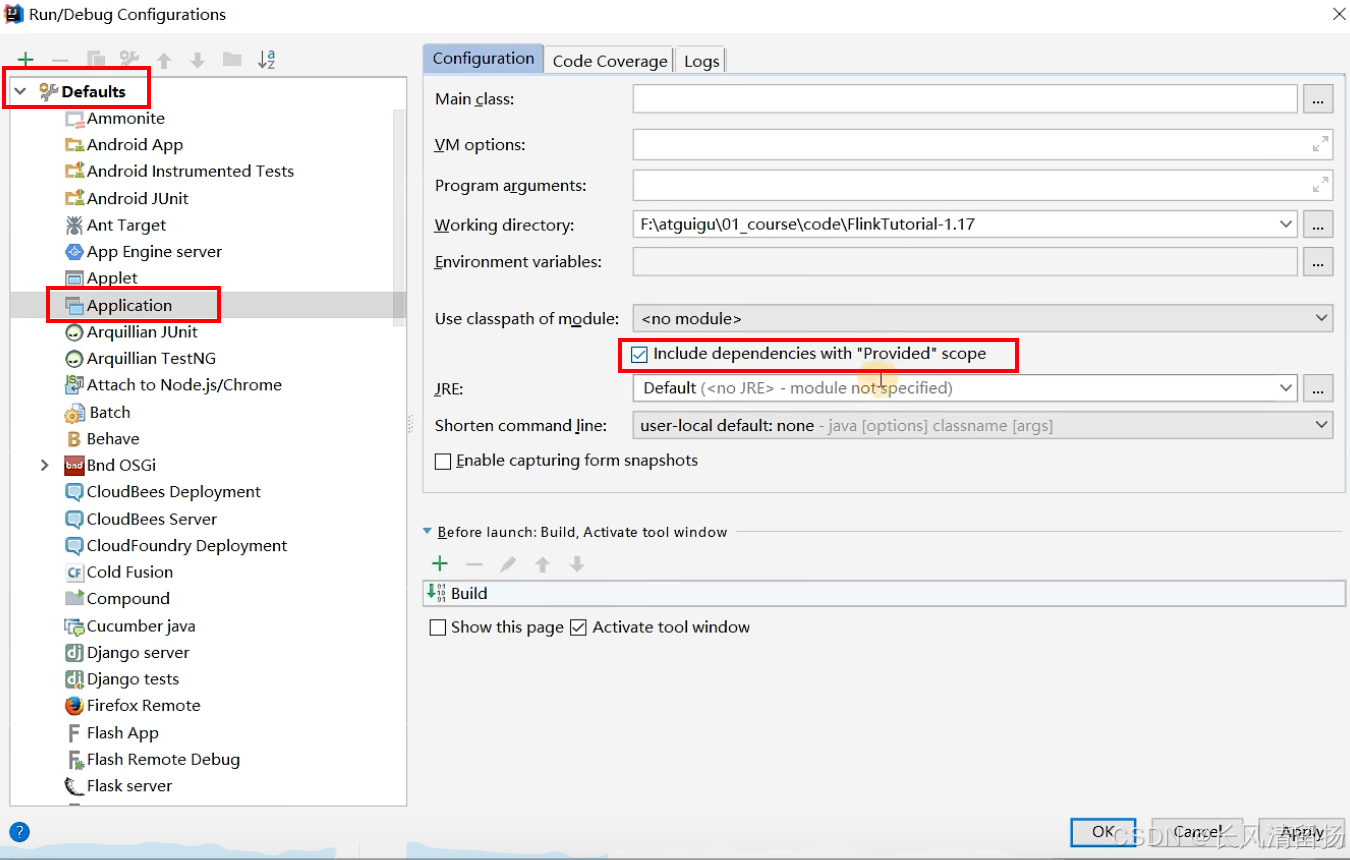
Нажмите «Изменить конфигурацию».
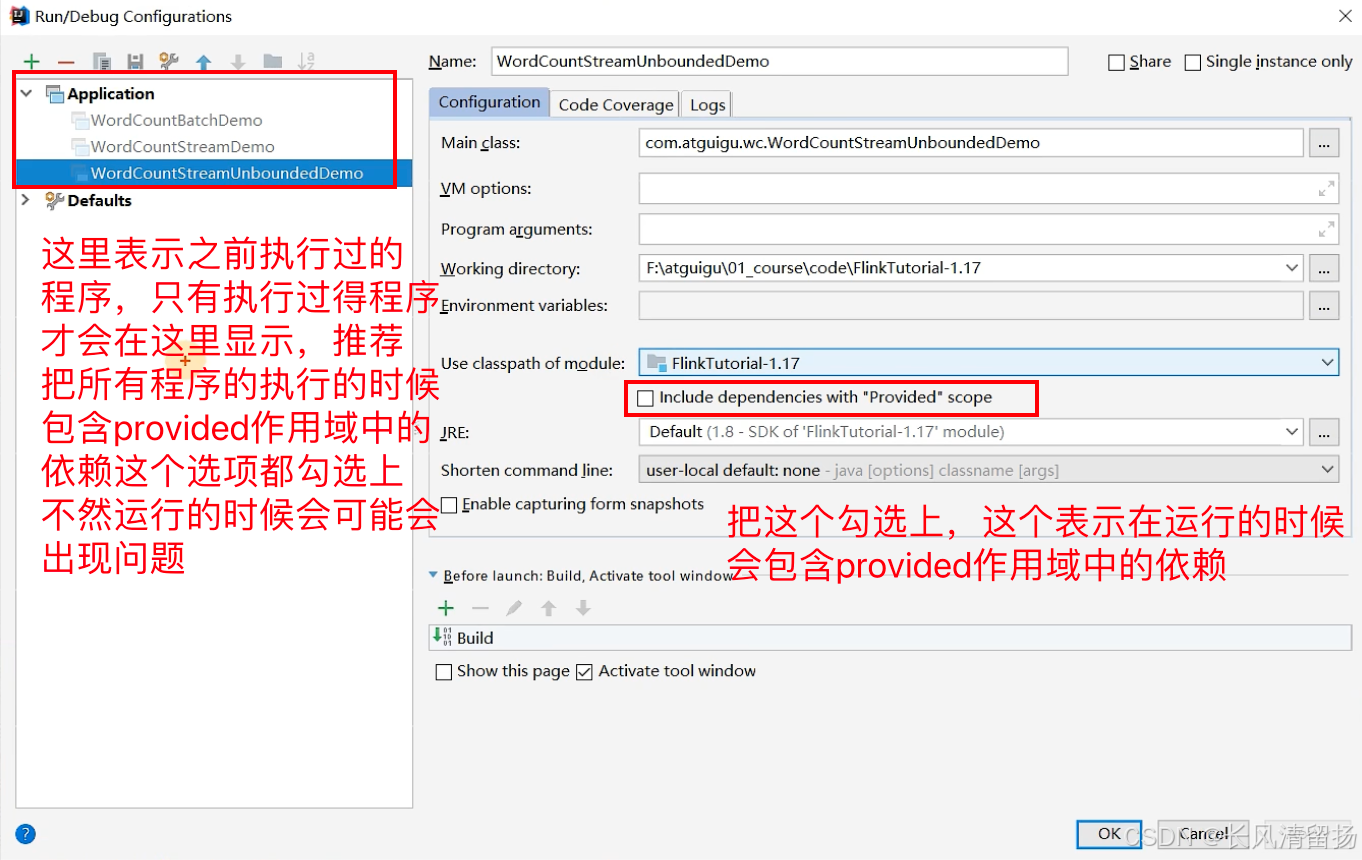
Но если программ много, вы не можете проверять их одну за другой, тогда нажмите «По умолчанию» в разделе «Приложение», настройте шаблон для последующих программ, проверьте параметры, и все последующие программы будут запускаться в соответствии с этой конфигурацией.
(5) Упаковка программы
После настройки плагина вы можете использовать инструмент Maven IDEA для выполнения команды пакета. Однако рекомендуется нажимать кнопку «Очистить» перед каждым пакетом, чтобы очистить ранее упакованный пакет jar. В противном случае могут возникнуть проблемы, если ранее упакованный jar-файл является неактивным. не очищено перед упаковкой. Затем нажмите «Упаковать». Если появится следующее сообщение, упаковка прошла успешно.
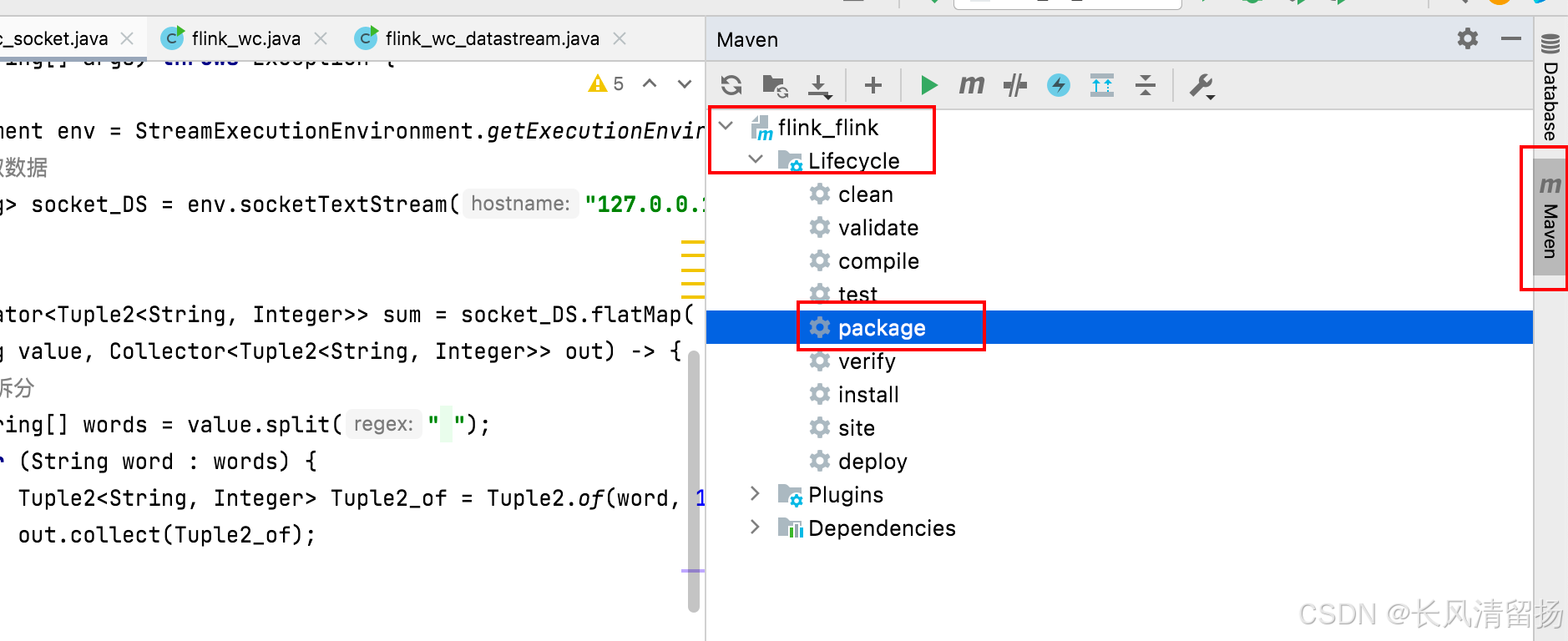
Когда появится сообщение INFO BUILD SUCCESS, упаковка прошла успешно.
После завершения упаковки,Вы можете найти необходимый пакет JAR в целевом каталоге.,Будет два JAR-пакета.,flink_flink-1.0-SNAPSHOT.jar и original-flink_flink-1.0-SNAPSHOT.jar
Но если мы добавим предоставленную область видимости в файл pom, между ними не будет никакой разницы.
- flink_flink-1.0-SNAPSHOT.jar:
- Это тот, который обычно содержит весь ваш код.、Зависимые библиотеки и, возможно, некоторые шаги сборки.(нравитьсяMavenиз
maven-shade-pluginПлагин обработки)изjarСумка。 - нравиться Если тысуществоватьMavenилиGradleКонфигурациясередина使用了нравиться
maven-shade-pluginилиshadowJarждатьплагин,Этот jar-пакет мог подвергнуться перемещению классов (Relocation), объединению ресурсов и т. д.,Чтобы гарантировать, что проблемы пути к классам в jar-пакетах сведены к минимуму.,Избегайте ошибок во время выполнения, вызванных конфликтами зависимостей. - этотjarСумкарекомендуется дляразвертыватьприезжатьFlinkкластер(СумкавключатьFlink Web UI), поскольку он должен был пройти всю необходимую обработку и его можно запускать непосредственно в среде Flink.
- Это тот, который обычно содержит весь ваш код.、Зависимые библиотеки и, возможно, некоторые шаги сборки.(нравитьсяMavenиз
- original-flink_flink-1.0-SNAPSHOT.jar:
- Этот jar-пакет обычно представляет собой необработанный jar-пакет, который не обрабатывался какими-либо специальными плагинами в Maven или Gradle. Он может просто содержать ваш исходный код и скомпилированный байт-код, а также библиотеки зависимостей, разрешенные и загруженные с помощью функций управления зависимостями Maven или Gradle.
- Этот jar-пакет может не включать перемещение классов, объединение ресурсов и т. д., поэтому вероятность возникновения конфликтов путей к классам или проблем с зависимостями может быть выше.
- Вообще говоря,Этот jar-пакет не рекомендуется использовать непосредственно в производственной среде.,Потому что он может быть не оптимизирован для конкретной среды Flinkкластера.
Веб-интерфейс в веб-интерфейсе. Этот jar-пакет был правильно собран.,более подходящийсуществоватьFlinkБегать в окружающей среде。убедитесь, что выиз Конфигурация сборки(нравитьсяMavenизpom.xmlилиGradleизbuild.gradle)Уже настроен таргетингFlinkизразвертывать需求руководить了适当из Конфигурация,Включая, помимо прочего, перемещение классов, обработку ресурсов и т. д.

3. Отправьте задание через веб-интерфейс.
(1) После завершения упаковки задачи мы открываем страницу веб-интерфейса Flink, нажимаем «Отправить новое задание» на правой панели навигации, затем нажимаем кнопку «+ Добавить новый» и выбираем пакет JAR для загрузки и запуска, как показано на рисунке ниже.
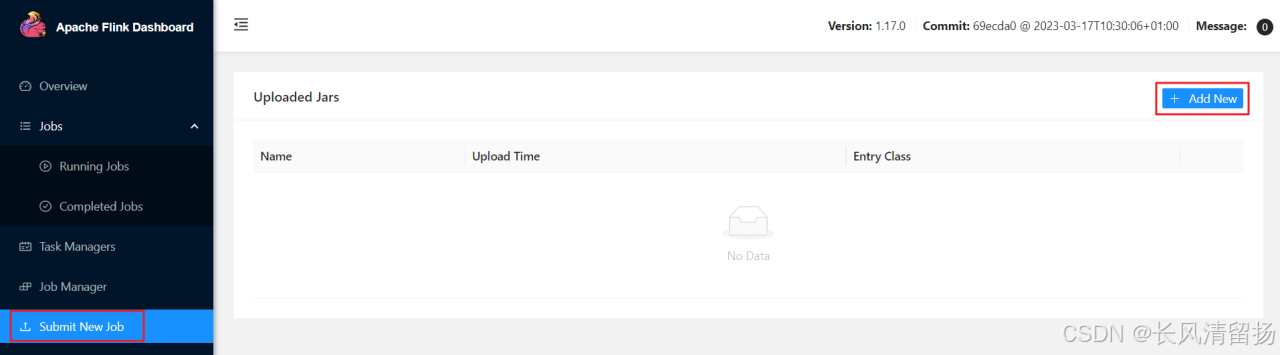
Пакет JAR будет загружен, как показано на рисунке ниже:
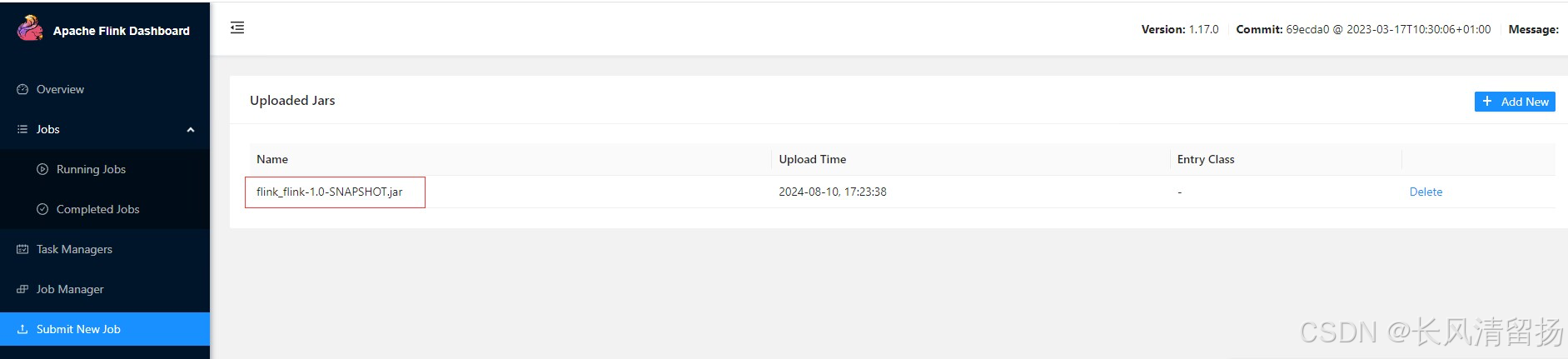
(2) Нажмите на пакет JAR, появится страница конфигурации задачи и настройте ее соответствующим образом.
В основном настройте полное имя основного класса входа в программу, параллелизм выполнения задачи, параметры конфигурации, необходимые для запуска задачи, путь к точке сохранения и т. д., как показано на рисунке ниже. вы можете нажать кнопку «Отправить», чтобы отправить задачу для запуска в кластере.
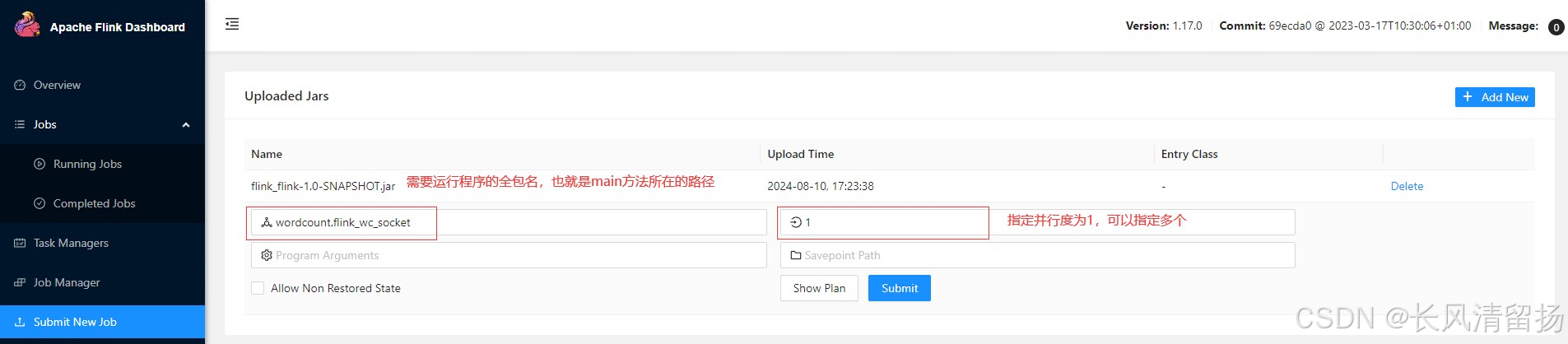
Таким образом, вы можете напрямую скопировать полное имя пакета программы, которую нужно запустить.
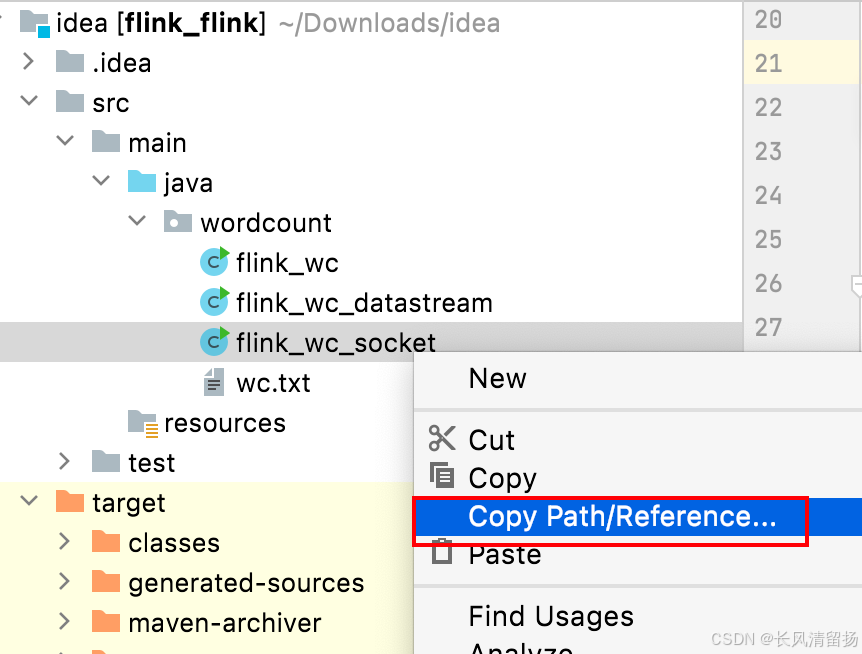
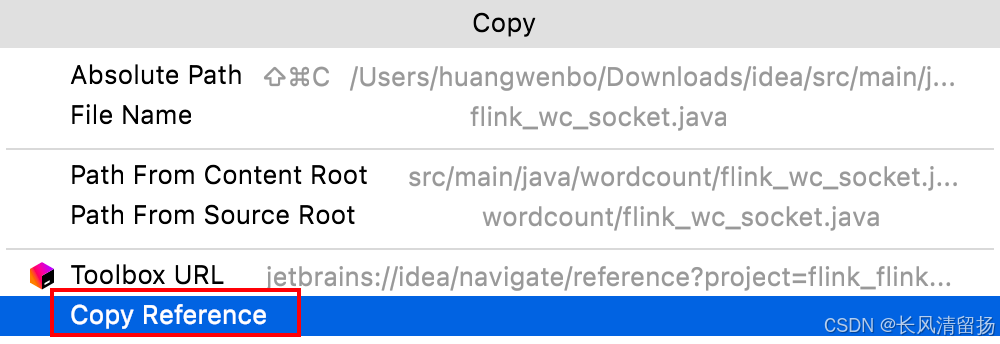
Перед отправкой убедитесь, что netcat включен. В противном случае будет сообщено об ошибке.

(3) После успешной отправки задачи вы можете нажать «Выполняемые задания» на левой панели навигации, чтобы просмотреть список запущенных программ.
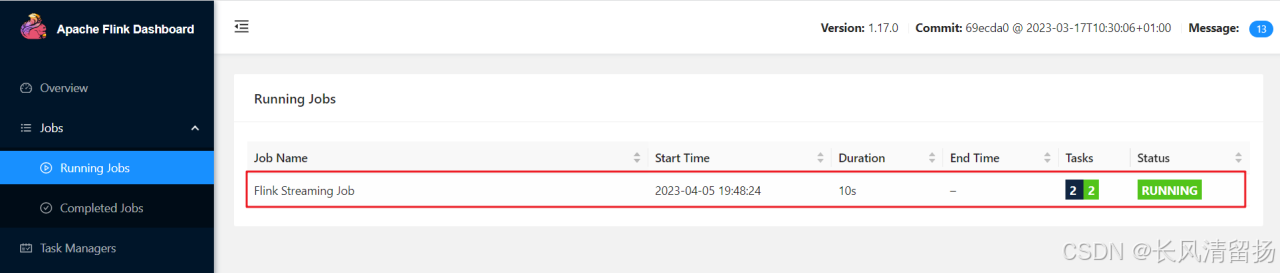
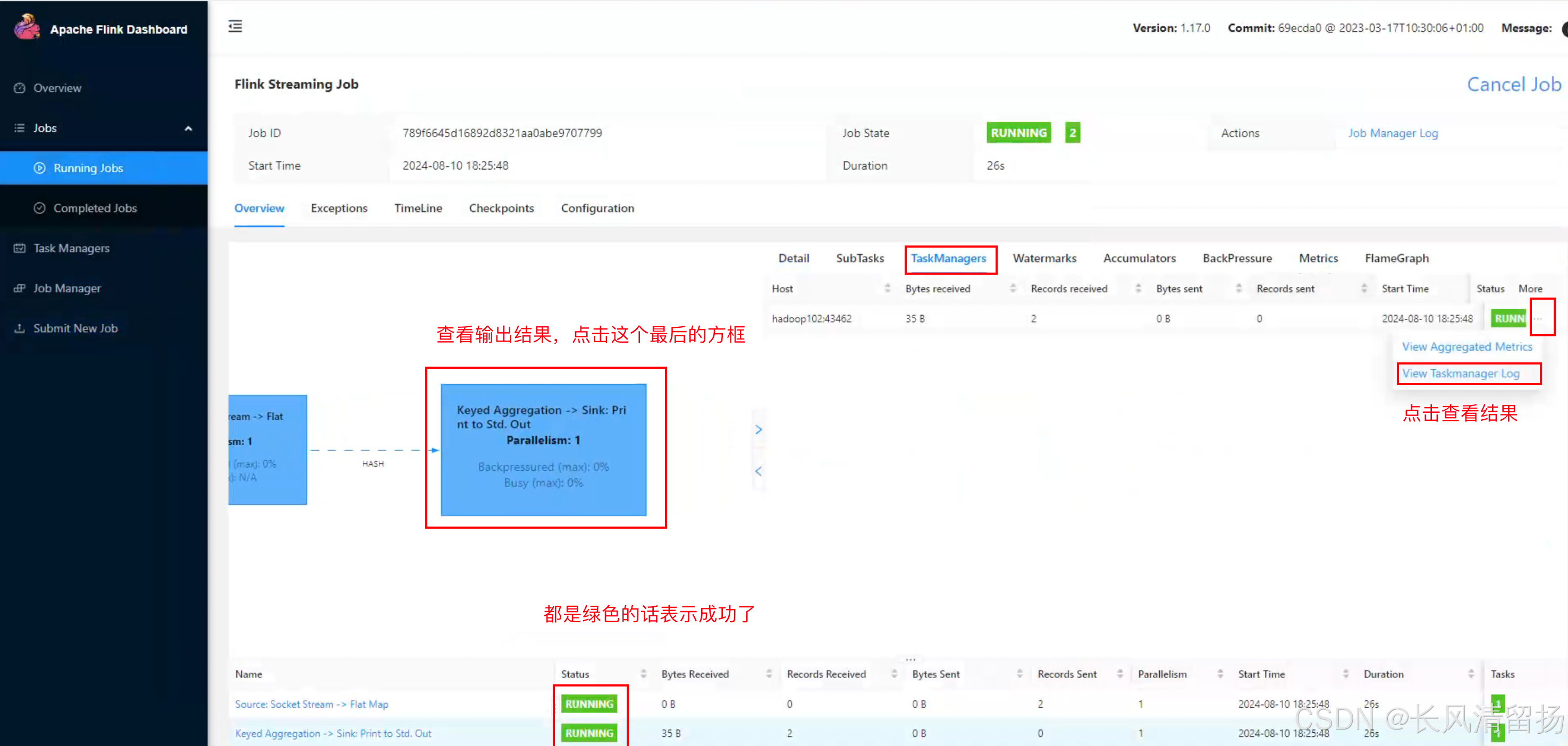
(4) Второй способ проверить рабочее состояние
Сначала нажмите «Диспетчер задач», затем щелкните узел сервера 192.168.10.104 справа.
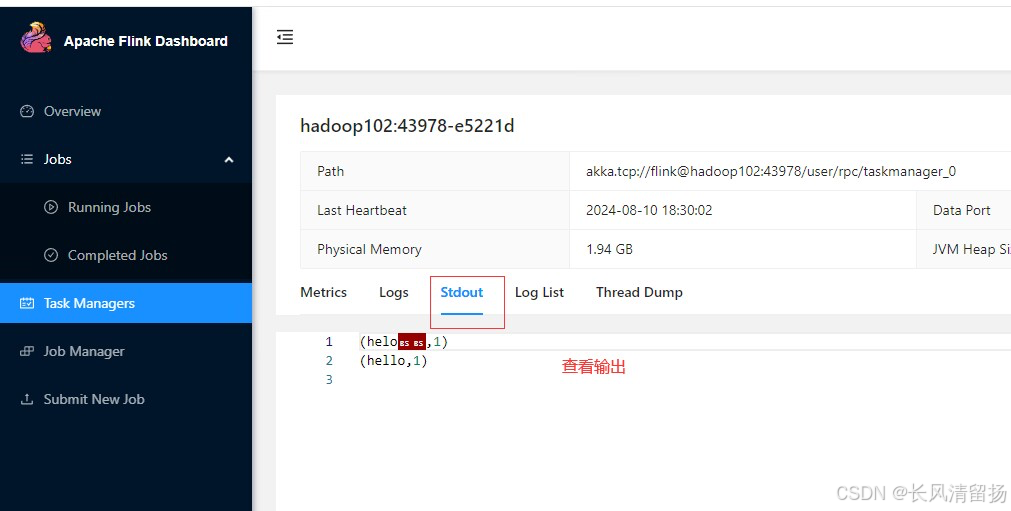
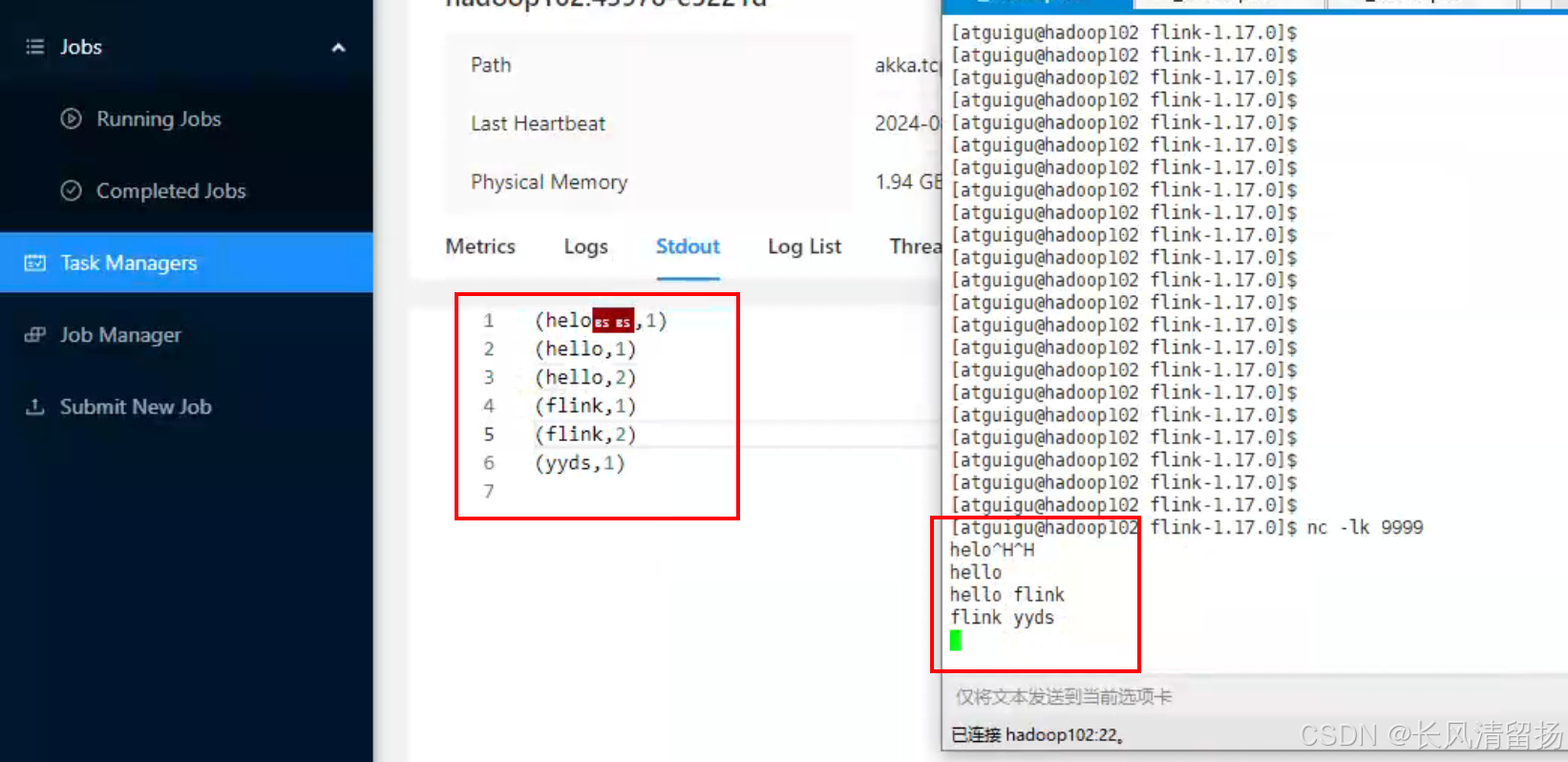
Нажмите Stdout, чтобы просмотреть статистику слов приветствия.

Примечание. Если узел Hadoop104 не имеет статистических данных о словах, вы можете проверить их на других узлах TaskManager.
(5) Тест
Введите содержимое в порт сокета
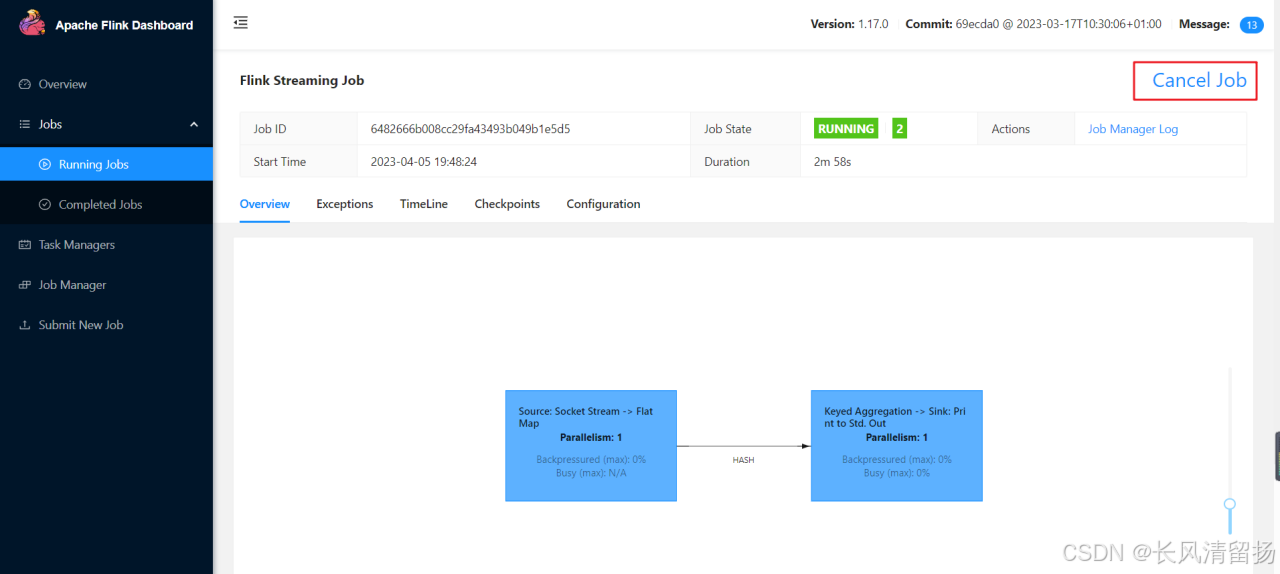
(6) Завершить программу
Нажмите на задачу, чтобы просмотреть сведения о выполняемой задаче, или нажмите «Отменить задание», чтобы завершить выполнение задачи.
4. Отправьте задание из командной строки.
Предполагается, что Flink-кластер запущен.
Помимо отправки задач через WEB-интерфейс, вы также можете отправлять задачи непосредственно через командную строку. Для удобства мы можем сначала загрузить jar-пакет непосредственно в каталог Hadoop102 flink-1.17.0 (это не обязательно, он может находиться в другом каталоге)
(1) Сначала вам нужно запустить кластер.
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh(2) Выполните следующую команду в Hadoop102, чтобы запустить netcat.
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777(3) Выполните команду запуска.
Снова откройте окно Hadoop102, введите путь установки Flink и используйте команду Flink Run в командной строке, чтобы отправить задание.
bin/flink run -m hadoop102:8081 -c wordcount.flink_wc_socket ./flink_flink-1.0-SNAPSHOT.jarbin/flink:ЭтоFlinkВ каталоге установкиизbin子目录серединаизflinkСкрипт,Используется для выполнения различных команд Flink.run:ЭтоflinkСкриптизподкоманда,Используется для отправки заданий во Flinkкластер для выполнения.-m hadoop102:8081:этот Параметры указаныFlinkкластеризMasterузел(JobManager)изадресипорт。существоватьэтот例子середина,Masterузелродыhadoop102на этой машине,и且监听существовать8081в порту。ЭтоFlinkкластер Интерфейс управления(Web UI) и порт по умолчанию для отправки заданий.-c wordcount.flink_wc_socket:этот Параметры указаны Операцияизосновной класс(Main Class)из Полное имя。существоватьэтот例子середина,wordcount.flink_wc_socketда Сумка Содержитmainметодиздобрыйиз Полное имя,Этот класс является точкой входа в задание. Flink загрузит этот класс,и执行其серединаизmainСпособ начать работу。./flink_flink-1.0-SNAPSHOT.jar:Это ОтправитьизFlinkОперацияизJARСумкапуть。существоватьэтот例子середина,JARСумка名дляflink_flink-1.0-SNAPSHOT.jar,Находится в текущем каталоге(Зависит от./выражать)。этотJARСумка Сумка Содержит了Операцияизвсе зависимостии После компиляциииздобрый文件,Это необходимый компонент для выполнения заданий Flink.

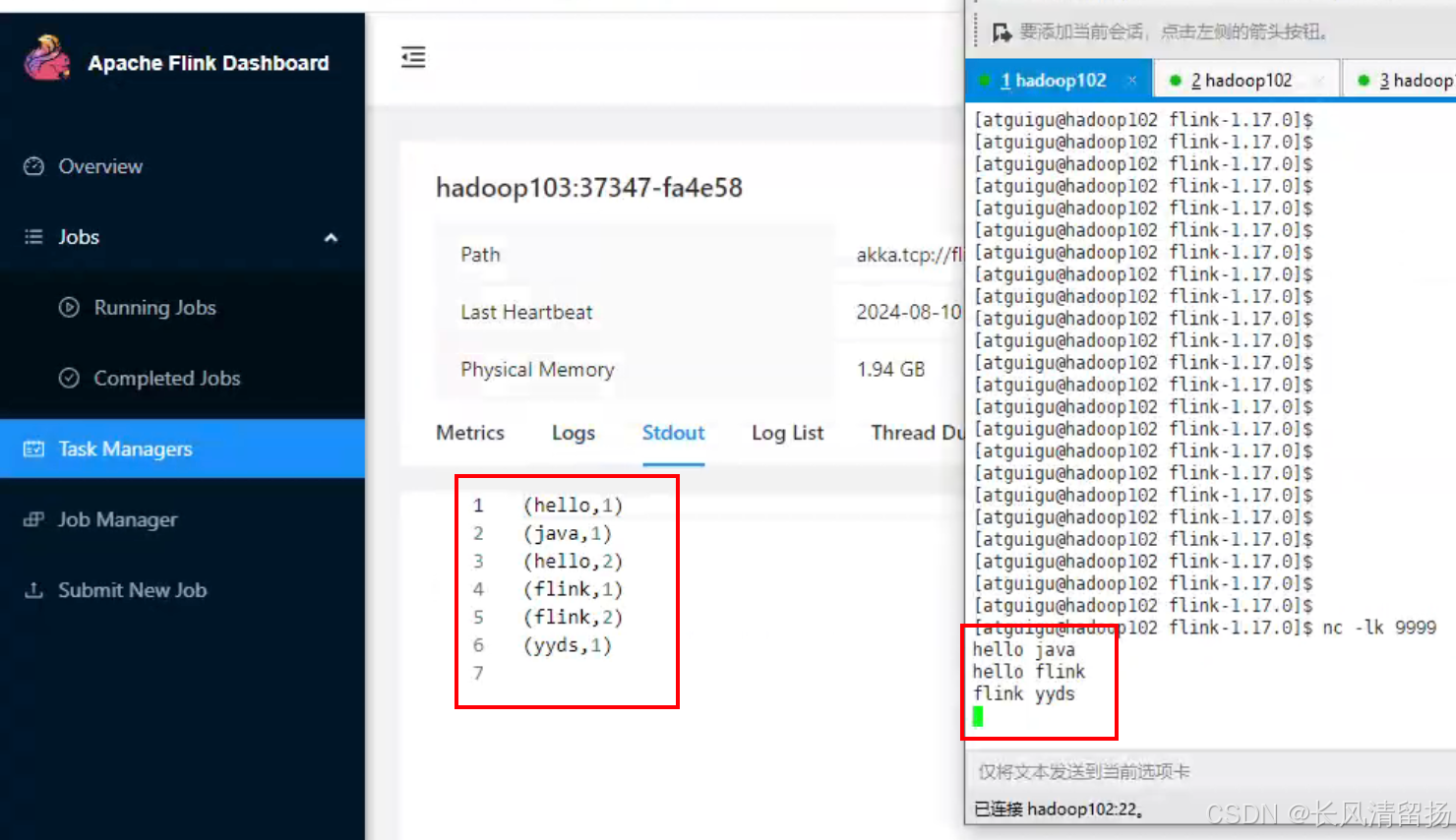
(4) Откройте веб-интерфейс в браузере.
Откройте веб-интерфейс в браузере и перейдите по адресу http://hadoop102:8081, чтобы просмотреть состояние выполнения приложения.
Используйте netcat для ввода данных, и вы сможете увидеть соответствующие статистические результаты в стандартном выводе (Stdout) TaskManager.
(5) По пути /opt/module/flink-1.17.0/log вы можете просмотреть узел TaskManager.
cat flink-atguigu-standalonesession-0-hadoop102.out


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
